
11. Deep Learning#
11.1. Gradiente descendente#
El método de gradiente descendente es uno de los mas ampliamente usados para la minimización iterativa de una función de costo diferenciable, \(J(\boldsymbol{\theta}),~\boldsymbol{\theta}\in\mathbb{R}^{l}\). Como cualquier otra técnica iterativa, el método parte de una estimación inicial, \(\boldsymbol{\theta}^{(0)}\), y genera una sucesión \(\boldsymbol{\theta}^{(i)},~i=1,2,\dots,\) tal que:
\[ \boldsymbol{\theta}^{(i)}=\boldsymbol{\theta}^{(i-1)}+\mu_{i}\Delta\boldsymbol{\theta}^{(i)},~ i >0,~\mu_{i}>0. \]La diferencia entre cada método radica en la forma que \(\mu_{i}\) y \(\Delta\boldsymbol{\theta}^{(i)}\) son seleccionados. \(\Delta\boldsymbol{\theta}^{(i)}\) es conocido como la dirección de actualización o de búsqueda. La sucesión \(\mu_{i}\) es conocida como el tamaño o longitud de paso en la \(i\)-ésima iteración, estos valores pueden ser constantes o cambiar. En el método de gradiente descendente, la selección de \(\Delta\boldsymbol{\theta}^{(i)}\) es realizada para garantizar que \(J(\boldsymbol{\theta}^{(i)})<J(\boldsymbol{\theta}^{(i-1)})\), excepto en el minimizador \(\boldsymbol{\theta}_{\star}\).
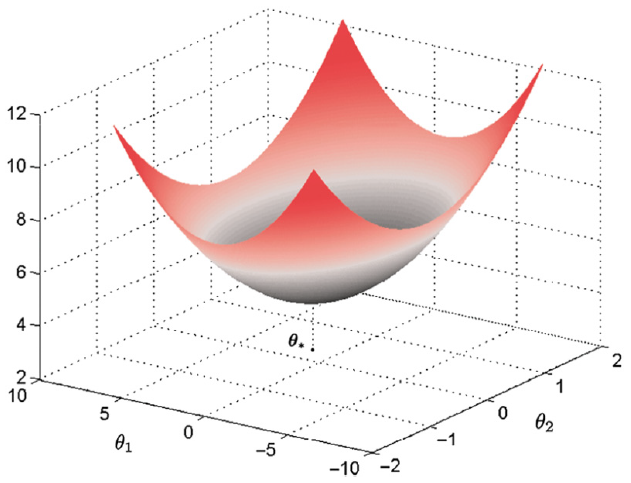
Fig. 11.1 Función de coste en el espacio de parámetros bidimensional.#
Suponga que en la iteración \(i-1\) el valor \(\boldsymbol{\theta}^{(i-1)}\) ha sido obtenido. Evaluando la función objetivo en el nuevo punto se obtiene
Si \(\mu_i\) es suficientemente pequeño, el nuevo punto se encuentra en un entorno cercano a \(\boldsymbol{\theta}^{(i-1)}\), lo que permite aproximar \(J(\cdot)\) mediante una expansión de Taylor de primer orden alrededor de \(\boldsymbol{\theta}^{(i-1)}\):
\[ J(\boldsymbol{\theta}^{(i-1)} + \mathbf{h}) \approx J(\boldsymbol{\theta}^{(i-1)}) + \nabla^{T} J(\boldsymbol{\theta}^{(i-1)})\, \mathbf{h}, \]donde \(\mathbf{h}\) es una perturbación pequeña.
En este caso,
Sustituyendo en la expresión anterior se obtiene
\[ J(\boldsymbol{\theta}^{(i)}) \approx J(\boldsymbol{\theta}^{(i-1)}) + \nabla^{T} J(\boldsymbol{\theta}^{(i-1)}) \big(\mu_i \Delta \boldsymbol{\theta}^{(i)}\big), \]o, de forma equivalente,
\[ J(\boldsymbol{\theta}^{(i)}) \approx J(\boldsymbol{\theta}^{(i-1)}) + \mu_i \cdot \nabla^{T} J(\boldsymbol{\theta}^{(i-1)}) \Delta \boldsymbol{\theta}^{(i)}. \]Esta aproximación describe el cambio local de la función objetivo como una función lineal del desplazamiento en el espacio de parámetros. El término \(\nabla^{T} J(\boldsymbol{\theta}^{(i-1)}) \Delta \boldsymbol{\theta}^{(i)}\) corresponde al producto interno entre el gradiente y la dirección de actualización, e indica si el valor de la función objetivo aumenta o disminuye.
Nótese que seleccionando la dirección tal que \(\nabla^{T}J(\boldsymbol{\theta}^{(i-1)})\Delta\boldsymbol{\theta}^{(i)}<0\), garantizará que \(J(\boldsymbol{\theta}^{(i-1)}+\mu_{i}\Delta\boldsymbol{\theta}^{(i)})<J(\boldsymbol{\theta}^{(i-1)})\). Tal selección de \(\Delta\boldsymbol{\theta}^{(i)}\) y \(\nabla J(\boldsymbol{\theta}^{(i-1)})\) debe formar un ángulo obtuso. Las curvas de nivel asociadas a \(J(\boldsymbol{\theta})\) pueden tomar cualquier forma, la cual va a depender de como está definido \(J(\boldsymbol{\theta})\).
\(J(\boldsymbol{\theta})\) se supone diferenciable, por lo tanto, las curvas de nivel o contornos deben ser suaves y aceptar un plano tangente en cualquier punto. Además, de los cursos de cálculo sabemos que el vector gradiente \(\nabla J(\boldsymbol{\theta})\) es perpendicular al plano tangente (recta tangente) a la correspondiente curva de nivel en el punto \(\boldsymbol{\theta}\). Nótese que seleccionando la dirección de búsqueda \(\Delta\boldsymbol{\theta}^{(i)}\) que forma un angulo obtuso con el gradiente, se coloca a \(\boldsymbol{\theta}^{(i-1)}+\mu_{i}\Delta\boldsymbol{\theta}^{(i)}\) en un punto sobre el contorno el cual corresponde a un valor menor que \(J(\boldsymbol{\theta})\).
Dos problemas surgen ahora:
Escoger la mejor dirección de búsqueda
Calcular que tan lejos es aceptable un movimiento a traves de esta dirección.
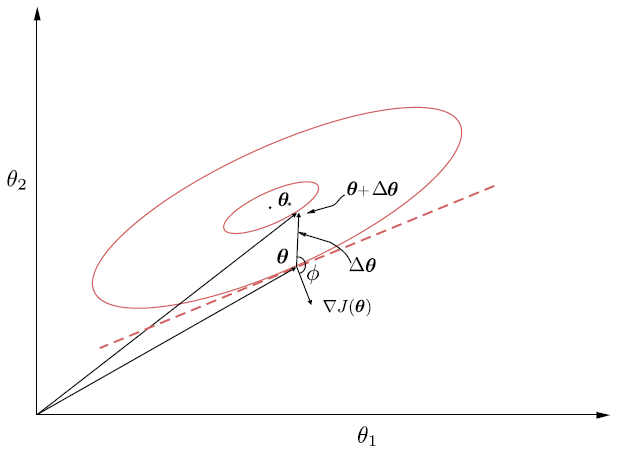
Fig. 11.2 El vector gradiente en un punto \(\boldsymbol{\theta}\) es perpendicular al plano tangente (línea punteada) en la curva de nivel que cruza \(\boldsymbol{\theta}\). La dirección de descenso forma un ángulo obtuso, \(\phi\), con el vector gradiente.#
Nótese que si \(\mu_{i}\|\Delta\boldsymbol{\theta}^{(i)}\|\) es demasiado grande, entonces el nuevo punto puede ser colocado en un contorno correspondiente a un valor mayor al del actual contorno.

Fig. 11.3 Las correspondientes curvas de nivel para la función de coste, en el plano bidimensional. Nótese que a medida que nos alejamos del valor óptimo, \(\boldsymbol{\theta}_{\star}\), los valores de \(c\) aumentan.#
Con el fin de analizar exclusivamente la dirección de búsqueda (1), se fija inicialmente \(\mu_i = 1\) y se consideran únicamente vectores de búsqueda unitarios \(\boldsymbol{z}\) tales que
De este modo, el problema se reduce a determinar la dirección unitaria que minimiza el producto interno con el gradiente:
Nótese que
Si \(\nabla^T J \cdot z\) es grande y positivo, \(J\) aumenta mucho.
Si \(\nabla^T J \cdot z\) es grande y negativo, \(J\) disminuye mucho.
Este planteamiento responde a la pregunta fundamental:
¿En qué dirección, manteniendo fija la longitud del desplazamiento, se logra la mayor disminución local de la función objetivo?
De álgebra lineal se sabe que, para cualquier vector no nulo \(\boldsymbol{a} \in \mathbb{R}^n\),
\[ \min_{\|\boldsymbol{z}\| = 1} \; \boldsymbol{a}^{T} \boldsymbol{z} = -\|\boldsymbol{a}\|, \]y que dicho mínimo se alcanza cuando
\[ \boldsymbol{z} = -\frac{\boldsymbol{a}}{\|\boldsymbol{a}\|}. \]
En efecto, queremos resolver:
\[ \min_{\|z\| = 1} \mathbf{a}^T z \]donde \(\mathbf{a} \in \mathbb{R}^n\) es un vector fijo no nulo.
Recordemos la identidad del producto escalar:
\[ \mathbf{a}^T z = \|\mathbf{a}\| \|z\| \cos \theta, \]donde \(\theta\) es el ángulo entre \(\mathbf{a}\) y \(z\).
Dado que \(\|z\| = 1\), la expresión se simplifica a:
Como \(\|\mathbf{a}\| > 0\) es constante, minimizar \(\mathbf{a}^T z\) equivale a minimizar \(\cos \theta\). El rango de la función coseno es
El valor mínimo \(\cos \theta = -1\) se alcanza cuando
Cuando \(\theta = \pi\), el vector \(z\) apunta en la dirección exactamente opuesta a \(\mathbf{a}\). Esto significa que existe un escalar \(\alpha < 0\) tal que
Calculamos la norma de \(z\)
Dado que \(\|z\| = 1\), tenemos
Como \(\alpha < 0\):
Sustituyendo \(\alpha\) en \(z = \alpha \mathbf{a}\):
Aplicación al gradiente. Tomando
\[ \boldsymbol{a} = \nabla J(\boldsymbol{\theta}^{(i-1)}), \]se concluye que la dirección unitaria que produce la mayor disminución local de \(J\) es
\[ \boldsymbol{z} = -\frac{\nabla J(\boldsymbol{\theta}^{(i-1)})} {\|\nabla J(\boldsymbol{\theta}^{(i-1)})\|}. \]Geométricamente:
El gradiente \(\nabla J\) apunta en la dirección de máximo crecimiento de \(J\).
El gradiente negativo apunta en la dirección de máximo descenso local.
La normalización únicamente fija la longitud del vector.
En la práctica, no es necesario normalizar la dirección de descenso, ya que el tamaño del paso está controlado por el parámetro \(\mu_i\). Por esta razón, se define directamente
\[ \Delta \boldsymbol{\theta}^{(i)} = -\nabla J(\boldsymbol{\theta}^{(i-1)}), \]lo que da lugar al método conocido como descenso por gradiente.
Sustituyendo esta elección en el producto interno se obtiene
Este valor es estrictamente negativo, excepto en puntos críticos donde el gradiente se anula. En consecuencia, para valores suficientemente pequeños de \(\mu_i\), la aproximación de Taylor garantiza que
\[ J(\boldsymbol{\theta}^{(i)}) < J(\boldsymbol{\theta}^{(i-1)}), \]lo que asegura una disminución del valor de la función objetivo en cada iteración.
Por lo tanto, para todos los vectores con norma Euclidiana 1, la dirección de descenso mas pronunciada coincide con la dirección del gradiente descendente, negativo, y la correspondiente actualización recursiva se convierte en
\[ \boldsymbol{\theta}^{(i)}=\boldsymbol{\theta}^{(i-1)}-\mu_{i}\nabla J(\boldsymbol{\theta}^{(i-1)}),\quad\text{Gradiente descendente}. \]donde
\(-\nabla J\!\left(\theta^{(i-1)}\right)\) representa la dirección de descenso.
\(\mu_i > 0\) es el tamaño del paso o learning rate.
La cantidad \(\|\nabla J(\theta^{(i-1)})\|^2\) aparece únicamente en el análisis teórico del descenso, al evaluar la variación de la función objetivo, y no forma parte de la actualización del algoritmo.
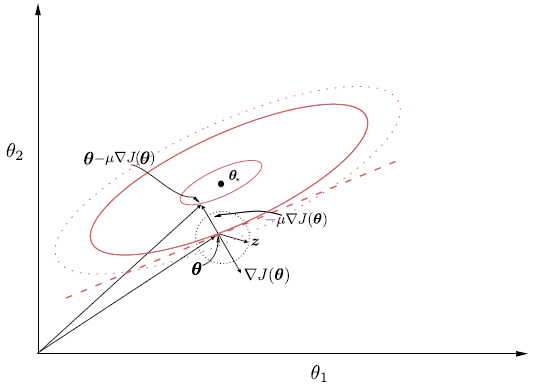
Fig. 11.4 Representación del gradiente negativo el cual conduce a la máxima disminución de la función de coste.#
La selección de \(\mu_{i}\) debe ser realizada de tal forma que garantice convergencia de la secuencia de minimización. Nótese que el algoritmo puede oscilar en torno al mínimo sin converger, si no seleccionamos la dirección correcta. La selección de \(\mu_{i}\) dependerá de la convergencia a cero del error entre \(\boldsymbol{\theta}^{(i)}\) y el mínimo real en forma de serie geométrica.
Ejercicio
Por ejemplo, para el caso de la función de coste del error cuadrático medio, la longitud de paso está dada por: \(0<\mu<2/\lambda_{\max}\), donde \(\lambda_{\max}\) el máximo eigenvalor de la matriz de covarianza \(\Sigma_{x}=\mathbb{E}[\boldsymbol{x}\boldsymbol{x}^{T}]\), donde \(J(\boldsymbol{\theta})=E[(y-\boldsymbol{\theta}^{T}\boldsymbol{x})^{2}]\) (ver Sección 5.3 [Theodoridis, 2020]).
11.2. Redes neuronales#
Introducción
Las redes neuronales son sistemas de aprendizaje compuestos por neuronas conectadas en capas que ajustan sus conexiones para aprender. Tras un período de 25 años desde su inicio, las redes neuronales se convirtieron en la norma en el aprendizaje automático. En un principio, dominaron durante una década, pero luego fueron superadas por máquinas de vectores de soporte.
Sin embargo, desde 2010, las redes neuronales profundas se han vuelto populares gracias a mejoras en la tecnología y la disponibilidad de grandes conjuntos de datos, impulsando el campo del aprendizaje automático.
11.3. El perceptrón#
Nuestro punto de partida será considerar el problema simple de una tarea de clasificación conformada por dos clases linealmente separables. En otras palabras, dado un conjunto de muestras de entrenamiento, \((y_{n}, \boldsymbol{x}_{n})\), \(n=1,2,\dots,N\), con \(y_{n}\in\{-1,+1\},~\boldsymbol{x}_{n}\in\mathbb{R}^{l}\), suponemos que existe un hiperplano
\[ \boldsymbol{\theta}_{\star}^{T}\boldsymbol{x}=0, \]tal que,
\[\begin{split} \begin{cases} \boldsymbol{\theta}_{\star}^{T}\boldsymbol{x}&>0,\quad\text{si}\quad\boldsymbol{x}\in\omega_{1}\\ \boldsymbol{\theta}_{\star}^{T}\boldsymbol{x}&<0,\quad\text{si}\quad\boldsymbol{x}\in\omega_{2} \end{cases} \end{split}\]En otras palabras, dicho hiperplano clasifica correctamente todos los puntos del conjunto de entrenamiento. Para simplificar, el término de sesgo del hiperplano ha sido absorbido en \(\boldsymbol{\theta}_{\star}\) después de extender la dimensionalidad del espacio de entrada en uno. El objetivo ahora es desarrollar un algoritmo que calcule iterativamente un hiperplano que clasifique correctamente todos los patrones de ambas clases. Para ello, se adopta una función de costo.
Sea \(\boldsymbol{\theta}\) la estimación del vector de parámetros desconocidos, disponible en la actual iteración. Entonces hay dos posibilidades. La primera es que todos los puntos estén clasificados correctamente; esto significa que se ha obtenido una solución. La otra alternativa es que \(\boldsymbol{\theta}\) clasifique correctamente algunos de los puntos y el resto estén mal clasificados.
Costo perceptrón
Sea \(\mathcal{Y}\) el conjunto de todas las muestras mal clasificadas. La función de costo, perceptrón se define como
donde
Nótese que la función la función de costo es no negativa. En efecto, dado que la suma es sobre los puntos mal clasificados, si \(\boldsymbol{x}_{n}\in\omega_{1}~(\omega_{2}),~\) entonces \(\boldsymbol{\theta}^{T}\boldsymbol{x}_{n}\leq (\geq)~0\), entregando así un producto \(-y_{n}\boldsymbol{\theta}^{T}\boldsymbol{x}_{n}\geq0\).
La función de costo es cero, si no existen puntos mal clasificados, esto es, \(\mathcal{Y}=\emptyset\). La función de costo perceptrón no es diferenciable en todos los puntos, es lineal por tramos. Si reescribimos \(J(\boldsymbol{\theta})\) en una forma ligeramente diferente:
Nótese que esta es una función lineal con respeto a \(\boldsymbol{\theta}\), siempre que el conjunto de puntos mal clasificados permanezca igual. Además, nótese que ligeros cambios del valor \(\boldsymbol{\theta}\) corresponden a cambios de posición del respectivo hiperplano. Como consecuencia, existirá un punto donde el número de muestras mal clasificadas en \(\mathcal{Y}\), repentinamente cambia; este es el tiempo donde una muestra en el conjunto de entrenamiento cambia su posición relativa con respecto a el hiperplano en movimiento, y en consecuencia, el conjunto \(\mathcal{Y}\) es modificado. Después de este cambio, el conjunto, \(J(\boldsymbol{\theta})\), corresponderá a una nueva función lineal.
El algoritmo perceptrón
A partir del método de subgradientes se puede verificar fácilmente que, iniciando desde un punto arbitrario, \(\boldsymbol{\theta}^{(0)}\), el siguiente método iterativo,
converge después de un número finito de pasos. La sucesión de parámetros \(\mu_{i}\) es seleccionada adecuadamente para garantizar convergencia.
Nótese que usando el método de subgradiente (ver apéndice) o gradiente descendente se tiene que
Otra versión del algoritmo considera una muestra por iteración en un esquema cíclico, hasta que el algoritmo converge. Denotemos por \(y_{(i)}\), \(\boldsymbol{x}_{i},~i\in\{1,2,\dots,N\}\) los pares de entrenamiento presentados al algoritmo en la iteración \(i\)-ésima. Entonces, la iteración de actualización se convierte en:
Esto es, partiendo de una estimación inicial de forma random, inicializando \(\boldsymbol{\theta}^{(0)}\) con algunos valores pequeños, testeamos cada una de las muestras, \(\boldsymbol{x}_{n},~n=1,2,\dots,N\). Cada vez que una muestra es mal clasificada, se toma acción por medio de la regla perceptrón para una corrección. En otro caso, ninguna acción es requerida.
Una vez que todas las muestras han sido consideradas, decimos que una
época (epoch)ha sido completada. Si no se obtiene convergencia, todas las muestras son reconsideradas en una segunda época, y así sucesivamente. La versión de este algoritmo es conocida como esquemapattern-by-pattern. Algunas veces también es referido como el algoritmo online. Nótese que el número total de datos muestrales es fijo, y que el algoritmo las considera en forma cíclica, época por época (epoch-by-epoch).
Observación
Después de un número finito de épocas, se garantiza que el algoritmo es convergente (convexidad de \(J\) y clases linealmente separables). Nótese que para obtener dicha convergencia, la sucesión \(\mu_{i}\) debe ser seleccionada apropiadamente. Sin embargo, para el caso del algoritmo perceptrón, la convergencia es garantizada, aun cuando \(\mu_{i}\) es una constante positiva, \(\mu_{i}=\mu>0\), usualmente tomado igual a uno.
La formulación en (11.1) es conocida también como la filosofía de aprendizaje
reward-punishment. Si la actual estimación es exitosa en la predicción de la clase del respectivo patrón, ninguna acción es tomada (reward), en otro caso, el algoritmo es obligado a realizar una actualización (punishment).
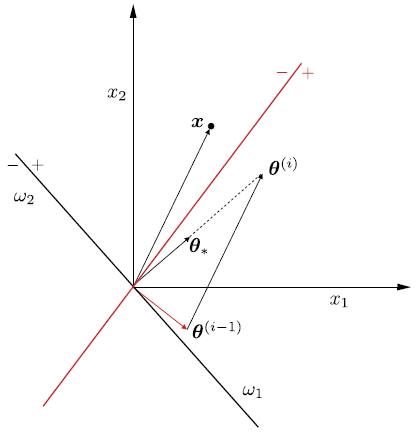
Fig. 11.5 El punto \(x\) está mal clasificado por la línea roja. La regla perceptrón gira el hiperplano hacia el punto \(x\), para intentar incluirlo en el lado correcto del nuevo hiperplano y clasificarlo correctamente.#
La Fig. 11.5 ofrece una interpretación geométrica de la regla del perceptrón. Supongamos que la muestra \(\boldsymbol{x}\) está mal clasificada por el hiperplano, \(\boldsymbol{\theta}^{(i-1)}\). Como sabemos, por geometría analítica, \(\boldsymbol{\theta}^{(i-1)}\) corresponde a un vector que es perpendicular al hiperplano que está definido por este vector. Como \(\boldsymbol{x}\) se encuentra en el lado \((-)\) del hiperplano y está mal clasificado, pertenece a la clase \(\omega_{1}\); asumiendo \(\mu = 1\), la corrección aplicada por el algoritmo es
\[ \boldsymbol{\theta}^{(i)}=\boldsymbol{\theta}^{(i-1)}+\boldsymbol{x}, \]y su efecto es girar el hiperplano en dirección a \(\boldsymbol{x}\) para colocarlo en el lado \((+)\) del nuevo hiperplano, que está definido por la estimación actualizada \(\boldsymbol{\theta^{(i)}}\). El algoritmo perceptrón en su modo de funcionamiento patrón por patrón (pattern-by-pattern) se resume en el siguiente algoritmo:
Algorithm 11.1 (Algoritmo perceptrón pattern-by-pattern)
Inicialización
Inicializar \(\boldsymbol{\theta}^{(0)}\); usualmente, de forma random, pequeño
Seleccionar \(\mu\); usualmente establecido como uno
\(i=1\)
Repeat Cada iteración corresponde a un epoch
counter = 0; Contador del número de actualizaciones por epoch
For \(n=1,2,\dots,N\) Do Para cada epoch, todas las muestras son presentadas una vez
If(\(y_{n}\boldsymbol{x}_{n}^{T}\leq0\)) Then
\(\boldsymbol{\theta}^{(i)}=\boldsymbol{\theta}^{(i-1)}+\mu y_{n}\boldsymbol{x}_{n}\)
\(i=i+1\)
counter = counter + 1
End For
Until counter = 0
Una vez que el algoritmo perceptrón se ha ejecutado y converge, tenemos los pesos, \(\theta_{i},~i = 1,2,\dots,l\), de las sinapsis de la neurona/perceptrón asociada, así como el término de sesgo \(\theta_{0}\). Ahora se pueden utilizar para clasificar patrones desconocidos. Las características \(x_{i}, i = 1, 2,\dots,l\), se aplican a los nodos de entrada. A su vez, cada característica se multiplica por la sinapsis respectiva (peso), y luego se añade el término de sesgo en su combinación lineal.
El resultado de esta operación pasa por una función no lineal, \(f\), conocida como función de activación (ver Activation function). Dependiendo de la forma de la no linealidad, se producen diferentes tipos de neuronas. La mas clásica conocida como neurona McCulloch-Pitts, la función de activación es la de Heaviside, es decir,
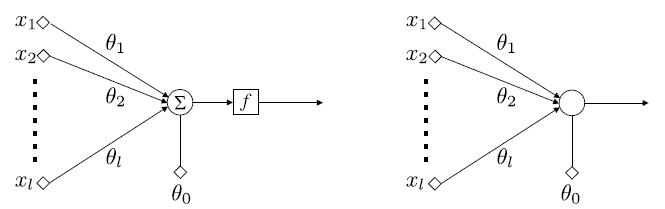
Fig. 11.6 Arquitectura básica de neuronas/perceptrones.#
En la arquitectura básica de neuronas/perceptrones, las características de entrada se aplican a los nodos de entrada y se ponderan por los respectivos pesos que definen las sinapsis. A continuación se añade el término de sesgo en su combinación lineal y el resultado es empujado a través de la no linealidad. En la neurona McCulloch-Pitts, la salida es 1 para los patrones de la clase \(\omega_{1}\) o 0 para la clase \(\omega_{2}\). La suma y la operación no lineal se unen para simplificar el gráfico.
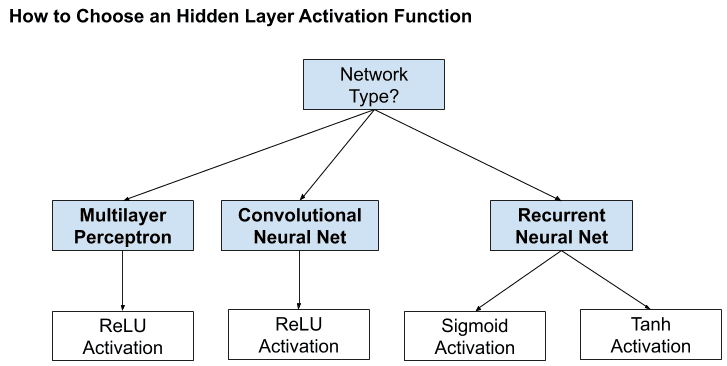
Para las capas ocultas (
input layer), la función de activación tangente hiperbólica suele funcionar mejor que la sigmoidea logística. Tanto la funciónsigmoidcomotanhpueden hacer que el modelo sea mássusceptible a los problemas durante el entrenamiento, a través del llamado problema de los gradientes desvanecientes. Los modelos modernos de redes neuronales con arquitecturas comunes, comoMLPyCNN, harán uso de la función de activaciónReLU, o extensiones.Las redes recurrentes suelen utilizar funciones de activación
tanhosigmoid, o incluso ambas. Por ejemplo, la LSTM suele utilizar la activaciónsigmoidpara las conexiones recurrentes y la activacióntanhpara la salida.
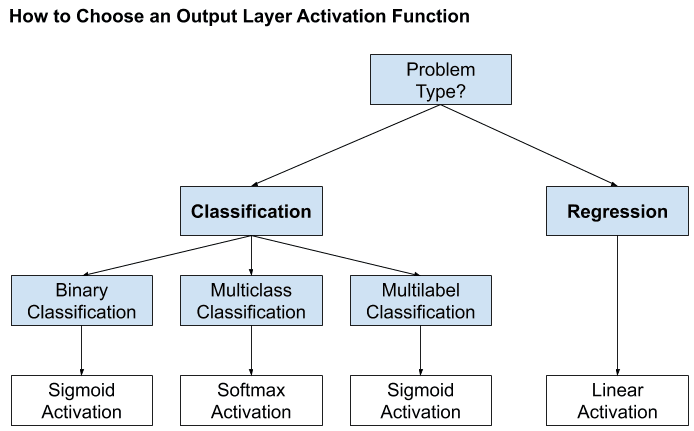
Fig. 11.8 Selección de función de activación para hidden layers. (Fuente [Brownlee and Mastery, 2017]).#
Si su problema es de regresión, debería utilizar una función de activación lineal en el
output layer. Si su problema es de clasificación, el modelo predice la probabilidad de pertenencia a una clase, que se puede convertir en una etiqueta de clase mediante redondeo (para sigmoid) oargmax(para softmax). Usualmente,softmaxes usada en clasificación múltiple cuando las clases son mutuamente excluyentes en caso contrario puede usar la función de activaciónsigmoidpara cada output.
11.4. Redes Totalmente Conectadas#
Para resumir de manera más formal el tipo de operaciones que tienen lugar en una red totalmente conectada, centrémonos en, por ejemplo, la capa \(r\) de una red neuronal multicapa y supongamos que está formada por \(k_{r}\) neuronas. El vector de entrada a esta capa está formado por las salidas de los nodos de la capa anterior, que se denomina \(\boldsymbol{y}^{r-1}\).
Sea \(\boldsymbol{\theta}_{j}^{r}\) el vector de los pesos sinápticos, incluido el término de sesgo, asociado a la neurona \(j\) de la capa \(r\), donde \(j = 1,2,\dots, k_{r}\). La dimensión respectiva de este vector es \(k_{r-1} + 1\), donde \(k_{r-1}\) es el número de neuronas de la capa anterior, \(r-1\), y el aumento en 1 representa el término de sesgo. Entonces las operaciones realizadas, antes de la no linealidad, son los productos internos
Colocando todos los valores de salida en un vector \(\boldsymbol{z}^{r}=[z_{1}^{r}, z_{2}^{r},\dots,z_{k_{r}}^{r}]^{T}\), y agrupando todos los vectores sinápticos como filas, una debajo de la otra, en una matriz, podemos escribir colectivamente
El vector de las salidas de la \(r\) th capa oculta, después de empujar cada \(z_{i}^{r}\) a través de la no linealidad \(f\), está finalmente dado por
La siguiente figura describe como es creada la \(j\)-ésima capa de la red neuronal full conectada
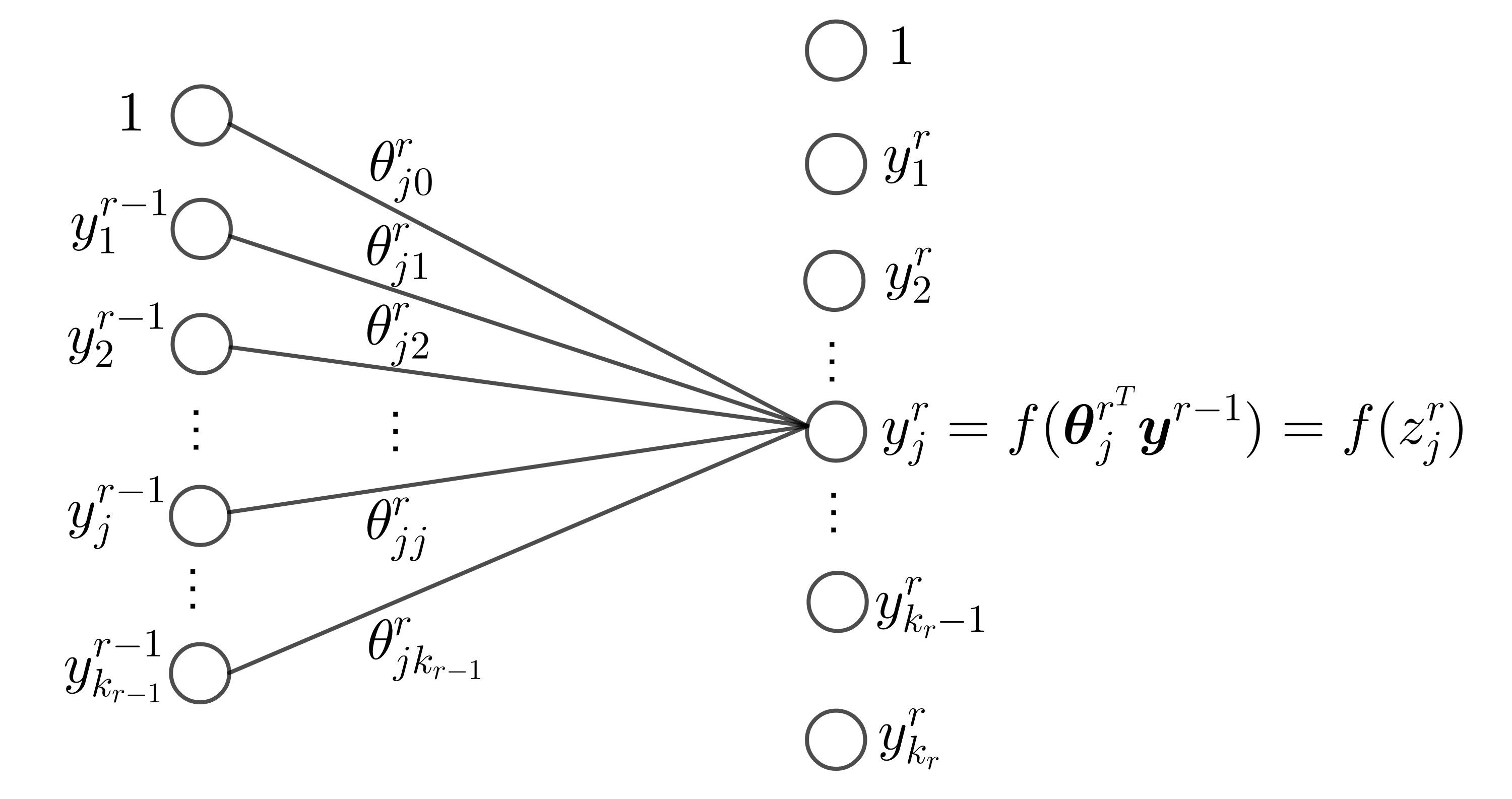
Fig. 11.9 \(j\)-ésimo elemento de la capa \(r\) de la red totalmente conectada.#
Observación
La notación anterior significa que \(f\) actúa sobre cada uno de los respectivos componentes del vector, individualmente, y la extensión del vector en uno es para dar cuenta de los términos de sesgo en la práctica estándar. Para redes grandes, con muchas capas y muchos nodos por capa, este tipo de conectividad resulta ser muy costoso en términos del número de parámetros (pesos), que es del orden de \(k_{r}k_{r-1}\).
Por ejemplo, si \(k_{r-1} = 1000\) y \(k_{r} = 1000\), esto equivale a un orden de 1 millón de parámetros. Tenga en cuenta que este número es la contribución de los parámetros de una sola de las capas. Sin embargo, un gran número de parámetros hace que una red sea vulnerable al sobreajuste, cuando se trata de entrenamiento
Las técnicas de reparto de pesos consisten en compartir un conjunto de parámetros entre varias conexiones mediante restricciones específicas. Las redes neuronales recurrentes y convolucionales aplican este principio; en estas últimas, las convoluciones reemplazan al producto interno, reduciendo significativamente el número de parámetros.
11.5. El Algoritmo De Backpropagation#
Una red neuronal considera una función paramétrica no lineal, \(\hat{y} = f_{\boldsymbol{\theta}}(\boldsymbol{x})\), donde \(\boldsymbol{\theta}\) representa todos los pesos/sesgo presentes en la red. Por lo tanto, el entrenamiento de una red neuronal no parece ser diferente del entrenamiento de cualquier otro modelo de predicción paramétrica.
Todo lo que se necesita es (a) un conjunto de muestras de entrenamiento, (b) una función de pérdida \(\mathcal{L}(y, \hat{y})\), y (c) un esquema iterativo, por ejemplo, el gradiente descendente, para realizar la optimización de la función de coste asociada (pérdida empírica).
La dificultad del entrenamiento de las redes neuronales radica en su estructura multicapa que complica el cálculo de los gradientes, que intervienen en la optimización. Además, la neurona McCulloch-Pitts se basa en la función de activación discontinua Heaviside no diferenciable.
Neurona sigmoidea logística: Una posibilidad es adoptar la función sigmoidea logística, es decir,
Nótese que cuanto mayor sea el valor del parámetro \(a\), la gráfica correspondiente se acerca más a la de la función de Heaviside (ver Fig. 11.10).
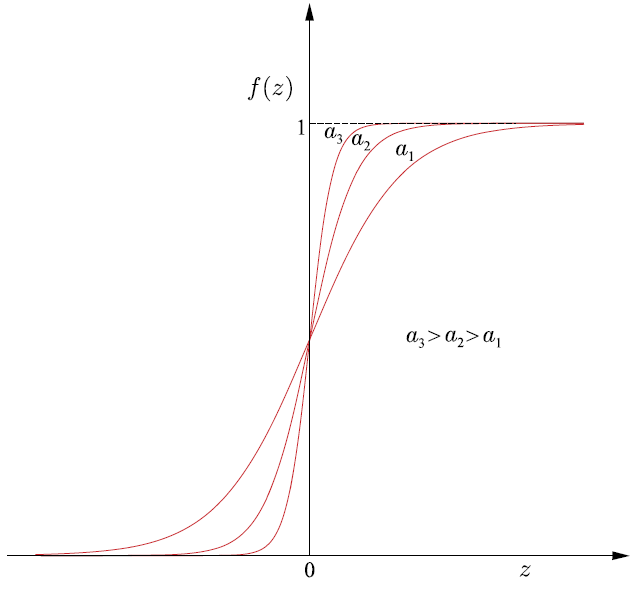
Fig. 11.10 Función sigmoidea logística para diferentes valores del parámetro \(a\).#
Otra posibilidad sería utilizar la función,
\[ f(z)=a\tanh\left(\frac{cz}{2}\right), \]donde \(c\) y \(a\) son parámetros de control. El gráfico de esta función se muestra en la Fig. 11.11. Nótese que a diferencia de la sigmoidea logística, esta es una función no simétrica, es decir, \(f(-z)=-f(z)\). Ambas son también conocidas como funciones de reducción, porque limitan la salida a un rango finito de valores.
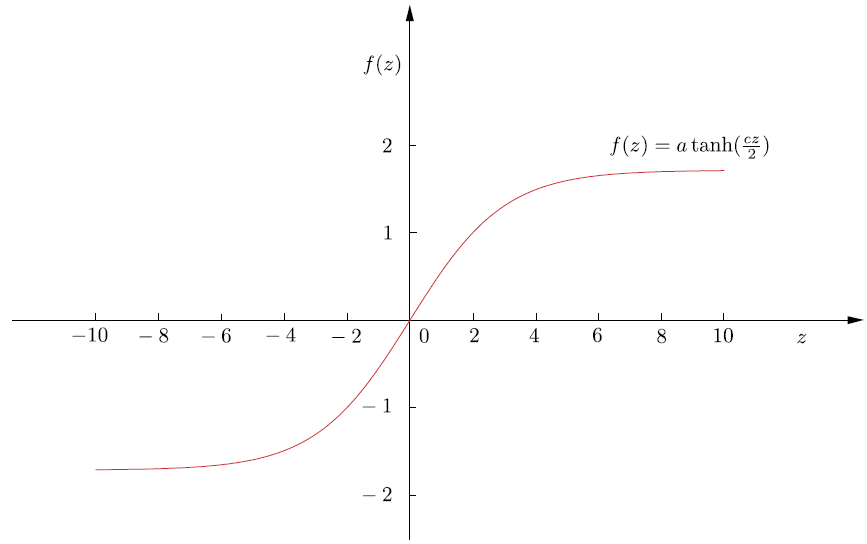
Fig. 11.11 Función de reducción de la tangente hiperbólica para \(a = 1.7\) y \(c = 4/3\).#
Recordemos que la regla de actualización del algoritmo gradiente descendente, en su versión unidimensional se convierte en
\[ \theta(new)=\theta(old)-\mu\left.\frac{d J}{d\theta}\right|_{\theta(old)}, \]y las iteraciones parten de un punto inicial arbitrario, \(\theta^{(0)}\).
Si en la iteración actual el algoritmo está digamos, en el punto \(\theta(old) = \theta_{1}\), entonces se moverá hacia el mínimo local, \(\theta_{l}\). Esto se debe a que la derivada del coste en \(\theta_{1}\) es igual a la tangente \(\phi_{1}\) (ver Fig. 11.12), que es negativa (el ángulo es obtuso) y la actualización, \(\theta(new)\), se moverá a la derecha, hacia el mínimo local, \(\theta_{l}\).
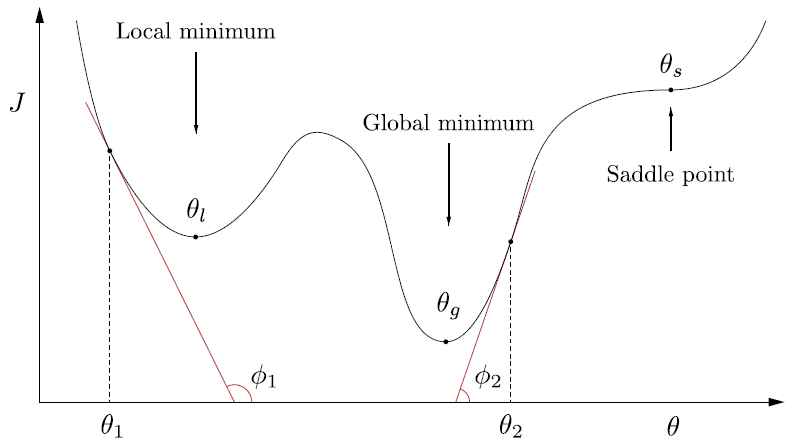
Fig. 11.12 Función no convexa global, con mínimos locales y puntos de silla.#
Observación
La elección del tamaño de paso \(\mu\) es clave para la convergencia. En espacios multidimensionales, abundan los mínimos locales, pero converger a uno profundo y cercano al mínimo global puede ser aceptable. Para evitarlos, pueden emplearse optimizadores como Adam, RMSprop o AdaGrad, explorar otras funciones de coste o aplicar regularización, ya que modelos muy complejos son más propensos a caer en mínimos locales.
11.6. El Esquema De Backpropagation Para Gradiente Descendente#
Habiendo adoptado una función de activación diferenciable, estamos listos para proceder a desarrollar el esquema iterativo de gradiente descendente para la minimización de la función de coste. Formularemos la tarea en un marco general.
Sea \((\boldsymbol{y}_{n}, \boldsymbol{x}_{n}), n = 1, 2,\dots, N\), el conjunto de muestras de entrenamiento. Nótese que hemos asumido múltiples variables output, como vectores. Suponemos que la red consta de \(L\) capas, \(L-1\) capas ocultas y una capa de salida. Cada capa consta de \(k_{r}, r = 1, 2,\dots, L\), neuronas. Así, los vectores de salida (objetivo/deseado) son
Para ciertas derivaciones matemáticas, también denotamos el número de nodos de entrada como \(k_{0}\); es decir, \(k_{0} = l\), donde \(l\) es la dimensionalidad del espacio de características de entrada.
Sea \(\boldsymbol{\theta}_{j}^{r}\) el vector de los pesos sinápticos asociados a la \(j\)-th neurona de la \(r\)-th capa, con \(j = 1, 2,\dots, k_{r}\) y \(r = 1, 2,\dots,L\), donde el término de sesgo se incluye en \(\boldsymbol{\theta}_{j}^{r}\), es decir,
Los pesos sinápticos en la capa \(r\) enlazan la neurona respectiva con todas las neuronas de la capa \(k_{r-1}\) (véase la Fig. 11.13). El paso iterativo básico para el esquema de gradiente descendente se escribe como
El parámetro \(\mu\) es el tamaño de paso definido por el usuario (también puede depender de la iteración) y \(J\) denota la función de coste.
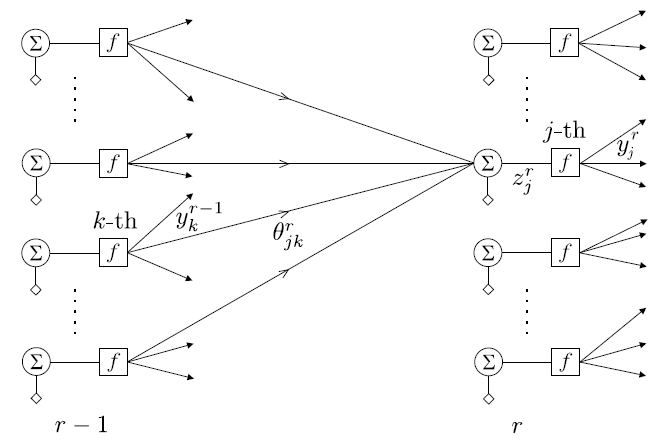
Fig. 11.13 Enlaces y las variables asociadas de la \(j\) th neurona en la \(r\) th capa. \(y_{k}^{r-1}\) es la salida de la \(k\) th neurona de la \((r - 1)\) th capa y \(\theta_{jk}^{r}\) es el peso respectivo que conecta estas dos neuronas.#
Las ecuaciones de actualización (11.3) comprenden el par del esquema de gradiente descendente para la optimización. Como se ha dicho anteriormente, la dificultad de las redes neuronales feed-forward surge de su estructura multicapa. Para calcular los gradientes en la Ecuación (11.3), para todas las neuronas, en todas las capas, se deben seguir dos pasos en su cálculo
Forward computations: Para un vector de entrada dado \(\boldsymbol{x}_{n}, n = 1, 2,\dots, N\), se utilizan las estimaciones actuales de los parámetros (pesos sinápticos) (\(\boldsymbol{\theta}_{j}^{r}(old)\)) y calcula todas las salidas de todas las neuronas en todas las capas, denotadas como \(y_{nj}^{r}\); en la Fig. 11.13, se ha suprimido el índice \(n\) para no afectar la notación.Backward computations: Utilizando las salidas neuronales calculadas anteriormente junto con los valores objetivos conocidos, \(y_{nk}\), de la capa de salida, se calculan los gradientes de la función de coste. Esto implica \(L\) pasos, es decir, tantos como el número de capas. La secuencia de los pasos algorítmicos se indica a continuación:Calcular el gradiente de la función de coste con respecto a los parámetros de las neuronas de la última capa, es decir, \(\partial J/\partial\boldsymbol{\theta}_{j}^{L}, j = 1, 2,\dots, k_{L}\).
For \(r = L-1\) to \(1\), Do
Calcular los gradientes con respecto a los parámetros asociados a las neuronas de la \(r\) th capa, es decir, \(\partial J/\partial\boldsymbol{\theta}_{k}^{r}, k= 1, 2,\dots, k_{r}\) basado en todos los gradientes \(\partial J/\partial\boldsymbol{\theta}_{j}^{r+1}, j= 1, 2,\dots, k_{r+1}\), con respecto a los parámetros de la capa \(r + 1\) que se han calculado en el paso anterior.
End For
Ejemplo
Analicemos un ejemplo concreto de forward computations, seguido de un enfoque backward computations. El ejemplo de entrenamiento será (\(x=2.1\), \(y=4\)), el peso inicial será \(w:=\theta_{1}=1\), el sesgo será \(b:=\theta_{0}=0\) y \(\textsf{Loss}=L\). \(\hat{y}\) representa la salida de la neurona y el valor predicho, mientras que la pérdida se refiere a la pérdida por error cuadrático
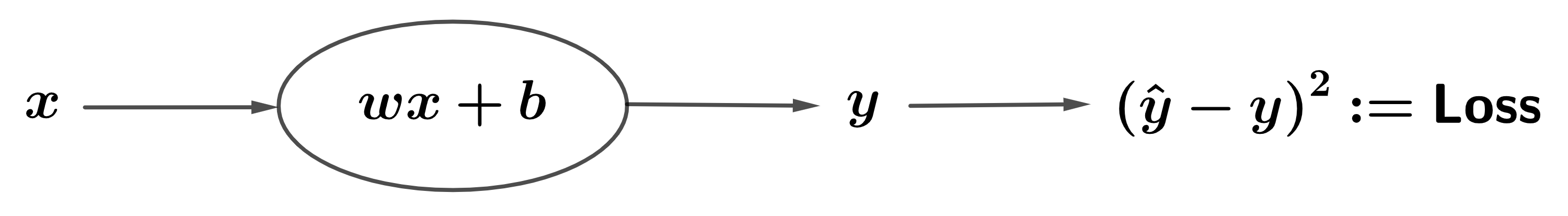
Fig. 11.14 Ejemplo de red neuronal para backpropagation#
Forward computaion:

Backward computation: Ahora podemos retroceder (backpropagation) y calcular las derivadas parciales aplicando la regla de la cadena para obtener
Luego, actualizamos los parámetros en la dirección opuesta al gradiente para disminuir la pérdida, con una tasa de aprendizaje de \(\textsf{lr}:=\mu=0.01\)
Para evaluar el rendimiento de nuestros parámetros ajustados, realizaremos una pasada adicional
La pérdida total disminuyó de 3.61 a 2.87, lo que representa una reducción de 0.74. ¡La pérdida ha bajado!
11.7. Entrenamiento de MLP#
Observación
Los pesos de una red neuronal se ajustan mediante algoritmos de optimización basados en gradiente, como el gradiente descendente estocástico, que minimiza iterativamente la función de pérdida \(L\). Para tareas de regresión, se emplean el error cuadrático medio (MSE) y el error absoluto medio (MAE); para clasificación, se utilizan pérdidas logarítmicas binarias o categóricas.
El algoritmo backpropagation se comprende a través de grafos computacionales, útiles para calcular en redes neuronales. En una red simple con una capa oculta de dos neuronas con activación sigmoidea y salida lineal, alimentada por dos entradas \([y_1, y_2]\), los pesos se distribuyen en los bordes de la red.
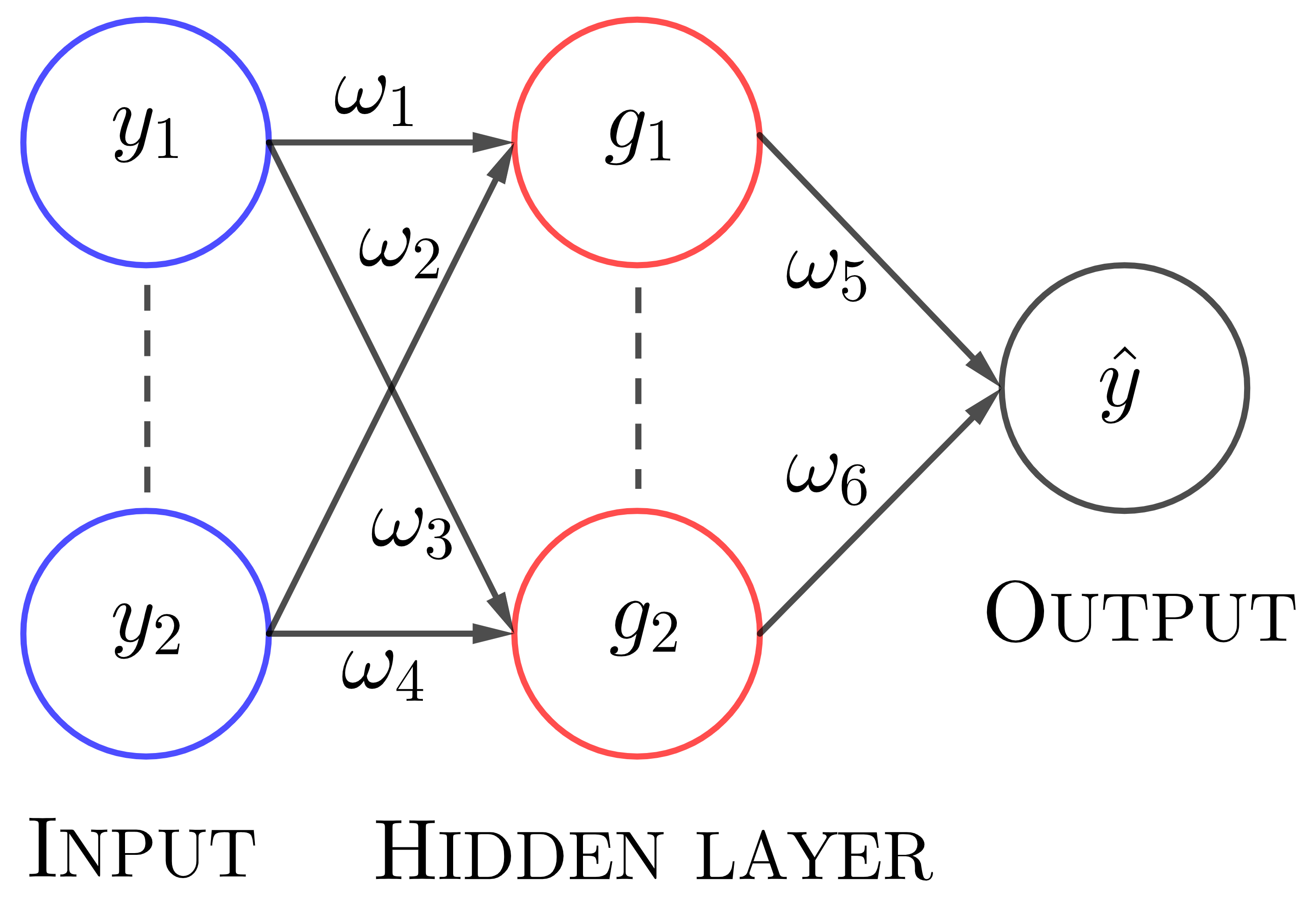
La Fig. 11.16 ilustra este proceso mediante un grafo computacional para la entrada \([-1, 2]\), generando salidas intermedias \(p_i\). En particular, \(p_7\) y \(p_8\) corresponden a las salidas de las neuronas ocultas \(g_1\) y \(g_2\). Durante este paso también se calcula la función de pérdida \(L\) usada en el entrenamiento.
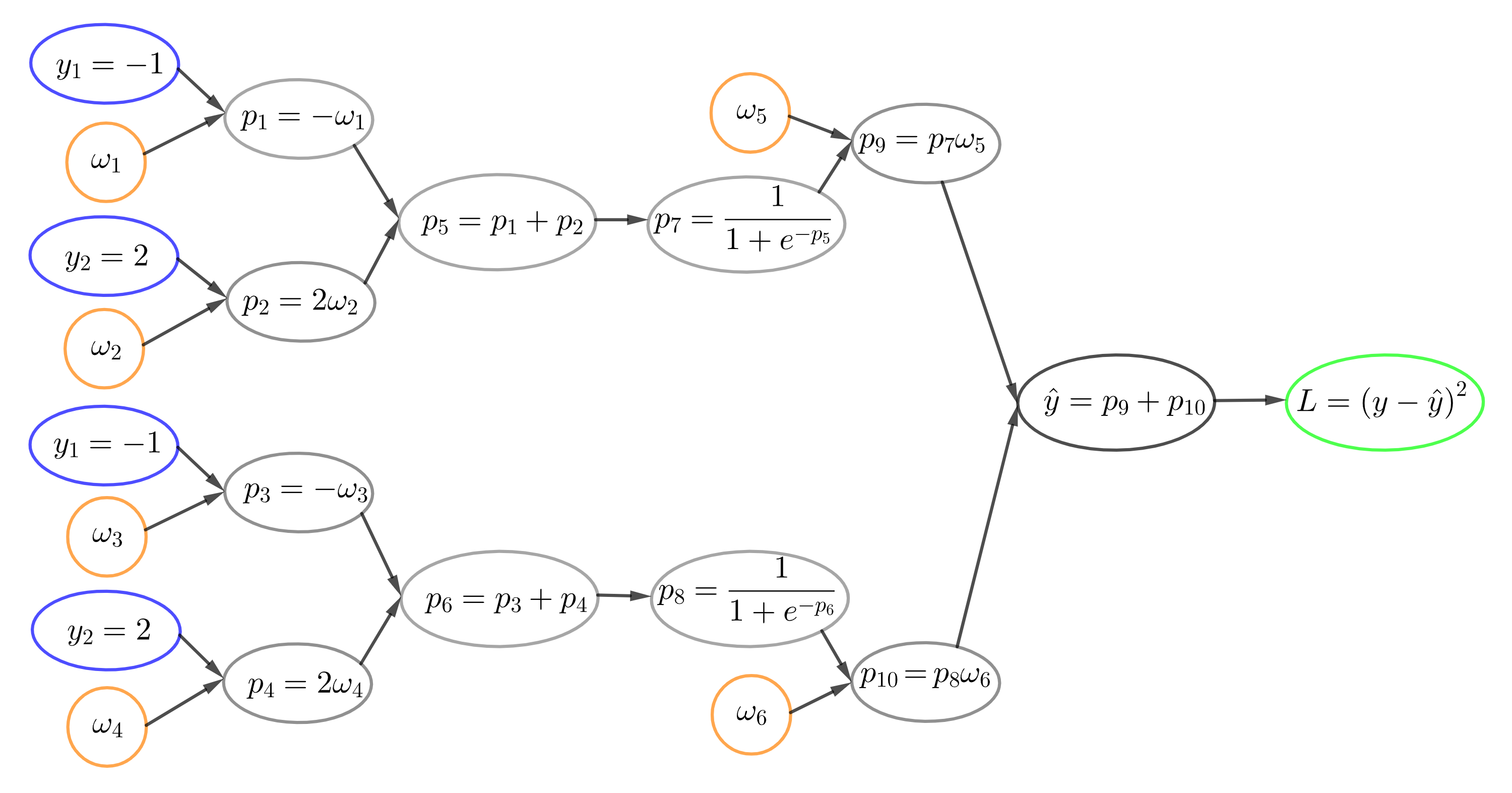
En el backpropagation, el recorrido inverso del grafo (backward pass) calcula las derivadas parciales entre nodos conectados. Siguiendo la regla de la cadena, la derivada de la pérdida respecto a un peso es el producto de las derivadas a lo largo de cada camino que los une, y si hay varios caminos, se suman. Este enfoque gráfico sustenta las bibliotecas modernas de deep learning para implementar los pasos forward y backward (ver Fig. 11.17)
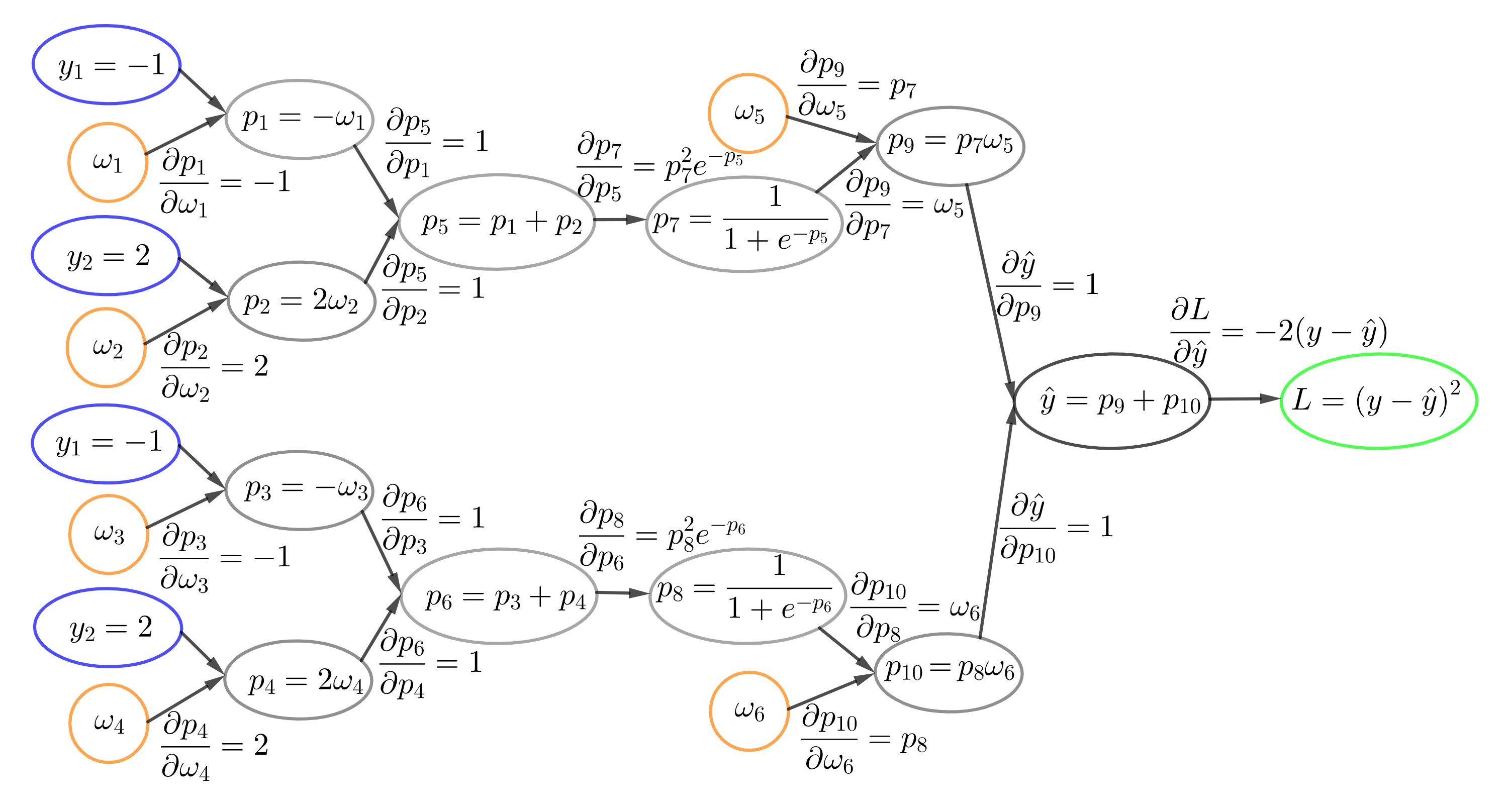
Las derivadas parciales de la función de pérdida con respecto a los pesos se obtienen aplicando la regla de la cadena:
Durante el entrenamiento, los pesos suelen inicializarse aleatoriamente, ya sea con una distribución uniforme en un rango como \([-1, 1]\) o con una distribución normal de media cero y varianza unitaria, existiendo variantes que aceleran la convergencia.
En este ejemplo, se asume inicialización uniforme, obteniendo: \(w_1 = -0.33,\; w_2 = -0.33,\; w_3 = 0.57,\; w_4 = -0.01,\; w_5 = 0.07,\; w_6 = 0.82\). Con estos valores, se realizan los pasos forward y backward sobre el grafo computacional, mostrando en azul los resultados del forward y en rojo los gradientes del backward. El valor real de la variable objetivo se fija en \(y = 1\).
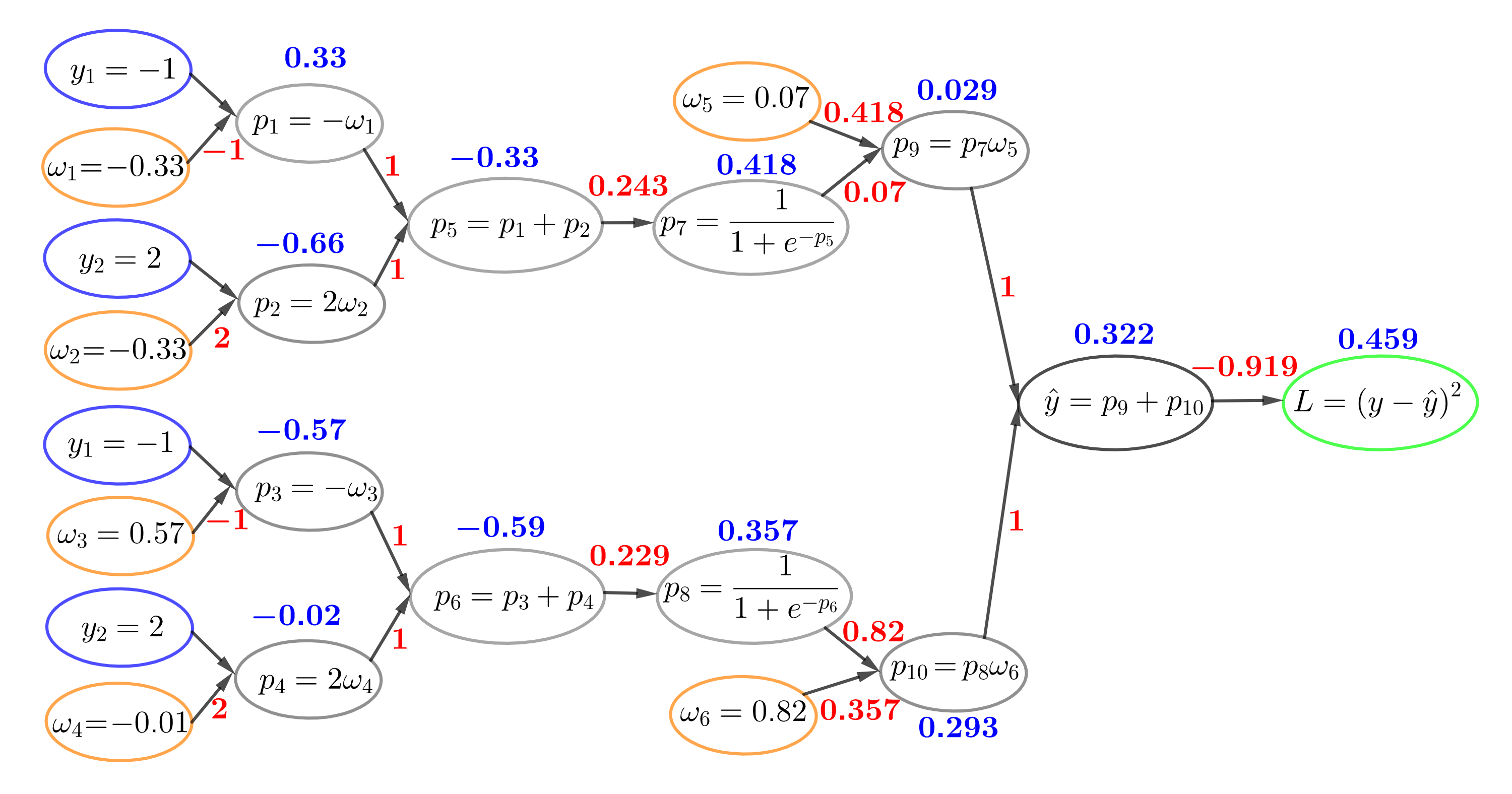
Una vez calculados los gradientes a lo largo de las aristas, las derivadas parciales con respecto a los pesos no son más que una aplicación de la regla de la cadena, de la que ya hemos hablado. Los valores de las derivadas parciales son los siguientes:
El siguiente paso es actualizar los pesos mediante gradiente descendente. Con tasa de aprendizaje \(\alpha = 0.01\):
El resto de pesos se actualizan con la misma fórmula. Este proceso se repite varias veces; el número de actualizaciones se denomina número de épocas. Generalmente, un criterio de tolerancia sobre el cambio en la función de pérdida controla cuándo detener el entrenamiento.
Para determinar los pesos, se combina backpropagation con un optimizador basado en gradiente. Bibliotecas como TensorFlow, Theano o CNTK implementan gráficos computacionales que entrenan redes neuronales de cualquier arquitectura, ejecutando operaciones matriciales y aprovechando GPU para acelerar el cálculo.
Observación
El backpropagation aplica la regla de la cadena para derivadas, comenzando por la última capa (salida), donde el cálculo del gradiente es directo: es la derivada de la función de pérdida respecto a la salida, sin depender de capas posteriores. Luego, el algoritmo retrocede capa por capa, propagando gradientes a través de funciones anidadas hasta las capas iniciales.
En efecto, centrémonos en la salida \(y_{k}^{r}\) de la neurona \(k\) en la capa \(r\). Entonces tenemos
\[ y_{k}^{r}=f(\boldsymbol{\theta}_{k}^{r^T}\boldsymbol{y}^{r-1}),\quad k=1,2,\dots, k_{r}, \]donde \(\boldsymbol{y}^{r-1}\) es el vector (ampliado) que comprende todas las salidas de la capa anterior, \(r-1\), y \(f\) denota la no-linealidad.
De acuerdo con lo anterior, la salida de la \(j\)-th neurona en la siguiente capa viene dada por
\[\begin{split} y_{j}^{r+1}=f(\boldsymbol{\theta}_{j}^{r+1^T}\boldsymbol{y}^{r})= f\left(\boldsymbol{\theta}_{j}^{r+1^{T}} \begin{bmatrix} 1\\ f(\Theta^{r}\boldsymbol{y}^{r-1}) \end{bmatrix} \right)= f\left(\boldsymbol{\theta}_{j}^{r+1^{T}} \begin{bmatrix} 1\\ f(\boldsymbol{y}^{r}) \end{bmatrix} \right), \end{split}\]donde \(\Theta^{r}:=[\boldsymbol{\theta}_{1}^{r}, \boldsymbol{\theta}_{2}^{r},\dots,\boldsymbol{\theta}_{k_{r}}]^{T}\) denota la matriz cuyas columnas corresponden al vector de pesos en el layer \(r\).
Nótese que obtuvimos evaluación de “una función interna bajo una función externa”. Claramente, esto continúa a medida que avanzamos en la jerarquía. Esta estructura de evaluación de funciones internas por funciones externas, es el subproducto de la naturaleza multicapa de las redes neuronales, la cual es una operación altamente no lineal, que da lugar a la dificultad de calcular los gradientes, a diferencia de otros modelos, como por ejemplo SVM.
Sin embargo, se puede observar fácilmente que el cálculo de los gradientes con respecto a los parámetros que definen la
capa de salidano plantea ninguna dificultad. En efecto, la salida de la \(j\)-th neurona de la última capa (que es en realidad la respectiva estimación de salida actual) se escribe como:
Dado que \(\boldsymbol{y}^{L-1}\) es conocido, después de los cálculos durante el paso adelante (
forward computaion), tomando la derivada con respecto a \(\boldsymbol{\theta}_{j}^{L}\) es sencillo; no hay ninguna operación de función sobre función. Por esto es que empezamos por la capa superior y luego nos movemos hacia atrás. Debido a su importancia histórica, se dará la derivación completa del algoritmo backpropagation.
Para la derivación detallada del algoritmo backpropagation, se adopta como ejemplo la función de pérdida del error cuadrático, es decir
(11.4)#\[ J(\boldsymbol{\theta})=\sum_{n=1}^{N}J_{n}(\boldsymbol{\theta})\quad\text{y}\quad J_{n}(\boldsymbol{\theta})=\frac{1}{2}\sum_{k=1}^{k_{L}}(\hat{y}_{nk}-y_{nk})^{2}, \]donde \(\hat{y}_{nk},~k=1,2,\dots,k_{L}\), son las estimaciones proporcionadas en los correspondientes nodos de salida de la red. Las consideraremos como los elementos de un vector correspondiente, \(\hat{\boldsymbol{y}}_{n}\).
11.8. Cálculo de gradientes#
Sea \(z_{nj}^{r}\) la salida del combinador lineal de la \(j\)-th neurona en la capa \(r\) en el instante de tiempo \(n\), cuando se aplica el patrón \(\boldsymbol{x}_{n}\) en los nodos de entrada (véase la Fig. 11.13). Entonces, para \(n, j\) fijos, podemos escribir
(11.5)#\[ z_{nj}^{r}=\sum_{m=1}^{k_{r-1}}\theta_{jm}^{r}y_{nm}^{r-1}+\theta_{j0}^{r}=\sum_{m=0}^{k_{r-1}}\theta_{jm}^{r}y_{nm}^{r-1}=\boldsymbol{\theta}_{j}^{r^{T}}\boldsymbol{y}_{n}^{r-1}, \]donde por definición
\[ \boldsymbol{y}_{n}^{r-1}:=[1, y_{n1}^{r-1},\dots, y_{nk_{r-1}}^{r-1}]^{T}, \]y \(y_{n0}^{r}\equiv 1,~\forall~r, n\) y \(\theta_{j}^{r}\) ha sido definido en la Ecuación (11.2).
Para las neuronas de la capa de salida \(r=L,~y_{nm}^{L}=\hat{y}_{nm},~m=1,2,\dots, k_{L}\), y para \(r=1\), tenemos \(y_{nm}^{1}=x_{nm},~m=1,2,\dots, k_{1}\); esto es, \(y_{nm}^{1}\) se fija igual a los valores de las características de entrada.
Por lo tanto, teniendo en cuenta que \(z_{j}^{r}=\boldsymbol{\theta}_{j}^{rT}\boldsymbol{y}^{r-1},~j=1,2,\dots,k_{r}\) y \(\hat{y}_{j}:=y_{j}^{r}=f(\boldsymbol{\theta}_{j}^{r^{T}}\boldsymbol{y}^{r-1})=f(z_{j}^{r})\), con base en la Ecuación (11.4) podemos escribir las derivadas parciales
Definamos
Entonces la Ecuación (11.3) puede escribirse como
11.9. Cálculo de \(\delta_{nj}^{r}\)#
Este es el cálculo principal del algoritmo backpropagation. Para el cálculo de los gradientes, \(\delta_{nj}^{r}\), se comienza en la última capa, \(r = L\), y se procede hacia atrás, hacia \(r = 1\); esta “filosofía” justifica el nombre dado al algoritmo.
\(r=L\): Tenemos que
\[ \delta_{nj}^{L}:=\frac{\partial J_{n}}{\partial z_{nj}^{L}}. \]Para la función de pérdida del error al cuadrado,
\[ J_{n}=\frac{1}{2}\sum_{k=1}^{k_{L}}\left(\hat{y}_{nk}-y_{nk}\right)^{2}=\frac{1}{2}\sum_{k=1}^{k_{L}}\left(f(z_{nk}^{L})-y_{nk}\right)^{2}. \]Por lo tanto,
(11.7)#\[\begin{split} \begin{align*} \delta_{nj}^{L}=\frac{\partial}{\partial z_{nj}^{L}}\left(\frac{1}{2}\sum_{k=1}^{k_{L}}\left(f(z_{nk}^{L})-y_{nk}\right)^{2}\right)&=(f(z_{nj}^{L})-y_{nj})f'(z_{nj}^{L})\\ &=(\hat{y}_{nj}-y_{nj})f'(z_{nj}^{L})=e_{nj}f'(z_{nj}^{L}), \end{align*} \end{split}\]donde \(j=1,2,\dots, k_{L}\), \(f'\) denota la derivada de \(f\) y \(e_{nj}\) es el error asociado con el \(j\)-th output en el tiempo \(n\). Nótese que para el último layer, el cálculo del gradiente, \(\delta_{nj}^{L}\) es sencillo.
\(r<L\): Debido a la dependencia sucesiva entre las capas, el valor de \(z_{nj}^{r-1}\) influye en todos los valores \(z_{nk}^{r},~k = 1, 2,\dots, k_{r}\), de la capa siguiente. Empleando la regla de la cadena para la diferenciación, obtenemos, para \(r=L, L-1,\dots, 2\):
(11.8)#\[ \delta_{nj}^{r-1}=\frac{\partial J_{n}}{\partial z_{nj}^{r-1}}=\sum_{k=1}^{k_{r}}\frac{\partial J_{n}}{\partial z_{nk}^{r}}\frac{\partial z_{nk}^{r}}{\partial z_{nj}^{r-1}}, \]o
(11.9)#\[ \delta_{nj}^{r-1}=\sum_{k=1}^{k_{r}}\delta_{nk}^{r}\frac{\partial z_{nk}^{r}}{\partial z_{nj}^{r-1}}. \]Además, usando la Ecuación (11.5) se tiene,
\[ \frac{\partial z_{nk}^{r}}{\partial z_{nj}^{r-1}}=\frac{\partial}{\partial z_{nj}^{r-1}}\left(\sum_{m=0}^{k_{r-1}}\theta_{km}^{r}y_{nm}^{r-1}\right), \]donde \(\textcolor{blue}{y_{nm}^{r-1}=f(z_{nm}^{r-1})}=f(\boldsymbol{\theta}_{m}^{r-1^{T}}\boldsymbol{y}_{n}^{r-2})\). Entonces,
\[ \frac{\partial z_{nk}^{r}}{\partial z_{nj}^{r-1}}=\theta_{kj}^{r}f'(z_{nj}^{r-1}), \]y combinando las Ecuaciones (11.8) y (11.9), obtenemos la regla recursiva
\[ \delta_{nj}^{r-1}=\left(\sum_{k=1}^{k_{r}}\delta_{nk}^{r}\theta_{kj}^{r}\right)f'(z_{nj}^{r-1}). \]
Manteniendo la misma notación en la Ecuación (11.7), definimos
\[ e_{nj}^{r-1}:=\sum_{k=1}^{k_{r}}\delta_{nk}^{r}\theta_{kj}^{r}, \]y finalmente obtenemos,
(11.10)#\[ \delta_{nj}^{r-1}=e_{nj}^{r-1}f'(z_{nj}^{r-1}). \]
El único cálculo que queda es la derivada de \(f\). Para el caso de la función sigmoidea logística se demuestra fácilmente que es igual a (
verifíquelo)
La derivación se ha completado y el esquema backpropagation neural network se resume en el siguiente algoritmo
Algorithm 11.2 (Algoritmo Backpropagation Gradiente Descendente)
Inicialización
Inicializar todos los pesos y sesgos sinápticos al azar con valores pequeños, pero no muy pequeños.
Seleccione el tamaño del paso \(\mu\).
Fije \(y_{nj}^{1}=x_{nj},\quad j=1,2,\dots,k_{1}:=l,\quad n=1,2,\dots,N\)
Repeat Cada repetición completa un epoch
For \(n=1,2,\dots,N\) Do
For \(r=1,2,\dots,L\) Do Cálculo Forward
For \(j=1,2,\dots,k_{r}\) Do
Calcule \(z_{nj}^{r}\) a partir de la Ecuación (11.5) Calcule \(y_{nj}^{r}=f(z_{nj}^{r})\)
End For
End For
For \(j = 1, 2,\dots, k_{L}\), Do; Cálculo Backward (output layer)
Calcule \(\delta_{nj}^{L}\) a partir de la Ecuación (11.10)
End For
For \(r=L, L-1,\dots, 2\), Do; Cálculo Backward (hidden layers)
For \(j=1,2,\dots, k_{r}\), Do
Calcule \(\delta_{nj}^{r-1}\) a partir de la Ecuación (11.10)
End For
End For
End For
For \(r=1,2,\dots,L\), Do: Actualice los pesos
For \(j=1,2,\dots,k_{r}\), Do
Calcule \(\Delta\boldsymbol{\theta}_{j}^{r}\) a partir de la Ecuación (11.6)
\(\boldsymbol{\theta}_{j}^{r}=\boldsymbol{\theta}_{j}^{r}+\Delta\boldsymbol{\theta}_{j}^{r}\)
End For
End For
Until Un criterio de parada se cumpla.
El algoritmo de backpropagation puede reivindicar una serie de padres. La popularización del algoritmo se asocia con el artículo clásico [Rumelhart et al., 1986], donde se proporciona la derivación del algoritmo. La idea de backpropagation también aparece en [Bryson Jr et al., 1963] en el contexto del control óptimo.
Existen diferentes variaciones del algoritmo backpropagation, tales como: Gradiende descendente con término de momento, Algoritmo de momentos de Nesterov’s, Algoritmo AdaGrad, RMSProp con momento de Nesterov, Algortimo de estimación de momentos adaptativo los cuales pueden ser utlizados para resolver la tarea de optimización (ver [Theodoridis, 2020]).
11.10. Tuning de Redes Neuronales#
Profundizaremos en la mecánica del Perceptrón Multicapa (MLP) empleando el
MLPClassifier()en el conjunto de datostwo_moonsque se utilizó anteriormente en esta sección
from sklearn.neural_network import MLPClassifier
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
import mglearn
import matplotlib.pyplot as plt
X, y = make_moons(n_samples=100, noise=0.25, random_state=3)
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, random_state=42)
mlp = MLPClassifier(solver='adam', random_state=0, max_iter=10000).fit(X_train, y_train)
adamOptimizer:adames un acrónimo de Adaptive Moment Estimation y es uno de los algoritmos de optimización más populares y efectivos utilizados en el entrenamiento de redes neuronales (ver [Kingma and Ba, 2014]). Es una variante avanzada del gradiente descendente que combina las ideas de los métodos de momentum y RMSProp para adaptarse mejor a diferentes problemas de optimización.
Características de Adam
Adaptative Learning Rate: Calcula tasas de aprendizaje adaptativas para cada parámetro utilizando estimaciones de primer y segundo orden de los momentos (media y varianza) de los gradientes.
Momentum:Utiliza el concepto de momentum para acumular una media móvil exponencial de los gradientes pasados (primer momento) y una media móvil exponencial de los cuadrados de los gradientes pasados (segundo momento).
mglearn.plots.plot_2d_separator(mlp, X_train, fill=True, alpha=.3)
mglearn.discrete_scatter(X_train[:, 0], X_train[:, 1], y_train)
plt.xlabel("Feature 0");
plt.ylabel("Feature 1");

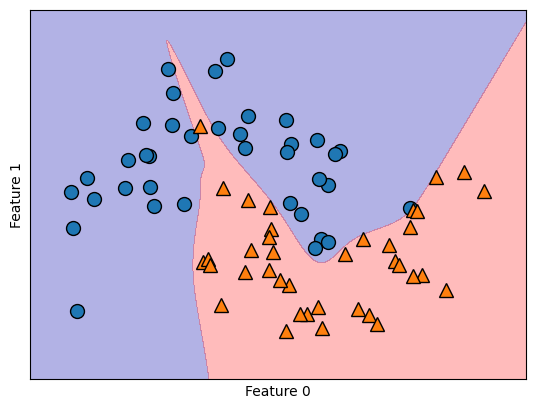
Evidentemente, la red neuronal ha adquirido un límite de decisión decisivamente no lineal pero relativamente gradual
mlp = MLPClassifier(solver='lbfgs', random_state=0, max_iter=400, hidden_layer_sizes=[10])
Se empleó el algoritmo
'lbfgs'(ver Broyden–Fletcher–Goldfarb–Shanno algorithm (L-BFGS), optimizador de la familia de los métodos cuasi-Newton.). En particular, el MLP emplea 100 nodos ocultos por defecto, un número considerable para este conjunto de datos compacto. Sin embargo, incluso con un número reducido de nodos, se puede lograr un resultado satisfactorio
Optimizador L-BFGS
L-BFGS es una variante del algoritmo BFGS, que es un método de optimización de segundo orden. A diferencia de los métodos de primer orden, que utilizan únicamente el gradiente de la función de pérdida, los métodos de segundo orden también utilizan la información de la segunda derivada (la matriz Hessiana) para mejorar la dirección de los pasos de actualización. L-BFGS ajusta internamente las tasas de aprendizaje basadas en la información de segundo orden.
mlp.fit(X_train, y_train)
MLPClassifier(hidden_layer_sizes=[10], max_iter=400, random_state=0,
solver='lbfgs')In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
MLPClassifier(hidden_layer_sizes=[10], max_iter=400, random_state=0,
solver='lbfgs')mglearn.plots.plot_2d_separator(mlp, X_train, fill=True, alpha=.3)
mglearn.discrete_scatter(X_train[:, 0], X_train[:, 1], y_train)
plt.xlabel("Feature 0");
plt.ylabel("Feature 1");
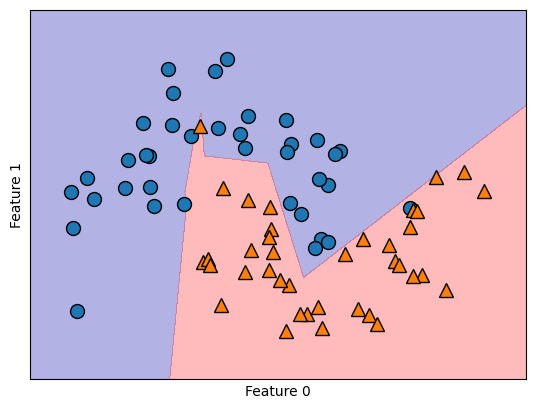
Al reducir las unidades ocultas a 10 hace que el límite de decisión tenga un aspecto algo irregular. La no linealidad por defecto empleada es la
"relu"
import numpy as np
line = np.linspace(-3, 3, 100)
plt.plot(line, np.tanh(line), label="tanh")
plt.plot(line, np.maximum(line, 0), label="relu")
plt.legend(loc="best")
plt.xlabel("x")
plt.ylabel("relu(x), tanh(x)");
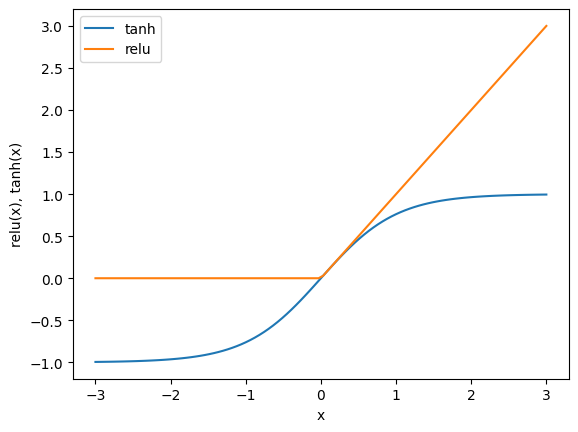
En el caso de una sola capa oculta, esto implica que la función de decisión comprende 10 segmentos de línea recta. Para conseguir un límite de decisión más gradual, las alternativas incluyen aumentar las unidades ocultas, introducir una segunda capa oculta o emplear la no linealidad
"tanh".
Utilizando dos capas ocultas, con 10 unidades cada una
mlp = MLPClassifier(solver='lbfgs', random_state=0, hidden_layer_sizes=[10, 10])
mlp.fit(X_train, y_train)
MLPClassifier(hidden_layer_sizes=[10, 10], random_state=0, solver='lbfgs')In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
MLPClassifier(hidden_layer_sizes=[10, 10], random_state=0, solver='lbfgs')
mglearn.plots.plot_2d_separator(mlp, X_train, fill=True, alpha=.3)
mglearn.discrete_scatter(X_train[:, 0], X_train[:, 1], y_train)
plt.xlabel("Feature 0")
plt.ylabel("Feature 1");
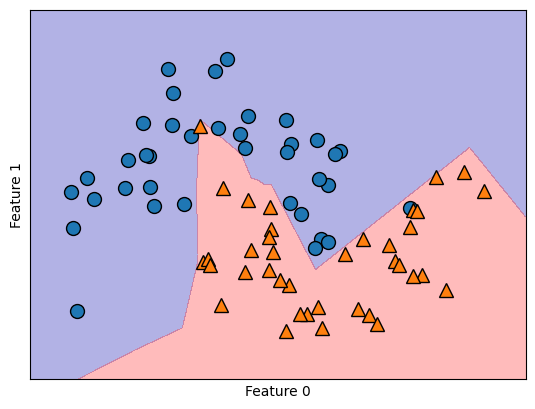
mlp = MLPClassifier(solver='lbfgs', activation='tanh', max_iter=400, random_state=0, hidden_layer_sizes=[10, 10])
mlp.fit(X_train, y_train)
MLPClassifier(activation='tanh', hidden_layer_sizes=[10, 10], max_iter=400,
random_state=0, solver='lbfgs')In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
MLPClassifier(activation='tanh', hidden_layer_sizes=[10, 10], max_iter=400,
random_state=0, solver='lbfgs')mglearn.plots.plot_2d_separator(mlp, X_train, fill=True, alpha=.3)
mglearn.discrete_scatter(X_train[:, 0], X_train[:, 1], y_train)
plt.xlabel("Feature 0")
plt.ylabel("Feature 1");
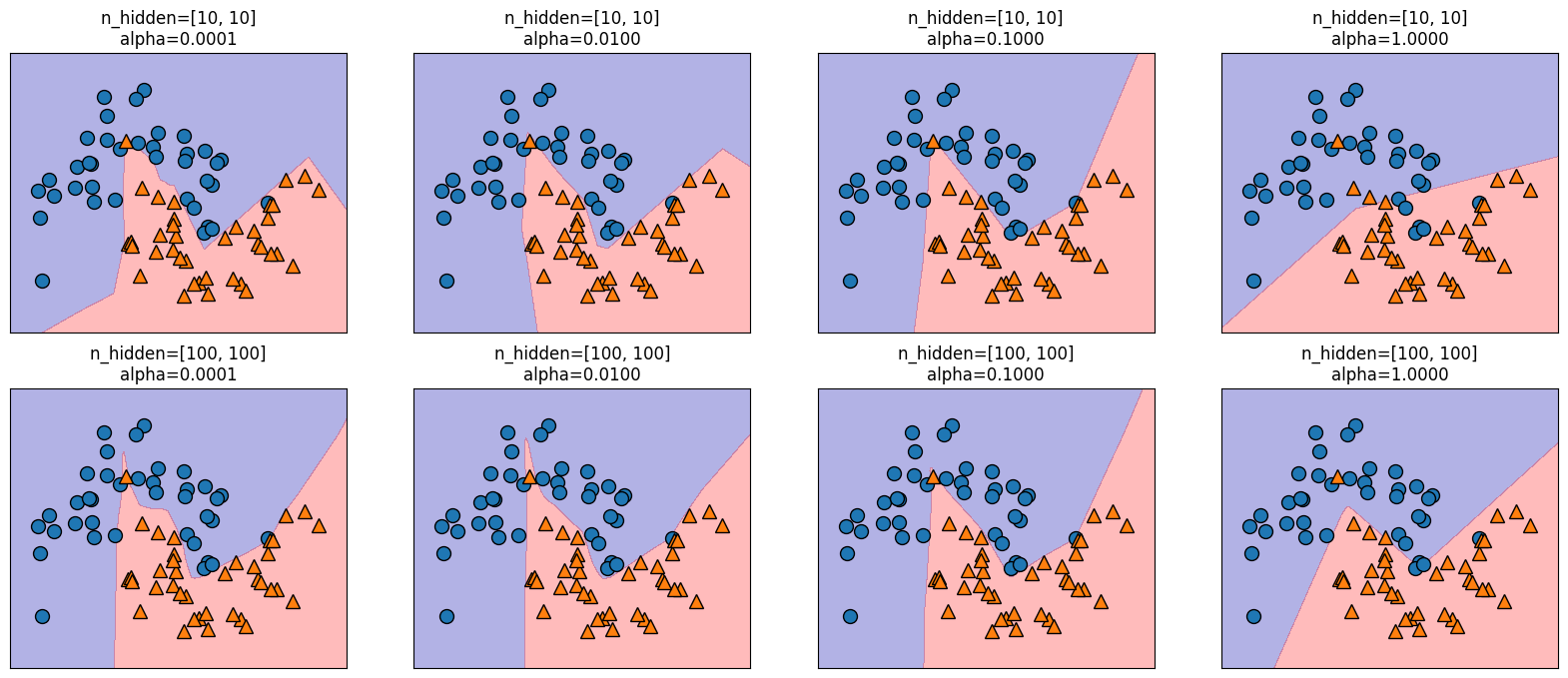
Además, podemos influir en la complejidad de una red neuronal incorporando una penalización \(L2\), similar al enfoque de la regresión de ridge y los clasificadores lineales. El parámetro responsable de esto en el
MLPClassifieres'alpha', análogo a los modelos de regresión lineal. Por defecto, asume un valor mínimo (regularización limitada). El siguiente experimento incluye dos capas ocultas, cada una de ellas compuesta por 10 o 100 unidades y diferentes valores dealpha
fig, axes = plt.subplots(2, 4, figsize=(20, 8))
for axx, n_hidden_nodes in zip(axes, [10, 100]):
for ax, alpha in zip(axx, [0.0001, 0.01, 0.1, 1]):
mlp = MLPClassifier(solver='lbfgs', random_state=0, max_iter=1000, hidden_layer_sizes=[n_hidden_nodes, n_hidden_nodes], alpha=alpha)
mlp.fit(X_train, y_train)
mglearn.plots.plot_2d_separator(mlp, X_train, fill=True, alpha=.3, ax=ax)
mglearn.discrete_scatter(X_train[:, 0], X_train[:, 1], y_train, ax=ax)
ax.set_title("n_hidden=[{}, {}]\nalpha={:.4f}".format(n_hidden_nodes, n_hidden_nodes, alpha))
Observación
Como habrá podido comprobar, existen multitud de métodos para gestionar la complejidad de una red neuronal, como el número de capas ocultas, las unidades en cada capa oculta y la regularización (
alpha), entre otros. Un rasgo fundamental de las redes neuronales reside en suconfiguración aleatoria inicial de pesos antes de comenzar el aprendizaje.Esta aleatoriedad influye en el modelo aprendido resultante. Así, el empleo de parámetros idénticos puede dar lugar a modelos distintos debido a semillas aleatorias diferentes. Mientras que este efecto es más pronunciado para redes pequeñas, es menos significativo para redes de tamaño adecuado donde la complejidad se elige apropiadamente.
fig, axes = plt.subplots(2, 4, figsize=(20, 8))
for i, ax in enumerate(axes.ravel()):
mlp = MLPClassifier(solver='lbfgs', random_state=i, max_iter=2000, hidden_layer_sizes=[100, 100])
mlp.fit(X_train, y_train)
mglearn.plots.plot_2d_separator(mlp, X_train, fill=True, alpha=.3, ax=ax)
mglearn.discrete_scatter(X_train[:, 0], X_train[:, 1], y_train, ax=ax)

Para una comprensión más completa de las redes neuronales en escenarios prácticos, implementaremos el MLPClassifier en el conjunto de datos Breast Cancer. Nuestro paso inicial consiste en utilizar los parámetros por defecto. Queda como tarea para el estudiante, utilizar
GridSearchCVyPipeline.
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
print("Cancer data per-feature maxima:\n{}".format(cancer.data.max(axis=0)))
Cancer data per-feature maxima:
[2.811e+01 3.928e+01 1.885e+02 2.501e+03 1.634e-01 3.454e-01 4.268e-01
2.012e-01 3.040e-01 9.744e-02 2.873e+00 4.885e+00 2.198e+01 5.422e+02
3.113e-02 1.354e-01 3.960e-01 5.279e-02 7.895e-02 2.984e-02 3.604e+01
4.954e+01 2.512e+02 4.254e+03 2.226e-01 1.058e+00 1.252e+00 2.910e-01
6.638e-01 2.075e-01]
X_train, X_test, y_train, y_test = train_test_split(cancer.data, cancer.target, random_state=0)
mlp = MLPClassifier(random_state=42)
mlp.fit(X_train, y_train)
MLPClassifier(random_state=42)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
MLPClassifier(random_state=42)
print("Accuracy on training set: {:.2f}".format(mlp.score(X_train, y_train)))
print("Accuracy on test set: {:.2f}".format(mlp.score(X_test, y_test)))
Accuracy on training set: 0.94
Accuracy on test set: 0.92
El MLP muestra una precisión notable, aunque no a la par de otros modelos. Al igual que en el caso anterior del
SVC, esta discrepancia se debe probablemente al escalado de los datos. Las redes neuronales exigen una varianza uniforme entre las características de entrada, idealmente con una media de 0 y una varianza de 1.Para satisfacer estos criterios, los datos deben reescalarse. Mientras que aquí estamos implementando este proceso manualmente, en el capítulo Evaluación de modelos y Pipelines se usa
StandardScalerpara el manejo automatizado de este procedimiento
Calculamos el valor medio por característica en el conjunto de entrenamiento
mean_on_train = X_train.mean(axis=0)
Calculamos la desviación estándar de cada característica en el conjunto de entrenamiento
std_on_train = X_train.std(axis=0)
Procedemos con el proceso de estandarización a media 0 y desviación 1
X_train_scaled = (X_train - mean_on_train) / std_on_train
X_test_scaled = (X_test - mean_on_train) / std_on_train
mlp = MLPClassifier(random_state=0, max_iter=400)
mlp.fit(X_train_scaled, y_train)
MLPClassifier(max_iter=400, random_state=0)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
MLPClassifier(max_iter=400, random_state=0)
print("Accuracy on training set: {:.3f}".format(mlp.score(X_train_scaled, y_train)))
print("Accuracy on test set: {:.3f}".format(mlp.score(X_test_scaled, y_test)))
Accuracy on training set: 1.000
Accuracy on test set: 0.972
Dado que se aprecia una disparidad entre el rendimiento de entrenamiento y el de prueba, se puede intentar mejorar el rendimiento de generalización reduciendo la complejidad del modelo. En este escenario, optamos por intensificar el parámetro
"alpha"(de 0.0001 a 1) para imponer una regularización más potente de los pesos
mlp = MLPClassifier(max_iter=1000, alpha=1, random_state=0)
mlp.fit(X_train_scaled, y_train)
MLPClassifier(alpha=1, max_iter=1000, random_state=0)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
MLPClassifier(alpha=1, max_iter=1000, random_state=0)
print("Accuracy on training set: {:.3f}".format(mlp.score(X_train_scaled, y_train)))
print("Accuracy on test set: {:.3f}".format(mlp.score(X_test_scaled, y_test)))
Accuracy on training set: 0.988
Accuracy on test set: 0.972
Descubrir lo que ha aprendido una red neuronal suele ser todo un reto. Una técnica para comprender mejor los conocimientos adquiridos consiste en analizar los pesos del modelo. Puede ver un ejemplo en la galería de
scikit-learn. Sin embargo, para el conjunto de datos de Cáncer de Mama, la comprensión puede ser algo desafiante.La siguiente rutina muestra los pesos aprendidos, conectando la entrada a la primera capa oculta. Las filas corresponden a las 30 características de entrada, mientras que las columnas corresponden a las 100 unidades ocultas.
import seaborn as sns
plt.figure(figsize=(20, 15))
sns.set(font_scale=1.8)
plt.imshow(mlp.coefs_[0], interpolation='none', cmap='viridis', aspect='auto')
plt.yticks(range(30), cancer.feature_names)
plt.xlabel("Columns in weight matrix")
plt.ylabel("Input feature")
plt.colorbar();

Una posible inferencia que podemos hacer es que las
características que tienen pesos muy pequeños para todas las unidades ocultas son "menos importantes" para el modelo. Podemos ver que “mean smoothness” y “mean compactness”, además de las características encontradas entre “smoothness error” y “fractal dimension error”, tienen pesos relativamente bajos comparados con otras características. Esto podría significar que se trata de rasgos menos relevantes o, posiblemente, que no las representamos de forma que la red neuronal pudiera utilizarlas.También podemos visualizar los pesos que conectan la capa oculta con la capa de salida, pero son aún más difíciles de interpretar. Aunque
MLPClassifieryMLPRegressorproporcionan interfaces fáciles de usar para las arquitecturas de redes neuronales más comunes, solo capturan un pequeño subconjunto de lo que es posible con las redes neuronales. Si está interesado en trabajar con modelos más flexibles o modelos más grandes, se recomienda mirar más allá de scikit-learn en las fantásticas bibliotecas de aprendizaje profundo.Para los usuarios de
Python, las más conocidas sonkeras, lasagnay `tensor-flow. Estas bibliotecas proporcionan una interfaz mucho más flexible para construir redes neuronales y seguir el rápido progreso en la investigación del aprendizaje profundo, también permiten el uso de unidades de procesamiento gráfico (GPU) de alto rendimiento que scikit-learn no soporta.
11.11. Análisis de Malware por API calls#
El siguiente conjunto de datos forma parte de una investigación sobre la detección y clasificación de Malware mediante Deep Learning (ver Oliveira, Angelo; Sassi, Renato José (2019)). Contiene 42.797 secuencias de llamadas a la API de malware y 1.079 secuencias de llamadas a la API de goodware. Cada secuencia de llamadas a la API se compone de las 100 primeras llamadas a la API consecutivas no repetidas asociadas al proceso principal, extraídas de los elementos “calls” de los informes de Cuckoo Sandbox.
CaracterísticasNombre de la columna: hashDescripción: El hash MD5 del ejemploTipo: Cadena de 32 bytes
Nombre de columna: t_0, t_1,…, t99Descripción: Llamada a la APITipo: Entero (0-306)
Nombre de columna: malwareDescripción: ClaseTipo: Entero: 0 (Goodware) o 1 (Malware)
Fig. 11.19 Gráfico de comportamiento del malware troyano con hash MD5 ac65ce897a1f0dc273e8dc54fe3768ec.#
import warnings
warnings.filterwarnings('ignore')
import numpy as np
import pylab as pl
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import random
from sklearn.utils import shuffle
from sklearn.svm import SVC
from sklearn.metrics import confusion_matrix,classification_report
from sklearn.model_selection import cross_val_score, GridSearchCV
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.neural_network import MLPClassifier
from sklearn.model_selection import train_test_split
import pickle
import glob
from sklearn.metrics import f1_score
from sklearn.metrics import classification_report
from sklearn.metrics import roc_curve
from sklearn.metrics import precision_recall_curve
from time import process_time
data = pd.read_csv("https://raw.githubusercontent.com/lihkir/Data/main/api_call_sequence_per_malware.csv")
data.shape
(43876, 102)
La siguiente es una construida en el presente curso, la cual puede ser útil para quienes solo desean presentar unas cuantas columnas al inicio y al final de cada
pandas. Solo requiere del nombre delpandasy el número de columnas que deseamos visualziar al inicio y al final. Es bastante util, para utilizar en losJupyter Books, donde el espacio horizontal es reducido.
def idx_lr(data, n_new_cols):
n_data_cols = len(data.columns)
idx_l = sorted(list(range(n_new_cols - 1, -1, -1)))
idx_r = sorted(list(range(n_data_cols - 1, n_data_cols - n_new_cols - 1, -1)))
return idx_l + idx_r
Para imprimir por ejemplo las tres primeras columnas al inicio y al final del pandas data utilizamos la orden
data.iloc[:, idx_lr(data, 4)]. Nótese que no contamos con datos faltantes que requieran de un procedimiento de imputación (ver Análisis con datos faltantes). Además, nótese que todas las columnas con la excepción dehashcorresponde a datos numericos discretos.
data.iloc[:, idx_lr(data, 4)].head()
| hash | t_0 | t_1 | t_2 | t_97 | t_98 | t_99 | malware | |
|---|---|---|---|---|---|---|---|---|
| 0 | 071e8c3f8922e186e57548cd4c703a5d | 112 | 274 | 158 | 208 | 56 | 71 | 1 |
| 1 | 33f8e6d08a6aae939f25a8e0d63dd523 | 82 | 208 | 187 | 171 | 215 | 35 | 1 |
| 2 | b68abd064e975e1c6d5f25e748663076 | 16 | 110 | 240 | 65 | 113 | 112 | 1 |
| 3 | 72049be7bd30ea61297ea624ae198067 | 82 | 208 | 187 | 302 | 228 | 302 | 1 |
| 4 | c9b3700a77facf29172f32df6bc77f48 | 82 | 240 | 117 | 260 | 141 | 260 | 1 |
print("# NaN values:", data.isna().sum().sum())
# NaN values: 0
data.dtypes
hash object
t_0 int64
t_1 int64
t_2 int64
t_3 int64
...
t_96 int64
t_97 int64
t_98 int64
t_99 int64
malware int64
Length: 102, dtype: object
Pasamos ahora a eliminar aquellas variables (columnas) irrelevantes en el análisis predictivo, a saber la columna
hashdel pandasdatay creamos uno nuevo al cual nombraremosdata_new.
data_new = data.drop(columns=['hash'], axis=1)
data_new.shape
(43876, 101)
Verifiquemos si nuestros datos están desbalanceados respecto a las clases de interés 0 (Goodware) o 1 (Malware)
import matplotlib
matplotlib.rc_file_defaults()
cnt_pro = data_new['malware'].value_counts()
sns.barplot(x=cnt_pro.index, y=cnt_pro.values, alpha=0.8)
plt.ylabel('Number of data', fontsize=10)
plt.xlabel('Malware Type', fontsize=10);
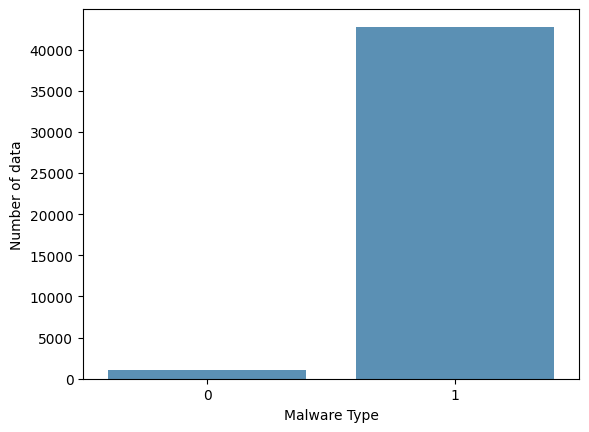
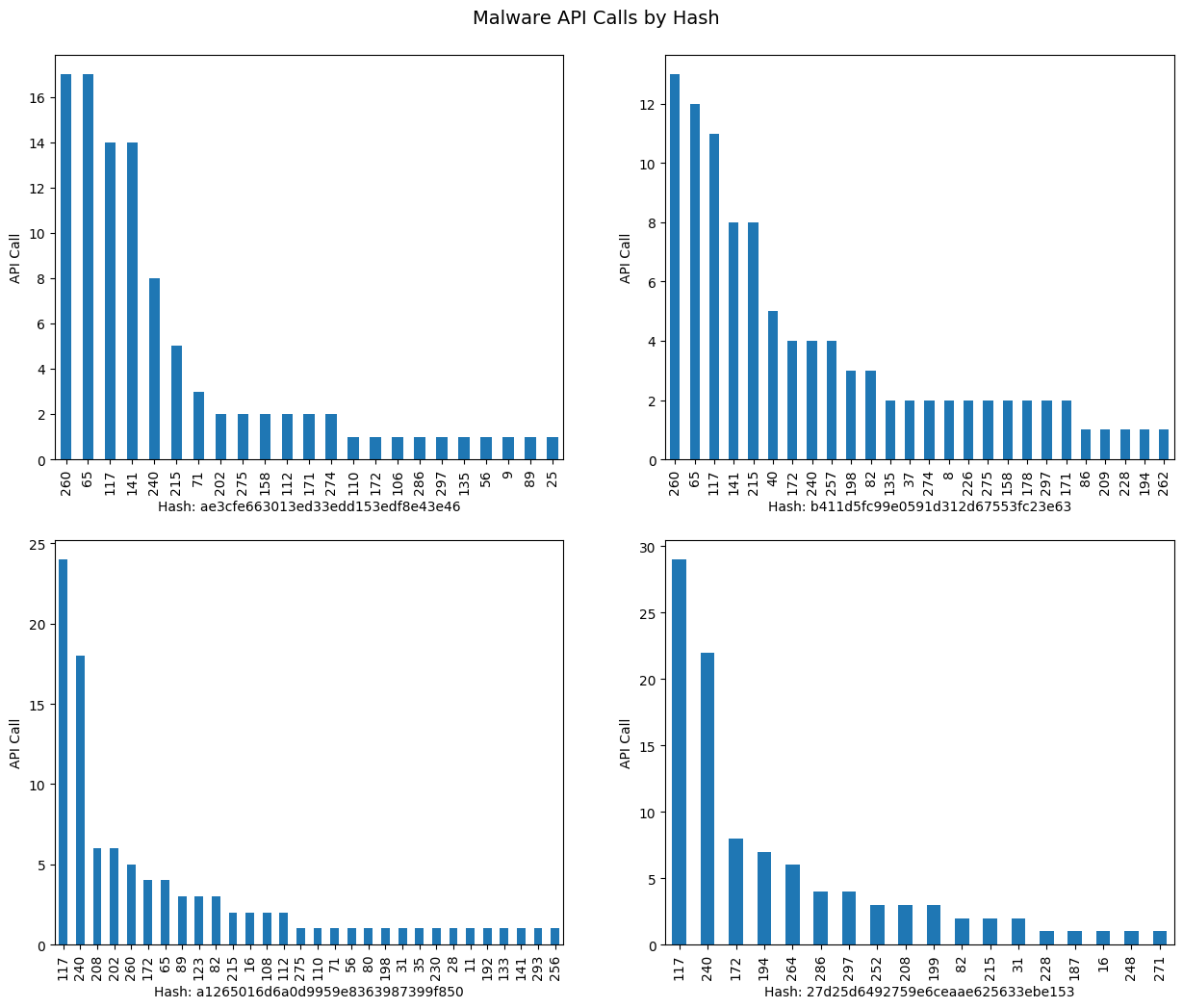
Claramente, existe un desbalance entre los tipos de Malware. Por otro lado, verifiquemos para algunos Hash, como se distribuyen la frecuencia de cada una de sus API calls. Las columnas representan las frecuencias de cada API call representado por los valores
t_0, t_1,..., t99.
fig, axs = plt.subplots(nrows=2, ncols=2, figsize=(15, 12))
plt.subplots_adjust(hspace=0.2)
fig.suptitle("Malware API Calls by Hash", fontsize=14, y=0.92)
for i, ax in zip(range(1, 5), axs.ravel()):
plt.subplot(2, 2, i)
n_hash = random.randint(0, len(data_new))
data_new.iloc[n_hash,:-1].value_counts().plot(kind='bar', xlabel='Hash: '+ data['hash'][n_hash], ylabel='API Call');
Procedemos a hacer uso de
make_pipelineyGridSearchCVpara obtener parámetros del mejor modelo. En este caso utilizaremos el clasificadorMLPClassifier, el cual se estudió en clase de forma analítica.
El algoritmo clasificador
MLPClassifierdenota el valor de la longitud de paso \(\mu_{i}\) comolearning_rate, el cual asume los valores constant, invscaling, adaptive. En este ejemplo se ha probado con los tres parámetros, obteniendo siempre el mejor score cuandolearning_rate = constant. Por otro lado,hidden_layer_sizesrepresenta el número de neuronas en el \(i\)th layer. En este problema de clasificación optamos por seleccionar desde una a tres capas escondidas (hidden layers), pero siempre el mejor score entregado porGridSearchCV, fue obtenido considerando una sola capa. Por lo tanto, en este problema hacemos solo un grid search sobre el número de neuronas sobre una sola capa.Dado que nuestro problema es de clasificación binaria, también consideramos en el
param_grid, soloactivation = logistic. Las opciones del clasificador sonidentity, logistic, tanh, relu, peroGridSearchCVentregó el mejor score usandologisticcomo era de esperarse. El parámetroalphaes la fuerza del término de regularización \(L^2\), similar al utilizado en la regresiónridgecuando deseamos reducir la complejidad de un modelo. Puede revisar la documentación del clasificador para ver todos los parámetros asociados, y aquellos que son por defecto (ver MLPClassifier).
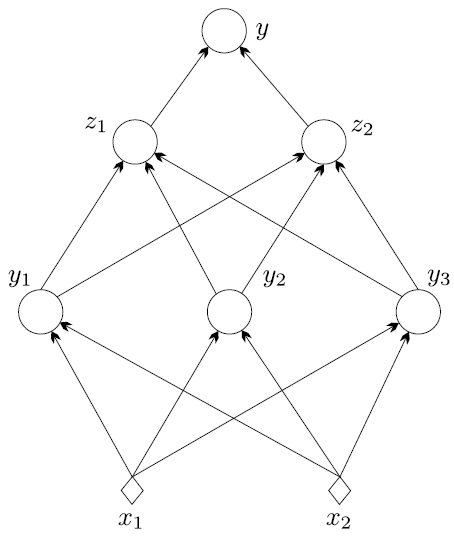
Fig. 11.20 Red neuronal feed-forward de tres capas.#
La capa de entrada
En general las ANNs tienen exactamente una capa de entrada. Con respecto al número de neuronas que componen esta capa, este parámetro se determina de forma completa y única, una vez que se conoce la forma de los datos de entrenamiento. En concreto, el número de neuronas que componen esa capa es igual al número de características (columnas) de sus datos. Algunas configuraciones de ANNs añaden un nodo adicional para un término de sesgo.
La capa de salida
Al igual que la capa de entrada, cada ANN tiene exactamente una capa de salida. Determinar su tamaño (número de neuronas) es sencillo; está completamente determinado por la configuración del modelo elegido. Si la ANN es un regresor, la capa de salida tiene un solo nodo (Time Series Forecasting). Si la ANN es un clasificador, entonces también tiene un solo nodo, a menos que se utilice
softmax, en cuyo caso la capa de salida tiene un nodo por cada etiqueta de clase en su modelo.
Las capas ocultas
¿Cuántas capas ocultas?. Si los datos son linealmente separables (lo que a menudo se sabe cuando se empieza a codificar una ANN, SVM puede servir de test), entonces no se necesita ninguna capa oculta. Por supuesto, tampoco se necesita una ANN para resolver los datos, pero está seguirá haciendo su trabajo.
Sobre la configuración de las capas ocultas en las ANNs, existe un consenso dentro de este tema, y es la diferencia de rendimiento al añadir capas ocultas adicionales: las situaciones en las que el rendimiento mejora con una segunda (o tercera, etc.) capa oculta son muy pocas. Una capa oculta es suficiente para la gran mayoría de los problemas.
Entonces, ¿qué pasa con el tamaño de la(s) capa(s) oculta(s), cuántas neuronas?. Existen algunas reglas empíricas; de ellas, la más utilizada es ‘The optimal size of the hidden layer is usually between the size of the input and size of the output layers’. Jeff Heaton, the author of Introduction to Neural Networks in Java.
Hay una regla empírica adicional que ayuda en los problemas de aprendizaje supervisado. Normalmente se puede evitar el sobreajuste si se mantiene el número de neuronas por debajo de:
\[ N_{h}=\frac{N_{s}}{(\alpha\cdot(N_{i}+N_{o}))} \]\(N_{i}=\) número de neuronas de entrada
\(N_{o}=\) número de neuronas de salida
\(N_{s}=\) número de muestras en el conjunto de datos de entrenamiento
\(\alpha=\) un factor de escala arbitrario, normalmente 2-10
Un valor de \(\alpha=2\) suele funcionar sin sobreajustar. Se puede pensar en \(\alpha\) como el factor de ramificación efectivo o el número de pesos distintos de cero para cada neurona. Las capas de salida harán que el factor de ramificación “efectivo” sea muy inferior al factor de ramificación medio real de la red. Para profundizar mas en el diseño de redes neuronales, ver el siguiente texto de Martin Hagan.
En resumen, para la mayoría de los problemas, probablemente se podría obtener un rendimiento decente (incluso sin un segundo paso de optimización) estableciendo la configuración de la capa oculta utilizando sólo dos reglas:
el número de capas ocultas es igual a uno
el número de neuronas de esa capa es la media de las neuronas de las capas de entrada y salida. ¡Nótese que en el ejemplo de esta sección el número de columnas para \(X\) es 100!.
Pasamos ahora a implementar un modelo de clasificación para el conjunto de datos relacionados con: Análisis de Malware por API calls. Utilizaremos la clase
MLPClassifiery como preprocesamiento, estandarizaremos nuestros datos usando la claseStandardScaler. Para encontrar los mejores parámetros y evita problemas de data leakage, utilizaremosPipelineyGridSearchCVtal como se explicó en secciones anteriores.
pipe = make_pipeline(StandardScaler(), MLPClassifier(max_iter=10000, random_state=42))
param_grid = {'mlpclassifier__alpha': [0.1, 0.01, 0.001],
'mlpclassifier__hidden_layer_sizes': [(10,), (100,), (1000,)],
'mlpclassifier__activation': ['logistic'],
'mlpclassifier__learning_rate': ['constant']}
Construimos nuestra matriz de caracteristicas, o variable explicativa X y el vector de clases o la variable respuesta y
y = data_new['malware']
X = data_new.drop(['malware'], axis=1)
Realizamos la división de nuestros datos a priori, con el objetivo de evitar data leakage. Consideramos el mismo
random_stateutilizado en el clasificador, con el objetivo de que los resutlados sean reproducibles.
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
El siguiente ciclo if ha sido implementado en este curso para evitar reentrenar nuestro modelo clasificador. Nótese que si el algoritmo no detecta que existe un archivo de extensión
.pkl, reentrena el modelo, de lo contrario, utiliza el modelo entrenado a priori, el cual ha sido guardado en el archivo.pkl. Los archivoPicklede extensión.pklen simples palabras se encargan de serializar un objeto, esto es transformar el mismo en una cadena de bytes única que puede ser guardada en un archivo (de extensión .pkl), archivo que podemos desempaquetar después y trabajar con su contenido. Para poder utlizarlo necesitamos importarlo con la ordenimport pickle, e instalar la librería (Pickel viene por defecto desde Python 3.9) si así se requiere utilizando:
pip install pickle
from joblib import dump, load
import time
grid = None
if len(glob.glob("grid_mlp.joblib")) != 0:
grid = load('grid_mlp.joblib')
if len(glob.glob("cpu_time.txt")) != 0:
with open('cpu_time.txt', 'r', encoding='utf-8') as f:
saved_time = f.read()
print(saved_time)
else:
print("Archivo cpu_time.txt no encontrado")
else:
start = time.time()
grid = GridSearchCV(pipe, param_grid, cv=5, n_jobs=-1, scoring='roc_auc')
grid.fit(X_train, y_train)
end = time.time()
elapsed_minutes = (end - start) / 60
str_cpu_time = f"GridSearchCV time: {elapsed_minutes:.2f} minutes"
print(str_cpu_time)
with open('cpu_time.txt', 'w', encoding='utf-8') as f:
f.write(str_cpu_time)
dump(grid, 'grid_mlp.joblib')
print("Best CV score = %0.3f" % grid.best_score_)
print("Best parameters:\n{}".format(grid.best_params_))
GridSearchCV time: 2.92 minutes
Best CV score = 0.958
Best parameters:
{'mlpclassifier__activation': 'logistic', 'mlpclassifier__alpha': 0.01, 'mlpclassifier__hidden_layer_sizes': (100,), 'mlpclassifier__learning_rate': 'constant'}
Utilizamos el
f1_score, el cual, de acuerdo a lo estudiado en secciones previas, calcula la media armonica entreprecisionyrecall
print(f"F1 Score of the classifier is: {f1_score(y_test, grid.predict(X_test))}")
F1 Score of the classifier is: 0.9937633808061063
Además podemos usar
classification_reporty la matriz de confusión, para identificar aquellas clases que fueron incorrectamente clasificadas por nuestro modelo
print(classification_report(y_test, grid.predict(X_test)))
precision recall f1-score support
0 0.94 0.56 0.70 283
1 0.99 1.00 0.99 10686
accuracy 0.99 10969
macro avg 0.96 0.78 0.85 10969
weighted avg 0.99 0.99 0.99 10969
mlp_cm = confusion_matrix(y_test, grid.predict(X_test))
f, ax = plt.subplots(figsize=(5,5))
sns.heatmap(mlp_cm, annot=True, linewidth=0.7, linecolor='black', fmt='g', ax=ax, cmap="BuPu")
plt.title('MLP Confusion Matrix')
plt.xlabel('Y predict')
plt.ylabel('Y test')
plt.show()

Nótese que la
clase 0, presenta el mayor número de clasificaciones erroneas(FP), obtenidas por nuestra ANN. Justamente esto se debe al desbalance notorio en nuestros datos, el cual se inclina hacia la clases 1, de mayor frecuencia. Si se tiene clara una métrica de negocio o un punto de operación, podríamos ajustar el número de prediccion incorrectas a favor de este punto de operación, tal como en el problema de detección de cancer, donde el interés era reducir (FN). Para analizar el comportamiento del clasificador a diferentes umbrales, utilizamos la curva ROC y precision-recall
fpr_mlp, tpr_mlp, thresholds_mlp = roc_curve(y_test, grid.predict_proba(X_test)[:, 1])
plt.plot(fpr_mlp, tpr_mlp, label="ROC Curve MLP")
plt.xlabel("FPR")
plt.ylabel("TPR (recall)")
close_default_mlp = np.argmin(np.abs(thresholds_mlp - 0.5))
plt.plot(fpr_mlp[close_default_mlp], tpr_mlp[close_default_mlp], '^',
markersize=10, label="threshold 0.5 MLP", fillstyle="none", c='k', mew=2)
plt.legend(loc=4);
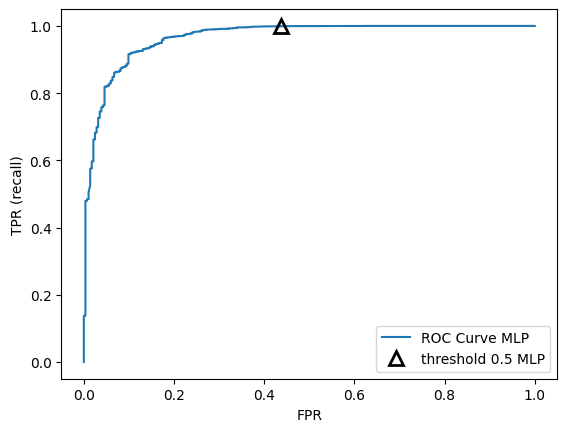
Nótese que la tasa TPR se mantiene aproximadamente contante para valores de FPR>0.2, esto es, para esta tasas de FPR no se está sacrificando la tasa recall. Si deseamos mantener un recall alto, aproximadamente, mayor que 0.8, podemos considerar por ejemplo una tasa FPR en torno a 0.1, con la que no estaríamos sacrificando recall y además, obtendriamos un tasa de falsos positivos FPR relativamente baja.
precision_mlp, recall_mlp, thresholds_mlp = precision_recall_curve(y_test, grid.predict_proba(X_test)[:, 1])
plt.plot(precision_mlp, recall_mlp, label="MLP")
close_default_mlp = np.argmin(np.abs(thresholds_mlp - 0.5))
plt.plot(precision_mlp[close_default_mlp], recall_mlp[close_default_mlp], '^', c='k',
markersize=10, label="threshold 0.5 MLP", fillstyle="none", mew=2)
plt.xlabel("Precision")
plt.ylabel("Recall")
plt.legend(loc="best");
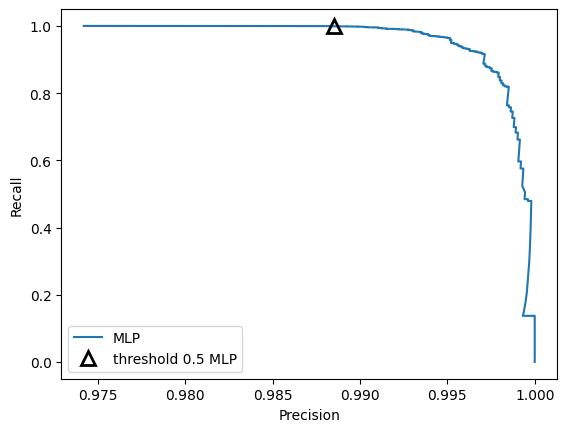
Nótese que con el umbral por defecto, la curva precision-recall muestra una clasificación con scores bastante buenos para cada una de estas métricas, incluso, si movemos el umbral un poco, para favorecer la clase 0 que es la menos frecuente, vamos a obtener de igual manera un rango de valores altos para precision y recall. Sólo valores de precision muy elevados, esto es, valores cuya distancia 1 tiende a cero, estaríamos sacrificando recall.
11.11.1. Entrenamiento en PySpark#
11.11.2. ¿Por qué usar PySpark para modelos de Machine Learning con grandes volúmenes de datos?#
A medida que trabajamos con datasets más grandes, las herramientas tradicionales como
scikit-learncomienzan a mostrar ciertas limitaciones. Aunque son excelentes para prototipado rápido y problemas de tamaño moderado, no están diseñadas para escalar eficientemente cuando tratamos con millones de registros. Ver ejemplo PySparkAquí es donde entra PySpark, la interfaz en Python de
Apache Spark.PySparkpermite:Ejecutar operaciones en paralelo aprovechando múltiples núcleos o incluso múltiples máquinas (clústeres)
Procesar y transformar datos a gran escala con pipelines eficientes
Entrenar modelos de machine learning distribuidos con la API
pyspark.ml
Elemento |
¿Necesario? |
Comentario |
|---|---|---|
Python |
Sí |
Versión recomendada: 3.8 a 3.10 |
PySpark instalado ( |
Sí |
Necesario para ejecutar Spark desde Python |
scikit-learn ( |
Sí |
Necesario para cargar el dataset de Iris |
Jupyter, VSCode o IDE |
Recomendado |
Necesario si deseas una interfaz cómoda para desarrollar |
Java JDK (versión requerida por PySpark |
Usualmente necesario |
Spark requiere Java. Asegúrate de tener |
findspark ( |
Opcional |
Útil si usas notebooks y necesitas inicializar Spark manualmente |
MLflow ( |
Opcional |
Solo si planeas hacer tracking de experimentos |
Para instalar Java (ver Java Downloads)
Configurar
JAVA_HOMEpermanentemente. Si prefieres no tener que hacer esto en cada notebook:Abre el Panel de Control → Sistema → Configuración avanzada del sistema.
Clic en “Variables de entorno”.
En “Variables del sistema”, haz clic en “Nueva…” y agrega:
Nombre:
JAVA_HOMEValor:
C:\Program Files\Java\jdk-17.0.20(ajusta según tu versión)
Cierra y vuelve a abrir tu entorno (
Jupyter, Anaconda, etc.).
Preparar entorno y datos en
PySpark
import pandas as pd
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("MLP with PySpark") \
.getOrCreate()
WARNING: Using incubator modules: jdk.incubator.vector
Using Spark's default log4j profile: org/apache/spark/log4j2-defaults.properties
26/02/04 22:09:56 WARN Utils: Your hostname, DESKTOP-14GHD2E, resolves to a loopback address: 127.0.1.1; using 10.255.255.254 instead (on interface lo)
26/02/04 22:09:56 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
Using Spark's default log4j profile: org/apache/spark/log4j2-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
26/02/04 22:09:58 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
pdf = pd.read_csv("https://raw.githubusercontent.com/lihkir/Data/main/api_call_sequence_per_malware.csv")
print(pdf.dtypes)
hash object
t_0 int64
t_1 int64
t_2 int64
t_3 int64
...
t_96 int64
t_97 int64
t_98 int64
t_99 int64
malware int64
Length: 102, dtype: object
total_unicos = pdf["hash"].nunique()
total_filas = len(pdf)
print(f"Hashes únicos: {total_unicos} de {total_filas} filas")
print("Top 10 hashes más frecuentes:")
print(pdf["hash"].value_counts().head(10))
Hashes únicos: 43867 de 43876 filas
Top 10 hashes más frecuentes:
hash
075323e77815ee8bcc7854ce23955a15 2
bdaaac3fa3f6796825a51ef1c0e5b3fd 2
3d8a7a97ea954dd4fe66279df2b445e0 2
a71a2319cf8c74a89501eb80acd04fe6 2
03384ab6368b68ed16ecb9e6352539af 2
0822ec2ba98d291e5bfc836bc3686096 2
79b78bb3d583748040c41ded09555fd3 2
f78ea80cec007b2c32fb10f9c6c82f39 2
64261f6acf8e566a70ec8b62af8ccdb1 2
fe19283eb05bbe24699c0a5134e1c9fd 1
Name: count, dtype: int64
pdf.drop(columns=['hash'], inplace=True)
df_spark = spark.createDataFrame(pdf)
target_col = "malware"
feature_cols = [c for c in df_spark.columns if c != target_col]
num_features = len(feature_cols)
num_classes = pdf['malware'].nunique()
En
PySpark, antes de entrenar un modelo, hay que combinar todas las columnas de entrada en una sola columnafeaturesusandoVectorAssembler
from pyspark.ml.feature import VectorAssembler
assembler = VectorAssembler(inputCols=feature_cols, outputCol="features")
data_assembled = assembler.transform(df_spark).select("features", target_col)
Escalado de datos (equivalente a
StandardScalerdesklearn)
from pyspark.ml.feature import StandardScaler
scaler = StandardScaler(inputCol="features", outputCol="scaledFeatures", withStd=True, withMean=True)
scaler_model = scaler.fit(data_assembled)
data_scaled = scaler_model.transform(data_assembled).select("scaledFeatures", target_col)
26/02/04 22:11:17 WARN SparkStringUtils: Truncated the string representation of a plan since it was too large. This behavior can be adjusted by setting 'spark.sql.debug.maxToStringFields'.
División en
trainytest
train, test = data_scaled.randomSplit([0.8, 0.2], seed=42)
Entrenar un
MLPenPySpark. PySpark tiene su propioMultilayerPerceptronClassifier
from pyspark.ml.classification import MultilayerPerceptronClassifier
from pyspark.ml.evaluation import BinaryClassificationEvaluator
from pyspark.ml.tuning import CrossValidator, ParamGridBuilder
from pyspark.ml.evaluation import MulticlassClassificationEvaluator
layers_10 = [num_features, 10, num_classes]
layers_100 = [num_features, 100, num_classes]
layers_1000 = [num_features, 1000, num_classes]
mlp = MultilayerPerceptronClassifier(
featuresCol="scaledFeatures",
labelCol=target_col,
maxIter=100,
seed=123
)
paramGrid = (ParamGridBuilder()
.addGrid(mlp.layers, [
[num_features, 10, num_classes],
[num_features, 100, num_classes],
[num_features, 1000, num_classes]
])
.addGrid(mlp.stepSize, [0.1, 0.01, 0.001]) # Aproximando a 'alpha' y 'learning_rate'
.addGrid(mlp.maxIter, [100]) # 'learning_rate' constant por defecto en PySpark
.build()
)
evaluator = BinaryClassificationEvaluator(
labelCol=target_col,
rawPredictionCol="rawPrediction",
metricName="areaUnderROC"
)
cv = CrossValidator(
estimator=mlp,
estimatorParamMaps=paramGrid,
evaluator=evaluator,
numFolds=5
)
import time
start_time = time.time()
cv_model = cv.fit(train)
end_time = time.time()
print("Tiempo total de cómputo: {:.2f} segundos".format(end_time - start_time))
26/02/04 22:11:22 WARN InstanceBuilder: Failed to load implementation from:dev.ludovic.netlib.blas.JNIBLAS
Tiempo total de cómputo: 419.27 segundos
predictions = cv_model.transform(test)
f1 = evaluator.evaluate(predictions)
print(f"F1 Score: {f1:.4f}")
F1 Score: 0.9457
Comparación de desempeño: PySpark vs Scikit-learn: Los resultados obtenidos muestran que, para conjuntos de datos de tamaño pequeño o mediano, el entrenamiento mediante scikit-learn puede ser significativamente más rápido que mediante PySpark. Esto se debe al costo adicional de inicialización, serialización y comunicación inherente a los sistemas distribuidos.
¿Cuándo PySpark resulta más eficiente? El uso de PySpark comienza a ser ventajoso en escenarios como:
Conjuntos de datos del orden de varios GB o TB.
Datos que no caben en memoria RAM de una sola máquina.
Entornos con múltiples nodos de cómputo.
Necesidad de procesamiento realmente distribuido.
Por ejemplo, en problemas con:
Decenas de millones de registros,
Cientos o miles de variables,
Entrenamiento distribuido en cluster,
las herramientas tradicionales como scikit-learn pueden no ser viables, mientras que PySpark permite escalar el procesamiento de forma eficiente.
“Distribuido no siempre es más rápido.”
El paralelismo distribuido introduce un overhead que solo se compensa cuando el volumen de datos lo justifica.
Regla práctica
Escenario |
Herramienta recomendada |
|---|---|
Dataset pequeño o mediano |
scikit-learn |
Dataset grande en una sola máquina |
scikit-learn |
Dataset muy grande distribuido |
PySpark |
Entornos productivos en cluster |
PySpark |
En síntesis, la elección entre scikit-learn y PySpark debe basarse principalmente en el tamaño de los datos y la infraestructura disponible, más que en la expectativa de una mayor velocidad por el solo hecho de utilizar cómputo distribuido.
11.12. Proyecto Integrador de Deep Learning#
11.12.1. Objetivo#
Construir un modelo de clasificación supervisada usando MLP (Multilayer Perceptron/Red Neuronal Multicapa) para predecir si un usuario hará clic en un anuncio móvil (click = 1) o no (click = 0). Se comparará el desempeño de los modelos construidos con scikit-learn y PySpark. Además, se aplicará LIME para interpretar predicciones individuales del modelo.
11.12.2. Dataset#
Nombre: Avazu Click-Through Rate Prediction
Fuente: Kaggle – Avazu CTR Prediction
Tamaño: aproximadamente 40 millones de registros
Características: variables anónimas relacionadas con publicidad móvil, dispositivo, aplicación y contexto de navegación
Descripción de los campos principales:
id: identificador del anuncioclick: indicador de si hubo clichour: hora de la impresión del anuncio (formato YYMMDDHH)C1: variable categórica anonimizadabanner_possite_id,site_domain,site_categoryapp_id,app_domain,app_categorydevice_id,device_ip,device_modeldevice_type,device_conn_typeC14–C21: variables categóricas anónimas
11.12.3. Target#
Variable binaria:
click0 = No hubo clic
1 = Hubo clic
La variable objetivo ya se encuentra definida en el dataset:
y = df["click"]
11.12.4. Exploración de datos (EDA)#
Cargar el dataset CSV
Analizar la distribución de la variable
clickVerificar valores faltantes y tipos de datos
Analizar la cardinalidad de las variables categóricas
Transformar la variable
houren nuevas características temporales (día, hora, franja horaria)
Visualizaciones requeridas:
Gráfico de barras de la variable
clickHistogramas de variables numéricas derivadas
Gráficos de frecuencia de las principales variables categóricas
Distribución de clics por hora del día
Matriz de correlación para variables numéricas creadas
11.12.5. scikit-learn#
Debido al gran tamaño del dataset, el trabajo en scikit-learn deberá realizarse sobre una muestra representativa (por ejemplo, 1 millón de registros).
Seleccionar un subconjunto de variables relevantes
Codificación de variables categóricas (OneHotEncoder o Target Encoding)
Escalado de variables numéricas con StandardScaler
División train_test_split (80/20), estratificada por clase
Ejemplo de muestreo:
df_sample = df.sample(n=1000000, random_state=42)
11.12.6. PySpark#
Esta sección debe trabajarse con el dataset completo.
Leer el CSV utilizando SparkSession
Uso de StringIndexer y OneHotEncoder para variables categóricas
Combinar columnas de entrada en una sola columna
featuresusando VectorAssemblerEscalar las variables con StandardScaler (opcional)
Dividir en train y test usando randomSplit, estratificada si es posible
Ejemplo de lectura:
spark.read.csv("train.csv", header=True, inferSchema=True)
11.12.7. Modelado con scikit-learn#
Usar MLPClassifier
Realizar búsqueda de hiperparámetros (GridSearchCV) para:
hidden_layer_sizes(por ejemplo: [(50,), (100,), (100,50)])alpha(por ejemplo: [0.0001, 0.001, 0.01])max_iter(por ejemplo: [50, 100])
Métricas a evaluar:
Accuracy
Precision
Recall
F1-score
ROC AUC
Matriz de confusión
Medir el tiempo de entrenamiento y predicción
11.12.8. Modelado con PySpark#
Usar pyspark.ml.classification.MultilayerPerceptronClassifier
Probar combinaciones de hiperparámetros como:
Estructura de capas (layers):
[num_features, 10, 2][num_features, 50, 2][num_features, 100, 2]
stepSize: 0.1, 0.01maxIter: 100, 200
Evaluar con BinaryClassificationEvaluator
Calcular:
Precisión
Recall
F1-score
Matriz de confusión
Medir el tiempo total de entrenamiento y predicción
11.12.9. Interpretabilidad con LIME#
Instalar LIME:
pip install limeSeleccionar una o dos instancias clasificadas erróneamente
Aplicar
lime.lime_tabular.LimeTabularExplainerpara analizar la(s) predicción(es)Visualizar variables más influyentes en la decisión del modelo
Incluir gráficos de explicación local
11.12.10. Comparación de Resultados#
Tabla comparativa con:
Métricas para scikit-learn vs PySpark
Tiempo de cómputo (entrenamiento y predicción)
Gráficos:
Curvas ROC
Gráficos comparativos de tiempo
11.12.11. Entregable#
Un Jupyter Book bien documentado que incluya:
Análisis exploratorio
Preprocesamiento en ambos entornos
Modelado y tuning de hiperparámetros
Evaluación de métricas
Interpretabilidad con LIME (con visualizaciones)
Reflexión crítica sobre:
¿Qué entorno fue más rápido?
¿Cuál más preciso?
¿Cuándo es útil PySpark?
¿Qué aporta LIME?
11.13. Recursos#
11.14. Aplicación: Predicción de series temporales#
Series de tiempo
Uno de los enfoques clásicos para la predicción de series temporales es el modelo autorregresivo de orden \(p\), denotado como \(AR(p)\), el cual modela el valor actual \(y_t\) como una combinación lineal de sus \(p\) valores pasados:
\[ y_t = \omega_0 + \sum_{i=1}^{p} \omega_i y_{t-i} + \varepsilon_t, \]donde \(\omega_i\) son coeficientes del modelo y \(\varepsilon_t\) es un término de error con media cero y varianza constante.
Este modelo puede generalizarse mediante una función no lineal \(f\):
\[ y_t = f(y_{t-1}, y_{t-2}, \dots, y_{t-p}), \]donde \(f\) puede ser aprendida utilizando redes neuronales artificiales. En este capítulo se consideran tres arquitecturas neuronales para aproximar \(f\), cada una definida por su número de capas ocultas, neuronas por capa y función de activación. El entrenamiento de los modelos se realiza mediante el algoritmo de backpropagation del error o sus variantes.
En esta sección, utilizaremos
MLPpara desarrollar modelos de predicción de series temporales. El conjunto de datos utilizado para estos ejemplos es sobre la contaminación atmosférica medida por la concentración de partículas (PM) de diámetro inferior o igual a 2.5 micrómetros.Hay otras variables, como la presión atmosférica, temperatura del aire, punto de rocío, etc. Se han desarrollado un par de modelos de series temporales, uno sobre la presión atmosférica
PRESy otro sobrepm 2.5. El conjunto de datos se ha descargado del repositorio de aprendizaje automático de la UCI.
import warnings
from matplotlib import pyplot as plt
import seaborn as sns
warnings.filterwarnings("ignore")
sns.set_style("darkgrid")
import sys
import pandas as pd
import numpy as np
import datetime
from sklearn.preprocessing import MinMaxScaler
import tensorflow as tf
from tensorflow import keras
from keras.layers import Dense, Input, Dropout
from keras.optimizers import SGD
from keras.models import Model
from keras.models import load_model
from keras.callbacks import ModelCheckpoint
import os
from sklearn.metrics import r2_score
from sklearn.metrics import mean_absolute_error
2025-11-03 20:36:21.586985: I tensorflow/core/util/port.cc:153] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
2025-11-03 20:36:21.869543: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:485] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
2025-11-03 20:36:21.964068: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:8454] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
2025-11-03 20:36:21.989089: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1452] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
2025-11-03 20:36:22.163965: I tensorflow/core/platform/cpu_feature_guard.cc:210] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 AVX512F AVX512_VNNI AVX512_BF16 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2025-11-03 20:36:23.254332: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
df = pd.read_csv('https://raw.githubusercontent.com/lihkir/Data/refs/heads/main/PRSA_data_2010.1.1-2014.12.31.csv', usecols=lambda column: column not in ['DEWP', 'TEMP', 'cbwd', 'Iws', 'Is', 'Ir'])
devices = tf.config.list_physical_devices()
print("Available devices:")
for device in devices:
print(device)
gpus = tf.config.list_physical_devices('GPU')
if gpus:
print("TensorFlow is using GPU.")
for gpu in gpus:
gpu_details = tf.config.experimental.get_device_details(gpu)
print(f"GPU details: {gpu_details}")
else:
print("TensorFlow is not using GPU.")
Available devices:
PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU')
PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')
TensorFlow is using GPU.
GPU details: {'compute_capability': (8, 9), 'device_name': 'NVIDIA GeForce RTX 4070'}
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1762220186.947118 6997 cuda_executor.cc:1001] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node
Your kernel may have been built without NUMA support.
I0000 00:00:1762220187.467196 6997 cuda_executor.cc:1001] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node
Your kernel may have been built without NUMA support.
I0000 00:00:1762220187.467264 6997 cuda_executor.cc:1001] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node
Your kernel may have been built without NUMA support.
I0000 00:00:1762220187.479272 6997 cuda_executor.cc:1001] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node
Your kernel may have been built without NUMA support.
print('Shape of the dataframe:', df.shape)
Shape of the dataframe: (43824, 7)
df.head()
| No | year | month | day | hour | pm2.5 | PRES | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 2010 | 1 | 1 | 0 | NaN | 1021.0 |
| 1 | 2 | 2010 | 1 | 1 | 1 | NaN | 1020.0 |
| 2 | 3 | 2010 | 1 | 1 | 2 | NaN | 1019.0 |
| 3 | 4 | 2010 | 1 | 1 | 3 | NaN | 1019.0 |
| 4 | 5 | 2010 | 1 | 1 | 4 | NaN | 1018.0 |
Para asegurarse de que las filas están en el orden correcto de fecha y hora de las observaciones, se crea una nueva columna datetime a partir de las columnas relacionadas con la fecha y la hora del DataFrame. La nueva columna se compone de objetos
datetime.datetime de Python. El DataFrame se ordena en orden ascendente sobre esta columna
df['datetime'] = df[['year', 'month', 'day', 'hour']].apply(lambda row: datetime.datetime(year=row['year'], month=row['month'], day=row['day'],
hour=row['hour']), axis=1)
df.sort_values('datetime', ascending=True, inplace=True)
df.head()
| No | year | month | day | hour | pm2.5 | PRES | datetime | |
|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2010 | 1 | 1 | 0 | NaN | 1021.0 | 2010-01-01 00:00:00 |
| 1 | 2 | 2010 | 1 | 1 | 1 | NaN | 1020.0 | 2010-01-01 01:00:00 |
| 2 | 3 | 2010 | 1 | 1 | 2 | NaN | 1019.0 | 2010-01-01 02:00:00 |
| 3 | 4 | 2010 | 1 | 1 | 3 | NaN | 1019.0 | 2010-01-01 03:00:00 |
| 4 | 5 | 2010 | 1 | 1 | 4 | NaN | 1018.0 | 2010-01-01 04:00:00 |
Dibujamos un diagrama de cajas para visualizar la tendencia central y la dispersión de por ejemplo la columna
PRES
plot_fontsize = 18;
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(15, 8))
plt.subplot(1, 2, 1)
g1 = sns.boxplot(x=df['PRES'], orient="h") # Removed palette
g1.set_title('Box plot of Air Pressure', fontsize=plot_fontsize)
g1.set_xlabel('Air Pressure readings in hPa', fontsize=plot_fontsize)
plt.subplot(1, 2, 2)
g2 = sns.boxplot(x=df['pm2.5'], orient="h") # Removed palette
g2.set_title('Box plot of PM2.5', fontsize=plot_fontsize)
g2.set_xlabel('PM2.5 readings in µg/m³', fontsize=plot_fontsize)
plt.show()

plt.figure(figsize=(15, 8))
plt.subplot(1, 2, 1)
g1 = sns.lineplot(x=df.index, y=df['PRES']) # Using x and y parameters instead of data
g1.set_title('Time series of Air Pressure', fontsize=plot_fontsize)
g1.set_xlabel('Index', fontsize=plot_fontsize)
g1.set_ylabel('Air Pressure readings in hPa', fontsize=plot_fontsize)
plt.subplot(1, 2, 2)
g2 = sns.lineplot(x=df.index, y=df['pm2.5']) # Using x and y parameters instead of data
g2.set_title('Time series of PM2.5', fontsize=plot_fontsize)
g2.set_xlabel('Index', fontsize=plot_fontsize)
g2.set_ylabel('PM2.5 readings in µg/m³', fontsize=plot_fontsize)
plt.show()
Los algoritmos de gradiente descendente funcionan mejor (por ejemplo, convergen más rápido) si las variables están dentro del intervalo \([-1, 1]\). Muchas fuentes relajan el límite hasta \([-3, 3]\). La variable
PRESes escalada conminmaxpara limitar la variable transformada dentro de \([0,1]\).
Observación
Antes de entrenar el modelo, el conjunto de datos se divide en dos partes: el conjunto de entrenamiento y el conjunto de validación. La red neuronal se entrena en el conjunto de entrenamiento. Esto significa que el cálculo de la función de pérdida, la propagación hacia atrás y los pesos actualizados mediante un algoritmo de gradiente descendente se realizan en el conjunto de entrenamiento.
El conjunto de validación se utiliza para evaluar el modelo y determinar el número de épocas en su entrenamiento. Aumentar el número de épocas reducirá aún más la función de pérdida en el conjunto de entrenamiento, pero no necesariamente tendrá el mismo efecto en el conjunto de validación debido al sobreajuste en el conjunto de entrenamiento, por lo que el número de épocas se controla manteniendo una evaluación y verificación sobre la función de pérdida calculada para el conjunto de validación.
Utilizamos
Kerascon el backendTensorflowpara definir y entrenar el modelo. Todos los pasos implicados en el entrenamiento y validación del modelo se realizan llamando a las funciones apropiadas de laAPIdeKeras.
Los cuatro primeros años, de 2010 a 2013, se utilizan como entrenamiento y 2014 se utiliza para la validación
from sklearn.preprocessing import MinMaxScaler
import datetime
split_date = datetime.datetime(year=2014, month=1, day=1, hour=0)
df_train = df.loc[df['datetime'] < split_date].copy()
df_val = df.loc[df['datetime'] >= split_date].copy()
scaler_pres = MinMaxScaler(feature_range=(0, 1))
df_train['scaled_PRES'] = scaler_pres.fit_transform(df_train[['PRES']])
df_val['scaled_PRES'] = scaler_pres.transform(df_val[['PRES']])
print('Shape of train:', df_train.shape)
print('Shape of val:', df_val.shape)
Shape of train: (35064, 9)
Shape of val: (8760, 9)
df_train.head()
| No | year | month | day | hour | pm2.5 | PRES | datetime | scaled_PRES | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2010 | 1 | 1 | 0 | NaN | 1021.0 | 2010-01-01 00:00:00 | 0.545455 |
| 1 | 2 | 2010 | 1 | 1 | 1 | NaN | 1020.0 | 2010-01-01 01:00:00 | 0.527273 |
| 2 | 3 | 2010 | 1 | 1 | 2 | NaN | 1019.0 | 2010-01-01 02:00:00 | 0.509091 |
| 3 | 4 | 2010 | 1 | 1 | 3 | NaN | 1019.0 | 2010-01-01 03:00:00 | 0.509091 |
| 4 | 5 | 2010 | 1 | 1 | 4 | NaN | 1018.0 | 2010-01-01 04:00:00 | 0.490909 |
df_val.head()
| No | year | month | day | hour | pm2.5 | PRES | datetime | scaled_PRES | |
|---|---|---|---|---|---|---|---|---|---|
| 35064 | 35065 | 2014 | 1 | 1 | 0 | 24.0 | 1014.0 | 2014-01-01 00:00:00 | 0.418182 |
| 35065 | 35066 | 2014 | 1 | 1 | 1 | 53.0 | 1013.0 | 2014-01-01 01:00:00 | 0.400000 |
| 35066 | 35067 | 2014 | 1 | 1 | 2 | 65.0 | 1013.0 | 2014-01-01 02:00:00 | 0.400000 |
| 35067 | 35068 | 2014 | 1 | 1 | 3 | 70.0 | 1013.0 | 2014-01-01 03:00:00 | 0.400000 |
| 35068 | 35069 | 2014 | 1 | 1 | 4 | 79.0 | 1012.0 | 2014-01-01 04:00:00 | 0.381818 |
Restablecemos los índices del conjunto de validación
df_val.reset_index(drop=True, inplace=True)
df_val.head()
| No | year | month | day | hour | pm2.5 | PRES | datetime | scaled_PRES | |
|---|---|---|---|---|---|---|---|---|---|
| 0 | 35065 | 2014 | 1 | 1 | 0 | 24.0 | 1014.0 | 2014-01-01 00:00:00 | 0.418182 |
| 1 | 35066 | 2014 | 1 | 1 | 1 | 53.0 | 1013.0 | 2014-01-01 01:00:00 | 0.400000 |
| 2 | 35067 | 2014 | 1 | 1 | 2 | 65.0 | 1013.0 | 2014-01-01 02:00:00 | 0.400000 |
| 3 | 35068 | 2014 | 1 | 1 | 3 | 70.0 | 1013.0 | 2014-01-01 03:00:00 | 0.400000 |
| 4 | 35069 | 2014 | 1 | 1 | 4 | 79.0 | 1012.0 | 2014-01-01 04:00:00 | 0.381818 |
También se grafican las series temporales de entrenamiento y validación normalizadas para PRES.
plt.figure(figsize=(15, 8))
plt.subplot(1, 2, 1)
g1 = sns.lineplot(df_train['PRES'], color='b')
g1.set_title('Time series of scaled Air Pressure in train set', fontsize=plot_fontsize)
g1.set_xlabel('Index', fontsize=plot_fontsize)
g1.set_ylabel('Scaled Air Pressure readings', fontsize=plot_fontsize);
plt.subplot(1, 2, 2)
g2 = sns.lineplot(df_val['PRES'], color='r')
g2.set_title('Time series of scaled Air Pressure in validation set', fontsize=plot_fontsize)
g2.set_xlabel('Index', fontsize=plot_fontsize)
g2.set_ylabel('Scaled Air Pressure readings', fontsize=plot_fontsize);
plt.show()
Regresores y Variable Objetivo
Ahora necesitamos generar los regresores (\(X\)) y la variable objetivo (\(y\)) para el entrenamiento y la validación. La matriz bidimensional de regresores y la matriz unidimensional objetivo se crean a partir de la matriz unidimensional original de la columna standardized_PRES en el DataFrame.
Para el modelo de predicción de series temporales, de este ejemplo, se utilizan las observaciones de los últimos siete días para predecir el día siguiente. Esto equivale a un modelo \(AR(7)\). Definimos una función que toma la serie temporal original y el número de pasos temporales en regresores como entrada para generar las matrices \(X\) e \(y\)
def makeXy(ts, nb_timesteps):
"""
Input:
ts: original time series
nb_timesteps: number of time steps in the regressors
Output:
X: 2-D array of regressors
y: 1-D array of target
"""
X = []
y = []
for i in range(nb_timesteps, ts.shape[0]):
if i-nb_timesteps <= 4:
print(i-nb_timesteps, i-1, i)
X.append(list(ts.loc[i-nb_timesteps:i-1])) #Regressors
y.append(ts.loc[i]) #Target
X, y = np.array(X), np.array(y)
return X, y
X_train, y_train = makeXy(df_train['scaled_PRES'], 7)
0 6 7
1 7 8
2 8 9
3 9 10
4 10 11
print('Shape of train arrays:', X_train.shape, y_train.shape)
Shape of train arrays: (35057, 7) (35057,)
X_val, y_val = makeXy(df_val['scaled_PRES'], 7)
0 6 7
1 7 8
2 8 9
3 9 10
4 10 11
print('Shape of validation arrays:', X_val.shape, y_val.shape)
Shape of validation arrays: (8753, 7) (8753,)
Ahora definimos la red
MLPutilizando laAPIfuncional deKeras. En este enfoque una capa puede ser declarada como la entrada de la siguiente capa en el momento de definir la siguiente
input_layer = Input(shape=(7,), dtype='float32')
En este caso,
Inputes una función que se utiliza para crear una capa de entrada en un modelo de red neuronal.shape=(7,)específica la forma de los datos de entrada. En este caso, significa que los datos de entrada tendrán 7 dimensiones.dtype='float32'especifica el tipo de datos de los elementos de la capa de entrada. En este caso, son números de punto flotante de 32 bits.
Las capas densas las definimos en esta caso con activación
tanh. Puede utilizar unGridSearchtal como se hizo en el curso de Machine Learning para encontrar hiperparámetros adecuados minimizando las métricas de regresión.
dense1 = Dense(32, activation='tanh')(input_layer)
dense2 = Dense(16, activation='tanh')(dense1)
dense3 = Dense(16, activation='tanh')(dense2)
I0000 00:00:1762220189.807484 6997 cuda_executor.cc:1001] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node
Your kernel may have been built without NUMA support.
I0000 00:00:1762220189.807558 6997 cuda_executor.cc:1001] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node
Your kernel may have been built without NUMA support.
I0000 00:00:1762220189.807588 6997 cuda_executor.cc:1001] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node
Your kernel may have been built without NUMA support.
I0000 00:00:1762220189.972938 6997 cuda_executor.cc:1001] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node
Your kernel may have been built without NUMA support.
I0000 00:00:1762220189.973005 6997 cuda_executor.cc:1001] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node
Your kernel may have been built without NUMA support.
2025-11-03 20:36:29.973014: I tensorflow/core/common_runtime/gpu/gpu_device.cc:2112] Could not identify NUMA node of platform GPU id 0, defaulting to 0. Your kernel may not have been built with NUMA support.
I0000 00:00:1762220189.973057 6997 cuda_executor.cc:1001] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node
Your kernel may have been built without NUMA support.
2025-11-03 20:36:29.993653: I tensorflow/core/common_runtime/gpu/gpu_device.cc:2021] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 9558 MB memory: -> device: 0, name: NVIDIA GeForce RTX 4070, pci bus id: 0000:01:00.0, compute capability: 8.9
Dense e input_layer
Dense: Correspone a una capa totalmente conectada (fully connected).Unidades (Neurons): 32 neuronas.
dense1: Esta capa toma como entradainput_layer, que puede ser la capa de entrada del modelo u otra capa anterior.dense2: Esta capa toma como entrada la salida dedense1. Esto significa que los 32 valores de salida dedense1se usan como entrada paradense2. Similarmente, ocurre condense3
Observación
Las múltiples capas ocultas y el gran número de neuronas en cada capa oculta le dan a las redes neuronales la capacidad de modelar la compleja no linealidad de las relaciones subyacentes entre los regresores y el objetivo. Sin embargo, las redes neuronales profundas también pueden sobreajustar los datos de entrenamiento y dar malos resultados en el conjunto de validación o prueba. La función
Dropoutse ha utilizado eficazmente para regularizar las redes neuronales profundas.
En este ejemplo, se añade una capa
Dropoutantes de la capa de salida. Dropout aleatoriamente establece \(p\) fracción de neuronas de entrada a cero antes de pasar a la siguiente capa. La eliminación aleatoria de entradas actúa esencialmente como un tipo de ensamblaje de modelos de agregaciónbootstrap. Al apagar neuronas aleatoriamente,Dropoutestá forzando a la red a no depender excesivamente de ninguna unidad específica, mejorando la generalización.Por ejemplo, el bosque aleatorio utiliza el ensamblaje mediante la construcción de árboles en subconjuntos aleatorios de características de entrada. Utilizamos \(p=0.2\) para descartar el 20% de las características de entrada seleccionadas aleatoriamente.
dropout_layer = Dropout(0.2)(dense3)
Por último, la capa de salida predice la presión atmosférica del día siguiente
output_layer = Dense(1, activation='linear')(dropout_layer)
Las capas de entrada, densa y de salida se empaquetarán ahora dentro de un modelo, que es una clase envolvente para entrenar y hacer predicciones. Como función de pérdida se utiliza el error cuadrático medio (MSE). Los pesos de la red se optimizan mediante el algoritmo
Adam.Adamsignifica Estimación Adaptativa de Momentos y ha sido una opción popular para el entrenamiento de redes neuronales profundas.A diferencia del Gradiente descendente Estocástico, Adam utiliza diferentes tasas de aprendizaje para cada peso y las actualiza por separado a medida que avanza el entrenamiento. La tasa de aprendizaje de un peso se actualiza basándose en medias móviles ponderadas exponencialmente de los gradientes del peso y los gradientes al cuadrado.
ts_model = Model(inputs=input_layer, outputs=output_layer)
ts_model.compile(loss='mean_squared_error', optimizer='adam')
ts_model.summary()
Model: "functional_1"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ input_layer (InputLayer) │ (None, 7) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense (Dense) │ (None, 32) │ 256 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_1 (Dense) │ (None, 16) │ 528 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_2 (Dense) │ (None, 16) │ 272 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dropout (Dropout) │ (None, 16) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_3 (Dense) │ (None, 1) │ 17 │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 1,073 (4.19 KB)
Trainable params: 1,073 (4.19 KB)
Non-trainable params: 0 (0.00 B)
Observación
En este caso,
Params #es calculado mediante la fórmula:Param # = #Entradas x #Neuronas + #Neuronas. Esto incluye los pesos de cada conexión entre las entradas y las neuronas y un bias para cada neurona. En este casoParams # = 7x32 + 32 = 256.El modelo se entrena llamando a la función
fit()en el objeto modelo y pasándoleX_trainyy_train. El entrenamiento se realiza para un número predefinido de épocas. Además,batch_sizedefine el número de muestras del conjunto de entrenamiento que se utilizarán para una instancia de backpropagation.
El conjunto de datos de validación también se pasa para evaluar el modelo después de cada
epochcompleta. Un objetoModelCheckpointrastrea la función de pérdida en el conjunto de validación y guarda el modelo para la época en la que la función de pérdida ha sido mínima.
save_weights_at = os.path.join('keras_models', 'PRSA_data_Air_Pressure_MLP_weights.{epoch:02d}-{val_loss:.4f}.keras')
save_best = ModelCheckpoint(save_weights_at, monitor='val_loss', verbose=0,
save_best_only=True, save_weights_only=False, mode='min', save_freq='epoch');
Aquí
val_losses el valor de la función de coste para los datos de validación cruzada ylosses el valor de la función de coste para los datos de entrenamiento. Converbose=0, no se imprime ningún mensaje en la consola durante el proceso de guardado del modelo.period=1indica que el modelo se evaluará y potencialmente se guardará después de cada época.
import os
from joblib import dump, load
history_airp = None
if os.path.exists('history_airp.joblib'):
history_airp = load('history_airp.joblib')
print("El archivo 'history_airp.joblib' ya existe. Se ha cargado el historial del entrenamiento.")
else:
history_airp = ts_model.fit(x=X_train, y=y_train, batch_size=16, epochs=20,
verbose=2, callbacks=[save_best], validation_data=(X_val, y_val),
shuffle=True);
dump(history_airp.history, 'history_airp.joblib')
print("El entrenamiento se ha completado y el historial ha sido guardado en 'history_airp.joblib'.")
El archivo 'history_airp.joblib' ya existe. Se ha cargado el historial del entrenamiento.
En este caso, el modo
verbose=2muestra una barra de progreso por cada época. Los modos posibles son:0para no mostrar nada,1para mostrar la barra de progreso,2para mostrar una línea por época. Las muestras se mezclan aleatoriamente antes de cada época (shuffle=True).
Se hacen predicciones para la presión atmosférica a partir del mejor modelo guardado. Las predicciones del modelo sobre la presión atmosférica escalada, se transforman inversamente para obtener predicciones sobre la presión atmosférica original. También se calcula la bondad de ajuste o
R cuadrado.
import os
import re
from tensorflow.keras.models import load_model
model_dir = 'keras_models'
files = os.listdir(model_dir)
pattern = r"PRSA_data_Air_Pressure_MLP_weights\.(\d+)-([\d\.]+)\.keras"
best_val_loss = float('inf')
best_model_file = None
best_model = None
# Buscar el mejor modelo según val_loss
for file in files:
match = re.match(pattern, file)
if match:
epoch = int(match.group(1))
val_loss = float(match.group(2))
if val_loss < best_val_loss:
best_val_loss = val_loss
best_model_file = file
if best_model_file:
best_model_path = os.path.join(model_dir, best_model_file)
print(f"\nCargando el mejor modelo: {best_model_file} (val_loss: {best_val_loss})")
try:
best_model = load_model(best_model_path)
print("Modelo cargado correctamente.")
except Exception as e:
print(f"Error al cargar modelo normalmente: {e}")
print("Intentando cargar con safe_mode=True ...")
try:
best_model = load_model(best_model_path, safe_mode=True, compile=False)
print("Modelo cargado correctamente en modo seguro.")
except Exception as e2:
print(f"No se pudo cargar el modelo ni en modo seguro: {e2}")
best_model = None
else:
print("No se encontraron archivos de modelos que coincidan con el patrón.")
Cargando el mejor modelo: PRSA_data_Air_Pressure_MLP_weights.03-0.0001.keras (val_loss: 0.0001)
Modelo cargado correctamente.
import tensorflow as tf, keras
print(tf.__version__)
print(keras.__version__)
2.17.0
3.2.1
preds = best_model.predict(X_val)
pred_PRES = scaler_pres.inverse_transform(preds)
pred_PRES = np.squeeze(pred_PRES)
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1762220204.091063 7155 service.cc:146] XLA service 0x7464d80052f0 initialized for platform CUDA (this does not guarantee that XLA will be used). Devices:
I0000 00:00:1762220204.091115 7155 service.cc:154] StreamExecutor device (0): NVIDIA GeForce RTX 4070, Compute Capability 8.9
2025-11-03 20:36:44.119000: I tensorflow/compiler/mlir/tensorflow/utils/dump_mlir_util.cc:268] disabling MLIR crash reproducer, set env var `MLIR_CRASH_REPRODUCER_DIRECTORY` to enable.
2025-11-03 20:36:44.480110: I external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:531] Loaded cuDNN version 8907
188/274 ━━━━━━━━━━━━━━━━━━━━ 0s 804us/step
I0000 00:00:1762220205.800996 7155 device_compiler.h:188] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process.
274/274 ━━━━━━━━━━━━━━━━━━━━ 2s 2ms/step
r2 = r2_score(df_val['PRES'].loc[7:], pred_PRES)
print('R-squared for the validation set:', round(r2,4))
R-squared for the validation set: 0.9955
plt.figure(figsize=(5.5, 5.5))
plt.plot(range(50), df_val['PRES'].loc[7:56], linestyle='-', marker='*', color='r')
plt.plot(range(50), pred_PRES[:50], linestyle='-', marker='.', color='b')
plt.legend(['Actual','Predicted'], loc=2)
plt.title('Actual vs Predicted Air Pressure')
plt.ylabel('Air Pressure')
plt.xlabel('Index');
11.15. Proyecto Integrador de Deep Learning#
Objetivo
El proyecto busca predecir una variable temporal de interés, como el precio de cierre de criptomonedas o la velocidad del viento, utilizando exclusivamente su histórico temporal (por ejemplo, fecha y valores observados). Para ello, se emplea la librería timeseries-cv, junto con estrategias de validación temporal, una red neuronal tipo MLP y un análisis riguroso de residuos.
Adicionalmente, se propone construir, validar y desplegar un modelo robusto de deep learning, orientado tanto a la predicción del nivel de la serie como a la modelación de su volatilidad o variabilidad, partiendo únicamente de observaciones históricas.
El flujo de trabajo incluye:
Exploración y caracterización de la variabilidad de la serie
Construcción de ventanas temporales
Validación cruzada para datos secuenciales
Evaluación mediante métricas específicas
Análisis de residuos
Todo ello con el objetivo final de su despliegue en un entorno de MLOps.
Contexto
Las series temporales asociadas a criptomonedas y a variables ambientales como la velocidad del viento comparten características fundamentales como:
Alta variabilidad
No linealidad
Dependencia temporal compleja
Posibles cambios de régimen
Estas propiedades representan tanto un desafío como una oportunidad para el desarrollo de modelos predictivos avanzados. En el caso de las criptomonedas, la alta volatilidad impacta directamente en:
Trading algorítmico
Gestión de portafolios
Estimación de riesgos
Por su parte, en el ámbito energético y ambiental, la predicción de la velocidad del viento es clave para:
Planificación de sistemas de generación eólica
Optimización operativa
Gestión de incertidumbre en energías renovables
En ambos contextos, si bien la predicción puntual de la serie es relevante, modelar y anticipar la variabilidad o volatilidad proporciona una base más robusta para la toma de decisiones bajo incertidumbre.
Por ello, el forecasting de series temporales, cuando se aborda de manera rigurosa, reproducible y orientada a datos reales, se consolida como una tarea central en la ciencia de datos aplicada tanto a sistemas financieros como a sistemas energéticos y ambientales.
Datasets recomendados:
Fuente: Binance Public API. API gratuita, sin registro, y es la fuente más citada en literatura académica de alta frecuencia. Seleccione la criptomoneda de su interés para esta tarea o el dataset de velocidad del viento. Ejemplo de uso de la API de Binance
import requests, pandas as pd, time
from datetime import datetime
def get_binance_1m(symbol="BTCUSDT", start="2024-01-01", end="2024-01-31"):
url = "https://api.binance.com/api/v3/klines"
start_ms = int(datetime.strptime(start, "%Y-%m-%d").timestamp() * 1000)
end_ms = int(datetime.strptime(end, "%Y-%m-%d").timestamp() * 1000)
all_data = []
while start_ms < end_ms:
params = {
"symbol": symbol,
"interval": "1m",
"startTime": start_ms,
"endTime": end_ms,
"limit": 1000
}
r = requests.get(url, params=params)
data = r.json()
if not data: break
all_data.extend(data)
start_ms = data[-1][0] + 60000 # avanza 1 minuto
time.sleep(0.1) # evita rate limit
df = pd.DataFrame(all_data, columns=[
"open_time","open","high","low","close","volume",
"close_time","quote_volume","trades",
"taker_buy_base","taker_buy_quote","ignore"
])
df["open_time"] = pd.to_datetime(df["open_time"], unit="ms")
df[["open","high","low","close","volume"]] = \
df[["open","high","low","close","volume"]].astype(float)
return df[["open_time","open","high","low","close","volume","trades"]]
df = get_binance_1m("BTCUSDT", "2024-01-01", "2024-03-31")
df.to_csv("btc_1m_Q1_2024.csv", index=False)
print(df.shape)
Frecuencia: 1 minuto.
Variable clave: Precio de Cierre (
Close)Cálculo de la volatilidad: definición formal y ejemplo:
La volatilidad es una medida de dispersión de los rendimientos de un activo financiero.
Para una ventana de tamaño \(n\):
\[ \sigma_t = \sqrt{ \frac{1}{n} \sum_{i=1}^{n} (r_{t-i} - \bar{r})^2},~\text{donde}~r_t = \ln\left(\frac{P_t}{P_{t-1}}\right) \]\(P_t\): Precio de cierre en el día \(t\)
\(r_t\): Retorno logarítmico diario
\(\sigma_t\): Volatilidad histórica realizada en ventana de \(n\) días
\(\bar{r}\): Promedio de los retornos en la ventana
Datos del INMET - National Institute of Meteorology relacionados con velocidad del viento. La variable respuesta en este caso es la velocidad de viento suministrada de forma horaria por INMET. Debe seleccionar solo un dataset, el de velocidad del viento o el de criptomonedas.
Actividades a desarrollar. Cada resultado debe ir acompañado de análisis, justificación y visualización/tablas cuando sea relevante.
Análisis Exploratorio de Datos (EDA)
Estadísticas descriptivas de precios y retornos.
Visualizaciones: serie de precios, retornos diarios, histograma de retornos, autocorrelación (ACF) y ACF de cuadrados (para heterocedasticidad).
Preprocesamiento y cálculo de features
Cálculo de retornos logarítmicos.
Cálculo de volatilidad histórica (rolling std) para inspección (variable objetivo alternativa).
Generación de lags del precio (ventanas previas) para los siguientes tamaños: 7, 14, 21, 28 días.
Generación de targets multi-step: horizonte de 7 días (salida multisalida de longitud 7).
Split temporal y validación cruzada
Usar
split_train_val_test_groupKFold(de timeseries-cv / tsxv) para crear splits train / val / test sin data leakage.Escalado: fit del scaler solo con el train en cada fold; transformar val/test con ese scaler.
Modelado con Deep Learning
Entrenar MLP multisalida (por ejemplo
MLPRegressoro un keras MLP con salida 7) fold a fold.Guardar por fold: predicciones para train, val y test (todas las muestras del fold).
Evaluación: calcular métricas por horizonte (1..7) y agregadas (promedio sobre horizontes).
Métricas obligatorias — tablas por tamaño de input
Por cada tamaño de input (7, 14, 21, 28) se debe entregar una tabla (en el conjunto de test) que incluya, idealmente por fold y con su promedio (y std):
MAPE (Mean Absolute Percentage Error) — por horizonte y promedio.
MAE (Mean Absolute Error).
RMSE (Root Mean Squared Error).
MSE (Mean Squared Error).
\(p\)-value BDS test aplicado a los residuos del primer horizonte (\(h=1\)) (por fold) — y su promedio.
Formato recomendado de la tabla (por lag):
Filas = folds (Fold 1, Fold 2, … , Mean ± Std).
Columnas = métricas por horizonte (\(h=1,\dots,7\)) o resumen por horizonte + columna con BDS_pvalue_h1.
Diagnóstico de residuos
En cada fold, calcular residuos en test \(\text{resid} = y_{test}^{\text{real}} - y_{pred}\)
Aplicar BDS test a los residuos del horizonte 1 (test de independencia serial / no-iid).
Reportar el \(p\)-value.
Interpretación: \(p > 0.05\) → no rechazo de iid (mejor señal de independencia residual).
Visualización y análisis
Para cada tamaño de input:
Dibujar una curva (time series) que muestre train / val / test (validados con sus timestamps) y las predicciones correspondientes (por lo menos para el mejor fold, el peor fold y el fold mediano por RMSE).
Etiquetar claramente: train actual, train predicho, val actual, val predicho, test actual, test predicho.
Gráfica de RMSE por fold (e.g., barras) y RMSE promedio por horizonte (líneas con 7 puntos).
Tabla resumen comparativa de los 4 tamaños de lag con las métricas solicitadas (MAPE, MAE, RMSE, MSE, p-value BDS).
Guardar figuras en
notebooks/figs/y las tablas enresults/(CSV).Documentación y deployment
Entregar notebook reproducible con todo el pipeline (EDA → features → CV → entrenamiento → evaluación → residuos → plots).
Entregar API (
app/api.py) que reciba lags y devuelva 7 predicciones de volatilidad (lista de floats).Incluir Dockerfile, tests unitarios y README con instrucciones de uso.
Utilice las siguientes instrucciones solo como borrador, para más detalles ver la librería timeseries-cv y las instrucciones dadas anteriormente
Descarga y preparación de datos
import yfinance as yf
import pandas as pd
import numpy as np
import pandas as pd
btc = pd.read_csv('btc_1d_data_2018_to_2025.csv')
btc = btc[['Date', 'Close']].dropna().reset_index(drop=True)
btc['Close'] = btc['Close'].astype(float)
btc['LogReturn'] = np.log(btc['Close'] / btc['Close'].shift(1))
window_size = 30 #Editar de acuerdo al problema
btc['Volatility'] = btc['LogReturn'].rolling(window=window_size).std() * np.sqrt(365) # Anualizada
btc = btc.dropna().reset_index(drop=True)
y_full = btc['Close'].values
volatility_full = btc['Volatility'].values
print(btc[['Date', 'Close', 'LogReturn', 'Volatility']].head())
Validación cruzada de series de tiempo (
timeseries-cv)
from tsxv.splitTrainValTest import split_train_val_test_groupKFold
lags_list = [7, 14, 21, 28] # Diferentes ventanas a probar
n_steps_forecast = 7 # Predicción para 7 días adelante
n_steps_jump = 1 # Saltar de a 1 ventana
results_lags = {}
for n_steps_input in lags_list:
print(f"\n===== Usando {n_steps_input} días previos como input =====")
# Split de datos por cada ventana (GroupKFold temporal)
X, y, Xcv, ycv, Xtest, ytest = split_train_val_test_groupKFold(
timeSeries, #Reemplazar por lo que corresponda
n_steps_input=n_steps_input,
n_steps_forecast=n_steps_forecast,
n_steps_jump=n_steps_jump
)
rmse_test_fold = []
bds_p_fold = []
for fold in range(len(X)):
# Escalar solo con train
scaler_x = StandardScaler().fit(X[fold])
scaler_y = StandardScaler().fit(y[fold])
X_train = scaler_x.transform(X[fold])
X_val = scaler_x.transform(Xcv[fold])
X_test = scaler_x.transform(Xtest[fold])
y_train = scaler_y.transform(y[fold])
y_val = scaler_y.transform(ycv[fold])
y_test = scaler_y.transform(ytest[fold])
# Modelo MLP multistep
model = MLPRegressor(hidden_layer_sizes=(64,32), max_iter=300, random_state=fold)
model.fit(X_train, y_train)
yhat_test = scaler_y.inverse_transform(model.predict(X_test))
ytest_real = scaler_y.inverse_transform(y_test)
# RMSE por cada horizonte
rmse_h = np.sqrt(np.mean((ytest_real - yhat_test)**2, axis=0))
rmse_prom = np.mean(rmse_h)
rmse_test_fold.append(rmse_prom)
# Test BDS (solo horizonte 1)
resid_h1 = ytest_real[:,0] - yhat_test[:,0]
bds_result = bds(resid_h1, max_dim=2)
pval = bds_result.iloc[1]['p-value'] if hasattr(bds_result, 'iloc') else bds_result['p-value'][1]
bds_p_fold.append(pval)
# Guardar resultados por ventana
results_lags[n_steps_input] = {
'rmse_test_fold': rmse_test_fold,
'rmse_test_avg': np.mean(rmse_test_fold),
'bds_p_fold': bds_p_fold,
'bds_p_avg': np.mean(bds_p_fold)
}
print(f"RMSE test promedio ({n_steps_input} lags): {np.mean(rmse_test_fold):.4f}")
print(f"BDS p-valor promedio (h1): {np.mean(bds_p_fold):.4f}")
plt.figure(figsize=(10,4))
for n_steps_input in lags_list:
plt.plot(results_lags[n_steps_input]['rmse_test_fold'], label=f'{n_steps_input} lags')
plt.title("RMSE promedio (7-step) test por fold")
plt.xlabel("Fold"); plt.ylabel("RMSE ($)")
plt.legend(); plt.show()
import pandas as pd
tabla_summary = pd.DataFrame(
[[n, results_lags[n]['rmse_test_avg'], results_lags[n]['bds_p_avg']] for n in lags_list],
columns=['# lags', 'avg RMSE test (7-step)', 'avg BDS p-valor (h1)']
)
print(tabla_summary)
Test BDS de independencia serial en residuos de test
from arch.bootstrap import bds
for ix in range(len(X_train)):
resid = dict_rmse[str(ix)]['resid_test']
resultado_bds = bds(resid, max_dim=2)
print(f"Test BDS residuos - Fold {ix+1}:\n{resultado_bds}\n")
# Si p-value > 0.05: residuos independientes (buen modelo temporal)
Visualización de desempeño
import matplotlib.pyplot as plt
rmse_train_list = [dict_rmse[str(i)]['rmse_train'] for i in range(len(dict_rmse))]
rmse_val_list = [dict_rmse[str(i)]['rmse_val'] for i in range(len(dict_rmse))]
rmse_test_list = [dict_rmse[str(i)]['rmse_test'] for i in range(len(dict_rmse))]
plt.plot(rmse_train_list, label='Train')
plt.plot(rmse_val_list, label='Val')
plt.plot(rmse_test_list, label='Test')
plt.xlabel('Fold')
plt.ylabel('RMSE ($)')
plt.title("RMSE por fold (Solo series históricas, univariadas)")
plt.legend()
plt.show()
Muestra, en un fold de test, la predicción vs el valor real:
ix = np.argmin(rmse_test_list)
plt.plot(y_test[ix], label='Real')
plt.plot(dict_rmse[str(ix)]['rmse_test'] + y_test[ix]*0, label='MLP Predicho (solo lags precio)')
plt.legend()
plt.title(f"Real vs Predicho - Mejor Fold Test (ix={ix}) (Solo Precio)")
plt.show()
Instrucciones para el entorno de MLOps
Para construir el entorno de MLOps correspondiente al problema planteado (predicción multistep del nivel y/o volatilidad de una serie temporal, como el precio de criptomonedas o la velocidad del viento), es necesario instalar las bibliotecas asociadas al modelado temporal, deep learning, validación cruzada temporal y análisis de residuos.
python -m pip install --force-reinstall pydantic
python -m pip install fastapi[all]
python -m pip install joblib
python -m pip install pandas
python -m pip install scikit-learn
python -m pip install matplotlib
python -m pip install tsxv
python -m pip install arch
Estructura general del proyecto
time-series-mlops/
├── data/
│ └── dataset.csv # Serie temporal (crypto o viento)
├── notebooks/
│ ├── 1_eda.ipynb # Exploración y análisis de la serie
│ ├── 2_model_training.ipynb # Entrenamiento MLP con validación temporal
│ ├── 3_residual_analysis.ipynb # Diagnóstico de residuos
├── app/
│ ├── api.py # API para inferencia
│ ├── schemas.py # Modelos Pydantic
│ └── model.joblib # Modelo entrenado (MLP multi-output)
├── tests/
│ ├── test_api.py # Pruebas unitarias de la API
│ └── test_model.py # Validación del modelo
├── Dockerfile
├── requirements.txt
├── .github/workflows/
│ └── ci.yml # CI/CD
└── README.md
API con FastAPI (
api.py)
from fastapi import FastAPI
from pydantic import BaseModel
import joblib
import numpy as np
app = FastAPI()
model = joblib.load("app/model.joblib")
class TimeSeriesData(BaseModel):
lags: list[float] # Ventanas históricas (ej. últimos valores observados)
@app.post("/predict")
def predict(data: TimeSeriesData):
features = np.array(data.lags).reshape(1, -1)
prediction = model.predict(features)[0]
return {"prediction": prediction.tolist()}
Dockerfile
FROM python:3.10-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY app/ ./app/
COPY data/ ./data/
EXPOSE 8000
CMD ["uvicorn", "app.api:app", "--host", "0.0.0.0", "--port", "8000"]
requirements.txt
fastapi>=0.95.0
uvicorn
scikit-learn
pandas
numpy
joblib
matplotlib
tsxv
arch
CI/CD con GitHub Actions
name: CI Pipeline
on: [push, pull_request]
jobs:
test:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
- name: Set up Python
uses: actions/setup-python@v4
with:
python-version: 3.10
- name: Install dependencies
run: |
pip install -r requirements.txt
pip install pytest flake8
- name: Run Linter
run: flake8 app/ --ignore=E501,W503
- name: Run Tests
run: pytest tests/
Pruebas unitarias del modelo
import joblib
import numpy as np
def test_model_prediction_shape():
model = joblib.load("app/model.joblib")
X_test = np.random.rand(5, 7)
y_pred = model.predict(X_test)
assert y_pred.shape == (5, 7)
def test_prediction_values():
model = joblib.load("app/model.joblib")
X = np.random.rand(1, 7)
y_pred = model.predict(X)[0]
assert len(y_pred) == 7
assert all(isinstance(v, (float, np.floating)) for v in y_pred)
Pruebas unitarias de la API
from fastapi.testclient import TestClient
from app.api import app
client = TestClient(app)
def test_predict_endpoint():
response = client.post("/predict", json={"lags": [1.0, 1.2, 1.1, 1.3, 1.25, 1.28, 1.35]})
assert response.status_code == 200
data = response.json()
assert "prediction" in data
assert isinstance(data["prediction"], list)
assert len(data["prediction"]) == 7
Prueba local con curl
curl -X POST http://localhost:8000/predict \
-H "Content-Type: application/json" \
-d '{"lags": [1.0, 1.2, 1.1, 1.3, 1.25, 1.28, 1.35]}'
Salida esperada:
{
"prediction": [
0.12,
0.11,
0.10,
0.09,
0.08,
0.07,
0.06
]
}
11.16. Redes Neuronales Convolucionales#
Introducción
Hasta ahora, las redes neuronales se han considerado como receptoras de vectores de características en su capa de entrada, similar a otros clasificadores discutidos anteriormente. Estos vectores se derivan de datos brutos para condensar información relevante para la tarea de aprendizaje automático. Sin embargo, a finales de los años 80, surgió un enfoque alternativo: integrar la generación de características en el entrenamiento de la red neuronal.
Así nacieron las Redes Neuronales Convolucionales (CNN), que aprenden características directamente de los datos junto con los parámetros de la red. Su éxito inicial fue en el reconocimiento de dígitos OCR [LeCun et al., 1989]. El término “convolucional” se refiere a que la primera capa realiza convoluciones en lugar de productos internos, usados en redes totalmente conectadas.
11.16.1. La necesidad de convoluciones#
Asegurémonos primero de que entendemos la razón por la que no podemos, en la práctica, alimentar la entrada de una red neuronal directamente con datos brutos, por ejemplo, una matriz de imágenes o las muestras de una versión digitalizada de un segmento de voz, y por qué es necesario un preprocesamiento para generar características. Lo mismo ocurre para cualquier predictor/aprendiz y no sólo para las redes neuronales. En muchas aplicaciones, trabajar directamente con los datos en bruto hace que la tarea sea sencillamente inmanejable.
Una imagen de \(256 \times 256\) se vectoriza como \(\boldsymbol{x} \in \mathbb{R}^{65000}\). Si la primera capa tiene \(k_1 = 1000\) nodos, una red totalmente conectada requeriría aproximadamente 65 millones de parámetros \(\theta_{jk}\), con \(j = 1, \dots, 65000\) y \(k = 1, \dots, 1000\). Esta cantidad crece considerablemente con imágenes de mayor resolución (\(1000 \times 1000\)) o a color, donde la entrada se triplica al emplear el modelo RGB.
A medida que se incrementan las capas ocultas, también crece el número de parámetros, lo que eleva la carga computacional y compromete la capacidad de generalización, requiriendo grandes volúmenes de datos para evitar el sobreajuste. Además, vectorizar matrices de imágenes implica pérdida de información, al ignorar relaciones espaciales entre píxeles. Por ello, los métodos de generación de características buscan extraer dependencias estadísticas que capturen dichas correlaciones y permitan codificar eficazmente la información relevante para el aprendizaje.
Al emplear convoluciones, se pueden abordar simultáneamente ambos problemas, es decir, el de la explosión de parámetros y el de la extracción de información estadística útil. Los pasos básicos de cualquier red convolucional son:
la etapa de convolución,
el paso de no linealidad,
el paso de agrupación.
11.16.2. La etapa de convolución#
Una forma de reducir el número de parámetros es mediante el reparto de pesos. Ahora tomaremos prestada esta idea del reparto de pesos y la utilizaremos de una forma más sofisticada. Para ello, nos centraremos en el caso en que la entrada de la red esté formada por imágenes. La imagen matricial de entrada se denomina \(I\).
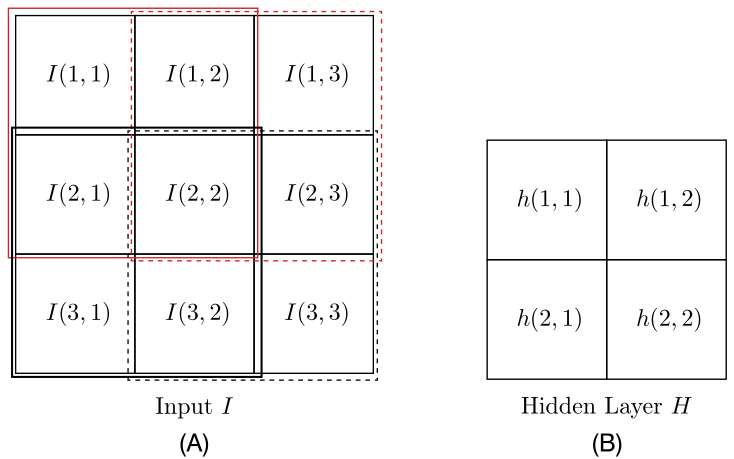
Fig. 11.21 (A) Imagen matricial de entrada de \(3\times 3\). (B) Nodos de la capa oculta.#
Para el caso de la Fig. 11.21, se trata de una matriz de 3 × 3; nótese que la entrada es no vectorizada. Para enfatizar que nos apartaremos de la lógica de las operaciones de multiplicar-añadir (producto interno) de las redes feed-forward completamente conectadas, utilizaremos un símbolo diferente \(h\) en lugar de \(\theta\), para denotar los parámetros asociados.
Introducimos ahora el concepto de reparto de pesos. Recordemos que en una red totalmente conectada, cada nodo está asociado con un vector de parámetros, \(\boldsymbol{\theta}_{i}\), para el nodo \(i\)th cuya dimensionalidad es igual al número de nodos de la capa anterior. En cambio, ahora cada nodo estará asociado a un único parámetro. Para ello, dispondremos los nodos en forma de matriz bidimensional, como se muestra en Fig. 11.21 (B). Para el caso de la figura, hemos supuesto cuatro nodos dispuestos en una matriz de 2 × 2, \(H\).
Observación
El primer nodo se caracteriza por \(h(1, 1)\), el segundo por \(h(1, 2)\), y así sucesivamente. En otras palabras, cualquier conexión que termine en el primer nodo se multiplicará por el mismo peso \(h(1, 1)\), y un argumento similar es válido para el resto de los nodos. Este razonamiento reduce drásticamente el número de parámetros. Sin embargo, para que esto tenga sentido, tenemos que alejarnos de la lógica de las operaciones de producto interior de las redes totalmente conectadas.
Para entender por qué, supongamos que utilizamos un único parámetro por nodo en una red totalmente conectada. Entonces, la salida del combinador lineal asociado al primer nodo sería \(O(1, 1) = h(1, 1)a\), donde \(a\) es la suma de todas las entradas al nodo recibidas de la capa anterior. La salida respectiva del segundo nodo sería \(O(1, 2) = h(1, 2)a\), y así sucesivamente. Por lo tanto, todos los nodos proporcionarían básicamente la misma información con respecto a los valores de entrada; la única diferencia serían los distintos pesos que actúan sobre la misma información de entrada de la capa anterior.
Pasemos ahora a introducir un concepto diferente, en el que mantenemos un único parámetro por nodo, aunque cada una de las salidas de una capa oculta transmite información diferente con respecto a las distintas entradas que se reciben de la capa anterior.
Para ello, introduciremos las convoluciones. En este contexto, los nodos de la capa oculta se interpretan como elementos de una matriz \(H\), y convolucionamos \(H\) con la matriz de entrada entrada \(I\). El primer valor de salida de la capa oculta será
El resultado anterior se obtiene si colocamos la matriz \(H\) de \(2\times2\) sobre \(I\), empezando por la esquina superior izquierda (el cuadrado rojo de Fig. 11.21(A) indica la posición de la matriz \(H\)). A continuación, multiplicamos los elementos en las partes superpuestas de las dos matrices y los sumamos. Desde un punto de vista físico, el valor \(O(1, 1)\) resultante es una media ponderada sobre un área local dentro de la matriz \(I\).
En la operación anterior, el área correspondiente de la imagen está formada por los píxeles de la parte superior izquierda 2 × 2 de la matriz \(I\). Para obtener el segundo valor de salida, \(O(1, 2)\), deslizamos \(H\) un píxel hacia la derecha, como indica el recuadro rojo punteado, y repetimos las operaciones, es decir
Siguiendo el mismo razonamiento, deslizamos \(H\) para “escanear” toda la imagen matricial; así, se obtienen otros dos valores de salida \(O(2, 1)\) y \(O(2, 2)\). Las cuatro posiciones posibles de \(H\) encima de \(I\) se indican en la Fig. 11.21(A) por los cuadros cuadrados de color rojo completo, rojo punteado, gris oscuro y gris punteado. Para cada posición se obtiene un valor de salida. Por lo tanto, bajo el escenario descrito anteriormente, las salidas de la primera capa oculta forman una matriz de \(2\times 2\), \(O\). Cada uno de los elementos de la matriz de salida codifica información de un área diferente de la imagen de entrada.
Convolución
En el entorno más general, la operación de convolución entre dos matrices, \(H\in R^{m\times m}\) e \(I\in\mathbb{R}^{l\times l}\), es otra matriz, definida como
En otras palabras, \(O(i, j)\) contiene información en un área de ventana de la matriz de entrada. De acuerdo con la definición de la Eq. (11.11) el elemento \(I(i, j)\) es el elemento superior izquierdo de esta área de la ventana. El tamaño de la ventana depende del valor de \(m\). El tamaño de la matriz de salida depende de las suposiciones que se adopten sobre cómo tratar los elementos/píxeles en los bordes de \(I\).
En sentido estricto, en la jerga del procesamiento de señales, la Eq. (11.11) se conoce como operación de correlación cruzada. Para la operación de convolución, primero hay que invertir los índices. Sin embargo, este es el nombre que ha “sobrevivido” en la comunidad del aprendizaje automático y bien nos adherimos a él. Al fin y al cabo, ambas son operaciones ponderadas sobre los píxeles dentro de un área de ventana de una imagen.
Observation 11.1
La discusión anterior nos “obliga” a pensar en una capa oculta como una colección de nodos uno al lado del otro. En cambio, en una CNN, cada capa oculta corresponde a una (o a más de una, como pronto veremos) matriz \(H\). Además, \(H\) se utiliza para realizar convoluciones.
Desde el punto de vista del tratamiento de señales, esta matriz es un
filtro que actúa sobre la entrada para proporcionar la salida.En la jerga del aprendizaje de maquinas, también se denomina matriz kernel en lugar de filtro. La matriz de salida suele denominarse la matriz del mapa de características.
En resumen, al realizar convoluciones, en lugar de operaciones de producto interno, hemos conseguido
Los parámetros que componen la capa oculta son compartidos por todos los píxeles de entrada y no tenemos un conjunto dedicado de parámetros por elemento de entrada (píxel)
Las salidas de la capa oculta
codifican la información de correlación de vecindad local de las distintas zonas de la imagen de entrada.Además, como la salida de la capa oculta también es una matriz de imágenes, se puede considerar como la entrada a una segunda capa oculta y construir así una red con muchas capas, cada una de las cuales realiza convoluciones.
De hecho, estas operaciones de filtrado se han utilizado tradicionalmente para generar características a partir de imágenes. La diferencia era que los elementos de la matriz de filtrado se preseleccionaban. Tomemos ejemplo, la siguiente matriz:
El filtro anterior se conoce como detector de bordes. Convolucionando una matriz de imagen, \(I\) , con la matriz anterior, \(H\),detecta los bordes de una imagen. La Fig. 11.22A muestra la imagen de un barco y la Fig. 11.22B muestra la salida después del filtrado de la imagen de la izquierda con la matriz de filtrado \(H\) anterior.

Fig. 11.22 (A) Imagen original y (B) Bordes de la imagen extraídos tras filtrar la matriz de la imagen original con el filtro \(H\) de la ecuación Eq. (11.12). Fuente [Theodoridis, 2020].#
La detección de bordes es de gran importancia en la comprensión de imágenes. Además, cambiando adecuadamente los valores en \(H\), se pueden detectar bordes en diferentes orientaciones, por ejemplo, diagonal, vertical, horizontal; en otras palabras, cambiando los valores de \(H\) se pueden generar diferentes tipos de características.
from skimage.color import rgb2gray
from skimage.io import imread
import numpy as np
from scipy import signal
import matplotlib.pylab as pylab
im = rgb2gray(imread('imgs/cameraman.jpg')).astype(float)
print(im.shape, np.max(im))
(256, 256) 0.9921568627450982
blur_box_kernel = np.ones((3,3)) / 9
edge_laplace_kernel = np.array([[0,1,0],[1,-4,1],[0,1,0]])
edge_laplace_kernel
array([[ 0, 1, 0],
[ 1, -4, 1],
[ 0, 1, 0]])
im_blurred = signal.convolve2d(im, blur_box_kernel)
im_edges = np.clip(signal.convolve2d(im, edge_laplace_kernel), 0, 1)
fig, axes = pylab.subplots(ncols=3, sharex=True, sharey=True, figsize=(18, 6))
axes[0].imshow(im, cmap=pylab.cm.gray)
axes[0].set_title('Original Image', size=20)
axes[1].imshow(im_blurred, cmap=pylab.cm.gray)
axes[1].set_title('Box Blur', size=20)
axes[2].imshow(im_edges, cmap=pylab.cm.gray)
axes[2].set_title('Laplace Edge Detection', size=20)
for ax in axes:
ax.axis('off')

Nos hemos acercado a la idea que subyace a las CNN
En lugar de utilizar una matriz de filtro/núcleo fija, como en el ejemplo del detector de bordes,
deje el cálculo de los valores de la matriz de filtro, \(H\) ,para la fase de entrenamiento. En otras palabras, hacemos que \(H\) se adapte a los datos y no preseleccionada.En lugar de utilizar una única matriz de filtros, empleamos más de una. Cada una de ellas generará un tipo diferente de características. Por ejemplo, una puede generar bordes diagonales, la otra horizontales, etc. Por lo tanto, cada capa oculta comprenderá más de una matriz de filtrado. Los valores de los elementos de cada una de
las matrices de filtrado se calcularán durante la fase de entrenamiento, optimizando algún criterio. En otras palabras, cada capa oculta de una CNN genera un conjunto de características de forma óptima.
Fig. 11.23 Ilustración de tres filtros/núcleos. Profundidad de la capa oculta (número de filtro) es tres. Fuente [Theodoridis, 2020].#
La Fig. 11.23 ilustra la entrada y la primera capa oculta de una CNN. La entrada comprende una matriz imagen. La capa oculta consta de tres matrices de filtrado, a saber, \(H_{1}, H_{2}, H_{3}\). Nótese que cada matriz es el resultado de convolucionar una matriz de filtros diferente sobre la imagen de entrada. Cuantos más filtros se empleen, más mapas de características se extraerán y, en principio, mejor será el rendimiento de la red.
Sin embargo, cuantos más filtros utilicemos, más parámetros habrá que aprender, lo que plantea problemas computacionales y de sobreajuste. Nótese que cada píxel de una matriz de mapeo de características de salida codifica información dentro del área de la ventana que está definida por la posición correspondiente de la respectiva matriz de filtro.
11.16.3. Ejemplo de uso de Múltiples Kernels en una CNN#
En una Red Neuronal Convolucional (CNN), cada kernel se aplica simultáneamente a la imagen de entrada, generando un mapa de características (feature map).
Proceso de Aplicación
Cada kernel detecta distintos patrones como bordes o texturas.
Cada filtro genera su propio mapa de características, reduciendo dimensiones según el tamaño del kernel, stride y padding.
El resultado es un volumen de salida de tamaño \(H' \times W' \times N\), donde \(N\) es el número de filtros (kernels).
Ejemplo con Tres Kernels: Si una imagen RGB de \(32 \times 32 \times 3\) se procesa con tres kernels de \(3 \times 3 \times 3\), la salida será: \(30 \times 30 \times 3\)
Conclusión: Cada kernel opera en paralelo, generando su propio mapa de características. El número de filtros define la profundidad de la salida. Las dimensiones dependen de los hiperparámetros de convolución.
Observation 11.2
Una característica importante de una CNN es que la invarianza de traslación (
reconoce patrones en una imagen sin importar dónde se encuentren esos patrones) está integrada de forma natural en la red y es un subproducto de las circunvoluciones implicadas. De hecho, estas últimas se realizan deslizando la misma matriz de filtros sobre toda la imagen.Así, si un objeto presente en una imagen se coloca en otra posición, la única diferencia sería que la contribución de este objeto a la salida también se desplazará la misma cantidad en el número de píxeles.
Es interesante señalar que existen pruebas sólidas en el campo de la neurociencia visual de que en el ser humano se realizan cálculos similares. (ver [Hubel and Wiesel, 1962, Serre et al., 2007]). La noción de convoluciones fue usada inicialmente por [Fukushima et al., 1983] en el contexto del aprendizaje no supervisado.
A continuación, presentamos algunos términos de la jerga utilizada en relación con las CNN:
Profundidad: La profundidad de una capa es el número de matrices de filtro que se emplean en esta capa. No debe confundirse profundidad de la red, que corresponde al número total de capas ocultas utilizadas. A veces, nos referimos al número de filtros como el número de canales.Campo receptivo: Cada píxel de una matriz de características de salida resulta como una media ponderada de los píxeles dentro de un área específica de la matriz imagen de entrada (o de la salida de la capa anterior). El área específica que corresponde a un píxel se conoce como su campo receptivo (ver Fig. 11.23).Deslizamiento(stride): En la práctica, en lugar de deslizar la matriz de filtros de píxel en píxel, se puede deslizar, por ejemplo, \(s\) píxeles. Este valor se conoce como stride. Para valores de \(s > 1\), se obtienen matrices de mapas de características de menor tamaño. Esto se ilustra en Fig. 11.24A y B.
Fig. 11.24 Matriz de entrada y filtro de tamaños 5 × 5 y 3 × 3 respectivamente. En (A), el paso es igual a \(s = 1\) y en (B) es igual a \(s = 2\). En (A) la salida es una matriz de tamaño 3 × 3 y en (B) de tamaño 2 × 2. Fuente [Theodoridis, 2020].#
Relleno de ceros(padding): A veces, se utilizan ceros para rellenar la matriz de entrada alrededor de los píxeles del borde. De esta forma, la dimensión de la matriz aumenta. Si la matriz original tiene dimensiones \(l\times l\), después de expandirla con \(p\) columnas y filas, las nuevas dimensiones pasan a ser (\(l + 2p\)). Esto se muestra en la Fig. 11.25.

Fig. 11.25 Ejemplo en el que la matriz original es de 5 × 5 y tras rellenarla con \(p = 2\) filas y columnas, su tamaño pasa a ser de 9 × 9. Fuente [Theodoridis, 2020].#
Término de sesgo: Tras cada convolución que genera un píxel en el mapa de características, se añade un sesgo común a todos los píxeles de dicho mapa, calculado durante el entrenamiento. Esto sigue la lógica de compartir parámetros, como ocurre con los filtros en la imagen de entrada..
Se puede ajustar el tamaño de una matriz de mapa de características de salida ajustando el valor del stride, \(s\), y el número de columnas y filas cero adicionales en el relleno. En general, se puede comprobar fácilmente que si \(I\in\mathbb{R}^{l\times l}, H\in\mathbb{R}^{m\times m}\), y \(p\) es el número de filas y columnas adicionales para el relleno, entonces el mapa de características tiene dimensiones \(k\times k\), donde
(11.13)#\[ k=\lfloor\frac{l+2p-m}{s}+1\rfloor, \]y \(\lfloor\cdot\rfloor\) es el operador suelo, i.e \(\lfloor2.7\rfloor=2\).
Por ejemplo, si \(l = 5, m = 3, p = 0\) y \(s = 1\), entonces \(k = 3\). Por otro lado, si \(l = 5, m = 3, p = 0\) y \(s = 2\), entonces \(k = 2\) (ver Fig. 11.24A y B). Nótese que si los valores de \(l, m, p\) y \(s\) son tales que la matriz de filtrado, al deslizarse sobre \(I\), cae fuera de \(I\), estas operaciones no se realizan. Solo realizamos operaciones mientras la matriz filtro esté contenida dentro de \(I\).
11.16.4. El paso de la no linealidad#
Una vez que se han realizado las convoluciones y se ha añadido el término de sesgo a todos los valores del mapa de características, el siguiente paso es
aplicar una no linealidad (función de activación) a cada uno de los píxeles de cada matrizde mapas de características.Se puede emplear cualquiera de las no linealidades que se han comentado anteriormente. Actualmente, la función de activación lineal rectificada,
ReLU, es la más popular.
Show code cell source
import numpy as np
import matplotlib.pyplot as plt
def relu(x):
return np.maximum(0, x)
x = np.linspace(-10, 10, 100)
y = relu(x)
plt.plot(x, y, label='ReLU', color='b')
plt.axhline(0, color='black', linewidth=0.5)
plt.axvline(0, color='black', linewidth=0.5)
plt.grid(True, linestyle='--', alpha=0.6)
plt.legend()
plt.show()
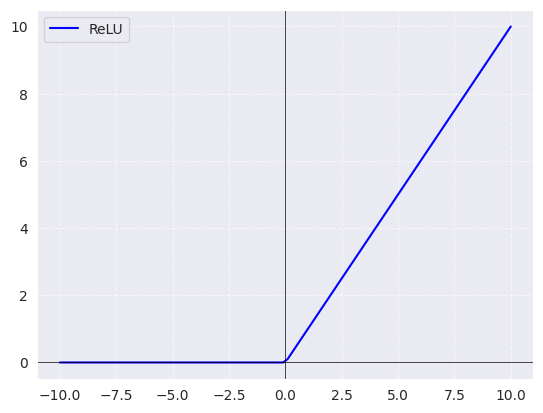
Importancia de ReLU
La función de activación más utilizada en CNN es ReLU (Rectified Linear Unit) por las siguientes razones:
Evita el gradiente desvaneciente: A diferencia de sigmoide o tangente hiperbólica, mantiene gradientes significativos en redes profundas, facilitando el entrenamiento.
Eficiencia computacional: Su cálculo \(\max(0, x)\) es más simple que funciones exponenciales, reduciendo la carga de procesamiento.
Favorece la esparsidad: Al asignar cero a valores negativos, desactiva neuronas, mejorando eficiencia y generalización.
Acelera el entrenamiento: Su linealidad en valores positivos y bajo costo computacional permiten una convergencia más rápida.
No obstante, puede generar neuronas muertas cuando ciertos pesos anulan permanentemente la activación. Para evitarlo, existen variantes como Leaky ReLU y PReLU.
La Fig. 11.26A muestra la imagen obtenida después de filtrar la imagen original del barco con el detector de bordes en la (11.12) y la Fig. 11.26B muestra el resultado que se obtiene tras la aplicación de la no linealidad en cada píxel individual.

Fig. 11.26 (A) Imagen donde se han extraído los bordes y (B) imagen resultante tras aplicar el en cada uno de los píxeles. Fuente [Theodoridis, 2020].#
11.16.5. La etapa de agrupación#
Pooling espacial: Este proceso reduce la dimensionalidad de las matrices de mapas de características. Se emplea una ventana deslizante, cuyo desplazamiento se define mediante un parámetro stride. La operación selecciona un único valor que representa todos los píxeles dentro de la ventana.La operación más común es la agrupación máxima (max pooling), donde se selecciona el píxel de mayor valor dentro de la ventana. Otra opción es la agrupación promedio (average pooling), que toma el valor medio de los píxeles, también conocida como pooling de suma. En la ilustración, una matriz de 6 × 6 se reduce aplicando una ventana de 2 × 2 con un stride de 2.
Fig. 11.27 (A) Matriz original de tamaño de 6 × 6. Agrupación mediante una ventana de 2 × 2 y un stride \(s = 2\). Valor máximo por ubicación de la ventana se indica en negrita. (B) Matriz 3 × 3 resultante tras la agrupación máxima. Fuente [Theodoridis, 2020].#
La misma fórmula de la Eq. (11.13) permite calcular el tamaño de la matriz resultante en el caso general. La agrupación reduce la dimensionalidad y el tamaño de las matrices, lo que es crucial, ya que cada salida se convierte en la entrada de la siguiente capa. Controlar el tamaño es esencial para gestionar el número de parámetros sin comprometer excesivamente la información.

Fig. 11.28 (A) Bordes de la imagen del barco tras la aplicación de ReLu (B) Imagen resultante tras aplicar max-pooling utilizando una ventana de 8 × 8. Fuente [Theodoridis, 2020].#
Observación
Fig. 11.28 muestra el efecto de aplicar el pooling a la imagen de la izquierda. Sin duda, los bordes se vuelven más gruesos, pero la información relacionada con los bordes puede extraerse. Nótese que después de la agrupación, el tamaño de la matriz imagen es reducido.
Desde otro punto de vista, el polling resume las estadísticas dentro del área pooling. El pooling puede considerarse un tipo especial de
filtrado, en el que, en lugar de la convolución, se selecciona el valor máximo (o medio) de la imagen. El pooling ayuda a que la representación sea aproximadamente invariante a pequeñas traslaciones de la entrada.
11.16.6. Convolución sobre volúmenes#
Observación
En la Fig. 11.23, la primera capa oculta genera tres matrices de imágenes como entrada para la siguiente capa, similar a la representación RGB de imágenes en color, donde cada matriz indica la intensidad de un color en cada píxel con valores de 0 a 255.
Rojo (R) |
Verde (G) |
Azul (B) |
Color resultante |
|---|---|---|---|
255 |
0 |
0 |
🔴 Rojo puro |
0 |
255 |
0 |
🟢 Verde puro |
0 |
0 |
255 |
🔵 Azul puro |
255 |
255 |
0 |
🟡 Amarillo (Rojo + Verde) |
0 |
255 |
255 |
🔵 Cian (Verde + Azul) |
255 |
0 |
255 |
🟣 Magenta (Rojo + Azul) |
255 |
255 |
255 |
⚪ Blanco (Máxima intensidad) |
0 |
0 |
0 |
⚫ Negro (Sin intensidad) |
Las entradas no son matrices bidimensionales, sino conjuntos de matrices bidimensionales, conocidos en matemáticas como tensores tridimensionales o volúmenes. Se adopta este último término por su relación con la geometría. El desafío radica en definir cómo realizar convoluciones en estos volúmenes.
import numpy as np
import matplotlib.pyplot as plt
imagen = np.array([
[[255, 0, 0], [0, 255, 0], [0, 0, 255]], # Rojo, Verde, Azul
[[255, 255, 0], [0, 255, 255], [255, 0, 255]], # Amarillo, Cian, Magenta
[[255, 255, 255], [128, 128, 128], [0, 0, 0]] # Blanco, Gris, Negro
], dtype=np.uint8)
canal_rojo = imagen[:, :, 0] # Matriz de valores R
canal_verde = imagen[:, :, 1] # Matriz de valores G
canal_azul = imagen[:, :, 2] # Matriz de valores B
plt.imshow(imagen)
plt.show()
print("Matriz del canal Rojo (R):\n", canal_rojo)
print("Matriz del canal Verde (G):\n", canal_verde)
print("Matriz del canal Azul (B):\n", canal_azul)
Matriz del canal Rojo (R):
[[255 0 0]
[255 0 255]
[255 128 0]]
Matriz del canal Verde (G):
[[ 0 255 0]
[255 255 0]
[255 128 0]]
Matriz del canal Azul (B):
[[ 0 0 255]
[ 0 255 255]
[255 128 0]]
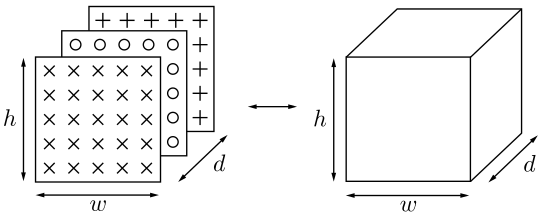
Fig. 11.29 Se apilan \(d\) matrices de tamaño \(h\times w\) cada una para formar un volumen de tamaño \(h \times w\times d\). En este caso, \(h = w = 5\) y \(d = 3\). Fuente [Theodoridis, 2020].#
Por convención, las tres dimensiones de un volumen se representarán como \(h\) para la altura, \(w\) para la anchura y \(d\) para la profundidad. Nótese que la profundidad \(d\) corresponde al número de imágenes implicadas. Así pues, si tenemos tres imágenes de 256 × 256, entonces \(h = w = 256\) y \(d = 3\) y diremos que el volumen es de tamaño (dimensión) 256 × 256 × 3. Fig. 11.29 ilustra la geometría asociada a las respectivas definiciones.
Tipos de formas tensoriales
En el procesamiento de imágenes, cada canal es una matriz 2D que contiene un tipo específico de información. Cuando se combinan varios canales, obtenemos un tensor 3D con forma:
\[ \text{(alto, ancho, canales)} \]Ejemplos de formas
Tipo de imagen |
Forma del tensor |
|---|---|
Escala de grises |
|
RGB (color) |
|
RGBA (color + transparencia) |
|
Satelital multiespectral |
|
Hiperespectral |
|
En
TensorFlow, cuando trabajamos con lotes de imágenes, la forma es\[ \text{(batch_size, alto, ancho, canales)} \]Las imágenes con más de tres canales se utilizan ampliamente en ciencia, ingeniería y medicina. Algunos casos representativos son los siguientes:
Teledetección Satelital
Sentinel-2 (ESA): imágenes multiespectrales con 13 bandas que capturan información en el visible, infrarrojo cercano e infrarrojo de onda corta.
Aplicaciones: monitoreo de cultivos, detección de deforestación, seguimiento de incendios forestales, calidad del agua.
Landsat-8 (NASA/USGS): imágenes con 11 bandas espectrales para estudios ambientales y urbanos.
Ejemplo: cálculo del NDVI (Normalized Difference Vegetation Index) para medir la salud de la vegetación.
Medicina e Imágenes Biomédicas
Resonancia Magnética (MRI): puede incluir múltiples secuencias (T1, T2, FLAIR, DWI, etc.), cada una representando un canal con distinta información anatómica o funcional.
Aplicaciones: detección de tumores, diagnóstico neurológico.
Microscopía de fluorescencia: imágenes con canales multicolor para visualizar diferentes proteínas o estructuras celulares.
Defensa y Detección
Radar de Apertura Sintética (SAR): imágenes con varios canales que representan diferentes polarizaciones de radar.
Aplicaciones: detección de barcos, monitoreo de movimientos de tierra, vigilancia marítima.
Agricultura de Precisión
Drones multiespectrales: capturan entre 5 y 10 bandas (RGB + infrarrojos).
Aplicaciones: estimación de rendimiento de cultivos, riego inteligente, detección temprana de plagas.
Industria y Calidad
Cámaras hiperespectrales (200+ canales): cada canal corresponde a una longitud de onda distinta.
Aplicaciones: inspección de alimentos (detección de contaminantes), control de calidad en textiles, minería (identificación de minerales).
Convolución de volúmenes
En una capa con entrada de dimensiones \(h \times w \times d\), los filtros de las capas ocultas también son volúmenes, pero deben tener la misma profundidad \(d\) que la entrada, aunque su altura y anchura pueden variar.
Si la entrada es un volumen \(\boldsymbol{I}\) de \(l \times l \times d\), este consta de \(d\) imágenes \(I_r\) de \(l \times l\). Un filtro \(\boldsymbol{H}\) de \(m \times m \times d\) también se compone de \(d\) imágenes \(H_r\) de \(m \times m\). La convolución se define a partir de estos elementos.
Convolucionar las correspondientes matrices de imágenes bidimensionales para generar \(d\) matrices bidimensionales de salida, es decir
La convolución de los dos volúmenes, \(\boldsymbol{I}\) y \(\boldsymbol{H}\), se define como
\[ O=\sum_{r=1}^{d}O_{r}. \]En otras palabras, la
convolución (denotada por\(\star\))de dos volúmenes es una matriz bidimensional, es decir,\[ \text{3D volume}\star\text{3D volume}=\text{2D array}. \]
Fig. 11.30 Convolución \(\text{3D volume}\star\text{3D volume}=\text{2D array}\). \(h = w = l, h = w = m\) y \(d = 3\).#
La operación se ilustra en la Fig. 11.30. Las matrices correspondientes (mostradas por diferentes colores y tipos de líneas). Las tres matrices de salida (\(d = 3\)) se suman posteriormente para formar la convolución de los dos volúmenes. La dimensión \(k\) de la salida depende de los valores de \(l\) y \(m\), del stride \(s\) y del padding \(p\), si se utiliza, según la Eq. (11.13).
Observación
En la práctica, cada capa de una CNN comprende varios de estos volúmenes de filtrado. Por ejemplo, si la entrada a una capa es un volumen \(l\times l\times d\), y hay, digamos, \(c\) volúmenes de núcleo, cada uno de dimensiones \(m\times m\times d\), la salida de la capa será un volumen \(k\times k\times c\), donde \(k\) se determina la Eq. (11.13).
11.16.7. Red en red y convolución 1 × 1#
Observación
La convolución 1 × 1 no tiene sentido cuando se trata de matrices bidimensionales. En efecto una matriz de filtro 1 × 1 es un escalar. Convolucionar una matriz \(I\) de \(l\times l\) con un escalar \(a\) equivale a deslizar el valor escalar sobre todos los píxeles y multiplicar cada uno de ellos por \(a\). El resultado es la trivial \(aI\) .
Sin embargo, cuando se trata de volúmenes, la convolución 1 × 1 tiene sentido. En este caso, el filtro correspondiente, \(\boldsymbol{H}\), es un volumen de tamaño \(1\times 1\times d\). Geométricamente, se trata de un “tubo”, con \(h = w = 1\) y \(d\) elementos en profundidad, \(h(1, 1, r), r = 1, 2,\dots,d\). Por lo tanto, el resultado de la convolución de un volumen \(\boldsymbol{I}\) de \(l\times l\times d\) con un \(1\times 1\times d\) volumen \(H\) es la media ponderada,
\[ O=\boldsymbol{I}\star\boldsymbol{H}=\sum_{r=1}^{d}h(1, 1, r)I_{r} \]donde \(I_{r},~r=1,2,\dots,d,\) son las \(d\) matrices, cada una de dimensiones \(l\times l\), que comprende \(\boldsymbol{I}\).
Convolución \(1\times 1\)
Ahora bien, cabe preguntarse por qué necesitamos una operación de este tipo en la práctica. La respuesta está relacionada con el tamaño de los volúmenes implicados; mediante el uso de convoluciones \(1\times 1\), se puede
controlar y cambiar su tamaño para adaptarlo a las necesidades de la red.Supongamos que en una etapa/capa de una red profunda hemos obtenido un volumen \(\boldsymbol{I}\) de dimensiones \(k\times k\times d\). Para cambiar la profundidad de \(d\) a \(c\), conservando el mismo tamaño \(k\), para la altura y la anchura, empleamos \(c\) volúmenes, \(H_{t}, t = 1, 2,\dots,c\), cada uno de dimensiones \(1\times 1\times d\). Al realizar las \(c\) convoluciones obtenemos
\[ O_{t}=\boldsymbol{I}\star\boldsymbol{H}_{t}=\sum_{r=1}^{d}h_{t}(1, 1, r)I_{r},~t=1,2,\dots,c. \]Apilando \(O_{t}, t = 1, 2,\dots,c\), obtenemos el volumen \(\boldsymbol{O}\) de dimensión \(k\times k\times c\) (ver Fig. 11.31).
La información original se sigue conservando en el nuevo volumen, de forma promediada. A menudo, una vez obtenido el nuevo volumen \(\boldsymbol{O}\), sus elementos se “empujan” a través de una no linealidad, por ejemplo,
ReLU.La convolución \(1\times 1\) seguida de la no linealidad se denomina
operación de red en redy su finalidad es añadir una etapa de no linealidad adicional en el flujo de operaciones a través de la red. Por lo tanto, en este contexto, si \(c<d\), la operación de red en red puede considerarse una técnica de reducción de la dimensionalidad no lineal.
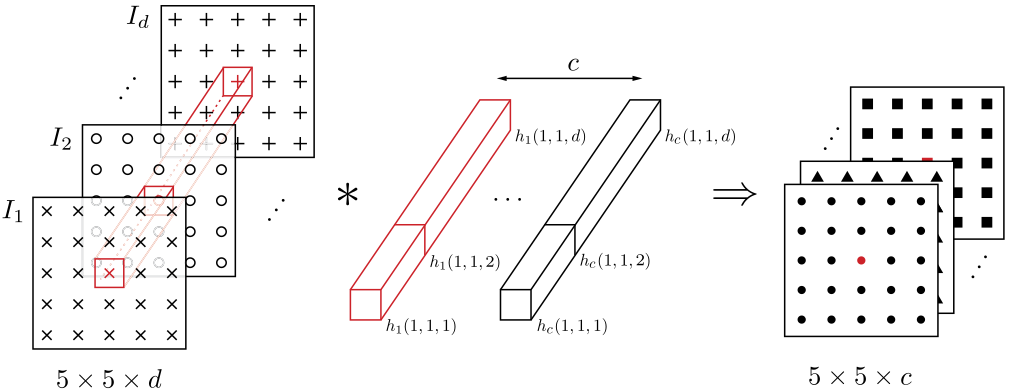
Fig. 11.31 Convolución \(1\times 1\), con \(c\) tubos de dimensión \(1\times 1\times d\), donde \(d\) es la profundidad del volumen de entrada. Fuente [Theodoridis, 2020].#
Ejemplo
Consideremos que la entrada de una capa es un volumen \(\boldsymbol{I}\) de 28 × 28 × 192. El objetivo es producir a la salida de la capa un volumen, \(O\), de dimensión 28 × 28 × 32. Para ello emplear 5 × 5 convoluciones iguales y un volumen intermedio \(\boldsymbol{O}'\) de dimensiones \(28\times 28\times 16\). Nótese que en la última capa se usó padding de 2 píxeles en cada borde.
Observe que, rellenando todas las matrices apiladas en \(\boldsymbol{I}\) con \(p\) cero columnas y filas, se tiene que el número de multiplicaciones y adiciones (MADS) es \(3.7\times 10^{6}\times 32\approx 120~\) millones MADS. Además, usando convoluciones \(1\times 1\), este número se reduce a \(28^{2}\times 25\times 16\times 32\approx 10\) millones MADS (ver [Theodoridis, 2020]).
A menudo, el volumen intermedio, \(\boldsymbol{O}'\), se conoce como capa
cuello de botella (bottleneck layer); su función es “reducir” primero el tamaño del volumen de entrada, antes de obtener el volumen de salida final (ver Fig. 11.32).
Fig. 11.32 Capa cuello de botella. Fuente [Theodoridis, 2020].#
11.16.8. Arquitectura CNN completa#
La forma típica de una red convolucional completa consiste en una
secuencia de capas convolucionales, cada una de las cuales que comprende los tres pasos básicos, a saber,convolución (Conv.), no linealidad (ReLU) y agrupación (Pooling), como se describe al principio de esta sección. Dependiendo de la aplicación,se pueden apilar tantas capas como sea necesario, donde la salida de una capa se convierte en la entrada de la siguiente. Las entradas y salidas de cada capa son volúmenes, como se ha descrito anteriormente.
Fig. 11.33 Arquitectura CNN completa. Fuente [Theodoridis, 2020].#
Procedimiento de una CNN completa
En la primera capa, se aplican filtros para realizar convoluciones seguidas de una transformación no lineal. Luego, la operación de pooling reduce las dimensiones de la salida, que sirve como entrada para la siguiente capa. Este proceso se repite hasta que el volumen final se vectoriza, en un paso conocido como flattening.
El resultado es un vector de características obtenido a partir de las transformaciones aplicadas en cada capa convolucional. Este vector se utiliza como entrada para un modelo de aprendizaje, como una red neuronal totalmente conectada o una máquina de vectores de soporte.
Observación
La estrategia consiste en reducir dimensiones mientras se incrementa la profundidad, aumentando filtros por etapa para extraer más características. La cantidad de capas convolucionales y totalmente conectadas depende de la aplicación, sin un método formal para su determinación, por lo que se elige mediante evaluación. Se sugiere partir de arquitecturas existentes, y el aprendizaje Bayesiano facilita la selección óptima de nodos o filtros.
11.16.9. Características en una CNN#
Las características (features) en una Red Neuronal Convolucional (CNN) son patrones visuales que la red aprende a reconocer en las imágenes. Se extraen automáticamente a través de capas convolucionales aplicadas en diferentes niveles de abstracción. ¿Cuáles son las características en una CNN? Las características son representaciones numéricas que describen el contenido visual de una imagen. Se generan a través de filtros convolucionales que detectan patrones en distintos niveles:
Características de bajo nivel(Primeras capas)
Se detectan patrones simples como:
Bordes
Texturas
Esquinas
Gradientes de color
Ejemplo: Un filtro Sobel detecta los bordes en una imagen.
Características de nivel intermedio (Capas medias)
Se combinan los bordes y texturas detectados antes para formar estructuras más complejas, como:
Formas básicas (círculos, líneas curvas)
Contornos de objetos
Partes de objetos (ojos, nariz, ruedas)
Ejemplo: En una CNN que detecta rostros, esta capa podría identificar una nariz o un ojo.
Características de alto nivel (Últimas capas)
Se forman representaciones abstractas y semánticas de la imagen, como:
Objetos completos (caras, coches, animales)
Relaciones espaciales entre partes
Categorización (perro vs. gato)
Ejemplo: En una CNN entrenada para clasificar animales, las capas profundas pueden reconocer la silueta completa de un gato.
Ejemplo Visual: Si la CNN clasifica gatos y perros:
Bordes → Detecta líneas y curvas.
Formas intermedias → Identifica orejas, ojos y hocico.
Características de alto nivel → Distingue un gato de un perro.
11.16.10. Arquitecturas de Redes Neuronales Convolucionales#
Introducción
El diseño de una CNN sigue pasos básicos con múltiples variantes arquitectónicas y optimizaciones para mejorar la eficiencia computacional (ver Fig. 11.33). Implementarlas requiere un gran esfuerzo técnico para su aprendizaje y aplicación.
A continuación, se presentan redes convolucionales clásicas, cuya comprensión es clave para profundizar en el tema, aunque algunos de sus métodos ya no se utilicen. Los estudios citados ofrecen una base sólida para el aprendizaje de las CNN.
11.16.11. LeNet-5#
LeNet-5
Este es un ejemplo típico de la primera generación de CNNs y fue construido para reconocer dígitos de números (ver [LeCun et al., 1998]). Por razones históricas, comentemos un poco su arquitectura. La entrada de la red consiste en imágenes en escala de grises de tamaño 32 × 32 × 1. La red emplea dos capas de convolución. En la primera capa, el volumen de salida tiene un tamaño de 28 × 28 × 6, que tras la agrupación se convierte en 14 × 14 × 6.
Las dimensiones del volumen en la segunda capa eran 10 × 10 × 16 y, tras la agrupación, 5 × 5 × 16. La no linealidad utilizada entonces era de tipo
sigmoid. Nótese que laaltura y la anchura de los volúmenes disminuyen y la profundidad aumenta, como se ha señalado antes. El número de elementos del último volumen es igual a 400. Estos elementos se apilan en un vector y alimentan los correspondientes nodos de entrada de una red totalmente conectada.Esta última consta de dos capas ocultas con 120 nodos en la primera y 84 nodos en la segunda. Hay 10 nodos de salida, uno por dígito, que utilizan una no linealidad
softmax. El número total de parámetros implicados es del orden de 60.000.
Fig. 11.35 Arquitectura LeNet-5. Fuente [LeCun et al., 1998].#
11.16.12. AlexNet#
AlexNet
Esta red también es histórica ya que, demostró que el punto crucial para hacer grandes redes es la disponibilidad de grandes conjuntos de entrenamiento [Krizhevsky et al., 2012]. El artículo relacionado es el que realmente hizo volver a las CNN y actuó como catalizador para su adopción mucho más allá de la tarea de reconocimiento de dígitos. La Alexnet es un desarrollo de la LeNet-5, pero es mucho más grande e implica aproximadamente 60 millones de parámetros.
Las entradas a la red son imágenes RGB de tamaño 227 × 227 × 3. Comprende cinco capas ocultas y el volumen final consta de 9216 elementos que alimentan una red totalmente conectada con dos capas ocultas de 4096 unidades cada una. La salida consta de 1000 nodos
softmax(uno por clase) para reconocer imágenes del conjunto de datos ImageNet para el reconocimiento de objetos.ReLUse ha utilizado como no linealidad en las capas ocultas.
Fig. 11.36 Arquitectura LeNet-5. Fuente [Krizhevsky et al., 2012].#
11.16.13. VGG-16#
VGG-16
Esta red [Simonyan and Zisserman, 2014] es mucho mayor que AlexNet. Implica un total de aproximadamente 140 millones de parámetros. La principal característica de esta red es su regularidad. Involucra filtros 3 × 3 para realizar las mismas convoluciones utilizando padding y stride \(s = 1\) y ventanas 2 × 2 para maxpooling con stride \(s = 2\). Cada vez que se realiza un pooling, la altura y la anchura de los volúmenes se reducen a la mitad y la profundidad se multiplica por dos.
Partiendo de 224 × 224 × 3 imagen de entrada y después de 13 capas el volumen final tiene un tamaño de 7 × 7 × 512, un total de 25088 elementos, que tras su vectorización alimenta a una red totalmente conectada con 2 capas ocultas de 4096 nodos cada una. Los 1000 nodos de salida están construidos en torno a la no linealidad
softmaxy se ha utilizadoReLUpara las unidades ocultas en toda la red.
Fig. 11.37 Arquitectura VGG-16. Fuente [Simonyan and Zisserman, 2014].#
El diseño de
VGG-16se basó en la hipótesis de que aumentar la profundidad de una red convolucional, mientras se usan pequeños filtros, conduciría a un mejor rendimiento en la tarea de clasificación de imágenes. La naturaleza homogénea de la arquitectura con filtros 3x3 repetidos permitió que la red aprendiera características jerárquicas más profundas, conservando al mismo tiempo una buena eficiencia computacional.El uso de filtros pequeños y capas profundas fue una decisión clave porque:
Filtros más pequeños capturan características locales, pero apilados sucesivamente tienen un campo receptivo mayor.
Mayor profundidad permite extraer características más abstractas y complejas a medida que las capas avanzan.
11.16.14. GoogleNet y la red Inception#
GoogleNet y la red Inception
La arquitectura utilizada en esta red se desvía del “arquetípico” que se muestra en Fig. 11.33. En el corazón de esta red se encuentra el llamado módulo de inicio [Szegedy et al., 2015]. Un módulo de inicio consta de filtros de diferentes tamaños y profundidades, así como de una ruta de agrupación diferente.
La arquitectura
Inceptiontoma la salida de una capa y la divide en varias rutas: una usa convolución 1x1 para reducir la profundidad, otra hace pooling seguido de convolución 5x5, y dos rutas realizan convoluciones separadas con filtros 3x3 y 5x5. Se usa una capa de cuello de botella (convolución 1x1) para reducir la carga computacional antes de las convoluciones.En el módulo de inicio, se concatenan los volúmenes de salida de varias trayectorias, permitiendo que la red, durante el entrenamiento, elija las mejores operaciones para cada capa. A medida que se avanza hacia capas superiores, se incrementa la proporción de convoluciones 3 × 3 y 5 × 5, ya que captan rasgos más abstractos. La red tiene 22 capas y 6 millones de parámetros.
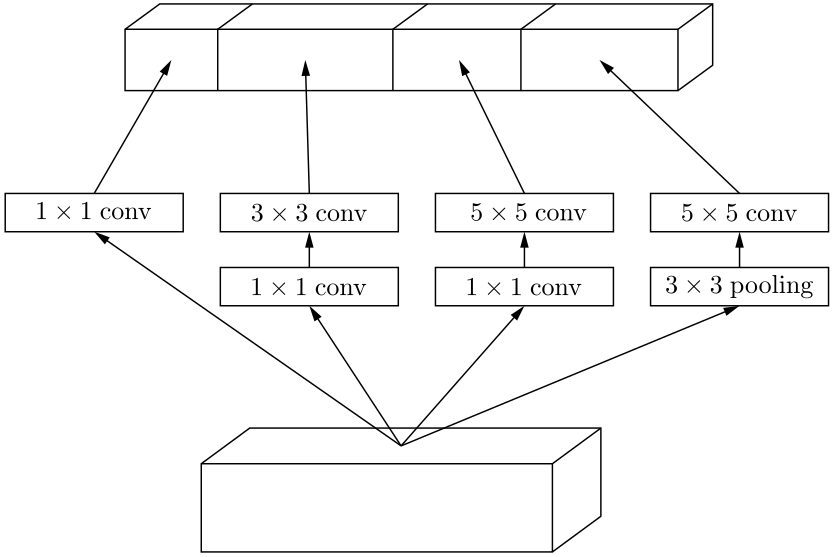
Fig. 11.39 Arquitectura Inception. Fuente [Szegedy et al., 2015].#
11.16.15. Redes residuales (ResNets)#
Redes residuales (ResNets)
Ya hemos hablado de las ventajas de diseñar redes profundas. También abordamos la forma de hacer frente al problema de los gradientes que se desvanecen/explotan mediante una combinación de métodos y trucos que permiten que el algoritmo backpropagation converja con suficiente rapidez. Sin embargo, una vez que empezamos a construir redes muy profundas (del orden de decenas o incluso centenares de capas) nos encontramos con el siguiente comportamiento “poco ortodoxo”.
Cabría esperar que, añadiendo más y más capas, el error de entrenamiento mejore o al menos no aumenta. Sin embargo, lo que se observa en la práctica es que
a partir de un cierto número de capas, el error de entrenamiento empieza a aumentar. Esto se ilustra gráficamente en la Fig. 11.40. Este fenómeno no tiene nada que ver con el sobreajuste. Después de todo, estamos hablando del error de entrenamiento y no del de generalización. Parece que esto puede deberse ala tarea de optimización que se vuelve más y más difícil a medida que se añaden más y más capas.
Fig. 11.40 Aumento en lugar de disminución del error cuando el número de capas supera cierto número, en una red muy profunda. (curva roja) como se esperaba a partir de la teoría.#
Interpretación Matemática de una Capa en la Red Neuronal
Cada capa de una red neuronal aplica una función \(H\) que transforma la salida anterior \(\boldsymbol{y}^{r-1}\) en una nueva salida \(\boldsymbol{y}^{r}\):
¿Por qué Añadir Más Capas No Debería Aumentar el Error de Entrenamiento?
Si una capa ha extraído toda la información útil, una capa adicional, en el peor caso, solo replicaría la salida anterior aplicando la función identidad:
\[ \boldsymbol{y}^{r} = H(\boldsymbol{y}^{r-1}) = \boldsymbol{y}^{r-1} \]Es decir, si no hay nada nuevo que aprender, la capa extra solo copiaría la información.
Problema de redes profundas: saturación y dificultades de optimización
En redes profundas, el rendimiento se estanca porque más capas no mejoran la precisión y la optimización enfrenta dificultades para aprender el mapeo de identidad \(H(y^{r-1}) = y^{r-1}\), generando errores por gradientes pequeños o desajustes en los pesos.
Solución propuesta por He et al. (2016): Redes Residuales (ResNets)
En lugar de aprender directamente \(H(y^{r-1})\), se propone un mapeo residual \(F(y^{r-1}) = H(y^{r-1}) - y^{r-1}\), donde la capa solo ajusta la diferencia necesaria en vez de replicar la entrada. Así, la salida se obtiene sumando este ajuste residual:
El uso de la representación residual no es nuevo y ya se ha utilizado anteriormente en el contexto de la cuantificación vectorial. La esencia del aprendizaje residual es introducir el llamado bloque de construcción residual, que se muestra en la Fig. 11.41.
Fig. 11.41 Bloque de construcción residual. Fuente [Theodoridis, 2020].#
De esta manera, un número de capas, digamos, dos, como en el caso de la Fig. 11.41, se apilan y dejamos que estas capas se ajusten explícitamente al mapeo residual, a través de las llamadas conexiones de atajo u omisión. Cada capa de pesos realiza una transformación sobre su entrada, por ejemplo, convoluciones. Si \(\boldsymbol{y}^{r}\) e \(\boldsymbol{y}^{r-1}\) son de dimensiones diferentes, el atajo de mapeo de identidad se modifica a \(W\boldsymbol{y}^{r-1}\), donde \(W\) es una matriz de dimensiones apropiadas.
11.16.16. U-Net: Redes Convolucionales para la Segmentación de Imágenes Biomédicas#

Fig. 11.42 Image segmentation vs Instance segmentation. Fuente v7labs#
En imágenes médicas, la segmentación semántica clasifica cada píxel según una categoría anatómica o patológica, mientras que la segmentación de instancias diferencia objetos individuales dentro de la misma clase. Estas técnicas son esenciales para el diagnóstico automatizado y la planificación clínica.
La arquitectura U-Net, diseñada para segmentación biomédica, permite una segmentación precisa mediante un diseño en forma de U que combina información de contexto con detalles espaciales, mejorando la detección de estructuras complejas en imágenes médicas.
Fig. 11.43 La arquitectura U-Net representa mapas de características con cajas, indicando canales y tamaño, mientras que las flechas señalan las operaciones.#
Arquitectura U-Net
La arquitectura U-Net es una red neuronal convolucional diseñada para la segmentación de imágenes biomédicas. Se basa en una estructura de encoder-decoder con una forma en “U”.
Encoder (contracción): Extrae características mediante convoluciones y capas de pooling para reducir la dimensionalidad.
Bottleneck: Conecta el encoder con el decoder, capturando la información más relevante.
Decoder (expansión): Usa convoluciones transpuestas para recuperar la resolución original de la imagen y refinar la segmentación.
Skip connections: Conectan capas del encoder con el decoder, permitiendo una mejor preservación de detalles.
Esta arquitectura es eficiente con pocos datos y logra segmentaciones precisas, lo que la hace ideal para aplicaciones médicas. Considera
conv 3x3, max pool 2x2, up-conv 2x2, conv 1x1, padding = 0, stride = 1fijos. En elencoderse reduce alto y ancho de los mapeos de caracteristicas mientras que se aumenta la profundidad. Lo contrario ocurre en eldecoder.Al final se aplican 2 convoluciones de
1x1x64(tubos) como las vistas en secciones anteriores, para obtener el último kernel de388x388x2en el que, cada canal representaria una clase diferente a segmentar, y despues de aplicar funciones de activación, lo que resulta en el mapeo de características es, la probabilidad de que un pixel en una respectiva posición pertenezca a la clase representada por cada canal, por ejemplo a la clase (black) o la clase (blue) (clasificación binaria).
La arquitectura U-Net aprende a segmentar imágenes asignando cada píxel a una clase específica.
Entrada (X): Imagen original (ej. un gato en fondo blanco).
Salida esperada (Y): Máscara binaria (1 = gato, 0 = fondo).
El modelo ajusta sus parámetros hasta que pueda predecir correctamente la máscara a partir de una nueva imagen.
¿Cómo se maneja la correspondencia de píxeles?
U-Net genera una salida de menor tamaño que la imagen de entrada debido a la reducción espacial provocada por las capas de max pooling en la fase de contracción y el uso de valid convolutions sin padding. Aunque las up-convolutions intentan recuperar la resolución original, la salida sigue siendo más pequeña.
¿Cómo mantener la correspondencia de píxeles?
Same padding: Mantiene el tamaño original sin postprocesamiento, pero puede introducir valores artificiales en los bordes.
Superposición de parches: Divide la imagen en fragmentos solapados para reconstruir la segmentación completa, útil en imágenes médicas de alta resolución.
Interpolación o recorte: Ajusta el tamaño de salida cuando se usan valid convolutions, aunque puede generar imprecisiones.
Recomendación:
Para conservar el tamaño original, usar same padding en todas las convoluciones.
En imágenes grandes, aplicar superposición de parches para optimizar memoria y evitar artefactos.
Si la red ya está entrenada con valid convolutions, usar interpolación como ajuste final.
11.16.17. Aplicación: Reconocimiento facial de emociones#
Los datos para el siguiente ejemplo pueden ser descargados del siguiente link: Face Sentiment Detection
import warnings
warnings.filterwarnings('ignore')
import tensorflow as tf
print("TensorFlow version:", tf.__version__)
devices = tf.config.list_physical_devices()
print("Available devices:")
for device in devices:
print(device)
gpus = tf.config.list_physical_devices('GPU')
if gpus:
print("TensorFlow is using GPU.")
for gpu in gpus:
gpu_details = tf.config.experimental.get_device_details(gpu)
print(f"GPU details: {gpu_details}")
else:
print("TensorFlow is not using GPU.")
TensorFlow version: 2.17.0
Available devices:
PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU')
PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')
TensorFlow is using GPU.
GPU details: {'compute_capability': (8, 9), 'device_name': 'NVIDIA GeForce RTX 4070'}
I0000 00:00:1778302004.470120 2460 cuda_executor.cc:1001] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node
Your kernel may have been built without NUMA support.
import numpy as np
import pandas as pd
import os
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.utils import load_img
from keras.layers import Conv2D, Dense, BatchNormalization, Activation, Dropout, MaxPool2D, Flatten, MaxPooling2D, GlobalAveragePooling2D
from tensorflow.keras.metrics import AUC
from tensorflow.keras.optimizers import Adam, RMSprop, SGD
from keras.callbacks import ModelCheckpoint,EarlyStopping
import datetime
from keras import regularizers
import matplotlib.pyplot as plt
from tensorflow.keras.utils import plot_model
from tensorflow.keras.regularizers import l2
train_dir = '/home/lihkir/Data/face_sentiment_detection/train/'
test_dir = '/home/lihkir/Data/face_sentiment_detection/test/'
def count_exp(path, set_):
dict_ = {}
for expression in os.listdir(path):
dir_ = path + expression
dict_[expression] = len(os.listdir(dir_))
df = pd.DataFrame(dict_, index=[set_])
return df
train_count = count_exp(train_dir, 'train')
test_count = count_exp(test_dir, 'test')
print(train_count)
print(test_count)
surprise disgust happy fear angry neutral sad
train 3171 436 7215 4097 3995 4965 4830
surprise disgust happy fear angry neutral sad
test 831 111 1774 1024 958 1233 1247
train_count.transpose().plot(kind='bar');
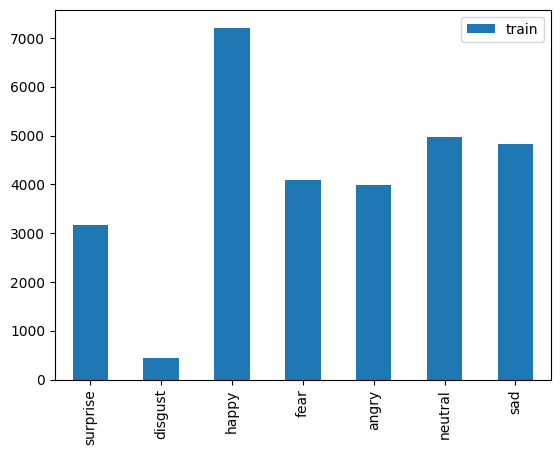
test_count.transpose().plot(kind='bar');
plt.figure(figsize=(14,22))
i = 1
for expression in os.listdir(train_dir):
img = load_img((train_dir + expression +'/'+ os.listdir(train_dir + expression)[5]))
plt.subplot(1,7,i)
plt.imshow(img)
plt.title(expression)
plt.axis('off')
i += 1

import tensorflow as tf
from tensorflow.keras.layers import (
Conv2D, Activation, BatchNormalization, MaxPooling2D,
Dropout, Flatten, Dense, GlobalAveragePooling2D
)
from tensorflow.keras.regularizers import l2
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.metrics import AUC
from tensorflow.keras.callbacks import EarlyStopping, ReduceLROnPlateau
from tensorflow.keras.preprocessing.image import ImageDataGenerator
weight_decay = 1e-4
# Aumento de datos solo en entrenamiento
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=15,
width_shift_range=0.1,
height_shift_range=0.1,
horizontal_flip=True,
zoom_range=0.1
)
test_datagen = ImageDataGenerator(rescale=1./255)
train_gen = train_datagen.flow_from_directory(
train_dir,
target_size=(48, 48),
color_mode='grayscale',
batch_size=64,
class_mode='categorical',
shuffle=True
)
test_gen = test_datagen.flow_from_directory(
test_dir,
target_size=(48, 48),
color_mode='grayscale',
batch_size=64,
class_mode='categorical',
shuffle=False
)
# Arquitectura
model = tf.keras.models.Sequential([
# Bloque 1: kernels 3x3, extracción local fina
Conv2D(32, (3,3), padding='same', kernel_regularizer=l2(weight_decay),
input_shape=(48,48,1)),
BatchNormalization(),
Activation('elu'),
Conv2D(32, (3,3), padding='same', kernel_regularizer=l2(weight_decay)),
BatchNormalization(),
Activation('elu'),
MaxPooling2D((2,2)),
Dropout(0.3),
# Bloque 2
Conv2D(64, (3,3), padding='same', kernel_regularizer=l2(weight_decay)),
BatchNormalization(),
Activation('elu'),
Conv2D(64, (3,3), padding='same', kernel_regularizer=l2(weight_decay)),
BatchNormalization(),
Activation('elu'),
MaxPooling2D((2,2)),
Dropout(0.4),
# Bloque 3
Conv2D(128, (3,3), padding='same', kernel_regularizer=l2(weight_decay)),
BatchNormalization(),
Activation('elu'),
Conv2D(128, (3,3), padding='same', kernel_regularizer=l2(weight_decay)),
BatchNormalization(),
Activation('elu'),
MaxPooling2D((2,2)),
Dropout(0.5),
# Clasificador — GlobalAveragePooling reduce parámetros vs Flatten
GlobalAveragePooling2D(),
Dense(256, kernel_regularizer=l2(weight_decay)),
BatchNormalization(),
Activation('elu'),
Dropout(0.5),
Dense(num_classes, activation='softmax')
])
model.compile(
loss='categorical_crossentropy',
optimizer=Adam(learning_rate=1e-3),
metrics=[AUC(name='auc')]
)
# Callbacks anti-sobreajuste
callbacks = [
EarlyStopping(
monitor='val_auc',
patience=10,
mode='max',
restore_best_weights=True,
verbose=1
),
ReduceLROnPlateau(
monitor='val_loss',
factor=0.5,
patience=5,
min_lr=1e-6,
verbose=1
)
]
history = model.fit(
train_gen,
validation_data=test_gen,
epochs=100,
callbacks=callbacks
)
Found 28709 images belonging to 7 classes.
Found 7178 images belonging to 7 classes.
Epoch 1/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 16s 26ms/step - auc: 0.5859 - loss: 2.2761 - val_auc: 0.6593 - val_loss: 1.8508 - learning_rate: 0.0010
Epoch 2/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.6832 - loss: 1.8630 - val_auc: 0.7084 - val_loss: 1.8896 - learning_rate: 0.0010
Epoch 3/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.7462 - loss: 1.6990 - val_auc: 0.7412 - val_loss: 1.7239 - learning_rate: 0.0010
Epoch 4/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 17ms/step - auc: 0.7792 - loss: 1.6087 - val_auc: 0.8127 - val_loss: 1.5164 - learning_rate: 0.0010
Epoch 5/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.7955 - loss: 1.5653 - val_auc: 0.7842 - val_loss: 1.6470 - learning_rate: 0.0010
Epoch 6/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.8140 - loss: 1.5078 - val_auc: 0.8372 - val_loss: 1.4343 - learning_rate: 0.0010
Epoch 7/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 9s 19ms/step - auc: 0.8249 - loss: 1.4711 - val_auc: 0.8433 - val_loss: 1.4121 - learning_rate: 0.0010
Epoch 8/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.8324 - loss: 1.4505 - val_auc: 0.8592 - val_loss: 1.3442 - learning_rate: 0.0010
Epoch 9/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 9s 19ms/step - auc: 0.8371 - loss: 1.4323 - val_auc: 0.8709 - val_loss: 1.2984 - learning_rate: 0.0010
Epoch 10/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 17ms/step - auc: 0.8434 - loss: 1.4138 - val_auc: 0.8656 - val_loss: 1.3258 - learning_rate: 0.0010
Epoch 11/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.8490 - loss: 1.3926 - val_auc: 0.8609 - val_loss: 1.3702 - learning_rate: 0.0010
Epoch 12/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.8559 - loss: 1.3686 - val_auc: 0.8748 - val_loss: 1.2897 - learning_rate: 0.0010
Epoch 13/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.8600 - loss: 1.3540 - val_auc: 0.8550 - val_loss: 1.4007 - learning_rate: 0.0010
Epoch 14/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.8623 - loss: 1.3457 - val_auc: 0.8762 - val_loss: 1.2882 - learning_rate: 0.0010
Epoch 15/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 17ms/step - auc: 0.8642 - loss: 1.3389 - val_auc: 0.8779 - val_loss: 1.2905 - learning_rate: 0.0010
Epoch 16/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 17ms/step - auc: 0.8676 - loss: 1.3264 - val_auc: 0.8766 - val_loss: 1.3041 - learning_rate: 0.0010
Epoch 17/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.8690 - loss: 1.3215 - val_auc: 0.8764 - val_loss: 1.2889 - learning_rate: 0.0010
Epoch 18/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 17ms/step - auc: 0.8694 - loss: 1.3220 - val_auc: 0.8874 - val_loss: 1.2412 - learning_rate: 0.0010
Epoch 19/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.8734 - loss: 1.3053 - val_auc: 0.8892 - val_loss: 1.2355 - learning_rate: 0.0010
Epoch 20/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 17ms/step - auc: 0.8767 - loss: 1.2924 - val_auc: 0.8771 - val_loss: 1.2989 - learning_rate: 0.0010
Epoch 21/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 17ms/step - auc: 0.8774 - loss: 1.2897 - val_auc: 0.8777 - val_loss: 1.3316 - learning_rate: 0.0010
Epoch 22/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.8793 - loss: 1.2814 - val_auc: 0.8826 - val_loss: 1.2764 - learning_rate: 0.0010
Epoch 23/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.8837 - loss: 1.2613 - val_auc: 0.8672 - val_loss: 1.4199 - learning_rate: 0.0010
Epoch 24/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - auc: 0.8838 - loss: 1.2612
Epoch 24: ReduceLROnPlateau reducing learning rate to 0.0005000000237487257.
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.8838 - loss: 1.2612 - val_auc: 0.8727 - val_loss: 1.3789 - learning_rate: 0.0010
Epoch 25/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 17ms/step - auc: 0.8903 - loss: 1.2294 - val_auc: 0.8934 - val_loss: 1.2239 - learning_rate: 5.0000e-04
Epoch 26/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.8937 - loss: 1.2108 - val_auc: 0.8908 - val_loss: 1.2351 - learning_rate: 5.0000e-04
Epoch 27/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.8948 - loss: 1.2032 - val_auc: 0.8971 - val_loss: 1.2075 - learning_rate: 5.0000e-04
Epoch 28/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 10s 18ms/step - auc: 0.8940 - loss: 1.2058 - val_auc: 0.8833 - val_loss: 1.2874 - learning_rate: 5.0000e-04
Epoch 29/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.8942 - loss: 1.2042 - val_auc: 0.8952 - val_loss: 1.2087 - learning_rate: 5.0000e-04
Epoch 30/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.8962 - loss: 1.1918 - val_auc: 0.8936 - val_loss: 1.2083 - learning_rate: 5.0000e-04
Epoch 31/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 17ms/step - auc: 0.8980 - loss: 1.1818 - val_auc: 0.9035 - val_loss: 1.1548 - learning_rate: 5.0000e-04
Epoch 32/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.8979 - loss: 1.1812 - val_auc: 0.8793 - val_loss: 1.2941 - learning_rate: 5.0000e-04
Epoch 33/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.8959 - loss: 1.1909 - val_auc: 0.8861 - val_loss: 1.2458 - learning_rate: 5.0000e-04
Epoch 34/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.8984 - loss: 1.1772 - val_auc: 0.8957 - val_loss: 1.2166 - learning_rate: 5.0000e-04
Epoch 35/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9000 - loss: 1.1698 - val_auc: 0.9052 - val_loss: 1.1413 - learning_rate: 5.0000e-04
Epoch 36/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9017 - loss: 1.1603 - val_auc: 0.8939 - val_loss: 1.2212 - learning_rate: 5.0000e-04
Epoch 37/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9007 - loss: 1.1638 - val_auc: 0.9079 - val_loss: 1.1309 - learning_rate: 5.0000e-04
Epoch 38/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9014 - loss: 1.1599 - val_auc: 0.8845 - val_loss: 1.3032 - learning_rate: 5.0000e-04
Epoch 39/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9025 - loss: 1.1544 - val_auc: 0.9108 - val_loss: 1.1104 - learning_rate: 5.0000e-04
Epoch 40/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9030 - loss: 1.1515 - val_auc: 0.8914 - val_loss: 1.2151 - learning_rate: 5.0000e-04
Epoch 41/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.8996 - loss: 1.1685 - val_auc: 0.8926 - val_loss: 1.2130 - learning_rate: 5.0000e-04
Epoch 42/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9007 - loss: 1.1623 - val_auc: 0.9014 - val_loss: 1.1749 - learning_rate: 5.0000e-04
Epoch 43/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 9s 19ms/step - auc: 0.9024 - loss: 1.1539 - val_auc: 0.8779 - val_loss: 1.3576 - learning_rate: 5.0000e-04
Epoch 44/100
447/449 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - auc: 0.9025 - loss: 1.1524
Epoch 44: ReduceLROnPlateau reducing learning rate to 0.0002500000118743628.
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 19ms/step - auc: 0.9025 - loss: 1.1524 - val_auc: 0.8997 - val_loss: 1.1705 - learning_rate: 5.0000e-04
Epoch 45/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9085 - loss: 1.1200 - val_auc: 0.9173 - val_loss: 1.0709 - learning_rate: 2.5000e-04
Epoch 46/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9083 - loss: 1.1209 - val_auc: 0.9161 - val_loss: 1.0785 - learning_rate: 2.5000e-04
Epoch 47/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 17ms/step - auc: 0.9080 - loss: 1.1228 - val_auc: 0.9172 - val_loss: 1.0700 - learning_rate: 2.5000e-04
Epoch 48/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 9s 19ms/step - auc: 0.9111 - loss: 1.1025 - val_auc: 0.9116 - val_loss: 1.1068 - learning_rate: 2.5000e-04
Epoch 49/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 17ms/step - auc: 0.9099 - loss: 1.1097 - val_auc: 0.9159 - val_loss: 1.0776 - learning_rate: 2.5000e-04
Epoch 50/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9123 - loss: 1.0969 - val_auc: 0.9055 - val_loss: 1.1351 - learning_rate: 2.5000e-04
Epoch 51/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9105 - loss: 1.1051 - val_auc: 0.9144 - val_loss: 1.0839 - learning_rate: 2.5000e-04
Epoch 52/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9137 - loss: 1.0863 - val_auc: 0.9179 - val_loss: 1.0695 - learning_rate: 2.5000e-04
Epoch 53/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 17ms/step - auc: 0.9112 - loss: 1.0997 - val_auc: 0.9123 - val_loss: 1.0933 - learning_rate: 2.5000e-04
Epoch 54/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9127 - loss: 1.0911 - val_auc: 0.9137 - val_loss: 1.1004 - learning_rate: 2.5000e-04
Epoch 55/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9145 - loss: 1.0807 - val_auc: 0.9089 - val_loss: 1.1219 - learning_rate: 2.5000e-04
Epoch 56/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9128 - loss: 1.0900 - val_auc: 0.8947 - val_loss: 1.2481 - learning_rate: 2.5000e-04
Epoch 57/100
444/449 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - auc: 0.9122 - loss: 1.0931
Epoch 57: ReduceLROnPlateau reducing learning rate to 0.0001250000059371814.
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9122 - loss: 1.0931 - val_auc: 0.9062 - val_loss: 1.1691 - learning_rate: 2.5000e-04
Epoch 58/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9161 - loss: 1.0692 - val_auc: 0.9193 - val_loss: 1.0531 - learning_rate: 1.2500e-04
Epoch 59/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 9s 19ms/step - auc: 0.9185 - loss: 1.0564 - val_auc: 0.9180 - val_loss: 1.0698 - learning_rate: 1.2500e-04
Epoch 60/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 9s 19ms/step - auc: 0.9178 - loss: 1.0583 - val_auc: 0.9164 - val_loss: 1.0893 - learning_rate: 1.2500e-04
Epoch 61/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9175 - loss: 1.0597 - val_auc: 0.9116 - val_loss: 1.1202 - learning_rate: 1.2500e-04
Epoch 62/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9165 - loss: 1.0665 - val_auc: 0.9165 - val_loss: 1.0747 - learning_rate: 1.2500e-04
Epoch 63/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - auc: 0.9174 - loss: 1.0609
Epoch 63: ReduceLROnPlateau reducing learning rate to 6.25000029685907e-05.
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9174 - loss: 1.0609 - val_auc: 0.9176 - val_loss: 1.0797 - learning_rate: 1.2500e-04
Epoch 64/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 17ms/step - auc: 0.9193 - loss: 1.0491 - val_auc: 0.9167 - val_loss: 1.0871 - learning_rate: 6.2500e-05
Epoch 65/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 17ms/step - auc: 0.9221 - loss: 1.0316 - val_auc: 0.9186 - val_loss: 1.0658 - learning_rate: 6.2500e-05
Epoch 66/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9220 - loss: 1.0330 - val_auc: 0.9211 - val_loss: 1.0479 - learning_rate: 6.2500e-05
Epoch 67/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9200 - loss: 1.0440 - val_auc: 0.9212 - val_loss: 1.0474 - learning_rate: 6.2500e-05
Epoch 68/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 9s 19ms/step - auc: 0.9202 - loss: 1.0422 - val_auc: 0.9239 - val_loss: 1.0286 - learning_rate: 6.2500e-05
Epoch 69/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9209 - loss: 1.0384 - val_auc: 0.9214 - val_loss: 1.0459 - learning_rate: 6.2500e-05
Epoch 70/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9216 - loss: 1.0348 - val_auc: 0.9220 - val_loss: 1.0438 - learning_rate: 6.2500e-05
Epoch 71/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 9s 19ms/step - auc: 0.9182 - loss: 1.0532 - val_auc: 0.9220 - val_loss: 1.0409 - learning_rate: 6.2500e-05
Epoch 72/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 19ms/step - auc: 0.9191 - loss: 1.0488 - val_auc: 0.9220 - val_loss: 1.0377 - learning_rate: 6.2500e-05
Epoch 73/100
448/449 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - auc: 0.9212 - loss: 1.0352
Epoch 73: ReduceLROnPlateau reducing learning rate to 3.125000148429535e-05.
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9212 - loss: 1.0352 - val_auc: 0.9196 - val_loss: 1.0645 - learning_rate: 6.2500e-05
Epoch 74/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9213 - loss: 1.0352 - val_auc: 0.9218 - val_loss: 1.0460 - learning_rate: 3.1250e-05
Epoch 75/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9225 - loss: 1.0280 - val_auc: 0.9227 - val_loss: 1.0395 - learning_rate: 3.1250e-05
Epoch 76/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 17ms/step - auc: 0.9222 - loss: 1.0293 - val_auc: 0.9219 - val_loss: 1.0443 - learning_rate: 3.1250e-05
Epoch 77/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 17ms/step - auc: 0.9224 - loss: 1.0290 - val_auc: 0.9239 - val_loss: 1.0309 - learning_rate: 3.1250e-05
Epoch 78/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9217 - loss: 1.0320 - val_auc: 0.9245 - val_loss: 1.0235 - learning_rate: 3.1250e-05
Epoch 79/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9222 - loss: 1.0292 - val_auc: 0.9233 - val_loss: 1.0315 - learning_rate: 3.1250e-05
Epoch 80/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 9s 19ms/step - auc: 0.9236 - loss: 1.0210 - val_auc: 0.9238 - val_loss: 1.0288 - learning_rate: 3.1250e-05
Epoch 81/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9242 - loss: 1.0178 - val_auc: 0.9244 - val_loss: 1.0249 - learning_rate: 3.1250e-05
Epoch 82/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9214 - loss: 1.0335 - val_auc: 0.9239 - val_loss: 1.0312 - learning_rate: 3.1250e-05
Epoch 83/100
446/449 ━━━━━━━━━━━━━━━━━━━━ 0s 17ms/step - auc: 0.9236 - loss: 1.0209
Epoch 83: ReduceLROnPlateau reducing learning rate to 1.5625000742147677e-05.
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9235 - loss: 1.0210 - val_auc: 0.9243 - val_loss: 1.0258 - learning_rate: 3.1250e-05
Epoch 84/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9218 - loss: 1.0302 - val_auc: 0.9234 - val_loss: 1.0343 - learning_rate: 1.5625e-05
Epoch 85/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 17ms/step - auc: 0.9214 - loss: 1.0334 - val_auc: 0.9242 - val_loss: 1.0282 - learning_rate: 1.5625e-05
Epoch 86/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 19ms/step - auc: 0.9224 - loss: 1.0275 - val_auc: 0.9233 - val_loss: 1.0353 - learning_rate: 1.5625e-05
Epoch 87/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 9s 19ms/step - auc: 0.9238 - loss: 1.0187 - val_auc: 0.9242 - val_loss: 1.0272 - learning_rate: 1.5625e-05
Epoch 88/100
449/449 ━━━━━━━━━━━━━━━━━━━━ 0s 16ms/step - auc: 0.9233 - loss: 1.0220
Epoch 88: ReduceLROnPlateau reducing learning rate to 7.812500371073838e-06.
449/449 ━━━━━━━━━━━━━━━━━━━━ 8s 18ms/step - auc: 0.9233 - loss: 1.0220 - val_auc: 0.9241 - val_loss: 1.0284 - learning_rate: 1.5625e-05
Epoch 88: early stopping
Restoring model weights from the end of the best epoch: 78.
# Curvas de aprendizaje
epochs_range = range(1, len(history_cnn.history['auc']) + 1)
best_epoch = int(np.argmax(history_cnn.history['val_auc'])) + 1
fig, ax = plt.subplots(1, 2)
fig.set_size_inches(12, 4)
ax[0].plot(epochs_range, history_cnn.history['auc'], color='#1f77b4', linewidth=1.6, label='Entrenamiento')
ax[0].plot(epochs_range, history_cnn.history['val_auc'], color='#d62728', linewidth=1.4,
linestyle='--', label='Validación')
ax[0].axvline(best_epoch, color='green', linewidth=1.0, linestyle=':', label=f'Mejor época ({best_epoch})')
ax[0].set_title('AUC en Entrenamiento vs Validación')
ax[0].set_ylabel('AUC')
ax[0].set_xlabel('Época')
ax[0].yaxis.set_major_formatter(ticker.FormatStrFormatter('%.2f'))
ax[0].legend(loc='lower right')
ax[1].plot(epochs_range, history_cnn.history['loss'], color='#1f77b4', linewidth=1.6, label='Entrenamiento')
ax[1].plot(epochs_range, history_cnn.history['val_loss'], color='#d62728', linewidth=1.4,
linestyle='--', label='Validación')
ax[1].axvline(best_epoch, color='green', linewidth=1.0, linestyle=':', label=f'Mejor época ({best_epoch})')
ax[1].set_title('Pérdida en Entrenamiento vs Validación')
ax[1].set_ylabel('Pérdida')
ax[1].set_xlabel('Época')
ax[1].yaxis.set_major_formatter(ticker.FormatStrFormatter('%.2f'))
ax[1].legend(loc='upper right')
plt.tight_layout()
plt.show()
Creamos los conjuntos de datos de entrenamiento, prueba y validación
train_datagen = ImageDataGenerator(rescale=1.0/255.0,
horizontal_flip=True,
validation_split=0.2)
rescale=1./255: Normaliza las imágenes escalando los valores de los píxeles de un rango de [0, 255] a [0, 1]. Esto es una práctica común para mejorar la eficiencia del entrenamiento de redes neuronales.horizontal_flip=True: Permite aplicar una transformación de “flip” horizontal (volteo) de manera aleatoria a las imágenes, una técnica de data augmentation para hacer que el modelo generalice mejor.validation_split=0.2: Define una división de los datos, reservando el 20% de ellos para validación, lo que significa que el 80% de los datos será usado para entrenamiento.
training_set = train_datagen.flow_from_directory(train_dir,
batch_size=64,
target_size=(48,48),
shuffle=True,
color_mode='grayscale',
class_mode='categorical',
subset='training')
Found 22968 images belonging to 7 classes.
train_dir: Es la ruta del directorio que contiene las imágenes de entrenamiento organizadas en subdirectorios según la clase.batch_size=64: Carga 64 imágenes a la vez (en lotes) para ser procesadas en cada paso del entrenamiento.target_size=(48,48): Redimensiona todas las imágenes al tamaño de 48x48 píxeles. Esto es útil para mantener un tamaño uniforme de las imágenes que ingresan al modelo.shuffle=True: Aleatoriza las imágenes en cada epoch, lo que evita que el modelo se adapte a un orden particular de los datos.color_mode='grayscale': Convierte las imágenes en escala de grises (1 canal en lugar de 3 para imágenes en color RGB).class_mode='categorical': Las etiquetas se asignan como categóricas, es decir, cada imagen pertenece a una clase específica (por ejemplo, clasificación multiclase).subset='training': Utiliza el 80% de los datos (definidos anteriormente convalidation_split=0.2) para entrenamiento.
validation_set = train_datagen.flow_from_directory(train_dir,
batch_size=64,
target_size=(48,48),
shuffle=True,
color_mode='grayscale',
class_mode='categorical',
subset='validation')
Found 5741 images belonging to 7 classes.
subset='validation': Selecciona el 20% de los datos reservados para la validación (definidos anteriormente convalidation_split=0.2)
test_datagen = ImageDataGenerator(rescale=1.0/255.0,
horizontal_flip=True)
test_set = test_datagen.flow_from_directory(test_dir,
batch_size=64,
target_size=(48,48),
shuffle=True,
color_mode='grayscale',
class_mode='categorical')
Found 7178 images belonging to 7 classes.
training_set.class_indices
{'angry': 0,
'disgust': 1,
'fear': 2,
'happy': 3,
'neutral': 4,
'sad': 5,
'surprise': 6}
Arquitectura del modelo. En este caso,
padding='same'indica que se realiza padding para que la salida tiene el mismo tamaño que la entrada.
weight_decay = 1e-4
num_classes = 7
# Arquitectura
model = tf.keras.models.Sequential([
# Bloque 1: kernels 3x3, extracción local fina
Conv2D(32, (3,3), padding='same', kernel_regularizer=l2(weight_decay),
input_shape=(48,48,1)),
BatchNormalization(),
Activation('elu'),
Conv2D(32, (3,3), padding='same', kernel_regularizer=l2(weight_decay)),
BatchNormalization(),
Activation('elu'),
MaxPooling2D((2,2)),
Dropout(0.3),
# Bloque 2
Conv2D(64, (3,3), padding='same', kernel_regularizer=l2(weight_decay)),
BatchNormalization(),
Activation('elu'),
Conv2D(64, (3,3), padding='same', kernel_regularizer=l2(weight_decay)),
BatchNormalization(),
Activation('elu'),
MaxPooling2D((2,2)),
Dropout(0.4),
# Bloque 3
Conv2D(128, (3,3), padding='same', kernel_regularizer=l2(weight_decay)),
BatchNormalization(),
Activation('elu'),
Conv2D(128, (3,3), padding='same', kernel_regularizer=l2(weight_decay)),
BatchNormalization(),
Activation('elu'),
MaxPooling2D((2,2)),
Dropout(0.5),
# Clasificador — GlobalAveragePooling reduce parámetros vs Flatten
GlobalAveragePooling2D(),
Dense(256, kernel_regularizer=l2(weight_decay)),
BatchNormalization(),
Activation('elu'),
Dropout(0.5),
Dense(num_classes, activation='softmax')
])
model.compile(
loss='categorical_crossentropy',
optimizer=Adam(learning_rate=1e-3),
metrics=[AUC(name='auc')]
)
model.summary()
Model: "sequential_3"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ conv2d_21 (Conv2D) │ (None, 48, 48, 32) │ 320 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ batch_normalization_21 │ (None, 48, 48, 32) │ 128 │ │ (BatchNormalization) │ │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ activation_24 (Activation) │ (None, 48, 48, 32) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ conv2d_22 (Conv2D) │ (None, 48, 48, 32) │ 9,248 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ batch_normalization_22 │ (None, 48, 48, 32) │ 128 │ │ (BatchNormalization) │ │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ activation_25 (Activation) │ (None, 48, 48, 32) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ max_pooling2d_12 (MaxPooling2D) │ (None, 24, 24, 32) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dropout_12 (Dropout) │ (None, 24, 24, 32) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ conv2d_23 (Conv2D) │ (None, 24, 24, 64) │ 18,496 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ batch_normalization_23 │ (None, 24, 24, 64) │ 256 │ │ (BatchNormalization) │ │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ activation_26 (Activation) │ (None, 24, 24, 64) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ conv2d_24 (Conv2D) │ (None, 24, 24, 64) │ 36,928 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ batch_normalization_24 │ (None, 24, 24, 64) │ 256 │ │ (BatchNormalization) │ │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ activation_27 (Activation) │ (None, 24, 24, 64) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ max_pooling2d_13 (MaxPooling2D) │ (None, 12, 12, 64) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dropout_13 (Dropout) │ (None, 12, 12, 64) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ conv2d_25 (Conv2D) │ (None, 12, 12, 128) │ 73,856 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ batch_normalization_25 │ (None, 12, 12, 128) │ 512 │ │ (BatchNormalization) │ │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ activation_28 (Activation) │ (None, 12, 12, 128) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ conv2d_26 (Conv2D) │ (None, 12, 12, 128) │ 147,584 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ batch_normalization_26 │ (None, 12, 12, 128) │ 512 │ │ (BatchNormalization) │ │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ activation_29 (Activation) │ (None, 12, 12, 128) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ max_pooling2d_14 (MaxPooling2D) │ (None, 6, 6, 128) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dropout_14 (Dropout) │ (None, 6, 6, 128) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ global_average_pooling2d │ (None, 128) │ 0 │ │ (GlobalAveragePooling2D) │ │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_6 (Dense) │ (None, 256) │ 33,024 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ batch_normalization_27 │ (None, 256) │ 1,024 │ │ (BatchNormalization) │ │ │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ activation_30 (Activation) │ (None, 256) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dropout_15 (Dropout) │ (None, 256) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_7 (Dense) │ (None, 7) │ 1,799 │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 324,071 (1.24 MB)
Trainable params: 322,663 (1.23 MB)
Non-trainable params: 1,408 (5.50 KB)
plot_model(model, to_file='model_cnn.png', show_shapes=True, show_layer_names=True)

epochs = 200
checkpointer = [
EarlyStopping(
monitor='val_auc',
verbose=1,
restore_best_weights=True,
mode='max',
patience=50
),
ModelCheckpoint(
filepath='model.weights.best.keras',
monitor='val_auc',
verbose=1,
save_best_only=True,
mode='max'
)
]
import os
from joblib import dump, load
history_cnn = None
if os.path.exists('history_cnn.joblib'):
history_cnn = load('history_cnn.joblib')
print("El archivo 'history_cnn.joblib' ya existe. Se ha cargado el historial del entrenamiento.")
else:
history_cnn = model.fit(x = training_set,
epochs = epochs, callbacks=checkpointer,
validation_data = validation_set,
verbose = 2)
dump(history_cnn.history, 'history_cnn.joblib')
print("El entrenamiento se ha completado y el historial ha sido guardado en 'history_cnn.joblib'.")
Epoch 1/200
2026-05-08 23:46:57.073819: I external/local_xla/xla/stream_executor/cuda/cuda_asm_compiler.cc:393] ptxas warning : Registers are spilled to local memory in function 'gemm_fusion_dot_4560', 452 bytes spill stores, 452 bytes spill loads
2026-05-08 23:46:57.140400: I external/local_xla/xla/stream_executor/cuda/cuda_asm_compiler.cc:393] ptxas warning : Registers are spilled to local memory in function 'gemm_fusion_dot_4560', 492 bytes spill stores, 492 bytes spill loads
2026-05-08 23:47:04.226936: I external/local_xla/xla/stream_executor/cuda/cuda_asm_compiler.cc:393] ptxas warning : Registers are spilled to local memory in function 'gemm_fusion_dot_4578', 4 bytes spill stores, 4 bytes spill loads
2026-05-08 23:47:04.627090: I external/local_xla/xla/stream_executor/cuda/cuda_asm_compiler.cc:393] ptxas warning : Registers are spilled to local memory in function 'gemm_fusion_dot_4560', 452 bytes spill stores, 452 bytes spill loads
2026-05-08 23:47:04.646176: I external/local_xla/xla/stream_executor/cuda/cuda_asm_compiler.cc:393] ptxas warning : Registers are spilled to local memory in function 'gemm_fusion_dot_4560', 436 bytes spill stores, 436 bytes spill loads
2026-05-08 23:47:09.750758: I external/local_xla/xla/stream_executor/cuda/cuda_asm_compiler.cc:393] ptxas warning : Registers are spilled to local memory in function 'gemm_fusion_dot_325', 8 bytes spill stores, 8 bytes spill loads
Epoch 1: val_auc improved from -inf to 0.67825, saving model to model.weights.best.keras
359/359 - 17s - 48ms/step - auc: 0.6289 - loss: 2.1100 - val_auc: 0.6783 - val_loss: 1.8584
Epoch 2/200
Epoch 2: val_auc improved from 0.67825 to 0.73554, saving model to model.weights.best.keras
359/359 - 3s - 9ms/step - auc: 0.7298 - loss: 1.7684 - val_auc: 0.7355 - val_loss: 1.8828
Epoch 3/200
Epoch 3: val_auc improved from 0.73554 to 0.78362, saving model to model.weights.best.keras
359/359 - 3s - 10ms/step - auc: 0.7810 - loss: 1.6103 - val_auc: 0.7836 - val_loss: 1.6034
Epoch 4/200
Epoch 4: val_auc improved from 0.78362 to 0.81577, saving model to model.weights.best.keras
359/359 - 4s - 10ms/step - auc: 0.8096 - loss: 1.5199 - val_auc: 0.8158 - val_loss: 1.5023
Epoch 5/200
Epoch 5: val_auc improved from 0.81577 to 0.82983, saving model to model.weights.best.keras
359/359 - 3s - 10ms/step - auc: 0.8241 - loss: 1.4727 - val_auc: 0.8298 - val_loss: 1.4517
Epoch 6/200
Epoch 6: val_auc did not improve from 0.82983
359/359 - 3s - 10ms/step - auc: 0.8339 - loss: 1.4391 - val_auc: 0.8274 - val_loss: 1.4661
Epoch 7/200
Epoch 7: val_auc improved from 0.82983 to 0.83052, saving model to model.weights.best.keras
359/359 - 3s - 10ms/step - auc: 0.8398 - loss: 1.4195 - val_auc: 0.8305 - val_loss: 1.4796
Epoch 8/200
Epoch 8: val_auc improved from 0.83052 to 0.83817, saving model to model.weights.best.keras
359/359 - 3s - 9ms/step - auc: 0.8477 - loss: 1.3919 - val_auc: 0.8382 - val_loss: 1.4406
Epoch 9/200
Epoch 9: val_auc improved from 0.83817 to 0.83835, saving model to model.weights.best.keras
359/359 - 3s - 10ms/step - auc: 0.8527 - loss: 1.3732 - val_auc: 0.8383 - val_loss: 1.4370
Epoch 10/200
Epoch 10: val_auc improved from 0.83835 to 0.86255, saving model to model.weights.best.keras
359/359 - 4s - 10ms/step - auc: 0.8597 - loss: 1.3485 - val_auc: 0.8625 - val_loss: 1.3350
Epoch 11/200
Epoch 11: val_auc improved from 0.86255 to 0.86344, saving model to model.weights.best.keras
359/359 - 3s - 9ms/step - auc: 0.8635 - loss: 1.3348 - val_auc: 0.8634 - val_loss: 1.3520
Epoch 12/200
Epoch 12: val_auc improved from 0.86344 to 0.87217, saving model to model.weights.best.keras
359/359 - 3s - 9ms/step - auc: 0.8665 - loss: 1.3221 - val_auc: 0.8722 - val_loss: 1.3010
Epoch 13/200
Epoch 13: val_auc improved from 0.87217 to 0.88287, saving model to model.weights.best.keras
359/359 - 3s - 9ms/step - auc: 0.8707 - loss: 1.3080 - val_auc: 0.8829 - val_loss: 1.2522
Epoch 14/200
Epoch 14: val_auc did not improve from 0.88287
359/359 - 3s - 9ms/step - auc: 0.8745 - loss: 1.2936 - val_auc: 0.8775 - val_loss: 1.2840
Epoch 15/200
Epoch 15: val_auc did not improve from 0.88287
359/359 - 3s - 9ms/step - auc: 0.8777 - loss: 1.2809 - val_auc: 0.8800 - val_loss: 1.2714
Epoch 16/200
Epoch 16: val_auc did not improve from 0.88287
359/359 - 3s - 9ms/step - auc: 0.8784 - loss: 1.2792 - val_auc: 0.8620 - val_loss: 1.3548
Epoch 17/200
Epoch 17: val_auc did not improve from 0.88287
359/359 - 3s - 9ms/step - auc: 0.8817 - loss: 1.2662 - val_auc: 0.8771 - val_loss: 1.2872
Epoch 18/200
Epoch 18: val_auc did not improve from 0.88287
359/359 - 3s - 8ms/step - auc: 0.8833 - loss: 1.2598 - val_auc: 0.8794 - val_loss: 1.2798
Epoch 19/200
Epoch 19: val_auc did not improve from 0.88287
359/359 - 3s - 9ms/step - auc: 0.8858 - loss: 1.2496 - val_auc: 0.8823 - val_loss: 1.2766
Epoch 20/200
Epoch 20: val_auc improved from 0.88287 to 0.88933, saving model to model.weights.best.keras
359/359 - 3s - 9ms/step - auc: 0.8874 - loss: 1.2438 - val_auc: 0.8893 - val_loss: 1.2357
Epoch 21/200
Epoch 21: val_auc did not improve from 0.88933
359/359 - 3s - 9ms/step - auc: 0.8900 - loss: 1.2326 - val_auc: 0.8854 - val_loss: 1.2646
Epoch 22/200
Epoch 22: val_auc did not improve from 0.88933
359/359 - 3s - 9ms/step - auc: 0.8918 - loss: 1.2256 - val_auc: 0.8688 - val_loss: 1.3632
Epoch 23/200
Epoch 23: val_auc did not improve from 0.88933
359/359 - 3s - 8ms/step - auc: 0.8931 - loss: 1.2218 - val_auc: 0.8857 - val_loss: 1.2591
Epoch 24/200
Epoch 24: val_auc did not improve from 0.88933
359/359 - 3s - 8ms/step - auc: 0.8942 - loss: 1.2161 - val_auc: 0.8774 - val_loss: 1.3262
Epoch 25/200
Epoch 25: val_auc improved from 0.88933 to 0.89485, saving model to model.weights.best.keras
359/359 - 3s - 9ms/step - auc: 0.8953 - loss: 1.2118 - val_auc: 0.8948 - val_loss: 1.2140
Epoch 26/200
Epoch 26: val_auc did not improve from 0.89485
359/359 - 3s - 9ms/step - auc: 0.8982 - loss: 1.1992 - val_auc: 0.8834 - val_loss: 1.2773
Epoch 27/200
Epoch 27: val_auc did not improve from 0.89485
359/359 - 3s - 8ms/step - auc: 0.8995 - loss: 1.1935 - val_auc: 0.8888 - val_loss: 1.2591
Epoch 28/200
Epoch 28: val_auc did not improve from 0.89485
359/359 - 3s - 8ms/step - auc: 0.8998 - loss: 1.1943 - val_auc: 0.8934 - val_loss: 1.2315
Epoch 29/200
Epoch 29: val_auc did not improve from 0.89485
359/359 - 3s - 9ms/step - auc: 0.9009 - loss: 1.1896 - val_auc: 0.8775 - val_loss: 1.3202
Epoch 30/200
Epoch 30: val_auc did not improve from 0.89485
359/359 - 3s - 8ms/step - auc: 0.9020 - loss: 1.1840 - val_auc: 0.8902 - val_loss: 1.2503
Epoch 31/200
Epoch 31: val_auc improved from 0.89485 to 0.89693, saving model to model.weights.best.keras
359/359 - 3s - 9ms/step - auc: 0.9034 - loss: 1.1780 - val_auc: 0.8969 - val_loss: 1.2120
Epoch 32/200
Epoch 32: val_auc did not improve from 0.89693
359/359 - 3s - 9ms/step - auc: 0.9041 - loss: 1.1746 - val_auc: 0.8820 - val_loss: 1.2932
Epoch 33/200
Epoch 33: val_auc did not improve from 0.89693
359/359 - 3s - 9ms/step - auc: 0.9037 - loss: 1.1784 - val_auc: 0.8875 - val_loss: 1.2665
Epoch 34/200
Epoch 34: val_auc did not improve from 0.89693
359/359 - 4s - 10ms/step - auc: 0.9061 - loss: 1.1670 - val_auc: 0.8882 - val_loss: 1.2875
Epoch 35/200
Epoch 35: val_auc did not improve from 0.89693
359/359 - 3s - 10ms/step - auc: 0.9065 - loss: 1.1660 - val_auc: 0.8946 - val_loss: 1.2513
Epoch 36/200
Epoch 36: val_auc did not improve from 0.89693
359/359 - 3s - 9ms/step - auc: 0.9070 - loss: 1.1632 - val_auc: 0.8489 - val_loss: 1.5025
Epoch 37/200
Epoch 37: val_auc did not improve from 0.89693
359/359 - 3s - 9ms/step - auc: 0.9076 - loss: 1.1614 - val_auc: 0.8390 - val_loss: 1.6907
Epoch 38/200
Epoch 38: val_auc improved from 0.89693 to 0.89817, saving model to model.weights.best.keras
359/359 - 3s - 9ms/step - auc: 0.9094 - loss: 1.1520 - val_auc: 0.8982 - val_loss: 1.2199
Epoch 39/200
Epoch 39: val_auc did not improve from 0.89817
359/359 - 3s - 8ms/step - auc: 0.9098 - loss: 1.1508 - val_auc: 0.8396 - val_loss: 1.5477
Epoch 40/200
Epoch 40: val_auc did not improve from 0.89817
359/359 - 3s - 8ms/step - auc: 0.9093 - loss: 1.1551 - val_auc: 0.8890 - val_loss: 1.2983
Epoch 41/200
Epoch 41: val_auc did not improve from 0.89817
359/359 - 3s - 8ms/step - auc: 0.9100 - loss: 1.1520 - val_auc: 0.8899 - val_loss: 1.2844
Epoch 42/200
Epoch 42: val_auc improved from 0.89817 to 0.89956, saving model to model.weights.best.keras
359/359 - 3s - 9ms/step - auc: 0.9109 - loss: 1.1477 - val_auc: 0.8996 - val_loss: 1.2117
Epoch 43/200
Epoch 43: val_auc improved from 0.89956 to 0.90143, saving model to model.weights.best.keras
359/359 - 3s - 9ms/step - auc: 0.9123 - loss: 1.1407 - val_auc: 0.9014 - val_loss: 1.2101
Epoch 44/200
Epoch 44: val_auc did not improve from 0.90143
359/359 - 3s - 8ms/step - auc: 0.9122 - loss: 1.1411 - val_auc: 0.9002 - val_loss: 1.2099
Epoch 45/200
Epoch 45: val_auc did not improve from 0.90143
359/359 - 3s - 8ms/step - auc: 0.9138 - loss: 1.1339 - val_auc: 0.8968 - val_loss: 1.2309
Epoch 46/200
Epoch 46: val_auc did not improve from 0.90143
359/359 - 3s - 8ms/step - auc: 0.9147 - loss: 1.1288 - val_auc: 0.8639 - val_loss: 1.5575
Epoch 47/200
Epoch 47: val_auc did not improve from 0.90143
359/359 - 3s - 8ms/step - auc: 0.9142 - loss: 1.1329 - val_auc: 0.8714 - val_loss: 1.3775
Epoch 48/200
Epoch 48: val_auc did not improve from 0.90143
359/359 - 3s - 8ms/step - auc: 0.9155 - loss: 1.1265 - val_auc: 0.8875 - val_loss: 1.3001
Epoch 49/200
Epoch 49: val_auc did not improve from 0.90143
359/359 - 3s - 8ms/step - auc: 0.9160 - loss: 1.1247 - val_auc: 0.8603 - val_loss: 1.4772
Epoch 50/200
Epoch 50: val_auc did not improve from 0.90143
359/359 - 3s - 8ms/step - auc: 0.9167 - loss: 1.1219 - val_auc: 0.8814 - val_loss: 1.3680
Epoch 51/200
Epoch 51: val_auc did not improve from 0.90143
359/359 - 3s - 8ms/step - auc: 0.9168 - loss: 1.1219 - val_auc: 0.8607 - val_loss: 1.5710
Epoch 52/200
Epoch 52: val_auc did not improve from 0.90143
359/359 - 3s - 8ms/step - auc: 0.9188 - loss: 1.1102 - val_auc: 0.8482 - val_loss: 1.7878
Epoch 53/200
Epoch 53: val_auc did not improve from 0.90143
359/359 - 3s - 9ms/step - auc: 0.9179 - loss: 1.1169 - val_auc: 0.8870 - val_loss: 1.3203
Epoch 54/200
Epoch 54: val_auc did not improve from 0.90143
359/359 - 3s - 9ms/step - auc: 0.9188 - loss: 1.1122 - val_auc: 0.8915 - val_loss: 1.2772
Epoch 55/200
Epoch 55: val_auc improved from 0.90143 to 0.90439, saving model to model.weights.best.keras
359/359 - 3s - 9ms/step - auc: 0.9184 - loss: 1.1145 - val_auc: 0.9044 - val_loss: 1.2121
Epoch 56/200
Epoch 56: val_auc did not improve from 0.90439
359/359 - 3s - 9ms/step - auc: 0.9196 - loss: 1.1083 - val_auc: 0.8973 - val_loss: 1.2370
Epoch 57/200
Epoch 57: val_auc did not improve from 0.90439
359/359 - 3s - 9ms/step - auc: 0.9203 - loss: 1.1051 - val_auc: 0.8921 - val_loss: 1.3001
Epoch 58/200
Epoch 58: val_auc did not improve from 0.90439
359/359 - 3s - 9ms/step - auc: 0.9204 - loss: 1.1041 - val_auc: 0.8188 - val_loss: 1.8108
Epoch 59/200
Epoch 59: val_auc did not improve from 0.90439
359/359 - 3s - 8ms/step - auc: 0.9205 - loss: 1.1039 - val_auc: 0.8852 - val_loss: 1.3687
Epoch 60/200
Epoch 60: val_auc did not improve from 0.90439
359/359 - 3s - 9ms/step - auc: 0.9205 - loss: 1.1054 - val_auc: 0.8658 - val_loss: 1.4205
Epoch 61/200
Epoch 61: val_auc did not improve from 0.90439
359/359 - 3s - 9ms/step - auc: 0.9222 - loss: 1.0960 - val_auc: 0.8829 - val_loss: 1.3409
Epoch 62/200
Epoch 62: val_auc did not improve from 0.90439
359/359 - 3s - 9ms/step - auc: 0.9212 - loss: 1.1028 - val_auc: 0.8763 - val_loss: 1.4201
Epoch 63/200
Epoch 63: val_auc did not improve from 0.90439
359/359 - 3s - 9ms/step - auc: 0.9233 - loss: 1.0903 - val_auc: 0.8744 - val_loss: 1.4674
Epoch 64/200
Epoch 64: val_auc did not improve from 0.90439
359/359 - 3s - 9ms/step - auc: 0.9227 - loss: 1.0953 - val_auc: 0.8850 - val_loss: 1.3868
Epoch 65/200
Epoch 65: val_auc did not improve from 0.90439
359/359 - 3s - 8ms/step - auc: 0.9233 - loss: 1.0932 - val_auc: 0.8958 - val_loss: 1.2844
Epoch 66/200
Epoch 66: val_auc did not improve from 0.90439
359/359 - 3s - 9ms/step - auc: 0.9235 - loss: 1.0912 - val_auc: 0.9004 - val_loss: 1.2308
Epoch 67/200
Epoch 67: val_auc did not improve from 0.90439
359/359 - 3s - 9ms/step - auc: 0.9236 - loss: 1.0914 - val_auc: 0.8780 - val_loss: 1.4744
Epoch 68/200
Epoch 68: val_auc did not improve from 0.90439
359/359 - 3s - 9ms/step - auc: 0.9236 - loss: 1.0924 - val_auc: 0.8584 - val_loss: 1.5533
Epoch 69/200
Epoch 69: val_auc improved from 0.90439 to 0.90910, saving model to model.weights.best.keras
359/359 - 3s - 9ms/step - auc: 0.9248 - loss: 1.0855 - val_auc: 0.9091 - val_loss: 1.2018
Epoch 70/200
Epoch 70: val_auc did not improve from 0.90910
359/359 - 3s - 9ms/step - auc: 0.9253 - loss: 1.0823 - val_auc: 0.8665 - val_loss: 1.4872
Epoch 71/200
Epoch 71: val_auc did not improve from 0.90910
359/359 - 3s - 10ms/step - auc: 0.9255 - loss: 1.0828 - val_auc: 0.8492 - val_loss: 1.5508
Epoch 72/200
Epoch 72: val_auc did not improve from 0.90910
359/359 - 3s - 9ms/step - auc: 0.9262 - loss: 1.0788 - val_auc: 0.8925 - val_loss: 1.3257
Epoch 73/200
Epoch 73: val_auc did not improve from 0.90910
359/359 - 3s - 9ms/step - auc: 0.9256 - loss: 1.0827 - val_auc: 0.8883 - val_loss: 1.3597
Epoch 74/200
Epoch 74: val_auc did not improve from 0.90910
359/359 - 3s - 10ms/step - auc: 0.9272 - loss: 1.0736 - val_auc: 0.8436 - val_loss: 1.6188
Epoch 75/200
Epoch 75: val_auc did not improve from 0.90910
359/359 - 3s - 10ms/step - auc: 0.9256 - loss: 1.0844 - val_auc: 0.8646 - val_loss: 1.4274
Epoch 76/200
Epoch 76: val_auc did not improve from 0.90910
359/359 - 4s - 10ms/step - auc: 0.9276 - loss: 1.0719 - val_auc: 0.8750 - val_loss: 1.3821
Epoch 77/200
Epoch 77: val_auc did not improve from 0.90910
359/359 - 3s - 9ms/step - auc: 0.9280 - loss: 1.0698 - val_auc: 0.8866 - val_loss: 1.3290
Epoch 78/200
Epoch 78: val_auc did not improve from 0.90910
359/359 - 3s - 9ms/step - auc: 0.9272 - loss: 1.0752 - val_auc: 0.8916 - val_loss: 1.2933
Epoch 79/200
Epoch 79: val_auc did not improve from 0.90910
359/359 - 3s - 10ms/step - auc: 0.9280 - loss: 1.0708 - val_auc: 0.8468 - val_loss: 1.6270
Epoch 80/200
Epoch 80: val_auc did not improve from 0.90910
359/359 - 3s - 9ms/step - auc: 0.9283 - loss: 1.0696 - val_auc: 0.8755 - val_loss: 1.4063
Epoch 81/200
Epoch 81: val_auc did not improve from 0.90910
359/359 - 3s - 9ms/step - auc: 0.9278 - loss: 1.0733 - val_auc: 0.8441 - val_loss: 1.6645
Epoch 82/200
Epoch 82: val_auc did not improve from 0.90910
359/359 - 3s - 8ms/step - auc: 0.9293 - loss: 1.0639 - val_auc: 0.8989 - val_loss: 1.2887
Epoch 83/200
Epoch 83: val_auc did not improve from 0.90910
359/359 - 3s - 8ms/step - auc: 0.9294 - loss: 1.0637 - val_auc: 0.7486 - val_loss: 2.3314
Epoch 84/200
Epoch 84: val_auc did not improve from 0.90910
359/359 - 3s - 8ms/step - auc: 0.9302 - loss: 1.0602 - val_auc: 0.8831 - val_loss: 1.4341
Epoch 85/200
Epoch 85: val_auc did not improve from 0.90910
359/359 - 3s - 8ms/step - auc: 0.9301 - loss: 1.0609 - val_auc: 0.8885 - val_loss: 1.3496
Epoch 86/200
Epoch 86: val_auc did not improve from 0.90910
359/359 - 3s - 8ms/step - auc: 0.9301 - loss: 1.0619 - val_auc: 0.8710 - val_loss: 1.4527
Epoch 87/200
Epoch 87: val_auc did not improve from 0.90910
359/359 - 3s - 8ms/step - auc: 0.9303 - loss: 1.0595 - val_auc: 0.8639 - val_loss: 1.5638
Epoch 88/200
Epoch 88: val_auc did not improve from 0.90910
359/359 - 3s - 9ms/step - auc: 0.9309 - loss: 1.0566 - val_auc: 0.9029 - val_loss: 1.2444
Epoch 89/200
Epoch 89: val_auc did not improve from 0.90910
359/359 - 3s - 8ms/step - auc: 0.9298 - loss: 1.0651 - val_auc: 0.8648 - val_loss: 1.5104
Epoch 90/200
Epoch 90: val_auc did not improve from 0.90910
359/359 - 3s - 8ms/step - auc: 0.9321 - loss: 1.0509 - val_auc: 0.8826 - val_loss: 1.4163
Epoch 91/200
Epoch 91: val_auc did not improve from 0.90910
359/359 - 3s - 9ms/step - auc: 0.9311 - loss: 1.0577 - val_auc: 0.8854 - val_loss: 1.3520
Epoch 92/200
Epoch 92: val_auc did not improve from 0.90910
359/359 - 3s - 9ms/step - auc: 0.9327 - loss: 1.0477 - val_auc: 0.8779 - val_loss: 1.4405
Epoch 93/200
Epoch 93: val_auc did not improve from 0.90910
359/359 - 3s - 8ms/step - auc: 0.9323 - loss: 1.0499 - val_auc: 0.8722 - val_loss: 1.5153
Epoch 94/200
Epoch 94: val_auc did not improve from 0.90910
359/359 - 3s - 8ms/step - auc: 0.9319 - loss: 1.0536 - val_auc: 0.8538 - val_loss: 1.5918
Epoch 95/200
Epoch 95: val_auc did not improve from 0.90910
359/359 - 3s - 8ms/step - auc: 0.9322 - loss: 1.0526 - val_auc: 0.8205 - val_loss: 1.8310
Epoch 96/200
Epoch 96: val_auc did not improve from 0.90910
359/359 - 3s - 9ms/step - auc: 0.9326 - loss: 1.0504 - val_auc: 0.8169 - val_loss: 1.7962
Epoch 97/200
Epoch 97: val_auc did not improve from 0.90910
359/359 - 3s - 8ms/step - auc: 0.9328 - loss: 1.0490 - val_auc: 0.8724 - val_loss: 1.5577
Epoch 98/200
Epoch 98: val_auc did not improve from 0.90910
359/359 - 3s - 8ms/step - auc: 0.9325 - loss: 1.0514 - val_auc: 0.8640 - val_loss: 1.4879
Epoch 99/200
Epoch 99: val_auc did not improve from 0.90910
359/359 - 3s - 8ms/step - auc: 0.9326 - loss: 1.0511 - val_auc: 0.7947 - val_loss: 1.9542
Epoch 100/200
Epoch 100: val_auc did not improve from 0.90910
359/359 - 3s - 8ms/step - auc: 0.9331 - loss: 1.0483 - val_auc: 0.8573 - val_loss: 1.5702
Epoch 101/200
Epoch 101: val_auc did not improve from 0.90910
359/359 - 3s - 8ms/step - auc: 0.9344 - loss: 1.0401 - val_auc: 0.8834 - val_loss: 1.4251
Epoch 102/200
Epoch 102: val_auc did not improve from 0.90910
359/359 - 3s - 9ms/step - auc: 0.9358 - loss: 1.0317 - val_auc: 0.8616 - val_loss: 1.5661
Epoch 103/200
Epoch 103: val_auc did not improve from 0.90910
359/359 - 3s - 9ms/step - auc: 0.9347 - loss: 1.0386 - val_auc: 0.8014 - val_loss: 2.1424
Epoch 104/200
Epoch 104: val_auc did not improve from 0.90910
359/359 - 3s - 9ms/step - auc: 0.9354 - loss: 1.0354 - val_auc: 0.8905 - val_loss: 1.3629
Epoch 105/200
Epoch 105: val_auc did not improve from 0.90910
359/359 - 3s - 9ms/step - auc: 0.9347 - loss: 1.0399 - val_auc: 0.8519 - val_loss: 1.5818
Epoch 106/200
Epoch 106: val_auc did not improve from 0.90910
359/359 - 3s - 8ms/step - auc: 0.9347 - loss: 1.0411 - val_auc: 0.8436 - val_loss: 1.7939
Epoch 107/200
Epoch 107: val_auc did not improve from 0.90910
359/359 - 3s - 9ms/step - auc: 0.9346 - loss: 1.0417 - val_auc: 0.8331 - val_loss: 1.9790
Epoch 108/200
Epoch 108: val_auc did not improve from 0.90910
359/359 - 3s - 8ms/step - auc: 0.9361 - loss: 1.0315 - val_auc: 0.8849 - val_loss: 1.4089
Epoch 109/200
Epoch 109: val_auc did not improve from 0.90910
359/359 - 3s - 9ms/step - auc: 0.9362 - loss: 1.0320 - val_auc: 0.8921 - val_loss: 1.3432
Epoch 110/200
Epoch 110: val_auc did not improve from 0.90910
359/359 - 3s - 9ms/step - auc: 0.9371 - loss: 1.0256 - val_auc: 0.8259 - val_loss: 1.8209
Epoch 111/200
Epoch 111: val_auc did not improve from 0.90910
359/359 - 3s - 9ms/step - auc: 0.9363 - loss: 1.0323 - val_auc: 0.8189 - val_loss: 2.1926
Epoch 112/200
Epoch 112: val_auc did not improve from 0.90910
359/359 - 3s - 9ms/step - auc: 0.9373 - loss: 1.0255 - val_auc: 0.8964 - val_loss: 1.3197
Epoch 113/200
Epoch 113: val_auc did not improve from 0.90910
359/359 - 3s - 9ms/step - auc: 0.9363 - loss: 1.0329 - val_auc: 0.8081 - val_loss: 1.8830
Epoch 114/200
Epoch 114: val_auc did not improve from 0.90910
359/359 - 4s - 10ms/step - auc: 0.9369 - loss: 1.0294 - val_auc: 0.8351 - val_loss: 1.8332
Epoch 115/200
Epoch 115: val_auc did not improve from 0.90910
359/359 - 3s - 10ms/step - auc: 0.9370 - loss: 1.0287 - val_auc: 0.8708 - val_loss: 1.5848
Epoch 116/200
Epoch 116: val_auc did not improve from 0.90910
359/359 - 3s - 9ms/step - auc: 0.9372 - loss: 1.0275 - val_auc: 0.8557 - val_loss: 1.5572
Epoch 117/200
Epoch 117: val_auc did not improve from 0.90910
359/359 - 3s - 8ms/step - auc: 0.9372 - loss: 1.0282 - val_auc: 0.8205 - val_loss: 1.7238
Epoch 118/200
Epoch 118: val_auc did not improve from 0.90910
359/359 - 3s - 9ms/step - auc: 0.9376 - loss: 1.0258 - val_auc: 0.8422 - val_loss: 1.7819
Epoch 119/200
Epoch 119: val_auc did not improve from 0.90910
359/359 - 3s - 9ms/step - auc: 0.9378 - loss: 1.0255 - val_auc: 0.8094 - val_loss: 1.9057
Epoch 119: early stopping
Restoring model weights from the end of the best epoch: 69.
El entrenamiento se ha completado y el historial ha sido guardado en 'history_cnn.joblib'.
fig, ax = plt.subplots(1, 2)
fig.set_size_inches(12, 4)
# AUC
ax[0].plot(history_cnn.history['auc'])
ax[0].plot(history_cnn.history['val_auc'])
ax[0].set_title('AUC en Entrenamiento vs Validación')
ax[0].set_ylabel('AUC')
ax[0].set_xlabel('Época')
ax[0].legend(['Entrenamiento', 'Validación'], loc='lower right')
# Loss
ax[1].plot(history_cnn.history['loss'])
ax[1].plot(history_cnn.history['val_loss'])
ax[1].set_title('Pérdida en Entrenamiento vs Validación')
ax[1].set_ylabel('Pérdida')
ax[1].set_xlabel('Época')
ax[1].legend(['Entrenamiento', 'Validación'], loc='upper right')
plt.tight_layout()
plt.show()
train_loss, train_auc = model.evaluate(training_set)
test_loss, test_auc = model.evaluate(validation_set)
print("final train accuracy = {:.2f} , validation accuracy = {:.2f}".format(train_auc*100, test_auc*100))
359/359 ━━━━━━━━━━━━━━━━━━━━ 3s 9ms/step - auc: 0.9432 - loss: 0.9625
90/90 ━━━━━━━━━━━━━━━━━━━━ 1s 7ms/step - auc: 0.9086 - loss: 1.2051
final train accuracy = 94.35 , validation accuracy = 90.81
Matriz de confusión del conjunto de entrenamiento
y_pred = model.predict(training_set)
y_pred = np.argmax(y_pred, axis=1)
class_labels = test_set.class_indices
class_labels = {v:k for k,v in class_labels.items()}
from sklearn.metrics import classification_report, confusion_matrix
cm_train = confusion_matrix(training_set.classes, y_pred)
print('Confusion Matrix')
print(cm_train)
print('Classification Report')
target_names = list(class_labels.values())
print(classification_report(training_set.classes, y_pred, target_names=target_names))
plt.figure(figsize=(8,8))
plt.imshow(cm_train, interpolation='nearest')
plt.colorbar()
tick_mark = np.arange(len(target_names))
_ = plt.xticks(tick_mark, target_names, rotation=90)
_ = plt.yticks(tick_mark, target_names)
Matriz de confusión en el conjunto de datos de validación
y_pred = model.predict(validation_set)
y_pred = np.argmax(y_pred, axis=1)
cm_val = confusion_matrix(validation_set.classes, y_pred)
print('Confusion Matrix')
print(cm_val)
print('Classification Report')
target_names = list(class_labels.values())
print(classification_report(validation_set.classes, y_pred, target_names=target_names))
plt.figure(figsize=(8,8))
plt.imshow(cm_train, interpolation='nearest')
plt.colorbar()
tick_mark = np.arange(len(target_names))
_ = plt.xticks(tick_mark, target_names, rotation=90)
_ = plt.yticks(tick_mark, target_names)
Matriz de confusión del conjunto de datos de prueba
y_pred = model.predict(test_set)
y_pred = np.argmax(y_pred, axis=1)
cm_test = confusion_matrix(test_set.classes, y_pred)
print('Confusion Matrix')
print(cm_test)
print('Classification Report')
target_names = list(class_labels.values())
print(classification_report(test_set.classes, y_pred, target_names=target_names))
plt.figure(figsize=(8,8))
plt.imshow(cm_test, interpolation='nearest')
plt.colorbar()
tick_mark = np.arange(len(target_names))
_ = plt.xticks(tick_mark, target_names, rotation=90)
_ = plt.yticks(tick_mark, target_names)
Grafico de predicciones
import numpy as np
x_test, y_test = next(test_set)
predict = model.predict(x_test)
figure = plt.figure(figsize=(20, 8))
for i, index in enumerate(np.random.choice(x_test.shape[0], size=24, replace=False)):
ax = figure.add_subplot(4, 6, i + 1, xticks=[], yticks=[])
ax.imshow(np.squeeze(x_test[index]))
predict_index = class_labels[np.argmax(predict[index])]
true_index = class_labels[np.argmax(y_test[index])]
ax.set_title(f"{predict_index} ({true_index})",
color=("green" if predict_index == true_index else "red"))
11.16.18. Aplicación: Segmentación de Imágenes Biomédicas con U-Net#
El cáncer de mama es una de las principales causas de mortalidad en mujeres, y su detección temprana reduce muertes prematuras. Este conjunto de datos de ultrasonido mamario incluye 780 imágenes de 600 pacientes (25-75 años), recopiladas en 2018, clasificadas en normales, benignas y malignas. Las imágenes, en formato PNG (500×500 píxeles), incluyen referencias (ground truth) para mejorar su análisis mediante aprendizaje automático en clasificación, detección y segmentación (ver Breast Ultrasound Images Dataset).
import tensorflow as tf
from glob import glob
import numpy as np
from sklearn.model_selection import train_test_split
import cv2
import matplotlib.pyplot as plt
from keras.models import Model
from keras.layers import Input, Conv2D, MaxPooling2D, Conv2DTranspose, concatenate
from keras.optimizers import Adam
from tensorflow.keras.metrics import *
paths = glob('/home/lihkir/datasets/Dataset_BUSI_with_GT/*/*')
print(f'\033[92m')
print(f"'normal' class has {len([i for i in paths if 'normal' in i and 'mask' not in i])} images and {len([i for i in paths if 'normal' in i and 'mask' in i])} masks.")
print(f"'benign' class has {len([i for i in paths if 'benign' in i and 'mask' not in i])} images and {len([i for i in paths if 'benign' in i and 'mask' in i])} masks.")
print(f"'malignant' class has {len([i for i in paths if 'malignant' in i and 'mask' not in i])} images and {len([i for i in paths if 'malignant' in i and 'mask' in i])} masks.")
print(f"\nThere are total of {len([i for i in paths if 'mask' not in i])} images and {len([i for i in paths if 'mask' in i])} masks.")
'normal' class has 133 images and 133 masks.
'benign' class has 437 images and 454 masks.
'malignant' class has 210 images and 211 masks.
There are total of 780 images and 798 masks.
sorted(glob('/home/lihkir/datasets/Dataset_BUSI_with_GT/benign/*'))[4:7]
['/home/lihkir/datasets/Dataset_BUSI_with_GT/benign/benign (100).png',
'/home/lihkir/datasets/Dataset_BUSI_with_GT/benign/benign (100)_mask.png',
'/home/lihkir/datasets/Dataset_BUSI_with_GT/benign/benign (100)_mask_1.png']
Cada caso (ej. benign (100)) puede tener varias máscaras de segmentación (
_mask.png, _mask_1.png, a veces_mask_2.png). Es porque los médicos que lo anotaron identificaron más de una región sospechosa en la misma imagen, o bien diferentes especialistas marcaron áreas distintas.
Cargue de datos
def load_image(path, size):
"""
Carga una imagen desde la ruta especificada, la redimensiona y la convierte a escala de grises.
Parámetros:
path (str): Ruta de la imagen.
size (int): Tamaño deseado para la imagen (size x size).
Retorna:
np.array: Imagen en escala de grises normalizada.
"""
image = cv2.imread(path) # Cargar la imagen
image = cv2.resize(image, (size, size)) # Redimensionar la imagen
image = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY) # Convertir a escala de grises (shape: (size, size, 3) -> (size, size, 1))
image = image / 255. # Normalizar la imagen (valores entre 0 y 1)
return image
def load_data(root_path, size):
"""
Carga imágenes y máscaras desde una carpeta, asegurando que múltiples máscaras para una misma imagen se combinen correctamente.
Parámetros:
root_path (str): Ruta donde se encuentran las imágenes y máscaras.
size (int): Tamaño deseado para las imágenes y máscaras.
Retorna:
tuple: Dos arrays de NumPy, uno con las imágenes y otro con las máscaras.
"""
images = [] # Lista para almacenar las imágenes
masks = [] # Lista para almacenar las máscaras
x = 0 # Variable auxiliar para identificar imágenes con más de una máscara
for path in sorted(glob(root_path)): # Iterar sobre las imágenes y máscaras en la carpeta
img = load_image(path, size) # Cargar la imagen o máscara
if 'mask' in path: # Verificar si el archivo es una máscara
if x: # Si la imagen ya tiene una máscara previa
masks[-1] += img # Sumar la nueva máscara a la última almacenada
# Al sumar dos máscaras, los valores pueden variar entre 0 y 2, por lo que se normaliza nuevamente al rango 0-1.
masks[-1] = np.array(masks[-1] > 0.5, dtype='float64')
else:
masks.append(img) # Agregar la máscara a la lista
x = 1 # Marcar que esta imagen tiene una máscara
else:
images.append(img) # Agregar la imagen a la lista
x = 0 # Reiniciar el indicador para la siguiente imagen
return np.array(images), np.array(masks) # Convertir listas a arrays de NumPy y retornar
La variable
xfunciona como bandera:x = 0→ aún no hay máscara asociada.x = 1→ ya se cargó al menos una máscara para esa imagen.
En datasets médicos como BUSI, las máscaras son binarias:
0→ fondo.1(o255en PNG) → lesión.
Al cargar se normalizan a
[0.0, 1.0]. El problema surge cuando una imagen tiene varias máscaras (_mask.png,_mask_1.png, …): al sumarlas aparecen valores2. Por ejemplo,máscara 1:
[0, 1, 0]máscara 2:
[0, 1, 1]suma:
[0, 2, 1]
Por eso se aplica:
masks[-1] = np.array(masks[-1] > 0.5, dtype="float64")
X, y = load_data(root_path='/home/lihkir/datasets/Dataset_BUSI_with_GT/*/*', size = 128)
Se usa 128×128 por:
Eficiencia: reduce memoria y tiempo de entrenamiento.
Escalabilidad: potencia de 2, compatible con CNNs (128 → 64 → 32…).
Aplicación: suficiente para prototipos en segmentación médica; mayor precisión requiere 256 o 512, pero con más costo computacional.
Exploratory Data Analysis (EDA)
fig, ax = plt.subplots(1, 3, figsize=(10, 5))
# Rango de índices para cada categoría de imágenes en el conjunto de datos:
# X[0:437] - Benigno
# X[437:647] - Maligno
# X[647:780] - Normal
# Selecciona un índice aleatorio dentro del rango de imágenes normales
i = np.random.randint(647, 780)
# Muestra la imagen original en escala de grises
ax[0].imshow(X[i], cmap='gray')
ax[0].set_title('Imagen')
# Muestra la máscara correspondiente
ax[1].imshow(y[i], cmap='gray')
ax[1].set_title('Máscara')
# Superpone la máscara sobre la imagen original con transparencia
ax[2].imshow(X[i], cmap='gray')
ax[2].imshow(tf.squeeze(y[i]), alpha=0.5, cmap='jet')
ax[2].set_title('Superposición')
# Título general de la figura
fig.suptitle('Clase Normal', fontsize=16)
# Muestra la figura con las imágenes
plt.show()
Cuando se cargaron los datos con:
X, y = load_data(root_path='/home/lihkir/datasets/Dataset_BUSI_with_GT/*/*', size=128)
la función
globjunto consorted()organiza las rutas en orden alfabético. Por eso se leen primero las imágenes de la carpetabenign, luegomalignanty finalmentenormal.De este modo, como las imagenes provienen directamente de cómo está organizado el dataset BUSI (Breast Ultrasound Images with Ground Truth): 437 imágenes de tumores benignos; 210 imágenes de tumores malignos; 133 imágenes normales (sin tumor), en los arrays
Xyylas posiciones quedan distribuidas así:X[0:437]→ BenignosX[437:647]→ MalignosX[647:780]→ Normales
fig, ax = plt.subplots(1,3, figsize=(10,5))
i = np.random.randint(437)
ax[0].imshow(X[i], cmap='gray')
ax[0].set_title('Image')
ax[1].imshow(y[i], cmap='gray')
ax[1].set_title('Mask')
ax[2].imshow(X[i], cmap='gray')
ax[2].imshow(tf.squeeze(y[i]), alpha=0.5, cmap='jet')
ax[2].set_title('Union')
fig.suptitle('Benign class', fontsize=16)
plt.show()
fig, ax = plt.subplots(1,3, figsize=(10,5))
i = np.random.randint(437,647)
ax[0].imshow(X[i], cmap='gray')
ax[0].set_title('Image')
ax[1].imshow(y[i], cmap='gray')
ax[1].set_title('Mask')
ax[2].imshow(X[i], cmap='gray')
ax[2].imshow(tf.squeeze(y[i]), alpha=0.5, cmap='jet')
ax[2].set_title('Union')
fig.suptitle('Malignant class', fontsize=16)
plt.show()
Preprocesamiento
# Eliminar la clase "normal" porque no tiene máscara (usar las primera 647)
X = X[:647]
y = y[:647]
print(f"Forma de X: {X.shape} | Forma de y: {y.shape}")
# Preparar los datos para el modelado. Agregar número de canales
X = np.expand_dims(X, -1)
y = np.expand_dims(y, -1)
print(f"\nForma de X: {X.shape} | Forma de y: {y.shape}")
Forma de X: (647, 128, 128) | Forma de y: (647, 128, 128)
Forma de X: (647, 128, 128, 1) | Forma de y: (647, 128, 128, 1)
Eliminación de imágenes (
X = X[:647]). El dataset BUSI tiene 3 clases:Benigno → 437 imágenes
Maligno → 210 imágenes
Normal → 133 imágenes
Las imágenes de la clase Normal no tienen máscara (
y). En segmentación se necesita siempre un par (imagen, máscara). Por eso se conservan solo las 647 imágenes deBenigno + Maligno, que sí tienen máscara. AsíXeyquedan con el mismo número de muestras.Expansión de dimensión (
np.expand_dims(X, -1)). Al cargar imágenes en escala de grises conload_image, cada muestra queda como:(size, size) # ej: (128, 128), pero, las redes neuronales esperan un tensor con canales:(altura, anchura, canales)Color:
(128, 128, 3)Escala de grises:
(128, 128, 1)
Por eso se usa:
X = np.expand_dims(X, -1) y = np.expand_dims(y, -1)
y cada muestra pasa de
(128, 128)a(128, 128, 1).
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1)
print(f'\033[92m')
print('X_train shape:',X_train.shape)
print('y_train shape:',y_train.shape)
print('X_test shape:',X_test.shape)
print('y_test shape:',y_test.shape)
X_train shape: (582, 128, 128, 1)
y_train shape: (582, 128, 128, 1)
X_test shape: (65, 128, 128, 1)
y_test shape: (65, 128, 128, 1)
Construcción de la Arquitectura U-Net
Conv block
El método He Normal (He et al., 2015) es una técnica de inicialización de pesos pensada para redes con activación ReLU. Motivación:
Pesos muy pequeños → gradiente desaparece.
Pesos muy grandes → gradiente explota.
He Normal busca un balance para mantener activaciones y gradientes estables.
Los pesos \(W\) se generan con una distribución normal de media 0 y varianza \(\mathbb{Var}(W) = 2/n_{in}\) donde \(n_{in}\) es el número de entradas de la capa. En Keras:
kernel_initializer='he_normal'
equivale a
\[ W \sim \mathcal{N}(0, \sqrt{2/n_{in}}) \]Ventajas:
Se adapta a ReLU, considerando que descarta la mitad de las neuronas.
Facilita un entrenamiento más rápido y estable en redes profundas.
def conv_block(input, num_filters):
conv = Conv2D(num_filters, (3, 3), activation="relu", padding="same", kernel_initializer='he_normal')(input)
conv = Conv2D(num_filters, (3, 3), activation="relu", padding="same", kernel_initializer='he_normal')(conv)
return conv
Encoder block
def encoder_block(input, num_filters):
conv = conv_block(input, num_filters)
pool = MaxPooling2D((2, 2))(conv)
return conv, pool
Decoder block
def decoder_block(input, skip_features, num_filters):
uconv = Conv2DTranspose(num_filters, (2, 2), strides=2, padding="same")(input)
con = concatenate([uconv, skip_features])
conv = conv_block(con, num_filters)
return conv
Modelo U-Net
def build_model(input_shape):
input_layer = Input(input_shape)
s1, p1 = encoder_block(input_layer, 64)
s2, p2 = encoder_block(p1, 128)
s3, p3 = encoder_block(p2, 256)
s4, p4 = encoder_block(p3, 512)
b1 = conv_block(p4, 1024)
d1 = decoder_block(b1, s4, 512)
d2 = decoder_block(d1, s3, 256)
d3 = decoder_block(d2, s2, 128)
d4 = decoder_block(d3, s1, 64)
output_layer = Conv2D(1, 1, padding="same", activation="sigmoid")(d4)
model = Model(input_layer, output_layer, name="U-Net")
return model
model = build_model(input_shape=(128, 128, 1))
model.compile(
loss="binary_crossentropy",
optimizer=Adam(learning_rate=1e-4),
metrics=["accuracy"]
)
tf.keras.utils.plot_model(model, show_shapes=True)

model.summary()
Model: "U-Net"
┏━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ Connected to ┃ ┡━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━┩ │ input_layer_3 │ (None, 128, 128, │ 0 │ - │ │ (InputLayer) │ 1) │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ conv2d_43 (Conv2D) │ (None, 128, 128, │ 640 │ input_layer_3[0]… │ │ │ 64) │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ conv2d_44 (Conv2D) │ (None, 128, 128, │ 36,928 │ conv2d_43[0][0] │ │ │ 64) │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ max_pooling2d_11 │ (None, 64, 64, │ 0 │ conv2d_44[0][0] │ │ (MaxPooling2D) │ 64) │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ conv2d_45 (Conv2D) │ (None, 64, 64, │ 73,856 │ max_pooling2d_11… │ │ │ 128) │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ conv2d_46 (Conv2D) │ (None, 64, 64, │ 147,584 │ conv2d_45[0][0] │ │ │ 128) │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ max_pooling2d_12 │ (None, 32, 32, │ 0 │ conv2d_46[0][0] │ │ (MaxPooling2D) │ 128) │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ conv2d_47 (Conv2D) │ (None, 32, 32, │ 295,168 │ max_pooling2d_12… │ │ │ 256) │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ conv2d_48 (Conv2D) │ (None, 32, 32, │ 590,080 │ conv2d_47[0][0] │ │ │ 256) │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ max_pooling2d_13 │ (None, 16, 16, │ 0 │ conv2d_48[0][0] │ │ (MaxPooling2D) │ 256) │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ conv2d_49 (Conv2D) │ (None, 16, 16, │ 1,180,160 │ max_pooling2d_13… │ │ │ 512) │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ conv2d_50 (Conv2D) │ (None, 16, 16, │ 2,359,808 │ conv2d_49[0][0] │ │ │ 512) │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ max_pooling2d_14 │ (None, 8, 8, 512) │ 0 │ conv2d_50[0][0] │ │ (MaxPooling2D) │ │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ conv2d_51 (Conv2D) │ (None, 8, 8, │ 4,719,616 │ max_pooling2d_14… │ │ │ 1024) │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ conv2d_52 (Conv2D) │ (None, 8, 8, │ 9,438,208 │ conv2d_51[0][0] │ │ │ 1024) │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ conv2d_transpose_8 │ (None, 16, 16, │ 2,097,664 │ conv2d_52[0][0] │ │ (Conv2DTranspose) │ 512) │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ concatenate_8 │ (None, 16, 16, │ 0 │ conv2d_transpose… │ │ (Concatenate) │ 1024) │ │ conv2d_50[0][0] │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ conv2d_53 (Conv2D) │ (None, 16, 16, │ 4,719,104 │ concatenate_8[0]… │ │ │ 512) │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ conv2d_54 (Conv2D) │ (None, 16, 16, │ 2,359,808 │ conv2d_53[0][0] │ │ │ 512) │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ conv2d_transpose_9 │ (None, 32, 32, │ 524,544 │ conv2d_54[0][0] │ │ (Conv2DTranspose) │ 256) │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ concatenate_9 │ (None, 32, 32, │ 0 │ conv2d_transpose… │ │ (Concatenate) │ 512) │ │ conv2d_48[0][0] │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ conv2d_55 (Conv2D) │ (None, 32, 32, │ 1,179,904 │ concatenate_9[0]… │ │ │ 256) │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ conv2d_56 (Conv2D) │ (None, 32, 32, │ 590,080 │ conv2d_55[0][0] │ │ │ 256) │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ conv2d_transpose_10 │ (None, 64, 64, │ 131,200 │ conv2d_56[0][0] │ │ (Conv2DTranspose) │ 128) │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ concatenate_10 │ (None, 64, 64, │ 0 │ conv2d_transpose… │ │ (Concatenate) │ 256) │ │ conv2d_46[0][0] │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ conv2d_57 (Conv2D) │ (None, 64, 64, │ 295,040 │ concatenate_10[0… │ │ │ 128) │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ conv2d_58 (Conv2D) │ (None, 64, 64, │ 147,584 │ conv2d_57[0][0] │ │ │ 128) │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ conv2d_transpose_11 │ (None, 128, 128, │ 32,832 │ conv2d_58[0][0] │ │ (Conv2DTranspose) │ 64) │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ concatenate_11 │ (None, 128, 128, │ 0 │ conv2d_transpose… │ │ (Concatenate) │ 128) │ │ conv2d_44[0][0] │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ conv2d_59 (Conv2D) │ (None, 128, 128, │ 73,792 │ concatenate_11[0… │ │ │ 64) │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ conv2d_60 (Conv2D) │ (None, 128, 128, │ 36,928 │ conv2d_59[0][0] │ │ │ 64) │ │ │ ├─────────────────────┼───────────────────┼────────────┼───────────────────┤ │ conv2d_61 (Conv2D) │ (None, 128, 128, │ 65 │ conv2d_60[0][0] │ │ │ 1) │ │ │ └─────────────────────┴───────────────────┴────────────┴───────────────────┘
Total params: 31,030,593 (118.37 MB)
Trainable params: 31,030,593 (118.37 MB)
Non-trainable params: 0 (0.00 B)
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
import os
from joblib import dump, load
checkpointer = [
EarlyStopping(monitor='val_accuracy', verbose=1, restore_best_weights=True, mode='max', patience=10),
ModelCheckpoint(
filepath='model.weights.best.keras',
monitor='val_accuracy',
verbose=1,
save_best_only=True,
mode='max'
)
]
history_unet = None
if os.path.exists('history_unet.joblib'):
history_unet = load('history_unet.joblib')
print("El archivo 'history_unet.joblib' ya existe. Se ha cargado el historial del entrenamiento.")
else:
history_unet = model.fit(
X_train, y_train,
epochs=100,
validation_data=(X_test, y_test),
callbacks=checkpointer,
verbose=2
)
dump(history_unet.history, 'history_unet.joblib')
print("El entrenamiento se ha completado y el historial ha sido guardado en 'history_unet.joblib'.")
Epoch 1/100
Epoch 1: val_accuracy improved from -inf to 0.90643, saving model to model.weights.best.keras
19/19 - 11s - 595ms/step - accuracy: 0.8765 - loss: 0.3809 - val_accuracy: 0.9064 - val_loss: 0.3078
Epoch 2/100
Epoch 2: val_accuracy improved from 0.90643 to 0.90831, saving model to model.weights.best.keras
19/19 - 5s - 255ms/step - accuracy: 0.9047 - loss: 0.2593 - val_accuracy: 0.9083 - val_loss: 0.2449
Epoch 3/100
Epoch 3: val_accuracy improved from 0.90831 to 0.91728, saving model to model.weights.best.keras
19/19 - 5s - 269ms/step - accuracy: 0.9114 - loss: 0.2214 - val_accuracy: 0.9173 - val_loss: 0.2097
Epoch 4/100
Epoch 4: val_accuracy improved from 0.91728 to 0.92540, saving model to model.weights.best.keras
19/19 - 5s - 264ms/step - accuracy: 0.9193 - loss: 0.2085 - val_accuracy: 0.9254 - val_loss: 0.1944
Epoch 5/100
Epoch 5: val_accuracy improved from 0.92540 to 0.93137, saving model to model.weights.best.keras
19/19 - 5s - 255ms/step - accuracy: 0.9268 - loss: 0.1888 - val_accuracy: 0.9314 - val_loss: 0.1844
Epoch 6/100
Epoch 6: val_accuracy improved from 0.93137 to 0.93417, saving model to model.weights.best.keras
19/19 - 5s - 263ms/step - accuracy: 0.9325 - loss: 0.1782 - val_accuracy: 0.9342 - val_loss: 0.1738
Epoch 7/100
Epoch 7: val_accuracy did not improve from 0.93417
19/19 - 3s - 142ms/step - accuracy: 0.9351 - loss: 0.1751 - val_accuracy: 0.9066 - val_loss: 0.2137
Epoch 8/100
Epoch 8: val_accuracy improved from 0.93417 to 0.93952, saving model to model.weights.best.keras
19/19 - 5s - 249ms/step - accuracy: 0.9366 - loss: 0.1648 - val_accuracy: 0.9395 - val_loss: 0.1643
Epoch 9/100
Epoch 9: val_accuracy improved from 0.93952 to 0.93953, saving model to model.weights.best.keras
19/19 - 5s - 267ms/step - accuracy: 0.9415 - loss: 0.1542 - val_accuracy: 0.9395 - val_loss: 0.1571
Epoch 10/100
Epoch 10: val_accuracy improved from 0.93953 to 0.93997, saving model to model.weights.best.keras
19/19 - 5s - 269ms/step - accuracy: 0.9440 - loss: 0.1436 - val_accuracy: 0.9400 - val_loss: 0.1513
Epoch 11/100
Epoch 11: val_accuracy improved from 0.93997 to 0.94766, saving model to model.weights.best.keras
19/19 - 5s - 239ms/step - accuracy: 0.9436 - loss: 0.1414 - val_accuracy: 0.9477 - val_loss: 0.1395
Epoch 12/100
Epoch 12: val_accuracy improved from 0.94766 to 0.94831, saving model to model.weights.best.keras
19/19 - 5s - 267ms/step - accuracy: 0.9484 - loss: 0.1309 - val_accuracy: 0.9483 - val_loss: 0.1358
Epoch 13/100
Epoch 13: val_accuracy improved from 0.94831 to 0.95184, saving model to model.weights.best.keras
19/19 - 5s - 270ms/step - accuracy: 0.9505 - loss: 0.1223 - val_accuracy: 0.9518 - val_loss: 0.1314
Epoch 14/100
Epoch 14: val_accuracy improved from 0.95184 to 0.95413, saving model to model.weights.best.keras
19/19 - 5s - 269ms/step - accuracy: 0.9541 - loss: 0.1117 - val_accuracy: 0.9541 - val_loss: 0.1254
Epoch 15/100
Epoch 15: val_accuracy did not improve from 0.95413
19/19 - 3s - 143ms/step - accuracy: 0.9577 - loss: 0.1038 - val_accuracy: 0.9522 - val_loss: 0.1366
Epoch 16/100
Epoch 16: val_accuracy did not improve from 0.95413
19/19 - 3s - 133ms/step - accuracy: 0.9575 - loss: 0.1027 - val_accuracy: 0.9451 - val_loss: 0.1403
Epoch 17/100
Epoch 17: val_accuracy did not improve from 0.95413
19/19 - 3s - 133ms/step - accuracy: 0.9618 - loss: 0.0936 - val_accuracy: 0.9518 - val_loss: 0.1305
Epoch 18/100
Epoch 18: val_accuracy did not improve from 0.95413
19/19 - 3s - 134ms/step - accuracy: 0.9630 - loss: 0.0881 - val_accuracy: 0.9526 - val_loss: 0.1299
Epoch 19/100
Epoch 19: val_accuracy did not improve from 0.95413
19/19 - 3s - 133ms/step - accuracy: 0.9667 - loss: 0.0804 - val_accuracy: 0.9504 - val_loss: 0.1290
Epoch 20/100
Epoch 20: val_accuracy did not improve from 0.95413
19/19 - 3s - 133ms/step - accuracy: 0.9654 - loss: 0.0829 - val_accuracy: 0.9492 - val_loss: 0.1575
Epoch 21/100
Epoch 21: val_accuracy did not improve from 0.95413
19/19 - 2s - 108ms/step - accuracy: 0.9689 - loss: 0.0757 - val_accuracy: 0.9494 - val_loss: 0.1327
Epoch 22/100
Epoch 22: val_accuracy did not improve from 0.95413
19/19 - 3s - 133ms/step - accuracy: 0.9687 - loss: 0.0757 - val_accuracy: 0.9492 - val_loss: 0.1309
Epoch 23/100
Epoch 23: val_accuracy improved from 0.95413 to 0.95520, saving model to model.weights.best.keras
19/19 - 5s - 256ms/step - accuracy: 0.9717 - loss: 0.0680 - val_accuracy: 0.9552 - val_loss: 0.1395
Epoch 24/100
Epoch 24: val_accuracy did not improve from 0.95520
19/19 - 3s - 133ms/step - accuracy: 0.9752 - loss: 0.0572 - val_accuracy: 0.9450 - val_loss: 0.1428
Epoch 25/100
Epoch 25: val_accuracy did not improve from 0.95520
19/19 - 3s - 133ms/step - accuracy: 0.9741 - loss: 0.0607 - val_accuracy: 0.9542 - val_loss: 0.1320
Epoch 26/100
Epoch 26: val_accuracy improved from 0.95520 to 0.95964, saving model to model.weights.best.keras
19/19 - 5s - 251ms/step - accuracy: 0.9754 - loss: 0.0569 - val_accuracy: 0.9596 - val_loss: 0.1254
Epoch 27/100
Epoch 27: val_accuracy did not improve from 0.95964
19/19 - 3s - 141ms/step - accuracy: 0.9788 - loss: 0.0491 - val_accuracy: 0.9586 - val_loss: 0.1334
Epoch 28/100
Epoch 28: val_accuracy did not improve from 0.95964
19/19 - 3s - 133ms/step - accuracy: 0.9793 - loss: 0.0480 - val_accuracy: 0.9574 - val_loss: 0.1361
Epoch 29/100
Epoch 29: val_accuracy did not improve from 0.95964
19/19 - 3s - 133ms/step - accuracy: 0.9808 - loss: 0.0434 - val_accuracy: 0.9519 - val_loss: 0.1316
Epoch 30/100
Epoch 30: val_accuracy did not improve from 0.95964
19/19 - 3s - 133ms/step - accuracy: 0.9784 - loss: 0.0493 - val_accuracy: 0.9576 - val_loss: 0.1698
Epoch 31/100
Epoch 31: val_accuracy improved from 0.95964 to 0.96042, saving model to model.weights.best.keras
19/19 - 4s - 236ms/step - accuracy: 0.9817 - loss: 0.0413 - val_accuracy: 0.9604 - val_loss: 0.1509
Epoch 32/100
Epoch 32: val_accuracy did not improve from 0.96042
19/19 - 3s - 148ms/step - accuracy: 0.9832 - loss: 0.0370 - val_accuracy: 0.9592 - val_loss: 0.1453
Epoch 33/100
Epoch 33: val_accuracy did not improve from 0.96042
19/19 - 3s - 135ms/step - accuracy: 0.9848 - loss: 0.0333 - val_accuracy: 0.9595 - val_loss: 0.1605
Epoch 34/100
Epoch 34: val_accuracy did not improve from 0.96042
19/19 - 3s - 134ms/step - accuracy: 0.9856 - loss: 0.0314 - val_accuracy: 0.9596 - val_loss: 0.1736
Epoch 35/100
Epoch 35: val_accuracy improved from 0.96042 to 0.96092, saving model to model.weights.best.keras
19/19 - 5s - 263ms/step - accuracy: 0.9864 - loss: 0.0296 - val_accuracy: 0.9609 - val_loss: 0.1584
Epoch 36/100
Epoch 36: val_accuracy did not improve from 0.96092
19/19 - 3s - 143ms/step - accuracy: 0.9869 - loss: 0.0288 - val_accuracy: 0.9603 - val_loss: 0.1691
Epoch 37/100
Epoch 37: val_accuracy improved from 0.96092 to 0.96169, saving model to model.weights.best.keras
19/19 - 5s - 259ms/step - accuracy: 0.9869 - loss: 0.0290 - val_accuracy: 0.9617 - val_loss: 0.1617
Epoch 38/100
Epoch 38: val_accuracy did not improve from 0.96169
19/19 - 3s - 145ms/step - accuracy: 0.9873 - loss: 0.0272 - val_accuracy: 0.9567 - val_loss: 0.1794
Epoch 39/100
Epoch 39: val_accuracy did not improve from 0.96169
19/19 - 3s - 132ms/step - accuracy: 0.9856 - loss: 0.0315 - val_accuracy: 0.9592 - val_loss: 0.1717
Epoch 40/100
Epoch 40: val_accuracy did not improve from 0.96169
19/19 - 3s - 132ms/step - accuracy: 0.9852 - loss: 0.0331 - val_accuracy: 0.9503 - val_loss: 0.1762
Epoch 41/100
Epoch 41: val_accuracy did not improve from 0.96169
19/19 - 2s - 106ms/step - accuracy: 0.9857 - loss: 0.0323 - val_accuracy: 0.9606 - val_loss: 0.1561
Epoch 42/100
Epoch 42: val_accuracy did not improve from 0.96169
19/19 - 3s - 132ms/step - accuracy: 0.9877 - loss: 0.0262 - val_accuracy: 0.9600 - val_loss: 0.1854
Epoch 43/100
Epoch 43: val_accuracy did not improve from 0.96169
19/19 - 3s - 132ms/step - accuracy: 0.9891 - loss: 0.0229 - val_accuracy: 0.9597 - val_loss: 0.2136
Epoch 44/100
Epoch 44: val_accuracy did not improve from 0.96169
19/19 - 3s - 132ms/step - accuracy: 0.9891 - loss: 0.0229 - val_accuracy: 0.9600 - val_loss: 0.1987
Epoch 45/100
Epoch 45: val_accuracy did not improve from 0.96169
19/19 - 3s - 134ms/step - accuracy: 0.9896 - loss: 0.0214 - val_accuracy: 0.9607 - val_loss: 0.2108
Epoch 46/100
Epoch 46: val_accuracy did not improve from 0.96169
19/19 - 3s - 135ms/step - accuracy: 0.9899 - loss: 0.0207 - val_accuracy: 0.9609 - val_loss: 0.2245
Epoch 47/100
Epoch 47: val_accuracy did not improve from 0.96169
19/19 - 3s - 134ms/step - accuracy: 0.9904 - loss: 0.0193 - val_accuracy: 0.9606 - val_loss: 0.2436
Epoch 47: early stopping
Restoring model weights from the end of the best epoch: 37.
El entrenamiento se ha completado y el historial ha sido guardado en 'history_unet.joblib'.
if hasattr(history_unet, "history"):
hist = history_unet.history
else:
hist = history_unet # es un dict cargado con joblib
# Graficar
fig, ax = plt.subplots(1, 2, figsize=(10, 3))
ax[0].plot(hist["loss"], label="Train loss")
ax[0].plot(hist["val_loss"], label="Validation loss")
ax[0].legend()
ax[0].set_title("Loss")
ax[1].plot(hist["accuracy"], label="Train accuracy")
ax[1].plot(hist["val_accuracy"], label="Validation accuracy")
ax[1].legend()
ax[1].set_title("Accuracy")
plt.show()
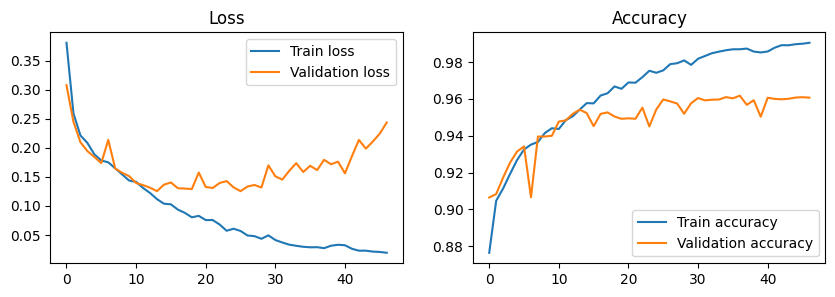
Evaluación
fig, ax = plt.subplots(5,3, figsize=(10,18))
j = np.random.randint(0, X_test.shape[0], 5)
for i in range(5):
ax[i,0].imshow(X_test[j[i]], cmap='gray')
ax[i,0].set_title('Image')
ax[i,1].imshow(y_test[j[i]], cmap='gray')
ax[i,1].set_title('Mask')
ax[i,2].imshow(model.predict(np.expand_dims(X_test[j[i]],0),verbose=0)[0], cmap='gray')
ax[i,2].set_title('Prediction')
fig.suptitle('Results', fontsize=16)
plt.show()
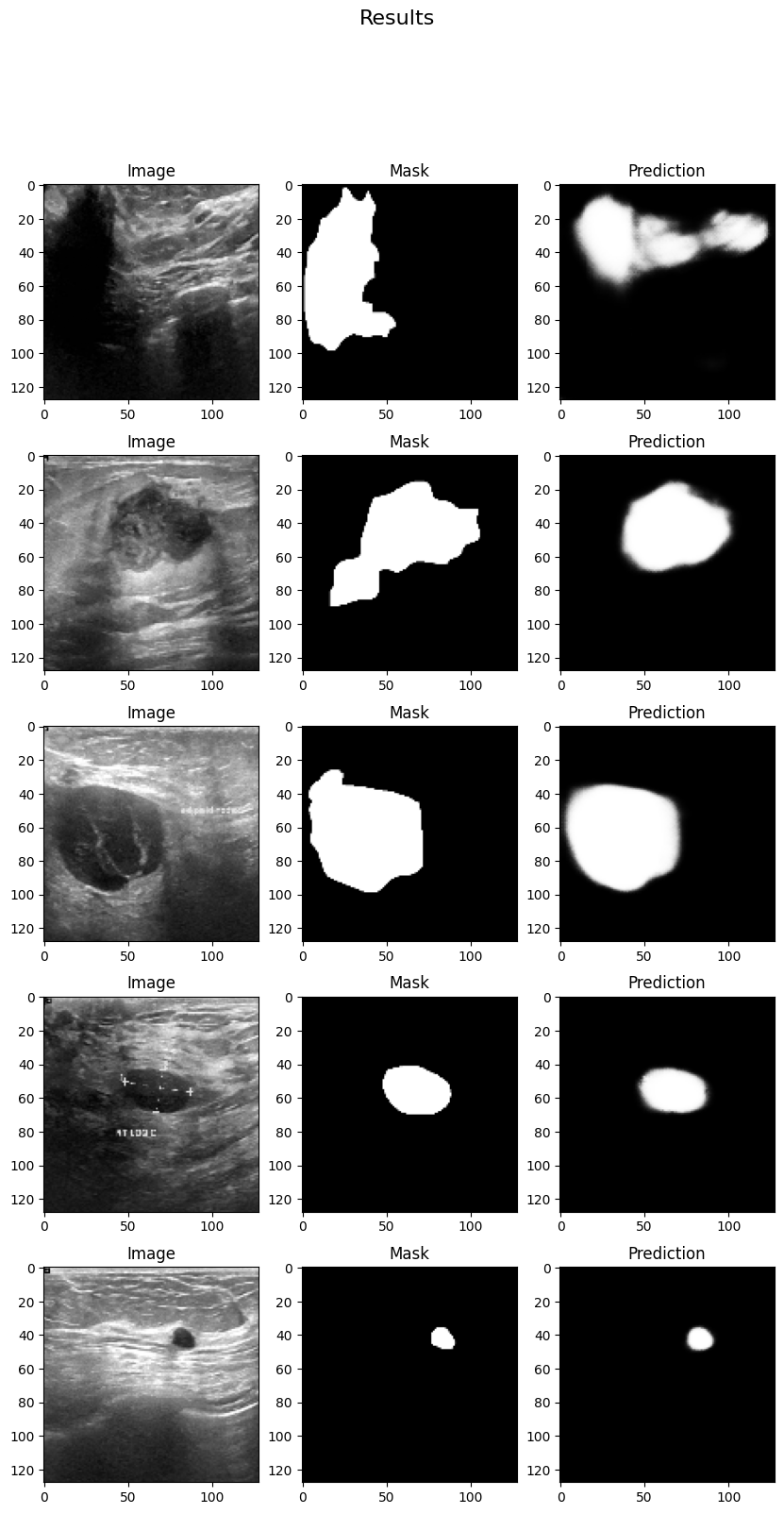
print(f'\033[93m')
y_pred=model.predict(X_test,verbose=0)
y_pred_thresholded = y_pred > 0.5
# mean Intersection-Over-Union metric
IOU_keras = MeanIoU(num_classes=2)
IOU_keras.update_state(y_pred_thresholded, y_test)
print("Mean IoU =", IOU_keras.result().numpy())
prec_score = Precision()
prec_score.update_state(y_pred_thresholded, y_test)
p = prec_score.result().numpy()
print('Precision Score = %.3f' % p)
recall_score = Recall()
recall_score.update_state(y_pred_thresholded, y_test)
r = recall_score.result().numpy()
print('Recall Score = %.3f' % r)
f1_score = 2*(p*r)/(p+r)
print('F1 Score = %.3f' % f1_score)
Mean IoU = 0.8064181
Precision Score = 0.746
Recall Score = 0.835
F1 Score = 0.788
Evaluación del Algoritmo de Segmentación
En un algoritmo de segmentación, estas métricas evalúan la calidad de la segmentación comparando la máscara predicha con la máscara real (ground truth).
1. Mean IoU (Intersection over Union) = 0.7593
Mide la superposición entre la segmentación predicha y la real.
Se calcula como:
Donde:
Área de intersección: Es la cantidad de píxeles correctamente segmentados en la imagen, es decir, los píxeles que coinciden entre la predicción y la verdad (ground truth). Ejemplo: Si la segmentación real marca 40 píxeles como “gato” y la segmentación predicha marca 50 píxeles, pero 30 de ellos coinciden, entonces la intersección es 30 píxeles.
Área de unión: Es la cantidad total de píxeles marcados como objeto en cualquiera de las dos máscaras (predicha o real). Ejemplo: Siguiendo el caso anterior: 40 píxeles están en la máscara real. 50 píxeles están en la máscara predicha. 30 píxeles coinciden (intersección). La unión es: 40 + 50 − 30 = 60 píxeles
Un IoU de 0.7593 indica que, en promedio, el 75.93% del área segmentada coincide con la verdad.
2. Precision Score = 0.695
Evalúa cuántos de los píxeles predichos como positivos realmente lo son.
Se calcula como:
Un valor de 0.695 significa que el 69.5% de las predicciones positivas fueron correctas.
3. Recall Score = 0.786
Mide cuántos de los píxeles verdaderamente positivos fueron detectados.
Se calcula como:
Un recall de 0.786 indica que el 78.6% de los píxeles reales fueron correctamente detectados.
4. F1 Score = 0.738
Es la media armónica entre precisión y recall, equilibrando ambos valores.
Se calcula como:
Un F1 de 0.738 indica un buen equilibrio entre precisión y recall.
Interpretación Global
El modelo segmenta bien las imágenes (IoU alto).
El recall es mayor que la precisión, lo que indica que el modelo detecta la mayoría de los píxeles relevantes, pero a costa de generar algunos falsos positivos.
El F1-score de 0.738 sugiere que el modelo tiene un rendimiento sólido pero puede mejorarse.
11.17. Redes Neuronales Recurrentes#
Introducción
Recordemos de la sección anterior que en el corazón de las redes convolucionales se encuentra el concepto de peso compartido. Es decir, la misma matriz de filtro se desliza sobre una matriz de imágenes en lugar de dedicar un peso específico a cada píxel de la imagen. De este modo, una red neuronal puede escalarse fácilmente a imágenes de diferentes dimensiones.
Nuestro interés en esta sección se centra en el caso de los datos secuenciales. Es decir, los vectores de entrada no son independientes, sino que aparecen en secuencia. Además, el orden específico en que se producen encierra información importante. Por ejemplo, este tipo de secuencias se dan en el reconocimiento del habla y en el procesamiento del lenguaje, como la traducción automática, así como también el pronostico de series de tiempo financieras. Sin duda, la secuencia en la que se producen las palabras es de suma importancia.
El reparto de pesos mediante convoluciones también podría ser y ha sido utilizado para estos casos [Lang et al., 1990]. Tales redes se conocen como redes neuronales de retardo temporal. Sin embargo, deslizar un filtro a través del tiempo para formar convoluciones es una operación de naturaleza local. La salida es una función de las muestras de entrada dentro de una ventana temporal que abarca la longitud de la respuesta al impulso del filtro, que por razones prácticas no puede ser muy larga.
Redes Neuronales Recurrentes
Las variables que intervienen en una RNN son:
Vector de estado en el tiempo \(n\), denotado como \(\boldsymbol{h}_{n}\). El símbolo nos recuerda que \(\boldsymbol{h}\) es un vector de variables ocultas (capa oculta en la jerga de las redes neuronales); el vector de estado constituye la memoria del sistema,
Vector de entrada en el momento \(n\), denominado \(\boldsymbol{x}_{n}\),
Vector de salida en el momento \(n\), \(\hat{\boldsymbol{y}}_{n}\), y el vector de salida objetivo, \(\boldsymbol{y}_{n}\).
El modelo se describe mediante un conjunto de matrices y vectores de parámetros desconocidos, a saber, \(U, W, V , \boldsymbol{b}\) y \(\boldsymbol{c}\), que deben aprenderse durante el entrenamiento.
Las ecuaciones que describen un modelo RNN son
(11.14)#\[\begin{split} \begin{align*} \boldsymbol{h}_{n}&=f(U\boldsymbol{x}_{n}+W\boldsymbol{h}_{n-1}+\boldsymbol{b})\\ \hat{\boldsymbol{y}}_{n}&=g(V\boldsymbol{h}_{n}+\boldsymbol{c}). \end{align*} \end{split}\]donde las funciones no lineales \(f\) y \(g\)*** actúan elemento a elemento (element-wise)*** y se aplican individualmente a cada elemento de sus argumentos vectoriales.
En otras palabras, una vez que se ha observado un nuevo vector de entrada, se actualiza el vector de estado. Su nuevo valor depende de la información más reciente, transmitida por la entrada \(\boldsymbol{x}_{n}\) así como de la historia pasada, ya que ésta se ha acumulado en \(\boldsymbol{h}_{n-1}\). La salida depende del vector de estado actualizado, \(\boldsymbol{h}_{n}\). Es decir, depende de la “historia” hasta el instante actual \(n\), tal y como se expresa en \(\boldsymbol{h}_{n}\).
Las opciones típicas para \(f\) son la tangente hiperbólica, tanh, o las no linealidades ReLU. El valor inicial \(\boldsymbol{h}_{0}\) suele ser igual al vector cero. La no linealidad de salida, \(g\), se elige a menudo para ser la función softmax.
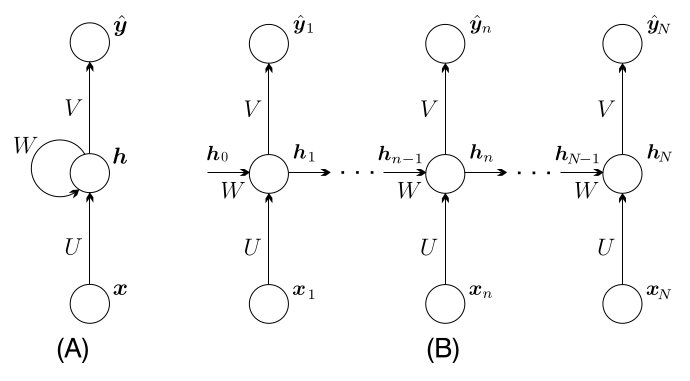
Fig. 11.44 Arquitectura de una Red Neuronal Recurrente. Fuente [Theodoridis, 2020].#
De las ecuaciones anteriores se deduce que las matrices y vectores de parámetros se comparten en todos los instantes temporales. Durante el entrenamiento, se inicializan mediante números aleatorios. El modelo gráfico asociado con Eq. (11.14) se muestra en la Fig. 11.44A. En la Fig. 11.44B, el gráfico se despliega sobre los distintos instantes de tiempo para los que se dispone de observaciones. Por ejemplo, si la secuencia de interés es una frase de 10 palabras, entonces \(N\) se establece igual a 10, mientras que \(\boldsymbol{x}_{n}\) es el vector que codifica las respectivas palabras de entrada.
11.17.1. Backpropagation en tiempo#
El entrenamiento de las RNN sigue una lógica similar a la del algoritmo backpropagation para el entrenamiento de redes neuronales de avance. Después de todo, una RNN puede verse como una red feed-forward con \(N\) capas. La capa superior es la del instante de tiempo \(N\) y la primera capa corresponde al instante de tiempo \(n = 1\). Una diferencia radica en que las capas ocultas en una RNN también producen salidas, es decir, \(\hat{\boldsymbol{y}}_{n}\), y se alimentan directamente con entradas. Sin embargo, en lo que respecta al entrenamiento, estas diferencias no afectan al razonamiento principal.
El aprendizaje de las matrices y vectores de parámetros desconocidos se consigue mediante un esquema de gradiente descendente, de acuerdo con Eq. (11.3). Resulta que los gradientes requeridos de la función de coste, con respecto a los parámetros desconocidos, tienen lugar recursivamente, comenzando en el último instante de tiempo, \(N\) , y retrocediendo en el tiempo, \(n = N-1, N-2,\dots,1\). Esta es la razón por la que el algoritmo se conoce como bakpropagation a traves del tiempo (BPTT).
La función de coste es la suma a lo largo del tiempo, \(n\), de las correspondientes contribuciones a la función de pérdida, que dependen de los valores respectivos de \(\boldsymbol{h}_{n}, \boldsymbol{x}_{n}\), es decir,
Por ejemplo, para el caso de la función de pérdida de entropía cruzada,
\[ J_{n}(U, W, V, \boldsymbol{b}, \boldsymbol{c}):=-\sum_{k}y_{nk}\ln\hat{y}_{nk}, \]donde la suma es sobre la dimensionalidad de \(\boldsymbol{y}\), y
\[ \hat{\boldsymbol{y}}_{n}=g(\boldsymbol{h}_{n}, V, \boldsymbol{c})~\text{y}~\boldsymbol{h}_{n}=f(\boldsymbol{x}_{n}, \boldsymbol{h}_{n-1}, U, W, \boldsymbol{b}). \]
En el corazón del cálculo de los gradientes de la función de coste con respecto a las diversas matrices y vectores de parámetros se encuentra el cálculo de los gradientes de \(J\) con respecto a los vectores de estado, \(\boldsymbol{h}_{n}\). Una vez calculados estos últimos, el resto de los gradientes, con respecto a las matrices y vectores de parámetros desconocidos, es una tarea sencilla. Para ello, nótese que cada \(h_{n},~n=1, 2,\dots,N-1\), afecta a \(J\) de dos maneras:
Directamente, a traves de \(J_{n}\)
Indirectamente, a través de la cadena que impone la estructura RNN, es decir,
\[ \boldsymbol{h}_{n}\rightarrow\boldsymbol{h}_{n+1}\rightarrow\cdots\rightarrow\boldsymbol{h}_{N}. \]Es decir, \(\boldsymbol{h}_{n}\), además de \(J_{n}\), también afecta a todos los valores de coste posteriores, \(J_{n+1},\dots, J_{N}\). Nótese que, a traves de la cadena \(\boldsymbol{h}_{n+1}=f(\boldsymbol{x}_{n+1}, \boldsymbol{h}_{n}, U, W, \boldsymbol{b}).\)
Empleando la regla de la cadena para las derivadas, las dependencias anteriores conducen al siguiente cálculo recursivo:
(11.15)#\[ \frac{\partial J}{\partial\boldsymbol{h}_{n}}=\underbrace{{\left(\frac{\partial\boldsymbol{h}_{n+1}}{\partial\boldsymbol{h}_{n}}\right)^{T}}\frac{\partial J}{\partial\boldsymbol{h}_{n+1}}}_{\text{parte recursiva indirecta}}+\underbrace{\left(\frac{\partial\hat{\boldsymbol{y}}_{n}}{\partial\boldsymbol{h}_{n}}\right)^{T}\frac{\partial J}{\partial\hat{\boldsymbol{y}}_{n}}}_{\text{parte directa}}, \]donde, por definición, la derivada de un vector, digamos, \(\boldsymbol{y}\), con respecto a otro vector, digamos, \(\boldsymbol{x}\), se define como la matriz
\[ \left[\frac{\partial\boldsymbol{y}}{\partial\boldsymbol{x}}\right]_{ij}:=\frac{\partial y_{i}}{\partial x_{j}}. \]
Nótese que el gradiente de la función de coste, con respecto a los parámetros ocultos (vector de estado) en la capa “\(n\)”, se da como una función del gradiente respectivo en la capa anterior, es decir, con respecto al vector de estado en el tiempo \(n + 1\). Las dos pasadas requeridas por backpropagation en el tiempo se resumen a continuación.
Pasadas de Backpropagation en Tiempo
Paso hacia adelante:
Iniciando en \(n=1\) y utilizando las estimaciones actuales de las matrices y vectores de parámetros implicados, calcular en secuencia,
\[ (\boldsymbol{h}_{1}, \hat{\boldsymbol{y}}_{1})\rightarrow(\boldsymbol{h}_{2}, \hat{\boldsymbol{y}}_{2})\rightarrow\cdots\rightarrow(\boldsymbol{h}_{N}, \hat{\boldsymbol{y}}_{N}). \]Paso hacia atrás:
Empezando en \(n = N\), calcular en secuencia,
\[ \frac{\partial J}{\partial\boldsymbol{h}_{N}}\rightarrow\frac{\partial J}{\partial\boldsymbol{h}_{N-1}}\rightarrow\cdots\rightarrow\frac{\partial J}{\partial\boldsymbol{h}_{1}}. \]
Nótese que el cálculo del gradiente \(\partial J/\partial\boldsymbol{h}_{N}\) es sencillo, y solo involucra la parte directa en Eq. (11.15).
Para la implementación de la BPTT, se procede a
inicializar aleatoriamente las matrices y vectores desconocidos implicados,
calcular todos los gradientes requeridos, siguiendo los pasos indicados anteriormente, y
realizar las actualizaciones según el esquema de gradiente descendente.
Los pasos (2) y (3) se realizan de forma iterativa hasta que se cumple un criterio de convergencia, de forma análoga al algoritmo estándar de backpropagation.
11.17.2. Desvanecimiento y explosión de gradientes#
La tarea de desvanecimiento y explosión de gradientes se ha introducido y discutido en secciones anteriores, en el contexto del algoritmo de backpropagation. Los mismos problemas se presentan en el algoritmo BPTT, dado que, este último es una forma específica del concepto de backpropagation y, como se ha dicho, una RNN puede considerarse como una red multicapa, donde cada instante de tiempo corresponde a una capa diferente. De hecho en las RNN, el fenómeno de desvanecimiento/explosión de gradiente aparece de una forma bastante “agresiva”, teniendo en cuenta que \(N\) puede alcanzar valores grandes.
La naturaleza multiplicativa de la propagación de gradientes puede verse fácilmente en la Eq. (11.15). Para ayudar a comprender el concepto principal, simplifiquemos el escenario y supongamos que sólo interviene una variante de estado. Entonces los vectores de estado se convierten en escalares, \(h_{n}\) , y la matriz \(W\) en un escalar \(w\). Además, supongamos que las salidas también son escalares. Entonces la recursión en la Eq. (11.15) se simplifica como:
Suponiendo en la Eq. (11.14) que \(f\) es la función \(\tanh(\cdot)\) estándar, teniendo en cuenta que, \(\text{sech}^2(\cdot)=1-\tanh^2(\cdot)\) y \(|\tanh(\cdot)|<1\), sobre su dominio, se ve fácilmente que
Escribiendo la recursión para dos pasos sucesivos, repitiendo el proceso en Eq. (11.16), por ejemplo, para \(\partial h_{n+2}/\partial h_{n+1}\) obtenemos que,
No es difícil ver que la multiplicación de los términos menores que uno puede llevar a valores de desvanecimiento, sobre todo si tenemos en cuenta que, en la práctica, las secuencias pueden ser bastante grandes, por ejemplo, \(N = 100\). Por lo tanto para instantes de tiempo cercanos a \(n = 1\), la contribución al gradiente del primer término del lado derecho en la Eq. (11.17) implicará un gran número de productos de números menores que uno en magnitud. Por otra parte, el valor de \(w\) estará contribuyendo en \(w^{n}\) potencia. Por lo tanto, si su valor es mayor que uno, puede conducir a valores explosivos de los gradientes respectivos.
En varios casos, se puede truncar el algoritmo de backpropagation a unos pocos pasos de tiempo. Otra forma, es sustituir la no linealidad tanh por la ReLU. Para el caso del valor explosivo, se puede introducir una técnica que recorte los valores a un umbral predeterminado, una vez que los valores superen ese umbral. Sin embargo, otra técnica que suele emplearse en la práctica es sustituir la formulación RNN estándar descrita anteriormente por una estructura alternativa, que puede hacer mejor frente a estos fenómenos causados por la dependencia a largo plazo de la RNN.
Observation 11.3
RNN profundas: Además de la red RNN básica que comprende una sola capa de estados, se han propuesto extensiones que implican múltiples capas de estados, una encima de otra (ver [Pascanu et al., 2013]).RNN bidireccionales: Como su nombre indica, en las RNN bidireccionales hay dos variables de estado, es decir, una denotada como \(\overset{\rightarrow}{\boldsymbol{h}}\), que se propaga hacia adelante, y otra, \(\overset{\leftarrow}{\boldsymbol{h}}\), que se propaga hacia atrás. De este modo, las salidas dependen tanto del pasado como del futuro (ver [Graves et al., 2013]).
Ejemplo
Ejemplo de BPTT con dos secuencias de texto. Este ejemplo utiliza dos secuencias de texto (una positiva y una negativa) para demostrar cómo funciona el proceso de Backpropagation Through Time (BPTT) en una red recurrente. Además, mostramos la actualización de los pesos mediante gradiente descendente.
Paso 1: Definición de los datos y parámetros
Secuencias de Texto
Secuencia 1 (Positiva):
"I love this movie"Secuencia 2 (Negativa):
"This movie is terrible"
Embeddings de las Palabras
Cada palabra se representa por un vector embedding (
Word2Vec) de 3 dimensiones:"I"= \([0.1, 0.2, 0.1]\)"love"= \([0.4, 0.5, 0.6]\)"this"= \([0.3, 0.1, 0.3]\)"movie"= \([0.5, 0.1, -0.3]\)"is"= \([0.2, 0.3, 0.2]\)"terrible"= \([-0.5, -0.6, -0.7]\)
Etiquetas de Salida (Clases)
Secuencia 1: clase 1 (positiva)
Secuencia 2: clase 0 (negativa)
Definir los Datos y Parámetros Iniciales (tres filas en las matrices significa que hay tres unidades en la capa oculta)
Sesgos
Paso 2: Propagación hacia Adelante
Vamos a recalcular las salidas de los estados ocultos \(h_n\) y la salida final \(y_n\), incluyendo la función de activación en la salida (
softmax).Tiempo \(n = 1\) (
"I")Para la palabra
"I", \(x_1 = [0.1, 0.2, 0.1]\):
Calcular la propagación hacia adelante del estado oculto \(h_1\):
\[\begin{split} U \cdot x_1 = U \cdot [0.1, 0.2, 0.1]^\top = \begin{bmatrix} (0.1 \times 0.1) + (-0.2 \times 0.2) + (0.3 \times 0.1) \\ (0.4 \times 0.1) + (0.1 \times 0.2) + (-0.3 \times 0.1) \\ (0.3 \times 0.1) + (0.2 \times 0.2) + (-0.1 \times 0.1) \end{bmatrix} = \begin{bmatrix} 0.01 + (-0.04) + 0.03 \\ 0.04 + 0.02 + (-0.03) \\ 0.03 + 0.04 + (-0.01) \end{bmatrix} = \begin{bmatrix} 0.02 \\ 0.05 \\ 0.07 \end{bmatrix} \end{split}\]Como \(h_0 = [0, 0, 0]\):
\[ h_1 = \tanh([0.02, 0.05, 0.07] + b) = \tanh([0.12, 0.15, 0.17]) \approx [0.119, 0.149, 0.168] \]Tiempo \(n = 2\) (
"love")Para la palabra
"love", \(x_2 = [0.4, 0.5, 0.6]\):
Calcular la propagación hacia adelante del estado oculto \(h_2\):
\[\begin{split} U \cdot x_2 = \begin{bmatrix} 0.22 \\ 0.13 \\ 0.15 \end{bmatrix} \end{split}\]Calcular el estado recurrente con \(W \cdot h_1\):
\[\begin{split} W \cdot h_1 = \begin{bmatrix} 0.065 \\ 0.096 \\ 0.074 \end{bmatrix} \end{split}\]Propagación total del estado oculto \(h_2\):
\[\begin{split} \begin{align*} h_2 &= \tanh([0.22, 0.13, 0.15] + [0.065, 0.096, 0.074] + b)\\ &= \tanh([0.385, 0.376, 0.394])\\ &\approx [0.367, 0.359, 0.374] \end{align*} \end{split}\]
Paso 3: Cálculo de la Salida con Activación Softmax
La salida se calcula utilizando la matriz \(V\), aplicando después la función de activación
softmaxpara obtener las probabilidades de las dos clases.
Calculamos la salida \(\hat{y}_{2}\) antes de la activación:
\[\begin{split} \hat{y}_{2} = V \cdot h_2 = \begin{bmatrix} 0.2 & -0.3 \\ 0.4 & 0.1 \\ -0.2 & 0.3 \end{bmatrix} \cdot [0.367, 0.359, 0.374]^\top = \begin{bmatrix} 0.0516 \\ 0.1108 \end{bmatrix} \end{split}\]Aplicamos la función de activación
softmaxpara convertir la salida en probabilidades:\[\begin{split} \text{softmax}(\hat{y}_{2}) = \frac{e^{\hat{y}_{2}}}{\sum e^{\hat{y}_{2}}} = \frac{\begin{bmatrix} e^{0.0516} \\ e^{0.1108} \end{bmatrix}}{e^{0.0516} + e^{0.1108}} = \begin{bmatrix} 0.4852 \\ 0.5148 \end{bmatrix} \end{split}\]
Paso 4: Retropropagación del Error
Ahora calculamos el error y el gradiente con respecto a los pesos \(V\), \(W\), \(U\), y los sesgos, usando el método de cross-entropy y BPTT
Cálculo del Error
La pérdida es:
\[ \text{Loss} = - \left[ y_{\text{real}} \cdot \log(\hat{y}) + (1 - y_{\text{real}}) \cdot \log(1 - \hat{y}) \right] \]“Nota: aquí, 0.5148 es la probabilidad asignada a la clase considerada correcta (la etiqueta real), y 0.4852 es la probabilidad para la clase incorrecta”. Si la clase verdadera es 1 (positiva) el error es:
\[ \text{Loss} = - \log(0.5148) \approx 0.663 \]
Gradientes
La siguiente es la derivada de la entropía cruzada con softmax
\[ \frac{\partial L}{\partial \tilde{y}_k} = \hat{y}_k - y_k \]es válido incluso si \(y\) es una distribución (ej. label smoothing).
Dado que,
Logits: \(\tilde{y}_k\), salidas crudas (no normalizadas) de la última capa lineal antes de aplicar la función softmax
Softmax:
\[ \hat{y}_k = \frac{e^{\tilde{y}_k}}{\sum_j e^{\tilde{y}_j}} \]Entropía cruzada:
\[ L = -\sum_i y_i \log(\hat{y}_i) \]Gradiente paso a paso
Separando casos
Sumando todo
\[ \frac{\partial L}{\partial \tilde{y}_k} = -y_k + y_k \hat{y}_k + \hat{y}_k \sum_{i \neq k} y_i \]y usando que:
\[ \sum_{i \neq k} y_i = \Big(\sum_i y_i \Big) - y_k \]Si \(y\) es un vector one-hot:
\[ \sum_i y_i = 1, \]entonces:
\[\begin{split} \begin{align} \frac{\partial L}{\partial \tilde{y}_k} &= -y_k + y_k \hat{y}_k + \hat{y}_k (1 - y_k) \\[6pt] &= \hat{y}_k - y_k \end{align} \end{split}\]
Gradiente para \(V\):
\[ \frac{\partial L}{\partial V} = (y_{\text{pred}} - y_{\text{real}}) \cdot h_2 \]\[\begin{split} \frac{\partial L}{\partial V} = \left( \begin{bmatrix} 0.4852 \\ 0.5148 \end{bmatrix} - \begin{bmatrix} 0 \\ 1 \end{bmatrix} \right) \cdot \begin{bmatrix} 0.367 \\ 0.359 \\ 0.374 \end{bmatrix}^\top \end{split}\]\[\begin{split} \frac{\partial L}{\partial V} = \begin{bmatrix} 0.4852 & 0.4852 \\ -0.4852 & -0.4852 \\ 0.5148 & -0.5148 \end{bmatrix} \end{split}\]Gradiente para \(W\) y \(U\): Usamos la retropropagación a través del tiempo (BPTT). Los gradientes para \(W\) y \(U\) se calculan usando la regla de la cadena considerando las derivadas del estado oculto.
Paso 5: Actualización de Pesos
Usamos gradiente descendente para actualizar los pesos. Dado un valor de \(\eta = 0.01\):
\[ V \leftarrow V - \eta \frac{\partial L}{\partial V} \]\[ W \leftarrow W - \eta \frac{\partial L}{\partial W}, \quad U \leftarrow U - \eta \frac{\partial L}{\partial U} \]Actualización de los pesos para \(V\):
\[\begin{split} V_{\text{nuevo}} = V - 0.01 \times \begin{bmatrix} 0.4852 & 0.4852 \\ -0.4852 & -0.4852 \\ 0.5148 & -0.5148 \end{bmatrix}=\begin{bmatrix} 0.495148 & 0.595148 \\ 0.404852 & 0.304852 \\ -0.005148 & 0.005148 \end{bmatrix} \end{split}\]Realiza las actualizaciones análogas para \(W\) y \(U\).
11.18. Red de memoria a largo plazo (LSTM)#
Observation 11.4
La idea clave de la red LSTM, propuesta en el artículo seminal [Hochreiter and Schmidhuber, 1997], es el llamado celda de estado (cell state), que ayuda a superar los problemas asociados con los fenómenos de desvanecimiento/explosión que son causados por las dependencias largo plazo dentro de la red.
Las redes LSTM tienen la capacidad incorporada de controlar el flujo de información que entra y sale de la memoria del sistema mediante algoritmos no lineales. Estas puertas se implementan mediante la no linealidad sigmoidea y un multiplicador.
Desde un punto de vista algorítmico, las puertas equivalen a aplicar una ponderación al flujo de información correspondiente. Los pesos se sitúan en el intervalo \([0,1]\) y dependen de los valores de las variables implicadas que activan la no linealidad sigmoidea.
En otras palabras, la ponderación (control) de la información tiene lugar en el contexto. Según este razonamiento, la red tiene la agilidad de olvidar la información que ya ha sido utilizada y ya no es necesaria. La célula/unidad LSTM básica se se muestra en la Fig. 11.45.
Se construye en torno a dos conjuntos de variables, apiladas en el vector \(\boldsymbol{s}\), que se conoce como el celda de estado, y el vector \(\boldsymbol{h}\), que se conoce como el vector de variables ocultas. Una red LSTM se construye a partir de la concatenación sucesiva de esta unidad básica. La unidad correspondiente al tiempo \(n\), además del vector de entrada, \(\boldsymbol{x}_{n}\), recibe \(\boldsymbol{s}_{n-1}\) y \(\boldsymbol{h}_{n-1}\) de la etapa anterior y pasa \(\boldsymbol{s}_{n}\) y \(\boldsymbol{h}_{n}\) a la siguiente. A continuación se resumen las ecuaciones de actualización asociadas
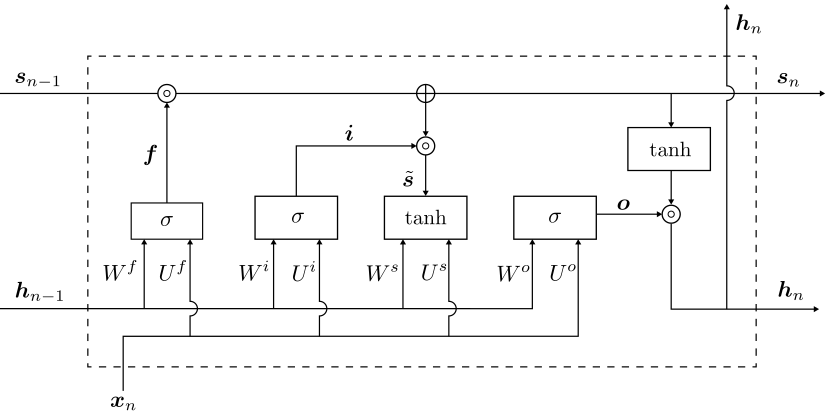
Fig. 11.45 Arquitectura de unidad LSTM. Fuente [Theodoridis, 2020].#
donde \(\circ\) denota el producto elemento a elemento entre vectores o matrices (producto de Hadamard), es decir, \((s\circ f)_{i} = s_{i}f_{i}\), y \(\sigma\) denota la función sigmoidea logística.
Observation 11.5
Nótese que el celda de estado, \(\boldsymbol{s}\), pasa información directa del instante anterior al siguiente. Esta información es controlada primero por la primera puerta, según los elementos en \(f\), que toman valores en el rango \([0, 1]\), dependiendo de la entrada actual y de las variables ocultas que se reciben de la etapa anterior. Esto es lo que decíamos antes, es decir, que la ponderación se ajusta en “contexto”. A continuación, se añade nueva información, es decir, \(\tilde{\boldsymbol{s}}\), a \(\boldsymbol{s}_{n-1}\), que también está controlada por la segunda red de puertas sigmoidales (es decir, \(\boldsymbol{i}\)). Así se garantiza que la información del pasado se transmita al futuro de forma directa, lo cual, ayuda a la red a memorizar información..
Resulta que este tipo de memoria explota mejor las dependencias de largo alcance en los datos, en comparación con la estructura RNN básica. El vector de variables ocultas \(\boldsymbol{h}\) está controlado tanto por el celda de estado como por los valores actuales de las variables de entrada y de estados anteriores. Todas las matrices y vectores implicados se aprenden en la fase de entrenamiento. Nótese que hay dos líneas asociadas a \(\boldsymbol{h}_{n}\). La de la derecha conduce a la siguiente etapa y la de la parte superior se utiliza para proporcionar la salida, \(\hat{\boldsymbol{y}}_{n}\), en el tiempo \(n\), a través de, digamos, la no linealidad softmax, como en las RNN estándar en Eq. (11.14).
Variantes y Aplicaciones
Además de la estructura LSTM ya comentada, se han propuesto diversas variantes. Un extenso estudio comparativo entre diferentes arquitecturas LSTM y RNN se puede encontrar en [Greff et al., 2016, Jozefowicz et al., 2015]. Las RNNs y las LSTMs se han utilizado con éxito en una amplia gama de aplicaciones, tales como:
el modelado del lenguaje [Sutskever et al., 2011],
traducción de máquinas [Liu et al., 2014],
reconocimiento del habla [Graves and Jaitly, 2014],
visión artificial para la generación de descriptores de imágenes [Karpathy and Fei-Fei, 2015],
análisis de datos de fMRI para comprender la dinámica temporal de las redes cerebrales asociadas [Seo et al., 2019].
pronostico de volatilidad de Bitcoin [Pratas et al., 2023]
Por ejemplo, en el procesamiento del lenguaje la entrada suele ser una secuencia de palabras, que se codifican como números (son punteros al diccionario disponible). La salida es la secuencia de palabras que hay que predecir. Durante el entrenamiento, se establece \(\boldsymbol{y}_{n} = \boldsymbol{x}_{n+1}\). Es decir, la red se entrena como un predictor no lineal.
11.19. Aplicación: Procesamiento del Lenguaje Natural#
import warnings
warnings.filterwarnings('ignore')
import sys
import tensorflow.keras
import pandas as pd
import sklearn as sk
import tensorflow as tf
2025-11-04 08:13:27.626863: I tensorflow/core/util/port.cc:153] oneDNN custom operations are on. You may see slightly different numerical results due to floating-point round-off errors from different computation orders. To turn them off, set the environment variable `TF_ENABLE_ONEDNN_OPTS=0`.
2025-11-04 08:13:27.938840: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:485] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
2025-11-04 08:13:28.031574: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:8454] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
2025-11-04 08:13:28.056231: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1452] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
2025-11-04 08:13:28.227779: I tensorflow/core/platform/cpu_feature_guard.cc:210] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 AVX512F AVX512_VNNI AVX512_BF16 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2025-11-04 08:13:29.727648: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
Iniciamos verificando que
Tensorflowestá correctamente instalado, y que, además, puede utilizar la GPU disponible en su computadora. En este caso corresponde a una tarjeta de video dedicadaGTX 4070 Maxq 12G
print(f"Tensor Flow Version: {tf.__version__}");
print();
print(f"Python {sys.version}");
print(f"Pandas {pd.__version__}");
print(f"Scikit-Learn {sk.__version__}");
gpu = len(tf.config.list_physical_devices('GPU'))>0
print("GPU is", "available" if gpu else "NOT AVAILABLE");
Tensor Flow Version: 2.17.0
Python 3.10.12 (main, Aug 15 2025, 14:32:43) [GCC 11.4.0]
Pandas 2.3.0
Scikit-Learn 1.3.0
GPU is available
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1762262012.973203 2450 cuda_executor.cc:1001] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node
Your kernel may have been built without NUMA support.
I0000 00:00:1762262013.484694 2450 cuda_executor.cc:1001] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node
Your kernel may have been built without NUMA support.
I0000 00:00:1762262013.484749 2450 cuda_executor.cc:1001] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node
Your kernel may have been built without NUMA support.
La librería
gensimutilizada en la presente implementación, debe ser instalada en suversión 3.8.3usando la orden. Además, debe instalargraphvizdel siguiente sitio web (ver GraphViz)
pip install gensim==3.8.3
import pandas as pd
import numpy as np
from tqdm import tqdm
from tensorflow.keras.preprocessing.text import Tokenizer
tqdm.pandas(desc="progress-bar")
from gensim.models import Doc2Vec
from sklearn import utils
from sklearn.model_selection import train_test_split
from keras_preprocessing.sequence import pad_sequences
import gensim
from sklearn.linear_model import LogisticRegression
from gensim.models.doc2vec import TaggedDocument
import re
import seaborn as sns
import matplotlib.pyplot as plt
df = pd.read_csv('https://raw.githubusercontent.com/lihkir/Data/main/spam_text_class.csv',delimiter=',',encoding='latin-1')
df = df[['Category','Message']]
df = df[pd.notnull(df['Message'])]
df.rename(columns = {'Message':'Message'}, inplace = True)
df.head()
| Category | Message | |
|---|---|---|
| 0 | ham | Go until jurong point, crazy.. Available only ... |
| 1 | ham | Ok lar... Joking wif u oni... |
| 2 | spam | Free entry in 2 a wkly comp to win FA Cup fina... |
| 3 | ham | U dun say so early hor... U c already then say... |
| 4 | ham | Nah I don't think he goes to usf, he lives aro... |
df.shape
(5572, 2)
df.index = range(5572)
df['Message'].apply(lambda x: len(x.split(' '))).sum()
87265
import matplotlib
matplotlib.rc_file_defaults()
cnt_pro = df['Category'].value_counts()
sns.barplot(x=cnt_pro.index, y=cnt_pro.values)
plt.ylabel('Number of Occurrences', fontsize=12)
plt.xlabel('Category', fontsize=12)
plt.xticks(rotation=90)
plt.show();
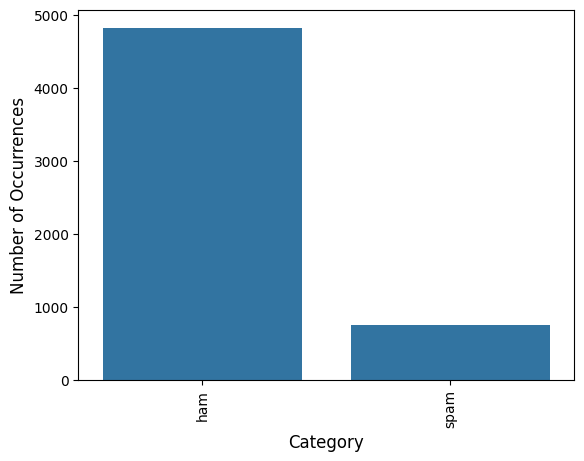
def print_message(index):
example = df[df.index == index][['Message', 'Category']].values[0]
if len(example) > 0:
print(example[0])
print('Message:', example[1])
print_message(12)
URGENT! You have won a 1 week FREE membership in our £100,000 Prize Jackpot! Txt the word: CLAIM to No: 81010 T&C www.dbuk.net LCCLTD POBOX 4403LDNW1A7RW18
Message: spam
print_message(0)
Go until jurong point, crazy.. Available only in bugis n great world la e buffet... Cine there got amore wat...
Message: ham
Preprocesamiento de Texto: A continuación, establecemos una función para transformar el texto a minúsculas y eliminar signos de puntuación/símbolos de las palabras.
import lxml
from bs4 import BeautifulSoup
import re
BeautifulSoup: Se usa para navegar y manipular la estructura de documentos HTML o XML.re: Permite buscar y manipular texto dentro de esos documentos o cualquier otro texto, usando patrones específicos de expresiones regulares.
def cleanText(text):
text = BeautifulSoup(text, "html.parser").text
text = re.sub(r'\|\|\|', r' ', text)
text = re.sub(r'http\S+', r'<URL>', text)
text = text.lower()
text = text.replace('x', '')
return text
BeautifulSoup(text, "html.parser").text:BeautifulSoupen este caso elimina etiquetas HTML del texto. Conviertetexten un objetoBeautifulSoup, y luego el método.textextrae solo el texto visible, eliminando cualquier HTML o XML.text = re.sub(r'\|\|\|', r' ', text): Aquíre.subreemplaza cualquier secuencia de caracteres"|||"por un espacio" ". Esto es útil para limpiar delimitadores o caracteres específicos del texto.text = re.sub(r'http\S+', r'<URL>', text): Reemplaza cualquier URL (que comience con “http” y continúe sin espacios) con el marcador de posición “” . Esto ayuda a evitar que URLs específicas queden en el texto sin ser normalizadas.text = text.replace('x', ''): En tareas de clasificación de texto o en análisis de sentimientos, algunos caracteres pueden no ser útiles para el modelo. Por ejemplo, si “x” se usa como símbolo decorativo o separador, eliminarlo mejora la calidad de las representaciones de texto sin afectar el contenido.
df['Message'] = df['Message'].apply(cleanText)
df['Message'] = df['Message'].apply(cleanText)
train, test = train_test_split(df, test_size=0.20, random_state=42)
import nltk
from nltk.corpus import stopwords
nltk.data.path.append('/home/lihkir/nltk_data')
nltk.download('punkt_tab')
[nltk_data] Downloading package punkt_tab to /home/lihkir/nltk_data...
[nltk_data] Package punkt_tab is already up-to-date!
True
El módulo
nltky, en particular,nltk.corpus.stopwordsse usan en Procesamiento de Lenguaje Natural (NLP) para trabajar con “stopwords”, es decir, palabras de relleno o comunes en un idioma que suelen eliminarse en el análisis de texto porque no aportan significado específico. Estas palabras pueden ser artículos, preposiciones, pronombres y otros términos que no añaden valor semántico relevante (por ejemplo, “el”, “la”, “un”, “de”, “y” en español; o “the”, “is”, “in”, “and” en inglés).
def tokenize_text(text):
tokens = []
for sent in nltk.sent_tokenize(text):
for word in nltk.word_tokenize(sent):
if len(word) <= 0:
continue
tokens.append(word.lower())
return tokens
La función
tokenize_texttoma un texto como entrada y lo divide en una lista de palabras o “tokens” en minúsculas. Esta función usanltk.sent_tokenizeynltk.word_tokenizepara descomponer el texto en oraciones y palabras.
test_message = "Are you unique enough? Find out from 30th August. www.areyouunique.co.uk"
print(tokenize_text(test_message))
['are', 'you', 'unique', 'enough', '?', 'find', 'out', 'from', '30th', 'august', '.', 'www.areyouunique.co.uk']
train_tagged = train.apply(lambda r: TaggedDocument(words=tokenize_text(r['Message']), tags=[r.Category]), axis=1)
test_tagged = test.apply(lambda r: TaggedDocument(words=tokenize_text(r['Message']), tags=[r.Category]), axis=1)
La función de arriba, aplica una transformación a cada fila del
DataFrametrain, convirtiendo el contenido de cada mensaje en un objetoTaggedDocument, un formato utilizado en NLP para entrenar modelos de aprendizaje de texto comoDoc2Vecde la libreríaGensim.
max_featuresdepende de cuántas palabras únicas hay en todo el corpus, no de la longitud de cada mensaje. Puedes ver cuántas palabras únicas tienes así:
from collections import Counter
import itertools
all_words = list(itertools.chain.from_iterable(df['Message'].apply(lambda x: x.split())))
word_counts = Counter(all_words)
print(f"Total de palabras únicas: {len(word_counts)}")
Y luego decidir cuántas palabras mantener. Por ejemplo, si tienes 20.000 palabras únicas, puedes limitar a las 5.000 más frecuentes (
max_features = 5000), lo cual es típico. El resto son palabras raras, errores tipográficos, tecnicismos o formas muy específicas que aportan poco al modelo y pueden introducir ruido¨. De esta forma mejoramos la eficiencia, rendimiento, y además, evitamos overfitting.
max_features = 500000
Puede usar la siguiente función, para definir
MAX_SEQUENCE_LENGTH:
df['Message'].apply(lambda x: len(x.split())).describe()
Por ejemplo, si el resultado del .describe() es algo como:
count 10000.000000
mean 12.340000
std 8.567890
min 1.000000
25% 6.000000
50% 10.000000
75% 15.000000
max 78.000000
Entonces podrías definir
MAX_SEQUENCE_LENGTH = 20oMAX_SEQUENCE_LENGTH = 25, ya que se cubre más del 75% de tus datos (percentil 75 = 15), y evitas que muchos mensajes se recorten. Otra opción es escogerMAX_SEQUENCE_LENGTH = 50se cubre más del 99% de los mensajes sin necesidad de truncamiento.
MAX_SEQUENCE_LENGTH = 50
tokenizer = Tokenizer(num_words=max_features, split=' ', filters='!"#$%&()*+,-./:;<=>?@[$$^_`{|}~', lower=True)
tokenizer.fit_on_texts(df['Message'].values)
X = tokenizer.texts_to_sequences(df['Message'].values)
X = pad_sequences(X, maxlen=MAX_SEQUENCE_LENGTH)
print('Found %s unique tokens.' % len(X))
print('Shape of data tensor:', X.shape)
Found 5572 unique tokens.
Shape of data tensor: (5572, 50)
Tokenizer: Es un objeto deKerasque convierte texto en secuencias de números enteros, donde cada número representa un token (una palabra o símbolo) en el vocabulario.num_words=max_features: Establece el número máximo de palabras que se considerarán. Solo se tomarán en cuenta las palabras más frecuentes hastamax_features.filters='!"#$%&()*+,-./:;<=>?@[$$^_{|}~': Especifica los caracteres que se eliminarán del texto, como puntuación y símbolos.pad_sequences: Este método se utiliza para hacer que todas las secuencias enXtengan la misma longitud. Si una secuencia es más corta queMAX_SEQUENCE_LENGTH, se rellenará con ceros (o con un valor especificado); si es más larga, se truncará.
train_tagged.values
array([TaggedDocument(words=['reply', 'to', 'win', 'â£100', 'weekly', '!', 'where', 'will', 'the', '2006', 'fifa', 'world', 'cup', 'be', 'held', '?', 'send', 'stop', 'to', '87239', 'to', 'end', 'service'], tags=['spam']),
TaggedDocument(words=['hello', '.', 'sort', 'of', 'out', 'in', 'town', 'already', '.', 'that', '.', 'so', 'dont', 'rush', 'home', ',', 'i', 'am', 'eating', 'nachos', '.', 'will', 'let', 'you', 'know', 'eta', '.'], tags=['ham']),
TaggedDocument(words=['how', 'come', 'guoyang', 'go', 'n', 'tell', 'her', '?', 'then', 'u', 'told', 'her', '?'], tags=['ham']),
...,
TaggedDocument(words=['prabha', '..', 'i', "'m", 'soryda', '..', 'realy', '..', 'frm', 'heart', 'i', "'m", 'sory'], tags=['ham']),
TaggedDocument(words=['nt', 'joking', 'seriously', 'i', 'told'], tags=['ham']),
TaggedDocument(words=['did', 'he', 'just', 'say', 'somebody', 'is', 'named', 'tampa'], tags=['ham'])],
dtype=object)
d2v_model = Doc2Vec(dm=1, dm_mean=1, vector_size=20, window=8, min_count=1, workers=12, alpha=0.065, min_alpha=0.065)
El modelo
Doc2Veces útil para convertir documentos en representaciones numéricas (vectores) de tamaño fijo. Esto es esencial porque las LSTM requieren representaciones numéricas para trabajar.dm=1: Especifica que se usará el método Distributed Memory (DM) (en lugar de dm=0, que indica Distributed Bag of Words). Usar DM tiene textos más largos y complejos donde el orden de las palabras es importante y es crucial capturar el contexto para tareas de NLP que requieren una comprensión profunda del documento, como análisis de sentimientos o clasificación temática.dm_mean=1: Utiliza la media de los vectores de contextos de palabras para representar los documentos. Esto suele mejorar la precisión en comparación con otros métodos.vector_size=20: Define el tamaño del vector de salida, lo que significa que cada documento se representará como un vector de 20 dimensiones. Para textos simples o tareas básicas, un tamaño pequeño como 20 puede ser suficiente. Para análisis de texto más detallados, el tamaño del vector puede incrementarse para capturar mejor las relaciones entre palabras y documentos, generalmente entre 100 y 300 dimensiones.window=8: Define el tamaño de la ventana de contexto, es decir, el número máximo de palabras a considerar alrededor de la palabra objetivo en cada documento. En este caso, se consideran hasta 8 palabras a cada lado.min_count=1: Establece el mínimo de veces que una palabra debe aparecer en el corpus para ser incluida en el modelo. Un valor de 1 significa que todas las palabras en el corpus se incluirán.workers=12: Utiliza un solo núcleo de procesamiento para el entrenamiento. Si se incrementa este valor, se pueden usar varios núcleos para acelerar el proceso.alpha=0.065: Establece la tasa de aprendizaje inicial.Doc2Vecreduce gradualmente esta tasa durante el entrenamiento.min_alpha=0.065: Fija el límite inferior de la tasa de aprendizaje para que no disminuya más allá de este valor durante el entrenamiento.
d2v_model.build_vocab([x for x in tqdm(train_tagged.values)])
100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 4457/4457 [00:00<00:00, 8356733.54it/s]
d2v_model.build_vocab([x for x in tqdm(train_tagged.values)]): Crea el vocabulario para el modeloDoc2Vecen función de los documentos de entrada entrain_tagged
%%time
for epoch in range(30):
d2v_model.train(utils.shuffle([x for x in tqdm(train_tagged.values)]), total_examples=len(train_tagged.values), epochs=1)
d2v_model.alpha -= 0.002
d2v_model.min_alpha = d2v_model.alpha
100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 4457/4457 [00:00<00:00, 8614752.50it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 4457/4457 [00:00<00:00, 8682774.24it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 4457/4457 [00:00<00:00, 8598901.99it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 4457/4457 [00:00<00:00, 4978432.20it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 4457/4457 [00:00<00:00, 8822091.99it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 4457/4457 [00:00<00:00, 8264373.53it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 4457/4457 [00:00<00:00, 8379207.95it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 4457/4457 [00:00<00:00, 9070360.47it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 4457/4457 [00:00<00:00, 8735520.06it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 4457/4457 [00:00<00:00, 8735520.06it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 4457/4457 [00:00<00:00, 8764187.96it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 4457/4457 [00:00<00:00, 8478010.40it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 4457/4457 [00:00<00:00, 9039658.09it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 4457/4457 [00:00<00:00, 9177227.75it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 4457/4457 [00:00<00:00, 9236172.40it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 4457/4457 [00:00<00:00, 9052790.76it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 4457/4457 [00:00<00:00, 8768298.75it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 4457/4457 [00:00<00:00, 8910397.01it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 4457/4457 [00:00<00:00, 8901910.92it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 4457/4457 [00:00<00:00, 5243762.39it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 4457/4457 [00:00<00:00, 9105705.27it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 4457/4457 [00:00<00:00, 8868127.57it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 4457/4457 [00:00<00:00, 8834599.68it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 4457/4457 [00:00<00:00, 9342335.30it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 4457/4457 [00:00<00:00, 9571947.22it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 4457/4457 [00:00<00:00, 9145798.89it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 4457/4457 [00:00<00:00, 9403427.03it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 4457/4457 [00:00<00:00, 9342335.30it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 4457/4457 [00:00<00:00, 9412896.74it/s]
100%|███████████████████████████████████████████████████████████████████████████████████████████████████| 4457/4457 [00:00<00:00, 9389258.13it/s]
CPU times: user 10.4 s, sys: 13 s, total: 23.4 s
Wall time: 20 s
print(d2v_model)
Doc2Vec<dm/m,d20,n5,w8,s0.001,t12>
dm/m: Indica el tipo de modelo que se está utilizando. dm significa que se está utilizando el enfoque de Distributed Memory (DM). El “m” se refiere a que se está usando la estrategia de “mean” (media) para la representación de los contextos de palabras.d20: Este parámetro indica el tamaño del vector de salida, que es de 20 dimensiones. Es decir, cada documento se representará como un vector de 20 dimensiones.n5: Este número se refiere al número de palabras mínimas requeridas para que una palabra sea incluida en el vocabulario. En este caso, las palabras que aparecen al menos 5 veces serán consideradas.w8: Este valor representa el tamaño de la ventana de contexto, que es de 8 palabras. Esto significa que al entrenar el modelo, se considera un contexto de 8 palabras antes y después de la palabra objetivo.s0.001: Este número indica la tasa de aprendizaje inicial (alpha), que es de 0.001 en este caso. Esta tasa determina cuánto se ajustan los pesos del modelo durante el entrenamiento.
num_words = len(d2v_model.wv.key_to_index)
print(num_words)
8266
words = d2v_model.wv.index_to_key
print(words[-10:])
['phone750', 'weaseling', 'connected', 'ltd.', 'gmw', 'wrongly', 'bless.get', 'gained', 'money.i', '.so']
embedding_matrix = np.zeros((len(d2v_model.wv.key_to_index)+ 1, 20))
embedding_matrix = np.zeros((len(d2v_model.wv.key_to_index)+ 1, 20)): Inicializa una matriz de embeddings (representaciones vectoriales) de tamaño (número de palabras en el vocabulario + 1, 20) llena de ceros. Esta matriz se puede utilizar posteriormente para almacenar las representaciones vectoriales de cada palabra del vocabulario aprendidas por el modeloDoc2Vec
for i in range(len(d2v_model.dv)):
vec = d2v_model.dv[i]
if vec is not None and len(vec) <= 1000:
print(i)
print(d2v_model.dv)
embedding_matrix[i] = vec
print(vec)
0
KeyedVectors<vector_size=20, 2 keys>
[ -2.1169324 -4.408813 -12.770262 3.3775191 2.234026
5.959987 -7.048608 -3.0703468 -9.062501 -0.1266938
3.2856421 3.3359487 -1.5149089 -0.75900716 -2.568246
-3.278381 4.8290677 9.247938 -9.8519945 -5.3881884 ]
1
KeyedVectors<vector_size=20, 2 keys>
[ 0.18017875 1.0570073 1.1698819 2.5047464 2.4777415 -4.003105
-1.7930715 -0.7937521 1.1903608 -3.1990352 2.5313067 0.22975987
-3.2666025 -1.7999983 -0.05136773 2.5013123 -0.37114444 -2.3989332
-1.7552563 -0.50705457]
Este bucle itera a través de los vectores de documento en el modelo Doc2Vec, verifica que cada vector sea válido y su longitud adecuada, imprime información relevante, y almacena los vectores en una matriz de embeddings.
d2v_model.wv.most_similar(positive=['urgent'], topn=10)
[('darlings', 0.8462594747543335),
('having', 0.8417801856994629),
('curtsey', 0.780465841293335),
('09061743810', 0.7634333968162537),
('aint', 0.750674307346344),
('-call', 0.7376469969749451),
('practising', 0.7356770038604736),
('roads', 0.7193555235862732),
('denying', 0.7155202627182007),
('09066612661', 0.7121841907501221)]
d2v_model.wv.most_similar(positive=['urgent'], topn=10): Se utiliza para encontrar las palabras más similares al término “urgent” en el modeloDoc2Vec
d2v_model.wv.most_similar(positive=['cherish'], topn=10)
[('canada', 0.8002477288246155),
('okors', 0.79483962059021),
('abi', 0.7816047072410583),
('enjoyed', 0.7601490020751953),
('thank', 0.7434270977973938),
('dent', 0.7304296493530273),
('hmmm.still', 0.7260045409202576),
('mr.', 0.7170077562332153),
('rugby', 0.7144231200218201),
('tall', 0.7090185284614563)]
Pasamos a implementar el modelo
LSTM
from keras.models import Sequential
from keras.layers import LSTM, Dense, Embedding
from tensorflow.keras.optimizers.legacy import Adam
Crear un modelo secuencial, es decir, un modelo LSTM donde las capas se apilan una detrás de otra, en orden
model = Sequential()
Vectores de palabras
Embedding
from tensorflow.keras.initializers import Constant
model.add(
Embedding(
input_dim=len(d2v_model.wv.key_to_index) + 1,
output_dim=20,
embeddings_initializer=Constant(embedding_matrix),
trainable=True
)
)
weights=[embedding_matrix]: Al pasar esto como un argumento deweights, se le indica aKerasque use estos vectores iniciales para la capa de incrustación.
LSTM(50)agrega una capa LSTM con 50 unidades (neuronas).return_sequences=False: Esto indica que la capa devuelve solo la última salida de la secuencia, no toda la secuencia de salidas.
model.add(LSTM(50,return_sequences=False))
I0000 00:00:1762262037.219688 2450 cuda_executor.cc:1001] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node
Your kernel may have been built without NUMA support.
I0000 00:00:1762262037.219775 2450 cuda_executor.cc:1001] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node
Your kernel may have been built without NUMA support.
I0000 00:00:1762262037.219805 2450 cuda_executor.cc:1001] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node
Your kernel may have been built without NUMA support.
I0000 00:00:1762262037.473344 2450 cuda_executor.cc:1001] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node
Your kernel may have been built without NUMA support.
I0000 00:00:1762262037.473413 2450 cuda_executor.cc:1001] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node
Your kernel may have been built without NUMA support.
2025-11-04 08:13:57.473423: I tensorflow/core/common_runtime/gpu/gpu_device.cc:2112] Could not identify NUMA node of platform GPU id 0, defaulting to 0. Your kernel may not have been built with NUMA support.
I0000 00:00:1762262037.473469 2450 cuda_executor.cc:1001] could not open file to read NUMA node: /sys/bus/pci/devices/0000:01:00.0/numa_node
Your kernel may have been built without NUMA support.
2025-11-04 08:13:57.480245: I tensorflow/core/common_runtime/gpu/gpu_device.cc:2021] Created device /job:localhost/replica:0/task:0/device:GPU:0 with 9558 MB memory: -> device: 0, name: NVIDIA GeForce RTX 4070, pci bus id: 0000:01:00.0, compute capability: 8.9
model.add(Dense(2,activation="softmax"))
Usamos
summary()para mostrar un resumen de la arquitectura del modelo.
model.summary()
Model: "sequential"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ embedding (Embedding) │ ? │ 0 (unbuilt) │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ lstm (LSTM) │ ? │ 0 (unbuilt) │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense (Dense) │ ? │ 0 (unbuilt) │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 0 (0.00 B)
Trainable params: 0 (0.00 B)
Non-trainable params: 0 (0.00 B)
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Embedding, LSTM, Dense
from tensorflow.keras.optimizers import Adam
Queda como ejercicio para el estudiante, cambiar la métrica de validación a AUC, tal como se hizo en el ejercicio de reconocimiento facial de emociones usando CNNs
model.compile(optimizer=Adam(), loss="binary_crossentropy", metrics=['accuracy'])
Y = pd.get_dummies(df['Category']).values
X_train, X_test, Y_train, Y_test = train_test_split(X,Y, test_size = 0.15, random_state = 42)
print(X_train.shape,Y_train.shape)
print(X_test.shape,Y_test.shape)
(4736, 50) (4736, 2)
(836, 50) (836, 2)
batch_size = 32
import os
from joblib import dump, load
history_lstm = None
if os.path.exists('history_lstm.joblib'):
history_lstm = load('history_lstm.joblib')
print("El archivo 'history_lstm.joblib' ya existe. Se ha cargado el historial del entrenamiento.")
else:
history_lstm = model.fit(X_train, Y_train, epochs=50, batch_size=batch_size, verbose=2)
dump(history_lstm.history, 'history_lstm.joblib')
print("El entrenamiento se ha completado y el historial ha sido guardado en 'history_lstm.joblib'.")
El archivo 'history_lstm.joblib' ya existe. Se ha cargado el historial del entrenamiento.
import matplotlib.pyplot as plt
import os
plt.plot(history_lstm['accuracy'])
plt.title('Model accuracy')
plt.ylabel('Accuracy')
plt.xlabel('Epochs')
plt.legend(['Train'], loc='upper left')
plt.show()
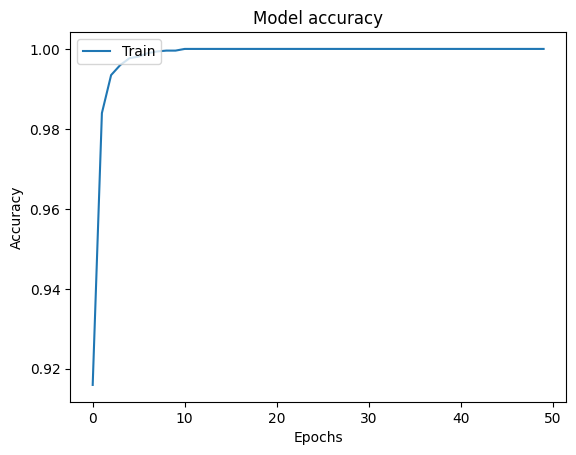
plt.plot(history_lstm['loss']);
plt.title('model loss');
plt.ylabel('loss');
plt.xlabel('epochs');
plt.legend(['train', 'test'], loc='upper left');
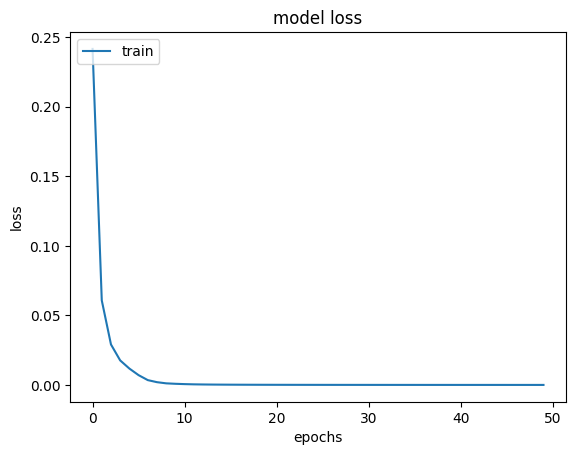
_, train_acc = model.evaluate(X_train, Y_train, verbose=2)
_, test_acc = model.evaluate(X_test, Y_test, verbose=2)
print('Train: %.3f, Test: %.4f' % (train_acc, test_acc))
2025-11-04 08:13:58.911293: I external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:531] Loaded cuDNN version 8907
148/148 - 2s - 17ms/step - accuracy: 0.2255 - loss: 0.8315
27/27 - 0s - 13ms/step - accuracy: 0.2081 - loss: 0.8315
Train: 0.226, Test: 0.2081
Las siguientes líneas están utilizando el modelo entrenado para predecir la probabilidad de que cada entrada en
X_testpertenezca a cada clase. Luego, se determina la clase más probable para cada entrada y se imprime tanto las probabilidades como las clases predichas.np.argmax(yhat_probs, axis=1)toma la clase con mayor probabilidad en cada fila.
yhat_probs = model.predict(X_test, verbose=0)
print(yhat_probs)
[[0.5000171 0.49998292]
[0.49831238 0.5016876 ]
[0.50272566 0.4972743 ]
...
[0.48602834 0.5139716 ]
[0.49706176 0.5029382 ]
[0.50004566 0.49995437]]
yhat_classes = np.argmax(yhat_probs, axis=1)
print(yhat_classes)
[0 1 0 1 1 1 1 0 1 1 1 0 1 1 0 1 0 1 0 1 1 1 1 0 0 1 1 1 1 1 1 0 1 1 1 1 1
1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0 1 1 1 1 0 1 1 1 0 1
1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 0 1 1 1 1 1 0
1 1 1 0 1 1 0 1 1 1 1 1 1 0 1 1 1 1 1 1 0 1 0 1 1 0 1 1 1 0 1 1 1 1 0 1 1
1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 0 0 1 1 1 0 1 1 1
1 1 1 1 1 1 1 1 1 1 0 1 0 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1
1 1 1 1 0 1 1 1 1 1 1 0 0 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1
1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 0 1 0 1 1 0 1 1 1 1 0 1 1 1
0 1 0 1 0 1 1 1 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 1
1 1 1 1 1 1 1 1 1 0 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 1 1 0 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 0 1 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 0 1 1 1
1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 0 1 1 1 1 1 0 1 1 0 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 1 0 1 0 1 1 1 1 0 1 1 1 1 0 1 1 1
1 1 1 1 1 1 1 0 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 0 1 1 1 1 1
1 0 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0 1 1 1 1
1 1 0 1 1 1 1 1 1 1 1 1 1 1 0 1 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 0 0 1 1
0 1 1 1 1 0 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 0 1 0 1 1 1 1 1 1 1 1 1 1 0 1 1 0 0 1 0 0 1 1 1 1 1 1 1 0 1 0 1 1
1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 1 0 1 1 1 1 1 1 1
1 0 1 1 1 1 1 1 1 0 1 1 1 0 1 1 0 1 1 1 1 0]
Cada número en este arreglo representa la clase predicha para cada muestra en el conjunto de prueba. Por ejemplo, si el valor es 0, significa que la muestra pertenece a la clase 0, y si es 1, significa que la muestra pertenece a la clase 1.
yhat_probs = yhat_probs[:, 0]
import numpy as np
rounded_labels=np.argmax(Y_test, axis=1)
rounded_labels
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0,
0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0,
0, 0, 0, 0, 1, 0, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0,
0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 1, 0,
0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0,
0, 1, 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1,
0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1,
0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0,
1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1,
0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0,
0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 1, 1, 0, 0, 0, 0,
1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0,
0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0,
0, 0, 0, 0, 0, 1, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0,
0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0,
0, 0, 1, 1, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 1, 1, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 0, 0, 0, 0])
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(rounded_labels, yhat_classes)
cm
array([[ 89, 640],
[ 22, 85]])
from sklearn.metrics import confusion_matrix
import seaborn as sns
lstm_val = confusion_matrix(rounded_labels, yhat_classes)
f, ax = plt.subplots(figsize=(5,5))
sns.heatmap(lstm_val, annot=True, linewidth=0.7, linecolor='cyan', fmt='g', ax=ax, cmap="BuPu")
plt.title('LSTM Classification Confusion Matrix')
plt.xlabel('Y predict')
plt.ylabel('Y test')
plt.show()

validation_size = 200
X_validate = X_test[-validation_size:]
Y_validate = Y_test[-validation_size:]
X_test = X_test[:-validation_size]
Y_test = Y_test[:-validation_size]
score,acc = model.evaluate(X_test, Y_test, verbose = 1, batch_size = batch_size)
print("score: %.2f" % (score))
print("acc: %.2f" % (acc))
20/20 ━━━━━━━━━━━━━━━━━━━━ 0s 4ms/step - accuracy: 0.2202 - loss: 0.8301
score: 0.83
acc: 0.21
model.save('Mymodel.keras')
Pruebas con conjuntos de datos nuevos y diferentes de los datos para construir el modelo.
message = ['Congratulations! you have won a $1,000 Walmart gift card. Go to http://bit.ly/123456 to claim now.']
seq = tokenizer.texts_to_sequences(message)
padded = pad_sequences(seq, maxlen=X.shape[1], dtype='int32', value=0)
pred = model.predict(padded)
labels = ['ham','spam']
print(pred, labels[np.argmax(pred)])
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 115ms/step
[[0.46063516 0.5393649 ]] spam
message = ['thanks for accepting my request to connect']
seq = tokenizer.texts_to_sequences(message)
padded = pad_sequences(seq, maxlen=X.shape[1], dtype='int32', value=0)
pred = model.predict(padded)
labels = ['ham','spam']
print(pred, labels[np.argmax(pred)])
1/1 ━━━━━━━━━━━━━━━━━━━━ 0s 12ms/step
[[0.2417007 0.7582993]] spam
11.20. Proyecto Integrador de Aprendizaje Automático#
11.20.1. Título#
Segmentación de células e interpretación de texto mediante modelos de deep learning: evaluación, comparación y despliegue básico
11.20.2. Objetivo general#
Desarrollar, entrenar, evaluar y comparar modelos de deep learning en dos dominios:
Segmentación de imágenes biomédicas
Clasificación de texto (NLP)
El estudiante deberá:
Construir modelos funcionales desde cero o usando transfer learning
Implementar pipelines reproducibles
Ajustar hiperparámetros
Evaluar modelos con métricas apropiadas
Interpretar resultados de manera crítica
Implementar un despliegue básico tipo MLOps
11.20.3. Contexto aplicado#
11.20.3.1. Biomedicina#
Segmentación automática de células en imágenes microscópicas para apoyar diagnósticos y análisis clínicos.
11.20.3.2. Procesamiento del Lenguaje Natural#
Clasificación automática de texto para aplicaciones como reclutamiento, clasificación de intenciones o atención al cliente.
11.20.4. Datasets#
11.20.4.1. Segmentación de imágenes#
Datos: imágenes + máscaras en formato RLE
11.20.4.2. NLP#
Datos: textos etiquetados
EDA (ver Complete Guide to EDA on Text Data)
11.20.5. Bloque 1: Segmentación de imágenes#
11.20.5.1. Análisis Exploratorio de Datos (EDA)#
11.20.5.1.1. Objetivo#
Comprender completamente la estructura del dataset antes de modelar.
11.20.5.1.2. Paso a paso#
11.20.5.1.2.1. 1. Carga de datos#
Leer imágenes con
cv2oPILCargar archivo de anotaciones (CSV con RLE)
Convertir máscaras RLE a imágenes binarias
11.20.5.1.2.2. 2. Construcción de dataset estructurado#
Crear un dataframe con:
id_imagen
ruta_imagen
número de máscaras
área de cada máscara
11.20.5.1.3. Análisis obligatorios#
11.20.5.1.3.1. Tamaño de imágenes#
Calcular alto y ancho de cada imagen
Visualizaciones:
Histograma de alturas
Histograma de anchos
Scatter plot (alto vs ancho)
11.20.5.1.3.2. Número de células por imagen#
Contar instancias por imagen
Visualizaciones:
Histograma
Boxplot
11.20.5.1.3.3. Área de células#
Calcular número de píxeles por máscara
Visualizaciones:
Histograma de áreas
Boxplot
11.20.5.1.3.4. Intensidad de píxeles#
Analizar distribución de intensidades
Visualizaciones:
Histogramas por canal
11.20.5.1.3.5. Visualización cualitativa#
Mostrar 5 imágenes con:
Imagen original
Máscaras superpuestas
11.20.5.1.4. Interpretación obligatoria#
¿Las imágenes son homogéneas o muy variables?
¿Existe desbalance en número de células?
¿Las células son pequeñas o grandes?
¿Hay ruido o artefactos?
11.20.5.2. Preprocesamiento#
11.20.5.2.1. Pasos obligatorios#
Normalización:
img = img / 255.0
Redimensionamiento:
256×256 o 512×512
Conversión de máscaras:
RLE → binaria → tensor
Data augmentation:
Rotaciones
Flips horizontales y verticales
Zoom
Deformaciones (opcional)
11.20.5.2.2. Entregable#
Comparación visual:
Imagen original
Imagen procesada
11.20.5.3. Modelos a implementar#
11.20.5.3.1. Obligatorio: implementar los 5 modelos#
Pos |
Modelo |
|---|---|
1 |
Mask R-CNN (+ Swin) |
2 |
Hover-Net |
3 |
U-Net++ + Watershed |
4 |
Cellpose 2.0 |
5 |
SAM / MedSAM |
11.20.5.3.2. Qué debe hacer en cada modelo#
Definir arquitectura
Entrenar modelo
Ajustar hiperparámetros
Evaluar
11.20.5.3.3. Hiperparámetros a ajustar#
learning_rate
batch_size
epochs
optimizer
scheduler (opcional)
11.20.5.4. Validación#
Train: 70%
Validation: 15%
Test: 15%
Validación cruzada: K-Fold (k=5)
11.20.5.5. Métricas de evaluación#
Calcular en validación y test:
Dice Coefficient
IoU
Precision
Recall
AUC
Hausdorff Distance
Balanced Accuracy
11.20.5.6. Evaluación y visualización#
Para cada modelo:
11.20.5.6.1. Comparación visual#
Imagen original
Ground Truth
Predicción
11.20.5.6.2. Curvas#
ROC
Precision-Recall
11.20.5.6.3. Mapas de error#
FP en rojo
FN en azul
11.20.5.6.4. Boxplots#
Dice
IoU
Precision
Recall
AUC
Hausdorff
Balanced Accuracy
11.20.5.6.5. Histogramas#
Distribución de métricas
11.20.5.7. Resultados#
Modelo |
Dice |
IoU |
Precision |
Recall |
AUC |
Hausdorff |
Balanced Acc |
|---|---|---|---|---|---|---|---|
Mask R-CNN (+ Swin) |
|||||||
Hover-Net |
|||||||
U-Net++ + Watershed |
|||||||
Cellpose 2.0 |
|||||||
SAM / MedSAM |
11.20.5.8. Análisis crítico#
¿Qué modelo funciona mejor y por qué?
¿Qué errores son más frecuentes?
¿Qué limitaciones tiene el dataset?
¿Cómo afecta el preprocesamiento?
11.20.6. Bloque 2: Procesamiento del Lenguaje Natural (NLP)#
11.20.6.1. Análisis Exploratorio de Datos (EDA)#
11.20.6.1.1. Paso a paso#
11.20.6.1.1.1. Carga de datos#
Leer dataset con
pandas
11.20.6.1.1.2. Análisis de clases#
Conteo de clases (barplot)
11.20.6.1.1.3. Longitud de textos#
Número de palabras por texto
Visualizaciones:
Histograma
Boxplot
11.20.6.1.1.4. Frecuencia de palabras#
Top palabras
Visualizaciones:
Barplot top 20
WordCloud
11.20.6.1.1.5. N-gramas#
Bigramas y trigramas
11.20.6.1.2. Interpretación#
¿Clases balanceadas?
¿Textos cortos o largos?
¿Hay ruido?
11.20.6.2. Preprocesamiento#
11.20.6.2.1. Pasos obligatorios#
Minúsculas
Eliminación de símbolos
Eliminación de stopwords
Tokenización
Padding
11.20.6.2.2. Embeddings#
Word2Vec
FastText
11.20.6.3. Modelos a implementar#
Pos |
Modelo |
|---|---|
1 |
DistilBERT o RoBERTa |
2 |
Word2Vec + BiLSTM |
3 |
CNN-1D |
4 |
TF-IDF + XGBoost |
5 |
FastText |
11.20.6.4. Hiperparámetros (BiLSTM obligatorio)#
lstm_units: 32, 64, 128
num_lstm_layers: 1, 2
dropout_rate: 0.3, 0.5
learning_rate: 0.0005, 0.001, 0.003
batch_size: 32, 64
sequence_length: 50, 100 (ajustado con EDA)
epochs: 20, 50 (con early stopping)
embedding_dim: 100, 200
11.20.6.5. Entrenamiento#
Dividir en train, validation y test
Ajustar usando validation
Evaluar en test
11.20.6.6. Métricas#
Accuracy
Precision
Recall
F1-score
Matriz de confusión
ROC-AUC
11.20.6.7. Evaluación#
Matriz de confusión
Curva ROC
Curva Precision-Recall
11.20.6.8. Resultados#
| Modelo | Accuracy | Precision | Recall | F1 | ROC-AUC |
11.20.6.9. Análisis crítico#
¿Transformers vs modelos clásicos?
¿Impacto del preprocesamiento?
¿Errores comunes?
11.20.7. MLOps (BÁSICO)#
11.20.7.1. Objetivo#
Desplegar modelos en una API.
11.20.7.2. FastAPI#
@app.post("/predict_text")
11.20.7.3. Docker#
Crear Dockerfile para ejecutar la API
11.20.7.4. CI/CD#
Tests básicos
Validación de ejecución
11.20.7.5. Monitoreo (conceptual)#
Data drift
Métricas en producción
Latencia
11.20.8. Restricciones#
Código claro y documentado
Uso de métricas obligatorio
Interpretación obligatoria
Visualizaciones obligatorias
11.20.9. Herramientas sugeridas#
Python
PyTorch / TensorFlow
scikit-learn
matplotlib / seaborn
fastapi
11.20.10. Entregables#
Jupyter Book completo
Notebooks (segmentación + NLP)
Código funcional
API básica
README
11.20.11. Estructura del proyecto#
project/
├── data/
├── notebooks/
├── app/
├── models/
├── Dockerfile
├── requirements.txt
└── README.md
11.20.12. Comparación final#
Mejor modelo en imágenes
Mejor modelo en NLP
Trade-offs (precisión vs costo)
11.20.13. Conclusiones#
¿Qué modelo usaría en producción?
¿Qué mejoraría?
¿Qué aprendió?
11.20.14. Reporte final#
El entregable debe ser un Jupyter Book que incluya:
EDA completo con visualizaciones
Detalles de modelos
Tablas comparativas
Análisis crítico
Recomendaciones de mejora
11.21. Aplicación: LSTM para la predicción de series de tiempo#
Continuaremos usando el conjunto de datos sobre contaminación del aire (
pm2.5) usando LSTM. La lectura y el preprocesamiento de los datos se mantienen igual que en los ejemplos deMLPs. El conjunto de datos original se divide en dos conjuntos: entrenamiento y validación, que se usan para el entrenamiento y validación del modelo respectivamente.
La función
makeXyse utiliza para generar arreglos de regresores y objetivos:X_train, X_val, y_trainyy_val.X_train y X_val, generados por la funciónmakeXy, son arreglos 2D de forma (número de muestras, número de pasos de tiempo). Sin embargo, la entrada a las capas RNN debe ser de forma (número de muestras, número de pasos de tiempo, número de características por paso de tiempo).En este caso, estamos tratando solo con
pm2.5, por lo tanto, el número de características por paso de tiempo es uno. El número de pasos de tiempo es siete y el número de muestras es el mismo que el número de muestras enX_trainyX_val, que se transforman a arreglos 3D
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
import datetime
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import warnings
warnings.filterwarnings('ignore')
plot_fontsize = 18;
df = pd.read_csv('https://raw.githubusercontent.com/lihkir/Data/refs/heads/main/PRSA_data_2010.1.1-2014.12.31.csv', usecols=lambda column: column not in ['DEWP', 'TEMP', 'cbwd', 'Iws', 'Is', 'Ir'])
print('Shape of the dataframe:', df.shape)
Shape of the dataframe: (43824, 7)
df.head()
| No | year | month | day | hour | pm2.5 | PRES | |
|---|---|---|---|---|---|---|---|
| 0 | 1 | 2010 | 1 | 1 | 0 | NaN | 1021.0 |
| 1 | 2 | 2010 | 1 | 1 | 1 | NaN | 1020.0 |
| 2 | 3 | 2010 | 1 | 1 | 2 | NaN | 1019.0 |
| 3 | 4 | 2010 | 1 | 1 | 3 | NaN | 1019.0 |
| 4 | 5 | 2010 | 1 | 1 | 4 | NaN | 1018.0 |
df.dropna(subset=['pm2.5'], axis=0, inplace=True)
df.reset_index(drop=True, inplace=True)
df['datetime'] = df[['year', 'month', 'day', 'hour']].apply(lambda row: datetime.datetime(year=row['year'], month=row['month'], day=row['day'],
hour=row['hour']), axis=1)
df.sort_values('datetime', ascending=True, inplace=True)
plt.figure(figsize=(15, 8))
plt.subplot(1, 2, 1)
g1 = sns.boxplot(df['pm2.5'], orient="h", palette="Set2")
g1.set_title('Box plot of pm2.5', fontsize=plot_fontsize);
g1.set_xlabel(xlabel='pm2.5', fontsize=plot_fontsize)
g1.set(yticklabels=[])
g1.tick_params(left=False);
plt.subplot(1, 2, 2)
g2 = sns.lineplot(df['pm2.5'])
g2.set_title('Time series of pm2.5', fontsize=plot_fontsize)
g2.set_xlabel('Index', fontsize=plot_fontsize)
g2.set_ylabel('pm2.5 readings');
plt.show()
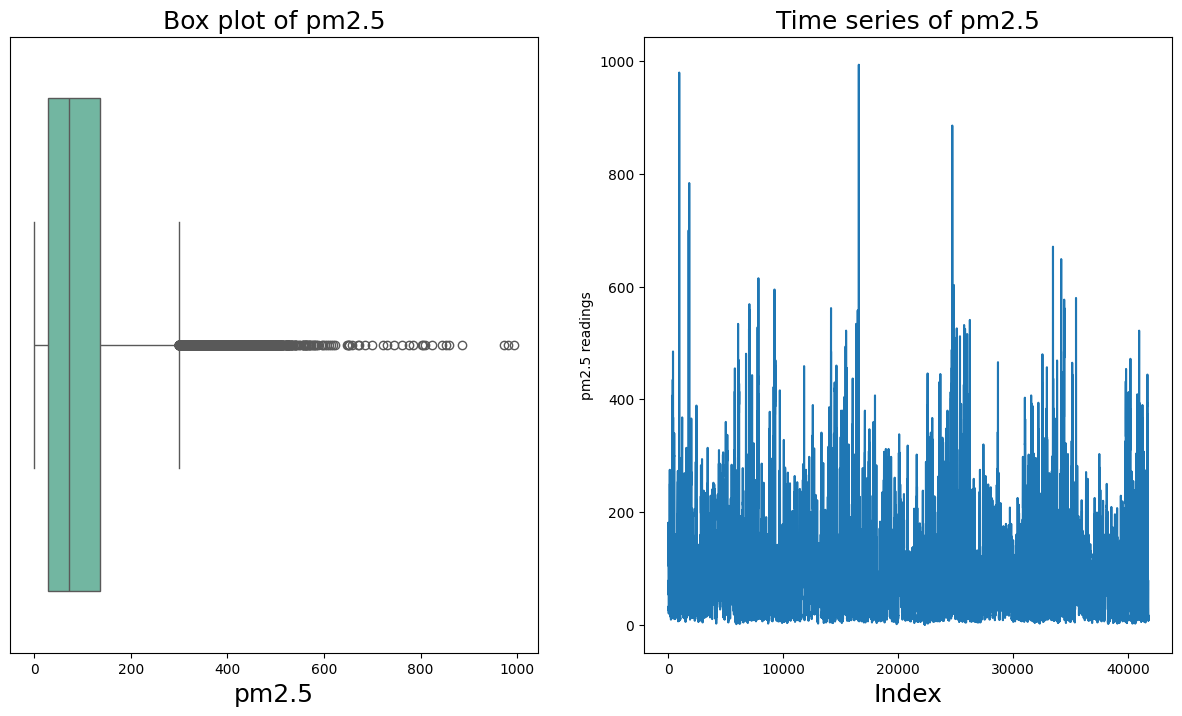
plt.figure(figsize=(15, 8))
plt.subplot(1, 2, 1)
g1 = sns.lineplot(df['pm2.5'].loc[df['datetime']<=datetime.datetime(year=2010,month=6,day=30)], color='g')
g1.set_title('pm2.5 during 2010', fontsize=plot_fontsize)
g1.set_xlabel('Index', fontsize=plot_fontsize)
g1.set_ylabel('pm2.5 readings', fontsize=plot_fontsize);
plt.subplot(1, 2, 2)
g = sns.lineplot(df['pm2.5'].loc[df['datetime']<=datetime.datetime(year=2010,month=1,day=31)], color='g')
g.set_title('Zoom in on one month: pm2.5 during Jan 2010', fontsize=plot_fontsize)
g.set_xlabel('Index', fontsize=plot_fontsize)
g.set_ylabel('pm2.5 readings', fontsize=plot_fontsize);
plt.show()

split_date = datetime.datetime(year=2014, month=1, day=1, hour=0)
df_train = df.loc[df['datetime']<split_date]
df_val = df.loc[df['datetime']>=split_date]
print('Shape of train:', df_train.shape)
print('Shape of test:', df_val.shape)
Shape of train: (33096, 8)
Shape of test: (8661, 8)
df_train.head()
| No | year | month | day | hour | pm2.5 | PRES | datetime | |
|---|---|---|---|---|---|---|---|---|
| 0 | 25 | 2010 | 1 | 2 | 0 | 129.0 | 1020.0 | 2010-01-02 00:00:00 |
| 1 | 26 | 2010 | 1 | 2 | 1 | 148.0 | 1020.0 | 2010-01-02 01:00:00 |
| 2 | 27 | 2010 | 1 | 2 | 2 | 159.0 | 1021.0 | 2010-01-02 02:00:00 |
| 3 | 28 | 2010 | 1 | 2 | 3 | 181.0 | 1022.0 | 2010-01-02 03:00:00 |
| 4 | 29 | 2010 | 1 | 2 | 4 | 138.0 | 1022.0 | 2010-01-02 04:00:00 |
df_val.head()
| No | year | month | day | hour | pm2.5 | PRES | datetime | |
|---|---|---|---|---|---|---|---|---|
| 33096 | 35065 | 2014 | 1 | 1 | 0 | 24.0 | 1014.0 | 2014-01-01 00:00:00 |
| 33097 | 35066 | 2014 | 1 | 1 | 1 | 53.0 | 1013.0 | 2014-01-01 01:00:00 |
| 33098 | 35067 | 2014 | 1 | 1 | 2 | 65.0 | 1013.0 | 2014-01-01 02:00:00 |
| 33099 | 35068 | 2014 | 1 | 1 | 3 | 70.0 | 1013.0 | 2014-01-01 03:00:00 |
| 33100 | 35069 | 2014 | 1 | 1 | 4 | 79.0 | 1012.0 | 2014-01-01 04:00:00 |
df_val.reset_index(drop=True, inplace=True)
scaler_pm25 = MinMaxScaler(feature_range=(0, 1))
df_train['scaled_pm2.5'] = scaler_pm25.fit_transform(df_train[['pm2.5']])
df_val['scaled_pm2.5'] = scaler_pm25.transform(df_val[['pm2.5']])
print('Shape of train:', df_train.shape)
print('Shape of val:', df_val.shape)
Shape of train: (33096, 9)
Shape of val: (8661, 9)
plt.figure(figsize=(15, 8))
plt.subplot(1, 2, 1)
g1 = sns.lineplot(df_train['scaled_pm2.5'], color='b')
g1.set_title('Time series of scaled pm2.5 in train set', fontsize=plot_fontsize)
g1.set_xlabel('Index', fontsize=plot_fontsize)
g1.set_ylabel('Scaled pm2.5 readings', fontsize=plot_fontsize);
plt.subplot(1, 2, 2)
g2 = sns.lineplot(df_val['scaled_pm2.5'], color='r')
g2.set_title('Time series of scaled pm2.5 in validation set', fontsize=plot_fontsize)
g2.set_xlabel('Index', fontsize=plot_fontsize)
g2.set_ylabel('Scaled pm2.5 readings', fontsize=plot_fontsize);
plt.show()

def makeXy(ts, nb_timesteps):
"""
Input:
ts: original time series
nb_timesteps: number of time steps in the regressors
Output:
X: 2-D array of regressors
y: 1-D array of target
"""
X = []
y = []
for i in range(nb_timesteps, ts.shape[0]):
if i-nb_timesteps <= 4:
print(i-nb_timesteps, i-1, i)
X.append(list(ts.loc[i-nb_timesteps:i-1])) #Regressors
y.append(ts.loc[i]) #Target
X, y = np.array(X), np.array(y)
return X, y
X_train, y_train = makeXy(df_train['scaled_pm2.5'], 7)
0 6 7
1 7 8
2 8 9
3 9 10
4 10 11
print('Shape of train arrays:', X_train.shape, y_train.shape)
Shape of train arrays: (33089, 7) (33089,)
X_val, y_val = makeXy(df_val['scaled_pm2.5'], 7)
0 6 7
1 7 8
2 8 9
3 9 10
4 10 11
print('Shape of validation arrays:', X_val.shape, y_val.shape)
Shape of validation arrays: (8654, 7) (8654,)
X_train, X_val = X_train.reshape((X_train.shape[0], X_train.shape[1], 1)), X_val.reshape((X_val.shape[0], X_val.shape[1], 1))
print('Shape of 3D arrays:', X_train.shape, X_val.shape)
Shape of 3D arrays: (33089, 7, 1) (8654, 7, 1)
X_trainyX_valse han convertido en matrices 3D y sus nuevas formas se ven en la salida de la instrucción de impresión anterior
from keras.layers import Dense, Input, Dropout
from keras.layers import LSTM
from keras.optimizers import SGD
from keras.models import Model
from keras.models import load_model
from keras.callbacks import ModelCheckpoint
La red neuronal para desarrollar el modelo de predicción de series temporales tiene una capa de entrada, que alimenta a la capa LSTM. La capa LSTM tiene siete pasos temporales, que es el mismo número de observaciones históricas tomadas para hacer la predicción de la presión atmosférica para el día siguiente. Solo el último paso temporal de la LSTM devuelve una salida.
Hay sesenta y cuatro neuronas ocultas en cada paso temporal de la capa LSTM. Por lo tanto, la salida de la LSTM tiene sesenta y cuatro características:
input_layer = Input(shape=(7,1), dtype='float32')
Aquí
shape=(7,1)forma de la entrada a la LSTM.7: Número de pasos de tiempo (timesteps).1: Número de características (features) por cada paso de tiempo.return_sequences=Truese usa cuando se necesita pasar la secuencia completa de salidas a la siguiente capa de la red, que también puede ser una capa recurrente como otra LSTM
lstm_layer1 = LSTM(64, input_shape=(7,1), return_sequences=True)(input_layer)
lstm_layer2 = LSTM(32, input_shape=(7,64), return_sequences=False)(lstm_layer1)
A continuación, la salida de LSTM pasa a una capa de exclusión que elimina aleatoriamente el 20% de la entrada antes de pasar a la capa de salida, que tiene una única neurona oculta con una función de activación lineal
dropout_layer = Dropout(0.2)(lstm_layer2)
output_layer = Dense(1, activation='linear')(dropout_layer)
Finalmente, todas las capas se envuelven en un
keras.models.Modely se entrenan durante veinte epochs para minimizar el MSE utilizando el optimizador Adam
ts_model = Model(inputs=input_layer, outputs=output_layer)
ts_model.compile(loss='mean_absolute_error', optimizer='adam') #SGD(lr=0.001, decay=1e-5))
ts_model.summary()
Model: "functional_2"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓ ┃ Layer (type) ┃ Output Shape ┃ Param # ┃ ┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩ │ input_layer_1 (InputLayer) │ (None, 7, 1) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ lstm_1 (LSTM) │ (None, 7, 64) │ 16,896 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ lstm_2 (LSTM) │ (None, 32) │ 12,416 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dropout (Dropout) │ (None, 32) │ 0 │ ├─────────────────────────────────┼────────────────────────┼───────────────┤ │ dense_1 (Dense) │ (None, 1) │ 33 │ └─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 29,345 (114.63 KB)
Trainable params: 29,345 (114.63 KB)
Non-trainable params: 0 (0.00 B)
import os
from joblib import dump, load
from keras.callbacks import EarlyStopping, ModelCheckpoint
save_weights_at = os.path.join('keras_models', 'PRSA_data_PM2.5_LSTM_weights.{epoch:02d}-{val_loss:.4f}.keras')
checkpointer = [
EarlyStopping(
monitor='val_loss',
verbose=1,
restore_best_weights=True,
mode='min',
patience=10
),
ModelCheckpoint(
filepath=save_weights_at,
monitor='val_loss',
verbose=1,
save_best_only=True,
save_weights_only=False,
mode='min',
save_freq='epoch'
)
]
history_pm25_LSTM = None
if os.path.exists('history_pm25_LSTM.joblib'):
history_pm25_LSTM = load('history_pm25_LSTM.joblib')
print("El archivo 'history_pm25_LSTM.joblib' ya existe. Se ha cargado el historial del entrenamiento.")
else:
history_pm25_LSTM = ts_model.fit(
x=X_train,
y=y_train,
batch_size=16,
epochs=120,
verbose=2,
callbacks=checkpointer,
validation_data=(X_val, y_val),
shuffle=True
)
dump(history_pm25_LSTM.history, 'history_pm25_LSTM.joblib')
print("El entrenamiento se ha completado y el historial ha sido guardado en 'history_pm25_LSTM.joblib'.")
El archivo 'history_pm25_LSTM.joblib' ya existe. Se ha cargado el historial del entrenamiento.
import re
model_dir = 'keras_models'
files = os.listdir(model_dir)
pattern = r"PRSA_data_PM2.5_LSTM_weights\.(\d+)-([\d\.]+)\.keras"
best_val_loss = float('inf')
best_model_file = None
best_model = None
for file in files:
match = re.match(pattern, file)
if match:
epoch = int(match.group(1))
val_loss = float(match.group(2))
if val_loss < best_val_loss:
best_val_loss = val_loss
best_model_file = file
if best_model_file:
best_model_path = os.path.join(model_dir, best_model_file)
print(f"Cargando el mejor modelo: {best_model_file} con val_loss: {best_val_loss}")
best_model = load_model(best_model_path)
else:
print("No se encontraron archivos de modelos que coincidan con el patrón.")
Cargando el mejor modelo: PRSA_data_PM2.5_LSTM_weights.107-0.0114.keras con val_loss: 0.0114
preds = best_model.predict(X_val)
pred_pm25 = scaler_pm25.inverse_transform(preds)
pred_pm25 = np.squeeze(pred_pm25)
271/271 ━━━━━━━━━━━━━━━━━━━━ 1s 2ms/step
from sklearn.metrics import mean_absolute_error
mae = mean_absolute_error(df_val['pm2.5'].loc[7:], pred_pm25)
print('MAE for the validation set:', round(mae, 4))
MAE for the validation set: 11.3706
Hemos utilizado
keras.callbacks.ModelCheckpointcomo callback para rastrear elMSEdel modelo en el conjunto de validación y guardar los pesos de la epoch que da el mínimo MSE. ElR-cuadradodel mejor modelo para el conjunto de validación es de 0.9959. Los primeros cincuenta valores reales y predichos se muestran en la siguiente figura
plt.figure(figsize=(5.5, 5.5))
plt.plot(range(50), df_val['pm2.5'].loc[7:56], linestyle='-', marker='*', color='r')
plt.plot(range(50), pred_pm25[:50], linestyle='-', marker='.', color='b')
plt.legend(['Actual','Predicted'], loc=2)
plt.title('Actual vs Predicted pm2.5')
plt.ylabel('pm2.5')
plt.xlabel('Index');
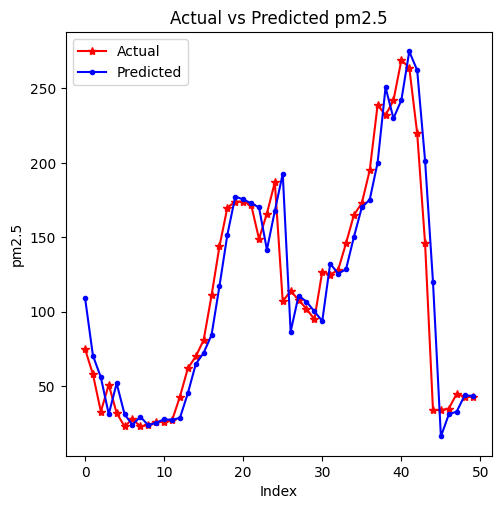
11.22. Autoencoders#
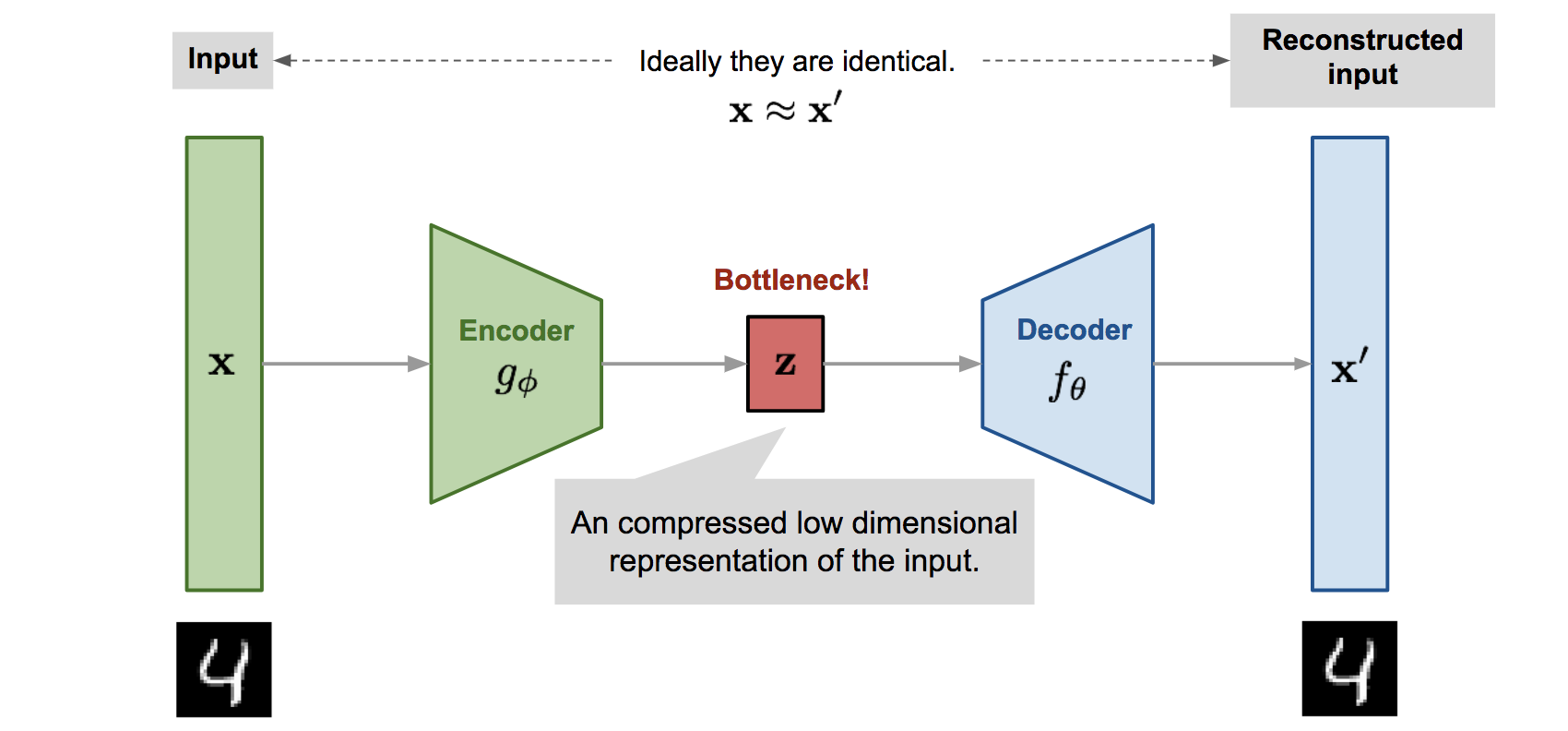
Los autoencoders han sido propuestos como métodos para la reducción de dimensionalidad. Un autoencoder consta de dos partes, el codificador y el decodificador. La salida del
codificador es la representación reducida del patrón de entrada, y se define en términos de una función vectorial\[ \boldsymbol{g}_{\phi}:~\boldsymbol{x}\in\mathbb{R}^{l}\longmapsto\boldsymbol{z}\in\mathbb{R}^{m}, \]donde
\[ z_{i}:=g_{\phi, i}(\boldsymbol{x})=\phi_{e}(\boldsymbol{\theta}_{i}^{T}\boldsymbol{x}+b_{i}),\quad i=1,2,\dots,m, \]con \(\phi_{e}\) función de activación; esta última suele tomarse como la función sigmoidea logística \(\phi_{e}(\cdot)=\sigma(\cdot)\). En otras palabras, el codificador es una red neuronal feed-forward de una sola capa oculta
El
decodificadores otra función \(\boldsymbol{f}_{\theta}\).\[ \boldsymbol{f}_{\theta}:~\boldsymbol{z}\in\mathbb{R}^{m}\longmapsto\boldsymbol{x}'\in\mathbb{R}^{l}, \]donde
\[ \hat{x}_{j}=f_{\theta, j}(\boldsymbol{z})=\phi_{d}(\boldsymbol{\theta}'^{T}\boldsymbol{z}+b_{j}'),\quad j=1,\dots,l. \]La función de activación \(\phi_{d}\) suele ser la identidad (reconstrucción lineal) o la sigmoidea logística.
La tarea de entrenamiento consiste en estimar los parámetros
Es habitual suponer que \(\Theta'=\Theta^{T}\). Los parámetros se estiman para que el error de reconstrucción \(\boldsymbol{e}=\boldsymbol{x}-\boldsymbol{x}'\), sobre las muestras de entrada disponibles sea mínimo. Normalmente, se utiliza el coste por mínimos cuadrados pero también son posibles otras opciones.
Las versiones regularizadas, que implican una norma de los parámetros, también es una posibilidad. Si se elige que la activación \(\phi_{e}\) sea la identidad (representación lineal) y \(m < l\) (para evitar la trivialidad), el autoencoder es equivalente a la técnica PCA.
11.23. Aplicación: Autoencoders para MNIST data#
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense
import warnings
warnings.filterwarnings('ignore')
A continuación
Se cargan los datos del conjunto MNIST, que contiene imágenes de dígitos escritos a mano.
Cada muestra es una imagen en escala de grises de 28×28 píxeles.
Se ignoran las etiquetas de clase (
_) porque el objetivo es reconstruir las imágenes (no clasificarlas), tal como se requiere en tareas de autoencoders.
(x_train, _), (x_test, _) = mnist.load_data()
print("Forma original de x_train:", x_train.shape)
print("Forma original de x_test:", x_test.shape)
Forma original de x_train: (60000, 28, 28)
Forma original de x_test: (10000, 28, 28)
Se normalizan los valores de los píxeles de las imágenes, originalmente en el rango [0, 255], para que estén en el intervalo [0, 1]. La normalización facilita el entrenamiento del modelo al mejorar la estabilidad numérica y acelerar la convergencia del optimizador. Se convierte el tipo de dato a
float32para asegurar compatibilidad con las operaciones enTensorFlow/Keras.
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
Cada imagen del conjunto de datos MNIST tiene dimensiones 28×28, es decir, 784 píxeles. Estas imágenes se transforman en vectores unidimensionales de 784 elementos para que puedan ser procesadas por capas densas (
Dense) del autoencoder. Esta transformación no altera la información de la imagen, solo su forma (reshape) para adaptarse a la entrada del modelo.
x_train = x_train.reshape((len(x_train), 784))
x_test = x_test.reshape((len(x_test), 784))
print("Forma después del reshape de x_train:", x_train.shape)
print("Forma después del reshape de x_test:", x_test.shape)
Forma después del reshape de x_train: (60000, 784)
Forma después del reshape de x_test: (10000, 784)
input_img = Input(shape=(784,)):
Se define la capa de entrada del modelo, correspondiente a una imagen aplanada de 784 píxeles.encoded = Dense(32, activation='relu')(input_img):
Esta capa es el codificador, que transforma la imagen de entrada en una representación latente de 32 dimensiones utilizando una función de activación ReLU.decoded = Dense(784, activation='sigmoid')(encoded):
Esta capa actúa como decodificador, intentando reconstruir la imagen original a partir de la representación latente.sigmoidse adapta bien cuando se usa la función de pérdidabinary_crossentropy, ya que esa pérdida espera que la salida esté entre 0 y 1. Asegura que los valores de salida no sean negativos ni mayores a 1, lo que tendría poco sentido en términos de imágenes normalizadas.autoencoder = Model(input_img, decoded):
Se define el modelo completo del autoencoder, que aprende a mapear una imagen a su reconstrucción.
input_img = Input(shape=(784,))
encoded = Dense(32, activation='relu')(input_img)
decoded = Dense(784, activation='sigmoid')(encoded)
autoencoder = Model(input_img, decoded)
autoencoder.compile(...):
Se compila el modelo autoencoder, especificando el optimizador y la función de pérdida.optimizer='adam':
Se utiliza el optimizador Adam, ampliamente usado en redes neuronales por su eficiencia y capacidad de adaptación del aprendizaje.loss='binary_crossentropy':
Se emplea la entropía cruzada binaria como función de pérdida, apropiada en tareas de reconstrucción donde los valores de salida están en el rango [0, 1].
autoencoder.compile(optimizer='adam', loss='binary_crossentropy')
autoencoder.fit(...):
Entrena el modelo autoencoder utilizando como entrada y objetivo los mismos datos, dado que la tarea es de reconstrucción.x_train, x_train:
Se entrena el modelo para que aprenda a reproducir su entrada como salida.epochs=50:
El entrenamiento se realiza durante 50 épocas completas sobre el conjunto de datos.batch_size=256:
El tamaño del mini-batch para cada actualización de parámetros es de 256 muestras.shuffle=True:
Se mezclan aleatoriamente las muestras en cada época para mejorar la generalización.validation_data=(x_test, x_test):
Se utiliza el conjunto de prueba para evaluar la pérdida de validación y así monitorear el sobreajuste.
autoencoder.fit(x_train, x_train,
epochs=50,
batch_size=256,
shuffle=True,
validation_data=(x_test, x_test))
Epoch 1/50
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1762262123.911098 3197 service.cc:146] XLA service 0x5c15adeb5240 initialized for platform CUDA (this does not guarantee that XLA will be used). Devices:
I0000 00:00:1762262123.911161 3197 service.cc:154] StreamExecutor device (0): NVIDIA GeForce RTX 4070, Compute Capability 8.9
2025-11-04 08:15:23.983188: I tensorflow/compiler/mlir/tensorflow/utils/dump_mlir_util.cc:268] disabling MLIR crash reproducer, set env var `MLIR_CRASH_REPRODUCER_DIRECTORY` to enable.
138/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.4416
I0000 00:00:1762262125.412862 3197 device_compiler.h:188] Compiled cluster using XLA! This line is logged at most once for the lifetime of the process.
235/235 ━━━━━━━━━━━━━━━━━━━━ 3s 7ms/step - loss: 0.3807 - val_loss: 0.1879
Epoch 2/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.1794 - val_loss: 0.1553
Epoch 3/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.1507 - val_loss: 0.1347
Epoch 4/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.1323 - val_loss: 0.1221
Epoch 5/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.1210 - val_loss: 0.1133
Epoch 6/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.1131 - val_loss: 0.1070
Epoch 7/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.1069 - val_loss: 0.1024
Epoch 8/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.1027 - val_loss: 0.0991
Epoch 9/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0998 - val_loss: 0.0969
Epoch 10/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - loss: 0.0977 - val_loss: 0.0954
Epoch 11/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - loss: 0.0962 - val_loss: 0.0944
Epoch 12/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0956 - val_loss: 0.0937
Epoch 13/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0948 - val_loss: 0.0934
Epoch 14/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - loss: 0.0944 - val_loss: 0.0931
Epoch 15/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - loss: 0.0943 - val_loss: 0.0927
Epoch 16/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0941 - val_loss: 0.0926
Epoch 17/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0934 - val_loss: 0.0925
Epoch 18/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0937 - val_loss: 0.0923
Epoch 19/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0935 - val_loss: 0.0922
Epoch 20/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - loss: 0.0933 - val_loss: 0.0922
Epoch 21/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - loss: 0.0932 - val_loss: 0.0920
Epoch 22/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0934 - val_loss: 0.0921
Epoch 23/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0932 - val_loss: 0.0919
Epoch 24/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0929 - val_loss: 0.0919
Epoch 25/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0930 - val_loss: 0.0919
Epoch 26/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0929 - val_loss: 0.0918
Epoch 27/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0928 - val_loss: 0.0918
Epoch 28/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0930 - val_loss: 0.0918
Epoch 29/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0928 - val_loss: 0.0917
Epoch 30/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0930 - val_loss: 0.0918
Epoch 31/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0929 - val_loss: 0.0916
Epoch 32/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0929 - val_loss: 0.0916
Epoch 33/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0927 - val_loss: 0.0916
Epoch 34/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0929 - val_loss: 0.0916
Epoch 35/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0924 - val_loss: 0.0916
Epoch 36/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0926 - val_loss: 0.0917
Epoch 37/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0927 - val_loss: 0.0916
Epoch 38/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0929 - val_loss: 0.0917
Epoch 39/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0928 - val_loss: 0.0915
Epoch 40/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0928 - val_loss: 0.0915
Epoch 41/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0927 - val_loss: 0.0916
Epoch 42/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0926 - val_loss: 0.0915
Epoch 43/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0925 - val_loss: 0.0915
Epoch 44/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0926 - val_loss: 0.0915
Epoch 45/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step - loss: 0.0925 - val_loss: 0.0915
Epoch 46/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0926 - val_loss: 0.0915
Epoch 47/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0927 - val_loss: 0.0914
Epoch 48/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0927 - val_loss: 0.0915
Epoch 49/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0927 - val_loss: 0.0915
Epoch 50/50
235/235 ━━━━━━━━━━━━━━━━━━━━ 0s 1ms/step - loss: 0.0927 - val_loss: 0.0915
<keras.src.callbacks.history.History at 0x7061501df2b0>
Define el modelo encoder que transforma una imagen de entrada (784 dimensiones) en su representación latente de 32 dimensiones. Este modelo extrae la parte de codificación del autoencoder original.
Crea un nuevo modelo decoder tomando como entrada una representación latente de 32 dimensiones y aplicando la última capa del autoencoder (la capa de decodificación). Esto permite reconstruir imágenes directamente desde sus representaciones codificadas, de forma independiente.
autoencoder.layers[-1]accede a la última capa del modelo autoencoder (elDense(784, activation='sigmoid'))
encoder = Model(input_img, encoded)
encoded_input = Input(shape=(32,))
decoder_layer = autoencoder.layers[-1]
decoder = Model(encoded_input, decoder_layer(encoded_input))
Codifica las imágenes de prueba transformándolas desde el espacio original (784 dimensiones) al espacio latente (64 dimensiones) mediante el modelo
encoder.Reconstruye las imágenes a partir de sus representaciones latentes usando el modelo
decoder.Este paso permite evaluar qué tan bien el autoencoder logra aproximar las imágenes originales.
encoded_imgs = encoder.predict(x_test)
decoded_imgs = decoder.predict(encoded_imgs)
313/313 ━━━━━━━━━━━━━━━━━━━━ 0s 821us/step
313/313 ━━━━━━━━━━━━━━━━━━━━ 0s 711us/step
Selecciona 10 imágenes del conjunto de prueba y configura el tamaño de la figura para mostrar una comparación clara entre las imágenes originales y sus reconstrucciones.
Primera fila: imágenes originales. Se toma la \(i\)-ésima imagen original, se remodela a su forma 2D (28×28) y se muestra en escala de grises sin ejes para mayor claridad.
Segunda fila: imágenes reconstruidas. Se visualiza la imagen generada por el autoencoder a partir de la codificación latente.
n = 10
plt.figure(figsize=(20, 4))
for i in range(n):
ax = plt.subplot(2, n, i + 1)
plt.imshow(x_test[i].reshape(28, 28), cmap="gray")
plt.axis('off')
ax = plt.subplot(2, n, i + 1 + n)
plt.imshow(decoded_imgs[i].reshape(28, 28), cmap="gray")
plt.axis('off')
plt.show()
Reconstrucción de imágenes
Se utiliza el modelo entrenado para generar reconstrucciones del conjunto de prueba, es decir, aproximaciones de las imágenes originales.Cálculo del Error Cuadrático Medio (MSE)
Se calcula el error cuadrático medio entre las imágenes originales y sus reconstrucciones. Este valor indica qué tan lejos están, en promedio, las imágenes reconstruidas de las originales.Estimación de la varianza total
Se computa la varianza de los datos originales del conjunto de prueba. Representa la cantidad total de información (variabilidad) presente en los datos sin comprimir.Cálculo de la variabilidad explicada
Se emplea la fórmula:\[ \text{Variabilidad explicada} = 1 - \frac{\text{MSE}}{\text{Varianza total}} \]Esta expresión indica qué fracción de la variación total en los datos originales ha sido retenida por el modelo de autoencoder. Es una métrica análoga al coeficiente de determinación (\(R^2\)) utilizado en modelos de regresión.
Interpretación del resultado
Un valor cercano a 1 sugiere que el autoencoder captura gran parte de la estructura de los datos. Un valor bajo indica que el modelo no ha logrado representar eficazmente la información original.
import numpy as np
decoded_imgs = autoencoder.predict(x_test)
mse = np.mean(np.square(x_test - decoded_imgs))
var_total = np.var(x_test)
var_explicada = 1 - (mse / var_total)
print("Variabilidad explicada por el autoencoder:", var_explicada)
313/313 ━━━━━━━━━━━━━━━━━━━━ 1s 935us/step
Variabilidad explicada por el autoencoder: 0.9004852250218391
En un autoencoder, el número de neuronas en la capa latente (bottleneck layer) representa la dimensión comprimida o el número de “componentes” aprendidos. Aunque no son componentes lineales como en PCA, son equivalentes en el sentido de que capturan una representación reducida de los datos. Por ejemplo, en el modelo:
encoded = Dense(32, activation='relu')(input_img)
Aquí el autoencoder utiliza 32 dimensiones latentes, lo que se puede comparar directamente con las 32 primeras componentes principales en PCA.
¿Cómo hacer una comparación justa con PCA?
Entrena un PCA con el mismo número de componentes:
from sklearn.decomposition import PCA pca = PCA(n_components=32) X_pca = pca.fit_transform(x_test) X_reconstructed = pca.inverse_transform(X_pca)
Calcula el MSE y la variabilidad explicada del PCA, de la misma forma que hiciste con el autoencoder:
mse_pca = np.mean(np.square(x_test - X_reconstructed)) var_total = np.var(x_test) var_explicada_pca = 1 - (mse_pca / var_total)
Compara valores:
Variabilidad explicada por el Autoencoder
Variabilidad explicada por el PCA
Esto te dirá cuál técnica preserva mejor la estructura de los datos bajo la misma cantidad de compresión (32 dimensiones, por ejemplo).
from sklearn.decomposition import PCA
pca = PCA(n_components=32)
X_pca = pca.fit_transform(x_test)
X_reconstructed = pca.inverse_transform(X_pca)
mse_pca = np.mean(np.square(x_test - X_reconstructed))
var_total = np.var(x_test)
var_explicada_pca = 1 - (mse_pca / var_total)
print("Variabilidad explicada por el PCA:", var_explicada_pca)
Variabilidad explicada por el PCA: 0.8270165622234344
11.24. Attention#
Introducción
Base Neurocientífica y Psicológica
En lectura humana, no procesamos cada palabra linealmente; nuestro cerebro focaliza atención en elementos relevantes según contexto y significado.
En NLP, esto se traduce en pesos de atención (\(\alpha\)) aplicados a los estados del encoder para generar un vector de contexto (\(c_t\)) que condicione la predicción del decoder.
Problema de los Encoder-Decoder clásicos. El modelo secuencial clásico codifica toda la información en un vector fijo \(v\):
\[ P(y_1, ..., y_T \mid x_1, ..., x_S) = \prod_{t=1}^T P(y_t \mid v, y_1, ..., y_{t-1}) \]\(v\) es un vector de contexto fijo → cuello de botella informativo. Es un vector de dimensión fija que intenta resumir toda la información relevante de la secuencia de entrada.
\(P(y_1, \ldots, y_T \mid x_1, \ldots, x_S)\): Representa la probabilidad total de generar toda la secuencia de salida (por ejemplo, en inglés) condicionada a la secuencia completa de entrada (por ejemplo, en español).
\(\prod_{t=1}^T\): Indica que el modelo genera los tokens uno por uno, siguiendo un proceso autoregresivo. Cada paso (\(t\)) depende de los tokens previos (\(y_1, \ldots, y_{t-1}\)).
\(P(y_t \mid v, y_1, \ldots, y_{t-1})\): Es la probabilidad de generar el token actual (\(y_t\)), dado:
El vector de contexto fijo (\(v\)), que proviene del encoder.
La historia previa de tokens ya generados por el decoder.
Contexto: Modelo Encoder-Decoder: ¿Qué hace cada parte?
1. Encoder:
Recibe la secuencia de entrada, por ejemplo una frase en español:
\[ X = [x_1, x_2, x_3, x_4] = [\text{"El", "gato", "negro", "duerme"}] \]La procesa paso a paso y genera hidden states (representaciones vectoriales de cada palabra):
\[ h_1, h_2, h_3, h_4 \]Cada \(h_i\) captura información del token \(x_i\) y del contexto de la secuencia (dependiendo de si usamos RNN, LSTM, GRU, etc.).
2. Decoder:
Genera la secuencia de salida (por ejemplo en inglés):
\[ Y = [y_1, y_2, y_3] = [\text{"The", "black", "cat"}] \]Lo hace token por token, usando:
El hidden state anterior del decoder.
Un vector de contexto \(v\) que representa la información de toda la entrada.
El token “duerme” se procesó dentro del encoder → generó un hidden state \(h_4\). Sin embargo, en el modelo Encoder-Decoder tradicional, el decoder no tiene acceso directo a \(h_4\) (ni a \(h_1, h_2, h_3\)). Solo recibe el vector \(v\), que resume todo en una representación fija.
Por tanto, el “significado” de duerme queda mezclado con el resto de la información en ese vector. Si el vector \(v\) no logra codificar bien la acción, el modelo olvida traducir “duerme” → “sleeps”.
Vector de contexto \(v\) en modelos Encoder–Decoder: ¿Qué es realmente \(v\)?. El vector \(v\) se define como una representación vectorial de dimensión fija que resume la información contenida en toda la secuencia de entrada.
Sea una secuencia de entrada
\[ X = (x_1, x_2, \dots, x_T) \]y supóngase que el encoder genera una sucesión de estados ocultos:
\[ h_1, h_2, \dots, h_T \]Entonces, el vector de contexto puede expresarse de forma general como:
\[ v = \phi(h_1, h_2, \dots, h_T) \]donde \(\phi(\cdot)\) es una función de agregación o selección y \(v \in \mathbb{R}^d\) es un vector de dimensión fija
En el modelo encoder–decoder clásico (sin atención), esta función adopta una forma particularmente simple.
¿Cómo se calcula \(v\)?: En arquitecturas secuenciales como RNN, LSTM o GRU, el cálculo de \(v\) se basa en la dinámica recursiva del modelo.
Caso estándar (sin mecanismo de atención):
\[ v = h_T \]Es decir, el vector de contexto corresponde al último estado oculto del encoder.
El estado oculto en una red recurrente se define mediante la relación:
\[ h_t = f(x_t, h_{t-1}) \]donde:
\(x_t\): embedding del token en la posición \(t\)
\(h_{t-1}\): estado oculto previo
\(f(\cdot)\): función no lineal (por ejemplo, una celda LSTM o GRU)
Desarrollo recursivo:
Por lo tanto, existe una función compuesta \(g(\cdot)\) tal que:
Esto implica:
El estado oculto final satisface:
Por lo tanto, depende funcionalmente de toda la secuencia de entrada, lo que justifica su uso como representación global:
Precisión conceptual:
\(h_T\) es un vector de dimensión fija
la secuencia puede ser arbitrariamente larga
Por lo tanto, el modelo realiza una compresión de información:
Limitaciones
Si la frase de entrada es larga, \(v\) no puede contener toda la información.
Esto se llama cuello de botella, porque el decoder “ve” toda la entrada a través de un solo vector.
Como resultado, la traducción o la predicción pierde información, especialmente en frases largas.
Analogía sencilla
Imagina que tienes que resumir un libro de 200 páginas en una sola oración y luego alguien tiene que escribir un resumen basado solo en esa oración.
Obviamente, perderías mucho detalle importante.
En el modelo clásico Encoder-Decoder sin atención, eso es exactamente lo que pasa: toda la secuencia de entrada se comprime en un solo vector \(v\).
Bahdanau Attention (Additive). La atención de Bahdanau et al. (2015) solucionó el problema de cuello de botella permitiendo que, en cada paso del decoder, el modelo “mire” directamente a los estados del encoder relevantes. Así nace el concepto de pesos de atención y contexto dinámico (\(c_t\)): el decoder ya no memoriza todo, sino que selecciona lo importante en cada momento.Score de atención (alineamiento)
\[ e_{tj} = v_a^\top \tanh(W_a s_{t-1} + U_a h_j) \]Donde:
\(s_{t-1}\): estado anterior del decoder “hidden state” (usualmente una LSTM o GRU). Aquí, el índice \(t\) recorre la secuencia de salida (decoder).
\(h_j\): \(j\)-ésimo estado del encoder (generalmente una Bi-LSTM o Bi-GRU).
\(W_a, U_a\): matrices de pesos entrenables
\(v_a\): vector de pesos entrenable
Pesos de atención normalizados
\[ \alpha_{tj} = \frac{\exp(e_{tj})}{\sum_{k=1}^S \exp(e_{tk})} \]Vector de contexto dinámico
\[ c_t = \sum_{j=1}^S \alpha_{tj} h_j \]En otras palabras:
Cada \(h_j\) es una codificación contextual de la palabra \(x_j\). No es la palabra en sí, sino su representación en el espacio latente del encoder.
Cada \(s_{t-1}\) es una codificación del estado de generación del decoder en el tiempo \(t-1\). Resume lo que el modelo “sabe” del texto ya producido y lo que espera producir ahora.
El vector de contexto \(c_t\)
Resume la información relevante de la entrada en el paso actual del decoder.
Se recalcula en cada paso de generación.
Permite que el modelo “mire” directamente partes específicas de la secuencia de entrada, en lugar de depender de una sola representación comprimida.
Por diseño clásico (Bahdanau et al., 2015, Neural Machine Translation by Jointly Learning to Align and Translate):
Encoder: Una RNN bidireccional (generalmente una Bi-LSTM o Bi-GRU). Produce una secuencia de hidden states:
\[ h_1, h_2, \dots, h_S \in \mathbb{R}^{d_h} \]Cada \(h_j\) es la concatenación de los estados forward y backward.
Decoder: Una RNN unidireccional (usualmente una LSTM o GRU). En cada paso \(t\), produce un nuevo estado:
\[ s_t = \text{RNNCell}(s_{t-1}, [y_{t-1}, c_t]) \]donde \(y_{t-1}\) es el embedding del token previo, y \(c_t\) es el vector de contexto dinámico que viene de la atención.
Generación del token de salida. A partir del estado oculto del decoder \(s_t\), y el contexto de atención \(c_{t}\), calculamos qué tan probable es cada palabra del vocabulario (siguiente token \(y_t\))
\[ p(y_t \mid y_{<t}, X) = \text{softmax}(W_o [s_t, c_t]) \]donde:
\(W_o \in \mathbb{R}^{|V| \times (d_s + d_c)}\) es una matriz de pesos entrenable,
\([s_t, c_t]\) es la concatenación del estado oculto y el vector de contexto,
\(|V|\) es el tamaño del vocabulario.
El token de salida se obtiene como:
\[\begin{split} y_t = \begin{cases} \arg\max p(y_t \mid y_{<t}, X), & \text{(inferencia)} \\ \text{sample}\big(p(y_t \mid y_{<t}, X)\big), & \text{(teacher forcing)} \end{cases} \end{split}\]
En este caso, \(\arg\max\) selecciona la palabra con mayor probabilidad y sampling selecciona una palabra aleatoriamente según las probabilidades aprendidas. En la práctica:
Durante el entrenamiento normalmente se utiliza teacher forcing.
Durante inferencia suele emplearse:
\[ y_t = \arg\max p(y_t \mid y_{<t}, X) \]
En teacher forcing, el decoder recibe las palabras reales para aprender. Por eso durante el entrenamiento sí conocemos los \(y_t\) verdaderos (supervisado).
El espacio latente es el espacio vectorial en el que viven los estados ocultos (\(h_j\), \(s_t\)) y el vector de contexto (\(c_t\)). Es decir, todos estos vectores están en la misma dimensión semántica (por ejemplo, \(\mathbb{R}^{512}\)).
Fig. 11.46 Fuente: Bahdanau et al. (2015), Neural Machine Translation by Jointly Learning to Align and Translate.#
Pseudocódigo Python:
scores = tanh(W_a @ s_prev + U_a @ encoder_outputs) # shape (seq_len,)
attention_weights = softmax(scores) # shape (seq_len,)
context_vector = sum(attention_weights * encoder_outputs)
Interpretación:
Linealizamos \(h_j\) y \(s_{t-1}\) con \(W_a\) y \(U_a\).
Aplicamos \(\tanh\) para no linealidades.
Multiplicamos por \(v_a^\top\) para obtener un escalar de relevancia.
Softmax transforma scores en distribución de atención.
Observación
La atención de Bahdanau soluciona el cuello de botella del encoder-decoder clásico porque ya no usa un único vector fijo para representar toda la entrada. En su lugar, el decoder calcula en cada paso un vector de contexto \(c_t\) como una combinación ponderada de los estados del encoder (\(h_j\)). Así, el modelo “enfoca su atención” dinámicamente en las partes más relevantes de la secuencia al generar cada palabra.
Ejemplo intuitivo: Bahdanau Attention
Imagina que queremos traducir esta oración del español al inglés
Entrada (X): “El gato negro duerme”
Salida (Y): “The black cat sleeps”
Encoder: procesa toda la frase
El encoder (por ejemplo, una Bi-LSTM) recorre la frase palabra por palabra y genera una representación vectorial (hidden state) para cada token.
Palabra |
Representación oculta (\(h_j\)) |
Intuición |
|---|---|---|
El |
\(h_1\) |
Entiende que es un artículo |
gato |
\(h_2\) |
Entiende que es un sustantivo, sujeto |
negro |
\(h_3\) |
Adjetivo que describe “gato” |
duerme |
\(h_4\) |
Verbo, acción principal |
Al final, el encoder produce una secuencia de vectores
Cada \(h_j\) contiene información contextual sobre su palabra y las palabras vecinas (dependiendo del tipo de RNN utilizada).
Decoder: genera la salida palabra por palabra
El decoder (una RNN unidireccional) produce la traducción una palabra a la vez.
En el paso \(t = 1\). Desea generar la primera palabra de la salida:
“The”
Para hacerlo, el decoder usa su estado anterior \(s_{t-1}\) (inicialmente \(s_0\)) y “mira” los estados del encoder (\(h_1, h_2, h_3, h_4\)) para determinar qué partes de la entrada son más relevantes.
La ecuación de alineamiento (score) es
Cada \(e_{tj}\) mide la relevancia del token de entrada \(x_j\) respecto al estado del decoder en el paso \(t\). El término \(v_a^{\top}\) es clave para transformar un vector de compatibilidad en un valor escalar de atención.
\(v_a\) es un vector entrenable que aprende cómo medir la relevancia entre el estado del decoder \(s_{t-1}\) y el estado del encoder \(h_j\).
La operación \(v_a^\top(\cdot)\) proyecta el resultado del tanh (un vector) en un único número \(e_{tj}\), que representa cuánto debe atender el modelo al token \(j\) al generar la palabra en el paso \(t\).
En otras palabras, \(v_a^{\top}\) convierte una relación compleja entre vectores en una medida de atención interpretable.
Softmax: conversión en pesos de atención
Los valores \(e_{tj}\) se normalizan con una función softmax para producir una distribución de atención:
Los \(\alpha_{tj}\) representan cuánto “atiende” el modelo a cada palabra del encoder.
Ejemplo numérico simplificado
Palabra del encoder |
Score bruto \(e_{tj}\) |
Peso de atención \(\alpha_{tj}\) |
|---|---|---|
El |
1.8 |
0.50 |
gato |
1.4 |
0.30 |
negro |
0.7 |
0.15 |
duerme |
0.2 |
0.05 |
En este caso, el modelo se enfoca principalmente en “El” (50%) y “gato” (30%) para generar “The”.
Cálculo del vector de contexto dinámico
A partir de los pesos de atención, se obtiene el vector de contexto \(c_t\) como una combinación ponderada de los hidden states del encoder:
Por ejemplo
El vector \(c_t\) resume la información más relevante de la entrada en ese paso, en este caso “El gato”.
Generación del token de salida
El decoder usa el contexto \(c_t\) junto con su estado actual \(s_t\) para predecir la siguiente palabra mediante una capa softmax:
De donde se obtiene
Generación de la siguiente palabra (“black”)
En el siguiente paso (\(t=2\)), el decoder actualiza su estado \(s_1\) y repite el proceso de atención. Los nuevos pesos \(\alpha_{2j}\) podrían ser:
Palabra |
Peso \(\alpha_{2j}\) |
|---|---|
El |
0.10 |
gato |
0.25 |
negro |
0.60 |
duerme |
0.05 |
Ahora el modelo enfoca más atención en “negro” y genera la palabra “black”.
Generación de “cat”
Palabra |
Peso \(\alpha_{3j}\) |
|---|---|
El |
0.05 |
gato |
0.70 |
negro |
0.20 |
duerme |
0.05 |
El modelo se centra en “gato” y produce la palabra “cat”.
Generación de “sleeps”
Palabra |
Peso \(\alpha_{4j}\) |
|---|---|
El |
0.05 |
gato |
0.10 |
negro |
0.05 |
duerme |
0.80 |
El modelo atiende principalmente a “duerme” y genera “sleeps”.
Conclusión intuitiva
En lugar de resumir toda la oración en un solo vector fijo \(v\), el modelo calcula un nuevo vector de contexto \(c_t\) en cada paso \(t\).
Este vector \(c_t\) cambia dinámicamente según la palabra que el decoder está generando.
De esta manera, la atención elimina el cuello de botella del modelo clásico, permitiendo al decoder acceder directamente a las partes más relevantes de la entrada.
Atención Luong (Multiplicativa)La atención multiplicativa fue propuesta por Luong et al. (2015) en “Effective Approaches to Attention-based Neural Machine Translation”. Surgió como una mejora computacional sobre la atención aditiva de Bahdanau, buscando simplificar el cálculo del alineamiento y aumentar la eficiencia.
El objetivo es medir qué tan bien se alinean el estado actual del decoder (\(s_t\)) y los estados del encoder (\(h_j\)). Para ello, se define una función de score que cuantifica la similitud entre ambos.
Interpretación geométrica
Caso “dot” (producto punto simple): El score es proporcional al coseno del ángulo entre \(s_t\) y \(h_j\)
\[ \text{score}(s_t, h_j) = \|s_t\|\|h_j\| \cos(\theta) \]Si los vectores apuntan en la misma dirección (\(\theta \approx 0\)), la atención es alta. Esto equivale a una medida de similitud geométrica en el espacio latente.
Caso “general”:
El producto punto se realiza tras aplicar una transformación lineal \(W_a\) a \(h_j\). Esto permite que el modelo aprenda una métrica de similitud no isotrópica, es decir, que ciertas dimensiones tengan más relevancia que otras
\[ \text{score}(s_t, h_j) = s_t^\top W_a h_j \]
Ejemplo: Supongamos que el estado del encoder está representado por el vector
El modelo aprende que la información semántica es mucho más importante para el alineamiento. Entonces, la matriz de atención puede aprender pesos como
Aplicando la transformación lineal:
La primera dimensión domina el cálculo del score, indicando que el modelo considera la componente semántica como la más relevante para el mecanismo de atención.
Caso “concat”: Similar a Bahdanau, pero en lugar de sumar, se concatenan los vectores
\[ \text{score}(s_t, h_j) = v_a^\top \tanh(W_a [s_t; h_j]) \]Este caso mezcla información multiplicativa y aditiva, pero es más costoso. En lugar de medir similitud geométrica directamente, el modelo aprende una función no lineal que decide cuánto se parecen \(s_t\) y \(h_j\).
Cálculo de pesos de atención y vector de contexto. El score se normaliza mediante softmax para obtener los pesos de atención:
\[ \alpha_{tj} = \frac{\exp(\text{score}(s_t, h_j))}{\sum_{k=1}^S \exp(\text{score}(s_t, h_k))} \]De esta forma
\(\alpha_{tj} \in [0,1]\)
\(\sum_j \alpha_{tj} = 1\)
El vector de contexto se obtiene como la combinación ponderada de los estados del encoder
\[ c_t = \sum_{j=1}^S \alpha_{tj} h_j \]Derivación: relación con Bahdanau
En Bahdanau
\[ e_{tj} = v_a^\top \tanh(W_a s_{t-1} + U_a h_j) \]Dos transformaciones lineales + activación no lineal.
Requiere multiplicaciones adicionales y más parámetros.
En Luong
\[ e_{tj} = s_t^\top W_a h_j \]Solo una multiplicación de matrices.
Sin activación \(\tanh\), lo que reduce el costo de cómputo.
Ideal para modelos con grandes secuencias o vocabularios.
Por tanto, Luong es una forma bilineal de Bahdanau
\[ e_{tj}^{\text{Luong}} = s_t^\top W_a h_j \quad \approx \quad v_a^\top \tanh(W_a s_t + U_a h_j) \]en el caso linealizado de \(\tanh\) (cercano a la identidad para pequeñas entradas).
Pseudocódigo Python
# s_t: hidden state del decoder (1 x d)
# encoder_outputs: matriz de hidden states (S x d)
scores = s_t @ encoder_outputs.T # Producto punto (dot)
attention_weights = softmax(scores) # Normalización
context_vector = attention_weights @ encoder_outputs
Versión “general” (con matriz de pesos \(W_a\)):
scores = (s_t @ W_a) @ encoder_outputs.T
attention_weights = softmax(scores)
context_vector = attention_weights @ encoder_outputs
Interpretación geométrica
La atención de Luong puede interpretarse como una proyección bilineal entre los subespacios del encoder y el decoder.
El término \(s_t^\top W_a h_j\) define una forma cuadrática, que mide la compatibilidad entre ambas representaciones.
En el espacio latente \(\mathbb{R}^{d}\), \(W_a\) actúa como una métrica aprendible: el modelo aprende qué direcciones (dimensiones) son relevantes para el alineamiento lingüístico.
Comparación
Característica |
Bahdanau (Additive) |
Luong (Multiplicative) |
|---|---|---|
Tipo de operación |
Suma + \(\tanh\) |
Producto punto (bilineal) |
Complejidad |
\(O(d^2)\) |
\(O(d)\) |
Parámetros adicionales |
\(W_a, U_a, v_a\) |
\(W_a\) (a veces ninguno) |
Interpretación |
Similaridad no lineal |
Similaridad geométrica |
Rendimiento |
Preciso, pero más lento |
Más rápido, especialmente en GPU |
Ideal para |
Traducciones cortas o ricas en sintaxis |
Secuencias largas, alta eficiencia |
Conclusión
La atención de Luong representa una generalización más eficiente de Bahdanau.
En lugar de aprender una función compleja de similitud, aprende una métrica bilineal que captura la compatibilidad entre los espacios del encoder y el decoder.
Su base matemática en el producto punto y la forma cuadrática hace que sea más interpretable desde el punto de vista del análisis lineal y más fácil de optimizar en práctica.
11.25. Self-Attention#
Self-Attention (atención escalada): mecanismo que permite que cada token de una secuencia “atienda” a los demás para construir representaciones contextualizadas.
Variables principales
\(n\): longitud de la secuencia (número de tokens).
\(d_{\text{model}}\): dimensión del embedding de entrada.
\(d_k\): dimensión para queries y keys.
\(d_v\): dimensión para values.
\(x_i \in \mathbb{R}^{d_{\text{model}}}\): embedding del token en la posición \(i\).
\(W_Q, W_K, W_V\): matrices aprendibles para generar \(Q\), \(K\) y \(V\).
Entrada a la capa
\[\begin{split} X = \begin{bmatrix} x_1 \\ x_2 \\ \vdots \\ x_n \end{bmatrix} \in \mathbb{R}^{n \times d_{\text{model}}} \end{split}\]Proyecciones lineales aprendibles
\[ Q = X W_Q,\qquad K = X W_K,\qquad V = X W_V \]\(Q \in \mathbb{R}^{n \times d_k}\): query (lo que el token busca entre otros).
\(K \in \mathbb{R}^{n \times d_k}\): key (información que ofrece a los demás).
\(V \in \mathbb{R}^{n \times d_v}\): value (contenido propagado realmente).
Para cada posición
\[ q_i = W_Q^\top x_i,\qquad k_j = W_K^\top x_j,\qquad v_j = W_V^\top x_j \]Cálculo del self-attention escalado
\[ \mathrm{Attention}(Q,K,V) = \mathrm{softmax}\!\left(\frac{QK^\top}{\sqrt{d_k}}\right)V \]Matriz de scores (similaridad query–key)
\[ S = \frac{QK^\top}{\sqrt{d_k}} \in \mathbb{R}^{n \times n} \]Para cada palabra, el mecanismo de atención evalúa:
¿Qué tan relevantes son las demás palabras para comprender mi contexto?
Por ejemplo, en la oración
El gato negro duerme
cuando el modelo procesa la palabra “duerme”, el vector query asociado tenderá a ser similar al vector key de “gato”, ya que esta palabra aporta información importante sobre quién realiza la acción. En consecuencia, el producto punto entre ambos vectores será alto, generando un peso de atención elevado.
Pesos de atención (normalizados por filas). Contiene: pesos, importancia, relevancia. Pero NO contiene contenido semántico.
\[ A = \mathrm{softmax}(S) \]Salida contextuada para toda la secuencia. El contenido real se encuentra en \(V\). Los values contienen la información que será propagada.
\[ Y = A V \in \mathbb{R}^{n \times d_v} \]Interpretación token a token
\[ y_i = \sum_{j=1}^n A_{ij}\, v_j \]La fila \(A_{i,:}\) indica cuánto “atiende” el token \(i\) al token \(j\).
Ambos Luong y Sefl-Attention buscan medir qué tan relevante es un token respecto a otro, pero
Self-Attention lo hace en paralelo y con proyecciones lineales entrenables.
Motivo para proyectar a \(Q,K,V\)
Permite aprender una métrica de similitud.
Separa roles semánticos:
Query → lo que el token busca.
Key → lo que el token representa.
Value → la información propagada posteriormente.
Reduce costo al no operar directamente sobre \(d_{\text{model}}\).
Escalado por \(1/\sqrt{d_k}\)
Sin escalado, los valores de \(QK^\top\) crecen con \(d_k\).
La softmax se satura y los gradientes se debilitan.
El escalado mantiene valores estables durante entrenamiento.
Complejidad computacional
Cálculo de \(Q,K,V\): \(O(n d_{\text{model}} d_k)\)
Producto \(QK^\top\): \(O(n^2 d_k)\)
Multiplicación \(AV\): \(O(n^2 d_v)\)
Tiempo total: \(O(n^2 d)\)
Memoria: \(O(n^2)\) por la matriz de atención
Implicación práctica
Para secuencias largas, esta complejidad motiva atenciones eficientes como Linformer, Longformer, BigBird y Flash Attention.
Relación con Bahdanau / Luong y ventajas conceptuales
Bahdanau (aditivo) usa una función no lineal que compara \(s\) y \(h_j\) tras dos proyecciones y una \(\tanh\). Es flexible, pero más pesado computacionalmente. Luong es bilineal (\(s^\top W h\)).
Self-attention se corresponde con aplicar una versión de Luong entre todas las posiciones de la misma secuencia: todas las posiciones actúan a la vez como queries y keys. Además, multi-head attention permite que diferentes \(W_Q^i,W_K^i,W_V^i\) aprendan diversas métricas simultáneamente.
Complejidad computacional y memoria
Para una secuencia de longitud \(n\) y dimensión \(d\) (tomando \(d_k\sim d\)):
Cálculo de \(Q,K,V\): \(O(n d d_k)\) trivialmente \(O(n d^2)\) si \(d_k\approx d\).
Cálculo de \(S = Q K^\top\): \(O(n^2 d_k)\).
Softmax y multiplicación \(A V\): \(O(n^2 + n^2 d_v) \sim O(n^2 d)\).
Por tanto, self-attention es \(O(n^2 d)\) en tiempo y \(O(n^2)\) en memoria (para almacenar la matriz \(S\) o \(A\)). Esto explica las limitaciones para secuencias largas y motiva aproximaciones (sparse, local attention, linformer, etc.).
11.26. Multi-head Attention#
Formulación: Multi-head attention (MHA) extiende self-attention con varias cabezas paralelas, cada una enfocada en un subespacio distinto del espacio de representación
Cada cabeza realiza su propia atención:
De esta forma, el modelo capta múltiples tipos de relaciones de manera simultánea. En la práctica, cada cabeza de atención analiza la secuencia desde una perspectiva diferente: algunas captan relaciones sintácticas, otras semánticas, dependencias a largo plazo o patrones locales.
Estos subespacios actúan como canales de atención especializados, que aprenden de forma automática distintos aspectos de la estructura de la secuencia. Cada cabeza (head) de atención puede especializarse en un tipo diferente de relación entre palabras.
Por ejemplo, en la oración
El gato negro duerme
una cabeza puede aprender relaciones asociadas a quién realiza una acción:
\[ \textbf{duerme} \rightarrow \textbf{gato} \]otra cabeza puede enfocarse en relaciones descriptivas:
\[ \textbf{negro} \rightarrow \textbf{gato} \]mientras que otra puede aprender estructura gramatical:
\[ \textbf{El} \rightarrow \textbf{gato} \]Todas las cabezas observan la misma secuencia, pero cada una aprende patrones distintos del lenguaje. Por ello, en Multi-Head Attention se utilizan múltiples cabezas en paralelo:
\[ \text{MultiHead}(Q,K,V) = \text{Concat}(\text{head}_1,\dots,\text{head}_h)W^O \]Cada \(\text{head}_i\) aprende una perspectiva diferente del contexto.
Dimensionalidad típica
\(d_{model} = 512\), \(h = 8\) heads
\(d_k = d_v = d_{model}/h = 64\)
Complejidad computacional
Interpretación geométrica: Cada cabeza proyecta la información en un subespacio diferente
Teorema (Yun et al., 2020): Multi-head attention puede aproximar cualquier función continua de múltiples variables.
Pseudocódigo Python:
heads = [self_attention(X @ WQ[i], X @ WK[i], X @ WV[i]) for i in range(h)]
output = np.concatenate(heads, axis=-1) @ WO
Observación
En multi-head attention, cada cabeza es un bloque independiente de self-attention, pero trabaja en un subespacio distinto del espacio de representaciones del modelo. Si tu vector de embeddings (una palabra o token) vive en un espacio de dimensión
\[ d_{\text{model}} = 512 \]y tienes
\[ h = 8 \]cabezas, entonces
\[ d_k = d_v = \frac{d_{\text{model}}}{h} = 64 \]Cada cabeza trabaja en un subespacio de 64 dimensiones, en lugar de usar todo el espacio de 512 dimensiones. Así, la Multi-Head Attention (MHA) no copia la misma atención 8 veces, sino que divide la información y la observa desde distintos ángulos.
11.27. Transformer#
Encoder Layer Matemático. El encoder del Transformer se basa en dos bloques principales:
Multi-Head Self-Attention (MHA)
Feed-Forward Network (FFN) ambos con conexiones residuales y normalización de capa.
Ecuaciones:
\[ Z = \text{LayerNorm}(X + \text{MultiHeadAttention}(X,X,X)) \]\[ \text{Output} = \text{LayerNorm}(Z + \text{FFN}(Z)) \]Donde:
\(X\) son las representaciones de entrada (tokens embebidos).
\(\text{MultiHeadAttention}(X,X,X)\) aplica autoatención en paralelo sobre \(X\).
\(\text{LayerNorm}\) estabiliza las distribuciones internas de activaciones.
La conexión residual \(X + F(X)\) evita el desvanecimiento del gradiente. Es decir, suma la entrada original \(X\) a la salida transformada \(F(X)\)
Transformer conserva la información original \(X\), pero le agrega el contexto aprendido por la atención. De esta forma se evita distorsionar información útil, degradar detalles, o dificultar el flujo del gradiente.
Relación con Multi-Head Attention
El bloque de atención múltiple es el núcleo del encoder. Cada cabeza aprende a atender distintos patrones dentro de la misma secuencia:
Conexión directa:
En el encoder, \(Q=K=V=X\) → el modelo se “autoatiende”, capturando dependencias internas del input.
Cada cabeza proyecta la información a un subespacio distinto (\(W_i^Q, W_i^K, W_i^V\)), y sus salidas se combinan linealmente.
El resultado pasa a través de un bloque Feed-Forward (FFN) que actúa como proyector no lineal, expandiendo y comprimiendo la dimensionalidad.
Feed-Forward Network (FFN). Cada token se procesa independientemente mediante dos transformaciones lineales y una no lineal:
\[ \text{FFN}(x) = \max(0, x W_1 + b_1) W_2 + b_2 \]Típicamente:
\[ d_{\text{model}} = 512, \quad d_{ff} = 2048 \]La FFN no mezcla información entre tokens; su función es refinar y transformar la representación enriquecida que proviene del MHA.
Decoder: Masked Self-Attention. El decoder utiliza una versión enmascarada del self-attention para evitar que un token vea los futuros (causalidad). Supóngase que el modelo desea generar la secuencia
El gato duerme
Durante el proceso de generación, cuando el decoder intenta predecir la palabra
gato
solo debe tener acceso a la información previa:
El
No debe poder ver la palabra
duerme
ya que esta todavía no ha sido generada. Por ello, el mecanismo de Masked Self-Attention bloquea el acceso a tokens futuros, garantizando una generación autorregresiva y causal.
Máscara causal:
\[\begin{split} M_{ij} = \begin{cases} 0 & i \ge j \\ -\infty & i < j \end{cases} \end{split}\]Aplicación en atención:
\[ \text{MaskedAttention}(Q,K,V) = \text{softmax}!\left(\frac{QK^\top}{\sqrt{d_k}} + M\right)V \]Esto asegura que el modelo genere tokens de manera autorregresiva, viendo solo los anteriores.
Residual Connections. Permiten un flujo estable de gradientes:
\[ y = x + F(x),\quad\frac{\partial L}{\partial x} = \frac{\partial L}{\partial y} \left(1 + \frac{\partial F}{\partial x}\right) \]Gracias a esto, la red puede ser profunda sin degradar el entrenamiento, algo problemático en RNN o LSTM. Para verificar esto, dado que, las conexiones residuales utilizadas en Transformers tienen la forma
\[ y = x + F(x) \]donde:
\(x\) representa la entrada original a la capa,
\(F(x)\) representa una transformación aprendida por la red neuronal (por ejemplo, un bloque de atención o una red feed-forward),
\(y\) es la salida final de la capa residual.
El objetivo es analizar cómo fluye el gradiente durante el proceso de entrenamiento mediante backpropagation. Supongamos que la función de pérdida del modelo es
\[ L = L(y) \]donde:
\(L\) es la loss function,
\(y\) depende de \(x\).
El gradiente respecto a la entrada \(x\) se obtiene aplicando la regla de la cadena:
Ahora derivamos la conexión residual \(y = x + F(x)\) respecto a \(x\):
\[ \frac{\partial y}{\partial x} = \frac{\partial}{\partial x}(x + F(x)) \]Aplicando linealidad de la derivada:
Sustituyendo este resultado en la expresión inicial:
Entonces, la expresión anterior muestra que el gradiente contiene siempre un término constante igual a: \(1\). Esto crea un camino directo para la propagación del gradiente, incluso si
En consecuencia:
el gradiente no desaparece fácilmente,
la información original puede preservarse,
y la red puede entrenarse con muchas capas profundas.
Por esta razón, las conexiones residuales son fundamentales en Transformers modernos y arquitecturas profundas como ResNet.
Layer Normalization. La normalización estabiliza las activaciones dentro de cada capa:
\[ \text{LayerNorm}(x) = \gamma \frac{x - \mu}{\sigma} + \beta, \]donde \(\gamma,\,\beta\) permiten ajustar esa normalización según lo que se necesita aprender y
\[ \mu = \frac{1}{d}\sum_{i=1}^d x_i, \quad \sigma = \sqrt{\frac{1}{d}\sum_{i=1}^d (x_i - \mu)^2} \]Esto mantiene la escala de las representaciones controlada, favoreciendo la convergencia.
Ventajas Matemáticas sobre LSTM
Aspecto |
Transformer |
LSTM |
|---|---|---|
Dependencia temporal |
Paralelizable |
Secuencial |
Gradientes |
Sin desvanecimiento |
Se atenúan exponencialmente |
Complejidad |
\(O(n^2 \cdot d)\) (paralelizable) |
\(O(n \cdot d^2)\) |
Dependencias largas |
Directas entre tokens |
Limitadas por memoria |
Eficiencia en GPU/TPU |
Alta |
Baja |
Gradiente:
En LSTM: \(O(\lambda^L)\) con \(\lambda < 1\) → se desvanece al aumentar la longitud.
En Transformer: la atención conecta tokens de manera directa, manteniendo \(O(1)\) en propagación.
Intuición final. El encoder construye representaciones jerárquicas del input combinando:
Multi-Head Self-Attention → capta relaciones internas desde múltiples subespacios.
Feed-Forward Network → transforma las representaciones locales.
Residual + LayerNorm → estabilizan y preservan información útil.
El decoder, por su parte, usa Masked Multi-Head Attention para generar texto o secuencias paso a paso, mientras se conecta con el encoder a través de un bloque adicional de atención cruzada.
Pseudocódigo Python
Implementación Self-Attention
def self_attention(X, WQ, WK, WV):
Q = X @ WQ
K = X @ WK
V = X @ WV
scores = Q @ K.T / np.sqrt(K.shape[-1])
weights = softmax(scores, axis=-1)
return weights @ V
Comparación Teórica LSTM vs Transformer
Métrica |
LSTM |
Transformer |
|---|---|---|
Paralelismo |
No |
Sí |
Dependencias largas |
Exponencial decay |
Directo |
Memoria |
O(n) |
O(n²) |
Training |
Lento |
Rápido |
11.28. Aplicación: Análisis de sentimiento con Transformer#
Instalar inicialmente
pip install tensorflow-text==2.17.0
pip install tensorflow-hub==0.16.1
pip install -q tf-models-official==2.17.0
import tensorflow as tf
import tensorflow_text as text
import tensorflow_hub as hub
import tensorflow as tf
print("TensorFlow version:", tf.__version__)
print("Num GPUs Available:", len(tf.config.list_physical_devices('GPU')))
print(tf.config.list_physical_devices('GPU'))
print("TensorFlow Text version:", text.__version__)
print("TensorFlow Hub:", hub.__version__)
/home/lihkir/.local/lib/python3.10/site-packages/tensorflow_hub/__init__.py:61: UserWarning: pkg_resources is deprecated as an API. See https://setuptools.pypa.io/en/latest/pkg_resources.html. The pkg_resources package is slated for removal as early as 2025-11-30. Refrain from using this package or pin to Setuptools<81.
from pkg_resources import parse_version
TensorFlow version: 2.17.0
Num GPUs Available: 1
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
TensorFlow Text version: 2.17.0
TensorFlow Hub: 0.16.1
# ==========================================================
# Transformer para clasificación de texto (TensorFlow)
# Métricas esenciales + Testing con textos personalizados
# ==========================================================
import tensorflow as tf
from tensorflow.keras import layers, models
import tensorflow_datasets as tfds
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.metrics import confusion_matrix, classification_report, roc_curve, auc
import pandas as pd
# Configurar estilo de plots
plt.style.use('default')
fig, axes = plt.subplots(1, 2, figsize=(15, 6))
fig.suptitle('Métricas Esenciales del Modelo Transformer', fontsize=16, fontweight='bold')
# ----------------------------------------------------------
# 1. Cargar dataset (IMDB)
# ----------------------------------------------------------
print("Cargando dataset IMDB...")
train_data, test_data = tfds.load(
"imdb_reviews",
split=["train", "test"],
as_supervised=True
)
# ----------------------------------------------------------
# 2. Vectorización de texto
# ----------------------------------------------------------
VOCAB_SIZE = 10000
SEQUENCE_LENGTH = 200
vectorize_layer = layers.TextVectorization(
max_tokens=VOCAB_SIZE,
output_mode="int",
output_sequence_length=SEQUENCE_LENGTH
)
# Adaptar vocabulario
train_text = train_data.map(lambda x, y: x)
vectorize_layer.adapt(train_text)
# ----------------------------------------------------------
# 3. Preparar datasets vectorizados
# ----------------------------------------------------------
AUTOTUNE = tf.data.AUTOTUNE
BATCH_SIZE = 64
def vectorize_text(text, label):
return vectorize_layer(text), label
train_vec = (
train_data.map(vectorize_text)
.cache()
.shuffle(10000)
.batch(BATCH_SIZE)
.prefetch(AUTOTUNE)
)
test_vec = (
test_data.map(vectorize_text)
.cache()
.batch(BATCH_SIZE)
.prefetch(AUTOTUNE)
)
# ----------------------------------------------------------
# 4. Definir modelo Transformer
# ----------------------------------------------------------
EMBED_DIM = 64
NUM_HEADS = 2
FF_DIM = 128
"""
TEORÍA TRANSFORMER - ENCODER LAYER MATEMÁTICO:
El encoder del Transformer se basa en dos bloques principales:
1. Multi-Head Self-Attention (MHA)
2. Feed-Forward Network (FFN)
ambos con conexiones residuales y normalización de capa.
Ecuaciones teóricas:
Z = LayerNorm(X + MultiHeadAttention(X,X,X))
Output = LayerNorm(Z + FFN(Z))
Donde:
- X son las representaciones de entrada (tokens embebidos)
- MultiHeadAttention(X,X,X) aplica autoatención en paralelo sobre X
- LayerNorm estabiliza las distribuciones internas de activaciones
- La conexión residual X + F(X) evita el desvanecimiento del gradiente
"""
inputs = layers.Input(shape=(SEQUENCE_LENGTH,), dtype=tf.int64)
"""
TEORÍA TRANSFORMER - EMBEDDING:
Cada token se representa como un vector denso en R^EMBED_DIM
Esto corresponde a la primera transformación de tokens en vectores numéricos
"""
x = layers.Embedding(VOCAB_SIZE, EMBED_DIM)(inputs)
"""
TEORÍA TRANSFORMER - MULTI-HEAD ATTENTION:
Ecuaciones teóricas:
MultiHead(Q,K,V) = Concat(head₁,...,headₕ)W^O
head_i = Attention(Q W_i^Q, K W_i^K, V W_i^V)
En nuestro caso: Q=K=V=X (self-attention del encoder)
Cada cabeza aprende a atender distintos patrones dentro de la misma secuencia
Cada cabeza proyecta la información a un subespacio distinto (W_i^Q, W_i^K, W_i^V)
"""
x = layers.MultiHeadAttention(num_heads=NUM_HEADS, key_dim=EMBED_DIM)(x, x)
"""
TEORÍA TRANSFORMER - POOLING PARA CLASIFICACIÓN:
En clasificación, necesitamos convertir la secuencia de vectores
(SEQUENCE_LENGTH × EMBED_DIM) en un solo vector para la clasificación
Esto adapta la arquitectura encoder para tareas de clasificación
"""
x = layers.GlobalAveragePooling1D()(x)
"""
TEORÍA TRANSFORMER - FEED-FORWARD NETWORK (FFN):
Ecuación teórica: FFN(x) = max(0, xW₁ + b₁)W₂ + b₂
La FFN no mezcla información entre tokens; su función es refinar y transformar
la representación enriquecida que proviene del MHA.
Típicamente: d_model = 512, d_ff = 2048 (en nuestro caso: EMBED_DIM=64, FF_DIM=128)
"""
x = layers.Dense(FF_DIM, activation="relu")(x)
# Dropout para regularización (no parte de la teoría original pero útil en práctica)
x = layers.Dropout(0.3)(x)
# Capa final de clasificación binaria
outputs = layers.Dense(1, activation="sigmoid")(x)
model = models.Model(inputs, outputs)
# ----------------------------------------------------------
# 5. Compilar y entrenar con AUC
# ----------------------------------------------------------
model.compile(
optimizer="adam",
loss="binary_crossentropy",
metrics=[
"accuracy",
tf.keras.metrics.AUC(name='auc'),
tf.keras.metrics.Precision(name='precision'),
tf.keras.metrics.Recall(name='recall')
]
)
print("Entrenando modelo Transformer...")
history = model.fit(
train_vec,
validation_data=test_vec,
epochs=3,
verbose=1
)
# ----------------------------------------------------------
# 6. Evaluar modelo y preparar datos para métricas
# ----------------------------------------------------------
print("\nEvaluación final del modelo:")
loss, accuracy, auc_score, precision, recall = model.evaluate(test_vec, verbose=0)
# Obtener predicciones para métricas detalladas
print("Generando predicciones para análisis...")
y_true = []
y_pred_proba = []
for batch in test_vec:
texts, labels = batch
predictions = model.predict(texts, verbose=0)
y_true.extend(labels.numpy())
y_pred_proba.extend(predictions.flatten())
y_true = np.array(y_true)
y_pred_proba = np.array(y_pred_proba)
y_pred = (y_pred_proba > 0.5).astype(int)
# ----------------------------------------------------------
# 7. MATRIZ DE CONFUSIÓN (SOLO PORCENTAJES)
# ----------------------------------------------------------
ax = axes[0]
cm = confusion_matrix(y_true, y_pred)
cm_percentage = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis] * 100
sns.heatmap(cm_percentage, annot=True, fmt='.1f', cmap='Blues', ax=ax,
xticklabels=['Negativo', 'Positivo'],
yticklabels=['Negativo', 'Positivo'],
cbar_kws={'label': 'Porcentaje (%)'})
ax.set_xlabel('Predicción')
ax.set_ylabel('Valor Real')
ax.set_title('Matriz de Confusión (% por Fila)', fontweight='bold')
# ----------------------------------------------------------
# 8. CURVA ROC
# ----------------------------------------------------------
ax = axes[1]
fpr, tpr, thresholds = roc_curve(y_true, y_pred_proba)
roc_auc = auc(fpr, tpr)
ax.plot(fpr, tpr, color='darkorange', lw=3, label=f'ROC Curve (AUC = {roc_auc:.4f})')
ax.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--', label='Clasificador Aleatorio')
ax.set_xlim([0.0, 1.0])
ax.set_ylim([0.0, 1.05])
ax.set_xlabel('Tasa de Falsos Positivos (False Positive Rate)')
ax.set_ylabel('Tasa de Verdaderos Positivos (True Positive Rate)')
ax.set_title('Curva ROC', fontweight='bold')
ax.legend(loc="lower right")
ax.grid(True, alpha=0.3)
# Destacar punto de operación con threshold 0.5
threshold_05_idx = np.argmin(np.abs(thresholds - 0.5))
ax.plot(fpr[threshold_05_idx], tpr[threshold_05_idx], 'ro', markersize=8,
label=f'Threshold 0.5\n(FPR={fpr[threshold_05_idx]:.3f}, TPR={tpr[threshold_05_idx]:.3f})')
ax.legend(loc="lower right")
# Ajustar layout
plt.tight_layout()
plt.savefig('metricas_esenciales_transformer.png', dpi=300, bbox_inches='tight')
plt.show()
# ----------------------------------------------------------
# 9. REPORTE DE CLASIFICACIÓN DETALLADO
# ----------------------------------------------------------
print("\n" + "="*80)
print("REPORTE DE CLASIFICACIÓN DETALLADO")
print("="*80)
report = classification_report(y_true, y_pred,
target_names=['Negativo', 'Positivo'],
digits=4, output_dict=True)
# Imprimir reporte formateado
print(f"\n{'':<15} {'Precision':<12} {'Recall':<12} {'F1-Score':<12} {'Support':<12}")
print("-" * 60)
for class_name in ['Negativo', 'Positivo']:
metrics = report[class_name]
print(f"{class_name:<15} {metrics['precision']:<12.4f} {metrics['recall']:<12.4f} "
f"{metrics['f1-score']:<12.4f} {metrics['support']:<12}")
print("-" * 60)
print(f"{'Accuracy':<15} {'':<12} {'':<12} {report['accuracy']:<12.4f} {len(y_true):<12}")
print(f"{'Macro Avg':<15} {report['macro avg']['precision']:<12.4f} {report['macro avg']['recall']:<12.4f} "
f"{report['macro avg']['f1-score']:<12.4f} {report['macro avg']['support']:<12}")
print(f"{'Weighted Avg':<15} {report['weighted avg']['precision']:<12.4f} {report['weighted avg']['recall']:<12.4f} "
f"{report['weighted avg']['f1-score']:<12.4f} {report['weighted avg']['support']:<12}")
# ----------------------------------------------------------
# 10. RESUMEN DE MÉTRICAS DEL MODELO
# ----------------------------------------------------------
print("\n" + "="*80)
print("RESUMEN DE MÉTRICAS DEL MODELO")
print("="*80)
# Calcular métricas adicionales
from sklearn.metrics import f1_score
f1 = f1_score(y_true, y_pred)
tn, fp, fn, tp = cm.ravel()
specificity = tn / (tn + fp) if (tn + fp) > 0 else 0
balanced_accuracy = (recall + specificity) / 2
# Crear resumen de métricas
metrics_summary = {
'AUC (Area Under ROC Curve)': roc_auc,
'Accuracy': accuracy,
'Precision': precision,
'Recall (Sensitivity)': recall,
'Specificity': specificity,
'F1-Score': f1,
'Balanced Accuracy': balanced_accuracy
}
print(f"\n{'MÉTRICA':<30} {'VALOR':<10} {'INTERPRETACIÓN':<40}")
print("-" * 85)
for metric, value in metrics_summary.items():
# Interpretaciones basadas en valores
if metric == 'AUC (Area Under ROC Curve)':
if value >= 0.9: interpretation = "Excelente discriminación"
elif value >= 0.8: interpretation = "Buena discriminación"
elif value >= 0.7: interpretation = "Discriminación aceptable"
else: interpretation = "Discriminación pobre"
elif metric in ['Accuracy', 'Balanced Accuracy']:
if value >= 0.9: interpretation = "Exactitud excelente"
elif value >= 0.8: interpretation = "Buena exactitud"
elif value >= 0.7: interpretation = "Exactitud aceptable"
else: interpretation = "Exactitud pobre"
elif metric in ['Precision', 'Recall (Sensitivity)', 'Specificity']:
if value >= 0.9: interpretation = "Rendimiento excelente"
elif value >= 0.8: interpretation = "Buen rendimiento"
elif value >= 0.7: interpretation = "Rendimiento aceptable"
else: interpretation = "Rendimiento pobre"
elif metric == 'F1-Score':
if value >= 0.9: interpretation = "Balance excelente"
elif value >= 0.8: interpretation = "Buen balance"
elif value >= 0.7: interpretation = "Balance aceptable"
else: interpretation = "Balance pobre"
print(f"{metric:<30} {value:<10.4f} {interpretation:<40}")
# ----------------------------------------------------------
# 11. TESTEAR CON TEXTOS PERSONALIZADOS - DEMOSTRACIÓN PRÁCTICA
# ----------------------------------------------------------
def predict_sentiment(text, model, vectorize_layer, threshold=0.5):
"""
Predice si un texto es positivo o negativo
Demuestra el pipeline completo del Transformer:
1. Vectorización → 2. Embedding → 3. Attention → 4. Clasificación
"""
# Vectorizar el texto (tokenización + padding)
vectorized_text = vectorize_layer([text])
# Predecir usando el modelo Transformer
prediction = model.predict(vectorized_text, verbose=0)
probability = prediction[0][0]
# Determinar sentimiento basado en threshold
sentiment = "POSITIVO" if probability > threshold else "NEGATIVO"
return {
'text': text,
'probability': probability,
'sentiment': sentiment,
'confidence': f"{probability*100:.2f}%"
}
# Textos de ejemplo para probar el modelo
# Estos textos demuestran cómo el Multi-Head Attention puede capturar
# dependencias semánticas largas y patrones lingüísticos complejos
test_texts = [
# Textos positivos - patrones que el modelo debe aprender
"This movie was absolutely fantastic! The acting was superb and the story was captivating from start to finish.",
"I loved this film! It's one of the best movies I've seen this year. Highly recommended!",
"Brilliant cinematography and outstanding performances. A true masterpiece of modern cinema.",
# Textos negativos - patrones opuestos
"This was the worst movie I've ever seen. Terrible acting and a boring plot. Complete waste of time.",
"I hated every minute of this film. The characters were poorly developed and the dialogue was awful.",
"Poor direction, bad screenplay, and mediocre acting. I regret watching this movie.",
# Textos neutrales/mixtos - casos desafiantes
"The movie had some good moments but overall it was just average. Not great, not terrible.",
"The special effects were impressive but the story was weak and predictable.",
# Textos cortos - prueba de generalización
"Awesome!", # Palabra positiva aislada
"Terrible.", # Palabra negativa aislada
"I liked it", # Expresión positiva simple
"Boring movie", # Expresión negativa simple
# Textos en español - prueba de transferencia (el modelo fue entrenado en inglés)
"Esta película es increíble, me encantó completamente!", # Debería ser positivo
"Que película tan mala, no la recomiendo para nada." # Debería ser negativo
]
print("\n" + "="*80)
print("DEMOSTRACIÓN: TESTEO CON TEXTOS PERSONALIZADOS")
print("El modelo usa Multi-Head Attention para analizar dependencias en el texto")
print("="*80)
for i, text in enumerate(test_texts, 1):
result = predict_sentiment(text, model, vectorize_layer)
print(f"\nTexto {i}:")
print(f" Texto: '{result['text']}'")
print(f" Probabilidad: {result['probability']:.4f}")
print(f" Confianza: {result['confidence']}")
print(f" Sentimiento: {result['sentiment']}")
# Visualización de la confianza de predicción
# Muestra cómo el modelo distribuye su certeza entre positivo/negativo
bar_length = 20
pos_ratio = result['probability']
neg_ratio = 1 - pos_ratio
pos_bar = "|" * int(bar_length * pos_ratio)
neg_bar = "." * int(bar_length * neg_ratio)
print(f" Visual: [{pos_bar}{neg_bar}]")
print("-" * 50)
# ----------------------------------------------------------
# 12. Análisis de rendimiento por categoría - EVALUACIÓN DETALLADA
# ----------------------------------------------------------
print("\n" + "="*80)
print("ANÁLISIS DETALLADO: RENDIMIENTO POR TIPO DE TEXTO")
print("Evalúa cómo el Transformer maneja diferentes patrones lingüísticos")
print("="*80)
# Agrupación estratégica para análisis
positive_texts = test_texts[:3] + [test_texts[8], test_texts[10], test_texts[12]]
negative_texts = test_texts[3:6] + [test_texts[9], test_texts[11], test_texts[13]]
neutral_texts = test_texts[6:8]
def analyze_category(texts, category_name, model, vectorize_layer):
"""
Analiza el rendimiento del modelo en categorías específicas
Demuestra la capacidad del Transformer para generalizar patrones
"""
print(f"\nAnálisis de textos {category_name}:")
correct_predictions = 0
total_predictions = len(texts)
for text in texts:
result = predict_sentiment(text, model, vectorize_layer)
is_positive = "POSITIVO" in result['sentiment']
# Lógica de evaluación según categoría esperada
if category_name == "positivos":
if is_positive:
correct_predictions += 1
elif category_name == "negativos":
if not is_positive:
correct_predictions += 1
else: # neutrales - solo mostramos sin evaluación binaria
print(f" '{text[:50]}...' -> {result['sentiment']} ({result['confidence']})")
if category_name != "neutrales":
accuracy = correct_predictions / total_predictions * 100
print(f" Precisión: {correct_predictions}/{total_predictions} ({accuracy:.1f}%)")
print(f" Interpretación: El modelo {'generaliza bien' if accuracy > 80 else 'tiene dificultades'} con textos {category_name}")
# Ejecutar análisis por categoría
analyze_category(positive_texts, "positivos", model, vectorize_layer)
analyze_category(negative_texts, "negativos", model, vectorize_layer)
analyze_category(neutral_texts, "neutrales", model, vectorize_layer)
# ----------------------------------------------------------
# 13. RESUMEN TÉCNICO: CONEXIÓN CON LA TEORÍA TRANSFORMER
# ----------------------------------------------------------
print("\n" + "="*80)
print("RESUMEN TÉCNICO: CONEXIÓN IMPLEMENTACIÓN-TEORÍA")
print("="*80)
"""
TEORÍA TRANSFORMER - VENTAJAS MATEMÁTICAS SOBRE LSTM:
Aspecto | Transformer | LSTM
----------------------|------------------------------|---------------------------
Dependencia temporal | Paralelizable | Secuencial
Gradientes | Sin desvanecimiento | Se atenúan exponencialmente
Complejidad | O(n²·d) (paralelizable) | O(n·d²)
Dependencias largas | Directas entre tokens | Limitadas por memoria
Eficiencia en GPU/TPU | Alta | Baja
- Gradiente:
* En LSTM: O(λᴸ) con λ < 1 → se desvanece al aumentar la longitud
* En Transformer: la atención conecta tokens de manera directa, manteniendo O(1)
INTUICIÓN FINAL:
El encoder construye representaciones jerárquicas del input combinando:
• Multi-Head Self-Attention → capta relaciones internas desde múltiples subespacios
• Feed-Forward Network → transforma las representaciones locales
• Residual + LayerNorm → estabilizan y preservan información útil
El decoder (no usado aquí) usa Masked Multi-Head Attention para generar texto
paso a paso, mientras se conecta con el encoder mediante atención cruzada.
"""
print("""
NUESTRA IMPLEMENTACIÓN vs. TEORÍA TRANSFORMER:
1. MULTI-HEAD ATTENTION:
• Teoría: Z = LayerNorm(X + MultiHeadAttention(X,X,X))
• Implementación: layers.MultiHeadAttention() maneja internamente
las proyecciones multi-head y combinación
2. FEED-FORWARD NETWORK:
• Teoría: FFN(x) = max(0, xW₁ + b₁)W₂ + b₂
• Implementación: layers.Dense(FF_DIM, activation='relu')
3. EMBEDDING + POSICIONAL:
• Teoría: Input embedding + positional encoding
• Implementación: layers.Embedding() (sin positional encoding explícito)
4. CLASIFICACIÓN:
• Adaptación de arquitectura encoder para clasificación
• GlobalAveragePooling convierte secuencia → vector
VENTAJAS DEMOSTRADAS:
• Paralelización completa del entrenamiento
• Captura de dependencias largas mediante self-attention
• Estabilidad numérica con capas de normalización implícitas
LIMITACIONES DE ESTA IMPLEMENTACIÓN:
• Arquitectura simplificada sin residual connections explícitas
• Sin positional encoding para información del orden
• Single-layer en lugar de multi-layer encoder
""")
# ----------------------------------------------------------
# 14. GRÁFICA ADICIONAL: Resumen de Métricas
# ----------------------------------------------------------
plt.figure(figsize=(10, 6))
metrics_for_plot = ['Accuracy', 'Precision', 'Recall', 'F1-Score', 'AUC']
values_for_plot = [accuracy, precision, recall, f1, roc_auc]
colors = ['#2E86AB', '#A23B72', '#F18F01', '#C73E1D', '#3E8914']
bars = plt.bar(metrics_for_plot, values_for_plot, color=colors, alpha=0.8)
plt.ylim(0, 1.0)
plt.title('Resumen de Métricas del Modelo Transformer', fontweight='bold', fontsize=14)
plt.ylabel('Valor de la Métrica', fontweight='bold')
# Añadir valores en las barras
for bar, value in zip(bars, values_for_plot):
plt.text(bar.get_x() + bar.get_width()/2, bar.get_height() + 0.01,
f'{value:.4f}', ha='center', va='bottom', fontweight='bold')
plt.grid(True, alpha=0.3, axis='y')
plt.tight_layout()
plt.savefig('resumen_metricas_transformer.png', dpi=300, bbox_inches='tight')
plt.show()
# ----------------------------------------------------------
# 15. INTERPRETACIÓN FINAL
# ----------------------------------------------------------
print("\n" + "="*80)
print("INTERPRETACIÓN FINAL DEL MODELO")
print("="*80)
print(f"""
El modelo Transformer ha demostrado los siguientes resultados:
• CAPACIDAD DISCRIMINATIVA: {'EXCELENTE' if roc_auc >= 0.9 else 'BUENA' if roc_auc >= 0.8 else 'ACEPTABLE' if roc_auc >= 0.7 else 'LIMITADA'}
- AUC de {roc_auc:.4f} indica que el modelo puede distinguir efectivamente entre reseñas positivas y negativas.
• EXACTITUD GENERAL: {accuracy*100:.2f}% de las predicciones son correctas.
• BALANCE PRECISIÓN-RECALL:
- Precisión: {precision*100:.2f}% de las predicciones positivas son correctas
- Recall: {recall*100:.2f}% de los casos positivos reales son detectados
- F1-Score: {f1:.4f} refleja un balance {'óptimo' if f1 >= 0.9 else 'bueno' if f1 >= 0.8 else 'aceptable' if f1 >= 0.7 else 'mejorable'}
• ROBUSTEZ: Especificidad de {specificity*100:.2f}% en identificar correctamente reseñas negativas.
""")
Cargando dataset IMDB...
Entrenando modelo Transformer...
Epoch 1/3
391/391 ━━━━━━━━━━━━━━━━━━━━ 18s 33ms/step - accuracy: 0.6739 - auc: 0.7456 - loss: 0.5608 - precision: 0.6701 - recall: 0.6799 - val_accuracy: 0.8508 - val_auc: 0.9287 - val_loss: 0.3416 - val_precision: 0.8549 - val_recall: 0.8450
Epoch 2/3
391/391 ━━━━━━━━━━━━━━━━━━━━ 2s 5ms/step - accuracy: 0.8930 - auc: 0.9543 - loss: 0.2740 - precision: 0.8930 - recall: 0.8924 - val_accuracy: 0.8611 - val_auc: 0.9369 - val_loss: 0.3269 - val_precision: 0.8685 - val_recall: 0.8510
Epoch 3/3
391/391 ━━━━━━━━━━━━━━━━━━━━ 2s 5ms/step - accuracy: 0.9290 - auc: 0.9758 - loss: 0.1954 - precision: 0.9302 - recall: 0.9275 - val_accuracy: 0.8440 - val_auc: 0.9252 - val_loss: 0.3892 - val_precision: 0.8761 - val_recall: 0.8014
Evaluación final del modelo:
Generando predicciones para análisis...
================================================================================
REPORTE DE CLASIFICACIÓN DETALLADO
================================================================================
Precision Recall F1-Score Support
------------------------------------------------------------
Negativo 0.8170 0.8866 0.8504 12500.0
Positivo 0.8761 0.8014 0.8371 12500.0
------------------------------------------------------------
Accuracy 0.8440 25000
Macro Avg 0.8465 0.8440 0.8437 25000.0
Weighted Avg 0.8465 0.8440 0.8437 25000.0
================================================================================
RESUMEN DE MÉTRICAS DEL MODELO
================================================================================
MÉTRICA VALOR INTERPRETACIÓN
-------------------------------------------------------------------------------------
AUC (Area Under ROC Curve) 0.9255 Excelente discriminación
Accuracy 0.8440 Buena exactitud
Precision 0.8761 Buen rendimiento
Recall (Sensitivity) 0.8014 Buen rendimiento
Specificity 0.8866 Buen rendimiento
F1-Score 0.8371 Buen balance
Balanced Accuracy 0.8440 Buena exactitud
================================================================================
DEMOSTRACIÓN: TESTEO CON TEXTOS PERSONALIZADOS
El modelo usa Multi-Head Attention para analizar dependencias en el texto
================================================================================
Texto 1:
Texto: 'This movie was absolutely fantastic! The acting was superb and the story was captivating from start to finish.'
Probabilidad: 1.0000
Confianza: 100.00%
Sentimiento: POSITIVO
Visual: [||||||||||||||||||||]
--------------------------------------------------
Texto 2:
Texto: 'I loved this film! It's one of the best movies I've seen this year. Highly recommended!'
Probabilidad: 1.0000
Confianza: 100.00%
Sentimiento: POSITIVO
Visual: [||||||||||||||||||||]
--------------------------------------------------
Texto 3:
Texto: 'Brilliant cinematography and outstanding performances. A true masterpiece of modern cinema.'
Probabilidad: 1.0000
Confianza: 100.00%
Sentimiento: POSITIVO
Visual: [||||||||||||||||||||]
--------------------------------------------------
Texto 4:
Texto: 'This was the worst movie I've ever seen. Terrible acting and a boring plot. Complete waste of time.'
Probabilidad: 0.0000
Confianza: 0.00%
Sentimiento: NEGATIVO
Visual: [...................]
--------------------------------------------------
Texto 5:
Texto: 'I hated every minute of this film. The characters were poorly developed and the dialogue was awful.'
Probabilidad: 0.0000
Confianza: 0.00%
Sentimiento: NEGATIVO
Visual: [...................]
--------------------------------------------------
Texto 6:
Texto: 'Poor direction, bad screenplay, and mediocre acting. I regret watching this movie.'
Probabilidad: 0.0000
Confianza: 0.00%
Sentimiento: NEGATIVO
Visual: [...................]
--------------------------------------------------
Texto 7:
Texto: 'The movie had some good moments but overall it was just average. Not great, not terrible.'
Probabilidad: 0.0897
Confianza: 8.97%
Sentimiento: NEGATIVO
Visual: [|..................]
--------------------------------------------------
Texto 8:
Texto: 'The special effects were impressive but the story was weak and predictable.'
Probabilidad: 0.0000
Confianza: 0.00%
Sentimiento: NEGATIVO
Visual: [...................]
--------------------------------------------------
Texto 9:
Texto: 'Awesome!'
Probabilidad: 1.0000
Confianza: 100.00%
Sentimiento: POSITIVO
Visual: [||||||||||||||||||||]
--------------------------------------------------
Texto 10:
Texto: 'Terrible.'
Probabilidad: 0.0000
Confianza: 0.00%
Sentimiento: NEGATIVO
Visual: [....................]
--------------------------------------------------
Texto 11:
Texto: 'I liked it'
Probabilidad: 1.0000
Confianza: 100.00%
Sentimiento: POSITIVO
Visual: [||||||||||||||||||||]
--------------------------------------------------
Texto 12:
Texto: 'Boring movie'
Probabilidad: 0.0000
Confianza: 0.00%
Sentimiento: NEGATIVO
Visual: [...................]
--------------------------------------------------
Texto 13:
Texto: 'Esta película es increíble, me encantó completamente!'
Probabilidad: 0.5310
Confianza: 53.10%
Sentimiento: POSITIVO
Visual: [||||||||||.........]
--------------------------------------------------
Texto 14:
Texto: 'Que película tan mala, no la recomiendo para nada.'
Probabilidad: 0.0003
Confianza: 0.03%
Sentimiento: NEGATIVO
Visual: [...................]
--------------------------------------------------
================================================================================
ANÁLISIS DETALLADO: RENDIMIENTO POR TIPO DE TEXTO
Evalúa cómo el Transformer maneja diferentes patrones lingüísticos
================================================================================
Análisis de textos positivos:
Precisión: 6/6 (100.0%)
Interpretación: El modelo generaliza bien con textos positivos
Análisis de textos negativos:
Precisión: 6/6 (100.0%)
Interpretación: El modelo generaliza bien con textos negativos
Análisis de textos neutrales:
'The movie had some good moments but overall it was...' -> NEGATIVO (8.97%)
'The special effects were impressive but the story ...' -> NEGATIVO (0.00%)
================================================================================
RESUMEN TÉCNICO: CONEXIÓN IMPLEMENTACIÓN-TEORÍA
================================================================================
NUESTRA IMPLEMENTACIÓN vs. TEORÍA TRANSFORMER:
1. MULTI-HEAD ATTENTION:
• Teoría: Z = LayerNorm(X + MultiHeadAttention(X,X,X))
• Implementación: layers.MultiHeadAttention() maneja internamente
las proyecciones multi-head y combinación
2. FEED-FORWARD NETWORK:
• Teoría: FFN(x) = max(0, xW₁ + b₁)W₂ + b₂
• Implementación: layers.Dense(FF_DIM, activation='relu')
3. EMBEDDING + POSICIONAL:
• Teoría: Input embedding + positional encoding
• Implementación: layers.Embedding() (sin positional encoding explícito)
4. CLASIFICACIÓN:
• Adaptación de arquitectura encoder para clasificación
• GlobalAveragePooling convierte secuencia → vector
VENTAJAS DEMOSTRADAS:
• Paralelización completa del entrenamiento
• Captura de dependencias largas mediante self-attention
• Estabilidad numérica con capas de normalización implícitas
LIMITACIONES DE ESTA IMPLEMENTACIÓN:
• Arquitectura simplificada sin residual connections explícitas
• Sin positional encoding para información del orden
• Single-layer en lugar de multi-layer encoder

================================================================================
INTERPRETACIÓN FINAL DEL MODELO
================================================================================
El modelo Transformer ha demostrado los siguientes resultados:
• CAPACIDAD DISCRIMINATIVA: EXCELENTE
- AUC de 0.9255 indica que el modelo puede distinguir efectivamente entre reseñas positivas y negativas.
• EXACTITUD GENERAL: 84.40% de las predicciones son correctas.
• BALANCE PRECISIÓN-RECALL:
- Precisión: 87.61% de las predicciones positivas son correctas
- Recall: 80.14% de los casos positivos reales son detectados
- F1-Score: 0.8371 refleja un balance bueno
• ROBUSTEZ: Especificidad de 88.66% en identificar correctamente reseñas negativas.