
3. Regresión Ridge y Lasso#
Introducción
Los modelos de regresión lineal son esenciales en estadística y aprendizaje automático para analizar la relación entre variables dependientes e independientes. Su simplicidad permite interpretar dichas relaciones, siendo útiles en la predicción de valores futuros, evaluación del impacto de variables y detección de tendencias.
Además, forman la base de métodos avanzados como la regresión logística y redes neuronales, siendo clave en economía, ciencias sociales, biología e ingeniería.
3.1. Modelo de regresión lineal#
3.1.1. Formulación#
El modelo
se denomina, modelo de regresión lineal clásico, si se cumplen los siguientes supuestos:
\(\mathbb{E}(\boldsymbol{\varepsilon})=\boldsymbol{0}\)
\(\text{Cov}(\boldsymbol{\varepsilon})=\mathbb{E}(\boldsymbol{\varepsilon}\boldsymbol{\varepsilon}^{T})=\sigma^{2}\boldsymbol{I}\)
La matriz de diseño \(\boldsymbol{X}\) tiene rango completo, es decir \(\textrm{rk}(\boldsymbol{X})=p+1\)
El modelo de regresión normal clasico es obtenido si adicionalmente se tiene que \(\boldsymbol{\varepsilon}\sim N(\boldsymbol{0}, \sigma^{2}\boldsymbol{I})\).
El modelo de regresión lineal (3.1) puede escribirse en la siguiente forma
A partir del sistema (3.2), se puede observar que la \(i\)-esima predicción para un modelo lineal es la siguiente:
Aquí, \(x_{i1},\dots, x_{ip}\) denotan las variables predictoras o características (en este ejemplo, el número de características es \(p\)). Los valores, \(\hat{\beta}_{i},~i=0,1,\dots,p\), son los parámetros aprendidos por el modelo y \(\hat{y}_{i}\) es la predicción obtenida por el modelo. Por ejemplo, para un conjunto de datos con una sola característica, se tiene que:
Aquí, \(\hat{\beta}_{1}\) es la pendiente y \(\hat{\beta}_{0}\) es el desplazamiento en el eje \(y\). Para más características, \(\boldsymbol{\hat{\beta}}\) contiene las pendientes a lo largo de cada eje de características. Alternativamente, se puede pensar en la respuesta predicha como una suma ponderada de las características de entrada, con pesos (que pueden ser negativos) dados por las entradas de \(\boldsymbol{\hat{\beta}}\).
3.1.2. Ilustración#
Considere el ejemplo de intentar aprender los parámetros \(\hat{\beta}_{1}:=w[0]\) y \(\hat{\beta}_{0}:=b\) en nuestro conjunto de datos de ondas unidimensionales (wave) usando
plot_linear_regression_wave(). En este caso, la función para la regresión lineal de ondas unidimensionales, usa la libreríaLinearRegression(), para ajustar la recta de regresión, basada en mínimos cuadrados.
import mglearn
import warnings
import seaborn as sns
warnings.filterwarnings('ignore')
sns.set_style("darkgrid")
mglearn.plots.plot_linear_regression_wave()
w[0]: 0.393906 b: -0.031804
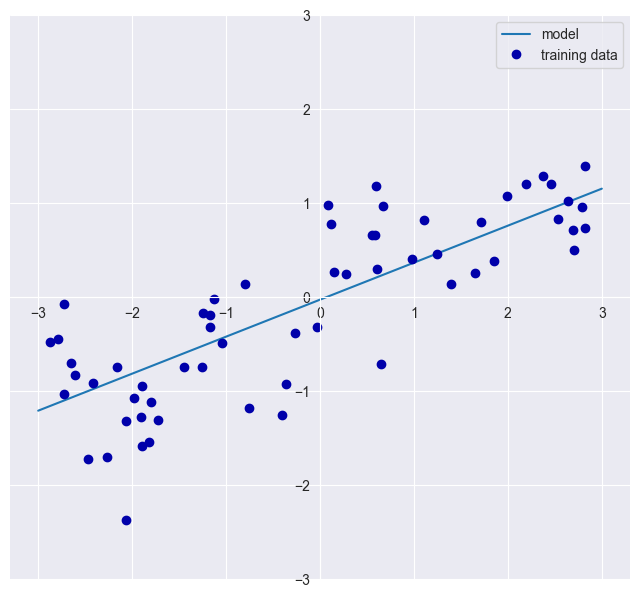
Si observamos \(\hat{\beta}_{1}\), vemos que la pendiente debería estar en torno a 0.4, lo que podemos confirmar visualmente en el gráfico. El intercepto, punto en el que la línea de predicción debería cruzar el eje \(y\), está ligeramente por debajo de cero, lo que también se puede confirmar en la imagen.
Los modelos de regresión lineal pueden caracterizarse como modelos de regresión en los que la predicción es una línea para una sola característica, un plano cuando se utilizan dos características, o un hiperplano en dimensiones más altas (es decir, cuando se utilizan más características).
Si se comparan las predicciones realizadas por la línea recta con las realizadas por el modelo KNeighborsRegressor, usar una línea recta para hacer predicciones parece muy restrictivo. Parece que se pierden todos los detalles finos de los datos. En cierto sentido, esto es cierto. Es una suposición fuerte (y algo irreal) que nuestro objetivo \(y\) es una combinación lineal de las características. Observar los datos de forma unidimensional da una perspectiva algo sesgada.
Observación
Para los conjuntos de datos con muchas características, los modelos lineales pueden ser muy potentes. En particular, si tiene más características que puntos de datos de entrenamiento, cualquier objetivo \(y\) puede modelarse perfectamente (en el conjunto de entrenamiento) como una función lineal.
Hay muchos modelos lineales diferentes para la regresión. La diferencia entre estos modelos radica en cómo se aprenden los parámetros del modelo \(\boldsymbol{\beta}_{1}\) y \(\boldsymbol{\beta}_{0}\) a partir de los datos de entrenamiento, y en cómo se puede controlar la complejidad del modelo. A continuación veremos los modelos lineales más populares.
3.2. Mínimos Cuadrados Ordinarios#
La regresión lineal, o mínimos cuadrados ordinarios (Ordinary Least Squares (OLS)), es el modelo lineal más sencillo y clásico para la regresión. La regresión lineal encuentra el vector de parámetros \(\boldsymbol{\hat{\beta}}\) que minimiza el error cuadrático medio entre las predicciones y los verdaderos objetivos de la regresión, \(y\), en el conjunto de entrenamiento.
El error cuadrático medio es la suma de las diferencias al cuadrado entre las predicciones y los valores reales. La regresión lineal no tiene parámetros, lo cual es una ventaja, pero, no tiene forma de controlar la complejidad del modelo.
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
import matplotlib
X, y = mglearn.datasets.make_wave(n_samples=60)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
lr = LinearRegression().fit(X_train, y_train)
random_state=42 :)
El número
42es normalmente elegido en la literatura relacionadas conAI, como homenaje al libro de laDouglas Adams“The Hitchhiker’s Guide to the Galaxy”, una serie de cómic de ciencia ficción creada porDouglas Adamsque se ha hecho popular entre los aficionados al género y los miembros de la comunidad científica.El número 42 corresponde a la respuesta a la gran pregunta
"Life, the universe, and everything", calculada por un ordenador (llamado"Deep Thought") creado específicamente para resolverla:). Supuestamente, el pensamiento profundo (Deep Thought) tarda \(7\frac{1}{2}\) millones de años en calcular y comprobar la respuesta, que resulta ser 42.
Sin embargo,
random_statepuede ser cualquier número entero, mas aún, podemos realizar ungrid searchpara conseguir aquel parámetrorandom_stateque nos entrega el mejor score. Mas adelante abordaremos el uso deGridSearch. Si no establecerandom_stateen42o cualquier otro entero positivo, cada vez que ejecute su código de nuevo, generará un conjunto de pruebas diferente.
Los parámetros de “pendiente” (\(\hat{\beta}_{i},~i=1,2,\dots,p\)), también llamados pesos o coeficientes, se almacenan en el atributo coef_, mientras que el desplazamiento o intercepto (\(\hat{\beta}_{0}\)) se almacena en el atributo
intercept_:
print("lr.coef_: {}".format(lr.coef_))
print("lr.intercept_: {}".format(lr.intercept_))
lr.coef_: [0.39390555]
lr.intercept_: -0.031804343026759746
Observation 3.1
El extraño guion bajo al final de coef_ e intercept_ es usado a menudo por scikit-learn para almacenar cualquier objeto que se deriva de los datos de entrenamiento, usando atributos que terminan con un guion bajo al final. Esto es para separarlos de los parámetros que son establecidos por el usuario.
El atributo
intercept_es siempre un único número flotante, mientras que el atributo coef_ es una matriz NumPy con una entrada por característica. Como solo tenemos una característica de entrada en el conjunto de datoswave,lr.coef_solo tiene una entrada. Veamos el rendimiento del conjunto de entrenamiento y del conjunto de prueba
print("Training set score: {:.2f}".format(lr.score(X_train, y_train)))
print("Test set score: {:.2f}".format(lr.score(X_test, y_test)))
Training set score: 0.67
Test set score: 0.66
¿Cual sería un buen score?
Definir un buen score en machine learning es un tema subjetivo, y bastante ligado a los datos. Pero, de forma coherente con los estándares de la industria, cualquier score superior al 70% es un gran rendimiento del modelo. De hecho, una medida de precisión de entre el 70% y el 90% no sólo es ideal, sino que es realista.
Un \(R^2\) en torno a 0.66 no es muy bueno, pero podemos ver que los score en los conjuntos de entrenamiento y de prueba están muy cerca. Esto significa que probablemente estemos subajustando (underfitting), no sobreajustando (overfitting) nuestro modelo de regresión lineal. Para este conjunto de datos unidimensional, hay poco peligro de overfitting, ya que el modelo es muy simple (o restringido).
En este tipo de casos, optamos por complejizar el modelo para obtener un modelo menos simple. Sin embargo, con conjuntos de datos de mayor dimensión (i.e dataset con un gran número de características), los modelos lineales son más potentes, y hay más posibilidades de que se ajusten en exceso.
3.3. Aplicación: LinearRegression()#
Veamos cómo se comporta
LinearRegressionen un conjunto de datos más complejo, como el conjunto de datos de viviendas de Boston. Recordemos que este conjunto de datos tiene 506 muestras y 105 características derivadas. En primer lugar, cargamos el conjunto de datos y lo dividimos en un conjunto de entrenamiento y otro de prueba. A continuación, construimos el modelo de regresión lineal como antes. Iniciemos realizando un análisis exploratorio de datos.

3.3.1. Análisis Exploratorio de Datos#
1. Importar librerías PythonImportar librerías Python
Se importan las librerías esenciales para facilitar el análisis que abarca la carga de datos, la evaluación estadística, la visualización, la transformación de datos, la fusión y la unión
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
2. Lectura de datos
data = pd.read_csv('https://raw.githubusercontent.com/lihkir/Data/main/boston.csv', index_col=0)
Análisis de Datos: El objetivo principal de la comprensión de datos es obtener información general sobre los datos, que abarca el número de filas y columnas, valores y tipos de datos así como también datos faltantes.
data.head()
| crim | zn | indus | chas | nox | rm | age | dis | rad | tax | ptratio | black | lstat | medv | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 0.00632 | 18.0 | 2.31 | 0 | 0.538 | 6.575 | 65.2 | 4.0900 | 1 | 296 | 15.3 | 396.90 | 4.98 | 24.0 |
| 2 | 0.02731 | 0.0 | 7.07 | 0 | 0.469 | 6.421 | 78.9 | 4.9671 | 2 | 242 | 17.8 | 396.90 | 9.14 | 21.6 |
| 3 | 0.02729 | 0.0 | 7.07 | 0 | 0.469 | 7.185 | 61.1 | 4.9671 | 2 | 242 | 17.8 | 392.83 | 4.03 | 34.7 |
| 4 | 0.03237 | 0.0 | 2.18 | 0 | 0.458 | 6.998 | 45.8 | 6.0622 | 3 | 222 | 18.7 | 394.63 | 2.94 | 33.4 |
| 5 | 0.06905 | 0.0 | 2.18 | 0 | 0.458 | 7.147 | 54.2 | 6.0622 | 3 | 222 | 18.7 | 396.90 | 5.33 | 36.2 |
data.tail()
| crim | zn | indus | chas | nox | rm | age | dis | rad | tax | ptratio | black | lstat | medv | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 502 | 0.06263 | 0.0 | 11.93 | 0 | 0.573 | 6.593 | 69.1 | 2.4786 | 1 | 273 | 21.0 | 391.99 | 9.67 | 22.4 |
| 503 | 0.04527 | 0.0 | 11.93 | 0 | 0.573 | 6.120 | 76.7 | 2.2875 | 1 | 273 | 21.0 | 396.90 | 9.08 | 20.6 |
| 504 | 0.06076 | 0.0 | 11.93 | 0 | 0.573 | 6.976 | 91.0 | 2.1675 | 1 | 273 | 21.0 | 396.90 | 5.64 | 23.9 |
| 505 | 0.10959 | 0.0 | 11.93 | 0 | 0.573 | 6.794 | 89.3 | 2.3889 | 1 | 273 | 21.0 | 393.45 | 6.48 | 22.0 |
| 506 | 0.04741 | 0.0 | 11.93 | 0 | 0.573 | 6.030 | 80.8 | 2.5050 | 1 | 273 | 21.0 | 396.90 | 7.88 | 11.9 |
data.info()
<class 'pandas.core.frame.DataFrame'>
Index: 506 entries, 1 to 506
Data columns (total 14 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 crim 506 non-null float64
1 zn 506 non-null float64
2 indus 506 non-null float64
3 chas 506 non-null int64
4 nox 506 non-null float64
5 rm 506 non-null float64
6 age 506 non-null float64
7 dis 506 non-null float64
8 rad 506 non-null int64
9 tax 506 non-null int64
10 ptratio 506 non-null float64
11 black 506 non-null float64
12 lstat 506 non-null float64
13 medv 506 non-null float64
dtypes: float64(11), int64(3)
memory usage: 59.3 KB
Información de atributos (por orden):
CRIM: tasa de criminalidad per cápita por ciudadZN: proporción de suelo residencial para parcelas de más de 25.000 pies cuadradosINDUS: proporción de acres comerciales no minoristas por ciudadCHAS: Variable dummy del Río Charles (= 1 si el tramo limita con el río; 0 en caso contrario)NOX: concentración de óxidos nítricos (partes por 10 millones)RM: número medio de habitaciones por viviendaAGE: proporción de unidades ocupadas por sus propietarios construidas antes de 1940DIS: distancias ponderadas a cinco centros de empleo de BostonRAD: índice de accesibilidad a autopistas radialesTAX: tipo del impuesto sobre bienes inmuebles de valor íntegro por 10.000 dólaresPTRATIO: relación alumnos-profesor por ciudadB: 1000(Bk - 0,63)^2 donde Bk es la proporción de negros por ciudadLSTAT: % más bajo de la poblaciónMEDV: Valor medio de las viviendas ocupadas por sus propietarios en $1000’s.
Comprobación de duplicados
data.nunique()
crim 504
zn 26
indus 76
chas 2
nox 81
rm 446
age 356
dis 412
rad 9
tax 66
ptratio 46
black 357
lstat 455
medv 229
dtype: int64
Conteo de datos faltantes y porcentaje
data.isnull().sum()
crim 0
zn 0
indus 0
chas 0
nox 0
rm 0
age 0
dis 0
rad 0
tax 0
ptratio 0
black 0
lstat 0
medv 0
dtype: int64
(data.isnull().sum()/(len(data)))*100
crim 0.0
zn 0.0
indus 0.0
chas 0.0
nox 0.0
rm 0.0
age 0.0
dis 0.0
rad 0.0
tax 0.0
ptratio 0.0
black 0.0
lstat 0.0
medv 0.0
dtype: float64
Operaciones relacionadas con Feature Engineering, Reducción y Gestión pueden llevarse a cabo de ser necesarias.
3. EDA Análisis exploratorio de datos
El análisis exploratorio de datos se refiere al proceso crucial de realizar investigaciones iniciales sobre los datos para descubrir patrones y comprobar supuestos con la ayuda de estadísticas resumidas y representaciones gráficas.
El EDA puede utilizarse para buscar valores atípicos, patrones y tendencias en los datos.
EDA ayuda a encontrar patrones significativos en los datos.
EDA proporciona una visión en profundidad de los conjuntos de datos para resolver nuestros problemas de negocio.
EDA proporciona una pista para imputar los valores que faltan en el conjunto de datos.
Resumen estadístico
data['chas'] = data['chas'].astype(object)
data.describe().T
| count | mean | std | min | 25% | 50% | 75% | max | |
|---|---|---|---|---|---|---|---|---|
| crim | 506.0 | 3.613524 | 8.601545 | 0.00632 | 0.082045 | 0.25651 | 3.677083 | 88.9762 |
| zn | 506.0 | 11.363636 | 23.322453 | 0.00000 | 0.000000 | 0.00000 | 12.500000 | 100.0000 |
| indus | 506.0 | 11.136779 | 6.860353 | 0.46000 | 5.190000 | 9.69000 | 18.100000 | 27.7400 |
| nox | 506.0 | 0.554695 | 0.115878 | 0.38500 | 0.449000 | 0.53800 | 0.624000 | 0.8710 |
| rm | 506.0 | 6.284634 | 0.702617 | 3.56100 | 5.885500 | 6.20850 | 6.623500 | 8.7800 |
| age | 506.0 | 68.574901 | 28.148861 | 2.90000 | 45.025000 | 77.50000 | 94.075000 | 100.0000 |
| dis | 506.0 | 3.795043 | 2.105710 | 1.12960 | 2.100175 | 3.20745 | 5.188425 | 12.1265 |
| rad | 506.0 | 9.549407 | 8.707259 | 1.00000 | 4.000000 | 5.00000 | 24.000000 | 24.0000 |
| tax | 506.0 | 408.237154 | 168.537116 | 187.00000 | 279.000000 | 330.00000 | 666.000000 | 711.0000 |
| ptratio | 506.0 | 18.455534 | 2.164946 | 12.60000 | 17.400000 | 19.05000 | 20.200000 | 22.0000 |
| black | 506.0 | 356.674032 | 91.294864 | 0.32000 | 375.377500 | 391.44000 | 396.225000 | 396.9000 |
| lstat | 506.0 | 12.653063 | 7.141062 | 1.73000 | 6.950000 | 11.36000 | 16.955000 | 37.9700 |
| medv | 506.0 | 22.532806 | 9.197104 | 5.00000 | 17.025000 | 21.20000 | 25.000000 | 50.0000 |
cat_cols=data.select_dtypes(include=['object']).columns
num_cols = data.select_dtypes(include=np.number).columns.tolist()
print("Categorical Variables:")
print(cat_cols)
print("Numerical Variables:")
print(num_cols)
Categorical Variables:
Index(['chas'], dtype='object')
Numerical Variables:
['crim', 'zn', 'indus', 'nox', 'rm', 'age', 'dis', 'rad', 'tax', 'ptratio', 'black', 'lstat', 'medv']
Análisis univariado
from scipy.stats import kurtosis
Asimetríaskew = 0: Distribución simétrica (valores aceptables skew\(\in(-1, 1)\)).skew > 0: Mayor peso en la cola izquierda de la distribución (sesgo positivo).skew < 0: Mayor peso en la cola derecha de la distribución (sesgo negativo).
Kurtosis: Determina si una distribución tiene colas gruesas con respecto a la distribución normal. Proporciona información sobre la forma de una distribución de frecuencias.kurtosis=3: se denomina mesocúrtica (distribución normal).
kurtosis<3: se denomina platicúrtica (distribución con colas menos gruesas que la normal).
kurtosis>3: se denomina leptocúrtica (distribución con colas más gruesas que la normal) y significa que trata de producir más valores atípicos que la distribución normal.
Variables numéricas
sns.set(font_scale=1.4)
for col in num_cols:
print('Column: ', col)
print('Skew:', round(data[col].skew(), 2))
print('Kurtosis: ', round(data[col].kurtosis(), 2))
plt.figure(figsize = (14, 6))
plt.subplot(1, 2, 1)
data[col].hist(grid=False)
plt.subplot(1, 2, 2)
sns.boxplot(x=data[col])
plt.show()
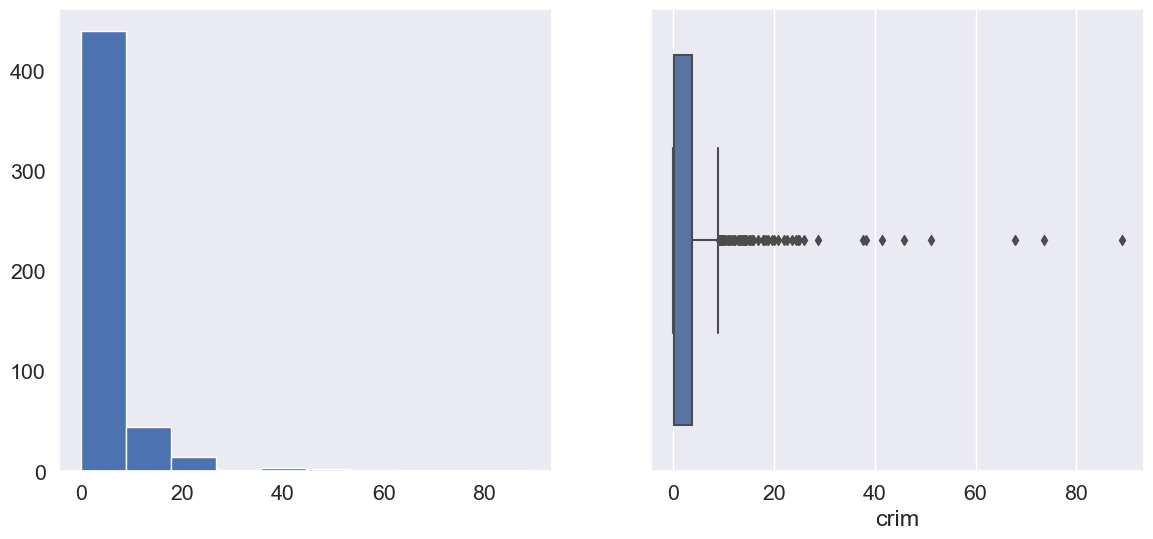
Column: crim
Skew: 5.22
Kurtosis: 37.13
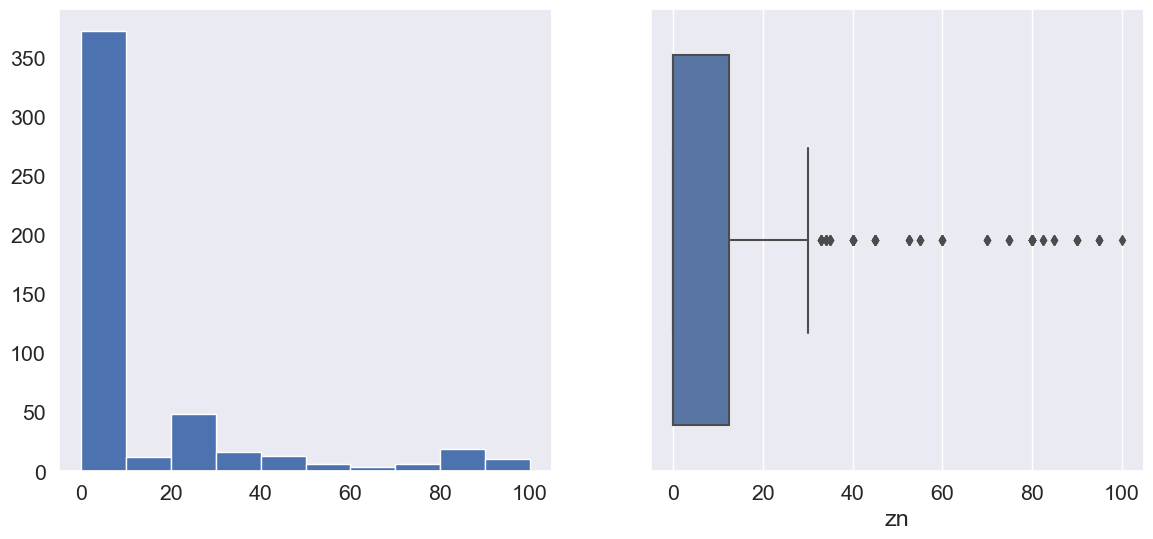
Column: zn
Skew: 2.23
Kurtosis: 4.03
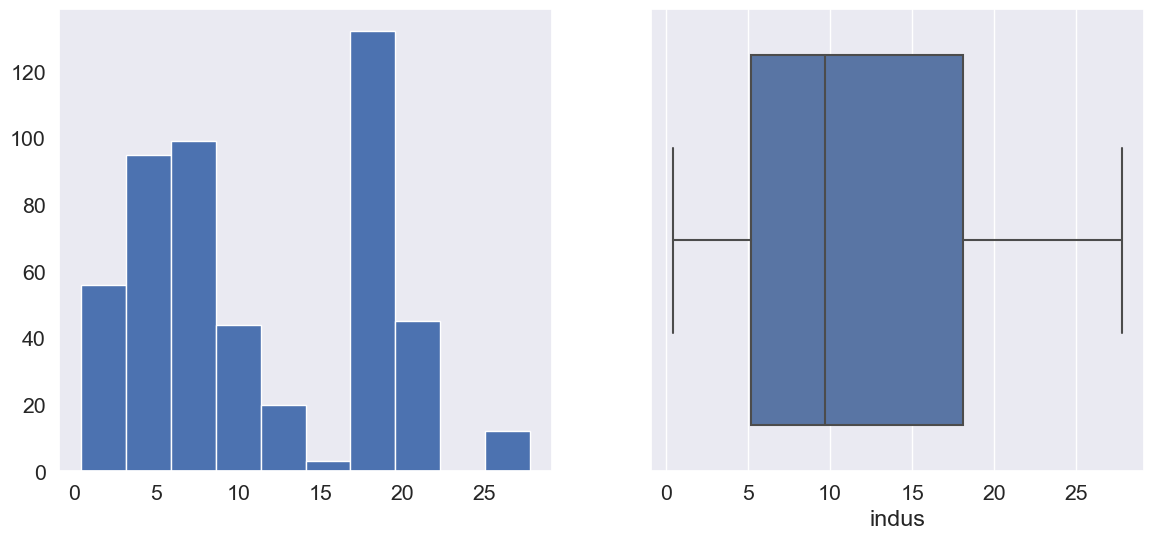
Column: indus
Skew: 0.3
Kurtosis: -1.23
Column: nox
Skew: 0.73
Kurtosis: -0.06
Column: rm
Skew: 0.4
Kurtosis: 1.89
Column: age
Skew: -0.6
Kurtosis: -0.97
Column: dis
Skew: 1.01
Kurtosis: 0.49
Column: rad
Skew: 1.0
Kurtosis: -0.87
Column: tax
Skew: 0.67
Kurtosis: -1.14
Column: ptratio
Skew: -0.8
Kurtosis: -0.29
Column: black
Skew: -2.89
Kurtosis: 7.23
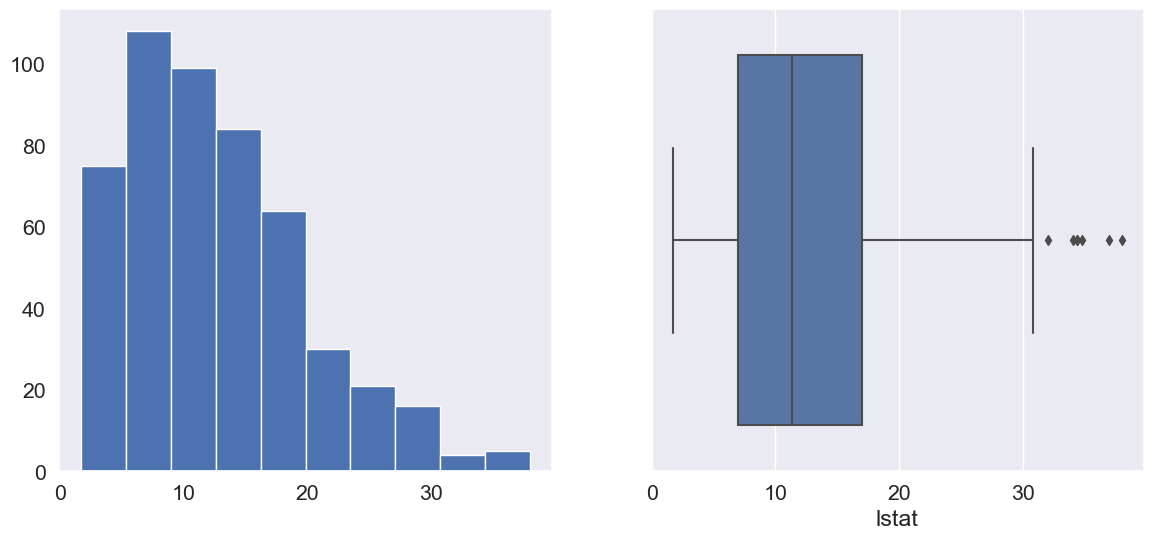
Column: lstat
Skew: 0.91
Kurtosis: 0.49
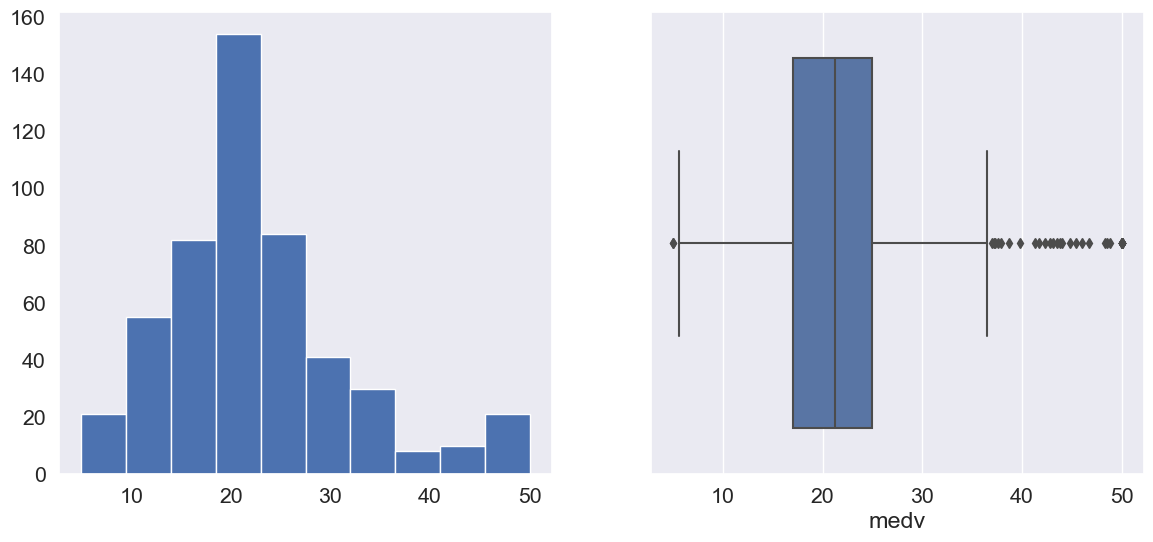
Column: medv
Skew: 1.11
Kurtosis: 1.5
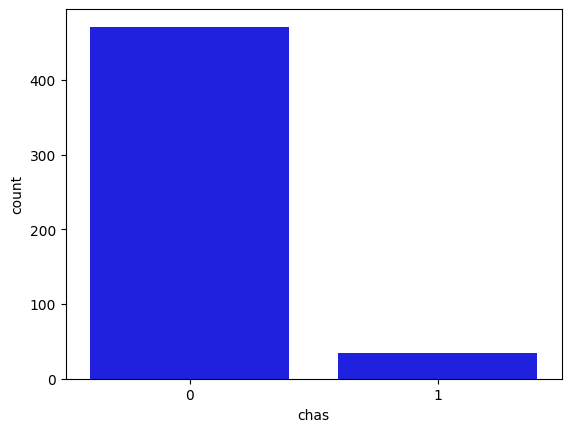
Variables categóricas: Usando diagramas de barras representamos la variable dummy del Río Charles (= 1 si el tramo limita con el río; 0 en caso contrario)
matplotlib.rc_file_defaults()
sns.countplot(x = 'chas', data = data, color = 'blue', order = data['chas'].value_counts().index);
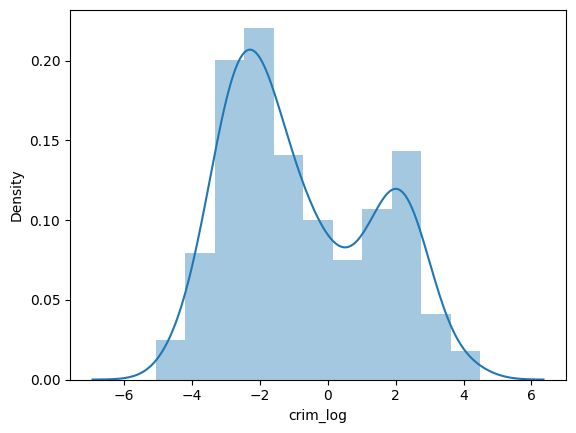
Transformación de datos:Las variables por ejemplocrimeyblack, por ejemplo, están muy sesgadas y en una escala mayor. Hagamos una transformación logarítmica. La transformación logarítmica puede ayudar en la normalización, por lo que esta variable puede mantener la escala estándar con otras variables
def log_transform(data,col):
for colname in col:
if (data[colname] == 1.0).all():
data[colname + '_log'] = np.log(data[colname]+1)
else:
data[colname + '_log'] = np.log(data[colname])
data.info()
log_transform(data,['crim','black'])
<class 'pandas.core.frame.DataFrame'>
Index: 506 entries, 1 to 506
Data columns (total 16 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 crim 506 non-null float64
1 zn 506 non-null float64
2 indus 506 non-null float64
3 chas 506 non-null object
4 nox 506 non-null float64
5 rm 506 non-null float64
6 age 506 non-null float64
7 dis 506 non-null float64
8 rad 506 non-null int64
9 tax 506 non-null int64
10 ptratio 506 non-null float64
11 black 506 non-null float64
12 lstat 506 non-null float64
13 medv 506 non-null float64
14 crim_log 506 non-null float64
15 black_log 506 non-null float64
dtypes: float64(13), int64(2), object(1)
memory usage: 67.2+ KB
sns.distplot(data["crim_log"], axlabel="crim_log");
sns.distplot(data["black_log"], axlabel="black_log");
Análisis bivariado: Pasemos ahora al análisis bivariado. El análisis bivariado ayuda a comprender cómo se relacionan las variables entre sí y la relación entre las variables dependientes e independientes presentes en el conjunto de datos. Puede utilizar el siguiente comando para visualizar todos los scatter plots, para las posibles relaciones:
sns.pairplot(data=data.drop(['chas', 'black_log', 'crim_log'],axis=1));
def scatter_regplot(data, strx, stry):
sns.set(font_scale=1.4)
fig, ax = plt.subplots(1, 2, figsize=(14, 6), sharey=True)
sns.scatterplot(data=data, x=strx, y=stry, ax=ax[0])
sns.regplot(data=data, x=strx, y=stry, ax=ax[1]);
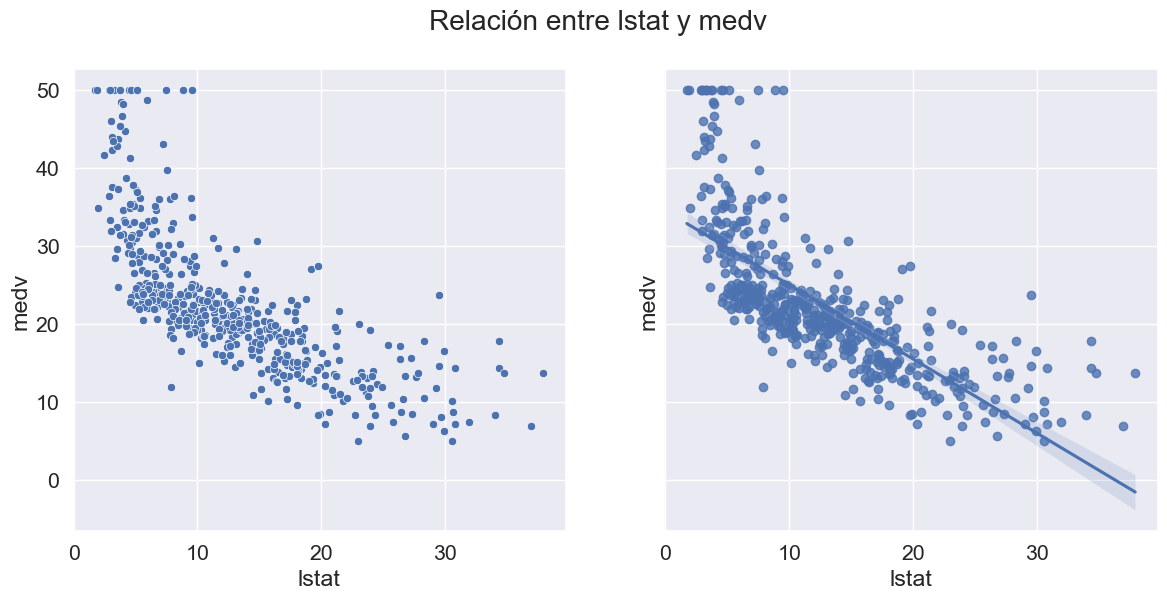
fig.suptitle('Relación entre %s y medv'%col)
num_cols.remove('medv')
for col in num_cols:
scatter_regplot(data, col, 'medv')
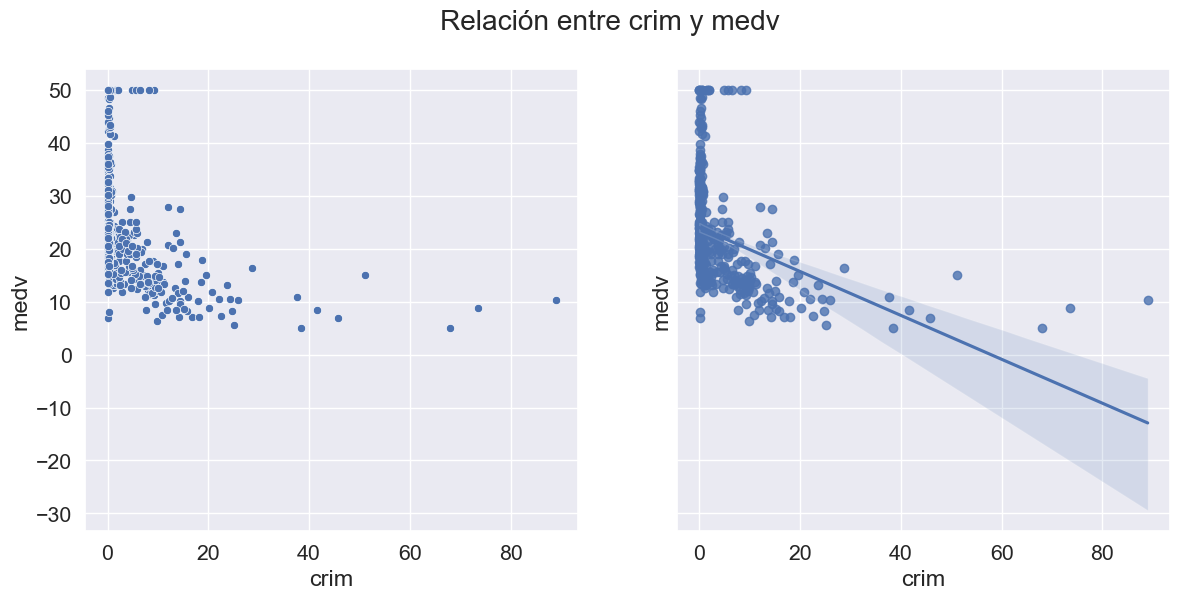
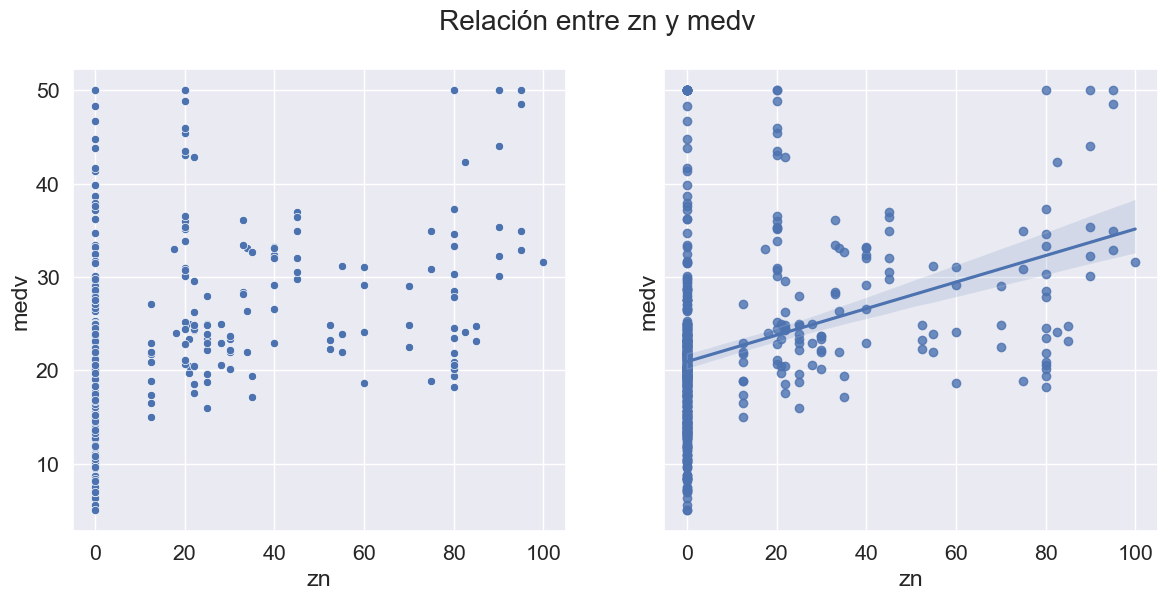
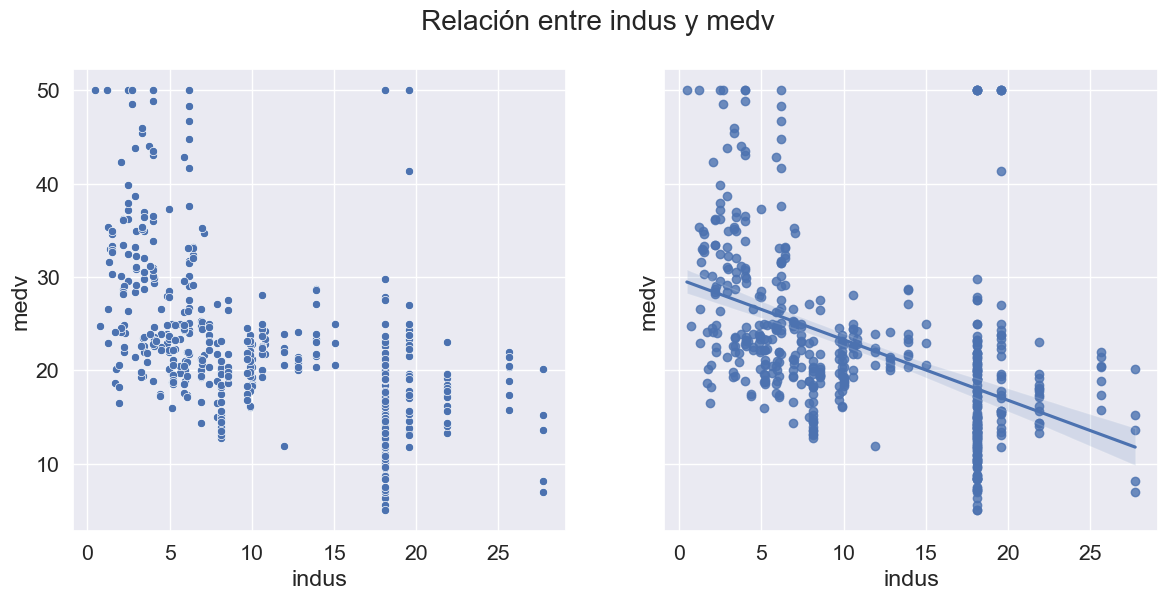
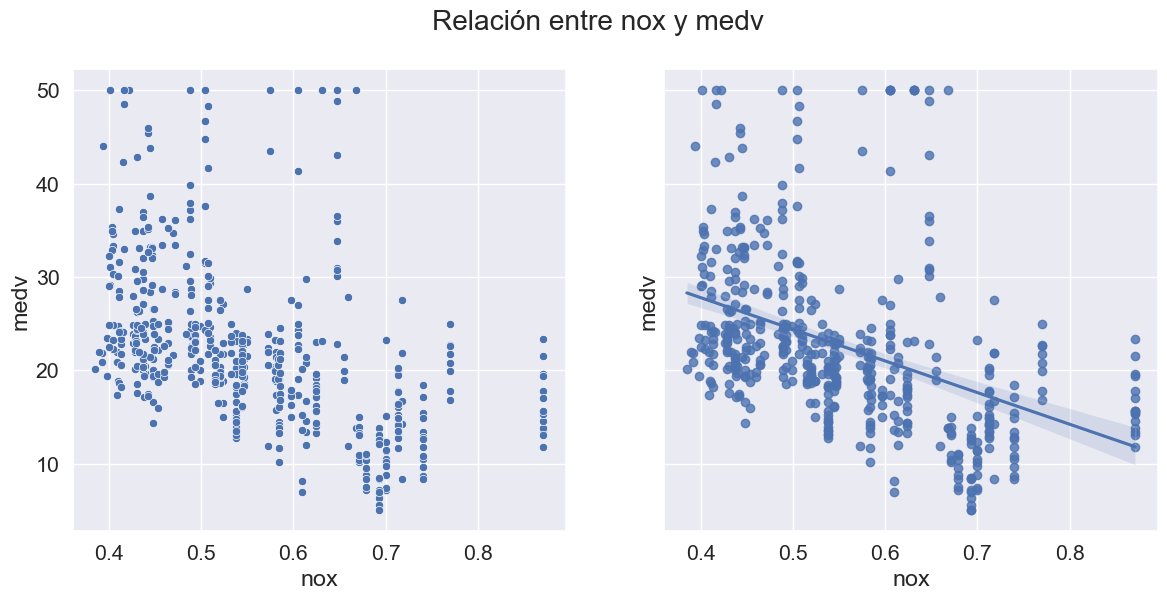
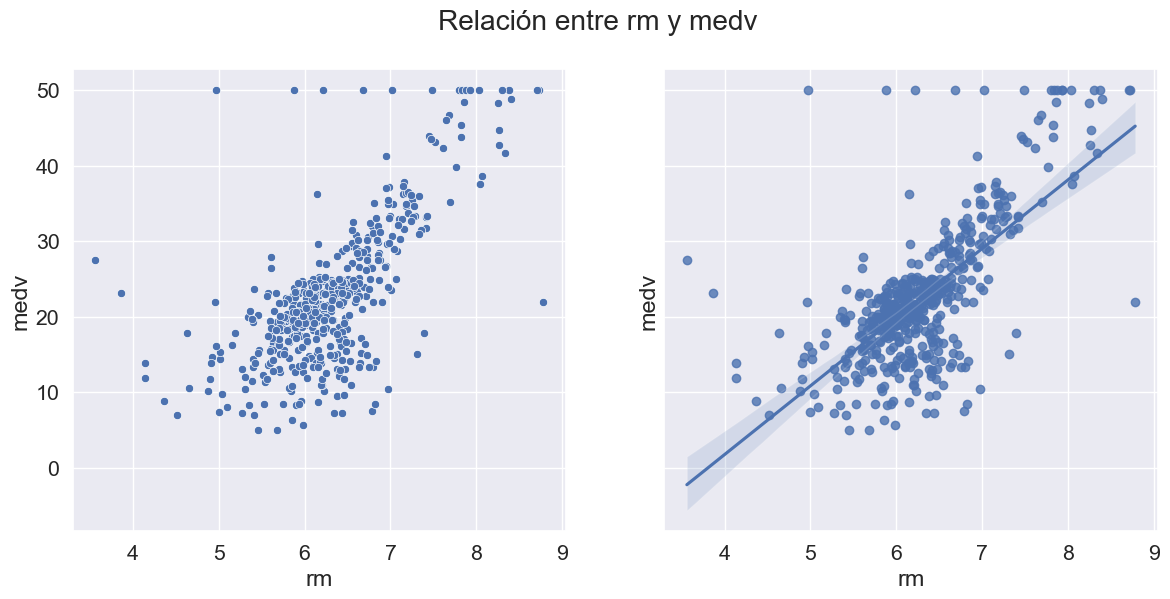
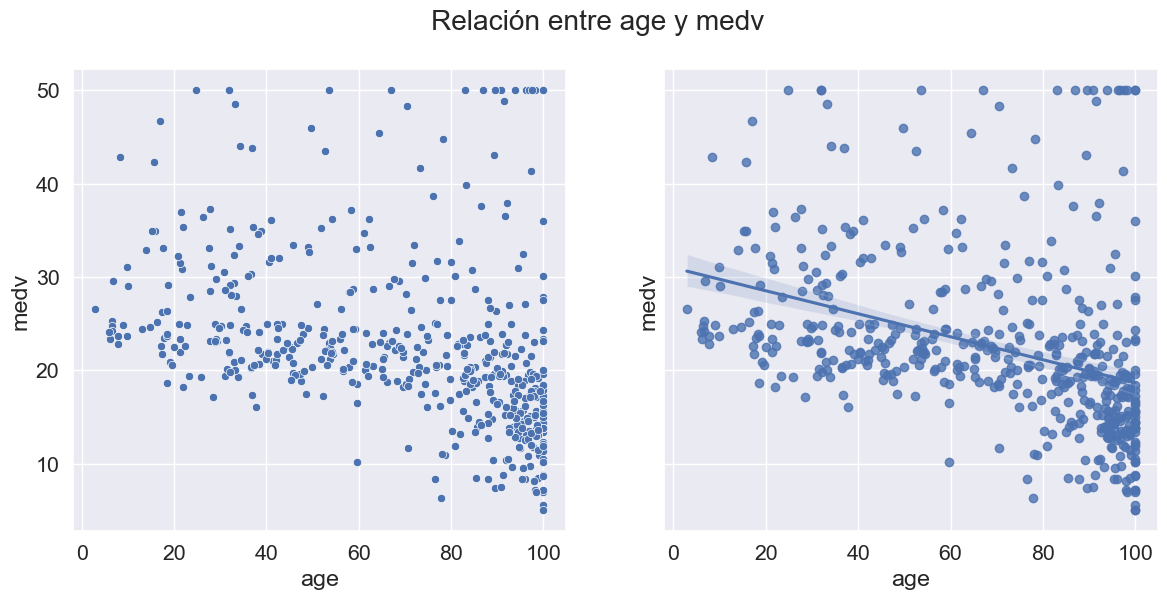
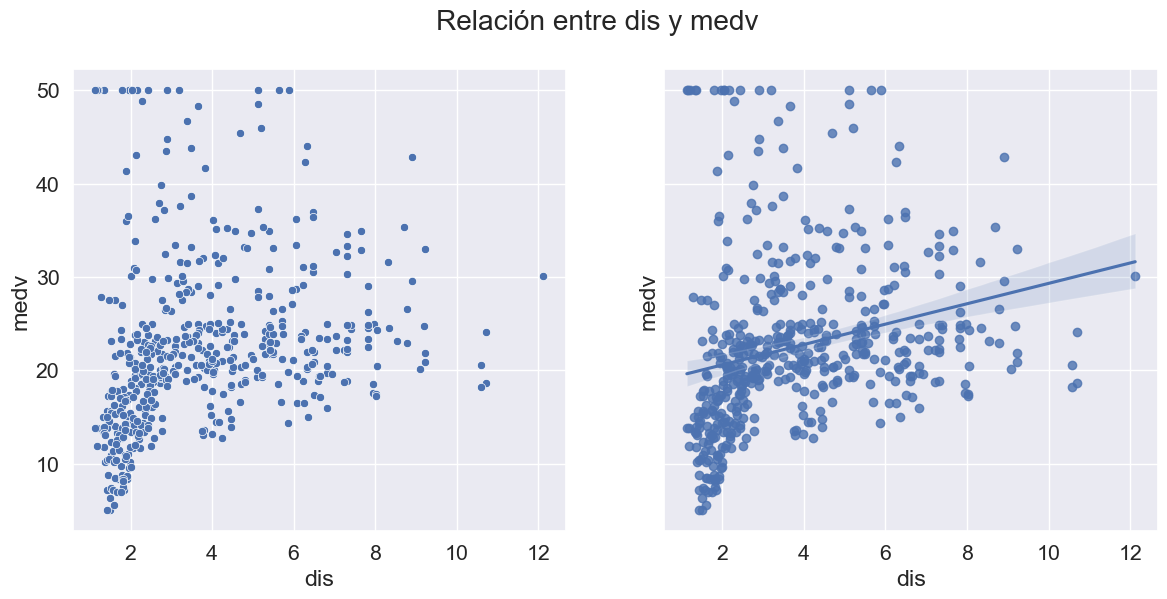
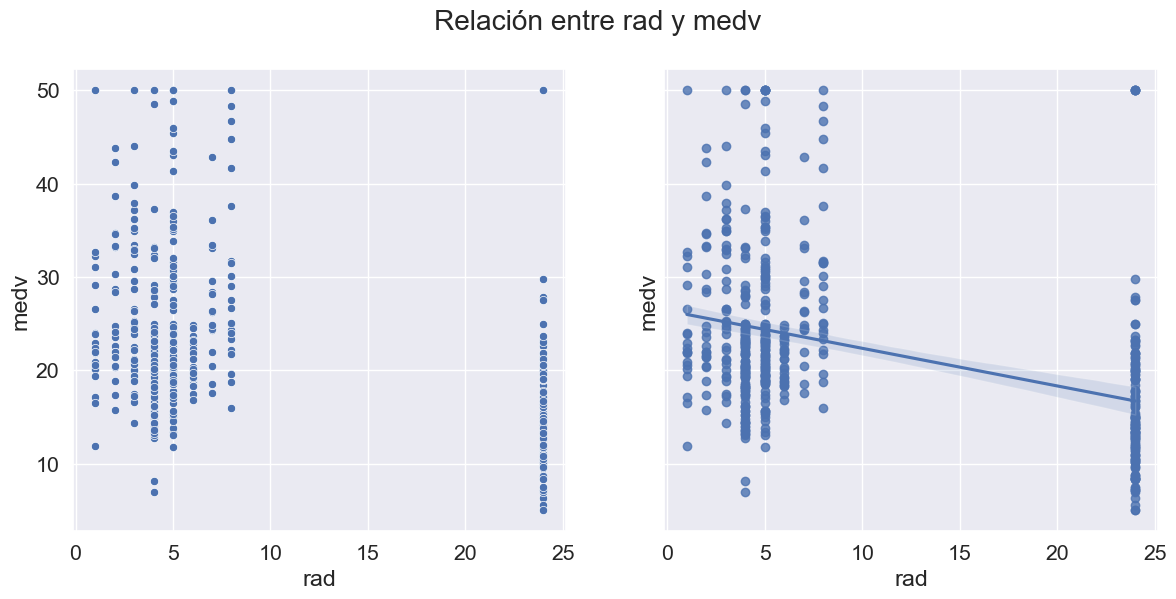
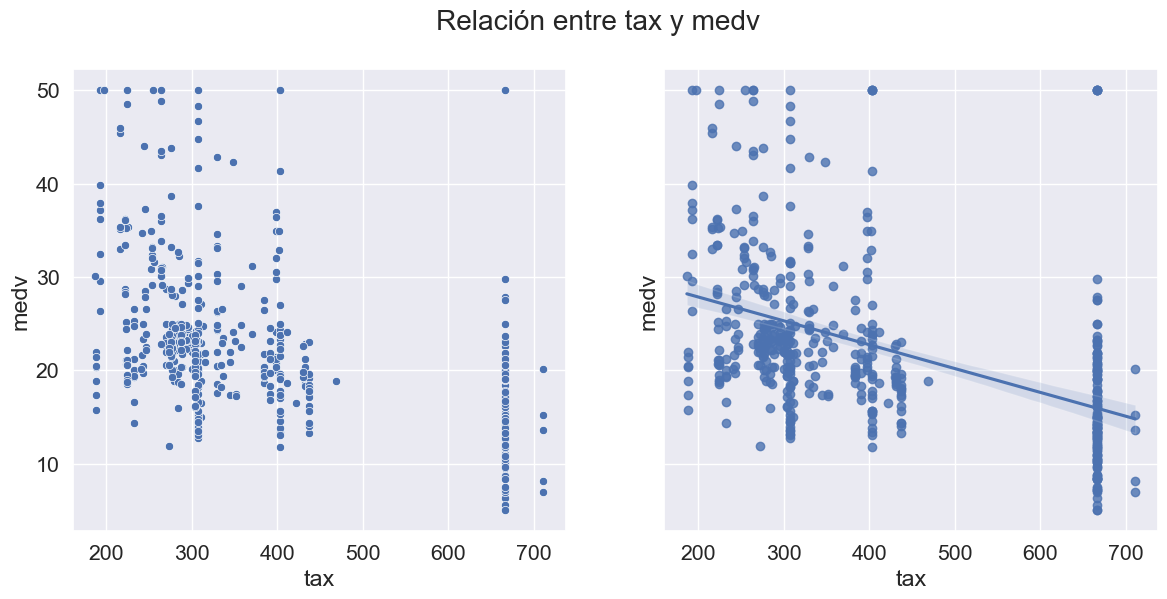
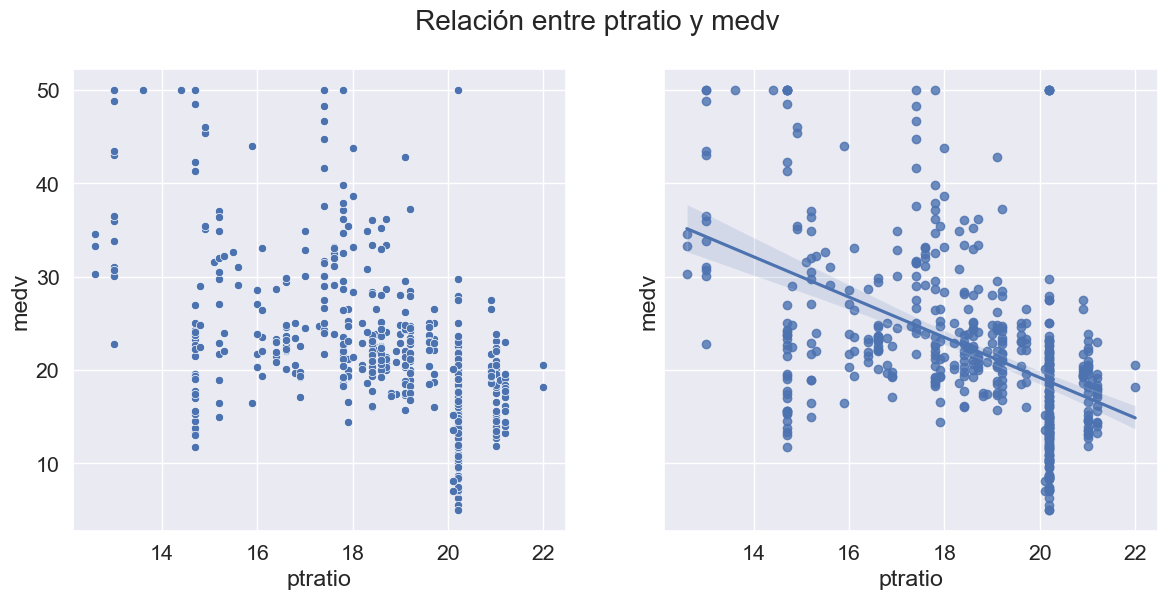
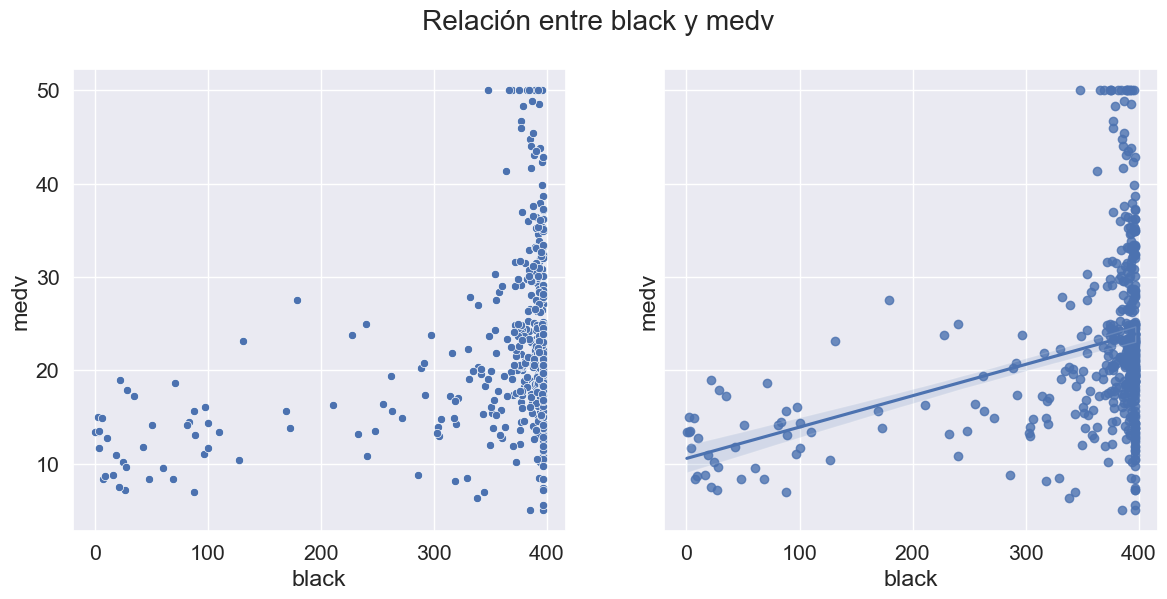
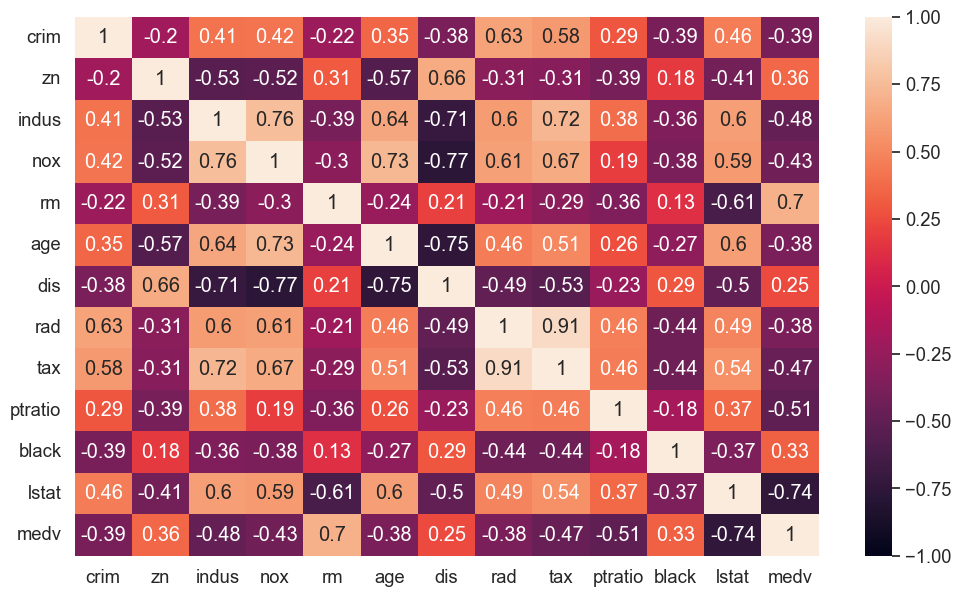
Un mapa de calor se utiliza ampliamente para este tipo de análisis. El mapa de calor muestra la correlación entre las variables, ya sea positiva o negativa.
matplotlib.rc_file_defaults()
sns.set(font_scale=1.2)
plt.figure(figsize=(12, 7))
sns.heatmap(data.drop(['chas', 'black_log', 'crim_log'],axis=1).corr(), annot = True, vmin = -1, vmax = 1);
A manera de ejemplo, utilizaremos el dataset mglearn.datasets.load_extended_boston() de las 104 características resultantes de las 13 características originales junto con las 91 combinaciones posibles de dos características dentro de esas 13.
X, y = mglearn.datasets.load_extended_boston()
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
lr = LinearRegression().fit(X_train, y_train)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
lr = LinearRegression().fit(X_train, y_train)
Al comparar los
scorede los conjuntos de entrenamiento y de prueba, comprobamos que predecimos con mucha precisión en el conjunto de entrenamiento, pero el \(R^2\) en el conjunto de prueba es mucho peor
print("Training set score: {:.2f}".format(lr.score(X_train, y_train)))
print("Test set score: {:.2f}".format(lr.score(X_test, y_test)))
Training set score: 0.95
Test set score: 0.61
Esta discrepancia entre el rendimiento en el conjunto de entrenamiento y el conjunto de prueba es un claro signo de overfitting, y por lo tanto, debemos tratar de encontrar un modelo que nos permita controlar la complejidad. Usualmente, en este tipo de casos utilizamos técnicas de regularización. Una de las alternativas más utilizadas a la regresión lineal estándar es la regresión ridge, que estudiaremos a continuación.
3.4. Regresión ridge#
3.4.1. Análisis#
Observación
En la regresión ridge, los coeficientes \(\boldsymbol{\hat{\beta}}\) se eligen no sólo para que predigan bien en los datos de entrenamiento, sino que también, para que se ajusten a una restricción adicional. La regresión Ridge regulariza la regresión lineal imponiendo una penalización al tamaño de los coeficientes.
La magnitud de los coeficientes se considera lo más pequeña posible; en otras palabras, todas las entradas de \(\boldsymbol{\hat{\beta}}\) deben ser cercanas a cero. Intuitivamente, esto significa que cada característica debe tener el menor efecto posible sobre el resultado (lo que se traduce en tener una pendiente pequeña), sin dejar de predecir bien. Esta restricción es un ejemplo de lo que se llama regularización.
La regularización consiste en restringir explícitamente un modelo para evitar el overfitting. El tipo particular utilizado por la regresión ridge se conoce como regularización \(L^2\).
Fig. 3.1 Ilustration del score de predicción en el conjunto de test para linear regression, ridge y lasso.#
3.4.2. Formulación#
Consideremos el modelo de regresión lineal
(3.3)#\[ y_{i}=\beta_{0}+\beta_{1}\cdot x_{i1}+\beta_{2}\cdot x_{i2}+\cdots+\beta_{p}\cdot x_{ip}+\varepsilon_{i},~i = 1,2,\dots, n, \]basado en los datos observados \(\{(y_{i}, x_{i1}, x_{i2},\dots, x_{ip}):~i=1,2,\dots,n\}\) para la variable respuesta \(y\) y \(p\) variables predictoras \(\boldsymbol{x}=(x_{1}, x_{2},\dots,x_{p})\). La regresión ridge propuesta por [Hoerl and Kennard, 1970] es un método para evitar la inestabilidad de las estimaciones en los modelos de regresión lineal, causada por la multicolinealidad, esto es, correlación alta entre más de dos variables predictoras.
Problema de multicolinealidad
Cuando las variables predictoras están correlacionadas, esto indica que los cambios en una variable están asociados a cambios en otra. Cuanto más fuerte sea la correlación, más difícil será cambiar una variable sin cambiar otra.
Resulta difícil para el modelo estimar la relación entre cada variable predictora y la variable respuesta de forma independiente porque las variables predictoras tienden a cambiar al unísono.
Este método es una regularización, en la que la suma de cuadrados de los coeficientes de regresión, excluyendo el intercepto, es el término de penalización, y las estimaciones de coeficientes de regresión se obtienen de la siguiente manera.
En primer lugar, obtenemos la media \(\bar x_{j}=n^{-1}\sum_{i=1}^{n}x_{ij}\) y la varianza \(s_{j}^2=n^{-1}\sum_{i=1}^{n}(x_{ij}-\bar x_{j})^{2}\), \(j=1,2,\dots,p\) de los datos para las variables predictoras y estandaricemos los datos de la siguiente manera
¿Por qué estandarizar?
La regresión Ridge penaliza los coeficientes, contrayéndolos hacia cero. Si las variables tienen escalas distintas, la penalización es desigual. Para evitarlo, se suelen escalar para tener varianza unitaria.
Si las variables independientes tienen escalas muy diferentes, Ridge penaliza más las de mayor magnitud. Por ejemplo, ingresos (30-100) y edad (20-70): al tener valores más grandes, ingresos dominará la penalización, afectando injustamente los coeficientes.
El modelo de regresión lineal basado en los datos estandarizados puede expresarse entonces como
(3.5)#\[\begin{split} \begin{align*} y_{i} &= \beta_{0} + \beta_{1}\bar x_{1} + \beta_{2}\bar x_{2} + \cdots + \beta_{p}\bar x_{p} + \beta_{1}^{\star}z_{i1} + \beta_{2}^{\star}z_{i2} + \cdots + \beta_{p}^{\star}z_{ip} + \varepsilon_{i}\\ &=\beta_{0}^{\star} + \beta_{1}^{\star}z_{i1} + \beta_{2}^{\star}z_{i2} + \cdots + \beta_{p}^{\star}z_{ip} + \varepsilon_{i},~ i = 1,2,\dots,n, \end{align*} \end{split}\]donde \(\beta_{0}^{\star}=\beta_{0}+\beta_{1}\bar x_{1}+\beta_{2}\bar x_{2}+\cdots+\beta_{p}\bar x_{p}~\text{y}~\beta_{j}^{\star}=s_{j}\beta_{j}\). Por lo tanto, podemos expresar el modelo de regresión lineal basados en los datos estandarizados para la variable predictora como
(3.6)#\[ \boldsymbol{y}=\beta_{0}^{\star}\boldsymbol{1}+Z\boldsymbol{\beta}_{s}+\boldsymbol{\varepsilon}, \]en forma matricial
\[\begin{split} \begin{pmatrix} y_{1}\\ y_{2}\\ \vdots\\ y_{i}\\ \vdots\\ y_{n} \end{pmatrix} = \beta_{0}^{\star} \begin{pmatrix} 1\\ 1\\ \vdots\\ 1\\ \vdots\\ 1 \end{pmatrix} + \begin{pmatrix} z_{11} & z_{12} & \cdots & z_{1p}\\ z_{21} & z_{22} & \cdots & z_{2p}\\ \vdots & \vdots & & \vdots\\ z_{31} & z_{32} & \cdots & z_{3p}\\ \vdots & \vdots & & \vdots\\ z_{n1} & z_{n2} & \cdots & z_{np} \end{pmatrix} \begin{pmatrix} \beta_{0}\\[2mm] \beta_{1}\\[2mm] \beta_{2}\\ \vdots\\[2mm] \beta_{p} \end{pmatrix} + \begin{pmatrix} \varepsilon_{1}\\ \varepsilon_{2}\\ \vdots\\ \varepsilon_{i}\\ \vdots\\ \varepsilon_{n} \end{pmatrix} \end{split}\]donde \(\boldsymbol{1}\) es un vector \(n\)-dimensional de unos, \(\boldsymbol{\beta}_{s}=(s_{1}\beta_{1}, s_{2}\beta_{2},\dots,s_{p}\beta_{p})^{T}\), y \(Z\) es una matriz de \(n\times p\) que contiene los datos estandarizados \(z_{ij}=(x_{ij}-\bar x_{j})/s_{j},~ i=1,2,\dots,n; j=1,2,\dots,p\) en su posición \((i,j)\).
El estimador ridge para el vector de coeficientes esta dado entonces por minimización de:
(3.7)#\[ S_{\lambda}(\beta_{0}^{\star}, \boldsymbol{\beta}_{s})=(\boldsymbol{y}-\beta_{0}^{\star}\boldsymbol{1}-Z\boldsymbol{\beta}_{s})^{T}(\boldsymbol{y}-\beta_{0}^{\star}\boldsymbol{1}-Z\boldsymbol{\beta}_{s})+\lambda\boldsymbol{\beta}_{s}^{T}\boldsymbol{\beta}_{s} \]donde el término de regularización \(L^2\): (\(\lambda\boldsymbol{\beta}_{s}^{T}\boldsymbol{\beta}_{s}\)) con parámetro de regularización \(\lambda\) ha sido agregado al vector de coeficientes de regresión, excepto el intercepto. Este término es conocido como
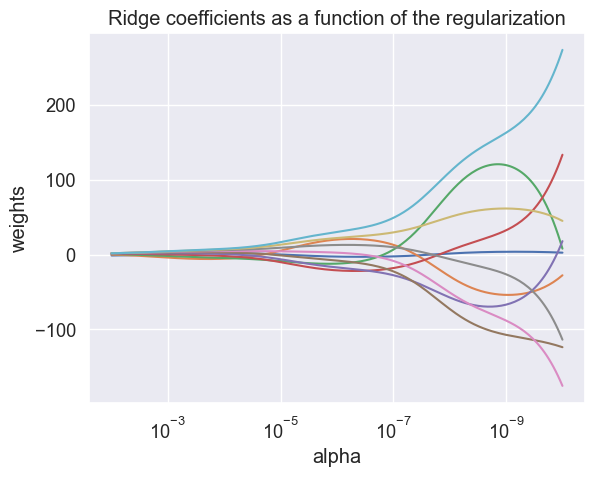
weight decay. Veamos una simulación de la regularización ridge usando a la matriz de Hilbert como input y un vector unitario, como output.
import matplotlib.pyplot as plt
import numpy as np
from sklearn import linear_model
X = 1.0 / (np.arange(1, 11) + np.arange(0, 10)[:, np.newaxis])
y = np.ones(10)
n_alphas = 200
alphas = np.logspace(-10, -2, n_alphas)
coefs = []
for a in alphas:
ridge = linear_model.Ridge(alpha=a, fit_intercept=False)
ridge.fit(X, y)
coefs.append(ridge.coef_)
ax = plt.gca()
ax.plot(alphas, coefs)
ax.set_xscale("log")
ax.set_xlim(ax.get_xlim()[::-1])
plt.xlabel("alpha")
plt.ylabel("weights")
plt.title("Ridge coefficients as a function of the regularization")
plt.axis("tight");
La Eq. (3.7) puede reescribirse de la siguiente forma al desarrollar los productos asociados y aplicar propiedades de la transpuesta
Diferenciando con respecto a \(\beta_{0}^{\star}\) y \(\boldsymbol{\beta}_{s}\) para resolver el problema de minimización, obtenemos las siguientes ecuaciones:
Nótese que \(Z^{T}\boldsymbol{1}=\boldsymbol{1}^{T}Z=0\) (verifíquelo). Para el caso de la derivada parcial con respecto a \(\boldsymbol{\beta}_{s}\) se requiere antes, estudiar la derivada de una forma cuadrática de la forma \(\boldsymbol{x}^{T}A\boldsymbol{x}\). Nótese que
Derivando con respecto a \(x_{k}\) para obtener la \(k\)-ésima componente del gradiente \(\nabla_{\boldsymbol{x}}(\boldsymbol{x}^{T}A\boldsymbol{x})\)
Por lo tanto, para \(k=1,2,\dots,p\), bajo el supuesto de simetría para \(A\) se tiene que
Nótese que \(A:=Z^{T}Z\), es simétrica, en efecto: \(A^{T}=(Z^{T}Z)^{T}=Z^{T}(Z^{T})^{T}=Z^{T}Z=A\), entonces \(\partial_{\boldsymbol{\beta}_{s}}(\boldsymbol{\beta}_{s}^{T}Z^{T}Z\boldsymbol{\beta}_{s})=2Z^{T}Z\boldsymbol{\beta}_{s}\), por lo tanto
Resolviendo las ecuaciones (3.8) y (3.10) para \(\beta_{0}^{\star}\) y \(\boldsymbol{\beta}_{s}\), se tienen estimadores ridge para el modelo de regresión (3.5)
Si \(\lambda > 0\), reduce coeficientes y evita sobreajuste. Si \(\lambda = 0\), es regresión lineal. Si \(\lambda < 0\), amplifica coeficientes y fomenta sobreajuste.
Dado que \(\beta_{0}^{\star}=\beta_{0}+\beta_{1}\bar x_{1}+\beta_{2}\bar x_{2}+\cdots+\beta_{p}\bar x_{p}\) usando la estimación obtenida \(\hat{\beta}_{0}^{\star}\) se tiene que
Además, la estimación ridge del vector de coeficientes de regresión, está dada separadamente por la minimización de la función
En efecto, para obtener estimación ridge del vector de coeficientes \(\boldsymbol{\beta}_{s}=(\hat{\beta}_{1}, \hat{\beta}_{2},\dots, \hat{\beta}_{p})\), primero, nótese que al reemplazar \(\hat{\beta}_{0}^{\star}=\overline{y}\) en Eq. (3.6) se tiene que \(y=\overline{y}\boldsymbol{1}+Z\boldsymbol{\beta}_{s}+\varepsilon\), entonces \(\boldsymbol{y}-\overline{y}\boldsymbol{1}\) esta centrando los datos en relación a la variable respuesta.
Estandarizando las variables predictoras y respuesta en nuestro modelo inicial Ecuación (3.3), mediante \(y_{i}-\overline{y}\) y \((x_{ij}-\bar x_{j})/s_{j}\) se tienen las siguientes igualdades, verifiquelas
Entonces,
En virtud de la implicación de estas igualdades con respecto al parámetro \(\beta_{0}^{\star}\) y la Ecuación (3.5), podemos considerar sin perdida de generalidad, el modelo de regresión
donde \(X\in\mathbb{R}^{n\times p},~\boldsymbol{\beta}\in\mathbb{R}^{p},~E(\boldsymbol{\varepsilon})=0\) y \(\textrm{cov}(\boldsymbol{\varepsilon})=\sigma^2\boldsymbol{I}\).
Por lo tanto minimizando el operador \(S_{\lambda}(\boldsymbol{\beta})=(y-X\boldsymbol{\beta})^{T}(y-X\boldsymbol{\beta})+\lambda\boldsymbol{\beta}^{T}\boldsymbol{\beta}\), de forma análoga al procedimiento de optimización para Eq. (3.7), obtenemos el estimador de ridge:
Propiedades del estimador ridge
El estimador ridge satisface las siguientes propiedades:
donde \(l_{1}, l_{2},\dots, l_{p}\) son los autovalores ordenados de \(X^{T}X\). El primer término del lado derecho de la última ecuación en (3.12) representa la suma de las varianzas de los componentes del estimador ridge, y el segundo término es el cuadrado del sesgo.
Ejercicio para el lector
Queda como ejercicio para el lector verificar las Propiedades (3.12) del estimador ridge. Sugerencia: Revisar el texto de Sadanori Konishi, Introduction to Multivariate Analysis: Linear and Nonlinear Modeling [Konishi, 2014].
3.4.3. Implementación#
La regresión ridge se implementa en
linear_model.Ridge. Veamos qué tal lo hace en el conjunto de datos ampliado deBoston Housing.
from sklearn.linear_model import Ridge
ridge = Ridge().fit(X_train, y_train)
print("Training set score: {:.2f}".format(ridge.score(X_train, y_train)))
print("Test set score: {:.2f}".format(ridge.score(X_test, y_test)))
Training set score: 0.89
Test set score: 0.75
Como puede ver, el score en el conjunto de entrenamiento de Ridge es menor que el de la regresión lineal, cuyos scores fueron: Training set score: 0.95 and Test set score: 0.61. Además, la puntuación en el conjunto de prueba es mayor. En este caso,
Ridge, usaalpha=1.0como parámetro por default (ver sklearn.linear_model.Ridge). Esto es coherente con nuestras expectativas.Con la regresión, nos ajustamos demasiado a los datos. Ridge es un modelo más restringido, por lo que existe menos probabilidad de overfitting. Un modelo menos complejo significa un peor rendimiento en el conjunto de de entrenamiento, pero una mejor generalización. Como sólo nos interesa el rendimiento de la generalización, deberíamos elegir el modelo Ridge en lugar del modelo de regresión lineal.
El modelo
Ridgehace un balance entre la simplicidad del modelo (coeficientes casi nulos) y su rendimiento en el conjunto de entrenamiento. La importancia que el modelo da a la simplicidad frente al rendimiento del conjunto de entrenamiento, puede ser especificada por el usuario, utilizando el parámetroalpha.En el ejemplo anterior, hemos utilizado el parámetro por defecto
alpha=1.0. Sin embargo, no hay ninguna razón por la que este nos dió la mejor compensación. El ajuste óptimo dealphadepende del conjunto de datos concreto que estemos utilizando.
Observación
Aumentar
alphaobliga a los coeficientes a acercarse más a cero, lo que disminuye el rendimiento del conjunto de entrenamiento, pero puede ayudar a mejorar la generalización.
ridge10 = Ridge(alpha=10).fit(X_train, y_train)
print("Training set score: {:.2f}".format(ridge10.score(X_train, y_train)))
print("Test set score: {:.2f}".format(ridge10.score(X_test, y_test)))
Training set score: 0.79
Test set score: 0.64
La disminución de
alphapermite que los coeficientes estén menos restringidos. Para valores muy pequeños de alpha, los coeficientes apenas están restringidos, y terminamos con un modelo que se parece a LinearRegression
ridge01 = Ridge(alpha=0.1).fit(X_train, y_train)
print("Training set score: {:.2f}".format(ridge01.score(X_train, y_train)))
print("Test set score: {:.2f}".format(ridge01.score(X_test, y_test)))
Training set score: 0.93
Test set score: 0.77
Observe cómo el parámetro
alphase corresponde con la complejidad del modelo. Discutiremos los métodos para seleccionar adecuadamente los parámetros en el capítulo de evaluación de modelos. También podemos obtener una visión más cualitativa de cómo el parámetroalphacambia el modelo, inspeccionando el atributocoef_de los modelos con diferentes valores dealpha.Un
alphamás alto significa un modelo más restringido, por lo que esperamos que las entradas decoef_tengan una magnitud menor.
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(font_scale=1.2)
plt.figure(figsize=(8, 8))
plt.plot(ridge.coef_, 's', label="Ridge alpha=1")
plt.plot(ridge10.coef_, '^', label="Ridge alpha=10")
plt.plot(ridge01.coef_, 'v', label="Ridge alpha=0.1")
plt.plot(lr.coef_, 'o', label="LinearRegression")
plt.xlabel("Coefficient index")
plt.ylabel("Coefficient magnitude")
plt.hlines(0, 0, len(lr.coef_))
plt.ylim(-25, 25)
plt.legend();
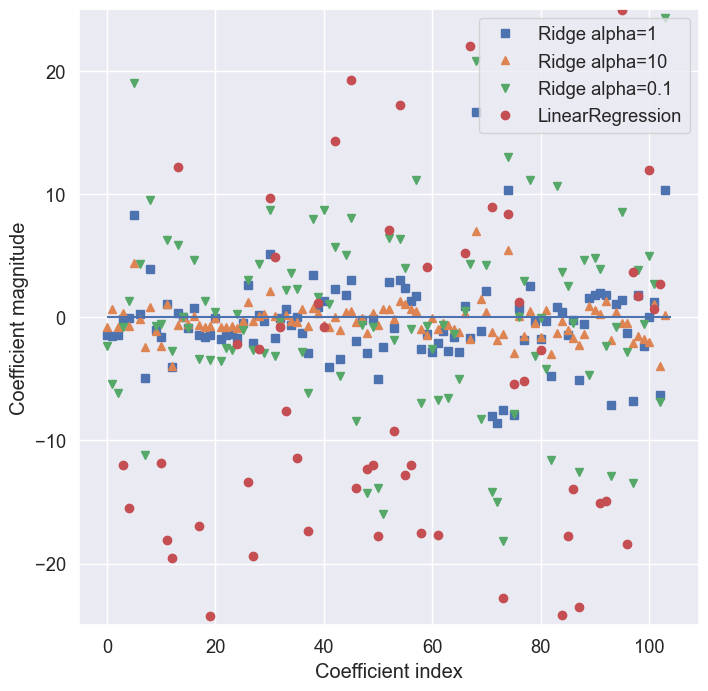
Aquí, el eje \(x\) enumera las entradas de
coef_. \(x=0\) muestra el coeficiente asociado a la primera característica, \(x=1\) el coeficiente asociado a la segunda característica, y así sucesivamente hasta \(x=100\). El eje \(y\) muestra los valores numéricos de los valores correspondientes de los coeficientes. La principal conclusión es que paraalpha=10, los coeficientes se sitúan en su mayoría entre -3 y 3.Los coeficientes del modelo
Ridgeconalpha=1son algo mayores. Los puntos correspondientes aalpha=0,1tienen una magnitud aún mayor, y muchos de los puntos correspondientes a la regresión lineal sin ninguna regularización (que seríaalpha=0), son tan grandes que quedan fuera del gráfico.Otra forma de entender la influencia de la regularización es fijar un valor de
alphapero variando la cantidad de datos de entrenamiento disponibles. Si submuestreamos el conjunto de datos deBoston Housingy evaluamosLinearRegressionyRidge(alpha=1)en subconjuntos de tamaño creciente, obtenemos la siguiente curva de aprendizaje
mglearn.plots.plot_ridge_n_samples()

Como era de esperarse, la puntuación de entrenamiento es mayor que la de prueba para todos los tamaños de conjuntos de datos, tanto para la regresión lineal como para la ridge. Debido a que la regresión ridge está regularizada, la puntuación de entrenamiento es inferior a la de la regresión lineal en todos los casos.
La puntuación de la prueba de la regresión ridge es mejor, en particular, para los subconjuntos pequeños de datos. Para menos de 400 puntos de datos, la regresión lineal no es capaz de aprender nada. A medida que el modelo dispone de más datos, ambos modelos mejoran, y la regresión lineal alcanza a la ridge.
3.5. Regresión Lasso#
Observación
Una alternativa a la regresión ridge para regularizar la regresión lineal es la regresión lasso. Al igual que con la regresión ridge, el uso de lasso también restringe los coeficientes para que sean cercanos a cero, pero de una forma ligeramente diferente, llamada regularización \(L^1\).
La consecuencia de la regularización \(L^1\) es que cuando se utiliza lasso, algunos coeficientes son exactamente cero. Esto significa que, algunas características son totalmente ignoradas por el modelo. Esto puede verse como una forma de
selección automática de características.El hecho de que algunos coeficientes sean exactamente cero a menudo hace que un modelo sea más fácil de interpretar, y puede revelar las características más importantes de un modelo.
Formulación
El método Lasso es un método de estimación de parámetros, mediante la minimización de la siguiente función objetivo, que impone la suma de valores absolutos (normas \(L^{1}\)) de los coeficientes de regresión como una restricción (penalización) a la suma de errores al cuadrado:
donde los datos observados están normalizados como en la Ecuación (3.11). A diferencia de la contracción de los coeficientes de regresión hacia cero, que se produce en la regresión de ridge, lasso da lugar a una estimación exactamente igual a cero para algunos de los coeficientes.
Observación
Una ventaja de la regresión ridge es que si \(p < n\) (número de variables predictoras menor que el número de observaciones), entonces con una selección adecuada del parámetro de regularización \(\lambda\), es posible obtener estimaciones estables de los coeficientes de regresión, incluso en casos que impliquen multicolinealidad entre las variables predictoras o en los que \(X^{T}X\) es aproximadamente singular para la matriz de diseño \(X\).
Sin embargo, debido a que, a diferencia de lasso, la regresión ridge no puede producir estimaciones exactamente iguales a cero, entonces, la regresión ridge no puede utilizarse como método de selección de variables.

Fig. 3.2 Estimación ridge (izquierda) y estimación lasso (derecha).#
La diferencia entre la estimación lasso y la estimación ridge puede demostrarse, para simplificar, para el caso de sólo dos variables predictoras \(x_{1}\) y \(x_{2}\). En la estimación ridge, la solución se basa en la restricción \(\beta_{1}^{2}+\beta_{2}^{2}\leq c_{1}\) de minimizar
para datos centrados, mientras que la estimación lasso se basa en la restricción \(|\beta_{1}|+|\beta_{2}|\leq c_{2}\).
Dado que la estimación por mínimos cuadrados es la solución que minimiza \(S(\beta_{1}, \beta_{2})\), esta se produce en el centro de una elipse. Sin embargo, como se muestra en la Fig. 3.2, las soluciones que satisfacen las restricciones en las estimaciones ridge se encuentran en regiones diferentes de las que satisfacen las restricciones en las estimaciones lasso.
La diferencia esencial entre la estimación ridge y la estimación lasso como se muestra en la Fig. 3.2, es que la estimación ridge reduce todas las estimaciones del coeficiente de regresión hacia, pero no exactamente cero, en relación con las correspondientes a los mínimos cuadrados, mientras que la estimación lasso localiza algunas de las estimaciones del coeficiente de regresión exactamente iguales a cero.
Debido a su característica de reducir algunos coeficientes a exactamente cero, lasso también puede utilizarse para la selección de variables en modelos a gran escala con muchas variables predictoras, para las que el parámetro de regularización \(\lambda\) afecta al grado de de esparcimiento de la solución.
Ejercicio para el lector
Queda como ejercicio para el lector, encontrar parámetros de estimación lasso, tal como se realizó en el caso de la regresión ridge. Se sugiere investigar sobre el algoritmo LARS (Least Angle Regression) de Efron et al. (2004).
3.6. Ejercicios#
Sea \(Y\) un vector aleatorio de dimensión \(n\). Consideremos la transformación lineal \(Z = c + A Y\), donde \(c\) es un vector constante de dimensión \(m\) y \(A\) es una matriz constante de dimensiones \(m \times n\). Demuestre que la esperanza y la matriz de varianza-covarianza del vector aleatorio \(Z\) de dimensión \(m\) están dadas, respectivamente, por
Se dice que una matriz cuadrada \(P\) es idempotente si \(P^2 = P\). Demuestre que una matriz simétrica \(P\) de dimensión \(n \times n\) es idempotente de rango \(r\) si y solo si todos sus valores propios son 0 o 1, y que el número de valores propios iguales a 1 es igual a \(\operatorname{tr} P = r\).
Sea \(P = X (X^T X)^{-1} X^T\), donde \(X\) es una matriz de diseño de dimensiones \(n \times (p+1)\), definida en la Ecuación (3.1). Demuestre que:
\(P^2 = P\),
\((I_n - P)^2 = I_n - P\),
\(\operatorname{tr} P = p + 1\),
\(\operatorname{tr} (I_n - P) = n - p - 1\).
Demuestre que el Criterio de Información de Akaike (AIC) para el modelo de regresión lineal Gaussiano (3.1) está dado por la siguiente ecuación:
\[ AIC = n \log(2\pi \hat{\sigma}^2) + n + 2(p + 2), \]donde
\[ \hat{\sigma}^2 = \frac{(y - X \hat{\beta})^T (y - X \hat{\beta})}{n} = \frac{(y - \hat{y})^T (y - \hat{y})}{n}. \]Demuestre que resolver la ecuación
\[ S_{\lambda}(\boldsymbol{\beta})=(y-X\boldsymbol{\beta})^{T}(y-X\boldsymbol{\beta})+\lambda\sum_{i=1}^{p}|\beta_{j}|^{q}, \]es equivalente a minimizar la siguiente función con la restricción de norma \(L_q\)
\[ (y - X\beta)^T (y - X\beta) \quad \text{sujeto a} \quad \sum_{j=1}^{m} |\beta_j|^q \leq \eta. \]Encuentre la relación entre el parámetro de regularización \(\lambda\) y \(\eta\).
3.7. Aplicación: Regresión Lasso#
Apliquemos
lassoal conjunto de datos ampliado deBoston Housing
import numpy as np
from sklearn.linear_model import Lasso
lasso = Lasso().fit(X_train, y_train)
print("Training set score: {:.2f}".format(lasso.score(X_train, y_train)))
print("Test set score: {:.2f}".format(lasso.score(X_test, y_test)))
print("Number of features used: {}".format(np.sum(lasso.coef_ != 0)))
Training set score: 0.29
Test set score: 0.21
Number of features used: 4
Como se puede ver,
Lassolo hace bastante mal, tanto en el conjunto de entrenamiento como en el de prueba. Esto indica underfitting, pero, nótese que sólo utilizó 4 de las 105 características (feature selection). De forma similar aRidge,Lassotambién tiene un parámetro de regularización,alpha, que controla la fuerza con la que los coeficientes son empujados hacia cero.En el ejemplo anterior, utilizamos el valor por defecto de
alpha=1.0. Para reducir underfitting, intentemos disminuiralpha. Cuando hacemos esto, también necesitamos aumentar el ajuste por defecto demax_iter(número máximo de iteraciones a ejecutar)
lasso001 = Lasso(alpha=0.01, max_iter=100000).fit(X_train, y_train)
print("Training set score: {:.2f}".format(lasso001.score(X_train, y_train)))
print("Test set score: {:.2f}".format(lasso001.score(X_test, y_test)))
print("Number of features used: {}".format(np.sum(lasso001.coef_ != 0)))
Training set score: 0.90
Test set score: 0.77
Number of features used: 33
Un alpha más bajo nos permitió ajustar un modelo más complejo, que funcionó mejor en los datos de entrenamiento y de prueba. El rendimiento es ligeramente mejor que utilizando
Ridge, y estamos utilizando solo 33 de las 105 características.Esto hace que este modelo sea potencialmente más fácil de entender. Sin embargo, si fijamos alpha demasiado bajo, volvemos a eliminar el efecto de la regularización y acabamos en overfitting, con un resultado similar al de
LinearRegression
lasso00001 = Lasso(alpha=0.0001, max_iter=100000).fit(X_train, y_train)
print("Training set score: {:.2f}".format(lasso00001.score(X_train, y_train)))
print("Test set score: {:.2f}".format(lasso00001.score(X_test, y_test)))
print("Number of features used: {}".format(np.sum(lasso00001.coef_ != 0)))
Training set score: 0.95
Test set score: 0.64
Number of features used: 96
Una vez más, podemos trazar los coeficientes de los diferentes modelos
sns.set(font_scale=1.2)
plt.figure(figsize=(8, 8))
plt.plot(lasso.coef_, 's', label="Lasso alpha=1")
plt.plot(lasso001.coef_, '^', label="Lasso alpha=0.01")
plt.plot(lasso00001.coef_, 'v', label="Lasso alpha=0.0001")
plt.plot(ridge01.coef_, 'o', label="Ridge alpha=0.1")
plt.legend(ncol=2, loc=(0, 1.05))
plt.ylim(-25, 25)
plt.xlabel("Coefficient index")
plt.ylabel("Coefficient magnitude");
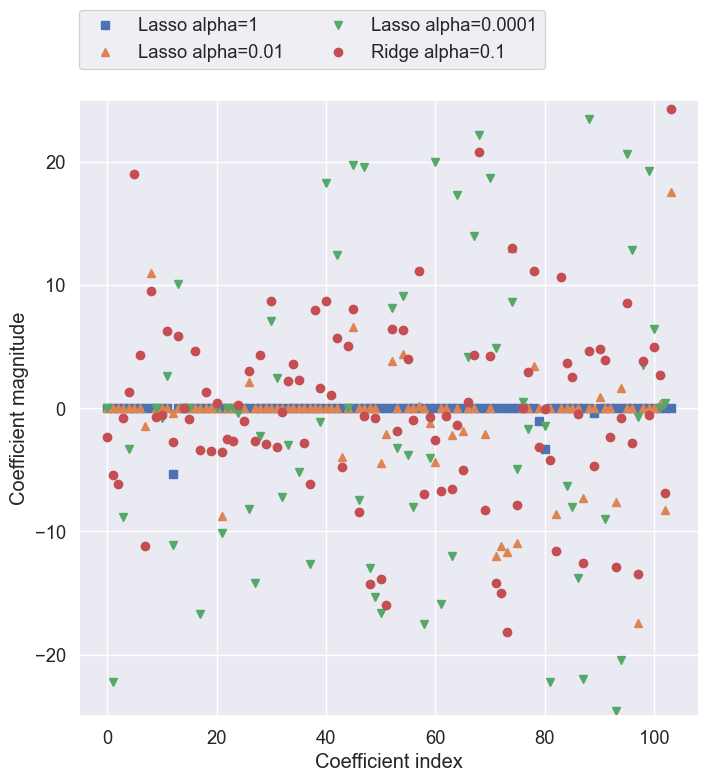
Para
alpha = 1, no sólo vemos que la mayoría de los coeficientes son cero (algo que ya sabíamos), sino que los coeficientes restantes también son de pequeña magnitud. Disminuyendo alpha a 0.01 , obtenemos la solución mostrada en triángulos salmones, que hace que la mayoría de las características sean exactamente cero.Utilizando alpha = 0.0001, obtenemos un modelo bastante poco regularizado, con la mayoría de los coeficientes no nulos y de gran magnitud. A modo de comparación, la mejor solución
Ridgese muestra con puntos rojos. El modelo Ridge con alpha = 0.1 tiene un rendimiento predictivo similar al del modelo lasso con alpha = 0.01, pero utilizando Ridge, todos los coeficientes son distintos de cero.
Observación
En la práctica, la regresión Ridge suele ser la primera opción entre estos dos modelos. Sin embargo, si tiene una gran cantidad de características y espera que sólo unas pocas sean importantes, Lasso podría ser una mejor opción. Del mismo modo, si desea tener un modelo que es fácil de interpretar, Lasso proporcionará un modelo que es más fácil de entender, ya que seleccionará sólo un subconjunto de las características de entrada.
scikit-learntambién proporciona la claseElasticNet, que combina las penalizaciones deLassoyRidge. En la práctica, esta combinación funciona mejor, aunque al precio de tener dos parámetros que ajustar: uno para la regularización \(L^1\), y otro para la regularización \(L^2\).
3.8. Modelos lineales para clasificación#
Los modelos lineales también se utilizan ampliamente para la clasificación. Veamos primero la clasificación binaria. En este caso, la predicción se realiza mediante la siguiente fórmula
La fórmula es muy similar a la de la regresión lineal, pero en lugar de devolver simplemente la suma ponderada de las características, ponemos un umbral al valor predicho en cero. Si la función es menor que cero, predecimos la clase -1; si es mayor que cero, predecimos la clase +1. Esta regla de predicción es común a todos los modelos lineales de clasificación. De nuevo, hay muchas formas diferentes de encontrar los coeficientes \(\boldsymbol{\beta}\).
En los modelos lineales de regresión, la salida, \(\hat{y}\), es una función lineal de las características: una línea, un plano o un hiperplano. En los modelos lineales de clasificación, la frontera de decisión es una función lineal de la entrada. En otras palabras, un clasificador lineal (binario) es un clasificador que separa dos clases utilizando una línea, un plano o un hiperplano.
Hay muchos algoritmos para aprender modelos lineales. Todos estos algoritmos difieren en los dos aspectos siguientes:
La forma en que miden que tan bien una combinación particular de coeficientes se ajusta a los datos de entrenamiento.
Si utilizan regularización, de que tipo utilizan
Los distintos algoritmos eligen diferentes formas de medir lo que significa “ajustarse bien al conjunto de entrenamiento”. Los dos algoritmos de clasificación lineal más comunes son la regresión logística, implementada en
linear_model.LogisticRegression, y las máquinas de vectores de soporte lineales (SVMs lineales), implementadas en svm.LinearSVC (SVC significa clasificador de vectores de soporte).A pesar de su nombre,
LogisticRegressiones un algoritmo de clasificación y no de regresión, por lo tanto no debe confundirse conLinearRegression. Podemos aplicar los modelosLogisticRegressionyLinearSVCal conjunto de datosforgey visualizar la frontera de decisión encontrada por los modelos lineales.
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC
sns.set_style("darkgrid")
X, y = mglearn.datasets.make_forge()
fig, axes = plt.subplots(1, 2, figsize=(15, 5))
for model, ax in zip([LinearSVC(), LogisticRegression()], axes):
clf = model.fit(X, y)
mglearn.plots.plot_2d_separator(clf, X, fill=False, eps=0.5, ax=ax, alpha=.7)
mglearn.discrete_scatter(X[:, 0], X[:, 1], y, ax=ax)
ax.set_title("{}".format(clf.__class__.__name__))
ax.set_xlabel("Feature 0")
ax.set_ylabel("Feature 1")
axes[0].legend()
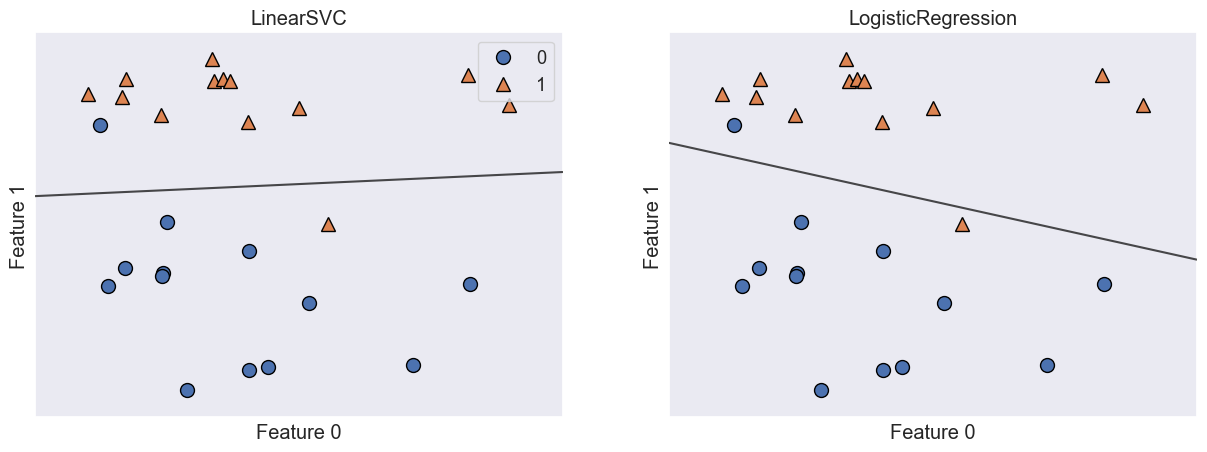
En esta figura, tenemos la primera característica del conjunto de datos
forgeen el eje \(x\) y la segunda característica en el eje \(y\), como antes. Se muestran las fronteras de decisión encontrados por LinearSVC y LogisticRegression respectivamente como líneas rectas, separando el área clasificada como clase 1 en la parte superior, del área clasificada como clase 0 en la parte inferior.En otras palabras, cualquier nuevo punto de datos que se encuentre por encima de la línea negra será clasificado como clase 1 por el clasificador respectivo, mientras que cualquier punto que se encuentre por debajo de la línea negra será clasificado como clase 0. Los dos modelos entregan fronteras de decisión similares. Obsérvese que ambos clasifican erróneamente dos de los puntos.
Por defecto, ambos modelos aplican una regularización \(L^{2}\), de la misma manera que lo hace Ridge para la regresión. Para
LogisticRegressionyLinearSVCel parámetro de compensación que determina la fuerza de la regularización se llamaC, y los valores más altos de C corresponden a menor regularización.
Hay otro aspecto interesante de cómo actúa el parámetro
C. El uso de valores bajos de C harán que los algoritmos traten de ajustarse a la “mayoría” de los puntos de datos, mientras que el uso de valores más altos de C enfatiza la importancia de que cada punto de datos individual sea clasificado correctamente. Veamos una ilustración utilizandoLinearSVC.
En otras palabras, cuando se utiliza un valor alto para el parámetro
C,LogisticRegressionyLinearSVCintentan ajustarse al conjunto de entrenamiento lo mejor posible, mientras que con valores bajos del parámetroC, los modelos ponen más énfasis en encontrar un vector de coeficientes \(\boldsymbol{\beta}\) que se acerque a cero.
mglearn.plots.plot_linear_svc_regularization();
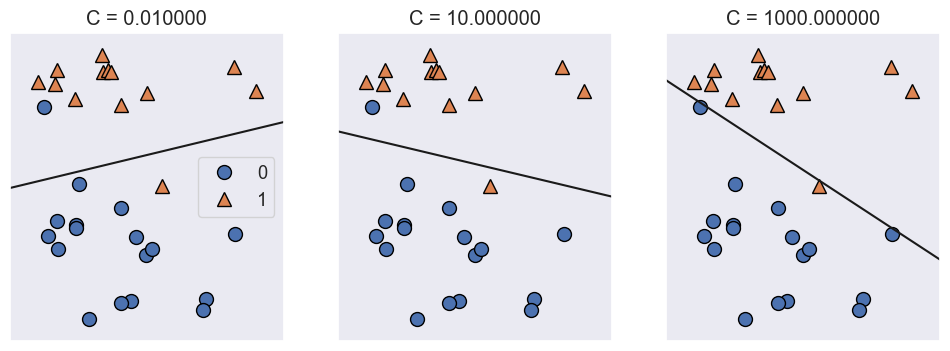
En el lado izquierdo, tenemos un valor de \(C\) muy pequeño (\(C=0.01\)) que corresponde a una gran regularización. La mayoría de los puntos de la clase 0 están en la parte superior, y la mayoría de los puntos de la clase 1 están en la parte inferior. El modelo fuertemente regularizado elige una línea relativamente horizontal, clasificando erróneamente dos puntos.
En el gráfico central, \(C\) es ligeramente más alto (\(C=10\)), y el modelo se centra más en las dos muestras mal clasificadas, inclinando el límite de decisión. Por último, en el lado derecho, correspondiente al valor mas alto de \(C\) (\(C=1000\)), el modelo inclina mucho mas la frontera de decisión, clasificando ahora correctamente todos los puntos de la clase 0. Solo uno de los puntos de la clase 1 sigue estando mal clasificado, ya que no es posible clasificar correctamente todos los puntos de este conjunto de datos utilizando una línea recta.
El modelo ilustrado en la parte derecha se esfuerza por clasificar correctamente todos los puntos, pero puede que no capte bien la disposición general de las clases. En otras palabras, es probable que el modelo ilustrado en la derecha presente overfitting. Al igual que en el caso de la regresión, los modelos lineales de clasificación pueden parecer muy restrictivos en espacios de baja dimensión, ya que sólo permiten límites de decisión que sean líneas rectas o planos.
De nuevo, en dimensiones altas, los modelos lineales de clasificación se vuelven muy potentes, y la protección contra el overfitting es cada vez más importante cuando se consideran más características.
Analicemos
LinearLogisticcon más detalle en el conjunto de datos de cáncer de mama:
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
X_train, X_test, y_train, y_test = train_test_split(cancer.data,
cancer.target,
stratify=cancer.target,
random_state=42)
logreg = LogisticRegression().fit(X_train, y_train)
print("Training set score: {:.3f}".format(logreg.score(X_train, y_train)))
print("Test set score: {:.3f}".format(logreg.score(X_test, y_test)))
Training set score: 0.955
Test set score: 0.951
El valor por defecto de \(C=1\) proporciona un rendimiento bastante bueno, con una precisión del 95% tanto en el conjunto de entrenamiento como en el de prueba. Si intentamos aumentar \(C\) obtenemos un modelo más complejo
logreg100 = LogisticRegression(C=1000000).fit(X_train, y_train)
print("Training set score: {:.3f}".format(logreg100.score(X_train, y_train)))
print("Test set score: {:.3f}".format(logreg100.score(X_test, y_test)))
Training set score: 0.958
Test set score: 0.958
El uso de \(C=1000000\) da lugar a una mayor precisión en el conjunto de entrenamiento. También podemos investigar qué ocurre si utilizamos un modelo aún más regularizado que el predeterminado de \(C=1\), estableciendo \(C=0.01\)
logreg001 = LogisticRegression(C=0.01).fit(X_train, y_train)
print("Training set score: {:.3f}".format(logreg001.score(X_train, y_train)))
print("Test set score: {:.3f}".format(logreg001.score(X_test, y_test)))
Training set score: 0.934
Test set score: 0.930
Cuando se desplaza más hacia la izquierda en la escala mostrada en la Fig. 1.3 e obtiene un modelo subjustado, tanto la precisión del conjunto de entrenamiento como la de la prueba disminuyen en relación con los parámetros por defecto. Por último, veamos los coeficientes aprendidos por los modelos con las tres configuraciones diferentes de los parámetros de regularización \(C\)
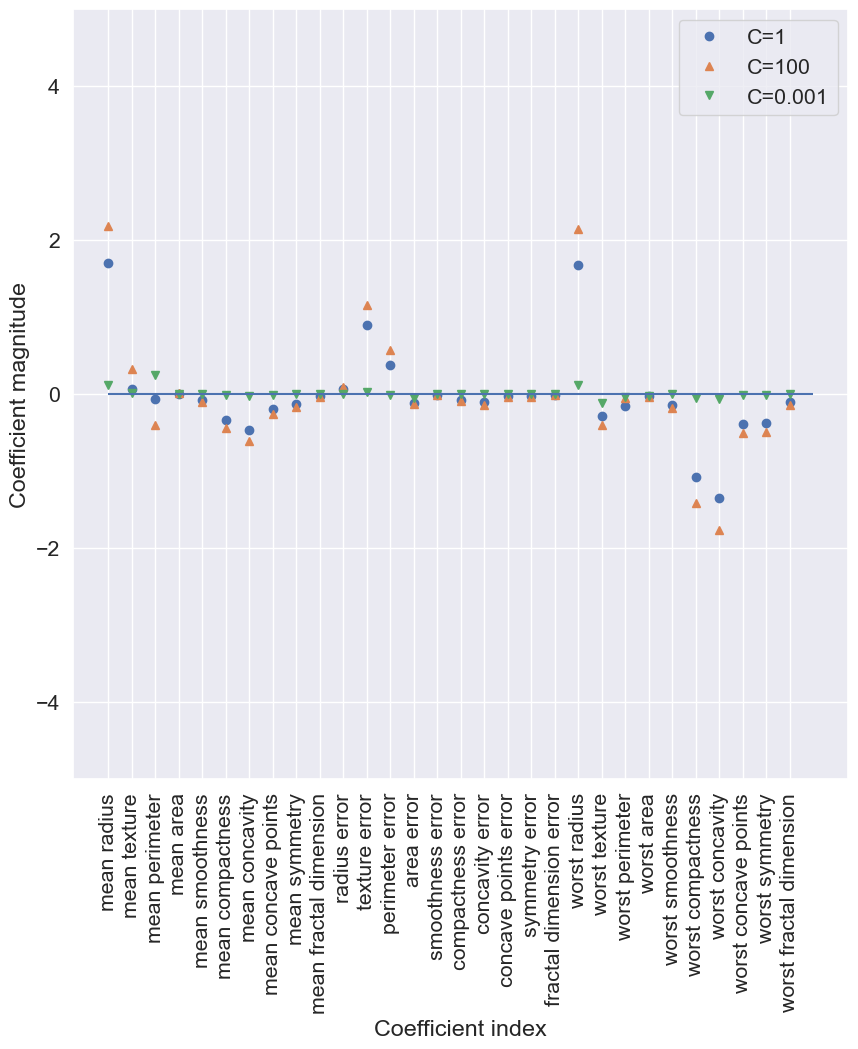
sns.set(font_scale=1.4)
plt.figure(figsize=(10, 10))
plt.plot(logreg.coef_.T, 'o', label="C=1")
plt.plot(logreg100.coef_.T, '^', label="C=100")
plt.plot(logreg001.coef_.T, 'v', label="C=0.001")
plt.xticks(range(cancer.data.shape[1]), cancer.feature_names, rotation=90)
plt.hlines(0, 0, cancer.data.shape[1])
plt.ylim(-5, 5)
plt.xlabel("Coefficient index")
plt.ylabel("Coefficient magnitude")
plt.legend();
Si deseamos un modelo más interpretable, el uso de la regularización \(L^{1}\) podría ayudar, ya que limita el modelo a utilizar sólo unas pocas características. El siguiente es el gráfico de coeficientes y las precisiones de clasificación para la regularización \(L^{1}\)
sns.set(font_scale=1.4)
plt.figure(figsize=(10, 10))
for C, marker in zip([0.001, 1, 100], ['o', '^', 'v']):
lr_l1 = LogisticRegression(C=C,
penalty="l1",
solver='liblinear').fit(X_train, y_train)
print("Training accuracy of l1 logreg with C={:.3f}: {:.2f}".format(
C, lr_l1.score(X_train, y_train)))
print("Test accuracy of l1 logreg with C={:.3f}: {:.2f}".format(
C, lr_l1.score(X_test, y_test)))
plt.plot(lr_l1.coef_.T, marker, label="C={:.3f}".format(C))
plt.xticks(range(cancer.data.shape[1]), cancer.feature_names, rotation=90)
plt.hlines(0, 0, cancer.data.shape[1])
plt.xlabel("Coefficient index")
plt.ylabel("Coefficient magnitude")
plt.ylim(-5, 5)
plt.legend(loc=3);
Training accuracy of l1 logreg with C=0.001: 0.91
Test accuracy of l1 logreg with C=0.001: 0.92
Training accuracy of l1 logreg with C=1.000: 0.96
Test accuracy of l1 logreg with C=1.000: 0.96
Training accuracy of l1 logreg with C=100.000: 0.99
Test accuracy of l1 logreg with C=100.000: 0.98
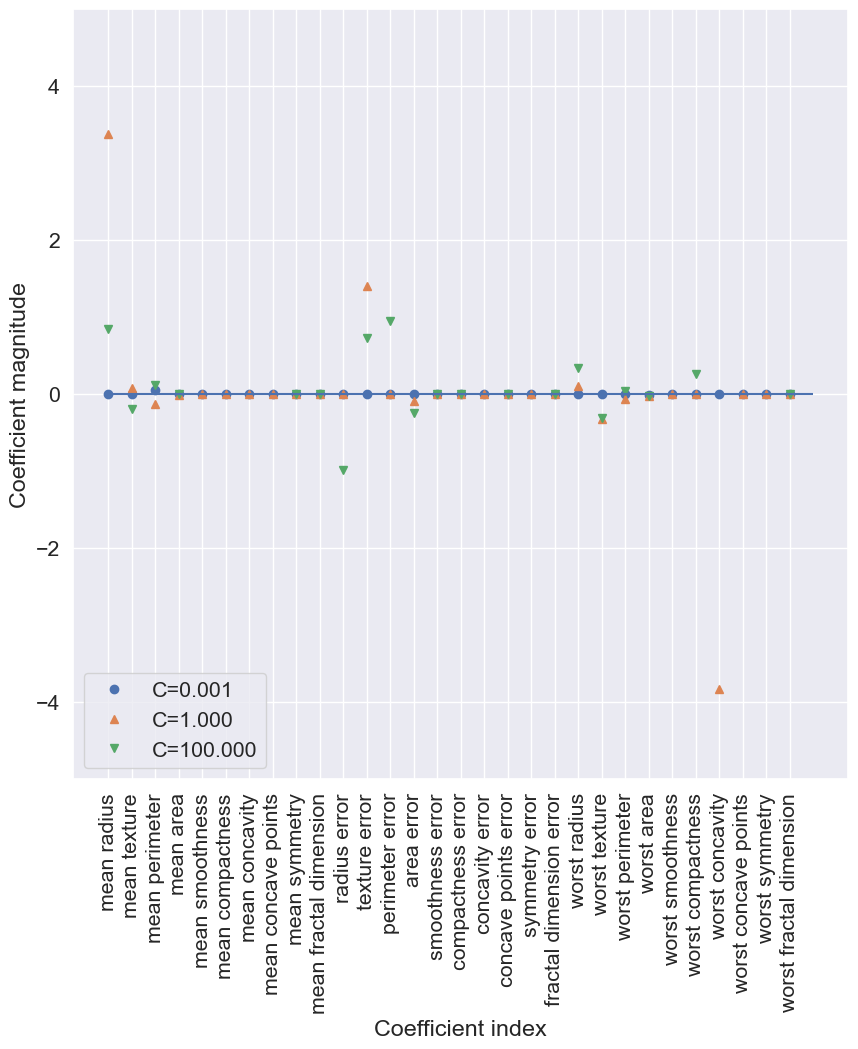
Como puede ver, hay mucha similitud entre los modelos lineales de clasificación binaria y los modelos lineales de regresión. Como en la regresión, la principal diferencia entre los modelos es el parámetro de penalización, que influye en la regularización, en si el modelo utilizará todas las características disponibles o seleccionará sólo un subconjunto.
3.9. Modelos lineales para la clasificación multiclase#
Muchos modelos de clasificación lineal solo funcionan para **clasificación binaria. Una forma común de extenderlos al caso multiclase es el enfoque one-vs-rest, donde se entrena un clasificador binario por cada clase contra el resto. Para predecir, se ejecutan todos los modelos y se asigna la clase con la mayor puntuación.
Las matemáticas que subyacen a la regresión logística multiclase difieren en cierta medida del enfoque de una sola clase, pero también dan como resultado un vector de coeficientes y un intercepto por clase, y se aplica el mismo método para hacer una predicción.
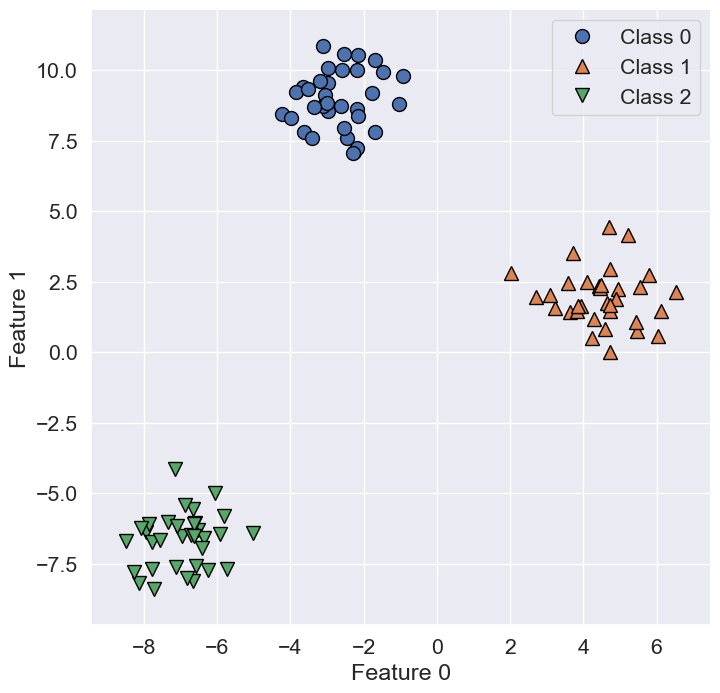
Apliquemos el método de one-vs.-rest a un conjunto de datos de clasificación de tres clases. Utilizamos un conjunto de datos bidimensional, en el que cada clase viene dada por datos muestreados de una distribución gaussiana.
from sklearn.datasets import make_blobs
X, y = make_blobs(random_state=42)
plt.figure(figsize=(8, 8))
mglearn.discrete_scatter(X[:, 0], X[:, 1], y)
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
plt.legend(["Class 0", "Class 1", "Class 2"]);
Ahora, entrenamos un clasificador
LinearSVCen el conjunto de datos
linear_svm = LinearSVC().fit(X, y)
print("Coefficient shape: ", linear_svm.coef_.shape)
print("Intercept shape: ", linear_svm.intercept_.shape)
Coefficient shape: (3, 2)
Intercept shape: (3,)
Vemos que la dimensión (
shape) decoef_es(3, 2), lo que significa que cada fila de coef_ contiene el vector de coeficientes para cada una de las tres clases y cada columna contiene el valor del coeficiente para cada característica específica (hay dos en este conjunto de datos).La matriz intercept_ es ahora una matriz unidimensional que almacena los interceptos de cada clase. Visualicemos las líneas dadas por los tres clasificadores binarios. En este caso
line=x, para el clasificador separadorax+by+c=0.
mglearn.discrete_scatter(X[:, 0], X[:, 1], y)
line = np.linspace(-15, 15)
for coef, intercept, color in zip(linear_svm.coef_, linear_svm.intercept_, ['b', 'r', 'g']):
plt.plot(line, -(line * coef[0] + intercept) / coef[1], c=color)
plt.ylim(-10, 15)
plt.xlim(-10, 8)
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
plt.legend(['Class 0', 'Class 1', 'Class 2', 'Line class 0', 'Line class 1',
'Line class 2'], loc=(1.01, 0.3))
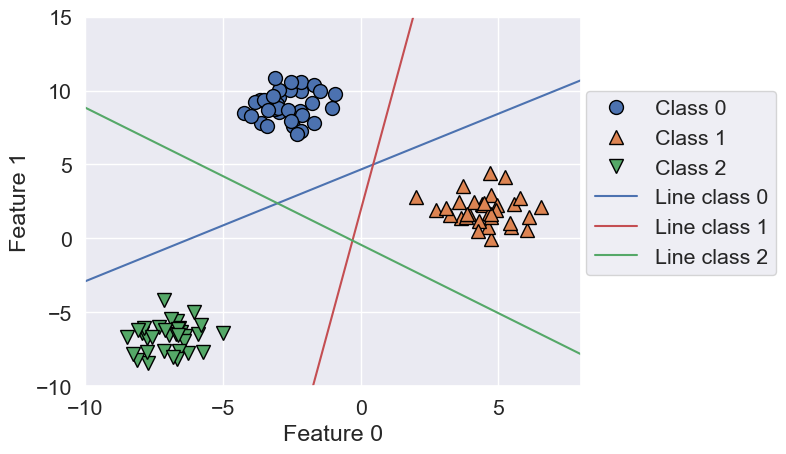
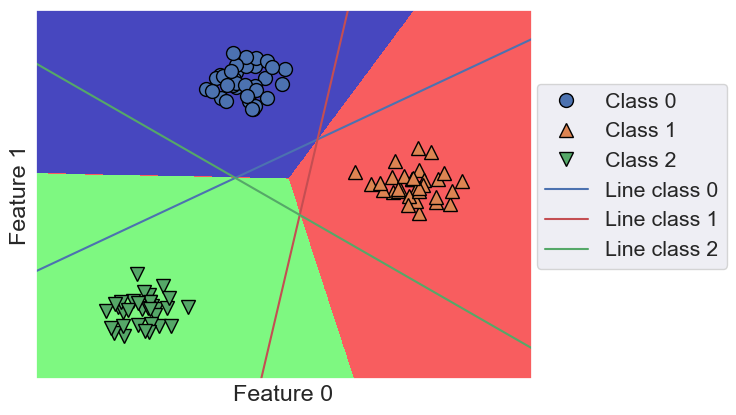
Los puntos de la clase 0 están en el lado de “clase 0” de su clasificador y son clasificados como “resto” por los clasificadores de clase 1 y 2. Así, cualquier punto en esta región será asignado a la clase 0. En el triángulo central, todos los clasificadores lo marcan como “resto”. En este caso, el punto se asigna a la clase cuya línea esté más cerca, según la fórmula de clasificación.
El ejemplo siguiente muestra las predicciones en el espacio 2D.
mglearn.plots.plot_2d_classification(linear_svm, X, fill=True, alpha=.7)
mglearn.discrete_scatter(X[:, 0], X[:, 1], y)
line = np.linspace(-15, 15)
for coef, intercept, color in zip(linear_svm.coef_, linear_svm.intercept_, ['b', 'r', 'g']):
plt.plot(line, -(line * coef[0] + intercept) / coef[1], c=color)
plt.legend(['Class 0', 'Class 1', 'Class 2', 'Line class 0', 'Line class 1',
'Line class 2'], loc=(1.01, 0.3))
plt.xlabel("Feature 0")
plt.ylabel("Feature 1")
Puntos fuertes, puntos débiles y parámetros
El parámetro principal de los modelos lineales es el parámetro de regularización, llamado
alphaen los modelos de regresión yCenLinearSVCyLogisticRegression. Los valores grandes de alpha o valores pequeños de C están asociados con modelos simples. En particular, para los modelos de regresión, el ajuste de estos parámetros es bastante importante. Normalmente,Cyalphase buscan en una escala logarítmica.La otra decisión que hay que tomar es si se quiere utilizar la regularización \(L^1\) o la regularización \(L^2\). Si se supone que sólo unas pocas características son realmente importantes, se debería utilizar la regularización \(L^1\), de lo contrario, debería utilizar \(L^2\) por defecto. \(L^1\) también puede ser útil si la interpretabilidad del modelo es importante. Como \(L^1\) utilizará sólo unas pocas características, es más fácil explicar qué características son importantes para el modelo, y cuáles son los efectos de esas características.
Los modelos lineales son muy rápidos de entrenar y de predecir. Se adaptan a conjuntos de datos muy grandes y funcionan bien con datos dispersos. Si sus datos constan de cientos de miles o millones de muestras, es posible que desee investigar el uso de la opción
solver='sag'enLogisticRegressionyRidge, que puede ser más rápida que la predeterminada en grandes conjuntos de datos. Otras opciones son la clase SGDClassifier y la clase SGDRegressor que implementan versiones aún más escalables de los modelos lineales descritos aquí.Otro punto fuerte de los modelos lineales es que permiten entender con relativa facilidad cómo se realiza una predicción, utilizando las fórmulas que vimos antes para la regresión y la clasificación. Por desgracia, a menudo, no está del todo claro por qué los coeficientes son como son. Esto es particularmente cierto si su conjunto de datos tiene características altamente correlacionadas; en estos casos, los coeficientes pueden ser difíciles de interpretar.
Los modelos lineales suelen funcionar bien cuando el número de características es grande en comparación con el número de muestras. También se utilizan a menudo en conjuntos de datos muy grandes, simplemente porque no es factible entrenar otros modelos. Sin embargo, en espacios de menor dimensión otros modelos pueden ofrecer un mejor rendimiento de generalización. Veremos algunos ejemplos en los que los modelos lineales fallan cuando abordemos
máquinas de vectores de soporte kernelizadas
3.10. Proyecto Integrador de Aprendizaje Automático#
3.10.1. Predicción del precio y clasificación de autos usados#
3.10.1.1. Objetivo general#
Diseñar modelos supervisados de regresión y clasificación binaria utilizando técnicas de regresión lineal regularizada (Ridge, Lasso) y regresión logística, integradas en un flujo completo con Pipeline y búsqueda de hiperparámetros mediante GridSearchCV, con el propósito de:
Estimar el precio de un auto usado a partir de sus características (tarea de regresión).
Clasificar si un vehículo está en alta demanda o baja demanda (tarea de clasificación binaria).
3.10.1.2. Contexto aplicado#
Plataformas digitales de compra-venta de autos usados requieren modelos predictivos para evaluar rápidamente el precio justo de un vehículo y su demanda esperada. Usando datos históricos reales de ventas, es posible entrenar modelos que orienten a compradores y vendedores en decisiones informadas.
3.10.1.3. Variables disponibles (ejemplo)#
Tipo |
Variables |
|---|---|
Técnicas |
Marca, modelo, año, tipo de carrocería, transmisión, combustible, tipo de tracción |
Operativas |
Kilometraje, número de dueños anteriores, cilindrada, condición del motor |
Mercado |
Precio ( |
Etiqueta extra |
|
3.10.1.4. Dataset sugerido#
Nombre: Used Cars Dataset
Fuente recomendada: Kaggle o UCI (varias versiones disponibles)
Tamaño típico: 15 000–30 000 registros
Enlace de ejemplo: https://www.kaggle.com/datasets/austinreese/craigslist-carstrucks-data
3.10.1.5. Tareas#
Preprocesamiento
Codificación categórica (
Brand,Model,Transmission, etc.) con one-hot encodingEscalado de variables numéricas (
Mileage,Year,EngineSize) usandoStandardScalerEliminación o imputación de valores faltantes
Generar la variable binaria
HighDemand:df['HighDemand'] = (df['Price'] > df['Price'].median()).astype(int)
Construcción de Pipelines
Definir pipelines independientes para:
Regresión (
Ridge,Lasso)Clasificación (
LogisticRegression)
Incluir en cada pipeline:
Transformaciones (escalado + encoding)
Modelo
Validación cruzada con
GridSearchCV
Entrenamiento y ajuste
Usar
GridSearchCVpara encontrar el mejor valor de:alphaenRidgeyLassoCenLogisticRegression
Validación cruzada estratificada (
cv=5)
Evaluación de desempeño
Regresión:
Métricas: MAE, RMSE, R²
Gráfico: valores predichos vs. reales
Clasificación:
Métricas: matriz de confusión, accuracy, precision, recall, F1-score
Curva ROC y cálculo del AUC
Análisis y reporte
Comparar modelos y valores óptimos de regularización
Discutir cuáles variables afectan más la demanda y el precio
Evaluar si la regularización mejora la capacidad de generalización
Presentar resultados en un notebook bien comentado
3.10.1.6. Restricciones didácticas#
Se debe usar
PipelineyGridSearchCVdescikit-learnEl código debe ser modular, reproducible y comentado
No se permite usar AutoML o herramientas de automatización externa
Incluir al menos 2 visualizaciones por tarea
3.10.1.7. Herramientas sugeridas#
pandas,numpy,scikit-learnmatplotlib,seabornJupyter Notebook o Google Colab
3.10.1.8. Resultado esperado#
Un notebook o script completo que documente:
Preprocesamiento y construcción de
HighDemandDiseño de pipelines
Resultados de
GridSearchCVpara regresión y clasificaciónEvaluación visual y cuantitativa
Conclusiones técnicas y reflexión crítica
3.10.1.9. Diseño sugerido del notebook#
Carga y exploración de los datos
Ingeniería de características (
HighDemand)Definición de pipelines
GridSearchCV con validación cruzada
Evaluación con métricas y gráficas
Conclusiones
3.10.1.10. Métricas#
Clasificación
Métrica |
Qué mide |
Cuándo usarla |
|---|---|---|
Accuracy |
Proporción de predicciones correctas sobre el total |
Datos balanceados y cuando todos los errores tienen el mismo costo |
Precision |
De las predicciones positivas, cuántas fueron realmente positivas |
Importante si los falsos positivos son costosos (ej: spam, diagnósticos falsos) |
Recall |
De los positivos reales, cuántos fueron detectados correctamente |
Importante si los falsos negativos son costosos (ej: enfermedades graves) |
F1-score |
Media armónica entre precision y recall |
Clases desbalanceadas; necesitas balancear precisión y cobertura |
ROC AUC |
Capacidad del modelo para distinguir entre clases |
Comparar modelos, especialmente si los umbrales cambian |
Matriz de confusión |
Muestra aciertos y errores por clase |
Siempre útil para entender los tipos de error |
Balanced Accuracy |
Promedio del recall de cada clase |
Dataset desbalanceado |
Regresión
Métrica |
Qué mide |
Cuándo usarla |
|---|---|---|
MSE (Mean Squared Error) |
Promedio de los errores al cuadrado |
Penaliza más los errores grandes; útil para comparar modelos durante el entrenamiento |
RMSE (Root Mean Squared Error) |
Raíz cuadrada del MSE |
Interpretación más intuitiva (en las mismas unidades que la variable objetivo) |
MAE (Mean Absolute Error) |
Promedio del valor absoluto de los errores |
Menos sensible a outliers que MSE; más robusto en datos con valores atípicos |
R² (Coeficiente de determinación) |
Proporción de la varianza explicada por el modelo |
Muy común para comparar modelos; varía entre -∞ y 1 (1=ajuste perfecto; <0=peor que promedio) |
Adjusted R² |
R² penalizado por el número de predictores |
Mejor para modelos con diferente número de variables; evita sobreajuste por exceso de variables |
MAPE (Mean Absolute Percentage Error) |
Error absoluto medio expresado en porcentaje |
Útil si te interesa interpretar los errores como porcentaje; cuidado con valores cercanos a cero |
Mediana AE (Median Absolute Error) |
Mediana del valor absoluto de los errores |
Aún más robusto a outliers que MAE |
3.10.1.11. Resumen#
Dataset |
Tareas |
Tamaño |
Ventajas clave |
|---|---|---|---|
Used Cars Dataset |
Clasificación y regresión |
~20 000 |
Real, variado, con variables relevantes y limpias |