
Introducción a PostreSQL y Docker#
Herramienta de administración de bases de datos: DBeaver#
DBeaveres una herramienta de base de datos multiplataforma gratuita para desarrolladores, administradores de bases de datos, analistas y todas las personas que necesiten trabajar con bases de datos. Soporta todas las bases de datos populares:MySQL, PostgreSQL, SQLite, Oracle, DB2, SQL Server, Sybase, MS Access, Teradata, Firebird, Apache Hive, Phoenix, Presto, etc.Para instalar
DBeaverusar el instalador correspondiente del siguiente link: (ver DBeaver). Para el caso de Windows el instalador a descargar aparece en la siguiente imagen:
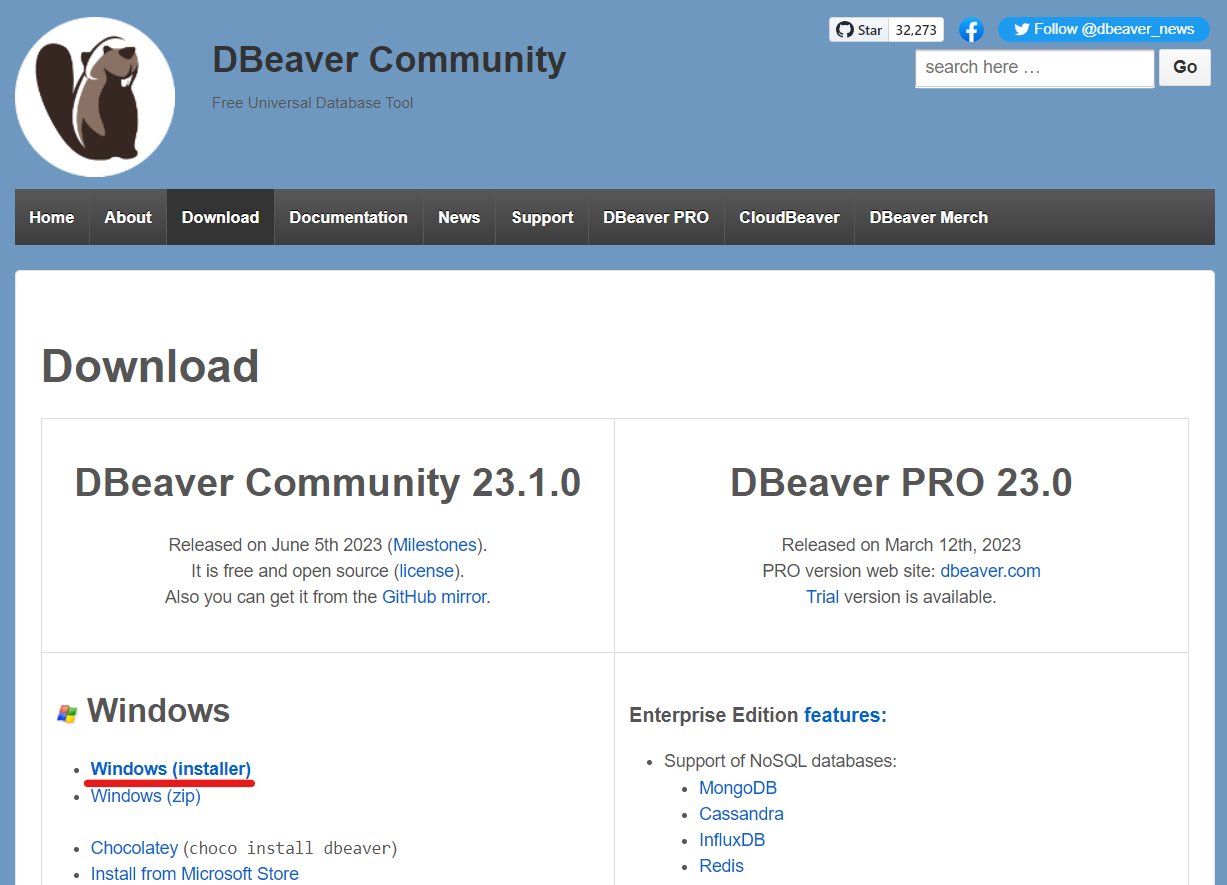
Fig. 3 Instalador de DBeaver para Windows y Mac.#
Siga los pasos de instalación. Procederemos ahora ahora con la instalación de
Dockery luego retomaremos el uso deDBeaverpara administrar la base de datos a crear.
Instalación y uso de Docker#
Dockeres una plataforma de software que le permitecrear, probar e implementar aplicaciones rápidamente.Dockerempaqueta software en unidades estandarizadas llamadascontenedoresque incluyen todo lo necesario para que el software se ejecute, incluidas bibliotecas, herramientas de sistema, código y tiempo de ejecución. ConDocker, puede implementar y ajustar la escala de aplicaciones rápidamente en cualquier entorno con la certeza de saber que su código se ejecutará.Dockerle proporciona una manera estándar de ejecutar su código.Dockeres unsistema operativo para contenedores. De manera similar a cómo unamáquina virtual virtualiza(elimina la necesidad de administrar directamente) el hardware del servidor,los contenedores virtualizan el sistema operativo de un servidor.Dockerse instala en cada servidor y proporciona comandos sencillos que puede utilizar para crear, iniciar o detener contenedores. Para instalarDockeruse el siguiente link (ver Docker Installer).Tenga en cuenta que debe instalar Docker como administrador.

Fig. 4 Instalador de Docker para Windows, Mac y Linux.#
Luego de instalar
Docker, puede iniciar la aplicación, ejecutandoDocker Desktop, el cual mantendrá ejecutando un proceso de virtualización. La siguiente será la interfaz gráfica que visualizará al ejecutarDocker
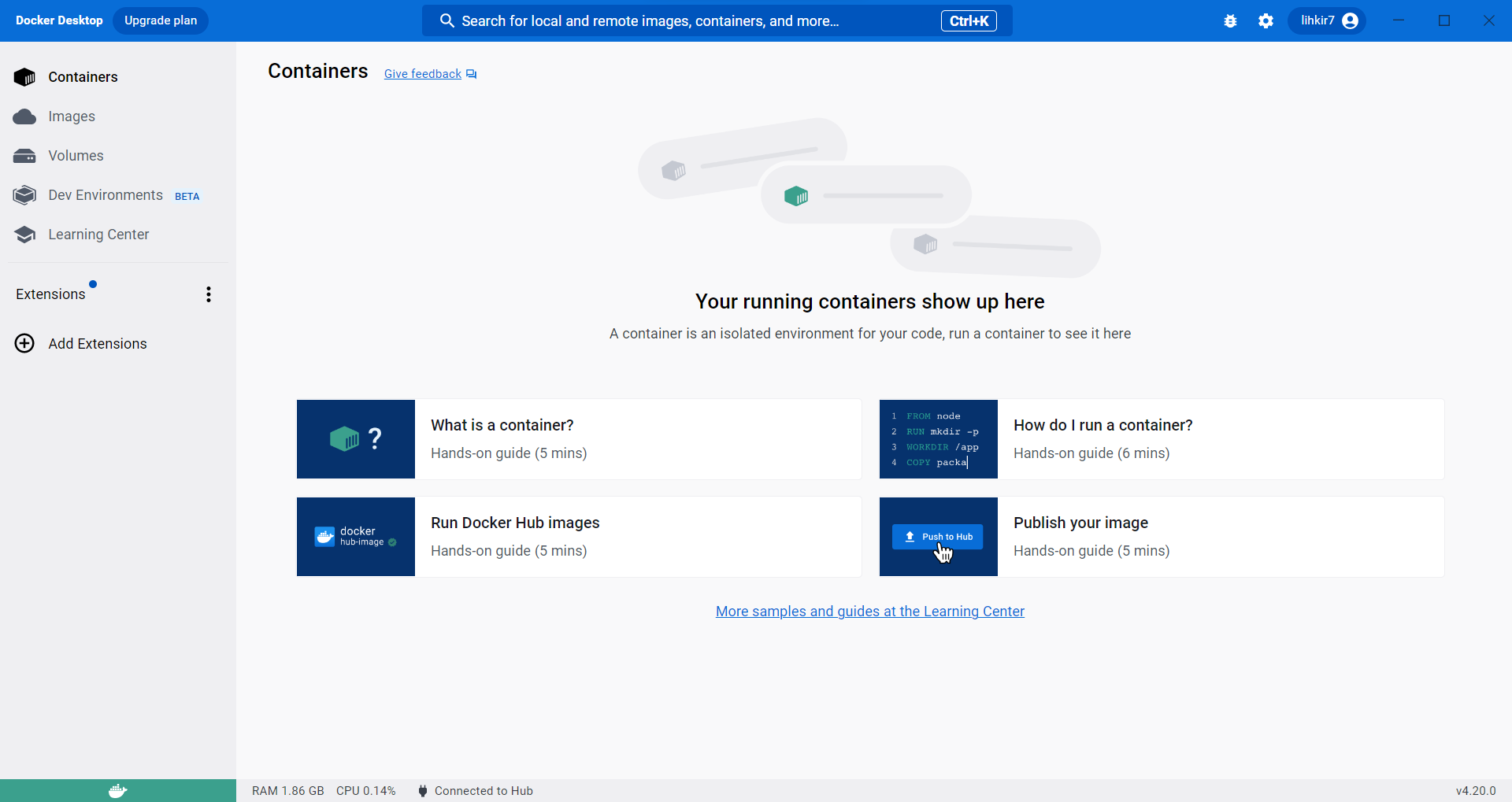
Fig. 5 Aplicación Docker Desktop para Windows.#
Inicialmente utilizaremos
Dockerdesde consola. Para esto abrimos una terminal deWindows PowerShellusando el comandoWindow + Ro directamente desde su terminal buscando el logo deWindows PowerShell. Luego de esto vamos adescargar el contenedor de PostgreSQLutilizando el comando siguiente (ver Docker PostgreSQL). Nótese que el contenedor deDockerparaPostgreSQLse llamapostgres.
docker pull postgres
Si desea eliminar la imagen
postgresde docker, puede usar el comando
docker rmi postgres
En
docker hub(ver Docker Hub) podrás encontrar otro tipo de contenedores, por ejemplo para:Engines, Apache, Java, C#, Python, Go, etc,….
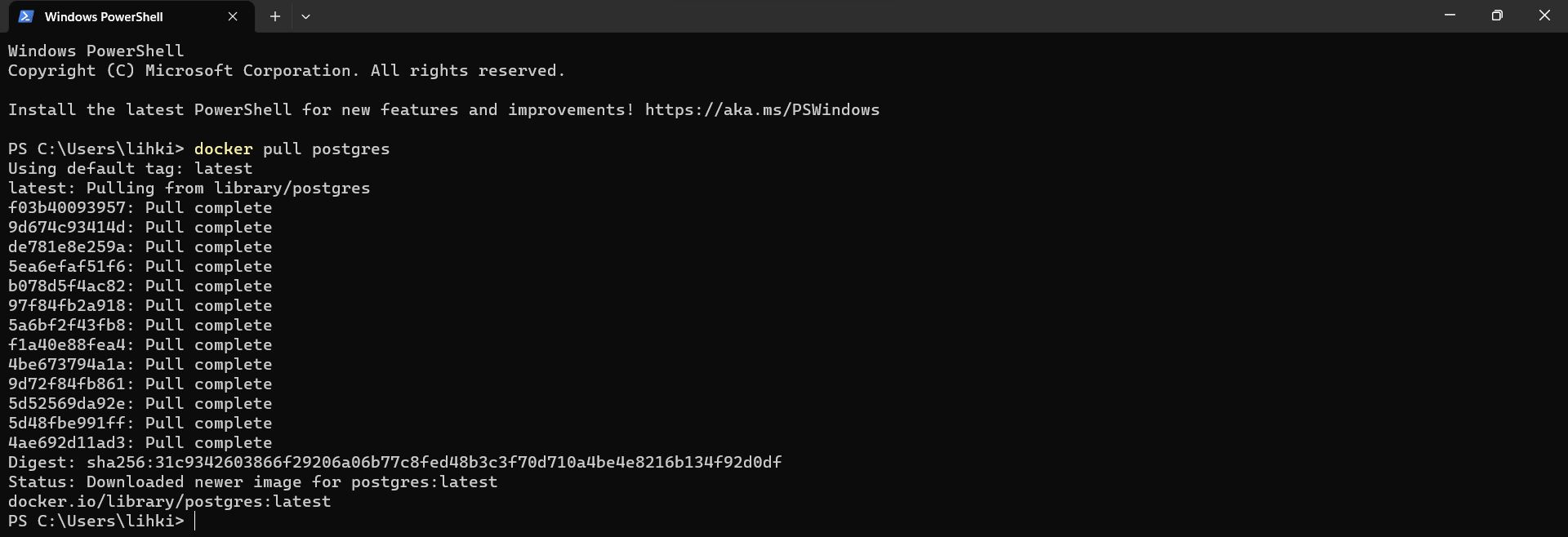
Fig. 6 Consola Windows PowerShell para ejecutar el cliente de Docker.#
El procedimiento anterior se encargará de descargar la última versión de
PostgreSQLen nuestro computador (imagen de Docker). Este es solo un proceso de instalación, el cual nospermitirá posteriormente, ejecutar múltiples instancias del contenedor para bases de datos.
Para crear una base de datos vamos a necesitar como
mínimo una contraseñapara inicializarla, para esto debemos usar el flag:POSTGRES_PASSWORD. Podemos también asignarle un usuario a la base de datos, en caso de no hacerlo, el usuario por defecto creado porPostgreSQLserápostgres. Para proceder entonces utilizamos el siguiente comando:
docker run -e POSTGRES_PASSWORD=password postgres
El comando
runejecutará una instancia para nuestra nueva base de datos. El flagees utilizado para agregar variables de entorno (ver Docker PostgreSQL). En este caso, vamos a utilizar la variablePOSTGRES_PASSWORDy asignaremos a esta la contraseña deseada, en este caso, a manera de ejemplo, utilizaremospasswordcomo contraseña. Al final de la instancia, podrá observar un mensaje indicando que el sistema ya esta listo para aceptar conexiones.Esta ventana la debemos de dejar ejecutándose.
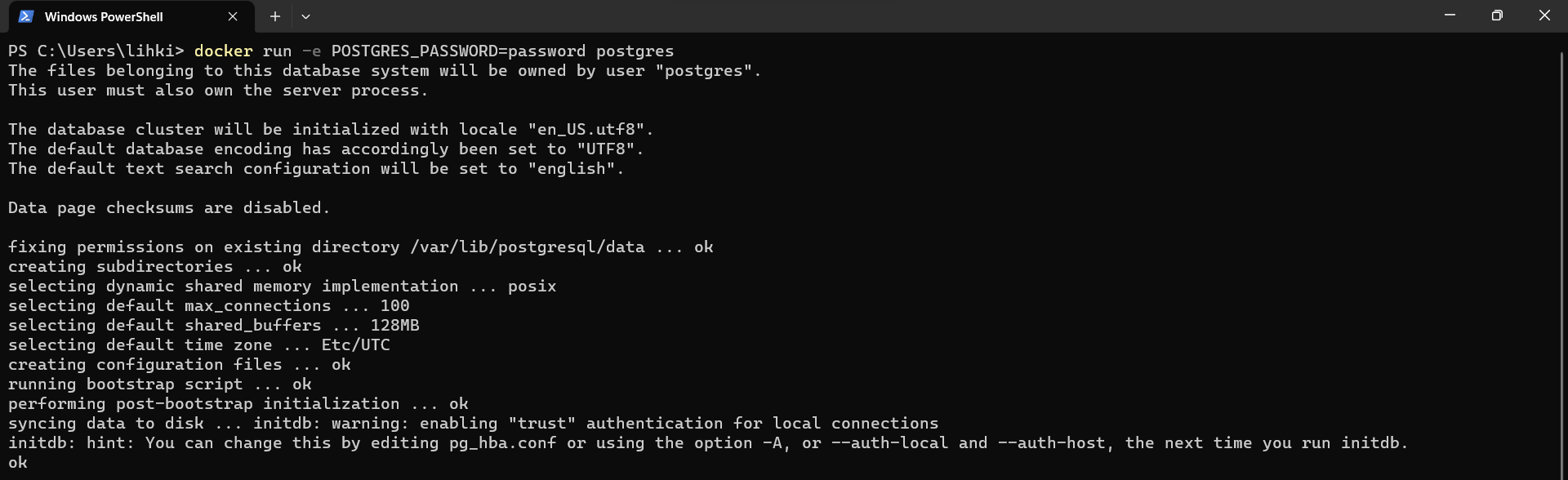
Fig. 7 Creación de instancia para la base de datos PostgreSQL.#
En
Docker Desktoppodrá visualizar la instancia dePostgreSQLque el contenedor ha creado, la cual tiene un nombre que generó de forma aleatoria.
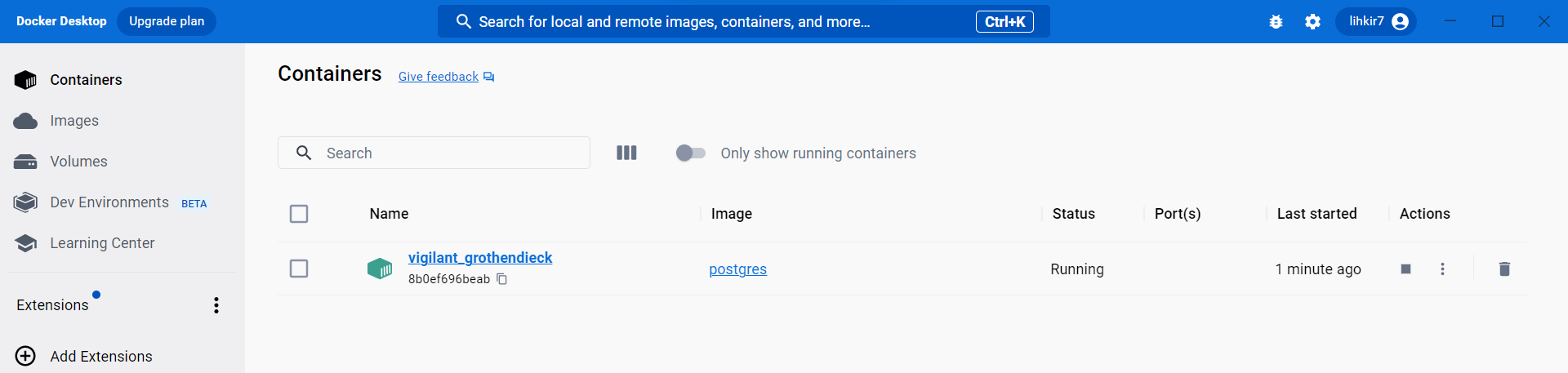
Fig. 8 Instancia de PostgreSQL con nombre random visualizada en Docker Desktop.#
El siguiente paso es conectarnos a la instancia de
PostgreSQLcreada por el contenedor. Para esto abrimos una nueva consola deWindows PowerShellpara conectarnos al contenedor que se está ejecutando. Antes, verificamos cual es el nombre del contenedor (adjetivo+nombre aleatorio) creado desde la consola o deDocker Desktop
docker ps
docker psnos mostrará en consola losprocesos que está ejecutando nuestro contenedor. En este caso nos aparece el único contenedor creado hasta el momento, cuyo nombre es:vigilant_grothendieck. Este nombre puede ser cambiado utilizando las variables de entorno.

Fig. 9 Procesos siendo ejecutados por nuestro contenedor Docker#
Procedemos ahora si a conectarnos a la instancia de
PostgreSQLcreada por el contenedor. Para esto utilizaremos el siguiente comando:
docker exec -it vigilant_grothendieck bash
docker exec se encarga de
ejecutar un comando de forma interactiva en un contenedor en ejecución, en este caso, el contenedor paraPostgreSQLpreviamente instanciado, utilizando el programabashdentro del contenedor. Luego de hacerlo, podemos conectarnos apostgresdesde elbashutilizando:
psql -U postgres --password
psqles la línea de comandos dePostgreSQL. Por otro lado,postgreses el nombre de usuario que se creo por defecto al instanciar la base de datos. Usamos el flag--passwordparaagregar por consola nuestra contraseñacreada para la base de datos. Podrá observar que se ha conectado a la instancia dePostgreSQLy puede realizar a esta, las consultas que desee. Para salir del contenedor puede presionarCtrl + D.Podemos crear una base de datos de prueba, para verificar que el funcionamiento de nuestro contenedor. Para eso usamos la siguiente orden:
CREATE DATABASE sql_test;
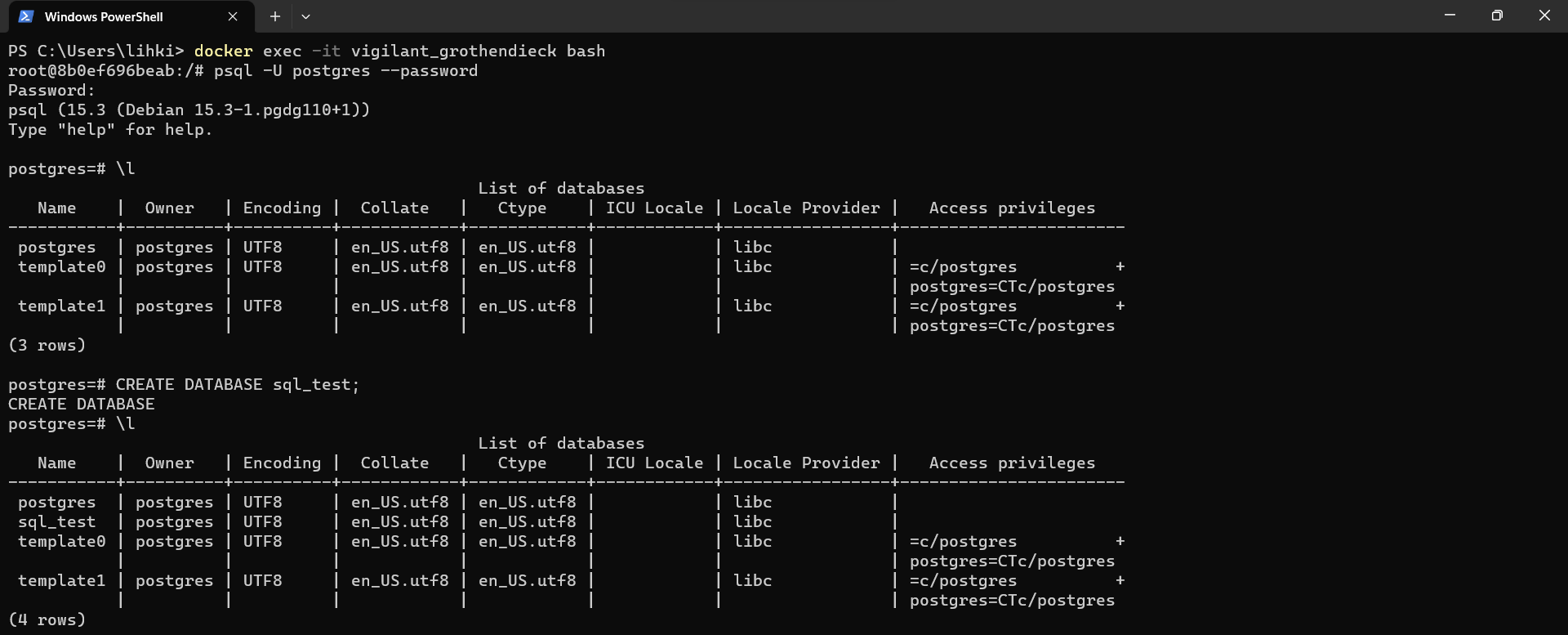
Fig. 10 Consulta y creación de base de datos test, en la instancia de PostgreSQL en Docker.#
Ahora procederemos a estudiar como podemos
eliminar un contenedor. Por ahora, tenemos nuestro contenedor ejecutándose, al usardocker pspodremos verlo listado. En caso de que la lista de contenedores activos está vacía (contenedor no ejecutado), si utilizamosdocker ps -apodremos visualizar los contenedores creados, aún cuando no se están ejecutando.Para eliminar contenedores creados a priori podemos utilizar el comando
docker rmseguido del identificador del contenedor, tal como se muestra a continuación. Antes puede salir del bash de PostgreSQL presionandoCtrl + Ddos veces. Si le arroja una respuesta de error del daemon, procedemos antes a detener el contenedor usandodocker stop vigilant_grothendieck.
docker rm vigilant_grothendieck

Fig. 11 Lista de contenedores creados por Docker. Eliminación de contenedor.#
Podemos volver a recrear lo realizado previamente, pero ahora sin necesidad de instalar el contenedor de
PostgreSQLcomo se realizó al inicio, pues ya el instalador fue descargado, el cual podemos reutilizar

Fig. 12 Imágenes de Docker instaladas.#
Ejecutemos nuevamente el contenedor de
PostgreSQLpara poder crear una nueva base de datos, ahora con mas opciones para las variables de entorno, comousuario además de la contraseña y el nombre de la base de datos, de tal forma que puedan ser usados para conectarse a la base de datos. El comando-d(detach) puede ser utilizado paramantener el proceso en ejecución
docker run --name=undatascience-postgres -e POSTGRES_USER=undatascience -e POSTGRES_PASSWORD=password -e POSTGRES_DB=undatasciencedb -d postgres

Fig. 13 Creación de nueva base de datos nombrada undatascience-postgres en el contenedor de Docker.#
Si se desea eliminar el
Dockerque está en ejecución, primero debe detenerlo utilizando el comandodocker stopseguido del nombre del contenedor y luegodocker rm. La base de datos creada también se puede visualizar desdeDocker Desktop.
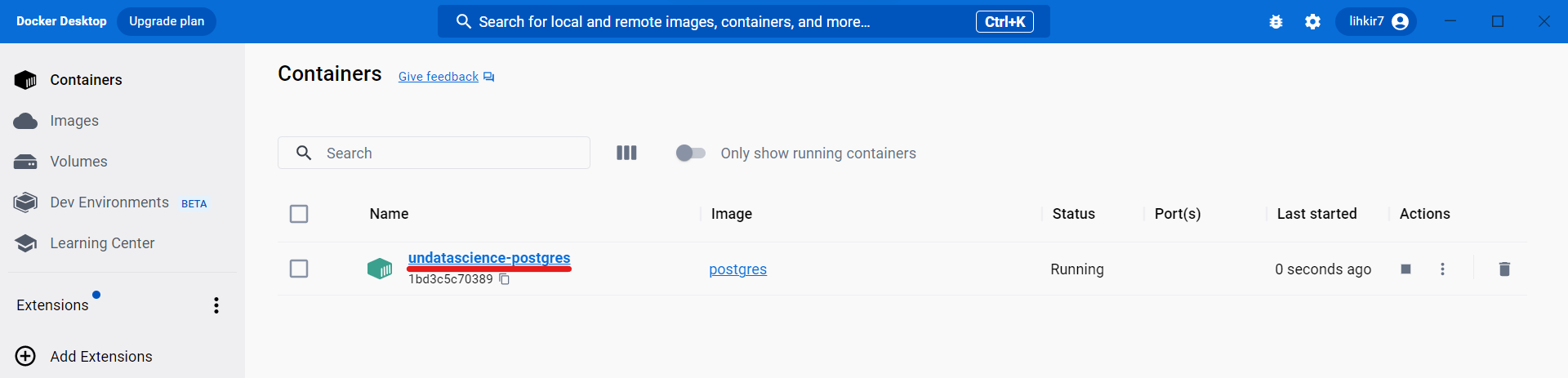
Fig. 14 Nueva base de datos creada administrada desde Docker Desktop.#
Podemos hacer el ejercicio de conectarnos nuevamente, de manera interactiva el nuevo contenedor creado utilizando el nombre con el que fue creado
undatascience-postgresy ejecutar dentro de este el programabash. Si el contenedor está apagado, debe iniciarse antes usandodocker start undatascience-postgres
docker exec -it undatascience-postgres bash

Fig. 15 Inicio del contenedor mediante su nombre, ejecutando el programa bash.#
Dentro de
bashpuede utilizar todos los atajos comúnmente usados, por ejemploCtrl + Lpara limpiar la consola,Ctrl + Dpara salir de la consola. Para verificar cual es la versión dePostgreSQLusamos el comando
psql --version
El mensaje arrojado en consola será del tipo:
psql (PostgreSQL) 15.3 (Debian 15.3-1.pgdg110+1). Si deseamos conectarnos a la base de datos recientemente creada, utilizaremos el siguiente comando en el que utilizamos: nombre de la base de datos y la contraseña asignada previamente.
Asignamos
nombres de usuario y base de datos. Lacontraseña será solicitada en el prompt.
psql -U undatascience --password --db undatasciencedb

Fig. 16 Conexión a base de datos. La contraseña es suministrada en el prompt.#
En caso de haber olvidado la contraseña, puede ingresar a
Docker Desktoppara recordarla y utilizarla
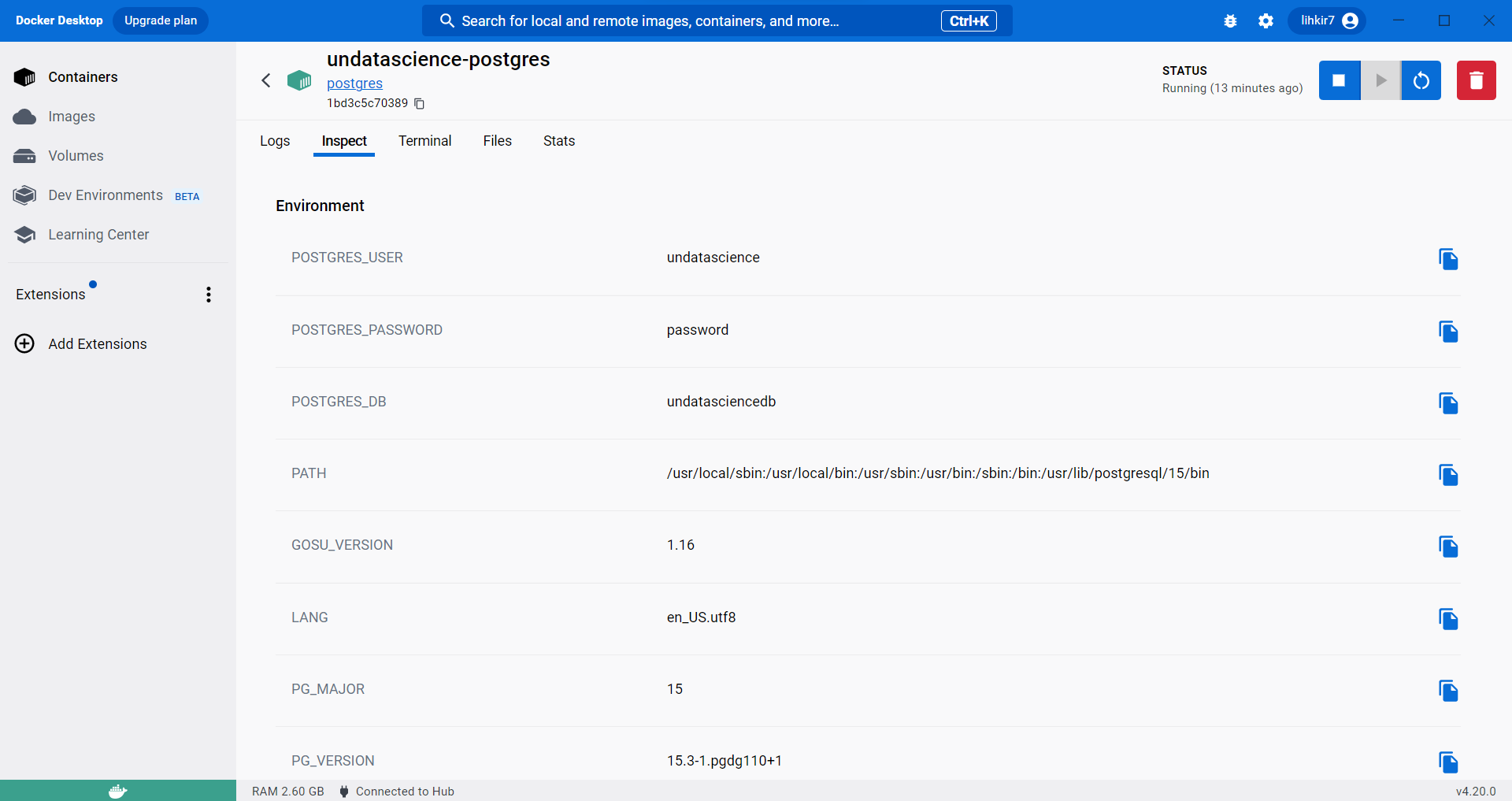
Fig. 17 Aplicación Docker Desktop para verificar credenciales de bases de datos.#
Para verificar que estamos dentro de la base de datos que hemos creado, podemos utilizar el siguiente comando (
SELECT CURRENT_USER;), el cual mostrará cual es elnombre del usuarioasociado a la base de datos a la cual nos hemos conectado
SELECT CURRENT_USER;

Fig. 18 Consulta a la base de datos para identificar el usuario actual.#
Ya dentro del bash asociado a nuestra base de datos, podemos usar comandos útiles de la consola interactiva de
PostgreSQL\h INSERT: Ver la ayuda con respecto a la sintaxis de nuestras consultasSQL, por ejemplo, el uso deINSERT.\dt: Mostrará la lista de las tablas de la base de datos que tengamos seleccionada.\?: Mostrará una lista de todos los comandos que podemos usar en la consola interactiva depostgresql. Presionarqpara salir de la lista.\conninfo: Mostrará la información de nuestra conexión activa.\l: Muestra la lista de instancias de bases de datos creadas
Cuando ejecutamos un contenedor (ver Fig. 13) obtenemos el puerto
5432/tcpel cual asigna por defectopostgres. En el caso de PostgreSQL, es típico usar el puerto5432si está disponible. Si no lo está, la mayoría de los instaladores elegirán el siguiente puerto libre, generalmente el5433.Este puerto solo funciona internamente dentro del contenedor. Sí deseamosacceder a este puerto desde fuera, necesitaremos exponerlo. Para esto usamos el flag-p 5432:5432. Ahora nos podemos conectar a nuestro contenedor dePostgreSQLdesde cualquier aplicación, por ejemplo desdeDBeaver.
docker run --name=undatascience-name -e POSTGRES_USER=undatascience-user -e POSTGRES_PASSWORD=undatascience-password -e POSTGRES_DB=undatascience-db -p 5432:5432 -d postgres
Fig. 19 Creación de contenedor con puerto expuesto para conexiones externas.#
Gracias a que hemos expuesto el contenedor, ahora podemos por medio de este conectarnos a la base de datos creada (
undatascience-db) desde cualquier aplicación, por ejemplo, usandoDBeaverel cual fue instalado al inicio de este capítulo (ver Fig. 3).
Nótese que aún sin tener instalado
PostgreSQLen nuestro computador, podemos utilizarDBeaverpara conectarnos a la base de datos creada enDocker. Para conectarnos a la base de datos creada, por ejemploundatascience-db, hacemos click enDatabase -> New Database Connectiony podremos observar la siguiente imagen, en la que seleccionaremosPostgreSQLy luego el botónNext.
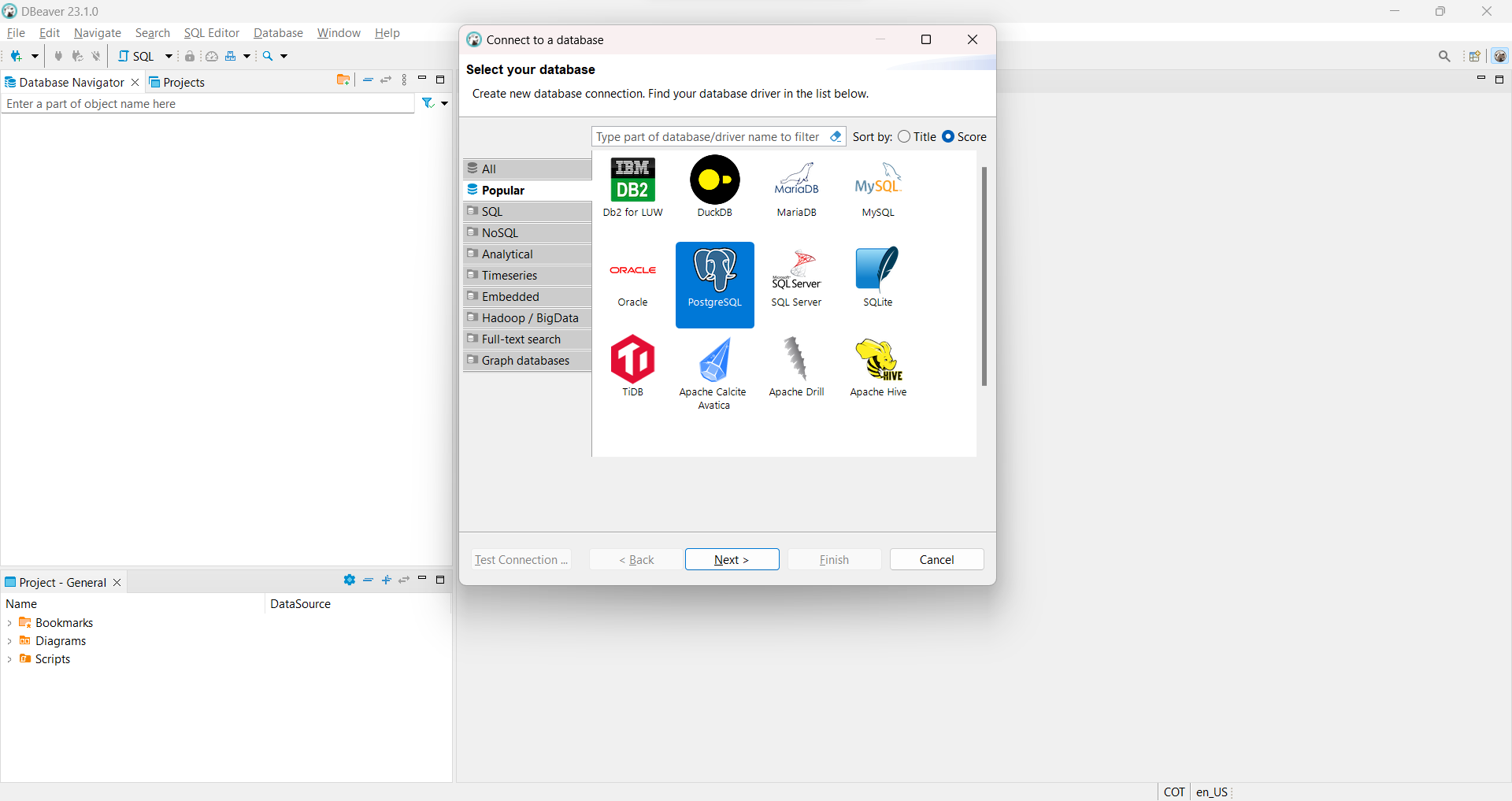
Fig. 20 Conexión a la base de datos creada en Docker, desde la aplicación DBeaver.#
En la ventana que se abrirá, vamos a
agregar las credenciales de la base de datos creada. Para conectarnos tendremos en cuenta lo siguiente:Host: localhostPort: 5432Database: undatascience-dbUsername: undatascience-userPassword: undatascience-password
Luego de ingresar las credenciales del paso anterior, puede probar la conexión utilizando el botón:
Test Connectiony luegoFinalizarpara guardar la conexión.Cuando realice la conexión por primera vez, podrá visualizar la siguiente imagen en la que se le solicita descargar e instalar algunos controladores necesarios para poder realizar la conexión a
PostgreSQL. SiDBeaverlesolicita instalar algunos drivers, haga click en descargar, esto le permitirá contar con las bibliotecas que le permitirán realizar la conexión.
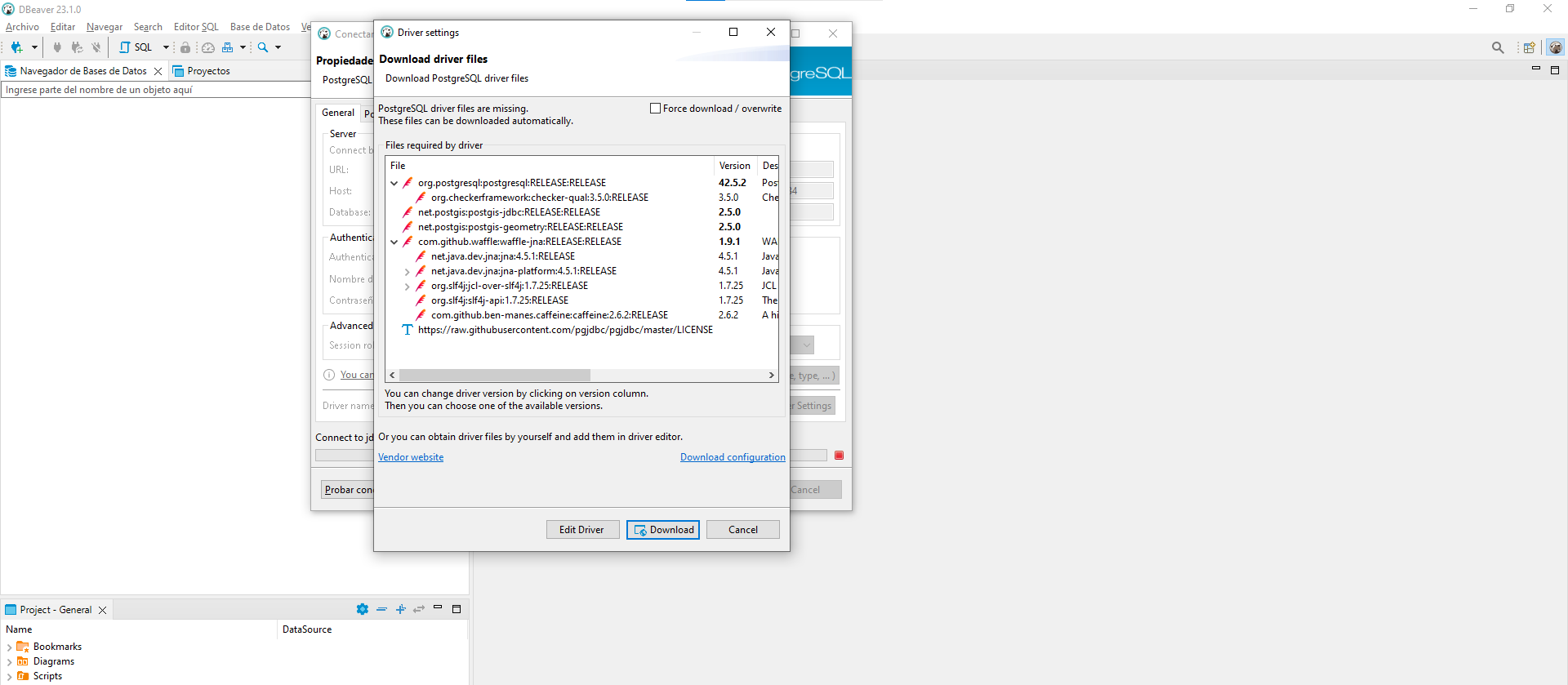
Fig. 21 Solicitud para instalar controladores necesarios para la conexión a PostgreSQL.#
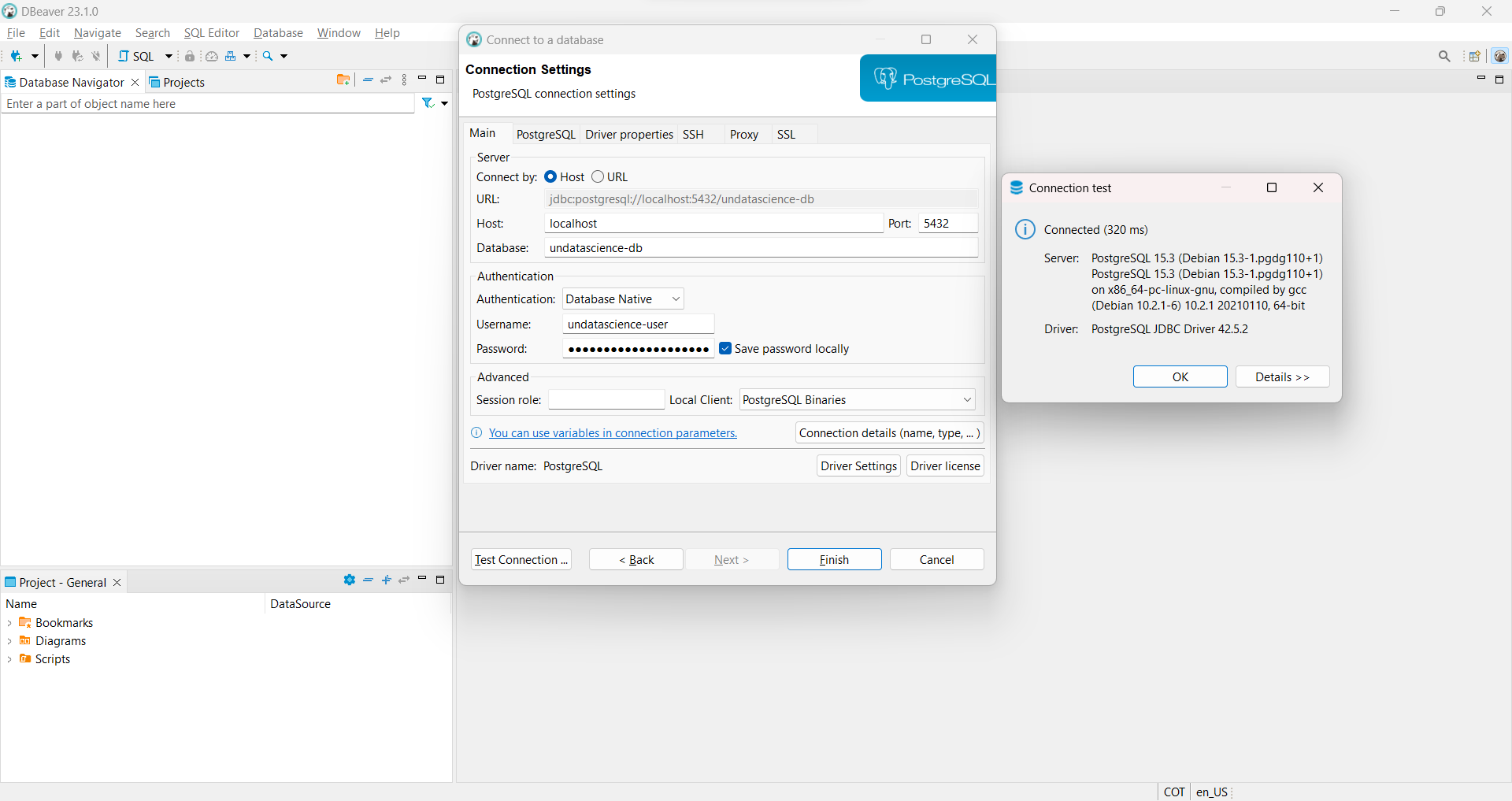
Fig. 22 Test de conexión a base de datos Docker desde DBeaver.#
Fig. 23 Base de datos guardarda en DBeaver disponible para ser gestionada.#
Podemos realizar una consulta de test, desde
DBeaver. Por ejemplo, si seguimos la ruta:Database Navigator -> undatascience-db -> Schemas -> public -> Tables, podemos realizar una consulta asociada con la creación de una tabla.Para esto, parados en
Tableshacemos click en la parte superior sobreSQL. Se va a generar un script deSQLel cual podemos usar para realizar consultas.En este caso usamos la siguiente consulta:
CREATE TABLE USERS (ID SERIAL)
El script creará la tabla
userscon unidnombrado serial.CREATE TABLEes utilizado para crear una nueva tabla en la base de datos.ID(identity column) es una columna numérica en la tabla que se rellena automáticamente con un valor entero cada vez que se inserta una fila.En la siguiente sección estudiaremos las consultas en mas detalle. Además usaremos la
APIdePythonpara realizar dichas consultas desde unnotebook.
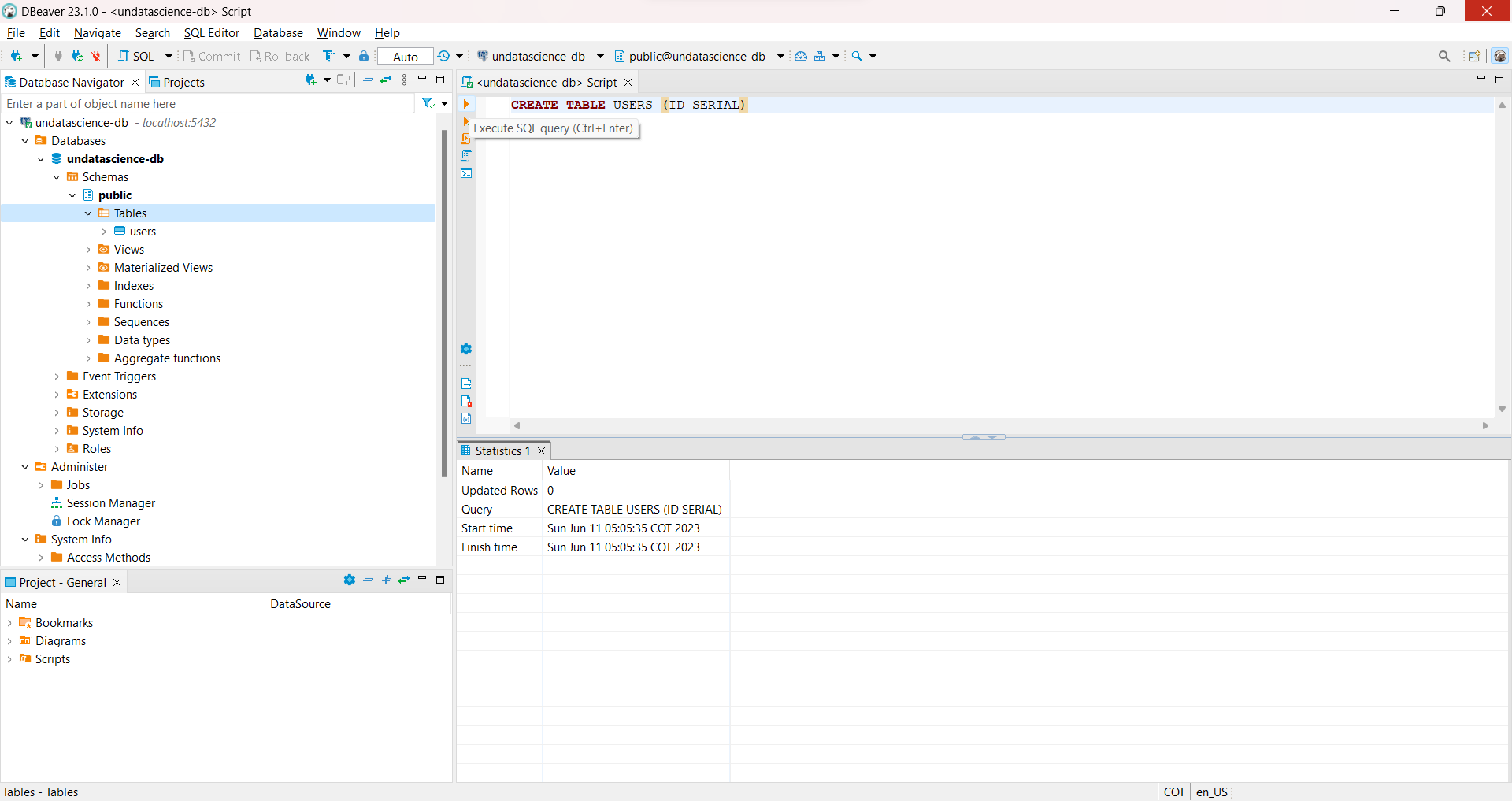
Fig. 24 Creación de la tabla users desde el script SQL en DBeaver.#
Dado que la tabla ya fue creada. Podemos interactuar con esta desde la consola de
PostgreSQLdentro de nuestro contenedor. Para visualizar las tablas creadas desde la consola dePostgreSQL, usamos por ejemplo el comando\d. Si el contenedor está apagado lo podemos iniciar usando antesdocker start undatascience-name
docker exec -it undatascience-name bash
psql -U undatascience-user --db undatascience-db --password
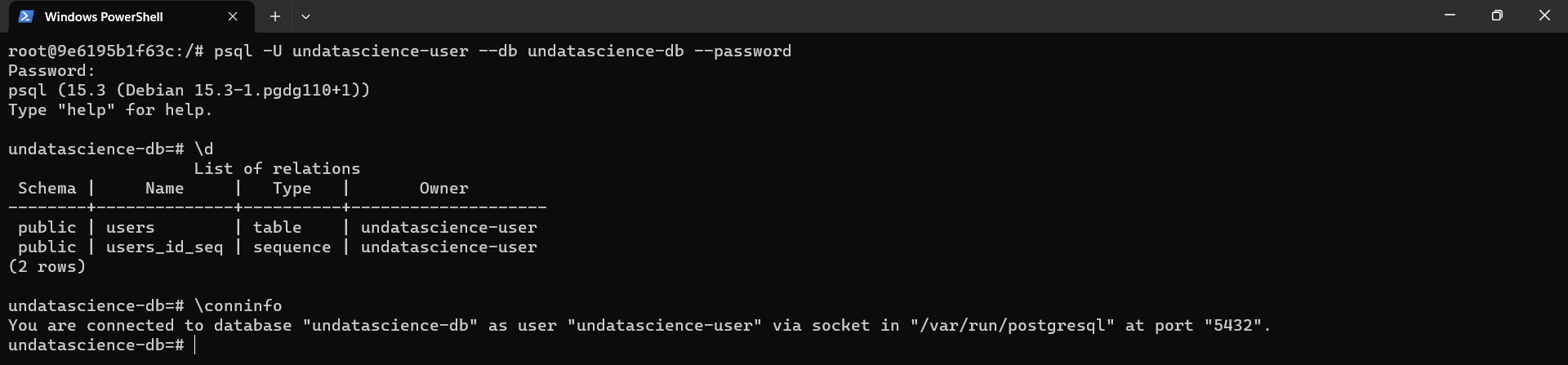
Fig. 25 Consultas a la base de datos creada. Test para verificar creación de la tabla users.#
Podemos
agregar una fila a la tabla creadapara verificar otra consulta. En este caso usamos:
INSERT INTO users VALUES (1);
SELECT * FROM users;

Fig. 26 Fila agregada a la tabla users en la base de datos undatascience-db.#
Podemos visualizar desde
DBeaverla nueva fila agregada a la tablalectura_database_tableuserscreada en el contenedor.
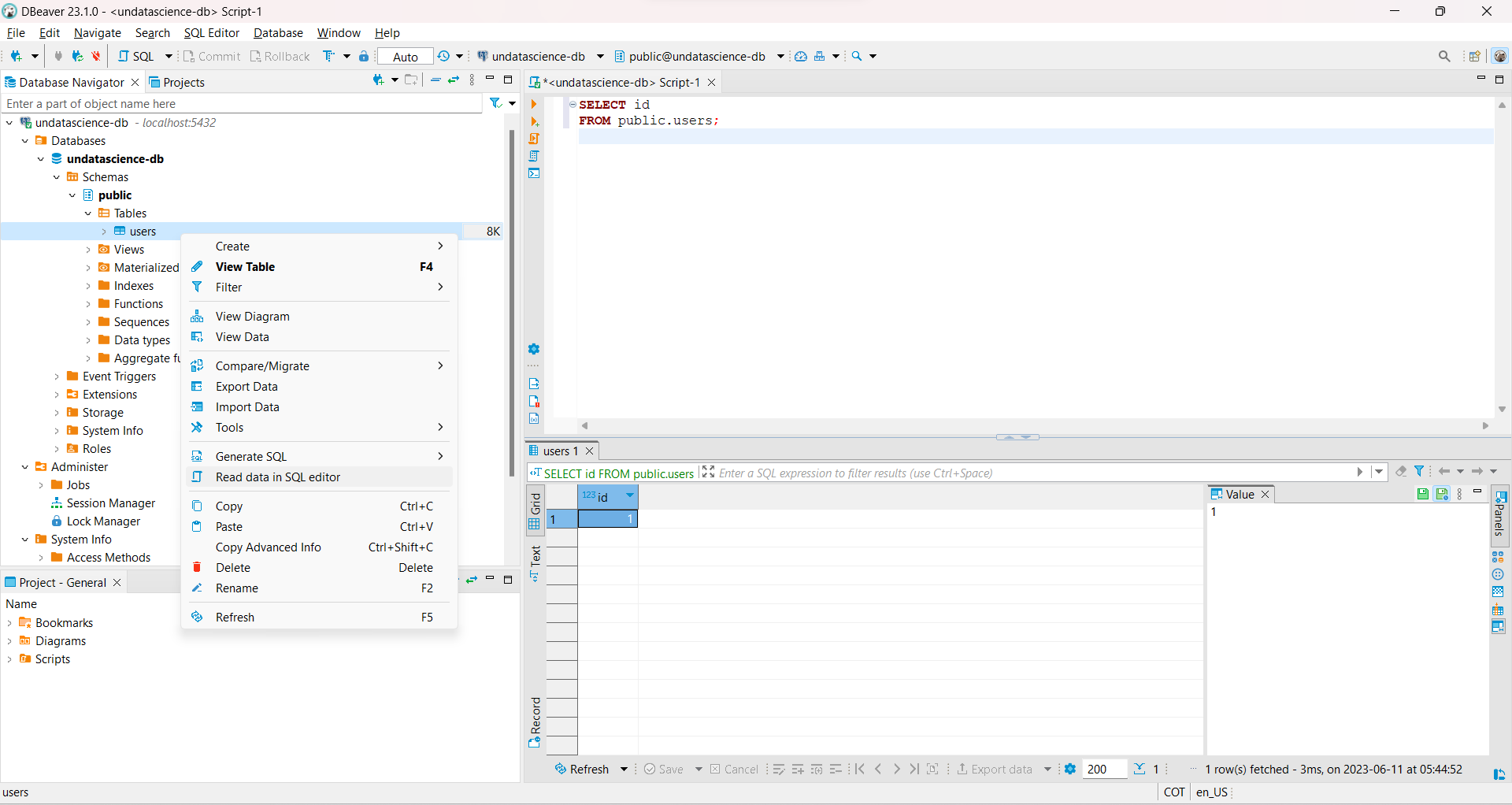
Fig. 27 Lectura de datos agregados a la tabla users desde DBeaver.#
Los
contenedorescreados recuerde quepueden ser eliminados cuantas veces usted lo desee, para construir nuevos proyectos. Para eliminarlos primero deben detenerse. Para esto usamos los siguientes comandos
docker stop undatascience-name
docker rm undatascience-name
También puede
eliminar la imagen creada cuando instaló PostgreSQLen el contenedor, usando la siguiente orden
docker images
docker rmi postgres
Por otro lado, es posible
exportar e importar imágenes dockercon el objetivo de ser compartida con otros usuarios. Lo único que necesita el usuario que recibe la imagen es, tener instaladoDockeren su computadora.Veamos un ejemplo. Primero usando
docker psverificamos que nuestro contenedor objetivo ha sido iniciado. En caso contrario, puede iniciarlo usandodocker start. Luego de ser iniciado pasamos aexportar la imagenusando la siguiente orden, en este caso vamos a exportar el contenedor recién creadoundatascience-nameconID igual a 075cf2a22e48
docker container export 075cf2a22e48 -o undatascience-docker.tar
ls
Nótese que
075cf2a22e48corresponde alIDcorrespondiente al contenedor. Luego de ser exportado el archivo.tarque contiene la imagen, dentro de la carpeta donde fue creado podemos importar la imagen docker usando la siguiente orden:
docker image import undatascience-docker.tar undatascience-docker
docker images

Fig. 28 Imagen docker importada usando la orden docker image import.#
Podemos seguir el procedimiento realizado previamente y
ejecutar de forma interactiva el contenedor importadousando la siguiente orden
docker run --name=undatascience-docker undatascience-docker bash
Además de
Docker, si no deseamos pagar un servidor tipoAWS, Google, IBM,...paradesplegar nuestra base de datos, podemos usar servidores gratuitos para esta tarea. Una de las opciones gratuitas mas usadas en la actualidad esRailwayel cual revisaremos a continuación.
Despliegue de Base de Datos en Railway#
Railwayes una plataforma de despliegue donde puedesproveer infraestructura, desarrollar con esa infraestructura localmente, y luego desplegar en la nube.Primero que todo debe crear una cuenta en
Railwayy realizar verificación de identidad usando su cuenta deGitHub. De esta forma obtendrá unplan inicial de 500 hrsequivalente a5 USD.
Fig. 29 Pagina inicial de Railway. Crear una cuenta haciendo click en Login#

Fig. 30 Autenticación de cuenta de Railway usando cuenta de GitHub.#
Una vez haya autenticado su cuenta de
Dockerpodrá visualizar el siguiente mensaje de confirmación de activación de cuenta. En este se resumen los limites delTrial Plan.
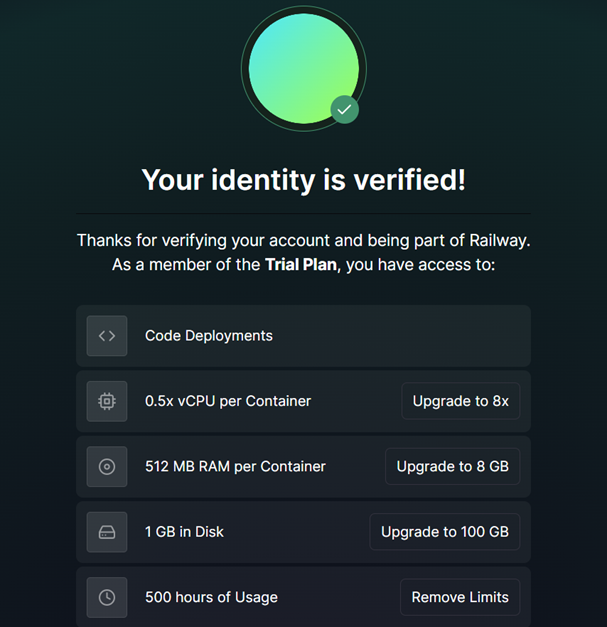
Fig. 31 Creación y verificación de cuenta de Railway. Autenticación por medio de cuenta de GitHub.#
Para crear una cuenta en
GitHubpuede usar el siguiente link (ver GitHub). Luego de haber creado y activado la cuenta, hacemos click en la opciónNew ProjectdelDashboarddeRailway. Para esto hacer click enProvision PostgreSQL. Al final podrá observar la base de datos creada.Una vez creada la cuenta, accedemos a el
DashboarddeRailwayy creamos un nuevo proyecto haciendo click enNew Project. Luego, creamos el servidor paraPostgreSQLenRailway, tal como se muestra en las imágenes siguientes:
Fig. 32 Creación de nuevo proyecto Railway desde el Dashboard.#
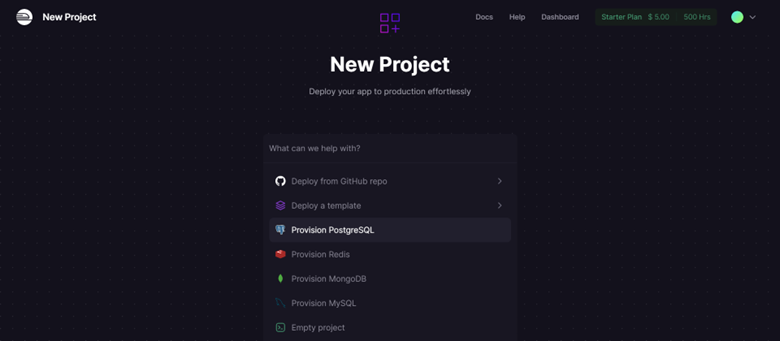
Fig. 33 Creación de base de datos PostgreSQL en Railway.#
Nótese que si hacemos click sobre la base de datos creada, podemos visualizar todas las opciones ofrecidas por
Railway. Si hacemos click enConnect, podemos acceder a las credencial necesarias para conectarnos a la base de datos.
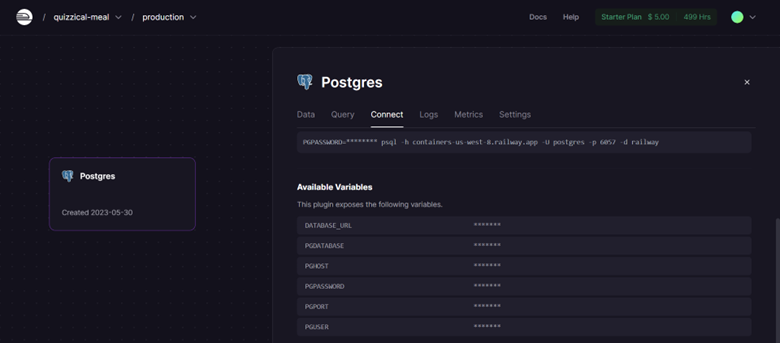
Fig. 34 Credenciales de conexión a la base de datos de PostgreSQL en Railway.#
Si usamos las credenciales de la bases de datos creada en
Railwaypodemos conectarnos a la base de datos como se muestra en la siguiente imagen, desdeDBeaver(ver Fig. 21).
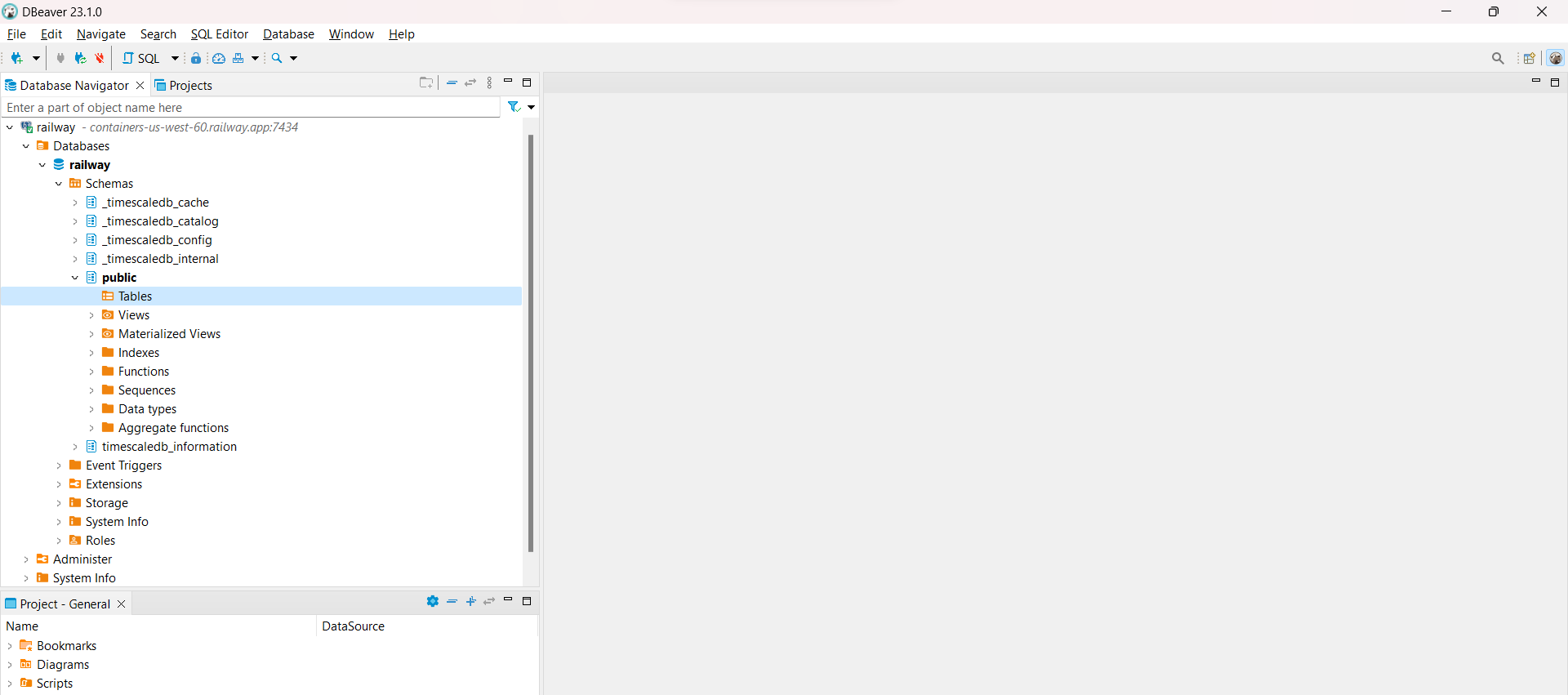
Fig. 35 Conexión a base de datos creada en Railway.#
Procederemos ahora a realizar algunas
consultas básicas a la base de datoscreada. En este caso utilizaremos la consola para consultasSQLdepgAdmin.
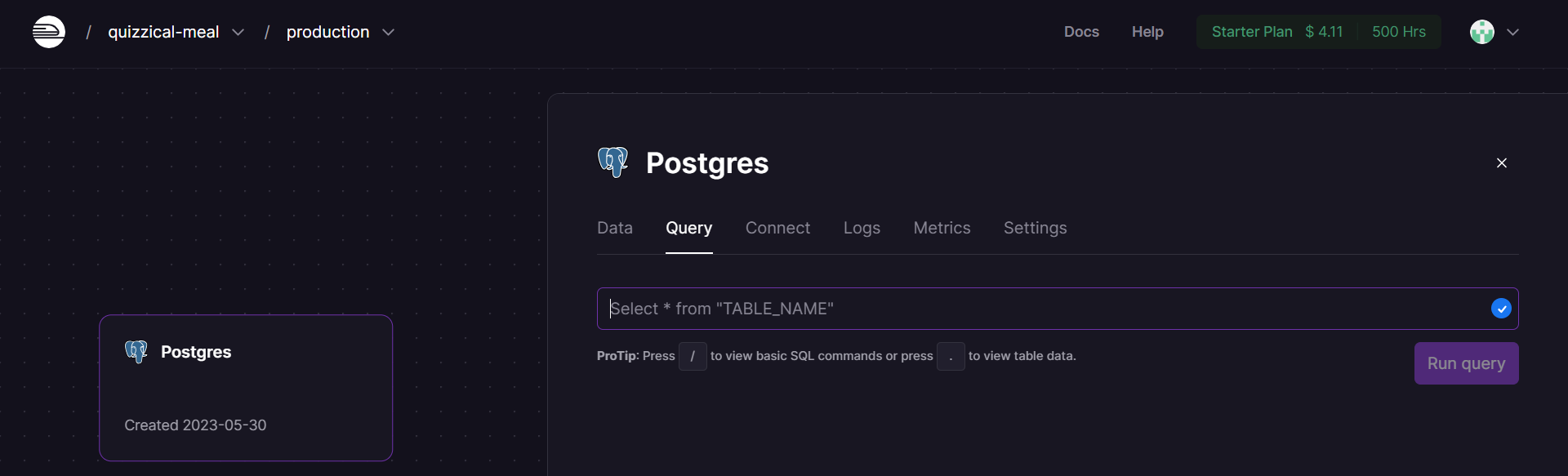
Fig. 36 Consultas SQL pueden realizarse desde el Dashboard de Railway directamente.#
Introducción a consultas SQL#
Restauración de bases de datos dvdrental#
En esta sección, se proporcionará una base de datos de ejemplo de
PostgreSQLque servirá como herramienta de aprendizaje y práctica. La base de datos utilizada es la de unnegocio de alquiler de DVD, diseñada para demostrar las características dePostgreSQL. Esta base de datos contiene numerosos objetos relacionados con los procesos de negocio de la tienda de alquiler de DVD15 tables
1 trigger
7 views
8 functions
1 domain
13 sequences
Hay 15 tablas en la base de datos de alquiler de DVD:
actor- almacena los datos de los actores, incluyendo nombre y apellidos.film- almacena datos de la película como título, año de lanzamiento, duración, clasificación, etc.film_actor- almacena las relaciones entre películas y actores.category- almacena los datos de las categorías de las películas.film_category- almacena las relaciones entre películas y categorías.store- contiene los datos de la tienda, incluido el personal de gestión y la dirección.inventory- almacena los datos de inventario.rental- almacena los datos de alquiler.payment- almacena los pagos de los clientes.staff- almacena los datos del personal.customer- almacena los datos del cliente.address- almacena la dirección del personal y de los clientes.city- almacena los nombres de las ciudades.country- almacena los nombres de los países.
Puede descargar la base de datos ejemplo
PostgreSQL DVD Rentala través del siguiente enlace (ver dvdrental.tar). Para importar esta base de datos en un servidor dePostgreSQLpodemos utilizar el gestor de bases de datospgAdmin, el cual es ampliamente usado para este tipo de tareas. Para esto, primero lo instalamos siguiendo el siguiente link (ver pgAdmin). Una vez instalado lo iniciamos y agregamos el servidor, nombradodvdrentalpor ejemplo.
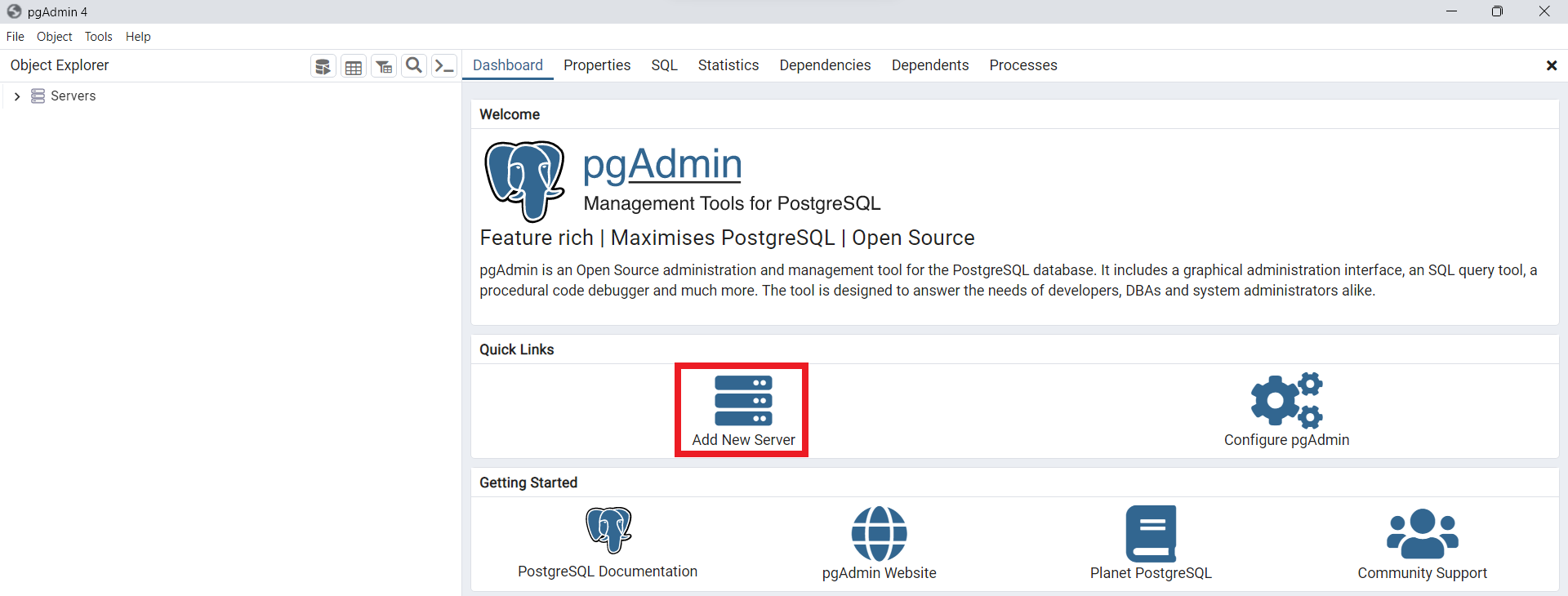
Fig. 37 Nuevo proyecto creado para el servidor dvdrental.#
Para crear un nuevo servidor agregamos cada una de las credenciales generadas en nuestro proyecto
PostgreSQLdeDocker, tal como se muestra en la siguientes figuras. Al finalizar, hacemos click enSavepara poder visualizar el nuevo servidor creado
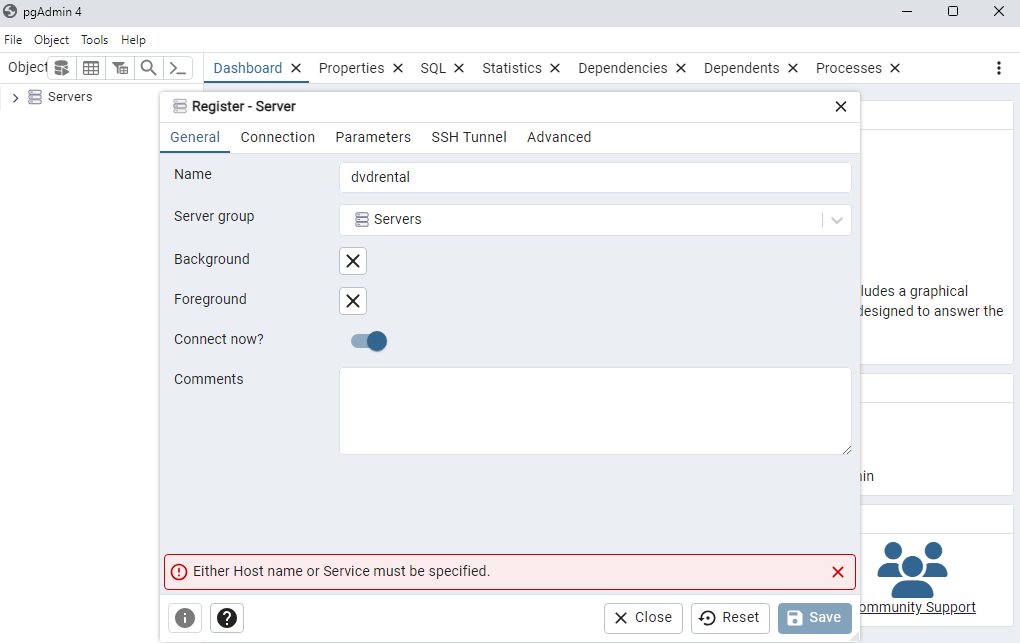
Fig. 38 Asignamos el nombre de la base de datos creada en Docker.#
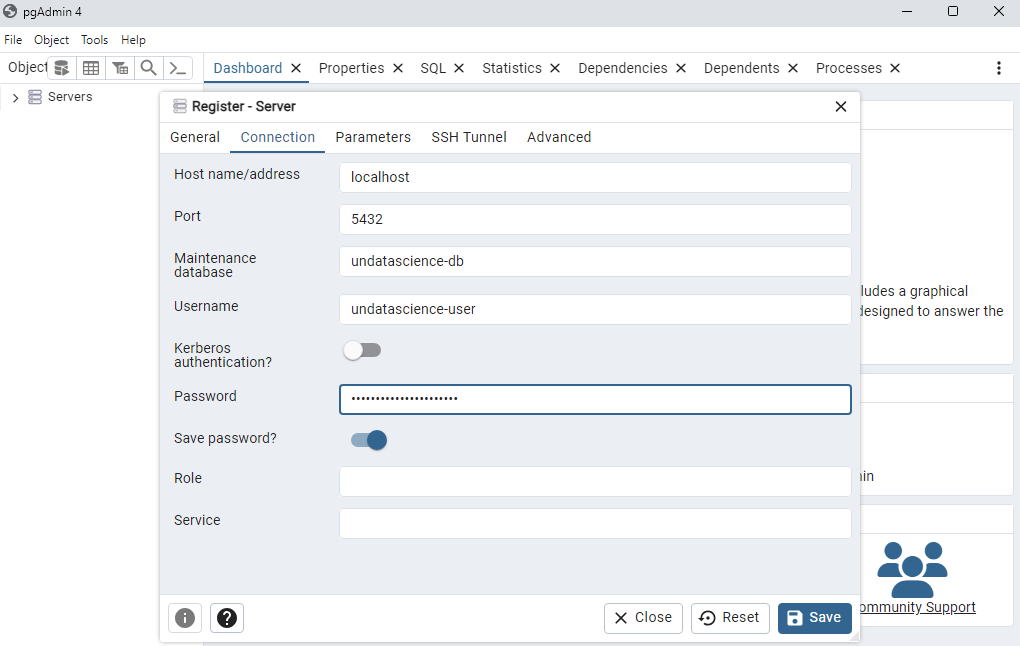
Fig. 39 Credenciales para conexión a la base de datos en Docker.#
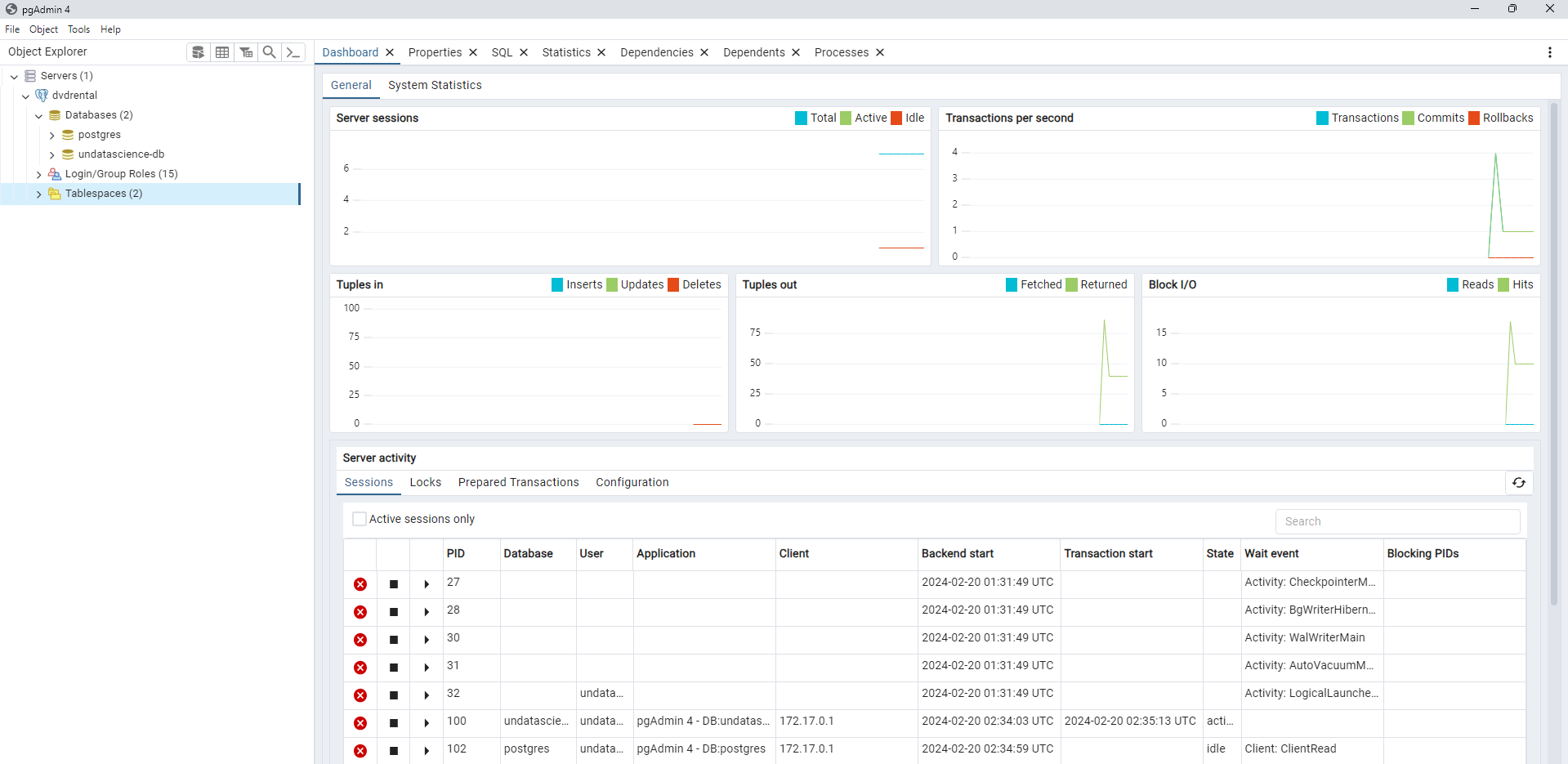
Fig. 40 Dashboard de pgAdmin con información de conexión al servidor Docker.#
Podemos realizar una primera consulta
SQLpara verificar nuestra conexión a la base de datos creada en el serverPostgreSQL. Para esto usamos la consulta
SELECT version();
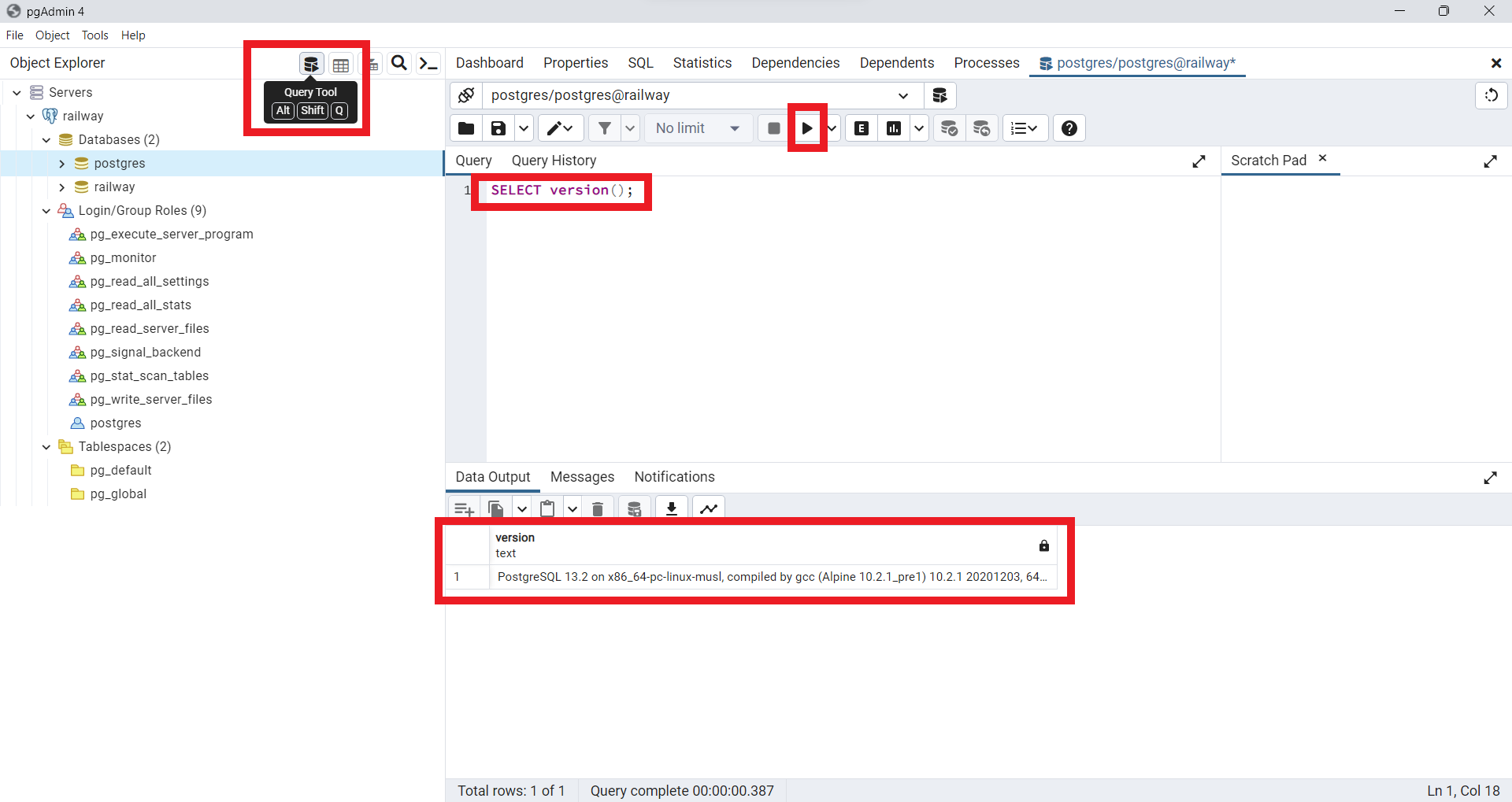
Fig. 41 Primera consulta a la base de datos creada en Docker.#
Procedemos ahora a cargar la base de datos
DVD Rentalen nuestro servidorDockerpor medio del gestorpgAdmin. Para esto, haga clic derecho enDatabasesluego enCreate/Database.
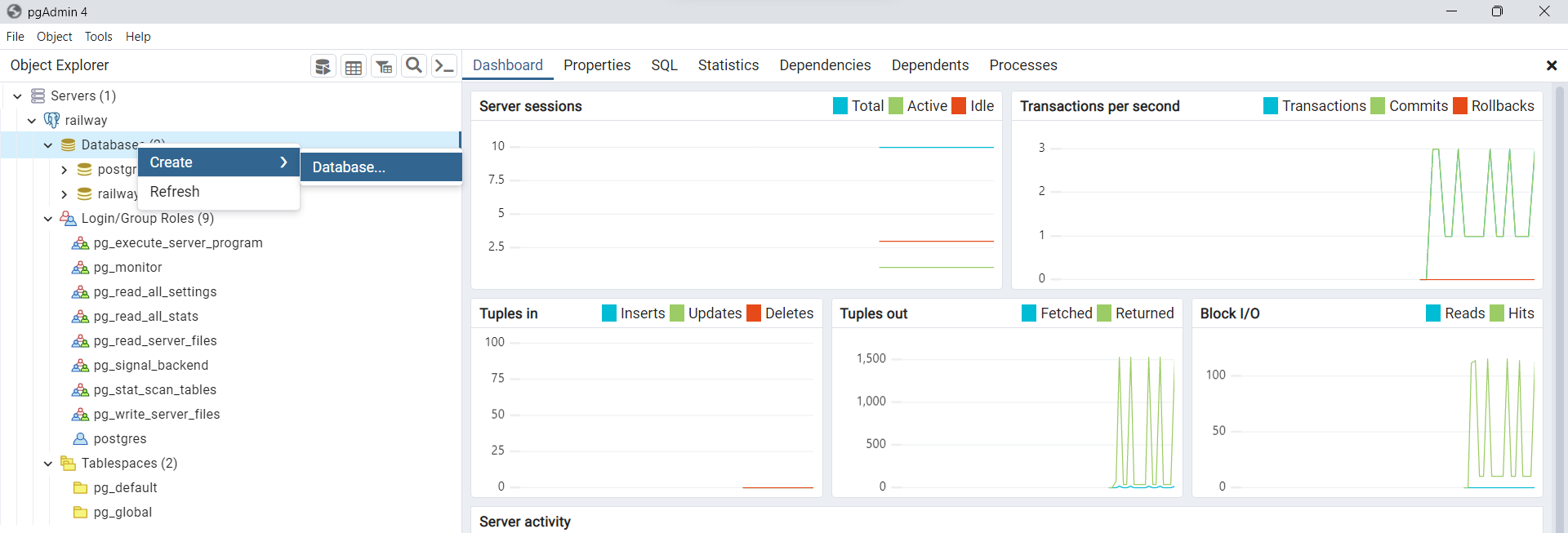
Fig. 42 Creación de base de datos para importar DVD Rental.#
Luego agregamos el nombre de la base de datos, en este caso
dvdrental. Puede hacer click derecho sobre el nombre de la base de datos y luego seleccionarRefreshpara actualizar cambios en la base de datos.
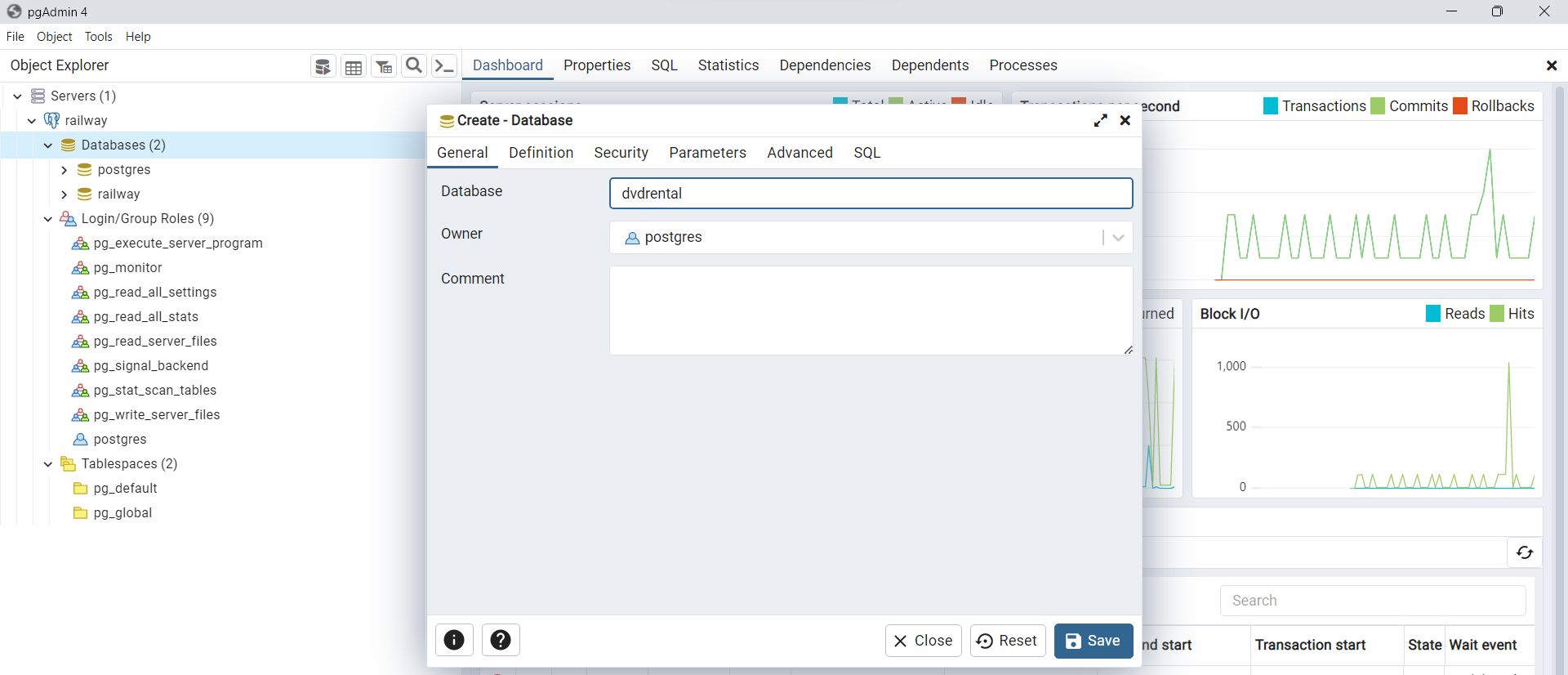
Fig. 43 Agregar nombre de la base de datos a importar en Docker.#
Procedemos ahora a importa la base de datos de interés, descargada previamente (ver dvdrental.tar). Para esto hacemos click derecho sobre la base de datos creada
dvdrentaly luego seleccionamos la opciónRestorepara cargar el archivo.tar.
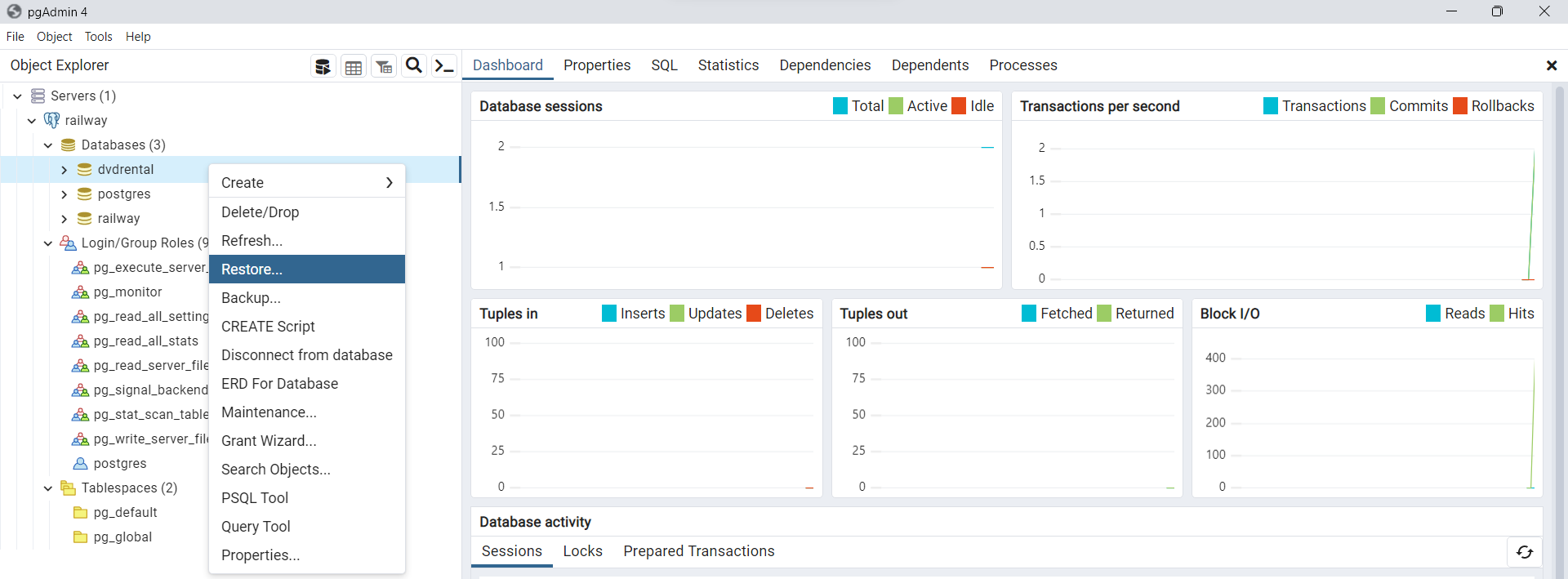
Fig. 44 Selección de opción de restauración de base de datos dvdrental.#
Luego de esto, procedemos a cargar la dirección de ubicación para nuestro archivo
dvdvrental.tardentro de la opciónFilename. Posteriormente hacemos click enRestore. Cuando se encuentre buscando el archivo debe seleccionar la opciónAll filespara que pueda visualizar el archivodvdvrental.tar.
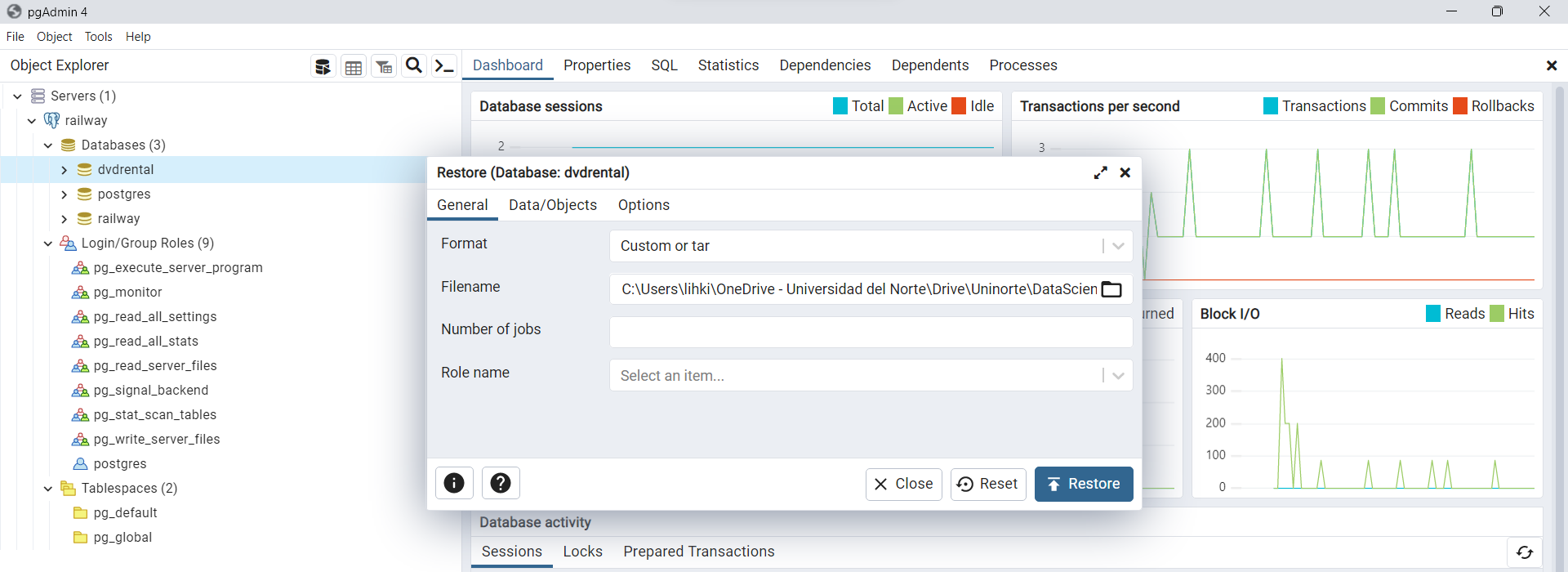
Fig. 45 Cargue de base de datos desde archivo dvdrental.tar.#
Fig. 46 Mensaje de carga exitosa de la base de datos dvdrental.tar.#
Podrá visualizar la base de datos creada en
Schemes/public/Tables. Nótese que la base de datos creada cuenta con 15 tablas, cada una de estas con las especificaciones mencionadas al inicio de la presente sección.
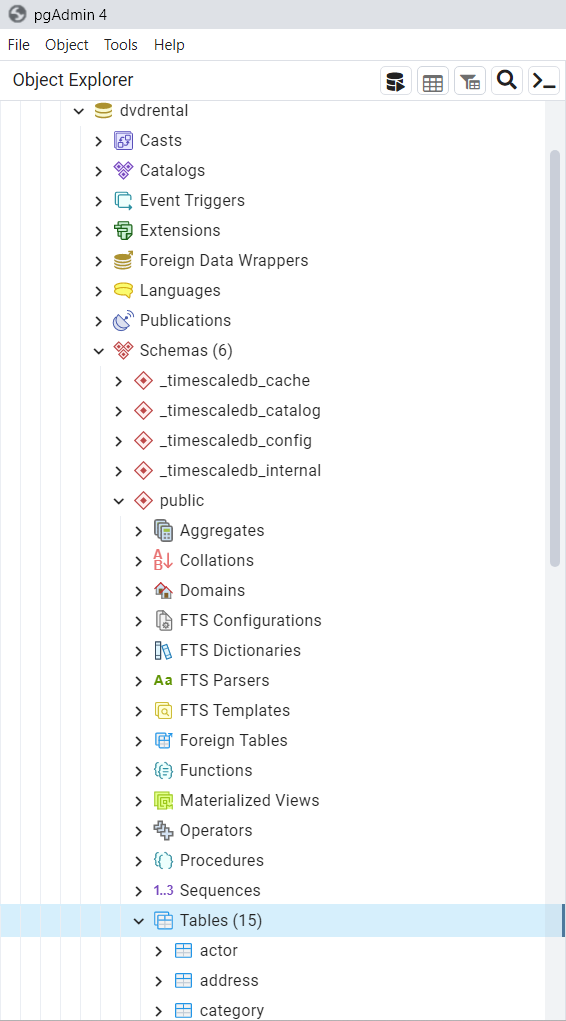
Fig. 47 15 Tablas han sido cargadas en la sección Tables en Schemes.#
Procederemos ahora a estudiar algunas consultas básicas que podemos realizar a nuestras bases de datos de prueba. En este caso iniciaremos con
SELECT. Usaremos inicialmente la consola de consultas ofrecida porpgAdmin.
Consultas SQL#
SELECT#
Cuando se trabaja con bases de datos, una tarea común es consultar datos de las tablas utilizando la sentencia
SELECT. Esta sentencia es compleja y tiene muchas cláusulas que permiten formar consultas flexibles. Dividiremos su uso en varias partes más cortas y fáciles de entenderSELECTincluye las siguientes cláusulas:Utilizar el operador
DISTINCTpara seleccionar filas distintas.Ordenar filas utilizando la cláusula
ORDER BY.Filtrar filas mediante la cláusula
WHERE.Seleccionar un subconjunto de filas de una tabla utilizando la cláusula
LIMIToFETCH.Agrupar filas en grupos mediante la cláusula
GROUP BY.Filtrar grupos mediante la cláusula
HAVING.Unir tablas mediante las cláusulas
INNER JOIN, LEFT JOIN, FULL OUTER JOINyCROSS JOIN.Realizar operaciones de conjunto utilizando
UNION, INTERSECTyEXCEPT.
En esta sección, nos centraremos en las cláusulas
SELECTyFROM.
Sintaxis de la sentencia SELECT de PostgreSQL
Empecemos con la forma básica de la sentencia
SELECTque recupera datos de una única tabla. A continuación se ilustra la sintaxis de la sentenciaSELECT:
SELECT
select_list
FROM
table_name;
En primer lugar, especifique una
lista de selección que puede ser una columna o una lista de columnas de una tabla de la que desee recuperar datos. Si especifica una lista de columnas, debe colocar una coma(,)entre dos columnas para separarlas. Si deseaseleccionar datos de todas las columnas de la tabla, puede utilizar la abreviatura asterisco(*)en lugar de especificar todos los nombres de las columnas. La lista de selección también puede contener expresiones o valores literales.En segundo lugar, especifique el nombre de la tabla desde la que desea consultar los datos después de la palabra clave
FROM. La cláusulaFROMes opcional. Si no consulta datos de ninguna tabla, puede omitir la cláusulaFROMen la sentenciaSELECT.PostgreSQLevalúa la cláusulaFROMantes de la cláusulaSELECTen la sentenciaSELECT.Tenga en cuenta que las palabras clave
SQLno distinguen entre mayúsculas y minúsculas. Esto significa queSELECTes equivalente aselectoSelect.Por convención, utilizaremos todas las palabras clave SQL en mayúsculas para facilitar la lectura de las consultas.
Ejemplos de SELECT PostgreSQL
Veamos algunos ejemplos del uso de la sentencia
SELECTdePostgreSQL. Vamos a utilizar la tablacustomeren la base de datos de ejemplo para la demostración.

Fig. 48 Estructura de la tabla customer.#
Podemos utilizar la sentencia
SELECTpara encontrarfirst_namedentro de todos los clientes de la tablacustomer. Para esto utilizaremos la siguiente orden, la cual podemos ejecutar desde la consola dePostgreSQL. Observe que hemos añadido un punto y coma(;)al final de la sentenciaSELECT. El punto y coma no es parte de la sentenciaSQL. Se utiliza para indicar aPostgreSQLel final de una sentenciaSQL. El punto y coma también se utiliza para separar dos sentenciasSQL.
SELECT first_name FROM customer;
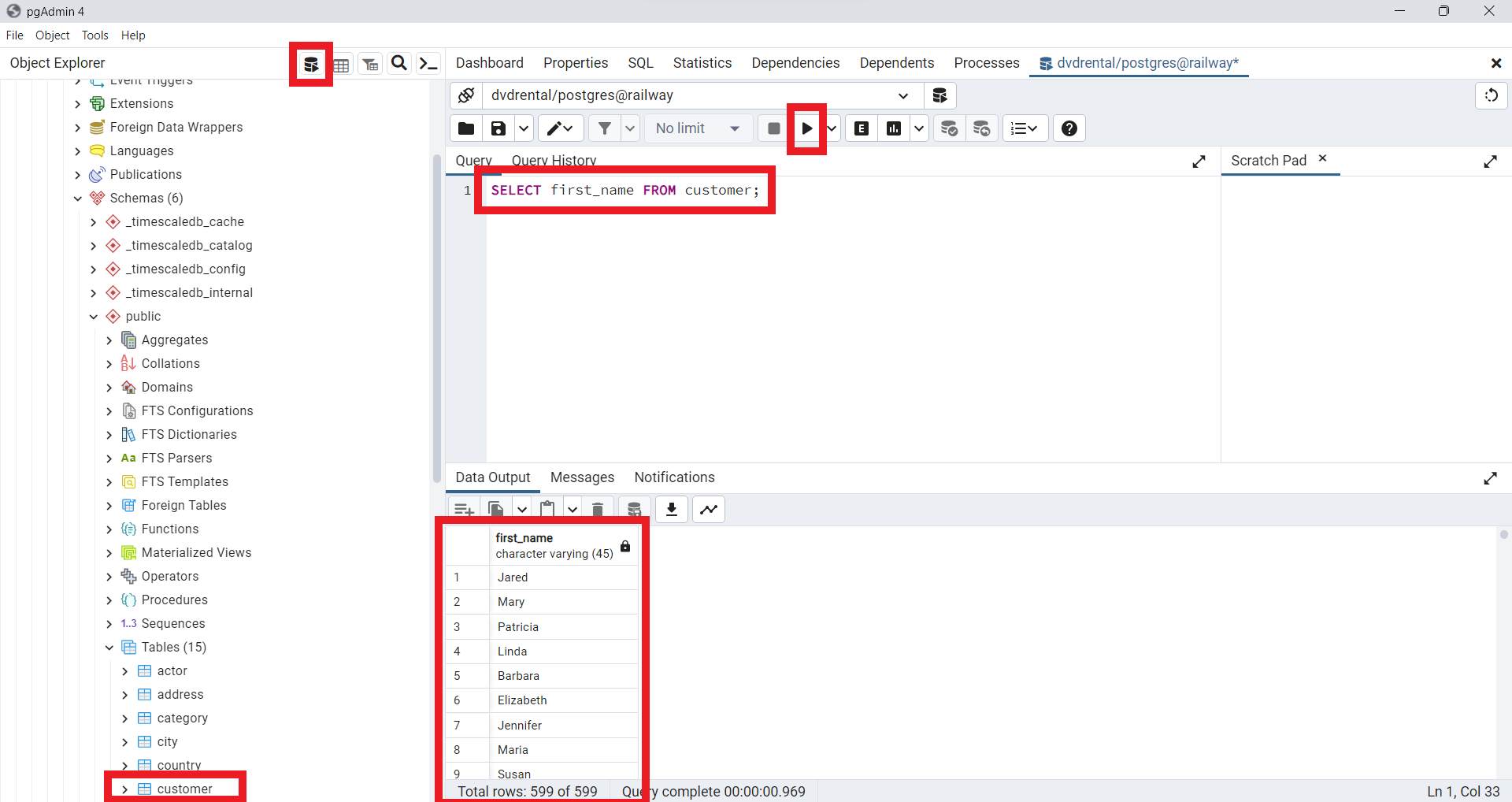
Fig. 49 Consulta desde la consola de pgAdmin para el ejemplo: SELECT first_name FROM customer;.#
Uso de sentencia SELECT de PostgreSQL para consultar datos de múltiples columnas
Supongamos que sólo desea conocer el nombre, apellido y correo electrónico de los clientes
(first_name, last_name, email), puede especificar estos nombres de columna en la cláusulaSELECTcomo se muestra en la siguiente consulta:
SELECT
first_name,
last_name,
email
FROM
customer;
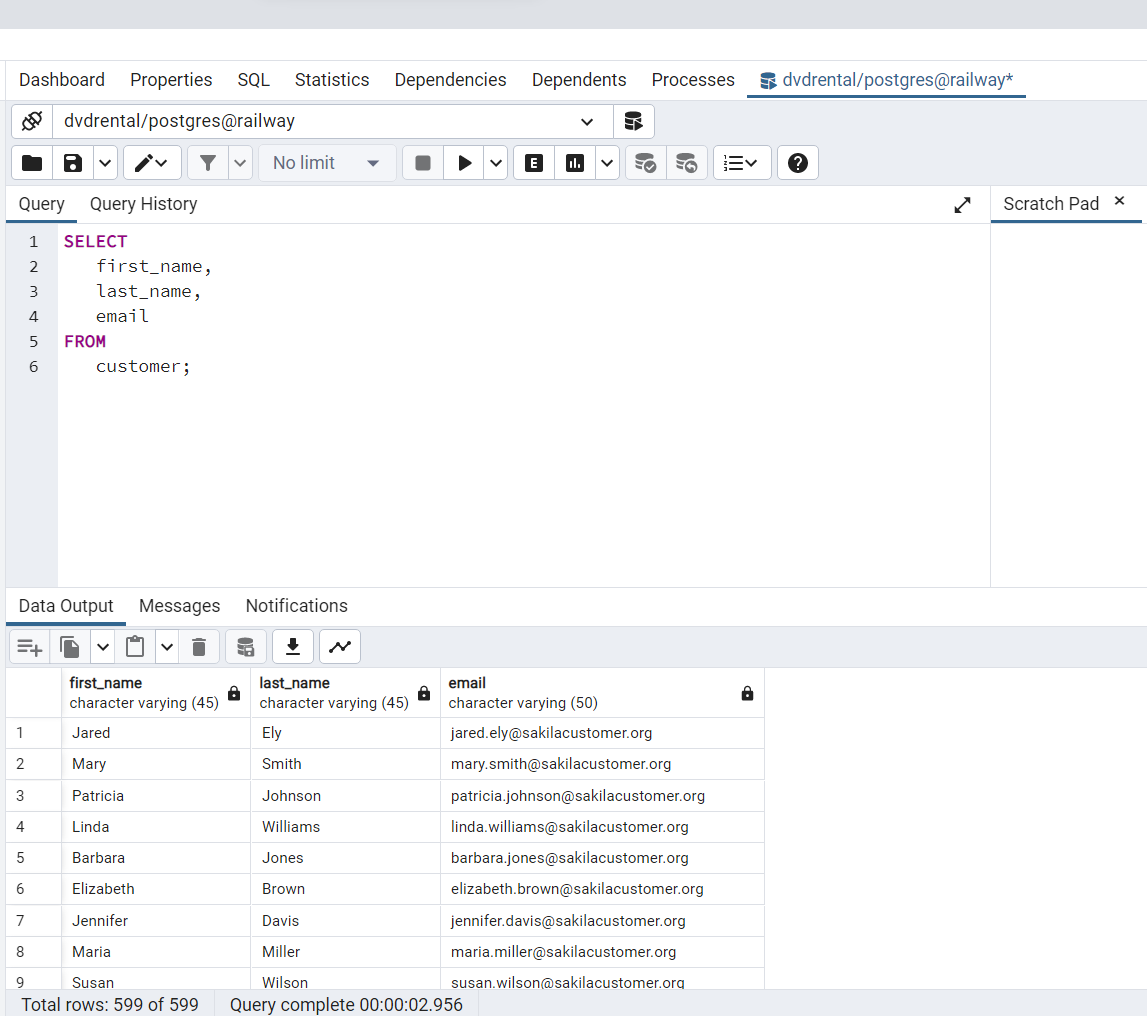
Fig. 50 Consulta desde la consola de pgAdmin para el ejemplo: SELECT first_name, last_name, email FROM customer;.#
Uso de la sentencia SELECT de PostgreSQL para consultar datos de todas las columnas de una tabla
La siguiente consulta utiliza la sentencia
SELECTpara seleccionar datos de todas las columnas de la tablacustomer. En este ejemplo, utilizamos asterisco(*)en la cláusulaSELECT, que es una abreviatura de todas las columnas.
SELECT * FROM customer;
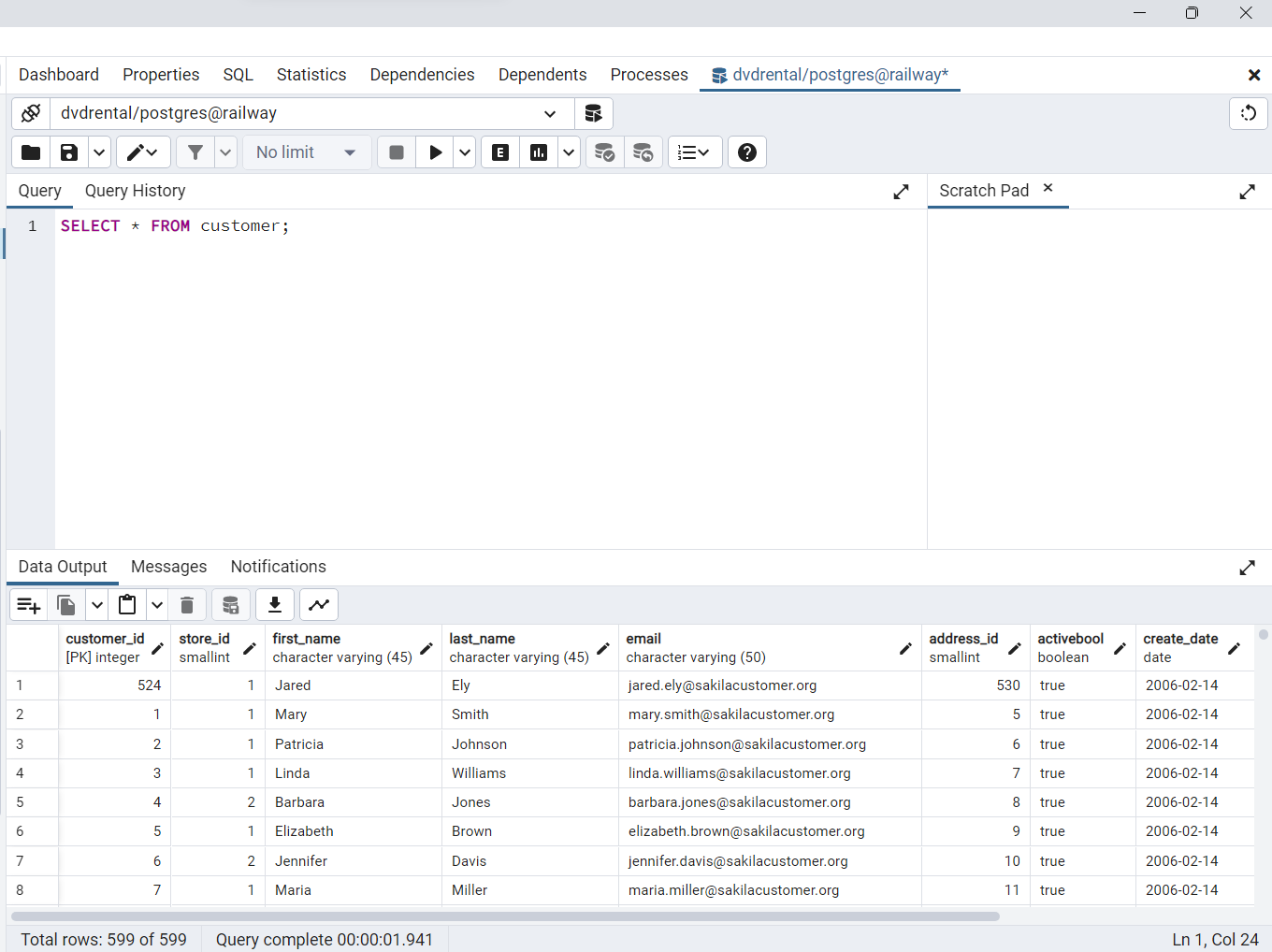
Fig. 51 Consulta desde la consola de pgAdmin para el ejemplo: SELECT * FROM customer;.#
Uso de la sentencia SELECT de PostgreSQL con expresiones
El siguiente ejemplo utiliza la sentencia
SELECTparadevolver los nombres completos y correos electrónicos de todos los clientes. Utilizamos eloperador de concatenación ||para concatenar: nombre, espacio y apellido de cada cliente.
SELECT
first_name || ' ' || last_name,
email
FROM
customer;
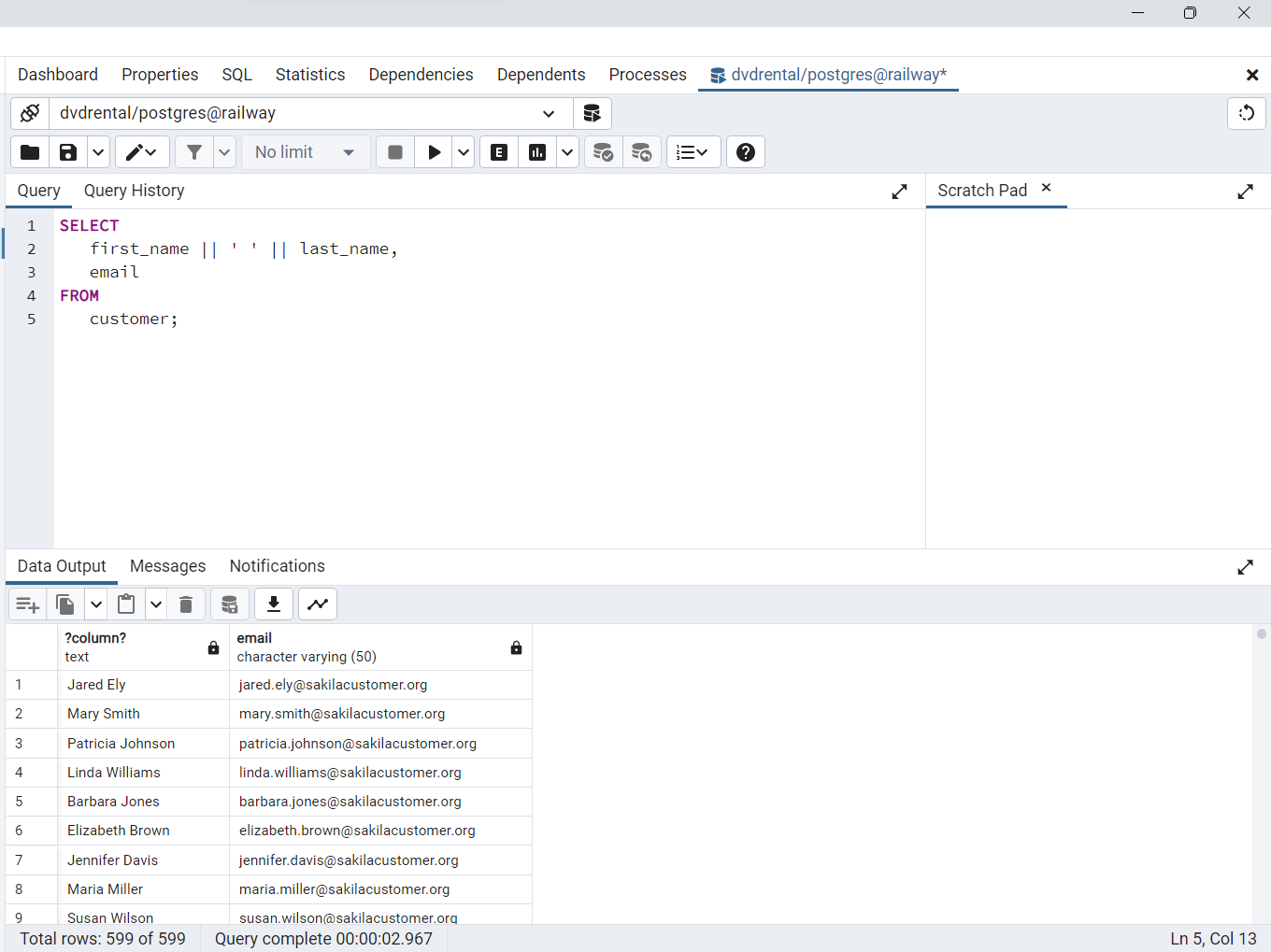
Fig. 52 Consulta desde la consola de pgAdmin para el ejemplo de concatenación de nombre y apellido.#
Uso de la sentencia SELECT de PostgreSQL con expresiones
El siguiente ejemplo utiliza la sentencia
SELECTcon una expresión. Omite la cláusulaFROM
SELECT 5 * 3;
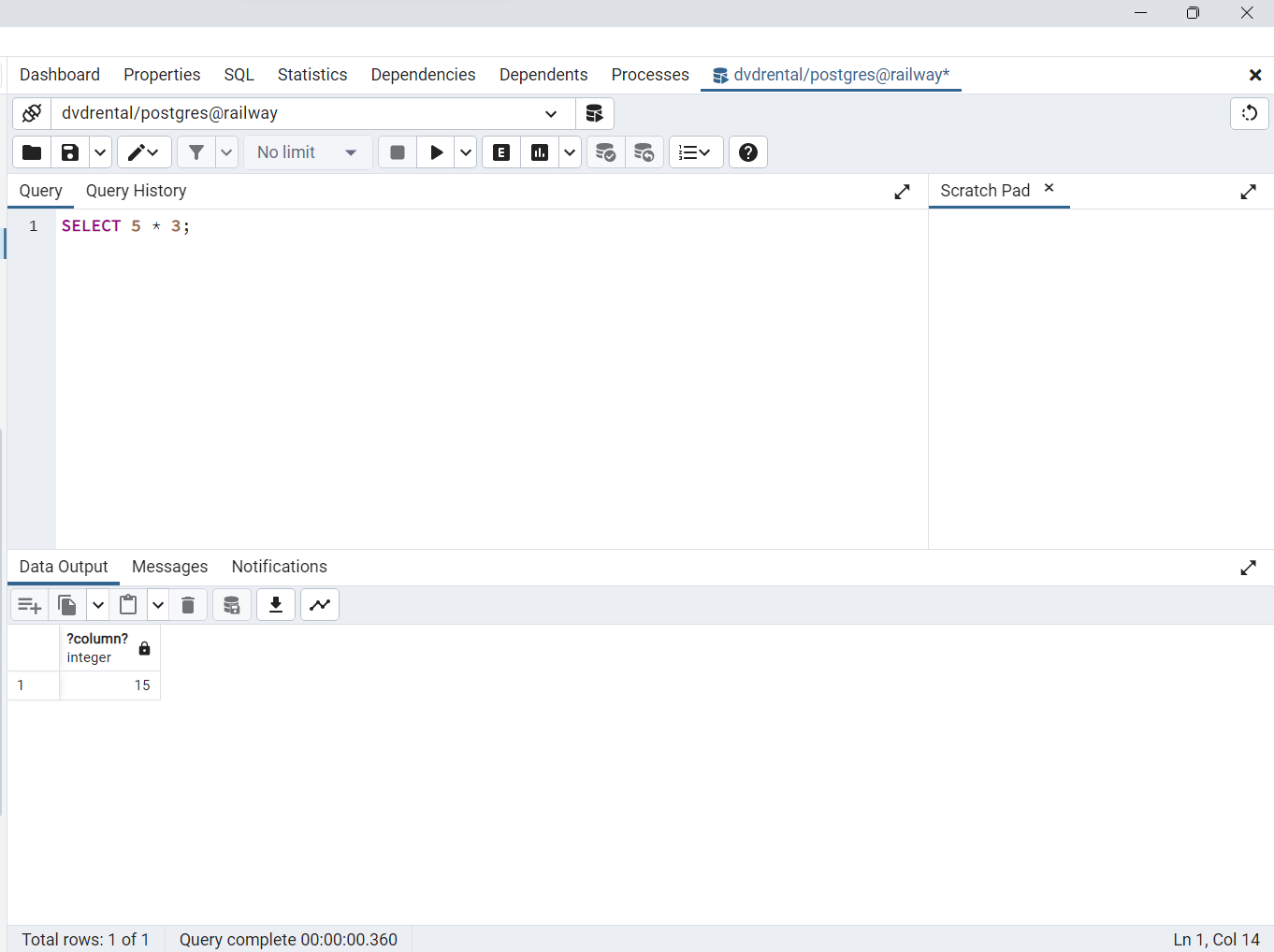
Fig. 53 Consulta desde la consola de pgAdmin para el ejemplo: SELECT 5 * 3;.#
Alias#
Un alias de columna
permite asignar un nombre temporal a una columnao a una expresión de la lista de selección de una sentenciaSELECT. Si desea cambiar el nombre de forma permanente debe usarRENAME COLUMN. El alias de columna existe temporalmente durante la ejecución de la consulta.
SELECT column_name AS alias_name
FROM table_name;
En esta sintaxis, a
column_namese le asigna un aliasalias_name. La palabra claveASes opcional, por lo que puede omitirla. Veamos algunos ejemplos utilizando la tablacustomerde la base de datos de ejemplo. Recordemos que La siguiente consulta devuelve los nombres y apellidos de todos los clientes de la tablacustomer
SELECT
first_name,
last_name
FROM customer;
Si deseamos renombrar el encabezado
last_name, podemos asignarle un nuevo nombre utilizando un alias de columna usando las siguientes dos opciones
SELECT
first_name,
last_name AS surname
FROM customer;
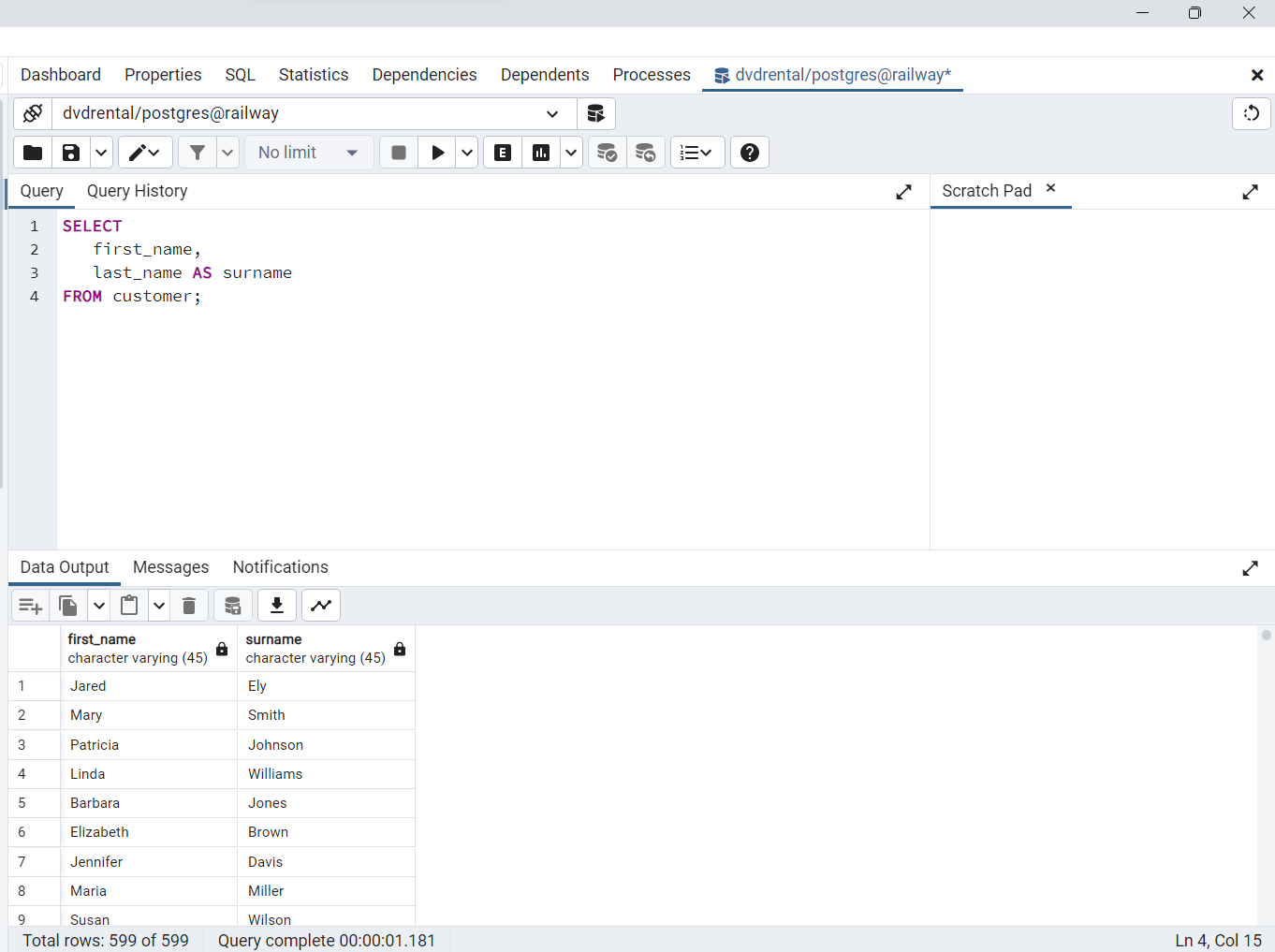
Fig. 54 Consulta desde la consola de pgAdmin para asignar alias en columnas de dvdrental.#
Asignación de un alias de columna a una expresión
La siguiente consulta devuelve los nombres completos de todos los clientes. Construye el nombre completo concatenando: nombre, espacio y apellido (
first_name, ' ', last_name). Si un alias de columna contiene uno o más espacios, debe ser encerrado entre comillas dobles, como se indica en el ejemplo a continuación. Nótese que la palabra claveASes opcional, por lo que puede ser omitida.
SELECT
first_name || ' ' || last_name "full name"
FROM
customer;
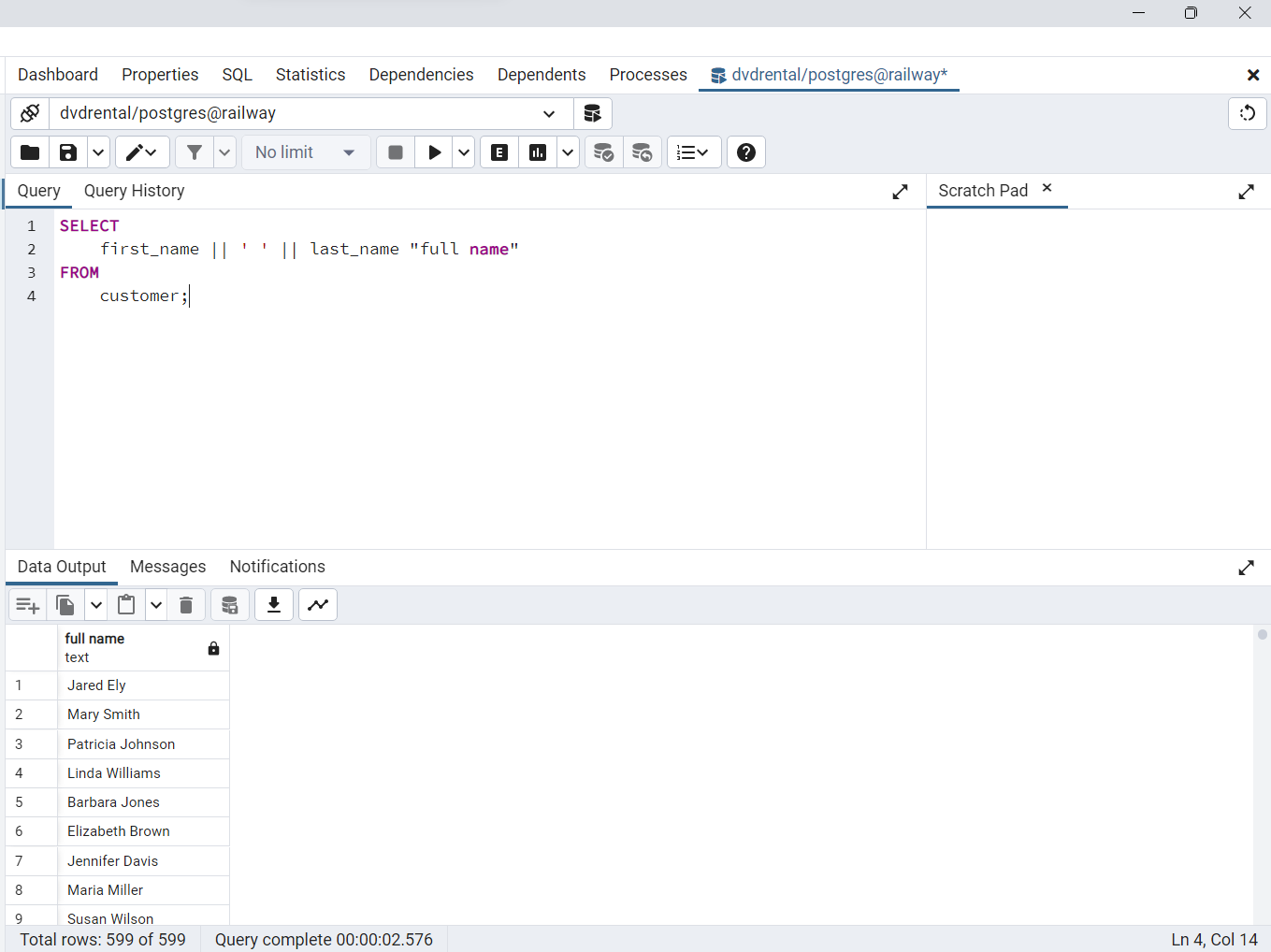
Fig. 55 Asignación de alias a una expresión compuesta de first_name, ' ', last_name.#
ORDER BY#
Cuando se consultan datos de una tabla, la sentencia
SELECTdevuelve filas en un orden no especificado. Para ordenar las filas del conjunto de resultados, se utiliza la cláusulaORDER BYen la sentenciaSELECT.La cláusula
ORDER BYpermite ordenar las filas devueltas por una cláusulaSELECTen orden ascendente o descendente en función de una expresión de ordenación. A continuación se ilustra la sintaxis de la cláusulaORDER BY
SELECT
select_list
FROM
table_name
ORDER BY
sort_expression1 [ASC | DESC],
...
sort_expressionN [ASC | DESC];
Cláusula ORDER BY de PostgreSQL para ordenar filas por una columna
La siguiente consulta utiliza la cláusula
ORDER BYpara ordenar los clientes por su primer nombre en orden ascendente
SELECT
first_name,
last_name
FROM
customer
ORDER BY
first_name ASC;
Dado que la opción
ASCes la predeterminada, puede omitirla en la cláusulaORDER BYde la siguiente manera
SELECT
first_name,
last_name
FROM
customer
ORDER BY
first_name;
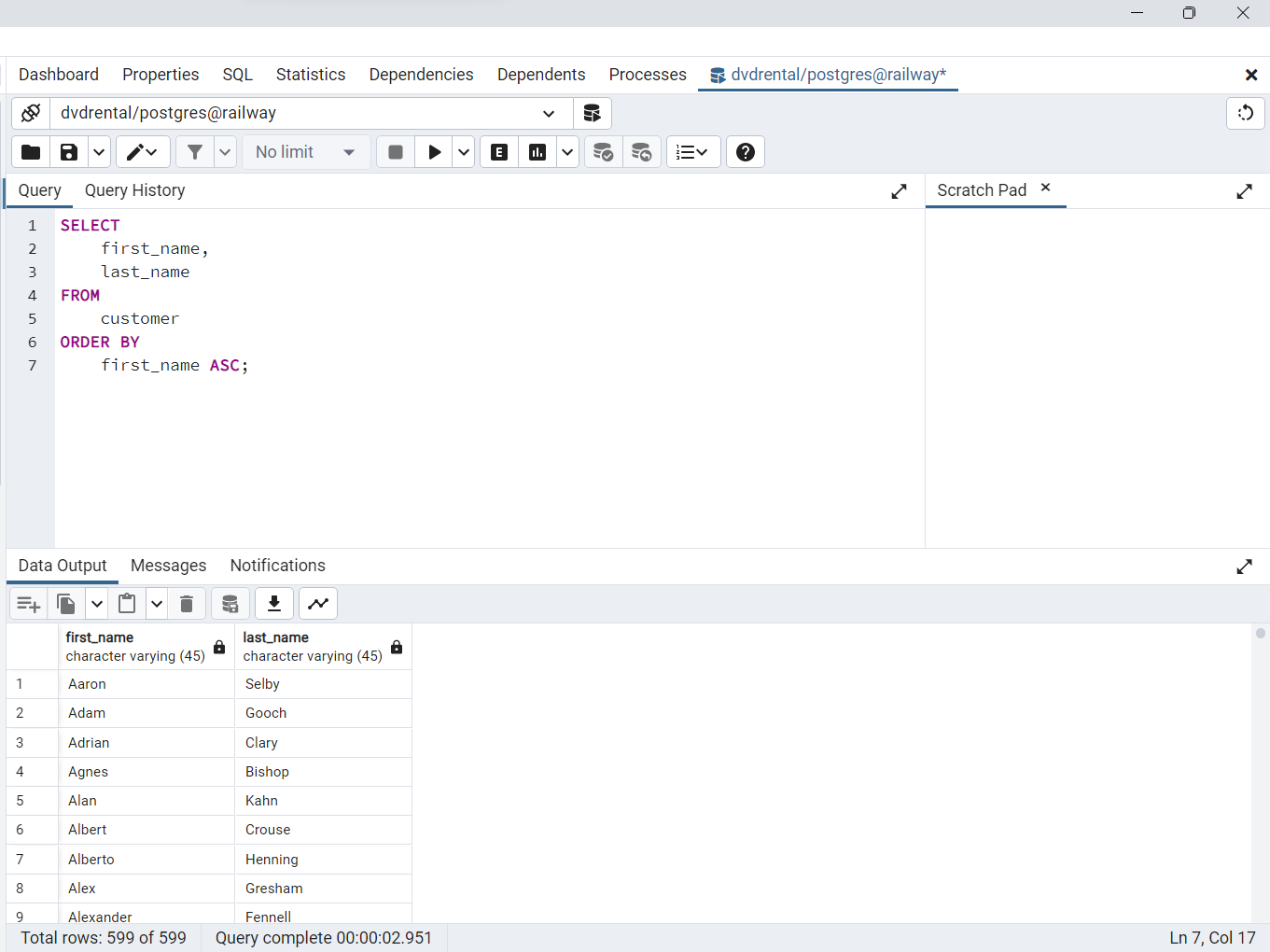
Fig. 56 Consulta SQL para orden ascendente basada en el primer nombre de los clientes.#
Cláusula ORDER BY de PostgreSQL para ordenar filas por varias columnas
La siguiente sentencia selecciona primer nombre y el apellido de la tabla de clientes y ordena las filas por primer nombre en orden ascendente y el apellido en orden descendente
SELECT
first_name,
last_name
FROM
customer
ORDER BY
first_name ASC,
last_name DESC;
En este ejemplo, la cláusula
ORDER BYordena primero las filas por los valores de la columnafirst_namey después ordena las filas ordenadas por los valores de la columnalast_name.
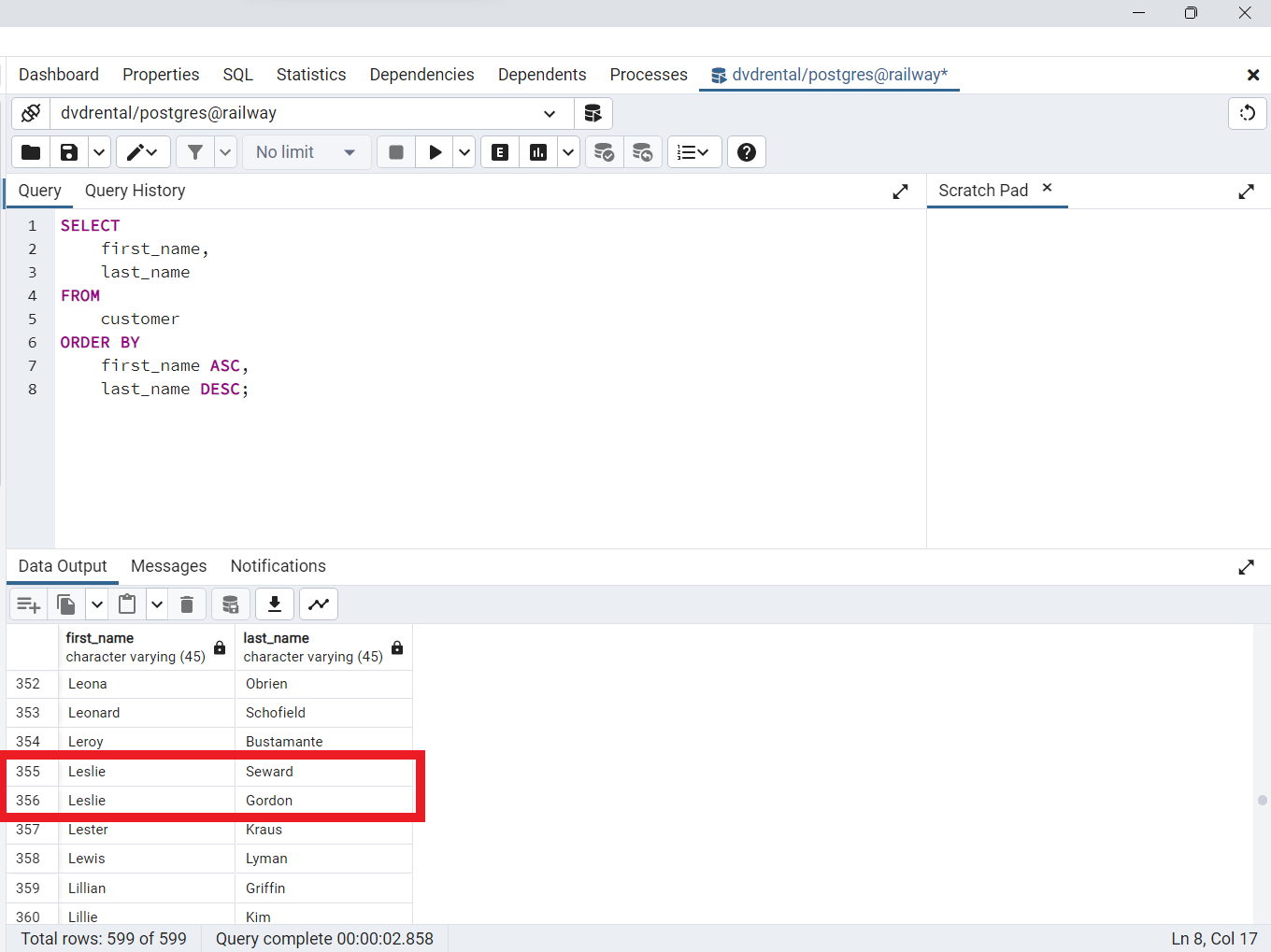
Fig. 57 Consulta SQL para ordenar dos columnas primero a ascendente seguida de la descendente.#
Cláusula ORDER BY de PostgreSQL para ordenar filas por expresiones
La función
LENGTH()acepta una cadena y devuelve su longitud. La siguiente sentencia selecciona los nombres y sus longitudes. Ordena las filas por la longitud de los nombres
SELECT
first_name,
LENGTH(first_name) len
FROM
customer
ORDER BY
len DESC;
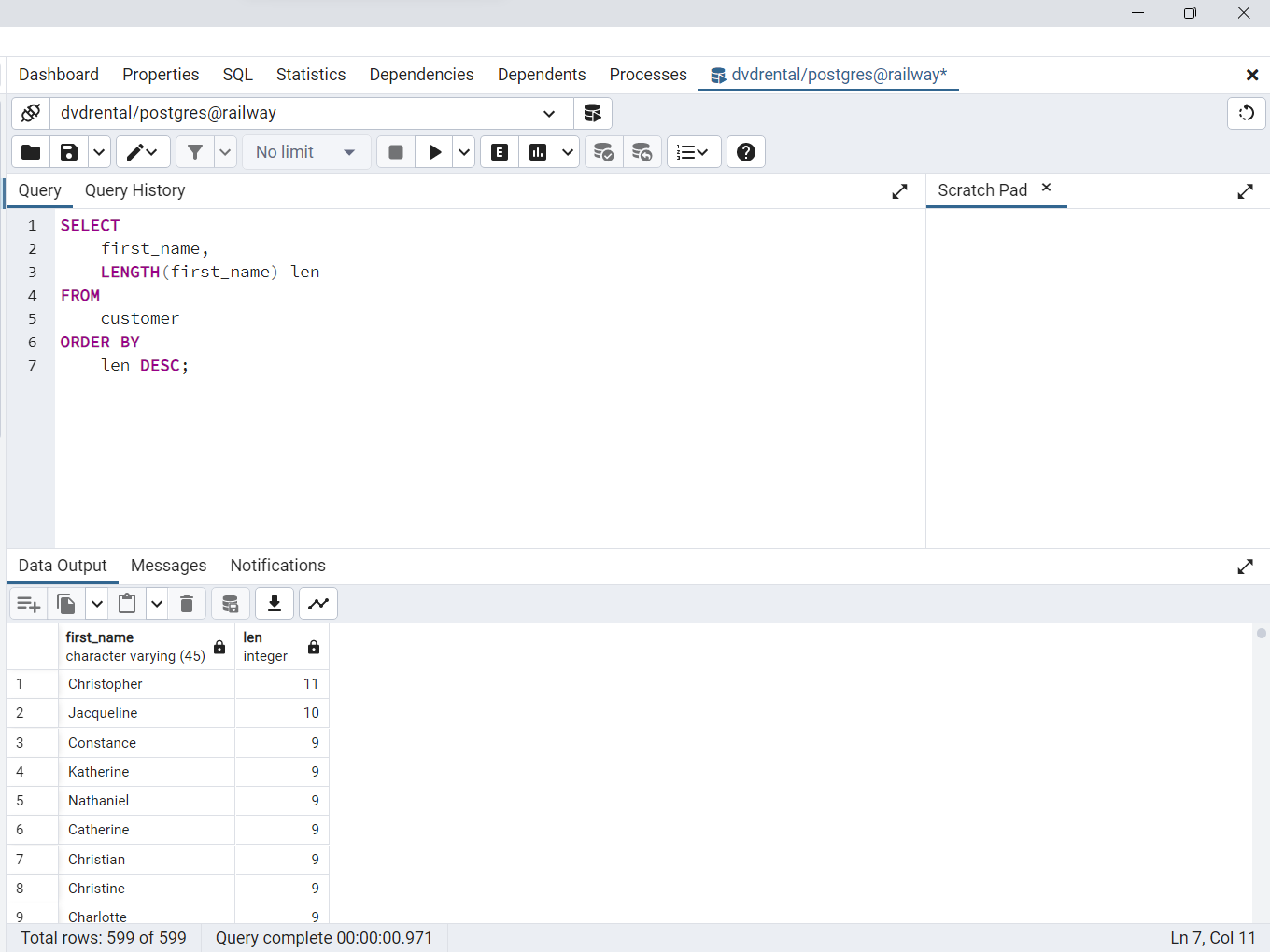
Fig. 58 Filas ordenadas por columna y expresión.#
Como la cláusula
ORDER BYse evalúa después de la cláusulaSELECT, el aliaslende la columna está disponible y se puede utilizar en la cláusulaORDER BY
Cláusula ORDER BY de PostgreSQL y NULL
En algunas bases de datos existen datos faltantes
NULLlos cuales debe ser tratados con técnicas estadísticas adecuadas. Usualmente este tipo de datos son desconocidos en el momento del registro.Cuando se trata de ordenar filas que contienen valores
NULL, existe la posibilidad de establecer el orden de losNULLen relación con los valores no nulos utilizando las opcionesNULLS FIRSToNULLS LASTen la cláusulaORDER BY.
ORDER BY sort_expresssion [ASC | DESC] [NULLS FIRST | NULLS LAST]
La opción
NULLS FIRSTcolocaNULLantes de otros valores no nulos y la opciónNULL LASTcolocaNULLdespués de otros valores no nulos. Vamos a crear una tabla para la demostración.
CREATE TABLE sort_demo(
num INT
);
INSERT INTO sort_demo(num)
VALUES(1),(2),(3),(null);
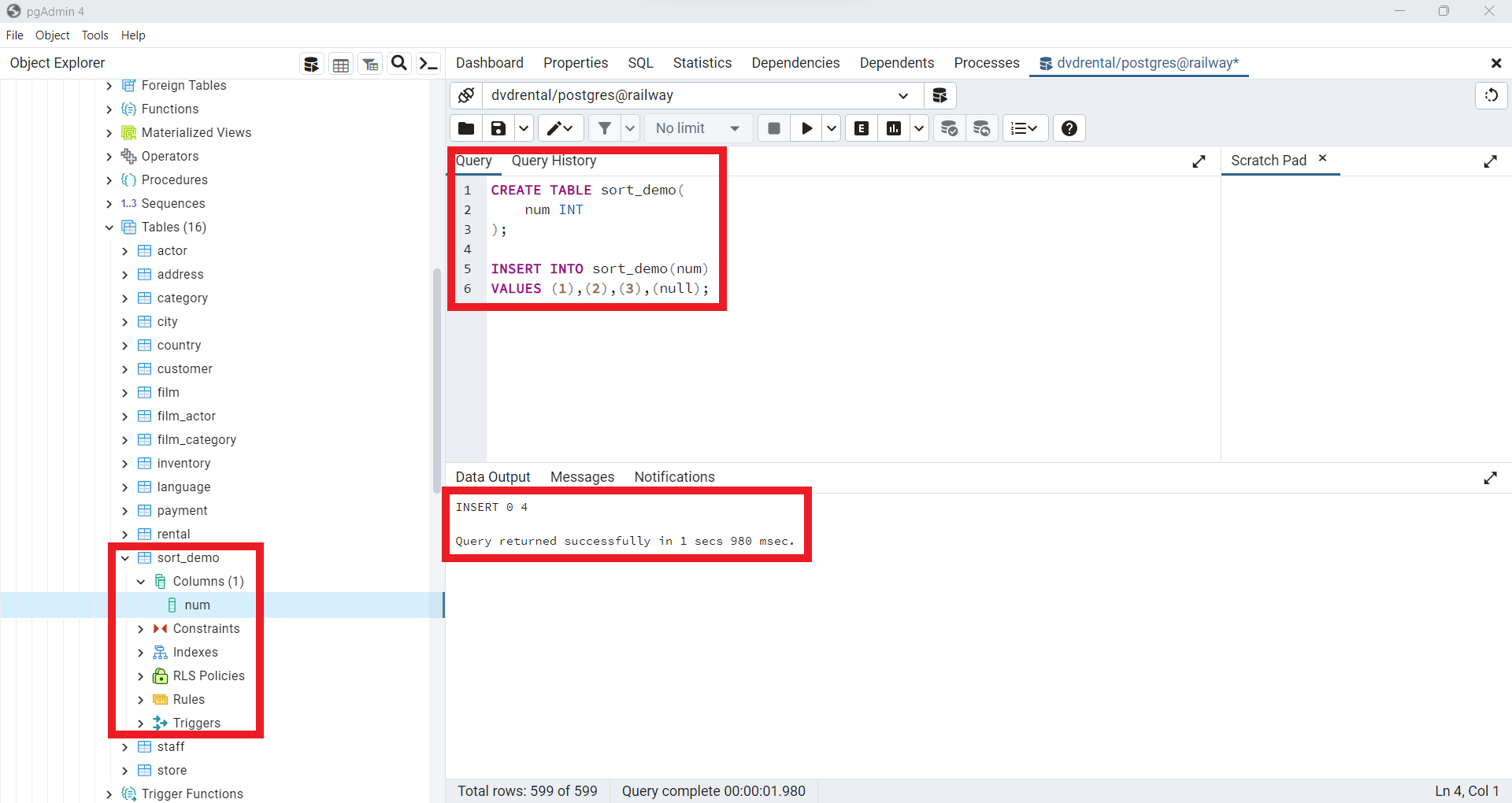
Fig. 59 Creación de tabla en la base de datos dvdrental en Railway.#
La siguiente consulta devuelve datos de la tabla
sort_demo
SELECT num
FROM sort_demo
ORDER BY num;
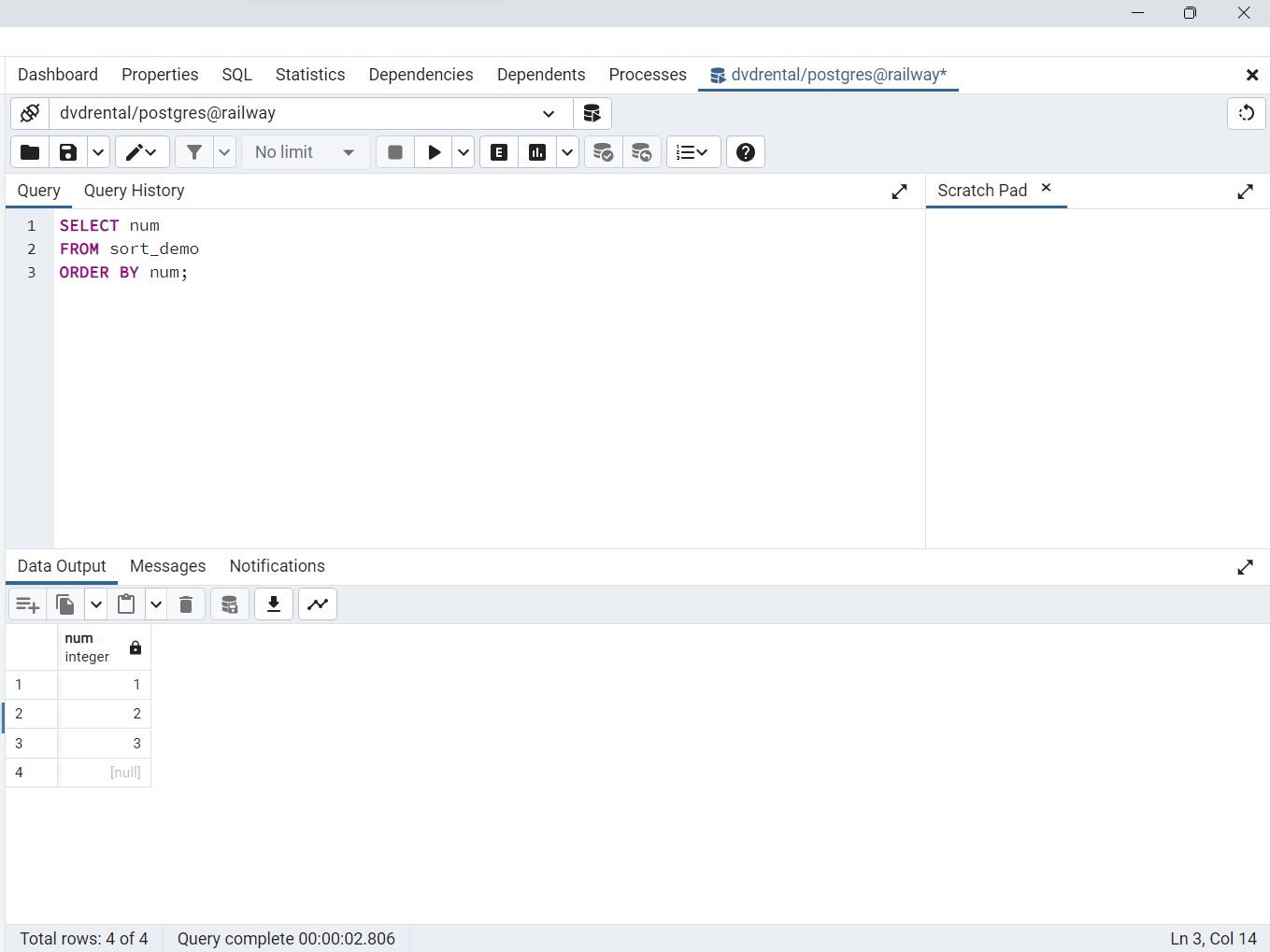
Fig. 60 Orden ascendente de filas en sort_demo por medio de la columna num.#
La cláusula
ORDER BYordena los valores de la columnanumde la tablasort_demoen orden ascendente. ColocaNULLdespués de otros valores. Por lo tanto, si utiliza la opciónASC, la cláusulaORDER BYutiliza por defecto la opciónNULLS LAST. Por lo tanto, la siguiente consulta devuelve el mismo resultado
SELECT num
FROM sort_demo
ORDER BY num NULLS LAST;
Para anteponer
NULLa otros valores no nulos, se utiliza la opciónNULLS FIRST
SELECT num
FROM sort_demo
ORDER BY num NULLS FIRST;
La siguiente sentencia ordena los valores de la columna
numde la tablasort_demoen orden descendente
SELECT num
FROM sort_demo
ORDER BY num DESC;
La cláusula
ORDER BYcon la opciónDESCutiliza losNULLS FIRSTpor defecto. Para invertir el orden, puede utilizar la opciónNULLS LAST
SELECT num
FROM sort_demo
ORDER BY num DESC NULLS LAST;
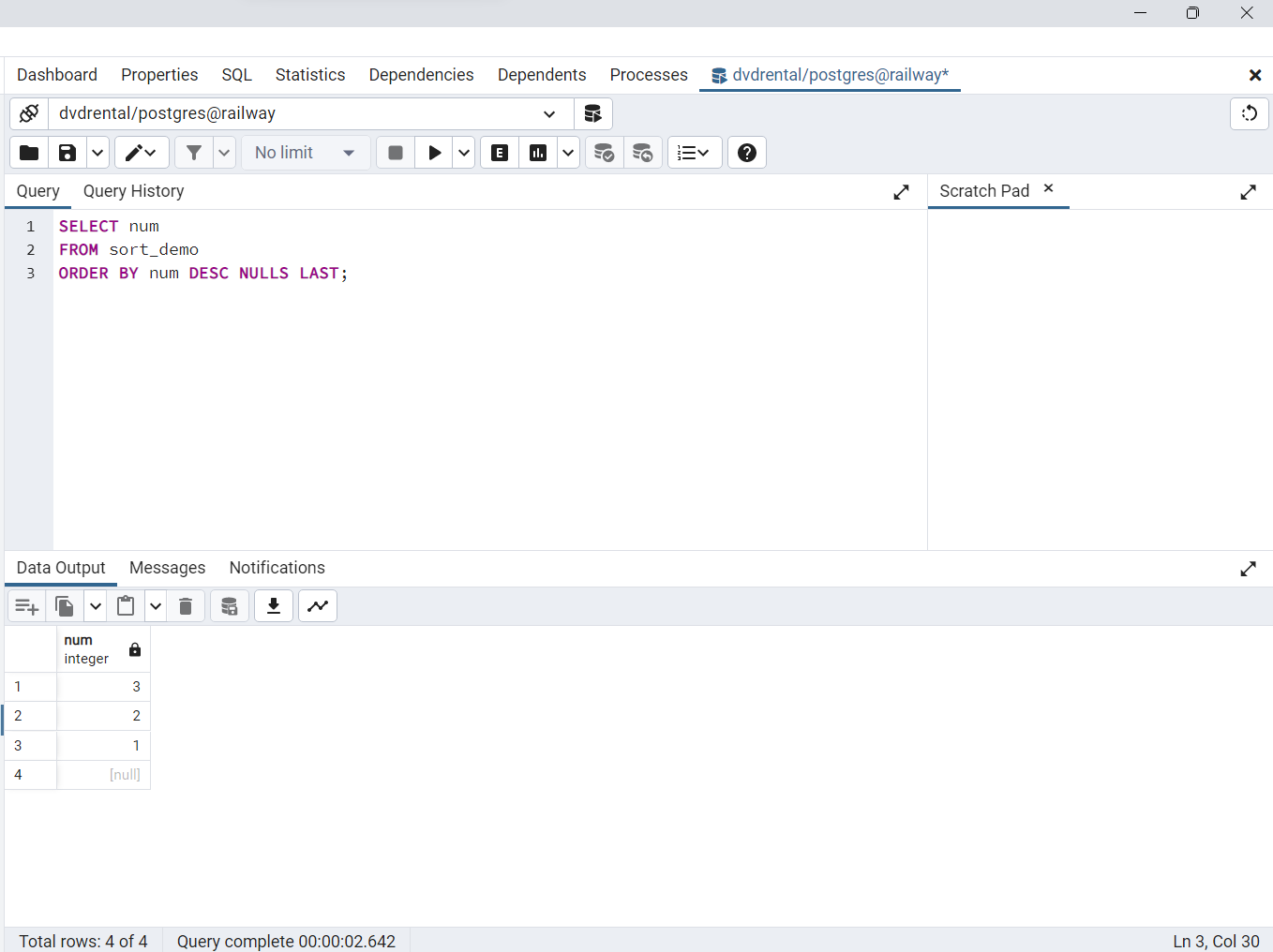
Fig. 61 Opción DESC para ordenar filas en sort_demo en forma descendente, con NULL al final, usando la opción NULL LAST.#
SELECT DISTINCT#
La cláusula
DISTINCTse emplea en la sentenciaSELECTparaeliminar filas repetidas de un conjunto de resultados. Al utilizar esta cláusula, se conserva una única fila para cada grupo de duplicados. Es posible aplicarla a una o varias columnas de la lista de selección en la sentenciaSELECT. La sintaxis es la siguiente
SELECT
DISTINCT column1
FROM
table_name;
En esta sentencia, se verifica si existen duplicados al evaluar los valores de la columna
"column1". Si se especificanmúltiples columnas, la cláusulaDISTINCTdeterminará si hay duplicados al considerar la combinación de valores de esas columnas. En resumen, la cláusulaDISTINCTevalúa duplicados utilizando los valores de una o más columnas específicas.
SELECT
DISTINCT column1, column2
FROM
table_name;
En esta situación, se utilizará la combinación de valores en las columnas
"columna1"y"columna2"para determinar si hay duplicados. Además,PostgreSQLofrece la cláusulaDISTINCT ON (expresión)para conservar únicamente la “primera” fila de cada grupo de duplicados, siguiendo la siguiente sintaxis:
SELECT
DISTINCT ON (column1) column_alias,
column2
FROM
table_name
ORDER BY
column1,
column2;
PostgreSQL SELECT DISTINCT
Para practicar el uso de la cláusula
DISTINCT, crearemos una tabla llamadadistinct_demoy realizaremos inserciones de datos en ella. Para crear la tabladistinct_democon tres columnasid, bcoloryfcolor, utilice la siguiente sentenciaCREATE TABLE
CREATE TABLE distinct_demo (
id serial NOT NULL PRIMARY KEY,
bcolor VARCHAR,
fcolor VARCHAR
);
A continuación, utilice la sentencia
INSERTpara agregar algunas filas a la tabladistinct_demo
INSERT INTO distinct_demo (bcolor, fcolor)
VALUES
('red', 'red'),
('red', 'red'),
('red', NULL),
(NULL, 'red'),
('red', 'green'),
('red', 'blue'),
('green', 'red'),
('green', 'blue'),
('green', 'green'),
('blue', 'red'),
('blue', 'green'),
('blue', 'blue');
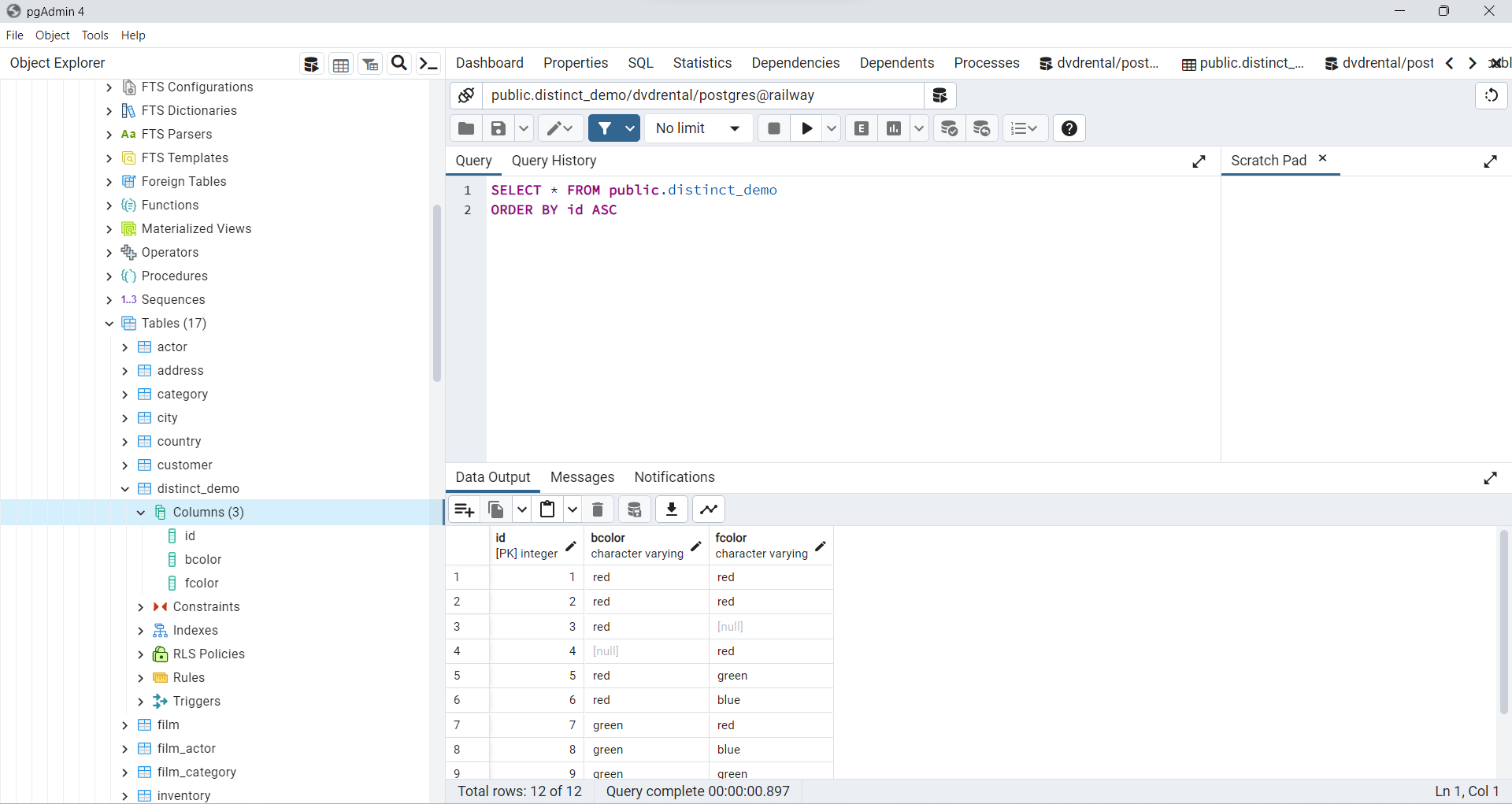
Fig. 62 Tabla distinct_demo creada en Docker mediante CREATE TABLE e INSERT INTO.#
Posteriormente, recupera los datos de la tabla
distinct_demoutilizando la sentenciaSELECT.
SELECT
id,
bcolor,
fcolor
FROM
distinct_demo ;
PostgreSQL DISTINCT para una columna
La siguiente sentencia selecciona valores únicos en la columna
bcolorde la tablat1y los ordena de forma alfabética utilizando la cláusulaORDER BY.
SELECT
DISTINCT bcolor
FROM
distinct_demo
ORDER BY
bcolor;
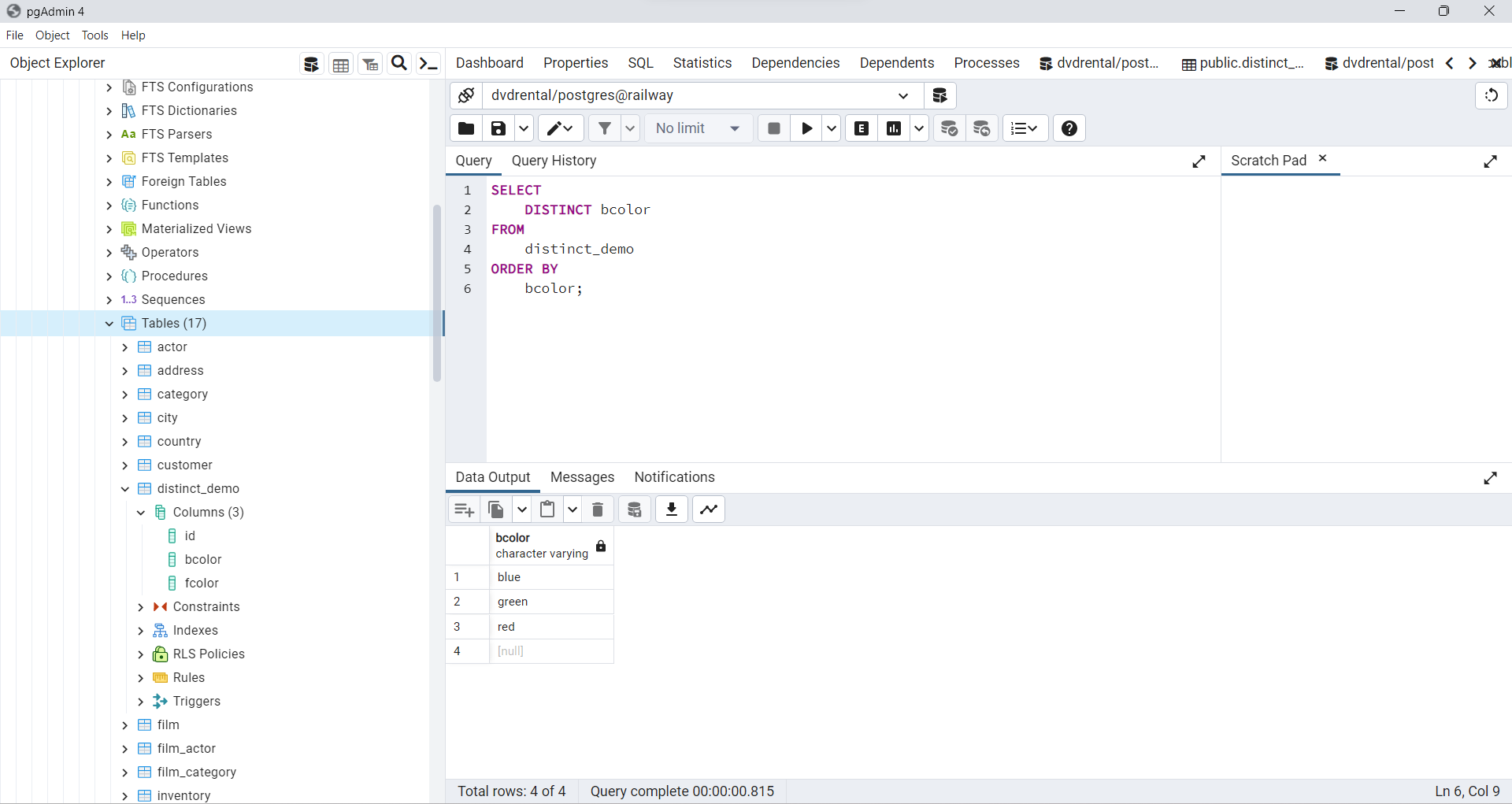
Fig. 63 Selección de valores únicos en la columna bcolor ordenados alfabéticamente.#
PostgreSQL DISTINCT múltiples columnas
La siguiente sentencia ejemplifica el uso de la cláusula DISTINCT en múltiples columnas.
SELECT
DISTINCT bcolor,
fcolor
FROM
distinct_demo
ORDER BY
bcolor,
fcolor;
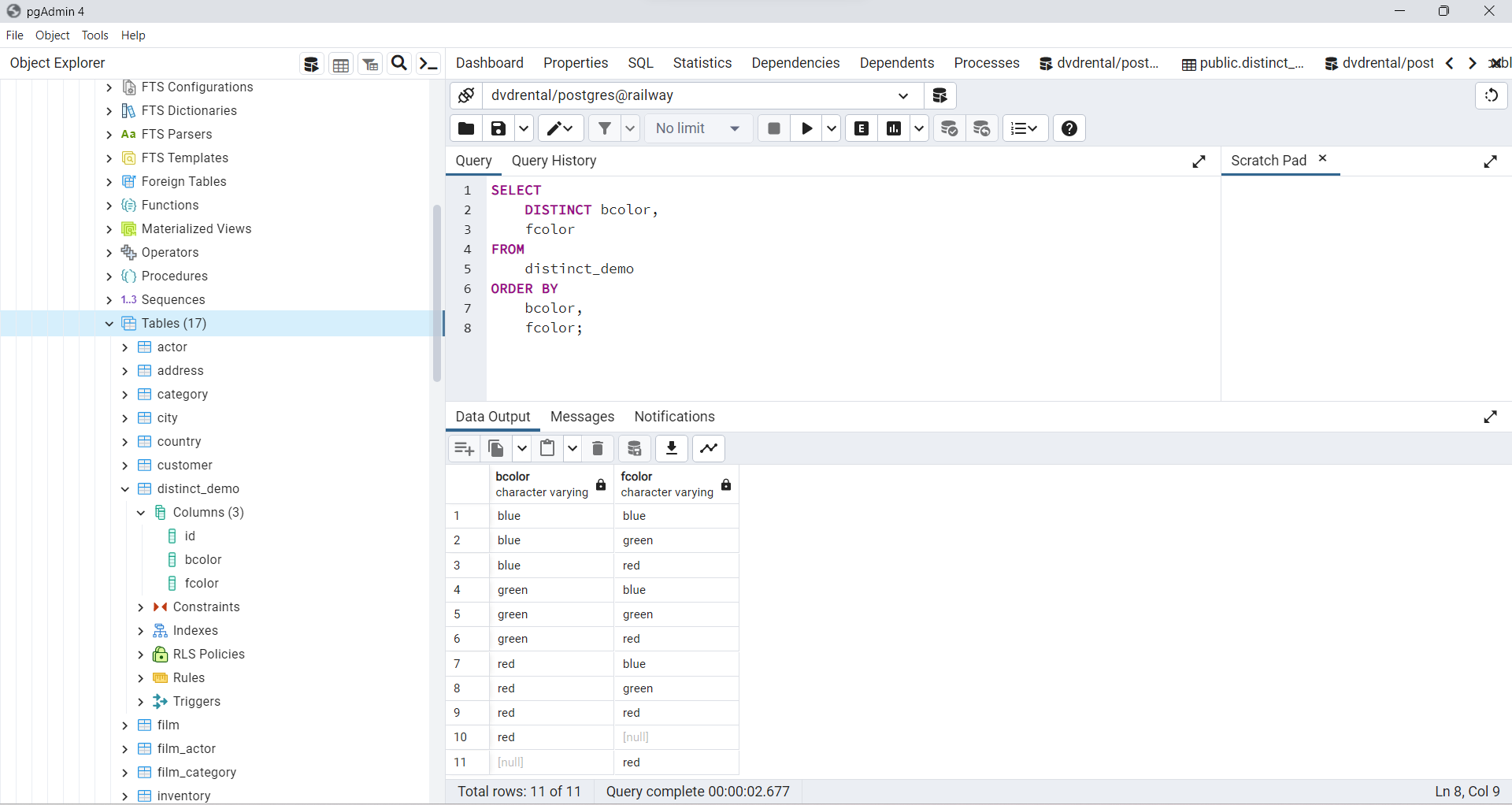
Fig. 64 Selección de valores únicos con base en las columnas: bcolor y fcolor.#
Al incluir las columnas
bcoloryfcoloren la cláusulaSELECT DISTINCT,PostgreSQLcombinó los valores de ambas columnas para determinar la unicidad de las filas.
WHERE#
En esta sección estudiaremos como usar la consulta
WHERE. La sentenciaSELECTrecupera datos de una tabla, devolviendo filas y columnas. Si deseas filtrar los resultados según una condición, puedes utilizar la cláusulaWHERE. La forma en que se escribe la cláusula WHERE en PostgreSQL es la siguiente:
SELECT select_list
FROM table_name
WHERE condition
ORDER BY sort_expression
La cláusula
WHEREse utiliza después de la cláusulaFROMen una sentenciaSELECT. Su función esfiltrar las filas devueltas por la consulta en base a una condición. La condición puede ser unaexpresión booleana o una combinación de ellasusando los operadoresANDyOR. Solo las filas que cumplan con la condición se incluirán en el resultado de la consulta. Para otros operadores de comparación (ver Funciones y operadores de comparación)
Uso de la cláusula WHERE con el operador igual (=)
Vamos a practicar con ejemplos de cómo utilizar la cláusula
WHERE. Usaremos la tabla decustomerde la base de datos de ejemplo para la demostración. La siguiente sentencia muestra cómo utilizar la cláusulaWHEREpara seleccionar clientes cuyos nombres sonJamie:
SELECT
last_name,
first_name
FROM
customer
WHERE
first_name = 'Jamie';
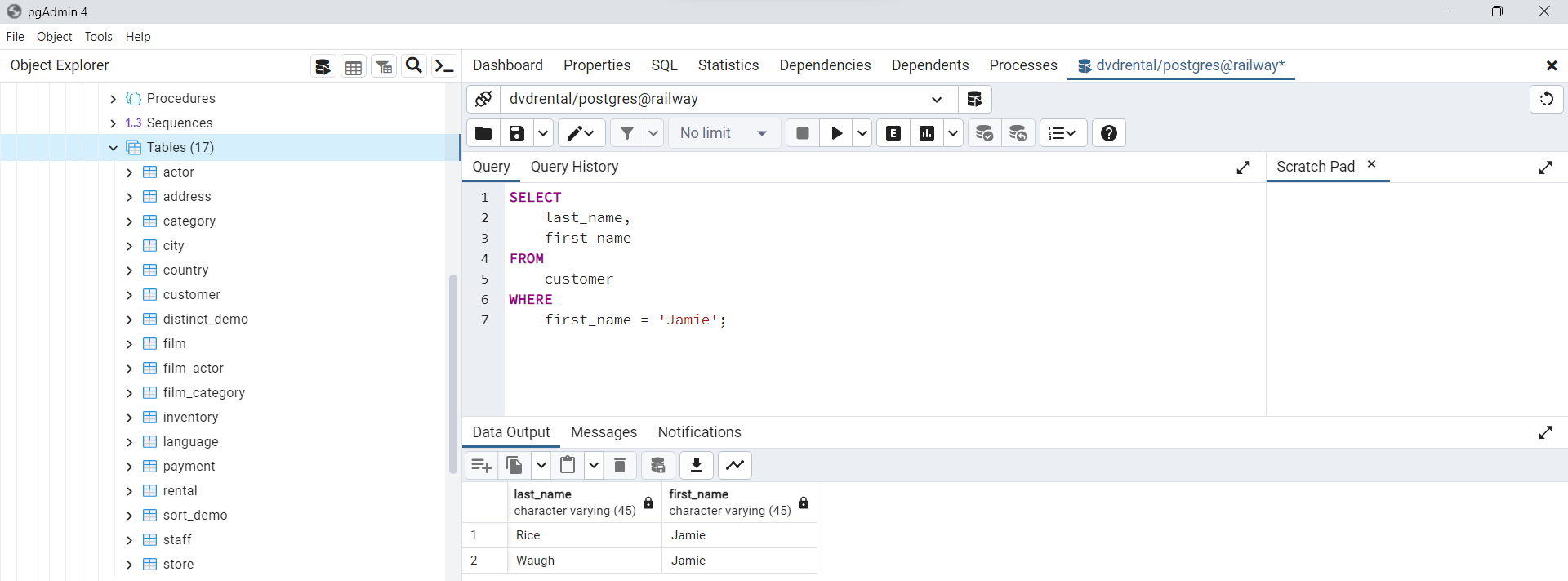
Fig. 65 Uso del condicional WHERE para filtrar columna por operador (=).#
Uso de la cláusula WHERE con el operador AND
En el siguiente ejemplo, se busca clientes que tengan tanto el nombre como los apellidos igual a
JamieyRice, respectivamente. Esto se logra utilizando el operador lógicoANDpara combinar las dos expresiones booleanas.
SELECT
last_name,
first_name
FROM
customer
WHERE
first_name = 'Jamie' AND
last_name = 'Rice';
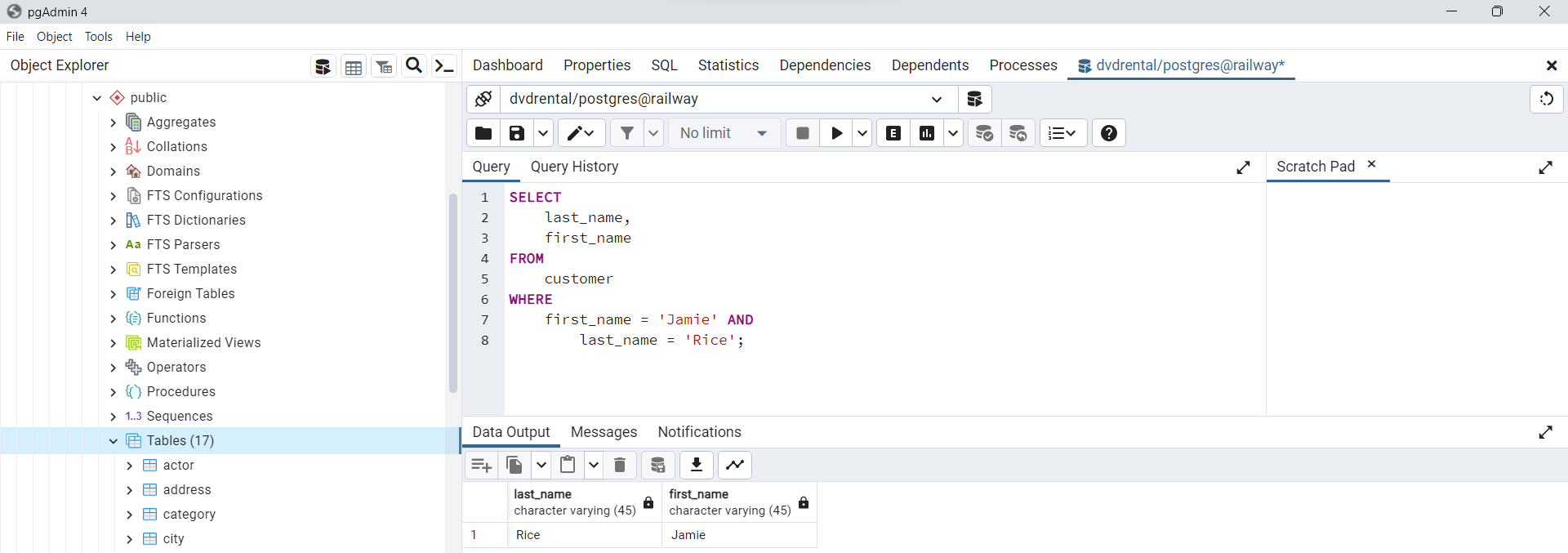
Fig. 66 Uso de cláusula WHERE con el operador AND.#
Uso de la cláusula WHERE con el operador OR
En este ejemplo, se buscan clientes que tengan como apellido
Rodríguezo como nombreAdán. Esto se logra utilizando el operadorORpara combinar las dos condiciones.
SELECT
first_name,
last_name
FROM
customer
WHERE
last_name = 'Rodriguez' OR
first_name = 'Adam';
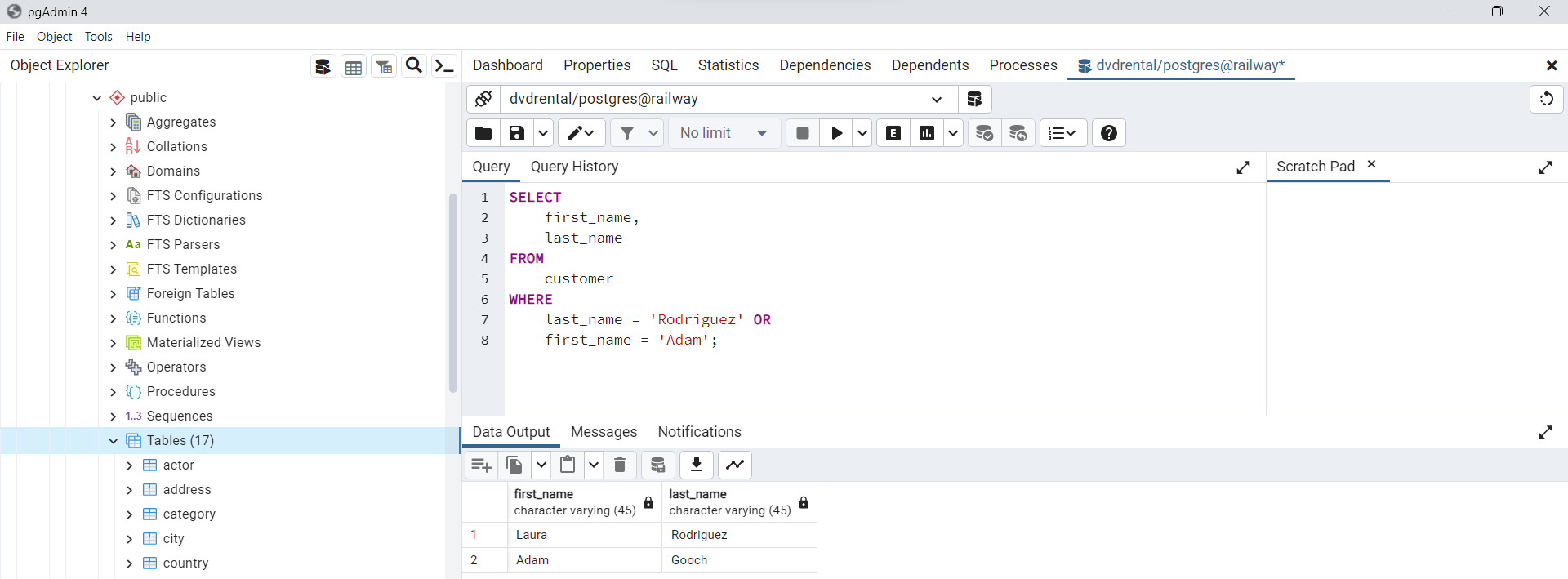
Fig. 67 Ejemplo de uso de WHERE con el operador OR.#
Uso de la cláusula WHERE con el operador IN
Si deseas que una cadena coincida con cualquiera de las cadenas de una lista, puedes utilizar el operadorIN. Por ejemplo, la siguiente sentencia selecciona clientes cuyo primer nombre puede serAnn, Anne o Annie.
SELECT
first_name,
last_name
FROM
customer
WHERE
first_name IN ('Ann','Anne','Annie');
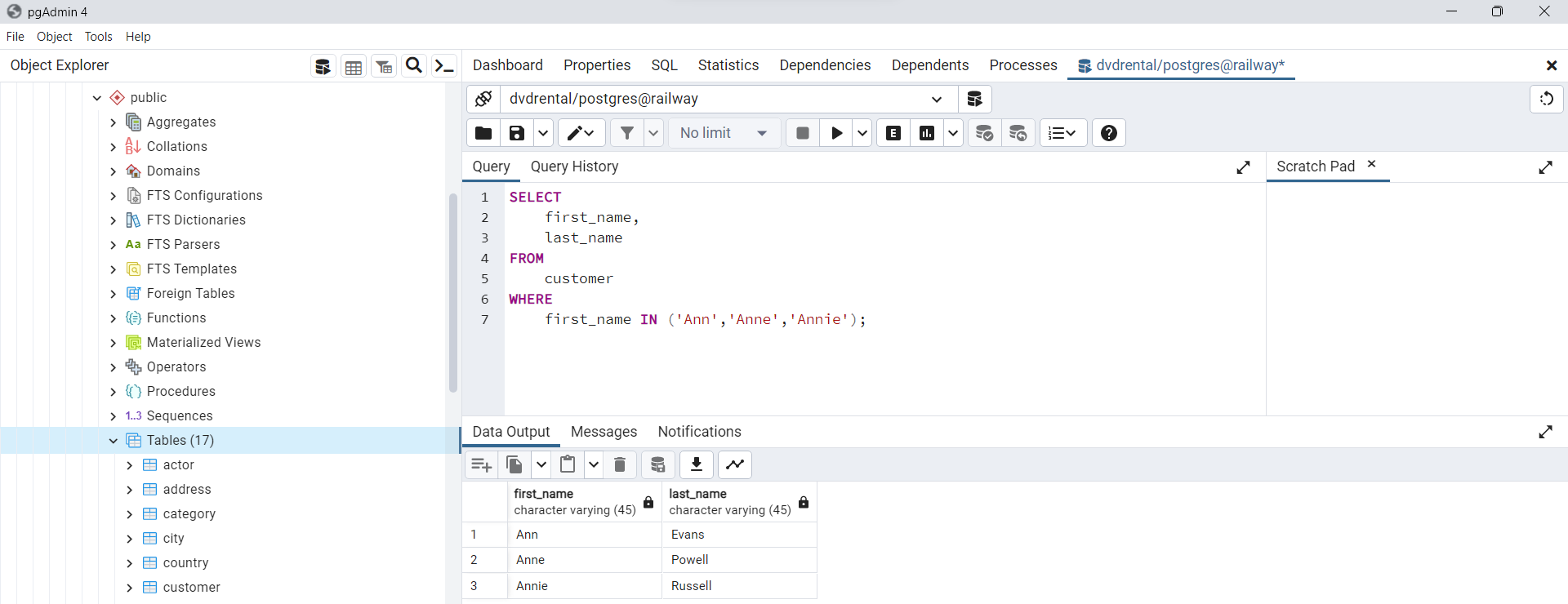
Fig. 68 Ejemplo de uso de cláusula WHERE con operador IN.#
Uso de la cláusula WHERE con el operador LIKE
Para buscar una cadena que cumpla con un patrón específico, se utiliza el operador
LIKE. En el siguiente ejemplo, se muestran todos los clientes cuyo nombre comienza con la cadenaAnn.
SELECT
first_name,
last_name
FROM
customer
WHERE
first_name LIKE 'Ann%'
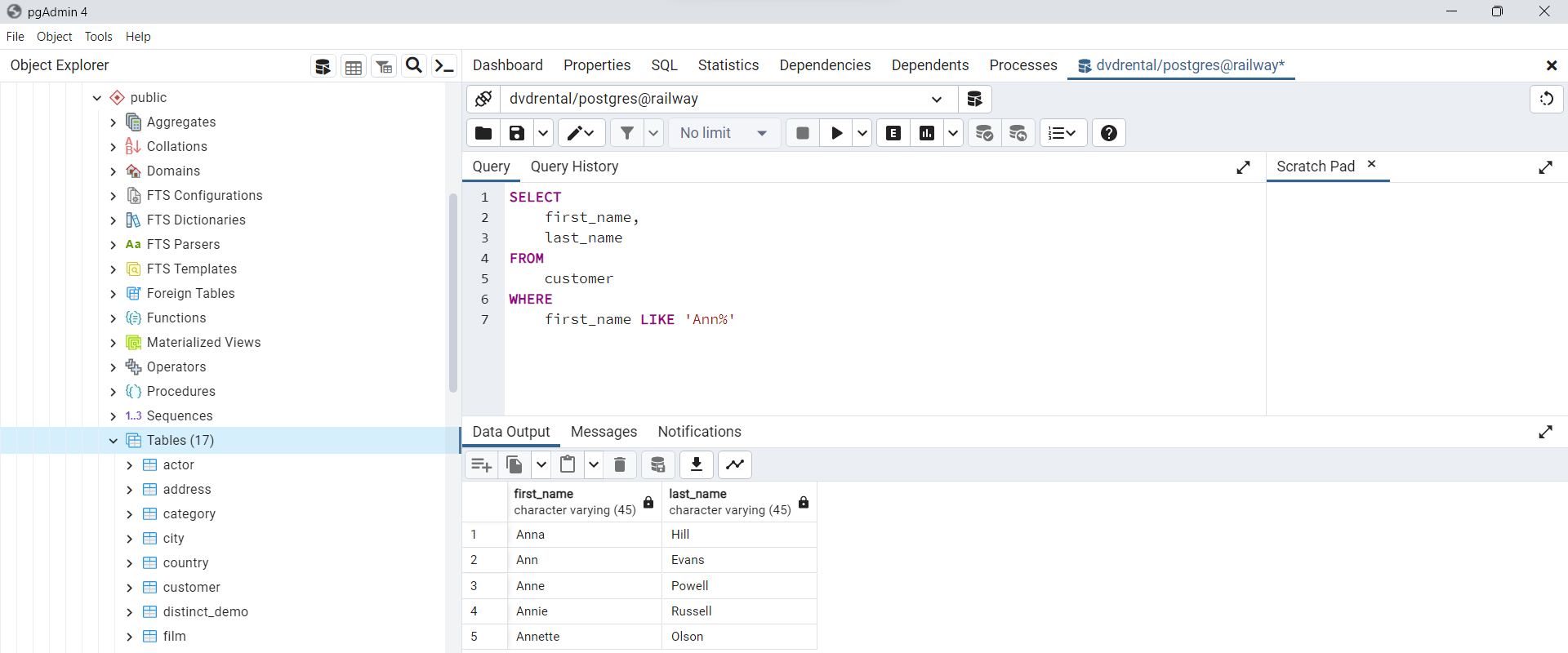
Fig. 69 Ejemplo de cláusula WHERE con el operador LIKE.#
Uso de la cláusula WHERE con el operador BETWEEN
En el siguiente ejemplo, se buscan clientes cuyo
nombre comienza con la letra A y tiene entre 3 y 5 caracteres de longitud. Esto se logra utilizando el operadorBETWEEN. El operadorBETWEENdevuelve verdadero si un valor se encuentra dentro de un rango de valores específico.
SELECT
first_name,
LENGTH(first_name) name_length
FROM
customer
WHERE
first_name LIKE 'A%' AND
LENGTH(first_name) BETWEEN 3 AND 5
ORDER BY
name_length;
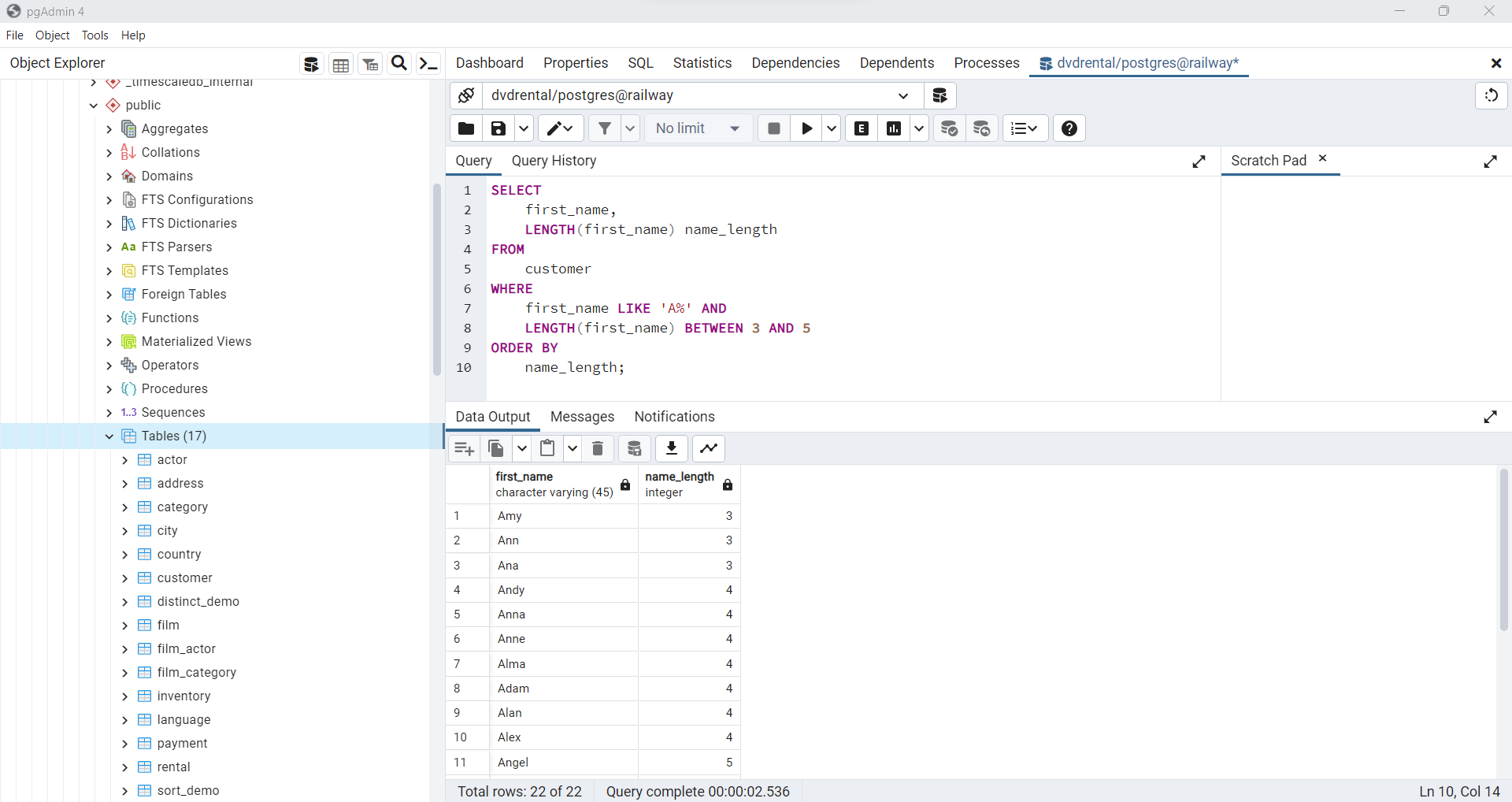
Fig. 70 Ejemplo de uso de WHERE con el operador BETWEEN.#
Uso de la cláusula WHERE con el operador no igual (<>)
En este ejemplo, se buscan clientes cuyo nombre comienza con
Bray cuyos apellidos no sonMotley. Tenga en cuenta que puede utilizar el operador!=y el operador<>indistintamente porque son equivalentes.
SELECT
first_name,
last_name
FROM
customer
WHERE
first_name LIKE 'Bra%' AND
last_name <> 'Motley';
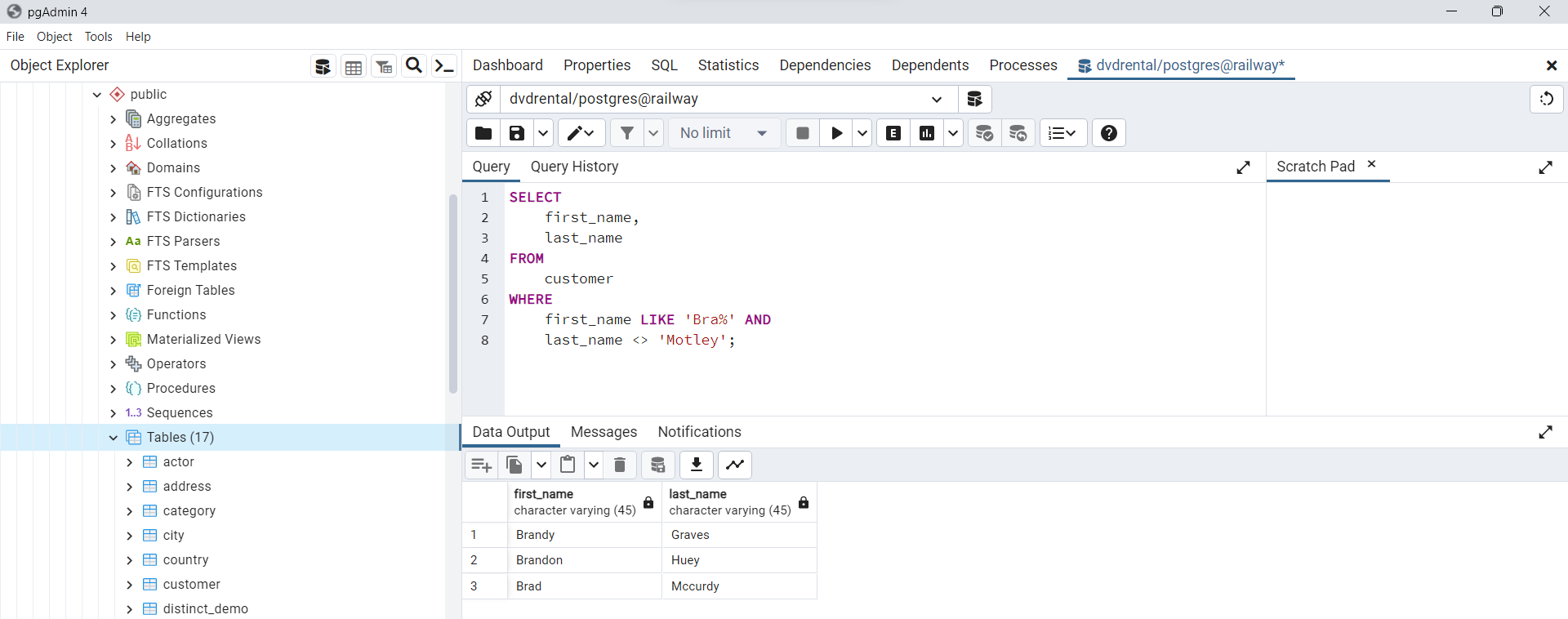
Fig. 71 Ejemplo de uso de la sentencia WHERE con el operador <>.#
En la siguiente sección realizaremos consultas de este tipo desde
Python, utilizando alAPIque ofrecePostgreSQLpara esta tarea. Existen muchas mas consultasSQLque puede realizar, dependiendo de cual sea su objetivo. En este taller se abordaron algunas de las mas utilizadas, pero, puede encontrar mas de estas en Queries PostgreSQL.
Configuración de su entorno usando Python, JupyterLab y VS Code#
Para la instalación de cada una de las librerías que usaremos en esta sección. Crearemos un
entorno virtualaislado dePythonen el cual instalaremos cada una de las dependencias que serán utilizadas, en especial la instalación dejupyter-bookypsycopg2mediante la orden:
pip install -U jupyter-book
pip install -U psycopg2
En su esencia, el propósito principal de los
entornos virtuales(virtual environment) dePythones crear un entorno aislado para sus proyectos dePython. Esto significa quecada proyecto puede tener sus propias dependencias, independientemente de las que tengan los demás proyectos. Lo bueno de esto, es que no hay límites en el número de entornos que puedes tener, ya que sólo son directorios que contienen unos pocos scripts. Además, son fácilmente creados usando las herramientas de línea de comandosvirtualenvopyenv, en el caso deanacondapor medio deconda create.
Para crear un
environmentdePythoncon el nombrepsqlpy_venv, por ejemplo, escriba la siguiente orden un su terminal, en el caso deWindowsen elWindows PowerShellel cual tiene un aspecto muy parecido al deUbuntu.
python -m venv psqlpy_venv
Es una buena costumbre crear los
environmenten una carpeta aislada de sincronizaciones en la nube, del tipo:OneDrive, Dropbox, Mega, etc,.... Es recomendable crear un carpeta nombrada por ejemplo:python_venven el disco localPS C:\python_venv>donde van a reposar todos susentornos virtualesy acceder a esta para activarlos.Al final de la ejecución del comando anterior, se creará una nueva carpeta con el nombre del entorno, en este caso
psqlpy_venv. Para visualizar esta carpeta puede presionar ejecutar en la consolals
Luego nos vamos a mover a la carpeta asociada a nuestro nuevo entorno virtual
psqlpy_venvusando el comandocd, y dentro de esta vamos a ejecutar la siguiente orden para activar elenvironment:
.\psqlpy_venv\Scripts\activate
Nótese que en la parte izquierda de la linea de comandos, aparece el
nombre del environment en color verde, indicando que ha sido activado correctamente el entorno creado. Luego de activado el environment se puede mover al directorio donde desea realizar el desarrollo de esta sección.¡No necesita estar parado dentro de la carpeta asociada al environment!

Fig. 72 Activación de virtual environment de Python.#
Cuando se trata de activar entornos virtuales por primera vez, algunas maquinas pueden generar
mensajes de error similares al que se muestra a continuaciónvenv\Scripts\activate : File C:\Users\Dell\Desktop\flask\microblog\venv\Scripts\Activate.ps1 cannot be loaded because running scripts is disabled on this system. For more information, see about_Execution_Policies at https:/go.microsoft.com/fwlink/?LinkID=135170. At line:1 char:1 + venv\Scripts\activate + ~~~~~~~~~~~~~~~~~~~~~ + CategoryInfo : SecurityError: (:) [], PSSecurityException + FullyQualifiedErrorId : UnauthorizedAccess
Para solucionar este problema, ejecute en su terminal
Windows PowerShellla siguiente orden para solucionarlo:Set-ExecutionPolicy -ExecutionPolicy RemoteSigned -Scope Process
En algunos casos, cuando se trabaja con
máquinas que requieren de permisos específicos, por ejemplo, aquellas utilizadas en universidades y centros de investigación, debe usar la siguiente ordenSet-ExecutionPolicy RemoteSigned -Scope CurrentUser
Puede instalar dentro del entorno librerías útiles en
Ciencia de Datostales como:
pip install -U numpy
pip install -U scipy
pip install -U pandas
pip install -U matplotlib
pip install -U scikit-learn
Cada una de estas librerías pueden ser instaladas a traves de un archivo de requerimientos, el cual podemos crear con el nombre:
requirements.txty copiar en éste sin espacio a la izquierda el nombre de cada librería, una debajo de la otra, así:
numpy
scipy
pandas
matplotlib
scikit-learn
Luego desde la línea de comando solo debe ejecutar
pip install -r requirements.txt
Estaremos usando en esta sección
jupyter labyVS Codedebido a que son editores gratuitos. Otras opciones son:Sublime, Atom, IDLE, PyCharm, Sublime Text 3, Jupyter, Spyder, PyDev, Vim, GNU/Emacsentre otros. Seleccione aquel editor con el que se sienta más cómodo. Para instalarjupyter labescriba dentro del mismo environment
pip install jupyterlab
Iniciamos
jupyter labpara crear el archivorequirements.txtcon las librerías a instalar. Éste archivo podemos ir actualizándolo en el transcurso de la sección a medida que una nueva librería va siendo necesaria.
Crea el archivo
requirements.txtcon librerías a instalar. Nótese quejupyter labcuenta también con una terminal integrada, por lo tanto, luego de crear el archivo, puede abrir una terminal dentro dejupyter lab, activar el environment y luego instalar las librerías usandopip install -r requirements.txt
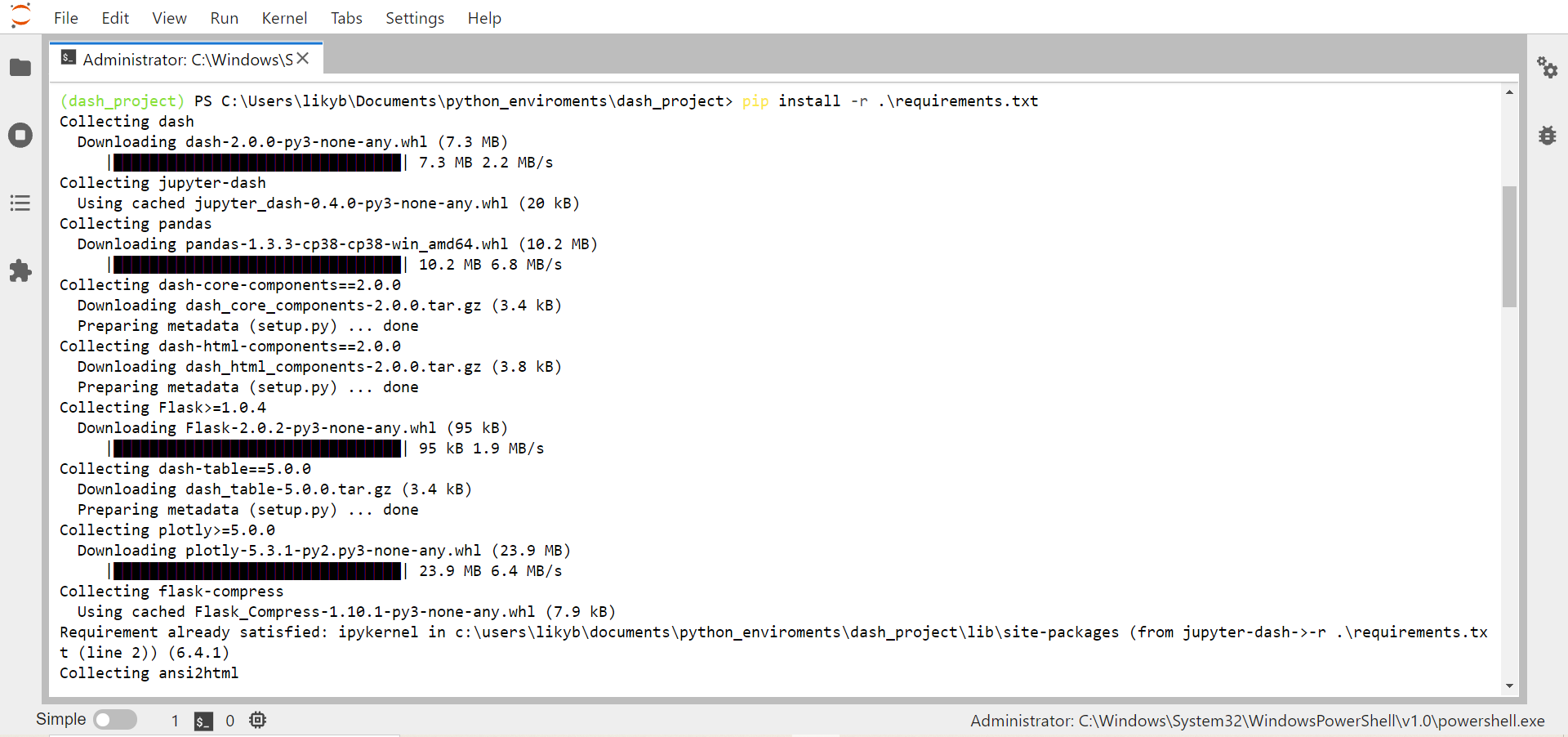
Si deseas utilizar un
entorno virtual específico en JupyterLab, debes seguir algunos pasos adicionales. Primero,activa tu entorno virtual, luego, instala el paqueteipykernelque proporciona elkernel IPythonnecesario paraJupyter. Estote permitirá agregar y utilizar el entorno virtual dentro de JupyterLab
pip install -U ipykernel
A continuación puede añadir su entorno virtual a
JupyterLabescribiendo:
python -m ipykernel install --user --name=psqlpy_venv
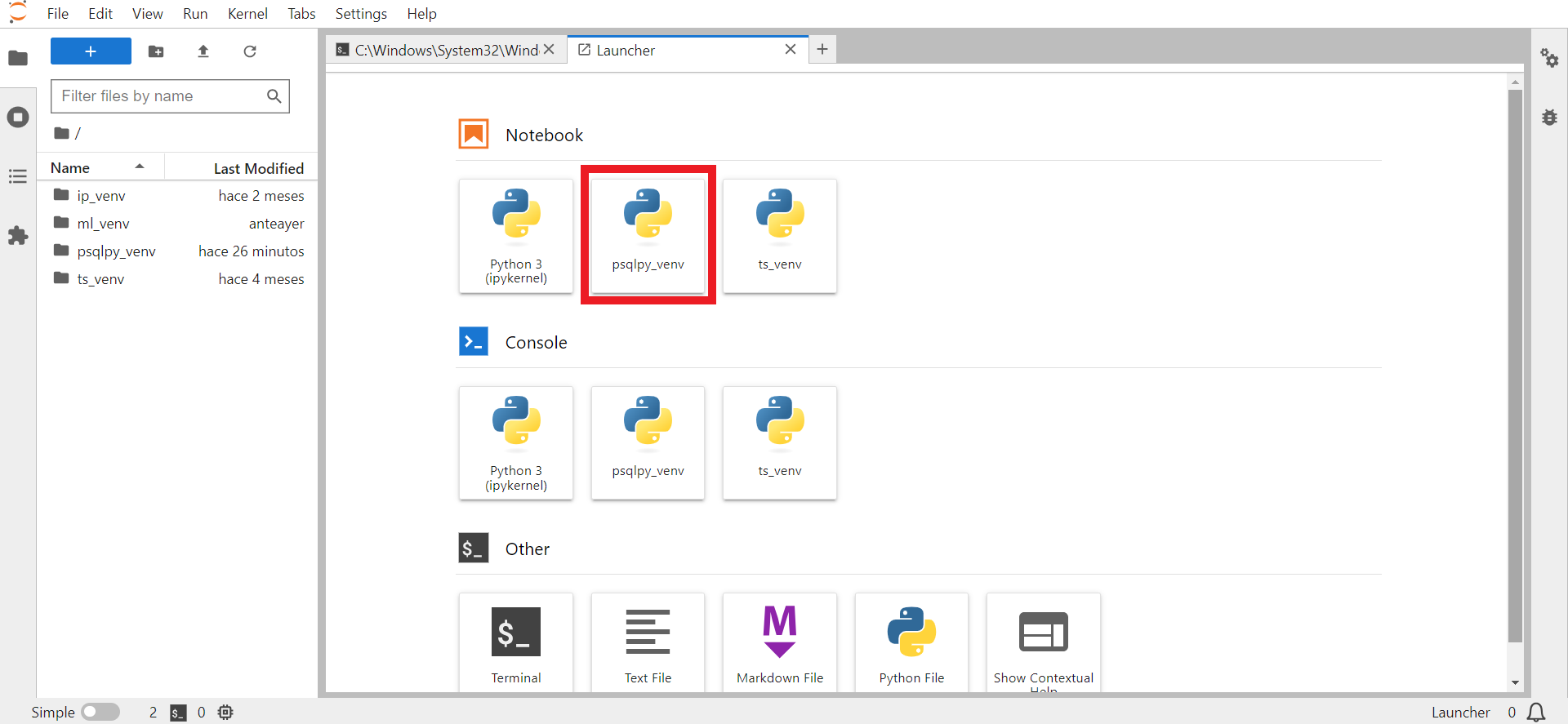
Fig. 73 Kernel psqlpy_venv listado dentro de JupyterLab.#
Si deseamos agregar el environment creado a
VS Code, debemos seguir las siguientes instrucciones:Presionar
Ctrl + Shit + PHacer click en:
Python: Select InterpreterHaga click en:
+ Enter interpreter path...Haga click en:
Find...Agregque la capreta donde se encuentra su environment, Ej:
C:\python_venv\psqlpy_venv\Scripts\pythonHaga click en
Select Interpreter
En la parte superior derecha de su editor de
VS Codeaparecerá la opciónSelect Kernel. Haga click sobre esta opción y luego enPython Environments..... Seleccione elenvironmentcreado.

Fig. 74 Selección de Python Environment desde VS Code.#
Luego de seleccionar el
environmentdeberá aparece en la parte superior derecha deVS Code, con el nombre creado inicialmente. El entorno estará listo para ser usado.
Python API for PostgreSQL#
PostgreSQLpuede ser integrado conPythonusando el módulopsycopg2.psycopg2es un adaptador de base de datosPostgreSQLpara el lenguaje de programaciónPython.psycopg2fue escrito con el objetivo de ser muypequeño, rápido y estable. No necesitas instalar este módulo por separado porque se entrega, por defecto, junto con la versión2.5.xdePythonen adelante. Sin embargo, si no lo tienes instalado en tu máquina, puedes usar los siguientes comandos según tu preferencia de gestor de instalación de paquetes
pip install -U psycopg2
Para aquellos que tienen instalado
Anacondaen sus computadoras
conda install -c anaconda psycopg2
Para utilizar el módulo
psycopg2, primero debecrear un objeto connection que represente la base de datosy luego, opcionalmente, puede crear un objetocursorque le ayudará a ejecutar todas las sentenciasSQL.
APIs del módulo Python psycopg2
Las siguientes son rutinas importantes del módulo
psycopg2, que pueden satisfacer su necesidad de trabajar con la base de datosPostgreSQLdesde su programaPython. Si usted está buscando una aplicación más sofisticada, entonces usted puede mirar en la documentación oficial del móduloPython psycopg2.Esta
APIabre una conexión a la base de datosPostgreSQL. Si la base de datos se abre con éxito, devuelve un objeto de conexión
psycopg2.connect(database="testdb", user="postgres", password="cohondob", host="127.0.0.1", port="5432")
Esta rutina
crea un cursorque se utilizará durante toda la programación de la base de datos conPython
connection.cursor()
Esta rutina ejecuta una sentencia
SQL. La sentenciaSQLpuede ser parametrizada (es decir, marcadores de posición en lugar de literalesSQL). El módulopsycopg2soportamarcadores de posiciónutilizando el signo%. Por ejemplo:cursor.execute("INSERT INTO people VALUES (%s, %s)", (who, age))
cursor.execute(sql [, optional parameters])
Esta rutina ejecuta un comando
SQLcontratodas las secuencias de parámetroso mapeos encontrados en la secuenciaSQL
cursor.executemany(sql, seq_of_parameters)
Este es un atributo de solo lectura, el cual
devuelve el número total de filas de la base de datosque han sido modificadas, insertadas o eliminadas por la última ejecución
cursor.rowcount
Este método
consigna la transacción actual. Si no se llama a este método, cualquier cosa que se haya hecho desde la última llamada acommit()no es visible desde otras conexiones de la base de datos
connection.commit()
Este método
revierte cualquier cambio en la base de datosdesde la última llamada acommit()
connection.rollback()
Este método
cierra la conexión a la base de datos. Tenga en cuenta que esto no llama automáticamente acommit().Si simplemente cierra la conexión a la base de datos sin llamar primero acommit(), ¡los cambios se perderán!
connection.close()
Este método
obtiene la siguiente fila de un conjunto de resultados de consulta, devolviendo una única secuencia, oNonecuando no hay más datos disponibles
cursor.fetchone()
Ejemplo
# Usando while loop
cursor.execute("SELECT * FROM employees")
row = cursor.fetchone()
while row is not None:
print(row)
row = cursor.fetchone()
# Usando el cursor como iterator
cursor.execute("SELECT * FROM employees")
for row in cursor:
print(row)
Esta rutina
obtiene el siguiente conjunto de filas de un resultado de consulta, devolviendo una lista. Se devuelve una lista vacía cuando no hay más filas disponibles. El método intenta obtener tantas filas como indique el parámetro de tamaño.
cursor.fetchmany([size=cursor.arraysize])
Esta rutina
recupera todas las filas (restantes) de un resultado de consulta, devolviendo una lista. Se devuelve una lista vacía cuando no hay filas disponibles.
cursor.fetchall()
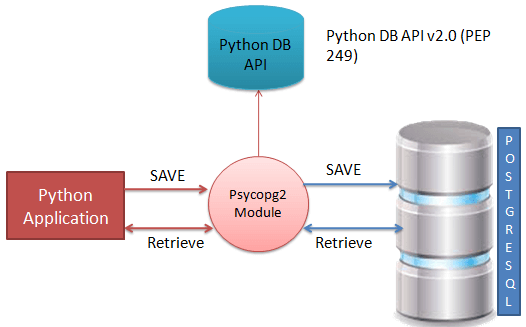
Fig. 75 Descripción del funcionamiento de la API psycopg2.#
Conexión a la base de datos
El siguiente código de
Pythonmuestra cómo conectarse a una base de datos existente. Para conectarse a la base de datosPostgreSQLy realizar consultasSQL,debe conocer las credenciales de la base de datos a la que se desea conectar. En éste caso la información de la base de datos creada la encontramos enDocker. Importamos primero las librerías necesarias para usarpsycopg2
import psycopg2
from psycopg2 import Error
try:
connection = psycopg2.connect(user="undatascience-user",
password="undatascience-password",
host="localhost",
port="5432",
database="undatascience-db")
cursor = connection.cursor()
print("PostgreSQL server information")
print(connection.get_dsn_parameters(), "\n")
cursor.execute("SELECT version();")
record = cursor.fetchone()
print("You are connected to - ", record, "\n")
except (Exception, Error) as error:
print("Error while connecting to PostgreSQL", error)
finally:
if (connection):
cursor.close()
connection.close()
print("PostgreSQL connection is closed")
PostgreSQL server information
{'user': 'undatascience-user', 'channel_binding': 'prefer', 'dbname': 'undatascience-db', 'host': 'localhost', 'port': '5432', 'options': '', 'sslmode': 'prefer', 'sslcompression': '0', 'sslcertmode': 'allow', 'sslsni': '1', 'ssl_min_protocol_version': 'TLSv1.2', 'gssencmode': 'disable', 'krbsrvname': 'postgres', 'gssdelegation': '0', 'target_session_attrs': 'any', 'load_balance_hosts': 'disable'}
You are connected to - ('PostgreSQL 16.3 (Debian 16.3-1.pgdg120+1) on x86_64-pc-linux-gnu, compiled by gcc (Debian 12.2.0-14) 12.2.0, 64-bit',)
PostgreSQL connection is closed
Crear una tabla
El siguiente programa de Python se utilizará para
crear una tabla en la base de datospreviamente creada
import psycopg2
connection = psycopg2.connect(user="undatascience-user",
password="undatascience-password",
host="localhost",
port="5432",
database="undatascience-db")
cursor = connection.cursor()
cursor.execute('''DROP TABLE IF EXISTS company''')
cursor.execute('''CREATE TABLE company(
id SERIAL PRIMARY KEY NOT NULL,
name TEXT NOT NULL,
age INT NOT NULL,
address CHAR(50),
salary REAL);
''')
print("Table created successfully")
connection.commit()
connection.close()
Table created successfully
Nótese en
pgAdminque la tabla fué creada exitosamente, dentro de la base de datos nombradadvdrental. También puede visualizar los cambios ocurridos en el dashboard depgAdmin.
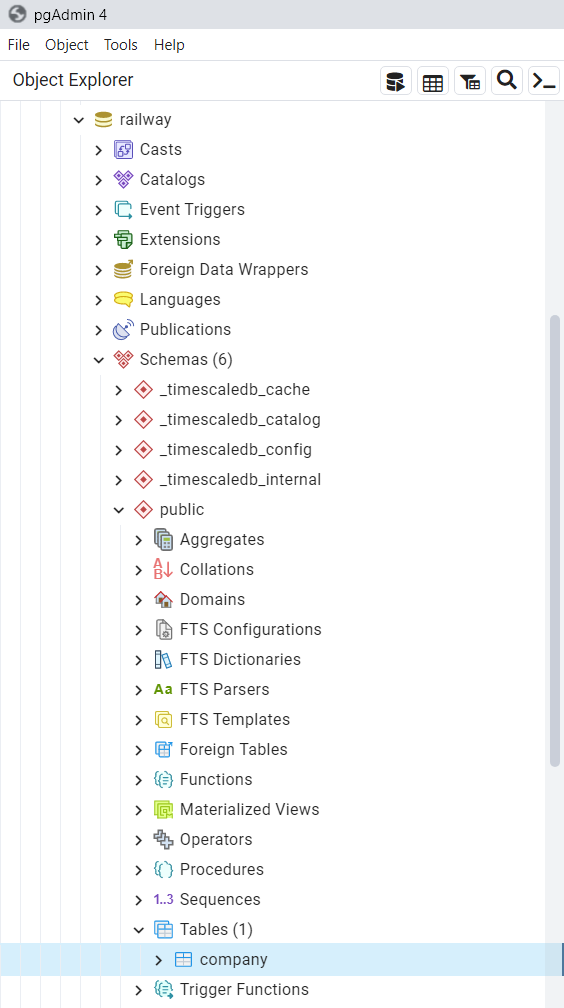
Fig. 76 Creación de tabla en base de datos PostgreSQL en Docker.#
Operación INSERT
El siguiente programa de
Pythonmuestra cómo podemos crear registros en nuestra tablacompanycreada en el ejemplo anterior
import psycopg2
connection = psycopg2.connect(user="undatascience-user",
password="undatascience-password",
host="localhost",
port="5432",
database="undatascience-db")
cursor = connection.cursor()
cursor.execute("INSERT INTO company (name, age, address, salary) VALUES ('Paul', 32, 'California', 20000.00 )");
cursor.execute("INSERT INTO company (name, age, address, salary) VALUES ('Allen', 25, 'Texas', 15000.00 )");
cursor.execute("INSERT INTO company (name, age, address, salary) VALUES ('Teddy', 23, 'Norway', 20000.00 )");
cursor.execute("INSERT INTO company (name, age, address, salary) \
VALUES ('Mark', 25, 'Rich-Mond ', 65000.00 )");
connection.commit()
print("Records created successfully")
connection.close()
Records created successfully
Observe desde
pgAdminque los registros han sido actualizados efectivamente, con los valores insertados en la tabla creada
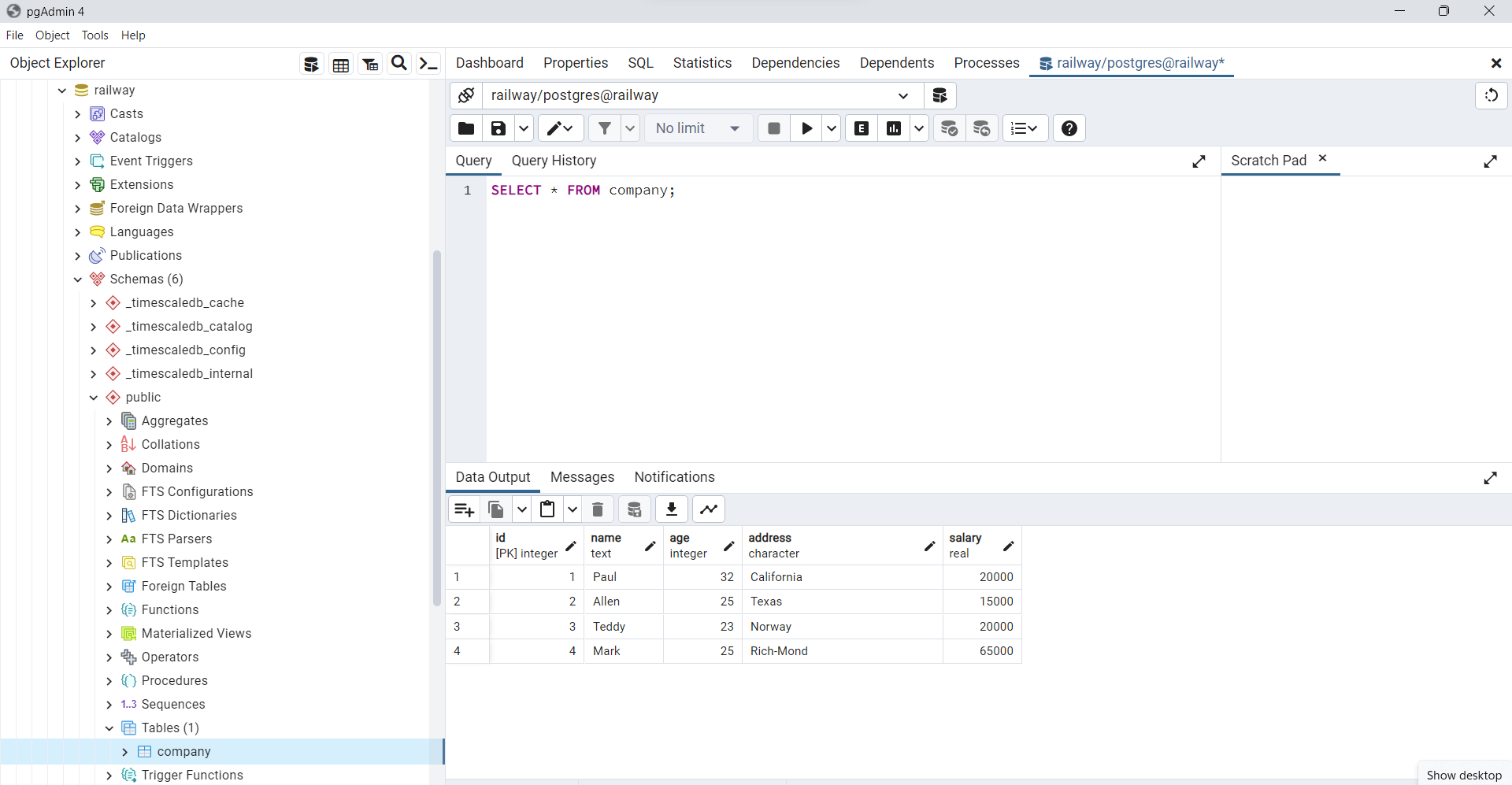
Fig. 77 Filas agregadas a la base de datos usando INSERT INTO.#
Operación SELECT
El siguiente programa de
Pythonmuestra cómo podemos obtener y mostrar registros de nuestra tablacompanycreada en el ejemplo anterior
import psycopg2
connection = psycopg2.connect(user="undatascience-user",
password="undatascience-password",
host="localhost",
port="5432",
database="undatascience-db")
cursor = connection.cursor()
cursor.execute("SELECT id, name, address, salary FROM company")
rows = cursor.fetchall()
for row in rows:
print("id = ", row[0])
print("name = ", row[1])
print("address = ", row[2])
print("salary = ", row[3], "\n")
print("Operation done successfully")
connection.close()
id = 1
name = Paul
address = California
salary = 20000.0
id = 2
name = Allen
address = Texas
salary = 15000.0
id = 3
name = Teddy
address = Norway
salary = 20000.0
id = 4
name = Mark
address = Rich-Mond
salary = 65000.0
Operation done successfully
Operación UPDATE
El siguiente código de
Pythonmuestra cómo podemos utilizar la sentenciaUPDATEpara actualizar cualquier registro y luego obtener y mostrar los registros actualizados de nuestra tablacompany
import psycopg2
connection = psycopg2.connect(user="undatascience-user",
password="undatascience-password",
host="localhost",
port="5432",
database="undatascience-db")
cursor = connection.cursor()
cursor.execute("UPDATE company set salary = 25000.00 where id = 1")
connection.commit()
print("Total number of rows updated :", cursor.rowcount)
cursor.execute("SELECT id, name, address, salary FROM company")
rows = cursor.fetchall()
for row in rows:
print("id = ", row[0])
print("name = ", row[1])
print("address = ", row[2])
print("salary = ", row[3], "\n")
print("Operation done successfully")
connection.close()
Total number of rows updated : 1
id = 2
name = Allen
address = Texas
salary = 15000.0
id = 3
name = Teddy
address = Norway
salary = 20000.0
id = 4
name = Mark
address = Rich-Mond
salary = 65000.0
id = 1
name = Paul
address = California
salary = 25000.0
Operation done successfully
Operación DELETE
El siguiente código de
Pythonmuestra cómo podemos utilizar la sentenciaDELETEpara eliminar cualquier registro y luego obtener y mostrar los registros restantes de nuestra tablacompany
import psycopg2
connection = psycopg2.connect(user="undatascience-user",
password="undatascience-password",
host="localhost",
port="5432",
database="undatascience-db")
cursor = connection.cursor()
cursor.execute("DELETE FROM company where id = 2;")
connection.commit()
print("Total number of rows deleted :", cursor.rowcount)
cursor.execute("SELECT id, name, address, salary FROM company")
rows = cursor.fetchall()
for row in rows:
print("id = ", row[0])
print("name = ", row[1])
print("address = ", row[2])
print("salary = ", row[3], "\n")
print("Operation done successfully")
connection.close()
Total number of rows deleted : 1
id = 3
name = Teddy
address = Norway
salary = 20000.0
id = 4
name = Mark
address = Rich-Mond
salary = 65000.0
id = 1
name = Paul
address = California
salary = 25000.0
Operation done successfully
Importar un archivo CSV o un pandas DataFrame en SQLite#
Introducción
Una alternativa a PostgreSQL es
SQLite.SQLitees una herramienta de software de código abierto que posibilita elalmacenamiento de datos en dispositivos integrados de manera simple, eficiente y rápida, incluso en dispositivos con recursos de hardware limitados, como PDAs o teléfonos móviles.SQLite es capaz de respaldar desde las consultas SQL más básicas hasta las más complejas, y lo más destacado es que se integra sin dificultades tanto en dispositivos móviles como en sistemas de escritorio, sin necesidad de procesos complicados de importación y exportación de datos. La compatibilidad total entre diversas plataformas garantiza que la portabilidad entre dispositivos y sistemas sea sin inconvenientes.
Para instalar SQLite debe visitar el sitio web oficial (ver SQLite download).
SQLiteofrece varias herramientas para trabajar en distintas plataformas, comoWindows, LinuxyMac. Debe seleccionar la versión adecuada para descargarla. Por ejemplo, para trabajar conSQLite en Windows, debe descargar el programa de shell de línea de comandos como se muestra en la siguiente captura de pantalla.

El archivo
sqlite-tools-win32-x86-3430200.zipdescargado del sitio web deSQLitedebe ser descomprimido en en una carpeta que puede nombrar comosqlitedentro del disco localC(C:\>sqlite). Luego agregue la ruta de esta carpeta a las variables de entorno (PATH environment variable) de windows.
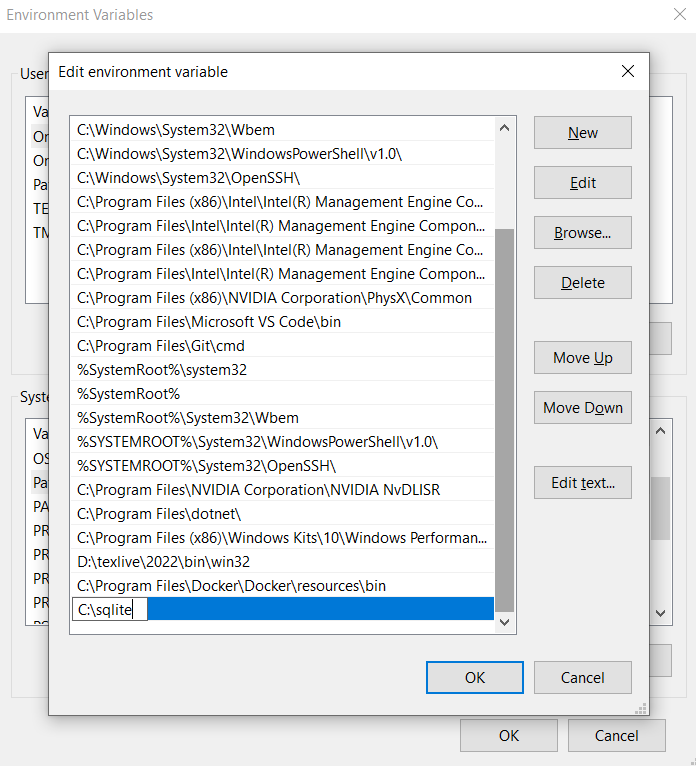
Para verificar que la instalación fue realizada correctamente, debe ejecutar desde la consola de
PowerShellla ordensqlite3

import sqlite3
from sqlite3 import Error
def create_connection(db_file):
""" create a database connection to a SQLite database """
conn = None
try:
conn = sqlite3.connect(db_file)
print(sqlite3.version)
except Error as e:
print(e)
finally:
if conn:
conn.close()
if __name__ == '__main__':
create_connection(r"sqlitedb.db")
2.6.0
En éste ejemplo vamos a importar un archivo
CSVenSQLiteutilizando la funciónto_sql()de la clasesqlalchemy. ElDataFramea usar corresponde al precio deEthereumenUSD. Vamos a importar el archivo en una tabla en nuestra base de datos y luego vamos a utilizar esta tabla para realizar un gráfico decandlesticks. Si desea ver los distinto tipos de variables numéricas y formatos de fechas enSQLitever el siguiente par de links: Formatos numéricos, Formatos fechas
import pandas as pd
df_ETH = pd.read_csv("https://raw.githubusercontent.com/lihkir/Data/main/ETH-USD.csv")
df_ETH.head()
| Date | Open | High | Low | Close | Adj Close | Volume | |
|---|---|---|---|---|---|---|---|
| 0 | 2017-11-09 | 308.644989 | 329.451996 | 307.056000 | 320.884003 | 320.884003 | 893249984 |
| 1 | 2017-11-10 | 320.670990 | 324.717987 | 294.541992 | 299.252991 | 299.252991 | 885985984 |
| 2 | 2017-11-11 | 298.585999 | 319.453003 | 298.191986 | 314.681000 | 314.681000 | 842300992 |
| 3 | 2017-11-12 | 314.690002 | 319.153015 | 298.513000 | 307.907990 | 307.907990 | 1613479936 |
| 4 | 2017-11-13 | 307.024994 | 328.415009 | 307.024994 | 316.716003 | 316.716003 | 1041889984 |
df_ETH = df_ETH.rename({'Date': 'date',
'Open': 'open',
'High': 'high',
'Low': 'low',
'Close': 'close',
'Adj Close': 'adj_close',
'Volume': 'volume'}, axis=1)
df_ETH.head()
| date | open | high | low | close | adj_close | volume | |
|---|---|---|---|---|---|---|---|
| 0 | 2017-11-09 | 308.644989 | 329.451996 | 307.056000 | 320.884003 | 320.884003 | 893249984 |
| 1 | 2017-11-10 | 320.670990 | 324.717987 | 294.541992 | 299.252991 | 299.252991 | 885985984 |
| 2 | 2017-11-11 | 298.585999 | 319.453003 | 298.191986 | 314.681000 | 314.681000 | 842300992 |
| 3 | 2017-11-12 | 314.690002 | 319.153015 | 298.513000 | 307.907990 | 307.907990 | 1613479936 |
| 4 | 2017-11-13 | 307.024994 | 328.415009 | 307.024994 | 316.716003 | 316.716003 | 1041889984 |
names_list = df_ETH.columns.tolist()
from sqlalchemy import create_engine
engine = create_engine('sqlite:///sqlitedb.db')
df_ETH.to_sql('ethereum', engine, if_exists = 'replace', index=False, method='multi')
2169
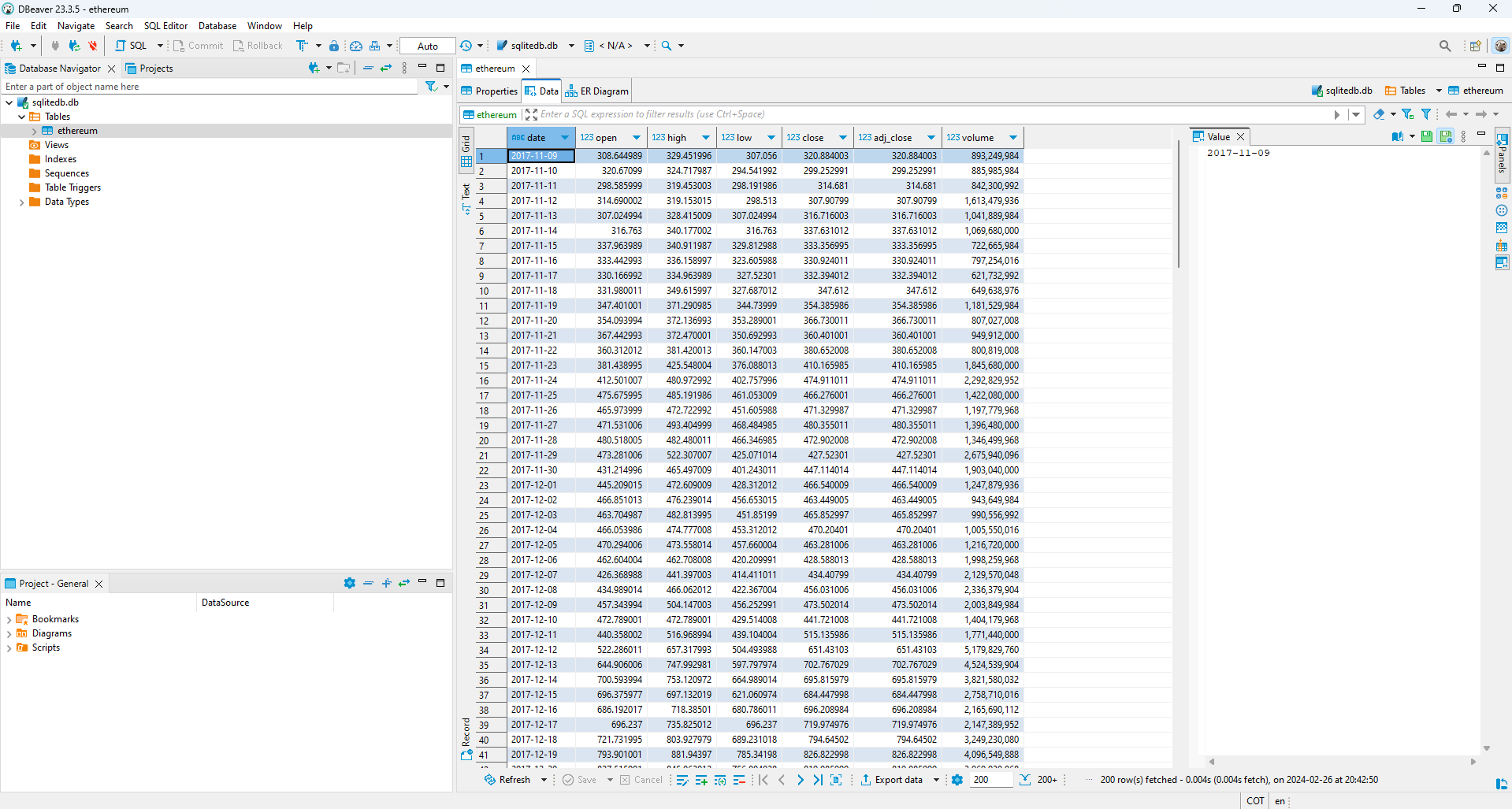
Fig. 78 Visualización de la tabla ethereum creada en SQLite, usando el gestor DBeaver.#
connection = sqlite3.connect('sqlitedb.db')
cursor = connection.cursor()
cursor.execute("SELECT * FROM ethereum;")
close = cursor.fetchall()
ETH_sql = pd.DataFrame(close)
display(ETH_sql.head())
ETH_names = []
cnames_list = cursor.execute('''SELECT * FROM ethereum''')
for column in cnames_list.description:
ETH_names.append(column[0])
display(ETH_names)
print("\nOperation done successfully")
connection.close()
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | |
|---|---|---|---|---|---|---|---|
| 0 | 2017-11-09 | 308.644989 | 329.451996 | 307.056000 | 320.884003 | 320.884003 | 893249984 |
| 1 | 2017-11-10 | 320.670990 | 324.717987 | 294.541992 | 299.252991 | 299.252991 | 885985984 |
| 2 | 2017-11-11 | 298.585999 | 319.453003 | 298.191986 | 314.681000 | 314.681000 | 842300992 |
| 3 | 2017-11-12 | 314.690002 | 319.153015 | 298.513000 | 307.907990 | 307.907990 | 1613479936 |
| 4 | 2017-11-13 | 307.024994 | 328.415009 | 307.024994 | 316.716003 | 316.716003 | 1041889984 |
['date', 'open', 'high', 'low', 'close', 'adj_close', 'volume']
Operation done successfully
ETH_sql.columns = names_list
ETH_sql = ETH_sql.sort_values(by = "date")
ETH_sql.head()
| date | open | high | low | close | adj_close | volume | |
|---|---|---|---|---|---|---|---|
| 0 | 2017-11-09 | 308.644989 | 329.451996 | 307.056000 | 320.884003 | 320.884003 | 893249984 |
| 1 | 2017-11-10 | 320.670990 | 324.717987 | 294.541992 | 299.252991 | 299.252991 | 885985984 |
| 2 | 2017-11-11 | 298.585999 | 319.453003 | 298.191986 | 314.681000 | 314.681000 | 842300992 |
| 3 | 2017-11-12 | 314.690002 | 319.153015 | 298.513000 | 307.907990 | 307.907990 | 1613479936 |
| 4 | 2017-11-13 | 307.024994 | 328.415009 | 307.024994 | 316.716003 | 316.716003 | 1041889984 |
Para realizar la siguiente figura necesitará instalar las siguientes librerías
pip install -U plotly
pip install -U kaleido
import plotly.graph_objects as go
fig = go.Figure(data=[go.Candlestick(x = ETH_sql['date'],
open = ETH_sql['open'],
high = ETH_sql['high'],
low = ETH_sql['low'],
close = ETH_sql['close'])
])
fig.update_layout(
title="Ethereum USD (ETH-USD)",
xaxis_title="Day",
yaxis_title="ETH-USD",
font=dict(
family="Courier New, monospace",
size=12,
color="RebeccaPurple"
)
)
fig.update_layout(xaxis_rangeslider_visible=False)
fig.show()
Ejercicio para entregar#
El siguiente informe debe ser presentado usando
Jupyter Book. Por lo tanto, la entrega realizada corresponde a un link de una página deGitHubsimilar a la del presente curso. Debe crear una conexión conpgAdminpara mostrar las tablas creadas,agregar imágenes.
Crear una instancia de base de datos en
Dockerla cual utilizará para la solución de los siguientes ejercicios. Luego de finalizar con cada una de las consultas requeridas, deberá exportar la imagen de la base de datos a un archivo nombrado como,primernombre_primerapellido_imagendocker.tar, ejemplo:lihki_rubio_imagendocker.tar.
La imagen
Dockery la base de datos que debe crear debe contar con la siguiente información de conexión. Nótese que debe usar la contraseñapassword.Host: localhostPort: 5342Database Name: myname_dbUser Name: myname_userPassword: password
Cada una de las siguientes consultas deben ser realizadas desde
Pythonusando laAPI psycopg2. Por lo tanto, debe crear unaconexióny uncursorpreviamente para realizar cada una de las siguientes consultas:
I) Crear la tabla nombrada: employees y explicar que tarea realiza la consulta realizada y mostrar en pantalla la tabla
CREATE TABLE employees
( employee_id INTEGER
, first_name VARCHAR(20)
, last_name VARCHAR(25)
, email VARCHAR(25)
, phone_number VARCHAR(20)
, hire_date DATE
, job_id VARCHAR(10)
, salary NUMERIC(8,2)
, commission_pct NUMERIC(2,2)
, manager_id INTEGER
, department_id INTEGER
) ;
CREATE UNIQUE INDEX emp_emp_id_pk
ON employees (employee_id) ;
ALTER TABLE employees ADD
PRIMARY KEY (employee_id);
SELECT * FROM employees LIMIT 10;
SELECT count(1) FROM employees;
II) Crear la tabla courses con las siguientes columnas:
course_id- integer y primary keycourse_name- valores alfanuméricos o de cadena de hasta 60 caracterescourse_author- nombre del autor de hasta 40 caracterescourse_status- published, draft, inactive.course_published_dt- valor de tipo fecha.
III) Insertar datos
Inserte los datos en courses utilizando los datos proporcionados. Asegúrese de que el id es generado por el sistema. No olvide refrescar la información de la base de datos.
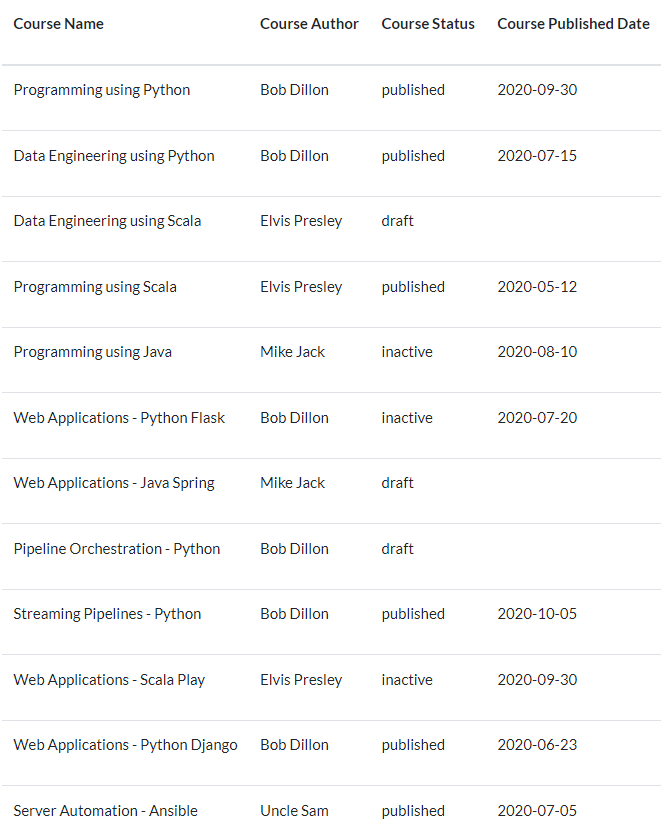
Fig. 79 Filas a insertar en la tabla courses#
IV) Borre todos los cursos que no estén en modo borrador ni publicados. Proporcione la sentencia de borrado como respuesta para este ejercicio en el Jupyter Book. Para validar, obtenga el recuento de todos los cursos publicados por autor y asegúrese de que la salida está ordenada en forma descendente por recuento.
VI) Crear la base de datos users
CREATE TABLE users(
user_id SERIAL PRIMARY KEY,
user_first_name VARCHAR(30),
user_last_name VARCHAR(30),
user_email_id VARCHAR(50),
user_gender VARCHAR(1),
user_unique_id VARCHAR(15),
user_phone_no VARCHAR(20),
user_dob DATE,
created_ts TIMESTAMP
)
Inserte los siguientes valores
insert into users (
user_first_name, user_last_name, user_email_id, user_gender,
user_unique_id, user_phone_no, user_dob, created_ts
) VALUES
('Giuseppe', 'Bode', 'gbode0@imgur.com', 'M', '88833-8759',
'+86 (764) 443-1967', '1973-05-31', '2018-04-15 12:13:38'),
('Lexy', 'Gisbey', 'lgisbey1@mail.ru', 'F', '262501-029',
'+86 (751) 160-3742', '2003-05-31', '2020-12-29 06:44:09'),
('Karel', 'Claringbold', 'kclaringbold2@yale.edu', 'F', '391-33-2823',
'+62 (445) 471-2682', '1985-11-28', '2018-11-19 00:04:08'),
('Marv', 'Tanswill', 'mtanswill3@dedecms.com', 'F', '1195413-80',
'+62 (497) 736-6802', '1998-05-24', '2018-11-19 16:29:43'),
('Gertie', 'Espinoza', 'gespinoza4@nationalgeographic.com', 'M', '471-24-6869',
'+249 (687) 506-2960', '1997-10-30', '2020-01-25 21:31:10'),
('Saleem', 'Danneil', 'sdanneil5@guardian.co.uk', 'F', '192374-933',
'+63 (810) 321-0331', '1992-03-08', '2020-11-07 19:01:14'),
('Rickert', 'O''Shiels', 'roshiels6@wikispaces.com', 'M', '749-27-47-52',
'+86 (184) 759-3933', '1972-11-01', '2018-03-20 10:53:24'),
('Cybil', 'Lissimore', 'clissimore7@pinterest.com', 'M', '461-75-4198',
'+54 (613) 939-6976', '1978-03-03', '2019-12-09 14:08:30'),
('Melita', 'Rimington', 'mrimington8@mozilla.org', 'F', '892-36-676-2',
'+48 (322) 829-8638', '1995-12-15', '2018-04-03 04:21:33'),
('Benetta', 'Nana', 'bnana9@google.com', 'M', '197-54-1646',
'+420 (934) 611-0020', '1971-12-07', '2018-10-17 21:02:51'),
('Gregorius', 'Gullane', 'ggullanea@prnewswire.com', 'F', '232-55-52-58',
'+62 (780) 859-1578', '1973-09-18', '2020-01-14 23:38:53'),
('Una', 'Glayzer', 'uglayzerb@pinterest.com', 'M', '898-84-336-6',
'+380 (840) 437-3981', '1983-05-26', '2019-09-17 03:24:21'),
('Jamie', 'Vosper', 'jvosperc@umich.edu', 'M', '247-95-68-44',
'+81 (205) 723-1942', '1972-03-18', '2020-07-23 16:39:33'),
('Calley', 'Tilson', 'ctilsond@issuu.com', 'F', '415-48-894-3',
'+229 (698) 777-4904', '1987-06-12', '2020-06-05 12:10:50'),
('Peadar', 'Gregorowicz', 'pgregorowicze@omniture.com', 'M', '403-39-5-869',
'+7 (267) 853-3262', '1996-09-21', '2018-05-29 23:51:31'),
('Jeanie', 'Webling', 'jweblingf@booking.com', 'F', '399-83-05-03',
'+351 (684) 413-0550', '1994-12-27', '2018-02-09 01:31:11'),
('Yankee', 'Jelf', 'yjelfg@wufoo.com', 'F', '607-99-0411',
'+1 (864) 112-7432', '1988-11-13', '2019-09-16 16:09:12'),
('Blair', 'Aumerle', 'baumerleh@toplist.cz', 'F', '430-01-578-5',
'+7 (393) 232-1860', '1979-11-09', '2018-10-28 19:25:35'),
('Pavlov', 'Steljes', 'psteljesi@macromedia.com', 'F', '571-09-6181',
'+598 (877) 881-3236', '1991-06-24', '2020-09-18 05:34:31'),
('Darn', 'Hadeke', 'dhadekej@last.fm', 'M', '478-32-02-87',
'+370 (347) 110-4270', '1984-09-04', '2018-02-10 12:56:00'),
('Wendell', 'Spanton', 'wspantonk@de.vu', 'F', null,
'+84 (301) 762-1316', '1973-07-24', '2018-01-30 01:20:11'),
('Carlo', 'Yearby', 'cyearbyl@comcast.net', 'F', null,
'+55 (288) 623-4067', '1974-11-11', '2018-06-24 03:18:40'),
('Sheila', 'Evitts', 'sevittsm@webmd.com', null, '830-40-5287',
null, '1977-03-01', '2020-07-20 09:59:41'),
('Sianna', 'Lowdham', 'slowdhamn@stanford.edu', null, '778-0845',
null, '1985-12-23', '2018-06-29 02:42:49'),
('Phylys', 'Aslie', 'paslieo@qq.com', 'M', '368-44-4478',
'+86 (765) 152-8654', '1984-03-22', '2019-10-01 01:34:28')
VII) Obtenga el número de usuarios creados por año. Utilice la tabla de usuarios para este ejercicio.
La salida debe contener el año de 4 dígitos y el recuento.
Use funciones específicas de fecha para obtener el año usando
created_ts.Asegúrese de definir
aliasa las columnas comocreated_yearyuser_countrespectivamente.Los datos deben ordenarse de forma ascendente por
created_year.Cuando ejecutes la consulta usando el entorno
Jupyter, puede que tenga decimales para los enteros. Por lo tanto, puede mostrar los resultados incluso con decimales.
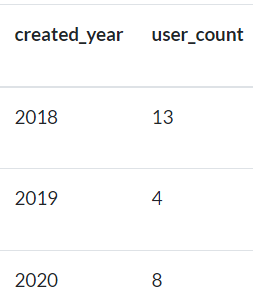
Fig. 80 Ejemplo de salida que debe obtener a partir de este ejercicio.#
VIII) Obtenga los días de nacimiento de todos los usuarios nacidos en el mes May.
Utilice la tabla
userspara este ejercicio.La salida debe contener
user_id, user_dob, user_email_idyuser_day_of_birth.Utilice funciones específicas de fecha para obtener el mes utilizando
user_dob.user_day_of_birthdebe ser un día completo con el primer carácter en mayúsculas, por ejemploTuesday.Los datos deben ordenarse por día dentro del mes
May.
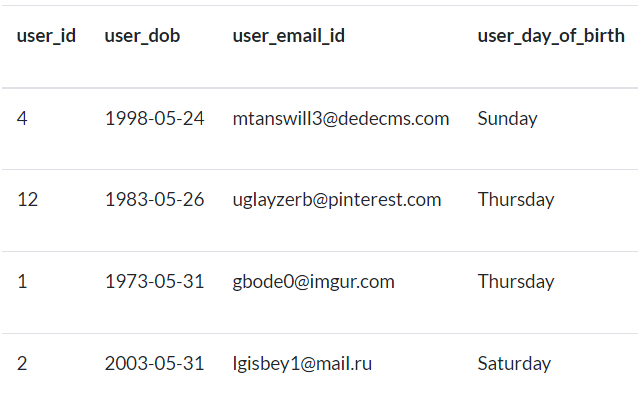
Fig. 81 Ejemplo de salida para nacimientos en el mes de mayo.#
IX) Obtenga los nombres e ids de correo electrónico de los usuarios añadidos en el año 2019.
Utilice la tabla
userspara este ejercicio.La salida debe contener
user_id, user_name, user_email_id, created_ts, created_year.Utilice funciones específicas de fecha para obtener el año utilizando
created_ts.user_namees una columna derivada de concatenaruser_first_nameyuser_last_namecon un espacio en medio.user_namedebe tener valores en mayúsculas.Los datos deben ordenarse en forma ascendente por
user_name
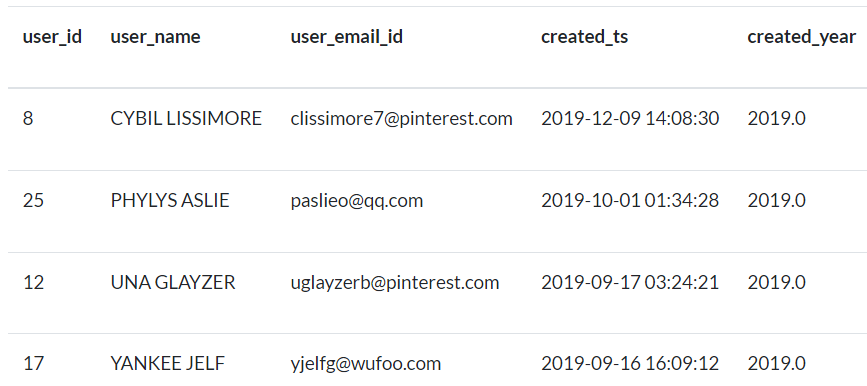
Fig. 82 Ejemplo de salida para nombres, ids, correo electrónico y fechas.#
X) Obtenga el número de usuarios por género. Utilice la tabla de users para este ejercicio.
La salida debe contener el
genderyuser_count.Para los hombres la salida debe mostrar
Maley para las mujeres la salida debe mostrarFemale.Si no se especifica el sexo, se mostrará
Not SpecifiedLos datos deben ordenarse en forma descendente por
user_count.
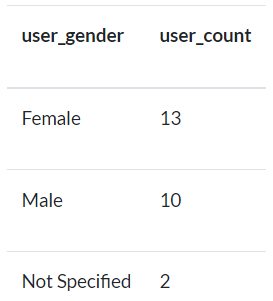
Fig. 83 Ejemplo de salida para el ejercicio X.#
XII) Obtenga los 4 últimos dígitos de los ids únicos.
Utilice la tabla
userspara este ejercicio.El resultado debe contener
user_id, user_unique_idyuser_unique_id_last4.Los identificadores únicos son
nullonot null.Los identificadores únicos contienen números y guiones y son de diferente longitud.
Necesitamos obtener los últimos 4 dígitos descartando los guiones sólo cuando el número de dígitos es al menos 9.
Si el identificador único es nulo, debe mostrarse
Not Specified.Después de descartar los guiones, si el identificador único tiene menos de 9 dígitos, debe mostrar
Invalid Unique Id.Los datos deben ordenarse por
user_id. Es posible que aparezcaNoneonullpara aquellos identificadores de usuario en los que no haya un identificador único parauser_unique_id.
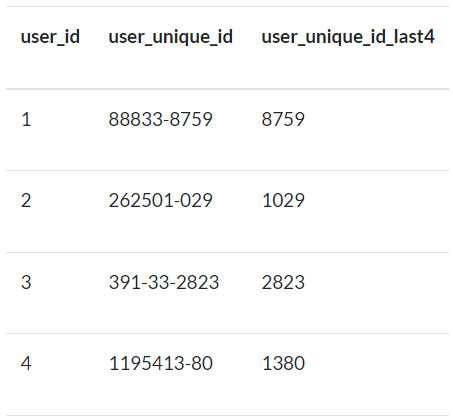
Fig. 84 Ejemplo de output para Ejercicio XII.#
XIII) Obtenga el recuento de usuarios en función del código de país.
Utilice la tabla
userspara este ejercicio.La salida debe contener el código de país y el recuento.
No debe haber ningún
+en el código de país. Sólo debe contener dígitos.Los datos deben ordenarse como números por código de país.
Debemos descartar
user_phone_nocon valoresnull.
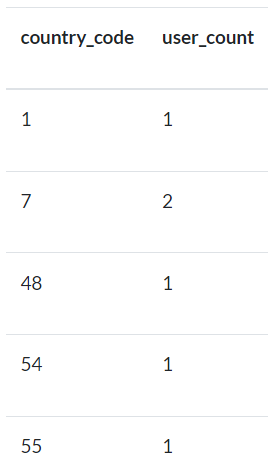
Fig. 85 Ejemplo de output para ejercicio de recuento de usuarios en función del código de país.#
Importe los datos del precio de
Cardano USD (ADA-USD)en su instancia de base de datosDocker, teniendo en cuenta lo explicado durante esta sección. Luego dibuje ungráfico de candlestickpara la criptomoneda. En el siguiente link encontrará elCSVdeCardano: Cardano USD (ADA-USD). Describa lo que puede observar en la serie de tiempo. Realice un análisis exploratorio de datos(EDA)para la serie de tiempo.