
Visualización estática#
Introducción
Este capítulo es un manual sobre los diferentes tipos de visualización estática y los contextos en los que son más eficaces. Utilizando
seaborn, aprenderá a crear una variedad de variedad de gráficos y a seleccionar el tipo correcto de visualización para la representación más adecuada de sus datos.En esta sección, estudiaremos el contexto de los gráficos que presentan patrones globales en los datos, como por ejemplo:
Gráficos que muestran la varianza de las características individuales de los datos, como los histogramas
Gráficos que muestran cómo varían las diferentes características presentes en los datos entre sí, como los gráficos de dispersión, los gráficos de líneas y los mapas de calor.
Scatter plot
Un gráfico de dispersión (
scatter plot) es un gráfico simple que presenta los valores de dos características en un conjunto de datos.Cada punto de datos se representa mediante un punto con la coordenada \(x\) como valor de la
primera característicay la coordenada \(y\) como valor de lasegunda característica.Un gráfico de dispersión es una gran herramienta para aprender más sobre dos atributos numéricos.
Los gráficos de dispersión pueden ayudar a
descubrir las relaciones entre diferentes características de los datos, como el tiempo y las ventas, la ingesta de alimentos y las estadísticas de salud en varios contextos.
Creación de un gráfico de dispersión estático#
En este ejercicio, generaremos un gráfico de dispersión para examinar la relación entre el peso (weight) y el millaje (mpg) de los vehículos del conjunto de datos
mpg. Para ello, vamos a seguir los siguientes pasos:
Abra un cuaderno
Jupytere importe los módulos dePythonnecesarios:
import seaborn as sns
Importe el conjunto de datos de
seaborn
mpg_df = sns.load_dataset("mpg")
mpg_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 398 entries, 0 to 397
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 mpg 398 non-null float64
1 cylinders 398 non-null int64
2 displacement 398 non-null float64
3 horsepower 392 non-null float64
4 weight 398 non-null int64
5 acceleration 398 non-null float64
6 model_year 398 non-null int64
7 origin 398 non-null object
8 name 398 non-null object
dtypes: float64(4), int64(3), object(2)
memory usage: 28.1+ KB
mpg: Millas por galóncylinders: Número de cilindrosdisplacement: Cilindrada del motor, en litroshorsepower: Caballos de fuerzaweight: Peso del auto en librasacceleration: Aceleración del automodel_year: Año del modeloorigin: País de origen del autoname: Nombre del auto (marca-modelo-variante)
Generar un gráfico de dispersión utilizando la función
scatterplot()
ax = sns.scatterplot(x="weight", y="mpg", data=mpg_df)
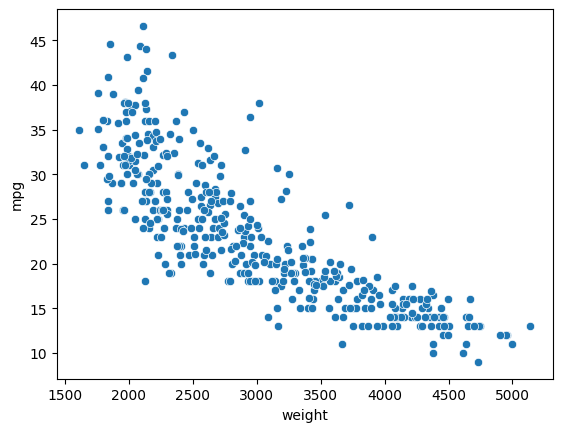
Observación Nótese que el gráfico de dispersión muestra una disminución del mileage (mpg) con un aumento del weight. Es una visión útil de las relaciones entre las diferentes características del conjunto de datos.
Creación de un gráfico hexagonal estático Binning#
También existe una versión más elegante de los gráficos de dispersión, llamada
hexagonal binning plot (hexbin plot). En este ejercicio, generaremos un diagrama de dispersión hexagonal para comprender mejor la relación entre el peso (weight) y el millaje (mileage (mpg)):
Abra un cuaderno
Jupytere importe los módulos dePythonnecesarios:
import seaborn as sns
Importe el conjunto de datos de
seaborn
mpg_df = sns.load_dataset("mpg")
Trazar un gráfico
hexbinusandojointplotcon el tipo establecido enhex
sns.set(style="ticks")
sns.jointplot(data=mpg_df, x="weight", y="mpg", kind="hex", color="#4CB391");
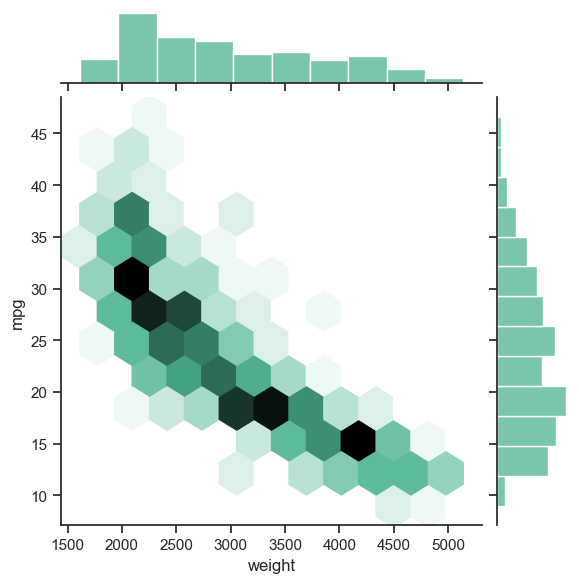
Observación Como puede observar, el histograma de los ejes superior y derecho representa la varianza de las características representadas por los ejes \(x\) e \(y\) respectivamente (mpg y weight, en este ejemplo). Además, es posible que haya notado en el gráfico de dispersión anterior que los datos se superponían fuertemente en ciertas áreas, ocultando la distribución real de las características. Los gráficos Hexbin son una buena herramienta de visualización utilizada cuando los datos son muy densos.
Creación de un gráfico de contorno estático#
Otra alternativa a los gráficos de dispersión cuando los puntos de datos están densamente poblados en regiones específicas es un
gráfico de contorno. En este ejercicio, crearemos un gráfico de contorno para mostrar la relación entre weight y el mileage en el conjunto de datos mpg. Podremos ver que la relación entre weight y mileage es más fuerte cuando hay mayor volumen de datos
Abra un cuaderno
Jupytere importe los módulos dePythonnecesarios:
import seaborn as sns
Importe el conjunto de datos de
seaborn:
mpg_df = sns.load_dataset("mpg")
Crea un gráfico de contorno utilizando el método
set_style
sns.set_style("white")
Generar un gráfico de estimación de la densidad del núcleo (KDE). Los dos primeros parámetros son matrices de \(X\) e \(Y\) coordenadas de los puntos de datos, el parámetro
fillse establece enTruepara que los contornos se rellenen con un gradiente de color basado en el número de puntos de datos
sns.kdeplot(data=mpg_df, x="weight", y="mpg", fill=True);
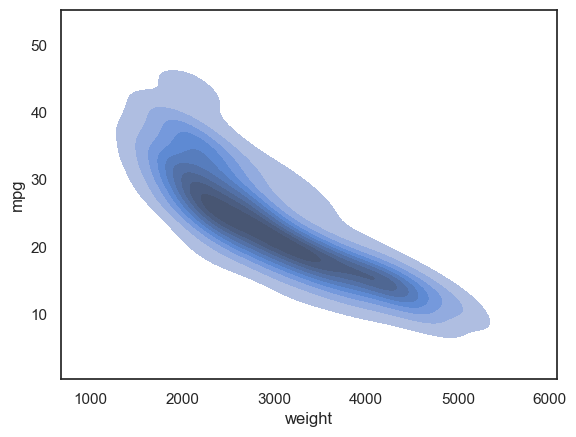
Observación En nuestro ejemplo de weight frente a mileage (mpg), el diagrama hexagonal y el diagrama de contorno indican que hay una determinada curva a lo largo de la cual la relación negativa entre el peso y el kilometraje es más fuerte, como es evidente por el mayor número de puntos de datos. La relación negativa se vuelve relativamente más débil a medida que nos alejamos de la curva (menos volumen de datos).
Creación de un gráfico de líneas estático#
Los gráficos de líneas representan la información como una serie de puntos de datos conectados por segmentos de líneas rectas. Son útiles para indicar la relación entre una característica numérica discreta (en el eje \(x\)), como
model_year, y una característica numérica continua (en el eje \(y\)), como mpg del conjunto de datosmpg. En este ejercicio, crearemos un gráfico de dispersión para un par de características diferentes,model_yearympg.
Abra un cuaderno
Jupytere importe los módulos dePythonnecesarios:
import seaborn as sns
Importe el conjunto de datos de
seaborn:
mpg_df = sns.load_dataset("mpg")
Seleccione el estilo para la figura con
set_style
sns.set_style("white")
Crear un gráfico de dispersión bidimensional
ax1 = sns.scatterplot(x="model_year", y="mpg", data=mpg_df)
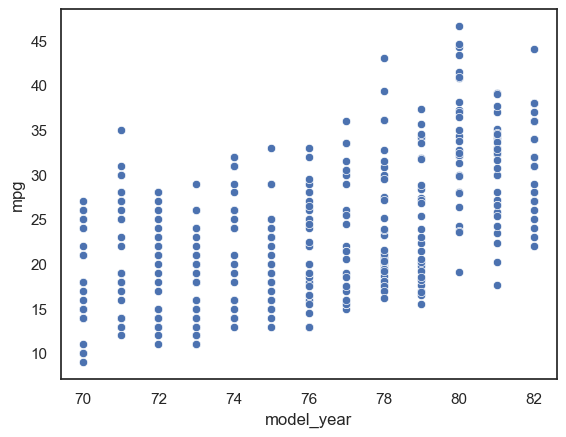
Observación: En este ejemplo, vemos que la característica model_year sólo toma valores discretos entre 70 y 82. Ahora, cuando tenemos una característica numérica discreta como esta (modelo_año), dibujar un gráfico de líneas uniendo los puntos de datos es una buena idea. Podemos dibujar un simple gráfico de líneas que muestre la relación entre model_year y mpg con el siguiente código
ax = sns.lineplot(x="model_year", y="mpg", data=mpg_df)
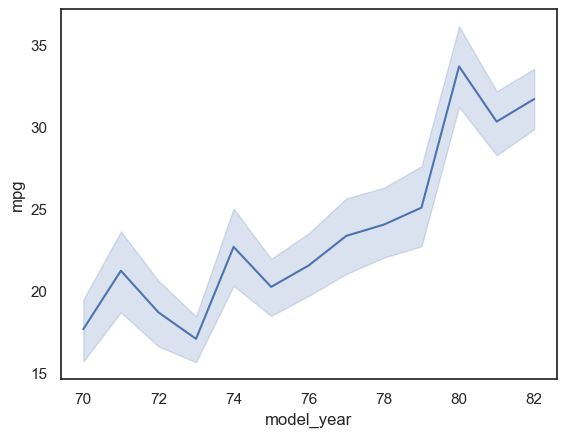
Observación: Como podemos ver, los puntos conectados por la línea sólida representan la media de la característica del eje \(y\) en la coordenada \(x\) correspondiente. El área sombreada alrededor de la línea muestra el intervalo de confianza para la característica del eje \(y\) (por defecto, seaborn establece el intervalo de confianza del 95%). El parámetro ci puede utilizarse para cambiar a un intervalo de confianza diferente.
sns.lineplot(x="model_year", y="mpg", data=mpg_df, errorbar=('ci', 68));
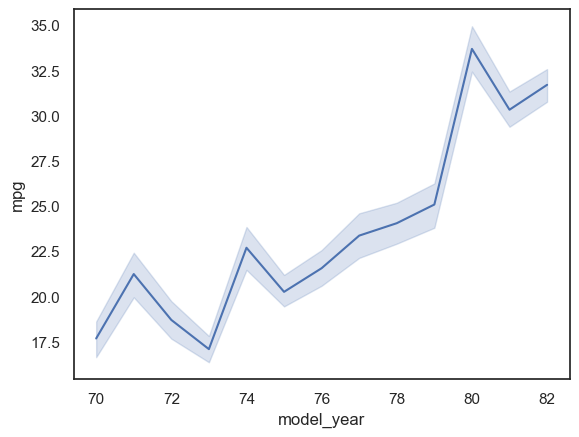
Observación: Como podemos ver en el gráfico anterior, el intervalo de confianza del 68% se traduce en un rango de valores de características en el que están presentes el 68% de los puntos de datos. Los gráficos de líneas son excelentes técnicas de visualización para escenarios en los que tenemos datos que cambian con el tiempo, eje \(x\), podría representar la fecha o el tiempo, y el gráfico ayudaría a visualizar cómo un valor varía a lo largo de ese periodo.
Presentación de datos a través del tiempo con múltiples gráficos de líneas#
En este ejemplo, veremos cómo presentar los datos a través del tiempo con múltiples gráficos de líneas. En este ejemplo utilizamos el conjunto de datos de vuelos (
flights)
Abra un cuaderno
Jupytere importe los módulos dePythonnecesarios:
import seaborn as sns
Importe el conjunto de datos de
seaborn:
flights_df = sns.load_dataset("flights")
flights_df.head()
| year | month | passengers | |
|---|---|---|---|
| 0 | 1949 | Jan | 112 |
| 1 | 1949 | Feb | 118 |
| 2 | 1949 | Mar | 132 |
| 3 | 1949 | Apr | 129 |
| 4 | 1949 | May | 121 |
Supongamos que quiere observar cómo varía el número de pasajeros entre meses en diferentes años. ¿Cómo mostraría esta información? Una opción es dibujar varios gráficos de líneas en una sola figura.
Crear varias gráficas para los meses de diciembre y enero
import matplotlib.pyplot as plt
fig,ax=plt.subplots()
ax = sns.lineplot(x="year", y="passengers", data=flights_df[flights_df['month']=='Jan'], color='green')
ax = sns.lineplot(x="year", y="passengers", data=flights_df[flights_df['month']=='Feb'], color='red')
ax = sns.lineplot(x="year", y="passengers", data=flights_df[flights_df['month']=='Mar'], color='blue')
ax = sns.lineplot(x="year", y="passengers", data=flights_df[flights_df['month']=='Apr'], color='cyan')
ax = sns.lineplot(x="year", y="passengers", data=flights_df[flights_df['month']=='May'], color='pink')
ax = sns.lineplot(x="year", y="passengers", data=flights_df[flights_df['month']=='Jun'], color='black')
ax = sns.lineplot(x="year", y="passengers", data=flights_df[flights_df['month']=='Jul'], color='grey')
ax = sns.lineplot(x="year", y="passengers", data=flights_df[flights_df['month']=='Aug'], color='yellow')
ax = sns.lineplot(x="year", y="passengers", data=flights_df[flights_df['month']=='Sep'], color='turquoise')
ax = sns.lineplot(x="year", y="passengers", data=flights_df[flights_df['month']=='Oct'], color='orange')
ax = sns.lineplot(x="year", y="passengers", data=flights_df[flights_df['month']=='Nov'], color='darkgreen')
ax = sns.lineplot(x="year", y="passengers", data=flights_df[flights_df['month']=='Dec'], color='darkred')
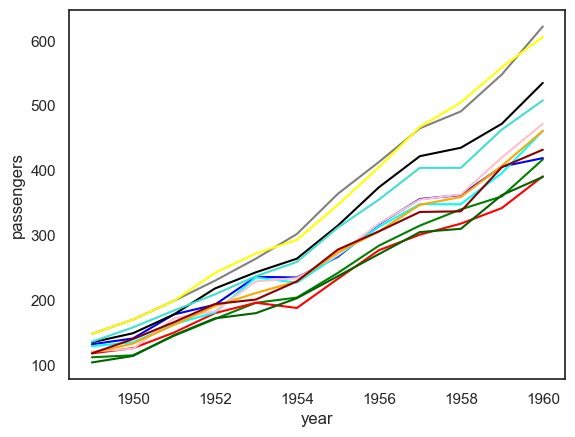
Observación: Con este ejemplo de 12 gráficos de líneas, podemos ver cómo una figura con demasiados gráficos de líneas rápidamente comienza a abarrotarse y a confundirse. Por lo tanto, para ciertos escenarios, los gráficos de líneas no son no son atractivos ni útiles. Entonces, ¿cuál es la alternativa para nuestro caso de uso? Lo veremos en el siguiente ejercicio
Creación y exploración de un mapa de calor estático#
Un
heatmapes una representación visual de una característica numérica continua específica en función de otras dos características discretas (ya sea una categórica o una numérica discreta) en el conjunto de datos. En este ejercicio, exploraremos y crearemos un mapa de calor. Utilizaremos el conjunto de datos de vuelos de la bibliotecaseabornpara generar unmapa de calorque represente el número de pasajeros por mes en los años 1949-1960
Abra un cuaderno
Jupytere importe los módulos dePythonnecesarios:
import seaborn as sns
Importe el conjunto de datos de
seaborn:
flights_df = sns.load_dataset("flights")
flights_df.head()
| year | month | passengers | |
|---|---|---|---|
| 0 | 1949 | Jan | 112 |
| 1 | 1949 | Feb | 118 |
| 2 | 1949 | Mar | 132 |
| 3 | 1949 | Apr | 129 |
| 4 | 1949 | May | 121 |
Ahora tenemos que hacer pivotar el conjunto de datos sobre las variables requeridas utilizando la función
pivot()antes de generar el mapa de calor. La funciónpivottoma primero como argumentos la característica que se mostrará en filas, luego la que se muestra en columnas y, por último, la característica cuya variación nos interesa observar. Utiliza los valores únicos de los índices/columnas especificados para formar los ejes delDataFrameresultante
df_pivoted = flights_df.pivot(index="month", columns="year", values="passengers")
ax = sns.heatmap(df_pivoted)
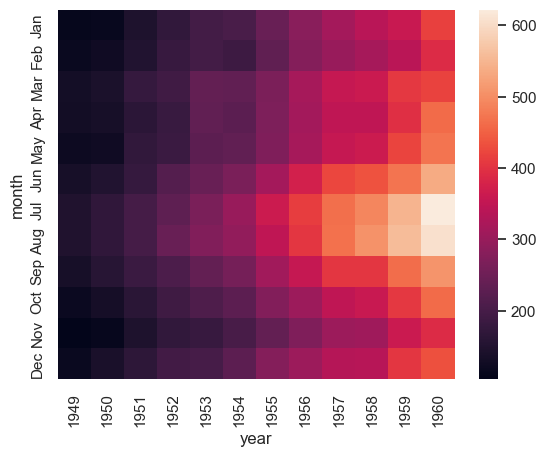
Observación: Aquí podemos observar que el número total de vuelos anuales aumentó de forma constante desde 1949 a 1960. Además, los meses de julio y agosto parecen tener el mayor número de vuelos (en comparación con el resto de los meses) en todos los años de observación.
Utilice la opción
clustermappara agrupar filas y columnas:
ax = sns.clustermap(df_pivoted, col_cluster=False, row_cluster=True)
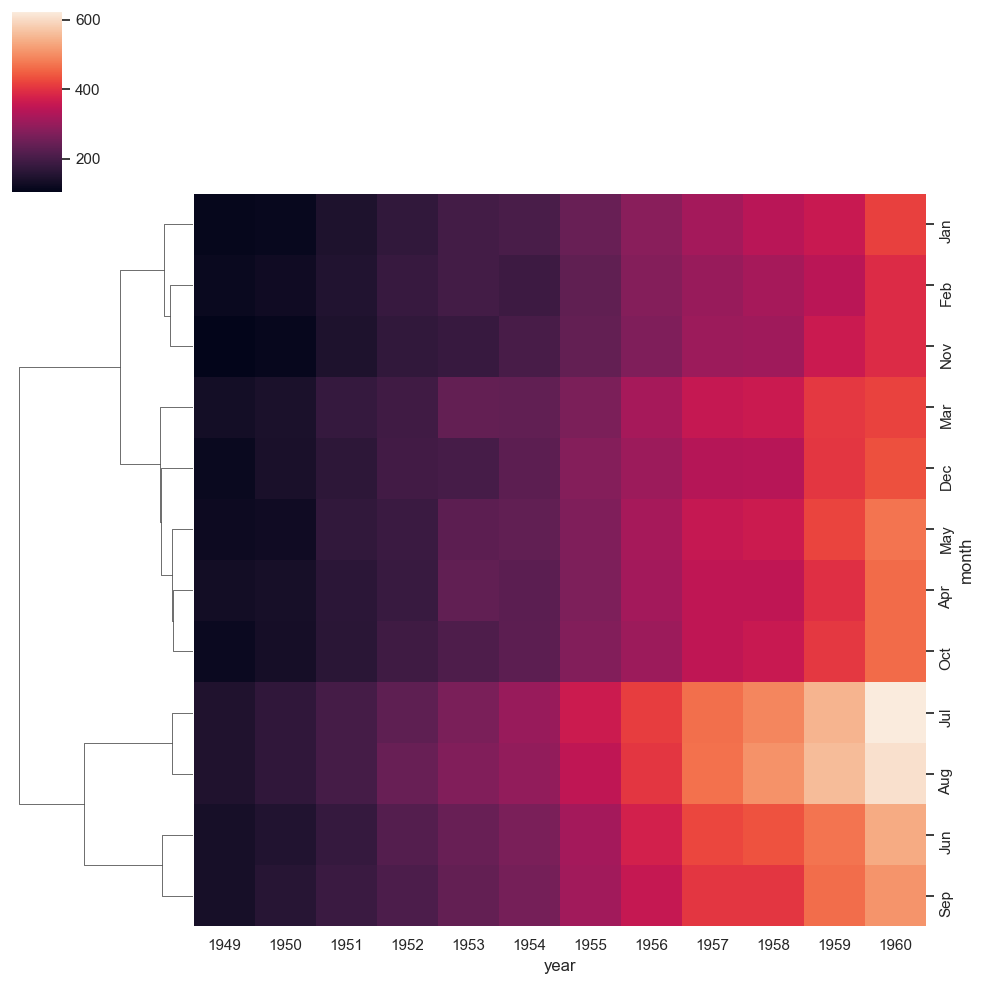
Observación: Nótese que el orden de los meses se ha reordenado en los gráficos, pero algunos meses (por ejemplo, julio y agosto) se han mantenido juntos debido a sus tendencias similares. Tanto en julio como en agosto, el número de vuelos aumentó de forma relativamente más drástica en los últimos años hasta 1960. ¿Cómo se calcula la similitud entre filas y columnas? La respuesta es que depende de la métrica de distancia
Establecer la métrica como euclidiana
ax = sns.clustermap(df_pivoted, col_cluster=False)
Cambiar la métrica a correlación
ax = sns.clustermap(df_pivoted, row_cluster=False, metric='correlation')
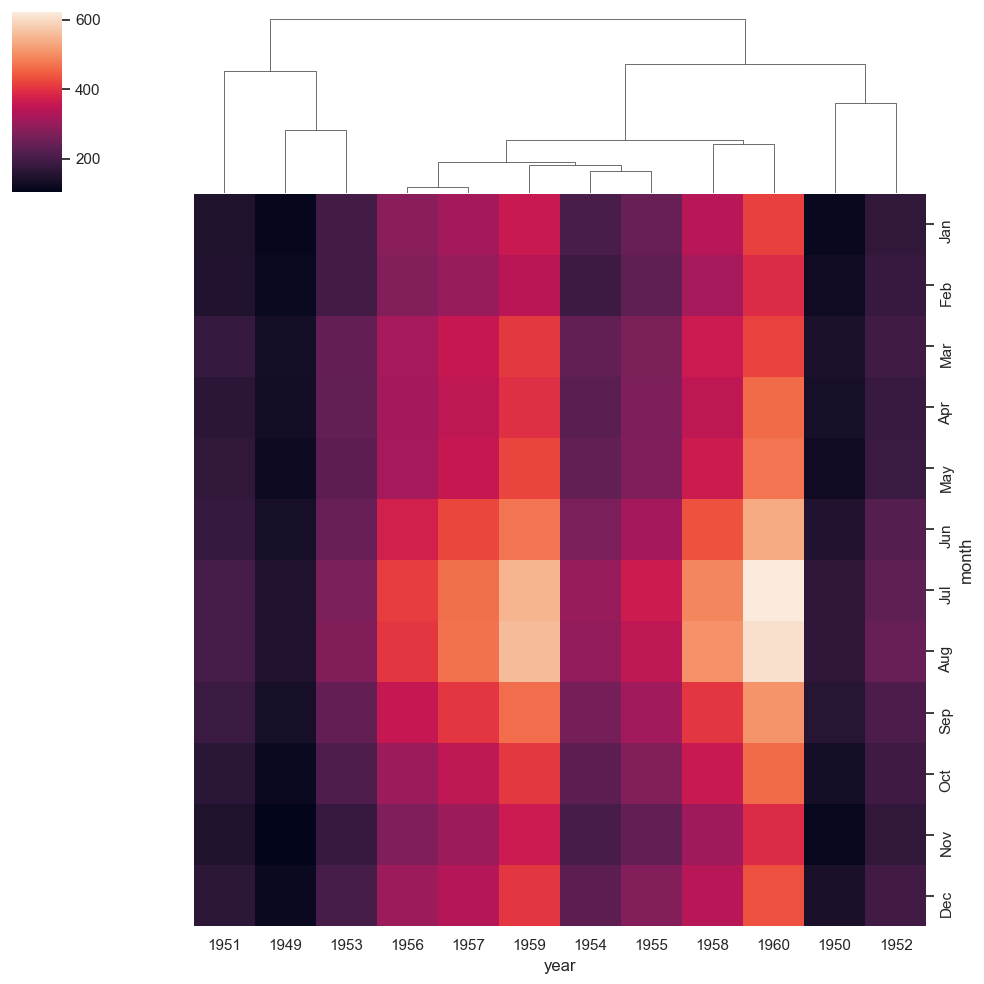
Observación: Al leer sobre la métrica de la distancia, aprendemos que define la distancia entre dos filas/columnas. Sin embargo, si nos fijamos bien, vemos que el mapa de calor también agrupa no sólo filas o columnas individuales, sino también grupos de filas y columnas. filas o columnas individuales. Aquí es donde entra en juego la vinculación.
Creación de vínculos en mapas de calor estáticos#
Si definimos la distancia entre dos clusters como la
distancia entre los dos puntos de los clusters más cercanosentre sí, la regla se denomina enlace único (single linkage).Si la regla es definir la distancia entre dos clusters como la
distancia entre los puntos más alejados entre sí, se denomina vinculación completa (complete linkage).Si la regla es definir la distancia como
la media de todos los posibles pares de filas en los dos clústeres, se denomina vinculación media (average linkage).
En este ejercicio, generaremos un mapa de calor y comprenderemos el concepto de enlace único, completo y promedio en los mapas de calor utilizando el conjunto de datos
flights.
Abra un cuaderno
Jupytere importe los módulos dePythonnecesarios:
import seaborn as sns
Importe el conjunto de datos de
seaborn:
flights_df = sns.load_dataset("flights")
flights_df.head()
| year | month | passengers | |
|---|---|---|---|
| 0 | 1949 | Jan | 112 |
| 1 | 1949 | Feb | 118 |
| 2 | 1949 | Mar | 132 |
| 3 | 1949 | Apr | 129 |
| 4 | 1949 | May | 121 |
Ahora necesitamos pivotar el conjunto de datos en las variables requeridas utilizando la función
pivot()antes de generar el mapa de calor:
df_pivoted = flights_df.pivot(index="month", columns="year", values="passengers")
ax = sns.heatmap(df_pivoted)
Enlaza los mapas de calor utilizando el código que sigue
ax = sns.clustermap(df_pivoted, col_cluster=False, metric='correlation', method='average')
ax = sns.clustermap(df_pivoted, row_cluster=False, metric='correlation', method='complete')
ax = sns.clustermap(df_pivoted, row_cluster=False, metric='correlation', method='single')
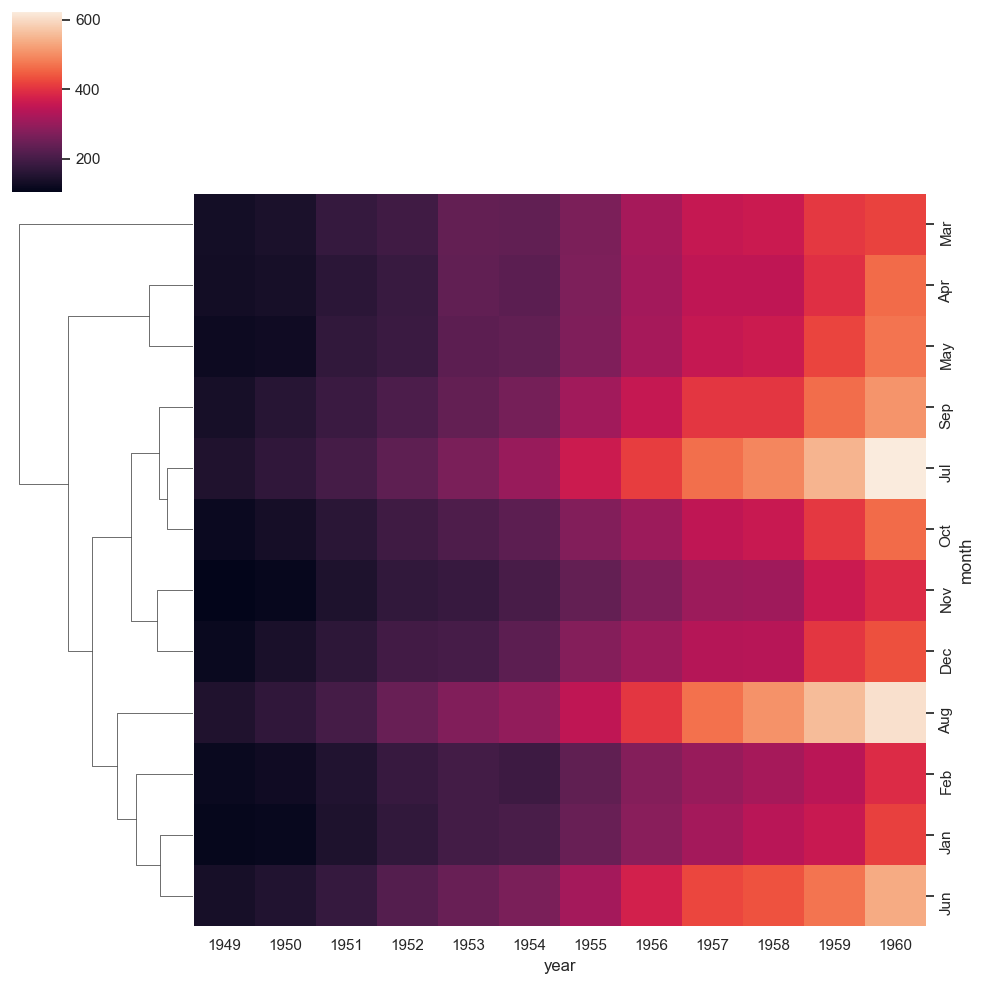
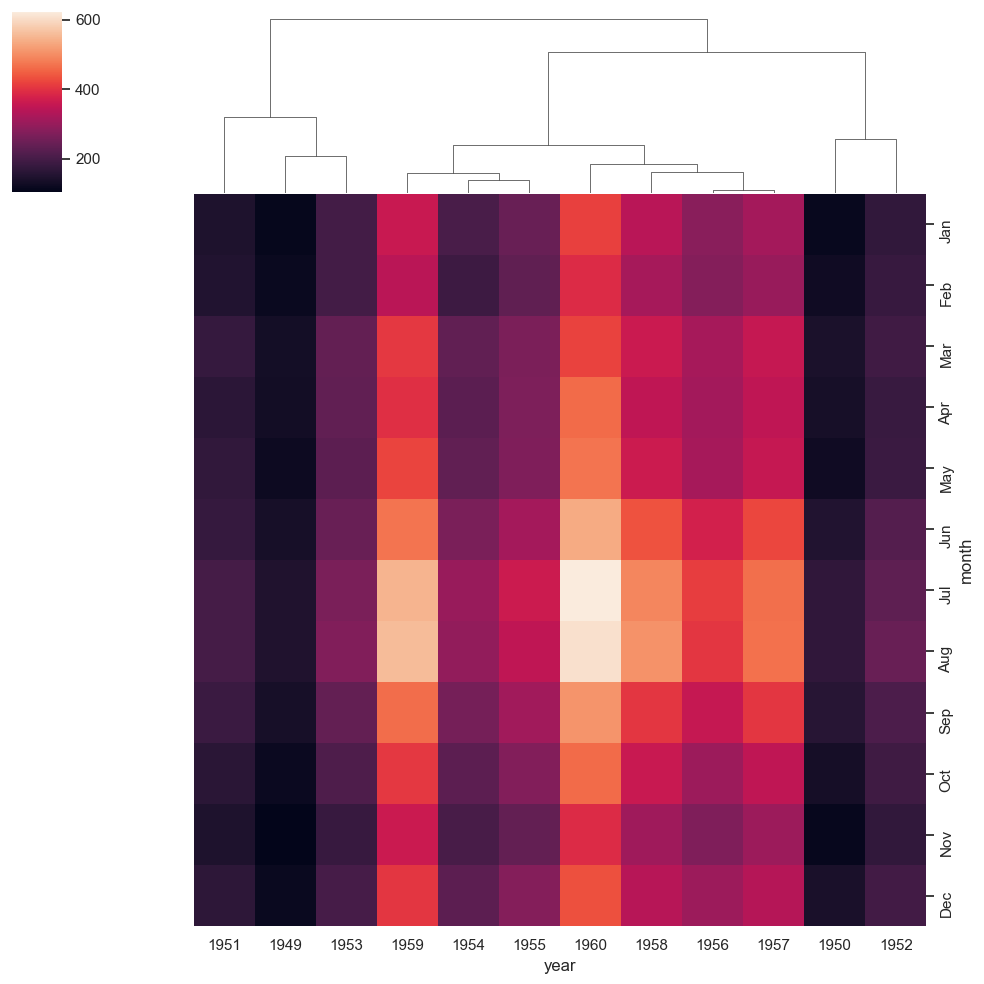
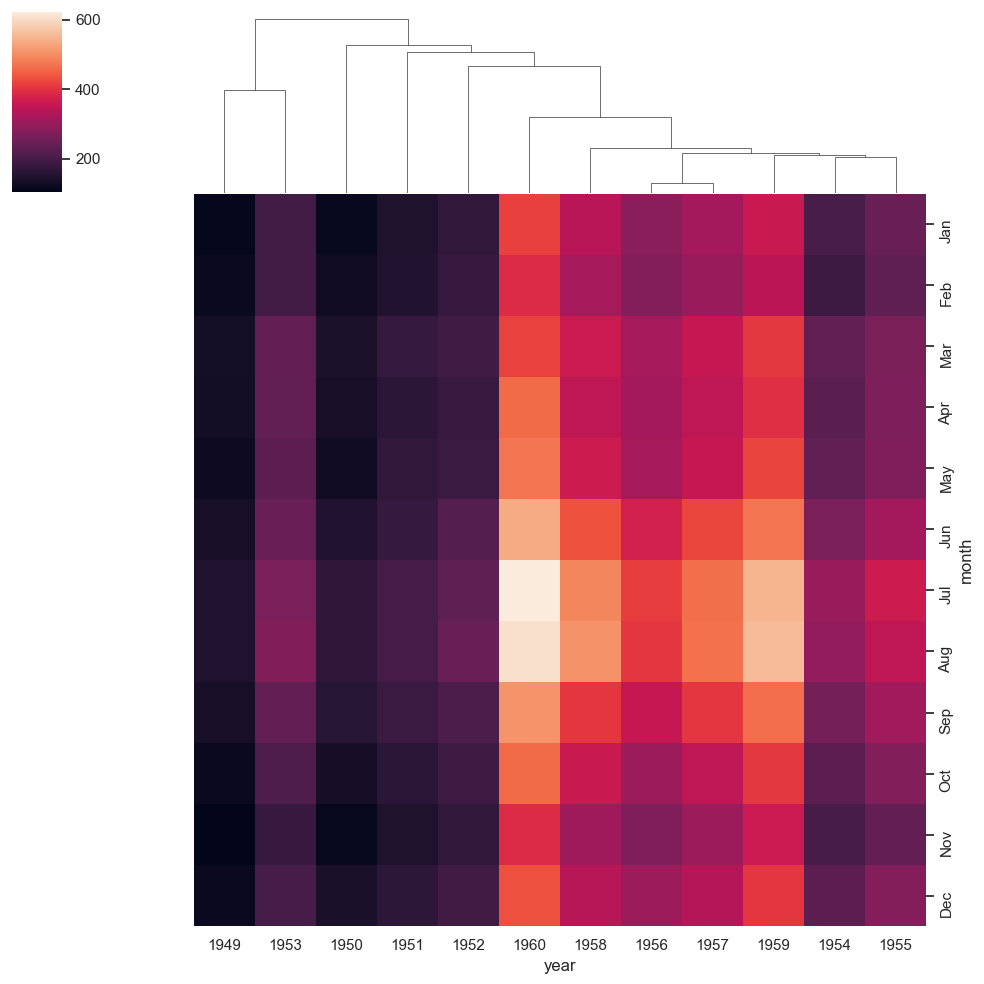
Observación Los mapas de calor también son una buena forma de visualizar lo que ocurre en un espacio 2D. Por ejemplo, pueden utilizarse para mostrar dónde hay más acción en el campo en un partido de fútbol. Del mismo modo, en un sitio web, los mapas de calor se pueden utilizar para mostrar las áreas que son más más frecuentadas por los usuarios.
Creación de gráficos para representar estadísticas#
Cuando los conjuntos de datos son enormes, a veces resulta útil observar las estadísticas de resumen de una serie de características diferentes y hacerse una idea preliminar del conjunto de datos. Por ejemplo, las
estadísticas de resumen de cualquier característica numérica incluyen medidas de tendencia central, como la media, y medidas de dispersión, como la desviación estándar. Los histogramas muestran la distribución de una característica dada en los datos, podemos hacer un gráfico un poco más informativo mostrando algunas estadísticas de resumen en el mismo gráfico.
Histograma revisado#
Importar los módulos de
Pythonnecesarios; cargar el conjunto de datos; elegir el número de intervalos y si la estimación de la densidad del kernel debe mostrarse o no; usar el color rojo para mostrar media utilizando una línea recta en el eje \(x\) (paralela al eje \(y\)); definir la ubicación de la leyenda. Además, podemos agregar la legenda, usando los simbolo correspondientes a cada medida de tendencia central (\(\overline{x},~\tilde{x}\)) usando Latex. Pare esto debe tener instalado en su computadoratextlivee importarplt.rcParams['text.usetex'] = True.
plt.rcParams['text.usetex'] = True
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
mpg_df = sns.load_dataset("mpg")
ax = sns.histplot(mpg_df.weight, bins=50, kde=False)
plt.axvline(x=np.mean(mpg_df.weight), color='red', label=r'$\overline{x}$')
plt.axvline(x=np.median(mpg_df.weight), color='orange', label=r'$\tilde{x}$')
ax.set_xlabel(r'\textbf{weight}', fontsize=16)
ax.set_ylabel(r'\textbf{Frequency}', fontsize=16)
plt.legend(loc='upper right', fontsize = 20);
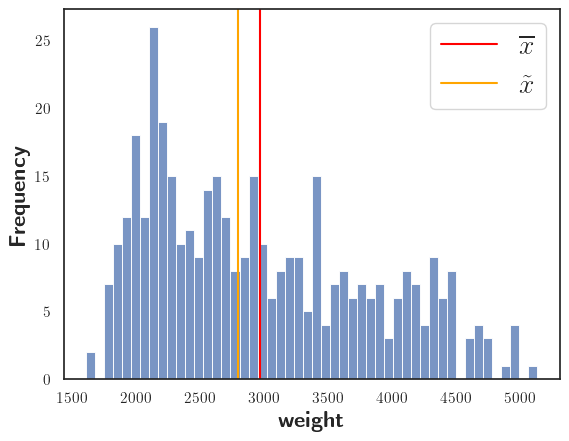
Este histograma muestra la distribución de la característica
weightjunto con la media y la mediana. Observe que la media no es igual a la mediana, lo que significa que la característica no está distribuida normalmente. En este caso presenta un sesgo a la derecha, tal como se muestra en la figura.
Creación y exploración de un gráfico de caja#
Los gráficos de caja son una forma excelente de examinar la relación entre las estadísticas de resumen de una característica numérica en relación con otras características categóricas. En este ejercicio crearemos un diagrama para establecer la relación entre
model_yearandmileageusing thempgdataset. Analizaremos la eficiencia de los vehículos medida en millas por galón a lo largo de un periodo de años. Para ello, vamos a seguir los siguientes pasos
Importe la libreria
seaborn
import seaborn as sns
Cargue el
dataset
mpg_df = sns.load_dataset("mpg")
mpg_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 398 entries, 0 to 397
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 mpg 398 non-null float64
1 cylinders 398 non-null int64
2 displacement 398 non-null float64
3 horsepower 392 non-null float64
4 weight 398 non-null int64
5 acceleration 398 non-null float64
6 model_year 398 non-null int64
7 origin 398 non-null object
8 name 398 non-null object
dtypes: float64(4), int64(3), object(2)
memory usage: 28.1+ KB
Crear un diagrama de cajas
sns.boxplot(x='model_year', y='mpg', data=mpg_df);
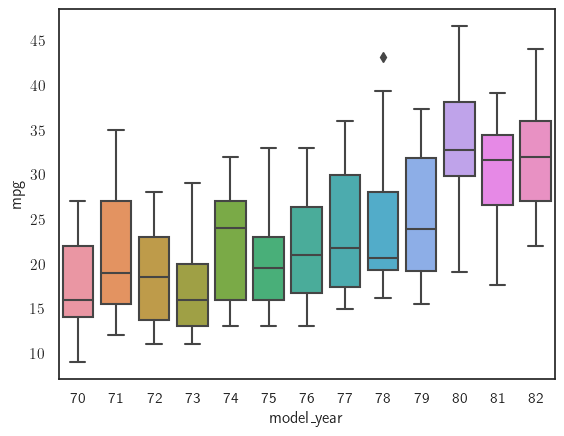
Como podemos ver, los límites de la caja indican el rango intercuartil, el límite superior marca el cuartil del 25% y el límite inferior el cuartil del 75%. La línea horizontal dentro de la caja indica la mediana. Cualquier punto aislado fuera de los bigotes (las barras en forma de \(T\) por encima y por debajo de la caja) marca los valores atípicos, mientras que los propios bigotes muestran los valores mínimos y máximos que no son valores atípicos. Aparentemente,
las millas por galón mejoraron sustancialmente en los 80 en comparación con los 70.
Añadamos otra característica a nuestro
mpg_dfque denote si el coche fuefabricado en los 70 o en los 80. Modifica el DataFramempgcreando una nueva característica,model_decade
import numpy as np
mpg_df['model_decade'] = np.floor(mpg_df.model_year/10)*10
mpg_df['model_decade'] = mpg_df['model_decade'].astype(int)
mpg_df[['mpg', 'model_decade']].head()
| mpg | model_decade | |
|---|---|---|
| 0 | 18.0 | 70 |
| 1 | 15.0 | 70 |
| 2 | 18.0 | 70 |
| 3 | 16.0 | 70 |
| 4 | 17.0 | 70 |
Ahora, volvamos a dibujar nuestro gráfico de caja para ver la distribución de millas por galón en las dos décadas. Puede verificar si esta diferencia es significativa usando un test estadístico “
verifíquelo” (ver Mood’s median test).
sns.boxplot(x='model_decade', y='mpg', data=mpg_df);
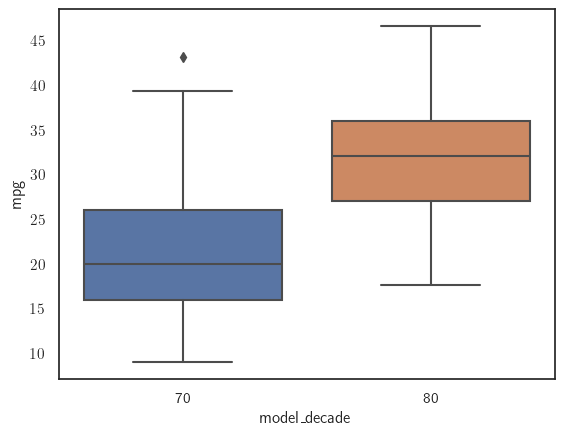
También podemos añadir otra característica, por ejemplo, la región de origen, y ver cómo afecta a la relación entre millas por galón y el tiempo de fabricación, las dos características que hemos estado considerando hasta ahora
Utiliza el parámetro
huepara agrupar por origen
sns.boxplot(x='model_decade', y='mpg', data=mpg_df, hue='origin');
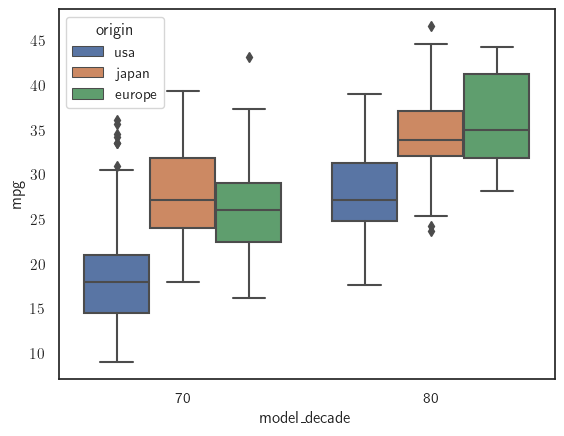
Como podemos ver, según el conjunto de datos,
mpg, en los años 70 y principios de los 80,Europa y Japón produjeron coches con mejor millas por galón que los Estados Unidos.
Creación de un gráfico de violín#
¿Y si pudiéramos obtener una pista sobre la distribución completa de una característica numérica específica agrupada por otras características categóricas? El tipo de técnica de visualización adecuada en este caso es un gráfico de violín. Un gráfico de violín es similar a un grafico de caja pero
incluye más detalles sobre las variaciones de los datos. En este ejercicio, utilizaremos el conjunto de datosmpgy generaremos un gráfico de violín que represente la variación detallada delmillaje (mpg)en función demodel_decadey la región de origen
Importe la libreria
seaborn
import seaborn as sns
Cargue el
dataset
mpg_df = sns.load_dataset("mpg")
Generar el gráfico de violín utilizando la función
violinplotenseaborn
import numpy as np
mpg_df['model_decade'] = np.floor(mpg_df.model_year/10)*10
mpg_df['model_decade'] = mpg_df['model_decade'].astype(int)
sns.violinplot(x='model_decade', y='mpg', data=mpg_df, hue='origin');
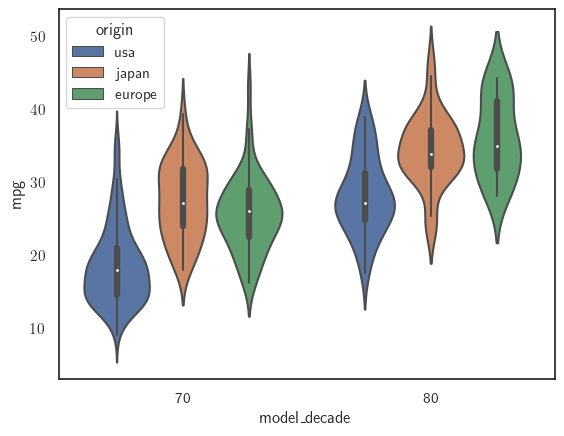
Podemos ver aquí que, durante los años 70, mientras que la mayoría de los vehículos de EE.UU. tenían en promedio millas por galón de 19 mpg, los vehículos de Japón y Europa tenían en promedio millas por galón de alrededor de 27 y 25
mpg. Mientras que las millas por galón de los vehículos en Europa y Japón aumentó entre 7 y 8 puntos en los años 80, el kilometraje medio de los vehículos en EE.UU. seguía siendo similar al de los vehículos en Japón y Europa en la década anterior.
Ejercicio para entregar#
Estadísticos: Seguiremos trabajando con el conjunto de datos de 120 años de historia olímpica adquirido por Randi Griffin en Randi Griffin
Como especialista en visualización, su tarea consiste en crear dos parcelas para los ganadores de medallas de 2016 de cinco deportes: atletismo, natación, remo, fútbol y hockey
Crea un gráfico utilizando una técnica de visualización adecuada que presente de la mejor manera posible el patrón global de las características de
heightyweightde los ganadores de medallas de 2016 de los cinco deportes.
Crea un gráfico utilizando una técnica de visualización adecuada que presente de la mejor manera posible la estadística de resumen para la altura y el peso de los jugadores que ganaron cada tipo de medalla (oro/plata/bronce) en los datos.
Utilizar su creatividad y sus habilidades para sacar conclusiones importantes de los datos
Pasos importantes
Descargue el conjunto de datos y formatéelo como un
pandasDataFrame
Filtrar el DataFrame para incluir únicamente las filas correspondientes a los ganadores de medallas de 2016 en los deportes mencionados en la descripción de la actividad
Observe las características del conjunto de datos y anote su tipo de datos: ¿son categóricos o numéricos?
Evaluar cuál sería la visualización adecuada para que un patrón global represente las características de
heightyweight
Evaluar cuál sería la visualización adecuada para representar las estadísticas resumidas de las características de
heightyweighten función de las medallas, separadas además por género de los atletas.