
De la visualización estática a la interactiva: Bokeh#
Objetivos
Explicar las diferencias entre las visualizaciones estáticas e interactivas
Explicar la aplicación de las visualizaciones interactivas en diversos sectores
Crear gráficos interactivos con funcionalidades de
zoom, hoveryslideUtilizar las librerías
BokehyPlotly(Express) dePythonpara crear visualizaciones de datos interactivas
En este capítulo, pasaremos de las visualizaciones estáticas a las interactivas y estudiaremos las aplicaciones de las visualizaciones interactivas para diferentes escenarios.
Introducción#
En la sección anterior hablamos de las visualizaciones de datos estáticas, es decir, gráficos y diagramas que están inmóviles y no pueden ser modificados o interactuados en tiempo real por el público.
Las visualizaciones de datos interactivas están un paso por delante de las estáticas. La definición de interactivo es algo que implica la comunicación entre dos o más cosas o personas que trabajan juntas. Por lo tanto, las visualizaciones interactivas son representaciones gráficas de datos analizados (estáticos o dinámicos) que pueden reaccionar y responder a las acciones del usuario en el momento.

Visualización estática versus interactiva#
Aunque las visualizaciones estáticas de datos son un gran avance hacia el objetivo de extraer y explicar el valor y la información que contienen los conjuntos de datos, la adición de interactividad hace que estas visualizaciones vayan un paso más allá.
Las visualizaciones de datos interactivas tienen las siguientes cualidades:
Son más fáciles de explorar ya que permiten interactuar con los datos cambiando colores, parámetros y gráficos.
Se pueden manipular fácilmente y al instante. Ya que se puede interactuar con ellas, los gráficos se pueden cambiar delante del usuario. Por ejemplo, usando un deslizador interactivo. Cuando la posición de este deslizador cambia el gráfico también lo hace, además se úeden crear casillas de verificación que le permitan seleccionar los parámetros que desea ver.
Permiten acceder a los datos en tiempo real y a la información que proporcionan. Esto permite el análisis eficaz y rápido de las tendencias.
Son más fáciles de comprender, lo que permite a las organizaciones tomar mejores decisiones basadas en datos.
Eliminan la necesidad de tener varios gráficos para la misma información. Un solo gráfico interactivo es capaz de transmitir la misma información. Permiten observar relaciones (por ejemplo, causa y efecto).
Ejemplo#
Empecemos con un ejemplo para entender lo que podemos conseguir mediante la visualización interactiva. Consideremos un dataset de socios inscritos en un gimnasio:
La siguiente es una visualización de datos estática en forma de gráfico de caja que describe el peso de las personas clasificadas por su sexo (0 es hombre, 1 es mujer y 2 es otro):
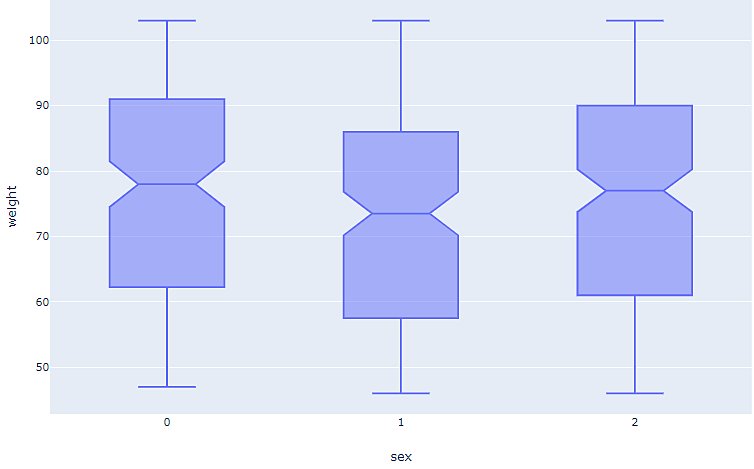
El único dato que podemos obtener de este gráfico es la relación entre el peso y el sexo. Sin embargo, hay una tercera característica presente en el conjunto de datos que se utiliza para generar este gráfico de caja: la edad. La adición de esta característica al gráfico estático anterior puede llevar a la confusión en cuanto a la comprensión de los datos.
Por lo tanto, estamos un poco atascados con respecto a mostrar la relación entre las tres características utilizando una visualización estática. Este problema de problema puede resolverse fácilmente creando una visualización interactiva, como se muestra aquí:
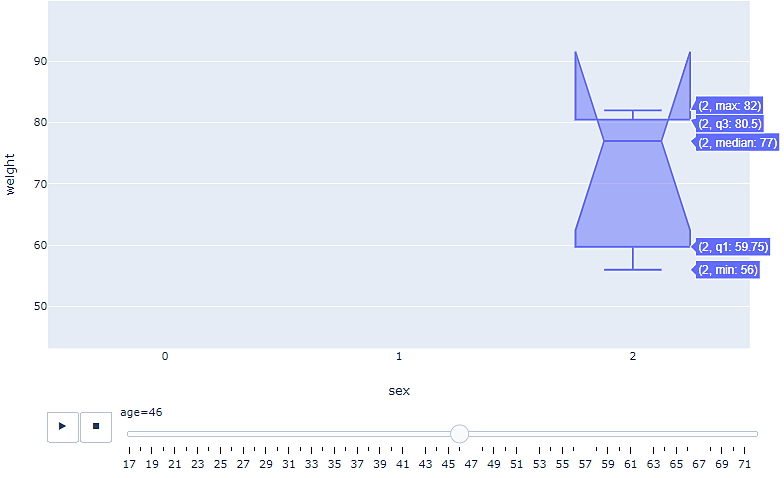
En el gráfico de caja anterior, se ha introducido un control deslizante para la característica de la edad. El usuario puede deslizar manualmente la posición del deslizador para observar la relación entre peso, el sexo y la edad en diferentes valores de edad. Además, hay una herramienta de desplazamiento que permite al usuario obtener más información sobre los datos.
El gráfico de caja anterior describe que, en este gimnasio, los únicos clientes de 46 años son los que se identifican como otros, y el más pesado de 46 años pesa 82 kilogramos, mientras que el más ligero pesa 56 kilogramos. El usuario puede deslizarse a otra posición para observar la relación entre peso y sexo a una edad diferente, como se muestra en el siguiente gráfico:
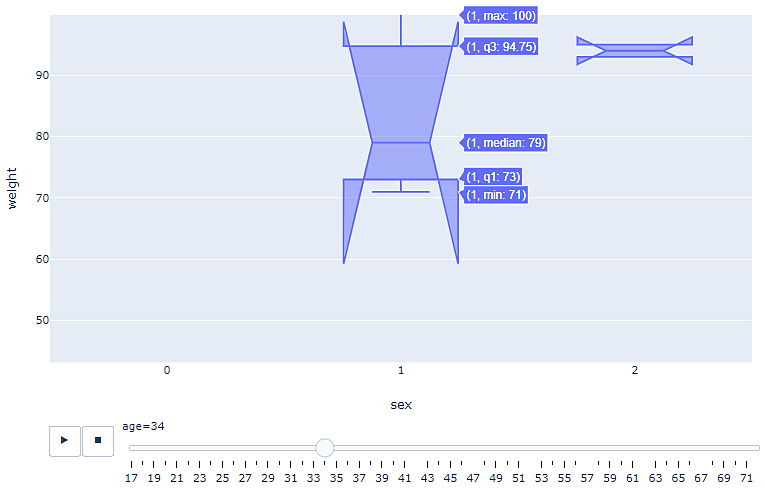
El gráfico anterior describe los datos a la edad de 34 años: no hay clientes masculinos del gimnasio; Sin embargo, la clienta más pesada de 34 años pesa 100 kilogramos, mientras que la más ligera pesa 71 kilogramos. más ligera pesa 71 kilogramos.
Pero aún hay más aspectos a tener en cuenta a la hora de diferenciar entre visualizaciones estáticas e interactivas. Veamos la siguiente tabla:
Visualización Estática |
Visualización Interactiva |
|
|---|---|---|
Medios/campos objetivo |
Medios impresos y presentaciones |
Aplicaciones web, social media, BI |
Coste de creación |
Bajo |
Alto |
Conexión a fuente de datos |
No requerida |
Requerida en caso dinamico |
Visualización |
Renderización facil |
Requiere diseño de UI |
Librerias de Python |
Matplotlib, Seaborn |
Bokeh, Plotly |
En última instancia, las visualizaciones de datos interactivas transforman el debate sobre los datos en el arte de contar historias, simplificando así el proceso de comprensión de lo que los datos intentan decirnos. Estos aspectos son los que separan las visualizaciones interactivas de las estáticas. Veamos algunas aplicaciones de las visualizaciones de datos interactivas.
Aplicaciones de las visualizaciones interactivas de datos#
El aspecto clave de las visualizaciones de datos interactivas es su capacidad de responder y reaccionar a las entradas humanas en el momento o en un lapso de tiempo muy corto. En esta sección, veremos algunas entradas humanas, cómo pueden introducirse en las visualizaciones de datos, y el impacto que tienen en la comprensión de los datos
Slider: Un deslizador permite al usuario ver los datos correspondientes a un rango de algo. A medida que el usuario cambia la posición del deslizador, el gráfico cambia en tiempo real. Este permite al usuario ver varios gráficos en tiempo real:

Hover: Al pasar (hovering) el cursor por encima de un elemento de un gráfico, el usuario puede recibir más información sobre el punto de datos que la que se puede ver simplemente observando el gráfico. Esto es útil cuando la información que se desea transmitir no cabe en el propio gráfico (como valores precisos o descripciones breves). Veamos una herramienta de hover:
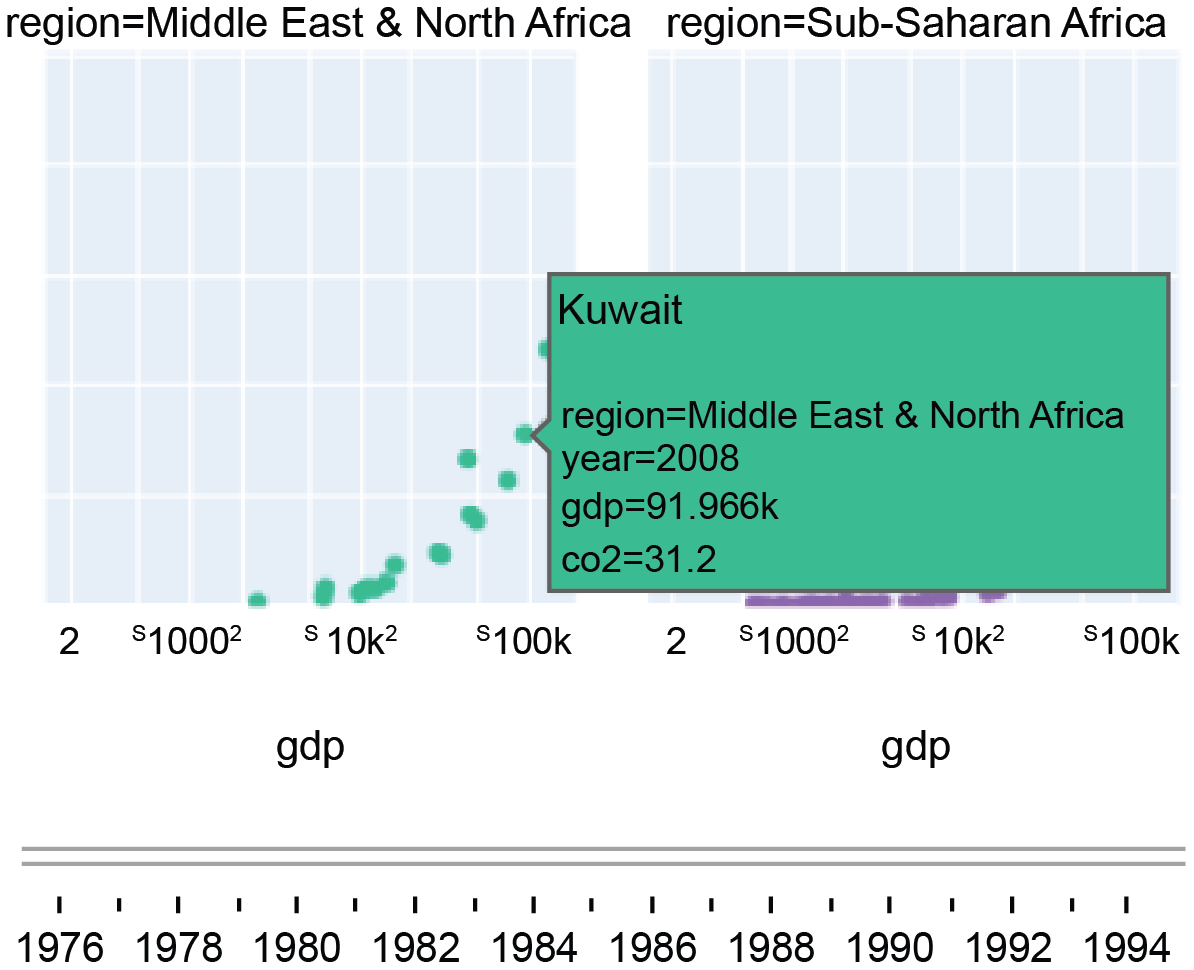
Zoom: Acercarse y alejarse de un gráfico es una característica que bastantes bibliotecas de visualización de datos interactivos crean por sí mismas. Le permiten centrarse en puntos de un gráfico y verlos más de cerca.
Clickable parameters: Hay varios tipos de parámetros clicables, como casillas de verificación y menús desplegables, que permiten al usuario elegir qué aspectos de los datos desea analizar y ver.

Hay bibliotecas de Python que se utilizan para crear estas funciones interactivas, que permiten que las visualizaciones tomen la entrada humana. En los capítulos anteriores, vimos dos bibliotecas de Python incorporadas:
matplotlibseaborn
Ambos son populares en la comunidad de visualización de datos. Con estas, podemos construir una visualización estática (un gráfico de dispersión estático que muestra la relación entre dos variables) como ésta:
Mientras que tanto matplotlib como seaborn son excelentes para las visualizaciones de datos estáticos, hay otras bibliotecas disponibles que hacen un buen trabajo de diseño de características interactivas. Dos de las bibliotecas Python de visualización de datos interactivos más populares son
bokehplotly
Esto nos ayuda a crear visualizaciones como las siguientes. Utilizaremos tanto
bokehcomoplotlyen los ejercicios de este capítulo para crear visualizaciones de datos interactivas.
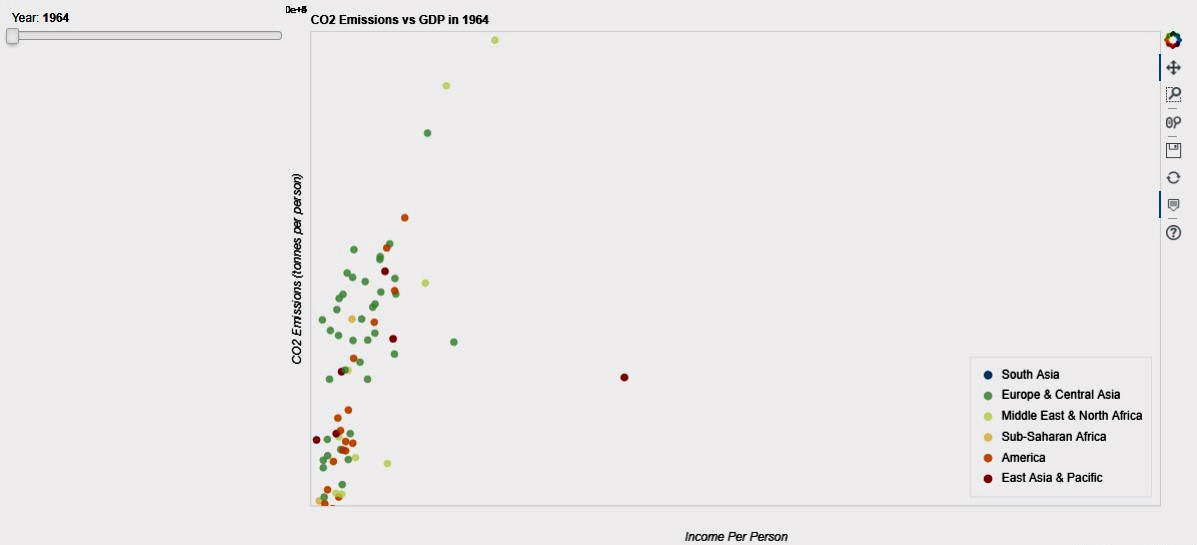
Visualización interactiva de datos con Bokeh#
bokehes una biblioteca dePythonpara la visualización interactiva de datos. Los gráficos deBokehse se crean apilando capas una encima de otra. El primer paso escrear una figura vacía figura, a la que se añaden elementos en capas. Estos elementos se conocen comoglifos, que pueden ser cualquier cosa, desde líneas hasta barras o círculos. A cadaglifose le adjuntan propiedades como el color, el tamaño y las coordenadas.
bokehes muy popular porque las visualizaciones se renderizan utilizandoHTMLyJavaScript, por lo que se suele elegir cuando se diseñan visualizaciones interactivas basadas en la web. Además, el módulobokeh.iocrea un archivo.htmlque contiene estático básico, junto con las características interactivas, y no requiere necesariamente un servidor para ejecutarse, lo que hace que la visualización sea muy fácil de desplegar.
En este capítulo, los siguientes ejercicios tienen como objetivo crear una visualización de datos interactiva para representar la
relación entre las emisiones de dióxido de carbono y el PIBde un país utilizando la bibliotecabokehdePython.
Preparación de nuestro conjunto de datos#
En este ejercicio, descargaremos y prepararemos nuestro conjunto de datos utilizando las bibliotecas incorporadas
pandasynumpy. Al final de este ejercicio, tendremos unDataFramesobre el que construiremos nuestras visualizaciones interactivas de datos. Utilizaremos los archivosco2.csvygapminder.csv. El primero consiste en las emisiones de dióxido de carbono por persona por año y por país, mientras que el segundo consiste en el PIB por año y por país.
Los siguientes pasos le ayudarán a preparar los datos:
Importar las bibliotecas
pandasynumpy:
import pandas as pd
import numpy as np
Guarde el archivo co2.csv en un DataFrame llamado co2, y el archivo gapminder.csv en un DataFrame llamado gm:
url_co2 = 'https://raw.githubusercontent.com/lihkir/Uninorte/main/AppliedStatisticMS/DataVisualizationRPython/Lectures/Python/PythonDataSets/co2.csv'
co2 = pd.read_csv(url_co2)
co2.head()
| country | 1800 | 1801 | 1802 | 1803 | 1804 | 1805 | 1806 | 1807 | 1808 | ... | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Afghanistan | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | 0.0529 | 0.0637 | 0.0854 | 0.154 | 0.242 | 0.294 | 0.412 | 0.35 | 0.316 | 0.299 |
| 1 | Albania | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | 1.3800 | 1.2800 | 1.3000 | 1.460 | 1.480 | 1.560 | 1.790 | 1.68 | 1.730 | 1.960 |
| 2 | Algeria | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | 3.2200 | 2.9900 | 3.1900 | 3.160 | 3.420 | 3.300 | 3.290 | 3.46 | 3.510 | 3.720 |
| 3 | Andorra | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | 7.3000 | 6.7500 | 6.5200 | 6.430 | 6.120 | 6.120 | 5.870 | 5.92 | 5.900 | 5.830 |
| 4 | Angola | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | 0.9800 | 1.1000 | 1.2000 | 1.180 | 1.230 | 1.240 | 1.250 | 1.33 | 1.250 | 1.290 |
5 rows × 216 columns
url_gm = 'https://raw.githubusercontent.com/lihkir/Uninorte/main/AppliedStatisticMS/DataVisualizationRPython/Lectures/Python/PythonDataSets/gapminder.csv'
gm = pd.read_csv(url_gm)
gm.head()
| Country | Year | fertility | life | population | child_mortality | gdp | region | |
|---|---|---|---|---|---|---|---|---|
| 0 | Afghanistan | 1964 | 7.671 | 33.639 | 10474903.0 | 339.7 | 1182.0 | South Asia |
| 1 | Afghanistan | 1965 | 7.671 | 34.152 | 10697983.0 | 334.1 | 1182.0 | South Asia |
| 2 | Afghanistan | 1966 | 7.671 | 34.662 | 10927724.0 | 328.7 | 1168.0 | South Asia |
| 3 | Afghanistan | 1967 | 7.671 | 35.170 | 11163656.0 | 323.3 | 1173.0 | South Asia |
| 4 | Afghanistan | 1968 | 7.671 | 35.674 | 11411022.0 | 318.1 | 1187.0 | South Asia |
Actualmente tenemos dos DataFrames separados, cada uno de ellos compuesto por datos que necesitamos para crear nuestra visualización de datos interactiva. Para crear la visualización, necesitamos combinar estos dos DataFrames y eliminar las columnas no deseadas.
Utilice
.drop_duplicates()para eliminar las instancias duplicadas del gm y guárdelo en un nuevo DataFrame llamado df_gm:
df_gm = gm[['Country', 'region']].drop_duplicates()
df_gm.head()
| Country | region | |
|---|---|---|
| 0 | Afghanistan | South Asia |
| 50 | Albania | Europe & Central Asia |
| 100 | Algeria | Middle East & North Africa |
| 150 | Angola | Sub-Saharan Africa |
| 200 | Antigua and Barbuda | America |
Utilice
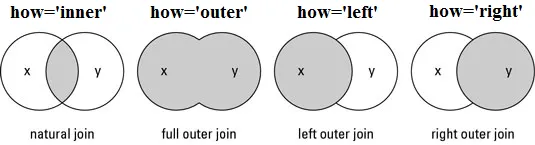
.merge()para combinar el DataFrame co2 con el DataFrame df_gm. Esta función funciónmergebásicamente realiza una unión interna en los dos DataFrames (lo mismo como el inner join cuando se utiliza en bases de datos). Esta fusión es necesaria para garantizar que tanto el DataFrame co2 como el DataFrame gm estén formados por los mismos países, garantizando así que los valores de las emisiones de CO2 correspondan a sus respectivos países. La opciónhow ='inner'devuelve un marco de datos con sólo las filas que tienen características comunes. Una unión interna requiere quecada fila de los dos dataframes unidos tenga valores de columna que coincidan. Esto es similar a la intersección de dos conjuntos (ver Different Types of Joins in Pandas).
Outer Join or Full outer join: Mantiene todas las filas de ambos marcos de datos, especifique:how='outer'Left Join or Left outer join: Para incluir todas las filas de su marco de datos \(X\) y sólo las de \(Y\) que coincidan, especifique:how='left'.Right Join or Right outer join: Para incluir todas las filas de su marco de datos \(Y\) y sólo las de \(X\) que coincidan, especifique:how='right'.
df_w_regions = pd.merge(co2, df_gm, left_on ='country', right_on ='Country', how ='inner')
df_w_regions.head()
| country | 1800 | 1801 | 1802 | 1803 | 1804 | 1805 | 1806 | 1807 | 1808 | ... | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | Country | region | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Afghanistan | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | 0.0854 | 0.154 | 0.242 | 0.294 | 0.412 | 0.35 | 0.316 | 0.299 | Afghanistan | South Asia |
| 1 | Albania | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | 1.3000 | 1.460 | 1.480 | 1.560 | 1.790 | 1.68 | 1.730 | 1.960 | Albania | Europe & Central Asia |
| 2 | Algeria | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | 3.1900 | 3.160 | 3.420 | 3.300 | 3.290 | 3.46 | 3.510 | 3.720 | Algeria | Middle East & North Africa |
| 3 | Angola | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | 1.2000 | 1.180 | 1.230 | 1.240 | 1.250 | 1.33 | 1.250 | 1.290 | Angola | Sub-Saharan Africa |
| 4 | Antigua and Barbuda | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | 5.1400 | 5.190 | 5.450 | 5.540 | 5.360 | 5.42 | 5.360 | 5.380 | Antigua and Barbuda | America |
5 rows × 218 columns
Se procede a eliminar una de las columnas de (
'Country' o 'country') ya que hay dos:
df_w_regions = df_w_regions.drop('Country', axis='columns')
df_w_regions.head()
| country | 1800 | 1801 | 1802 | 1803 | 1804 | 1805 | 1806 | 1807 | 1808 | ... | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 | 2012 | 2013 | 2014 | region | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Afghanistan | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | 0.0637 | 0.0854 | 0.154 | 0.242 | 0.294 | 0.412 | 0.35 | 0.316 | 0.299 | South Asia |
| 1 | Albania | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | 1.2800 | 1.3000 | 1.460 | 1.480 | 1.560 | 1.790 | 1.68 | 1.730 | 1.960 | Europe & Central Asia |
| 2 | Algeria | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | 2.9900 | 3.1900 | 3.160 | 3.420 | 3.300 | 3.290 | 3.46 | 3.510 | 3.720 | Middle East & North Africa |
| 3 | Angola | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | 1.1000 | 1.2000 | 1.180 | 1.230 | 1.240 | 1.250 | 1.33 | 1.250 | 1.290 | Sub-Saharan Africa |
| 4 | Antigua and Barbuda | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | ... | 4.9100 | 5.1400 | 5.190 | 5.450 | 5.540 | 5.360 | 5.42 | 5.360 | 5.380 | America |
5 rows × 217 columns
A continuación, vamos a aplicar la función
.melt()a este DataFrame y a almacenarlo en un nuevo DataFrame llamado new_co2. Esta función cambia el formato de un DataFrame en uno que tenga variables identificadoras de nuestra elección. En nuestro caso queremos que lasvariables identificadoras sean país y región. También vamos a cambiar las columnas que son valores de años, a elementos de la columnayearpor ejemplo. Este es el mismo procedimiento realizado enRpara normalizar una base de datos.
new_co2 = pd.melt(df_w_regions, id_vars=['country', 'region'])
new_co2.tail(10)
| country | region | variable | value | |
|---|---|---|---|---|
| 37185 | United Arab Emirates | Middle East & North Africa | 2014 | 23.300 |
| 37186 | United Kingdom | Europe & Central Asia | 2014 | 6.460 |
| 37187 | United States | America | 2014 | 16.500 |
| 37188 | Uruguay | America | 2014 | 1.970 |
| 37189 | Uzbekistan | Europe & Central Asia | 2014 | 3.450 |
| 37190 | Vanuatu | East Asia & Pacific | 2014 | 0.595 |
| 37191 | Venezuela | America | 2014 | 6.030 |
| 37192 | Vietnam | East Asia & Pacific | 2014 | 1.800 |
| 37193 | Zambia | Sub-Saharan Africa | 2014 | 0.288 |
| 37194 | Zimbabwe | Sub-Saharan Africa | 2014 | 0.780 |
columns = ['country', 'region', 'year', 'co2']
new_co2.columns = columns
new_co2.tail(10)
| country | region | year | co2 | |
|---|---|---|---|---|
| 37185 | United Arab Emirates | Middle East & North Africa | 2014 | 23.300 |
| 37186 | United Kingdom | Europe & Central Asia | 2014 | 6.460 |
| 37187 | United States | America | 2014 | 16.500 |
| 37188 | Uruguay | America | 2014 | 1.970 |
| 37189 | Uzbekistan | Europe & Central Asia | 2014 | 3.450 |
| 37190 | Vanuatu | East Asia & Pacific | 2014 | 0.595 |
| 37191 | Venezuela | America | 2014 | 6.030 |
| 37192 | Vietnam | East Asia & Pacific | 2014 | 1.800 |
| 37193 | Zambia | Sub-Saharan Africa | 2014 | 0.288 |
| 37194 | Zimbabwe | Sub-Saharan Africa | 2014 | 0.780 |
Establezca el
límite inferior de la columna del año como 1964para que la columna conste de valoresint64usamos la función.astype('int64'). Haga esto dentro del DataFramenew_co2que creamos en el paso anterior, y almacénelo en un nuevo DataFrame llamadodf_co2. Ordene los valores del DataFramedf_co2por las columnas['country', 'year']utilizando.sort_values().
df_co2 = new_co2[new_co2['year'].astype('int64') > 1963]
df_co2 = df_co2.sort_values(by=['country', 'year'])
df_co2['year'] = df_co2['year'].astype('int64')
df_co2.head()
| country | region | year | co2 | |
|---|---|---|---|---|
| 28372 | Afghanistan | South Asia | 1964 | 0.0863 |
| 28545 | Afghanistan | South Asia | 1965 | 0.1010 |
| 28718 | Afghanistan | South Asia | 1966 | 0.1080 |
| 28891 | Afghanistan | South Asia | 1967 | 0.1240 |
| 29064 | Afghanistan | South Asia | 1968 | 0.1160 |
Ahora tenemos un DataFrame que consiste en las emisiones de dióxido de carbono por año y por país. Los números de serie para
gdpno están en orden ascendente porque hemos ordenado los datos por la columna del país y luego por la del año. A continuación, vamos a crear una tabla similar para el PIB por año y por país.
Cree un nuevo DataFrame llamado
df_gdpque conste de las columnascountry, yearygdpdel DataFramegm
df_gdp = gm[['Country', 'Year', 'gdp']]
df_gdp.columns = ['country', 'year', 'gdp']
df_gdp.head()
| country | year | gdp | |
|---|---|---|---|
| 0 | Afghanistan | 1964 | 1182.0 |
| 1 | Afghanistan | 1965 | 1182.0 |
| 2 | Afghanistan | 1966 | 1168.0 |
| 3 | Afghanistan | 1967 | 1173.0 |
| 4 | Afghanistan | 1968 | 1187.0 |
Verifiquemos la cantidad de datos faltantes por columnas. En secciones posteriores, estudiaremos técnicas para imputación de datos. Por ahora optaremos por remover valores
NaN
df_co2.isna().sum()
country 0
region 0
year 0
co2 448
dtype: int64
df_gdp.isna().sum()
country 0
year 0
gdp 1111
dtype: int64
Finalmente tenemos dos DataFrames que consisten en lo siguiente: Las emisiones de dióxido de carbono y el PIB. Combine los dos
DataFramesutilizando la función.merge()en las columnascountryyyear. Guarde esto en un nuevo DataFrame llamadodata. En este caso usamoshow='left'porquedf_co2contiene menos datos faltantes en una de las columnas de interés, en este casoco2. Utilice la funcióndropna()para eliminar los valoresNaN.
data = pd.merge(df_co2, df_gdp, on=['country', 'year'], how='left')
data = data.dropna()
data.head()
| country | region | year | co2 | gdp | |
|---|---|---|---|---|---|
| 0 | Afghanistan | South Asia | 1964 | 0.0863 | 1182.0 |
| 1 | Afghanistan | South Asia | 1965 | 0.1010 | 1182.0 |
| 2 | Afghanistan | South Asia | 1966 | 0.1080 | 1168.0 |
| 3 | Afghanistan | South Asia | 1967 | 0.1240 | 1173.0 |
| 4 | Afghanistan | South Asia | 1968 | 0.1160 | 1187.0 |
Por último, comprobemos la
correlación entre las emisiones de dióxido de carbono y el PIBpara asegurarnos de que estamos analizando datos que merecen ser visualizados. Crea un arraynumpycon las columnas co2 y gdp:
np_co2 = np.array(data['co2'])
np_gdp = np.array(data['gdp'])
Utilice la función
.corrcoef()para imprimir la correlación entre las emisiones deco2y elPIB:
np.corrcoef(np_co2, np_gdp)
array([[1. , 0.78219731],
[0.78219731, 1. ]])
Como se puede ver en el resultado anterior, hay una alta correlación entre las emisiones de dióxido de carbono y el PIB.
Creación del gráfico estático base para una visualización de datos interactiva#
En este ejercicio, vamos a crear un gráfico estático para nuestro conjunto de datos y a añadirle glifos circulares circulares. Los siguientes pasos te ayudarán con la solución:
Import the following:
curdocdebokeh.io: Esto devuelve el estado actual por defecto del documento/ gráfico.La figura de
bokeh.plotting: Esto crea la figura para el trazado.HoverTool, ColumnDataSource, CategoricalColorMapper y Slider de
bokeh.models: Son herramientas y métodos interactivos para mapear datos de pandas DataFrames a una fuente de datos para su trazado.Spectral6 de
bokeh.palettes: Una paleta de colores para la gráfica.widgetboxyrowdebokeh.layouts:widgetboxcrea una columna de herramientas predefinidas (incluyendo el zoom), mientras querowcrea una fila de objetos de diseñobokeh, lo que les obliga a tener el mismo sizing_mode:
from bokeh.io import curdoc, output_notebook
from bokeh.models import HoverTool, ColumnDataSource, CategoricalColorMapper, Slider, CustomJS
from bokeh.palettes import Spectral6
from bokeh.layouts import widgetbox, row
from ipywidgets import interact
from bokeh.io import push_notebook, show, output_notebook
from bokeh.layouts import column
from bokeh.plotting import Figure, output_file, show
Ejecute la función output_notebook() para cargar BokehJS. Esto es lo que permite que el que se muestre en el notebook:
Vamos a codificar por colores nuestros puntos de datos (que serán los países individuales) en función de la región a la que pertenecen. Para ello, cree una lista de regiones aplicando la función .unique() a la columna región del DataFrame. Haga que una lista utilizando el método .tolist():
regions_list = data.region.unique().tolist()
Utilice CategoricalColorMapper para asignar un color del paquete Spectral6 a las diferentes regiones presentes en la lista regions_list:
color_mapper = CategoricalColorMapper(factors=regions_list, palette=Spectral6)
Utilizando la función
ColumnDataSourceconstruimos un diccionaro con las variables utlizadas en la grafica el cual llamaremos source_init. También crearemos otro que utlizaremos para actualizar la figura no estática por año la cual llamamos source_last
source_init = ColumnDataSource(data={'x': data.gdp[data.year == min(data.year)],
'y': data.co2[data.year == min(data.year)],
'country': data.country[data.year == min(data.year)],
'region': data.region[data.year == min(data.year)],
'year': data.year[data.year == min(data.year)]})
source_last = ColumnDataSource(data={'x': data.gdp, 'y': data.co2, 'year': data.year})
Creamos la figura vacía:
Establece el título como
Emisiones de CO2 versus PIB en 1964Establece el rango del eje
xdexminaxmaxEstablece el rango del eje
ydesdeyminhastaymaxEstablezca el tipo de eje
ycomo logarítmico
plot = Figure(title='CO2 Emissions vs GDP in 1964', y_axis_type='log')
Añadimos glifos circulares a la gráfica:
plot.circle(x='x', y='y',
fill_alpha=0.8,
source=source_init,
legend_label='region',
color=dict(field='region', transform=color_mapper),
size=7)
Establezca la ubicación de la leyenda en la esquina inferior derecha del gráfico, y agregue títulos a los ejes
plot.legend.location = 'bottom_right'
plot.xaxis.axis_label = 'Income Per Person'
plot.yaxis.axis_label = 'CO2 Emissions (tons per person)'
show(plot)
Añadir una herramienta Hover#
En este ejercicio, vamos a permitir que el usuario pase por encima de un punto de datos en nuestro gráfico para ver el nombre del país, las emisiones de dióxido de carbono y el PIB. Los siguientes pasos te ayudarán con la solución:
Crear una herramienta de rastreo llamada hover. Añade la herramienta hover a la gráfica
hover = HoverTool(tooltips=[('Country', '@country'), ('GDP', '@x'), ('CO2 Emission', '@y')])
plot.add_tools(hover)
show(plot)
ipywidgets JBook#
Importante
Tenga en cuenta que
ipywidgetstiende a comportarse de manera diferente a otras bibliotecas de visualización interactiva. Interactúan tanto conJavascriptcomo conPython. Algunas funcionalidades deipywidgetspueden no funcionar en las páginas por defecto de Jupyter Book (porque no se está ejecutando ningún kernelPython) ver ipywidgets JBook.
Cuando trabaje con figuras de
Plotly, es preferible usar el editorJupyter Lab. Además, debe instalar el respectivo soporte dePlotlyparaJupyter Lab(ver JupyterLab Support) mediante la instalación de las siguientes librerías. Esto le permitirá mostrar sus gráficos dePlotlyenJupyter Laben caso de que no los pueda visualizar
pip install "jupyterlab>=3" "ipywidgets>=7.6"
pip install jupyter-dash
Para que su
JBookse actualice con la figura dinámica, en ocasiones es necesario hacerjb cleanantes dejb build. Además de esto, debe asegurarse de que enJupyter Labse puede visualizar cada gráfico dinámico, y ejecutarjb buildnuevamente para visualizar su figura. Evite guardar los archivos de suJBookenOneDrive/Google Drive. También, debe agregar a su archivo_config.ymllas siguientes líneas:
sphinx:
config:
html_js_files:
- https://cdnjs.cloudflare.com/ajax/libs/require.js/2.3.4/require.min.js
Añadir un deslizador al gráfico estático#
Nombramos el archivo HTML de salida como co2_emissions
output_file("co2_emissions.html")
Creamos la función
callbackusandoCustomJSde la libreriabokehla cual permitira actualizar nuestra figura. Usamos algunas pocas ordenes en lenguajeJavaScript. En este casocb_obj.valuecontiene el modelo queactiva el callback
callback = CustomJS(args=dict(source_last=source_last, source_init=source_init), code="""
var data_init = source_init.data;
var yr = cb_obj.value;
var year = source_last.data['year'];
var x_new = [];
var y_new = [];
for(var i = 0; i < year.length; i++) {
if(year[i] == yr) {
x_new.push(source_last.data['x'][i]);
y_new.push(source_last.data['y'][i]);
}
}
data_init['x'] = x_new;
data_init['y'] = y_new;
source_init.change.emit();
""")
Construimos el
sliderque utilizaremos para actualizar las figuras, y realizamos el llamado de la funcióncallbackque recibirá como input cada año que proviene del slider. La siguiente figura podrá ser visualizada desde su editorVS CodeoJupyter Lab. Para visualizarla en suJBookdeberá actualizar elhtmldesde su navegador, para que la funciónshow()pueda activarse y mostrarse en su página.
slider = Slider(start=min(data.year), end=max(data.year), step=1, value=min(data.year), title='Year')
slider.js_on_change('value', callback)
layout = column(slider, plot)
show(layout)
Como puede ver, en la esquina derecha, hay varias herramientas. Estas son generadas automáticamente por Bokeh cuando se crea un gráfico
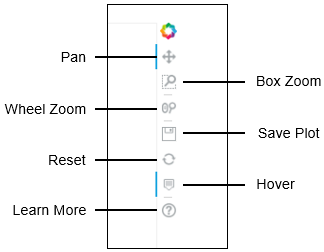
Estas herramientas son las siguientes:
Pan: La herramienta de desplazamiento le permite mover y cambiar la vista de su parcela
Box Zoom: Le permite ampliar una sección cuadrada concreta de la cuadrado de la parcela
Wheel Zoom: Le permite acercarse arbitrariamente a cualquier punto del gráfico.
Save Plot: Permite guardar el gráfico actual.
Reset: Esto restablece el gráfico y le lleva de vuelta al gráfico original en el que aterrizó. a la parcela original.
Hover: Creamos una herramienta de hover en nuestra parcela y la programamos para que muestre cierta información. Sin embargo, Bokeh también genera automáticamente una herramienta hover que puede ser activada y desactivada por este icono. Esta herramienta puede no mostrar siempre lo que que queremos, por lo que hemos creado una nosotros mismos.
Visualización interactiva de datos con Plotly Express#
Plotly es una biblioteca de Python muy popular y se utiliza para crear sorprendentes e informativas visualizaciones de datos interactivos.
Es una herramienta de ploteo basada en JSON, por lo que cada ploteo está definido por dos objetos JSON - datos y diseño.
El despliegue de una visualización Plotly requiere un poco más de esfuerzo que una visualización Bokeh porque tenemos que construir una aplicación separada (más comúnmente una aplicación Flask) utilizando el marco Dash.
En comparación con Bokeh, las herramientas y la sintaxis de Plotly son mucho más sencillas. Sin embargo, el código que se requiere para crear estas visualizaciones de datos interactivos es un poco más extenso.
Creación de un gráfico de dispersión interactivo#
En este ejercicio, vamos a crear una visualización de datos interactiva del DataFrame que creamos en el ejercicio anterior, de las emisiones de dióxido de carbono y el PIB. Los siguientes pasos te ayudarán con la solución
Abra un nuevo cuaderno Jupyter. Importe las siguientes bibliotecas y paquetes:
pandas: Para preparar el DataFrameplotly.express: Para crear las gráficas
import pandas as pd
import plotly.express as px
Cree el DataFrame de emisiones de dióxido de carbono y PIB del ejercicio anterior en este notebook:
url_co2 = 'https://raw.githubusercontent.com/lihkir/Uninorte/main/AppliedStatisticMS/DataVisualizationRPython/Lectures/Python/PythonDataSets/co2.csv'
co2 = pd.read_csv(url_co2)
url_gm = 'https://raw.githubusercontent.com/lihkir/Uninorte/main/AppliedStatisticMS/DataVisualizationRPython/Lectures/Python/PythonDataSets/gapminder.csv'
gm = pd.read_csv(url_gm)
df_gm = gm[['Country', 'region']].drop_duplicates()
df_w_regions = pd.merge(co2, df_gm, left_on='country', right_on='Country', how='inner')
df_w_regions = df_w_regions.drop('Country', axis='columns')
new_co2 = pd.melt(df_w_regions, id_vars=['country', 'region'])
columns = ['country', 'region', 'year', 'co2']
new_co2.columns = columns
df_co2 = new_co2[new_co2['year'].astype('int64') > 1963]
df_co2 = df_co2.sort_values(by=['country', 'year'])
df_co2['year'] = df_co2['year'].astype('int64')
df_gdp = gm[['Country', 'Year', 'gdp']]
df_gdp.columns = ['country', 'year', 'gdp']
data = pd.merge(df_co2, df_gdp, on=['country', 'year'], how='left')
data = data.dropna()
data.head()
| country | region | year | co2 | gdp | |
|---|---|---|---|---|---|
| 0 | Afghanistan | South Asia | 1964 | 0.0863 | 1182.0 |
| 1 | Afghanistan | South Asia | 1965 | 0.1010 | 1182.0 |
| 2 | Afghanistan | South Asia | 1966 | 0.1080 | 1168.0 |
| 3 | Afghanistan | South Asia | 1967 | 0.1240 | 1173.0 |
| 4 | Afghanistan | South Asia | 1968 | 0.1160 | 1187.0 |
Guarda los valores mínimo y máximo del PIB como xmin y xmax respectivamente
xmin, xmax = min(data.gdp), max(data.gdp)
Repita el paso 4 para los valores mínimos y máximos de emisión de dióxido de carbono
ymin, ymax = min(data.co2), max(data.co2)
Crea el gráfico de dispersión y guárdalo como fig:
El parámetro data será el nombre de nuestro DataFrame, es decir, data.
Asigna la columna gdp al eje x.
Asigna la columna co2 al eje y.
Establecer el parámetro animation_frame como la columna del año.
Establezca el parámetro animation_group como la columna del país.
Establezca el color de los puntos de datos como la columna región.
Asigna la columna country al parámetro hover_name.
Establecer el parámetro facet_col como la columna región (esto divide nuestro gráfico en seis columnas, una para cada región).
Establece la anchura como 1579 y la altura como 400.
El eje x debe ser logarítmico.
Establezca el parámetro size_max como 45.
Asigna el rango del eje x y del eje y como xmin, xmax y ymin, ymax, respectivamente
import plotly.io as pio
import plotly.express as px
import plotly.offline as py
fig = px.scatter(data,
x="gdp", y="co2",
animation_frame="year",
animation_group="country",
color="region",
hover_name="country",
facet_col="region",
width=1579, height=400,
log_x=True,
size_max=45,
range_x=[xmin,xmax],
range_y=[ymin,ymax])
fig.show()
Para visualizar la figura de utilizar la orden
fig.show(). Haga click en Play para visualizar cada gráfico de dispersión.
Observaciones
Como puede ver, tenemos un gráfico con seis subplots; uno para cada región.
Cada región está codificada por colores.
Cada subgrupo tiene las emisiones de dióxido de carbono en toneladas por persona como eje y la renta por persona en el eje de abscisas.
En la parte inferior del gráfico hay un control deslizante que nos permite comparar la correlación entre las emisiones de dióxido de carbono y la renta por año entre regiones y países por año.
Al pulsar el botón de reproducción en la esquina inferior izquierda, el gráfico progresa automáticamente desde el año 1964 hasta el 2013, mostrándonos cómo los puntos de datos con el tiempo.
También podemos mover manualmente el deslizador
Además, podemos pasar el ratón por encima de un punto de datos para obtener más información sobre él
Como puede ver, la creación de una visualización de datos interactivos con Plotly Express toma muy pocas líneas de código y la sintaxis es fácil de aprender y utilizar. Además de los gráficos de dispersión, la biblioteca tiene muchos otros tipos de gráficos que puede utilizar para visualizar interactivamente diferentes tipos de datos, los cuales serán estudiados en las siguientes actividades.
Haga clic en el siguiente enlace para consultar otras gráficas disponibles con:
Plotly Express
Ejercicio para entregar#
En esta actividad, trabajará con el mismo conjunto de datos que trabajó en los ejercicios de este capítulo. Es importante que pruebes varios tipos de visualización para determinar la visualización que mejor transmite el mensaje que está tratando de dar con sus datos. Vamos a crear algunas visualizaciones interactivas utilizando la biblioteca
Plotly Expresspara determinar cuál es la que mejor se adapta a nuestros datosVuelve a crear el
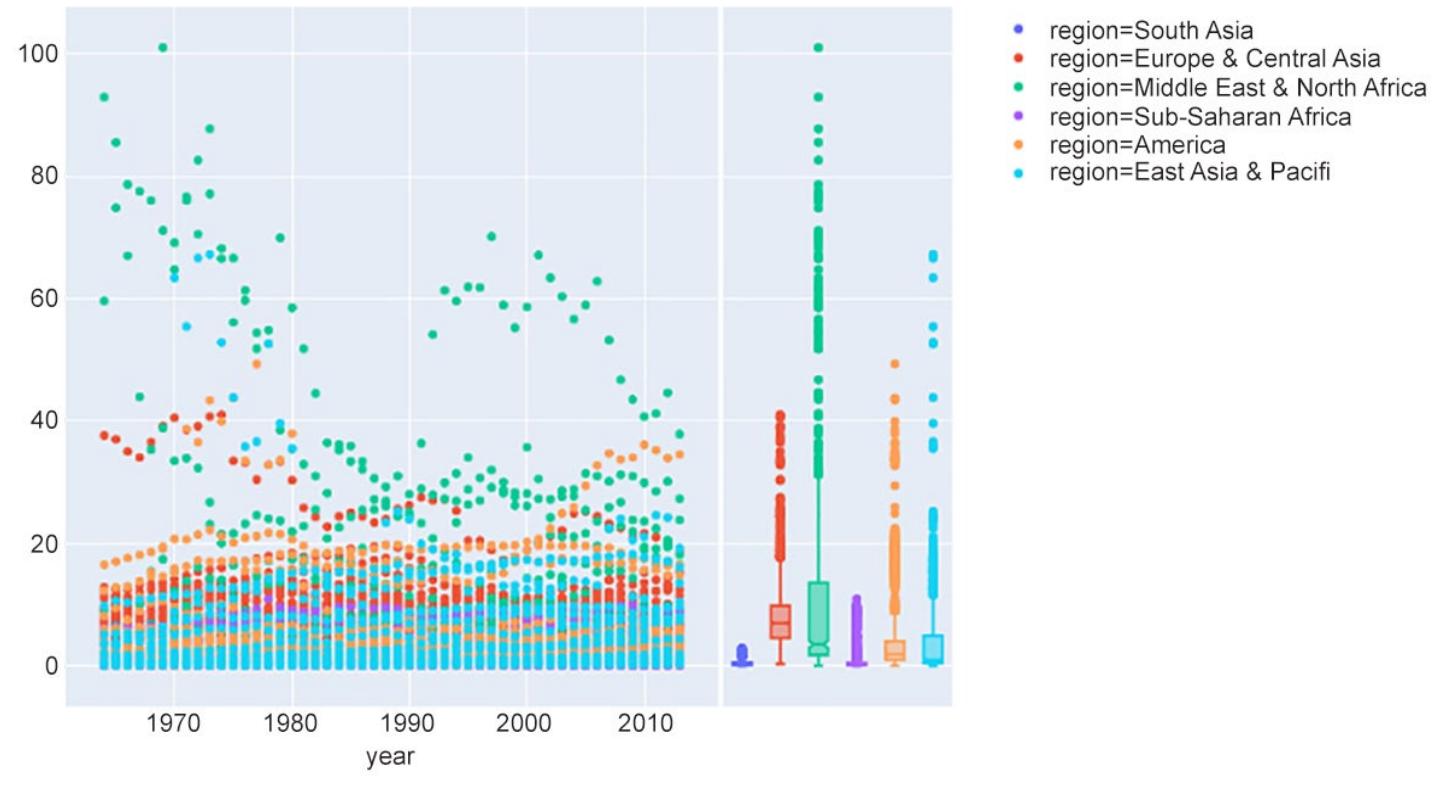
DataFramede las emisiones de dióxido de carbono y del PIB.Genere un gráfico de dispersión con los ejes
xeycomoyearyco2respectivamente. Añada uno para los valores deco2con el parámetro marginal_y.Genere un gráfico de caja para los valores del PIB con el parámetro marginal_x. Añada los parámetros de animación en la columna del año
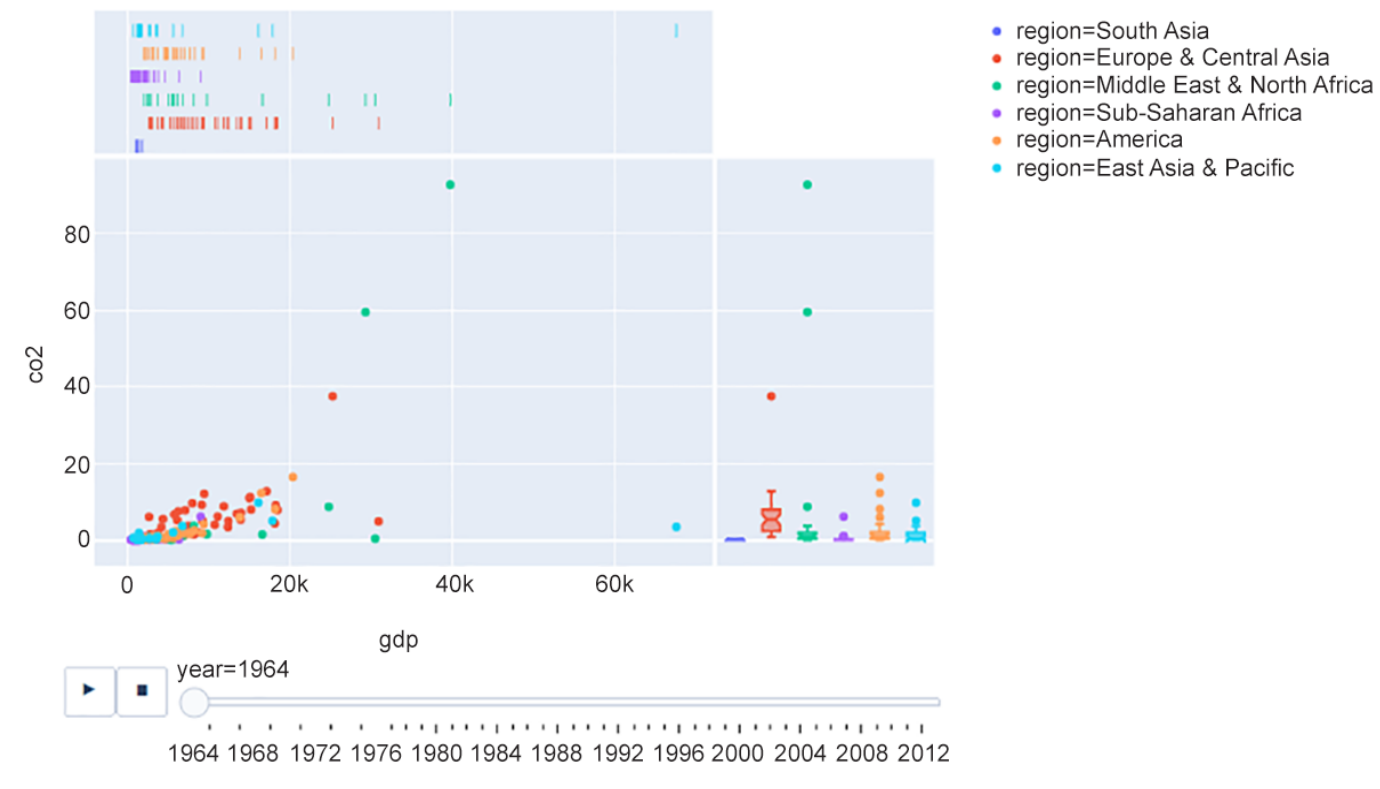
Genere un gráfico de dispersión con los ejes
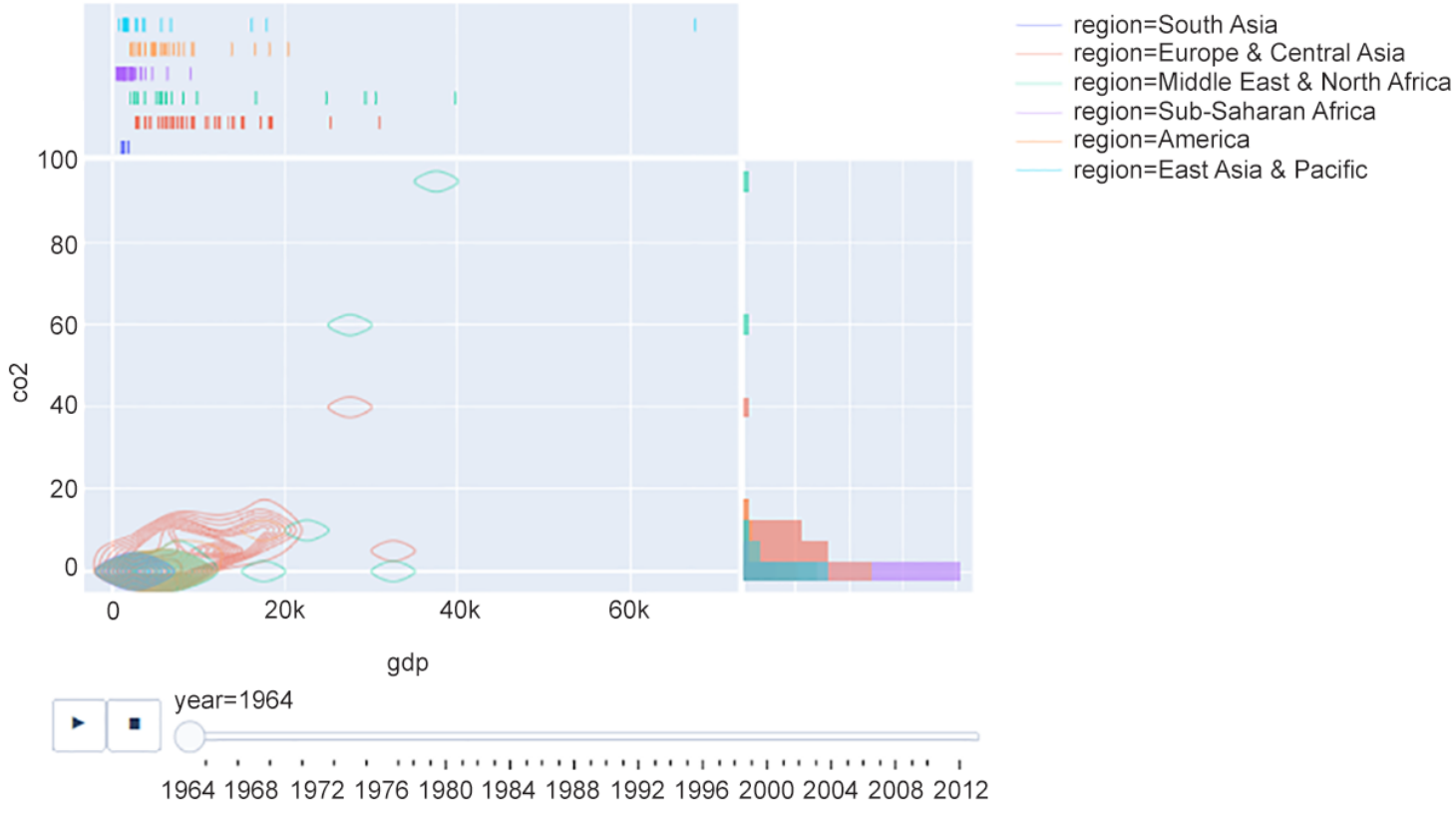
xeycomogdpyco2respectivamente.Genere un contorno de densidad con los ejes
xeycomogdpyco2respectivamente.
Las salidas deberían serrespectivamente para cada ejercicio
Resumen
En este capítulo, hemos aprendido que las visualizaciones de datos interactivas están un paso por delante de las de las visualizaciones de datos estáticas debido a su capacidad para responder a las entradas humanas en tiempo real.
La gama de aplicaciones de las visualizaciones de datos interactivas es muy amplia, y podemos visualizar casi cualquier tipo de datos de forma interactiva.
Las entradas humanas que pueden incorporarse a las visualizaciones de datos interactivas incluyen, pero no se limitan a los controles deslizantes, las funciones de zoom, las herramientas de desplazamiento y los parámetros en los que se puede hacer clic.
BokehyPlotly Expressson dos de las bibliotecas dePythonmás populares y sencillas para crear visualizaciones de datos interactivas.En la proxima sección, veremos cómo crear hermosas visualizaciones de datos interactivas basadas en el contexto.