
Introducción a la visualización de datos con Python#
Introducción
La visualización de datos es el arte y la ciencia de contar historias cautivadoras con datos.
¿Por qué Python?Pythonrealiza cálculos numéricos y científicos avanzados con librerías como: numpy y scipy, alberga una amplia gama de métodos de de métodos de aprendizaje automático gracias a la disponibilidad del paquete scikit-learnProporciona una gran interfaz para manipulación de big data gracias a la disponibilidad del paquete
pandasy su compatibilidad con Apache SparkGenera gráficos y figuras estéticamente con librerías como seaborn, plotly, etc.
Manejo de datos con pandas DataFrame#
La biblioteca pandas es un conjunto de herramientas de código abierto extremadamente ingenioso para manejar manipular y analizar datos estructurados. Las tablas de datos se pueden almacenar en el objeto DataFrame disponible en pandas, y los datos en múltiples formatos (por ejemplo, .csv, .tsv, .xlsx y .json) pueden leerse directamente en un DataFrame.
Lectura de datos desde archivos#
from bokeh.resources import INLINE
import bokeh.io
from bokeh import *
bokeh.io.output_notebook(INLINE)
Para importar la librería Bokeh, debe instalarla primero con la siguiente orden. La versión especificada permitirá ejecutar las visualizaciones del presente curso, sin ningún conflicto
pip install -U bokeh==2.4.0
En este ejercicio, leeremos de un conjunto de datos. En este ejemplo se utiliza el conjunto de datos diamantes
Abre un cuaderno jupyter y carga la librería pandas
import pandas as pd
import warnings
warnings.filterwarnings('ignore')
Especifique la URL del conjunto de datos:
diamonds_url = "https://raw.githubusercontent.com/lihkir/Uninorte/main/AppliedStatisticMS/DataVisualizationRPython/Lectures/Python/PythonDataSets/diamonds.csv"
Leer los archivos de la URL en el DataFrame de pandas
diamonds_df = pd.read_csv(diamonds_url)
diamonds_df.head()
| carat | cut | color | clarity | depth | table | price | x | y | z | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.23 | Ideal | E | SI2 | 61.5 | 55.0 | 326 | 3.95 | 3.98 | 2.43 |
| 1 | 0.21 | Premium | E | SI1 | 59.8 | 61.0 | 326 | 3.89 | 3.84 | 2.31 |
| 2 | 0.23 | Good | E | VS1 | 56.9 | 65.0 | 327 | 4.05 | 4.07 | 2.31 |
| 3 | 0.29 | Premium | I | VS2 | 62.4 | 58.0 | 334 | 4.20 | 4.23 | 2.63 |
| 4 | 0.31 | Good | J | SI2 | 63.3 | 58.0 | 335 | 4.34 | 4.35 | 2.75 |
Use the usecols parameter if only specific columns need to be read.
diamonds_df_specific_cols = pd.read_csv(diamonds_url, usecols=['carat','cut','color','clarity'])
diamonds_df_specific_cols.head()
| carat | cut | color | clarity | |
|---|---|---|---|---|
| 0 | 0.23 | Ideal | E | SI2 |
| 1 | 0.21 | Premium | E | SI1 |
| 2 | 0.23 | Good | E | VS1 |
| 3 | 0.29 | Premium | I | VS2 |
| 4 | 0.31 | Good | J | SI2 |
Observación y descripción de datos#
En este ejercicio, veremos cómo observar y describir datos en un DataFrame. Volveremos a utilizar el conjunto de datos de diamantes
Cargue la librería pandas:
import pandas as pd
Leer los archivos de la URL en el DataFrame de pandas
diamonds_df = pd.read_csv(diamonds_url)
Observe los datos utilizando la función head:
diamonds_df.head()
| carat | cut | color | clarity | depth | table | price | x | y | z | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.23 | Ideal | E | SI2 | 61.5 | 55.0 | 326 | 3.95 | 3.98 | 2.43 |
| 1 | 0.21 | Premium | E | SI1 | 59.8 | 61.0 | 326 | 3.89 | 3.84 | 2.31 |
| 2 | 0.23 | Good | E | VS1 | 56.9 | 65.0 | 327 | 4.05 | 4.07 | 2.31 |
| 3 | 0.29 | Premium | I | VS2 | 62.4 | 58.0 | 334 | 4.20 | 4.23 | 2.63 |
| 4 | 0.31 | Good | J | SI2 | 63.3 | 58.0 | 335 | 4.34 | 4.35 | 2.75 |
Los datos contienen diferentes características de los diamantes, como quilates, calidad de corte, color y precio: carat, cut, color, clarity, depth, table, price como columnas. Ahora, corte, claridad y color son variables categóricas, y x, y, z, profundidad, tabla y precio son variables continuas. Mientras que las variables categóricas toman como valores categorías/nombres únicos, los valores continuos toman números reales como valores.
Contar el número de filas y columnas en el DataFrame utilizando la función shape
diamonds_df.shape
(53940, 10)
Resumir las columnas utilizando
describe()para obtener la distribución de las variables, incluyendo la media, la mediana, el mínimo, el máximo y los diferentes cuartiles
diamonds_df.describe()
| carat | depth | table | price | x | y | z | |
|---|---|---|---|---|---|---|---|
| count | 53940.000000 | 53940.000000 | 53940.000000 | 53940.000000 | 53940.000000 | 53940.000000 | 53940.000000 |
| mean | 0.797940 | 61.749405 | 57.457184 | 3932.799722 | 5.731157 | 5.734526 | 3.538734 |
| std | 0.474011 | 1.432621 | 2.234491 | 3989.439738 | 1.121761 | 1.142135 | 0.705699 |
| min | 0.200000 | 43.000000 | 43.000000 | 326.000000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 0.400000 | 61.000000 | 56.000000 | 950.000000 | 4.710000 | 4.720000 | 2.910000 |
| 50% | 0.700000 | 61.800000 | 57.000000 | 2401.000000 | 5.700000 | 5.710000 | 3.530000 |
| 75% | 1.040000 | 62.500000 | 59.000000 | 5324.250000 | 6.540000 | 6.540000 | 4.040000 |
| max | 5.010000 | 79.000000 | 95.000000 | 18823.000000 | 10.740000 | 58.900000 | 31.800000 |
Esto funciona para las variables continuas. Sin embargo, para las variables categóricas, necesitamos utilizar el parámetro include=object.
diamonds_df.describe(include=object)
| cut | color | clarity | |
|---|---|---|---|
| count | 53940 | 53940 | 53940 |
| unique | 5 | 7 | 8 |
| top | Ideal | G | SI1 |
| freq | 21551 | 11292 | 13065 |
Para obtener información sobre el conjunto de datos, utilice el método
info():
diamonds_df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 53940 entries, 0 to 53939
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 carat 53940 non-null float64
1 cut 53940 non-null object
2 color 53940 non-null object
3 clarity 53940 non-null object
4 depth 53940 non-null float64
5 table 53940 non-null float64
6 price 53940 non-null int64
7 x 53940 non-null float64
8 y 53940 non-null float64
9 z 53940 non-null float64
dtypes: float64(6), int64(1), object(3)
memory usage: 4.1+ MB
Podemos acceder a la columna corte del DataFrame diamonds_df con diamonds_df.cut o diamonds_df[‘cut’]
Ahora, ¿qué tal si seleccionamos todas las filas correspondientes a los diamantes que tienen la talla Ideal y almacenarlas en un DataFrame separado? Podemos seleccionarlas utilizando la función loc para seleccionarlos:
diamonds_low_df = diamonds_df.loc[diamonds_df['cut']=='Ideal']
diamonds_low_df.head()
| carat | cut | color | clarity | depth | table | price | x | y | z | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.23 | Ideal | E | SI2 | 61.5 | 55.0 | 326 | 3.95 | 3.98 | 2.43 |
| 11 | 0.23 | Ideal | J | VS1 | 62.8 | 56.0 | 340 | 3.93 | 3.90 | 2.46 |
| 13 | 0.31 | Ideal | J | SI2 | 62.2 | 54.0 | 344 | 4.35 | 4.37 | 2.71 |
| 16 | 0.30 | Ideal | I | SI2 | 62.0 | 54.0 | 348 | 4.31 | 4.34 | 2.68 |
| 39 | 0.33 | Ideal | I | SI2 | 61.8 | 55.0 | 403 | 4.49 | 4.51 | 2.78 |
Añadir nuevas columnas al DataFrame#
En este ejercicio, vamos a añadir nuevas columnas al conjunto de datos de diamantes en la biblioteca pandas. Empezaremos con la adición simple de columnas y luego avanzaremos y veremos la adición condicional de columnas. Para ello, vamos a seguir los siguientes pasos:
Cargue la biblioteca
pandas
import pandas as pd
Leer los archivos de la URL en el DataFrame de pandas
diamonds_df = pd.read_csv(diamonds_url)
diamonds_df.head()
| carat | cut | color | clarity | depth | table | price | x | y | z | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.23 | Ideal | E | SI2 | 61.5 | 55.0 | 326 | 3.95 | 3.98 | 2.43 |
| 1 | 0.21 | Premium | E | SI1 | 59.8 | 61.0 | 326 | 3.89 | 3.84 | 2.31 |
| 2 | 0.23 | Good | E | VS1 | 56.9 | 65.0 | 327 | 4.05 | 4.07 | 2.31 |
| 3 | 0.29 | Premium | I | VS2 | 62.4 | 58.0 | 334 | 4.20 | 4.23 | 2.63 |
| 4 | 0.31 | Good | J | SI2 | 63.3 | 58.0 | 335 | 4.34 | 4.35 | 2.75 |
Añade una columna
price_per_caratalDataFrame. En este ejemplo el precio por quilates. Del mismo modo, también podemos utilizar la suma, la resta y otros operadores matemáticos sobre dos columnas numéricas.
diamonds_df['price_per_carat'] = diamonds_df['price']/diamonds_df['carat']
Llame a la función head de DataFrame para comprobar si la nueva columna se ha añadido como como se esperaba:
diamonds_df.head()
| carat | cut | color | clarity | depth | table | price | x | y | z | price_per_carat | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.23 | Ideal | E | SI2 | 61.5 | 55.0 | 326 | 3.95 | 3.98 | 2.43 | 1417.391304 |
| 1 | 0.21 | Premium | E | SI1 | 59.8 | 61.0 | 326 | 3.89 | 3.84 | 2.31 | 1552.380952 |
| 2 | 0.23 | Good | E | VS1 | 56.9 | 65.0 | 327 | 4.05 | 4.07 | 2.31 | 1421.739130 |
| 3 | 0.29 | Premium | I | VS2 | 62.4 | 58.0 | 334 | 4.20 | 4.23 | 2.63 | 1151.724138 |
| 4 | 0.31 | Good | J | SI2 | 63.3 | 58.0 | 335 | 4.34 | 4.35 | 2.75 | 1080.645161 |
Ahora, veremos la adición condicional de columnas. Vamos a intentar añadir una columna basada en el valor de
price_per_carat, digamos que todo lo que sea más de 3500 como alto (codificado como 1) y todo lo que sea inferior a 3500 como bajo (codificado como 0).
import numpy as np
diamonds_df['price_per_carat_is_high'] = np.where(diamonds_df['price_per_carat'] > 3500, 1, 0)
diamonds_df.tail()
| carat | cut | color | clarity | depth | table | price | x | y | z | price_per_carat | price_per_carat_is_high | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 53935 | 0.72 | Ideal | D | SI1 | 60.8 | 57.0 | 2757 | 5.75 | 5.76 | 3.50 | 3829.166667 | 1 |
| 53936 | 0.72 | Good | D | SI1 | 63.1 | 55.0 | 2757 | 5.69 | 5.75 | 3.61 | 3829.166667 | 1 |
| 53937 | 0.70 | Very Good | D | SI1 | 62.8 | 60.0 | 2757 | 5.66 | 5.68 | 3.56 | 3938.571429 | 1 |
| 53938 | 0.86 | Premium | H | SI2 | 61.0 | 58.0 | 2757 | 6.15 | 6.12 | 3.74 | 3205.813953 | 0 |
| 53939 | 0.75 | Ideal | D | SI2 | 62.2 | 55.0 | 2757 | 5.83 | 5.87 | 3.64 | 3676.000000 | 1 |
Aplicación de funciones a las columnas de DataFrame#
En este ejercicio, consideraremos un escenario en el que el precio de los diamantes ha aumentado y queremos aplicar un factor de incremento de 1.3 al precio de todos los diamantes en nuestro registro. Podemos conseguirlo aplicando una sencilla función. A continuación, redondearemos el precio de los diamantes hasta su tope. Para ello, vamos a seguir los siguientes pasos
Cargue la biblioteca
pandas
import pandas as pd
Leer los archivos de la URL en el DataFrame de pandas
diamonds_df = pd.read_csv(diamonds_url)
diamonds_df.head()
| carat | cut | color | clarity | depth | table | price | x | y | z | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.23 | Ideal | E | SI2 | 61.5 | 55.0 | 326 | 3.95 | 3.98 | 2.43 |
| 1 | 0.21 | Premium | E | SI1 | 59.8 | 61.0 | 326 | 3.89 | 3.84 | 2.31 |
| 2 | 0.23 | Good | E | VS1 | 56.9 | 65.0 | 327 | 4.05 | 4.07 | 2.31 |
| 3 | 0.29 | Premium | I | VS2 | 62.4 | 58.0 | 334 | 4.20 | 4.23 | 2.63 |
| 4 | 0.31 | Good | J | SI2 | 63.3 | 58.0 | 335 | 4.34 | 4.35 | 2.75 |
Aplique una función simple en las columnas utilizando el siguiente código:
diamonds_df['price'] = diamonds_df['price']*1.3
diamonds_df.head()
| carat | cut | color | clarity | depth | table | price | x | y | z | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.23 | Ideal | E | SI2 | 61.5 | 55.0 | 423.8 | 3.95 | 3.98 | 2.43 |
| 1 | 0.21 | Premium | E | SI1 | 59.8 | 61.0 | 423.8 | 3.89 | 3.84 | 2.31 |
| 2 | 0.23 | Good | E | VS1 | 56.9 | 65.0 | 425.1 | 4.05 | 4.07 | 2.31 |
| 3 | 0.29 | Premium | I | VS2 | 62.4 | 58.0 | 434.2 | 4.20 | 4.23 | 2.63 |
| 4 | 0.31 | Good | J | SI2 | 63.3 | 58.0 | 435.5 | 4.34 | 4.35 | 2.75 |
Aplicar la función
math.ceilpara redondear el precio de los diamantes hasta su tope
import math
diamonds_df['rounded_price'] = diamonds_df['price'].apply(math.ceil)
diamonds_df.head()
| carat | cut | color | clarity | depth | table | price | x | y | z | rounded_price | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.23 | Ideal | E | SI2 | 61.5 | 55.0 | 423.8 | 3.95 | 3.98 | 2.43 | 424 |
| 1 | 0.21 | Premium | E | SI1 | 59.8 | 61.0 | 423.8 | 3.89 | 3.84 | 2.31 | 424 |
| 2 | 0.23 | Good | E | VS1 | 56.9 | 65.0 | 425.1 | 4.05 | 4.07 | 2.31 | 426 |
| 3 | 0.29 | Premium | I | VS2 | 62.4 | 58.0 | 434.2 | 4.20 | 4.23 | 2.63 | 435 |
| 4 | 0.31 | Good | J | SI2 | 63.3 | 58.0 | 435.5 | 4.34 | 4.35 | 2.75 | 436 |
Puede haber ocasiones en las que tenga que escribir su propia función para realizar la tarea que desea llevar a cabo.
Por ejemplo, digamos que quiere añadir otra columna al DataFrame indicando el precio redondeado de los diamantes al múltiplo de 100 (igual o superior al precio).
Utilice la función
lambdacomo sigue para redondear el precio de los diamantes al múltiplo de 100 más cercano
import math
diamonds_df['rounded_price_to_100multiple'] = diamonds_df['price'].apply(lambda x: 100*math.ceil(x/100))
diamonds_df.head()
| carat | cut | color | clarity | depth | table | price | x | y | z | rounded_price | rounded_price_to_100multiple | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.23 | Ideal | E | SI2 | 61.5 | 55.0 | 423.8 | 3.95 | 3.98 | 2.43 | 424 | 500 |
| 1 | 0.21 | Premium | E | SI1 | 59.8 | 61.0 | 423.8 | 3.89 | 3.84 | 2.31 | 424 | 500 |
| 2 | 0.23 | Good | E | VS1 | 56.9 | 65.0 | 425.1 | 4.05 | 4.07 | 2.31 | 426 | 500 |
| 3 | 0.29 | Premium | I | VS2 | 62.4 | 58.0 | 434.2 | 4.20 | 4.23 | 2.63 | 435 | 500 |
| 4 | 0.31 | Good | J | SI2 | 63.3 | 58.0 | 435.5 | 4.34 | 4.35 | 2.75 | 436 | 500 |
Por supuesto, no todas las funciones pueden ser escritas en una sola línea y es importante saber cómo incluir funciones definidas por el usuario en la función
apply. Vamos a escribir el mismo código con una función definida por el usuario para ilustrarlo.
import math
def get_100_multiple_ceil(x):
y = 100*math.ceil(x/100)
return y
diamonds_df['rounded_price_to_100multiple']=diamonds_df['price'].apply(get_100_multiple_ceil)
diamonds_df.head()
| carat | cut | color | clarity | depth | table | price | x | y | z | rounded_price | rounded_price_to_100multiple | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.23 | Ideal | E | SI2 | 61.5 | 55.0 | 423.8 | 3.95 | 3.98 | 2.43 | 424 | 500 |
| 1 | 0.21 | Premium | E | SI1 | 59.8 | 61.0 | 423.8 | 3.89 | 3.84 | 2.31 | 424 | 500 |
| 2 | 0.23 | Good | E | VS1 | 56.9 | 65.0 | 425.1 | 4.05 | 4.07 | 2.31 | 426 | 500 |
| 3 | 0.29 | Premium | I | VS2 | 62.4 | 58.0 | 434.2 | 4.20 | 4.23 | 2.63 | 435 | 500 |
| 4 | 0.31 | Good | J | SI2 | 63.3 | 58.0 | 435.5 | 4.34 | 4.35 | 2.75 | 436 | 500 |
Aplicación de funciones en varias columnas#
Supongamos que estamos interesados en comprar diamantes que tengan Ideal cut y color D (totalmente incoloro). Este ejercicio consiste en añadir una nueva columna, desired, al DataFrame, cuyo valor será yes si se cumplen nuestros criterios y no si no se cumplen. Veamos cómo lo hacemos:
Cargue la biblioteca pandas
import pandas as pd
Leer los archivos de la URL en el DataFrame de pandas
diamonds_df_exercise = pd.read_csv(diamonds_url)
diamonds_df_exercise.head()
| carat | cut | color | clarity | depth | table | price | x | y | z | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.23 | Ideal | E | SI2 | 61.5 | 55.0 | 326 | 3.95 | 3.98 | 2.43 |
| 1 | 0.21 | Premium | E | SI1 | 59.8 | 61.0 | 326 | 3.89 | 3.84 | 2.31 |
| 2 | 0.23 | Good | E | VS1 | 56.9 | 65.0 | 327 | 4.05 | 4.07 | 2.31 |
| 3 | 0.29 | Premium | I | VS2 | 62.4 | 58.0 | 334 | 4.20 | 4.23 | 2.63 |
| 4 | 0.31 | Good | J | SI2 | 63.3 | 58.0 | 335 | 4.34 | 4.35 | 2.75 |
Write a function to determine whether a record, x, is desired or not:
def is_desired(x):
bool_var = 'yes' if (x['cut']=='Ideal' and x['color']=='D') else 'no'
return bool_var
Utilice la función
applypara añadir la nueva columna, desired:
diamonds_df_exercise['desired'] = diamonds_df_exercise.apply(is_desired, axis = 'columns')
diamonds_df_exercise.tail()
| carat | cut | color | clarity | depth | table | price | x | y | z | desired | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 53935 | 0.72 | Ideal | D | SI1 | 60.8 | 57.0 | 2757 | 5.75 | 5.76 | 3.50 | yes |
| 53936 | 0.72 | Good | D | SI1 | 63.1 | 55.0 | 2757 | 5.69 | 5.75 | 3.61 | no |
| 53937 | 0.70 | Very Good | D | SI1 | 62.8 | 60.0 | 2757 | 5.66 | 5.68 | 3.56 | no |
| 53938 | 0.86 | Premium | H | SI2 | 61.0 | 58.0 | 2757 | 6.15 | 6.12 | 3.74 | no |
| 53939 | 0.75 | Ideal | D | SI2 | 62.2 | 55.0 | 2757 | 5.83 | 5.87 | 3.64 | yes |
Eliminación de columnas de un DataFrame#
Por último, vamos a ver cómo eliminar columnas de un DataFrame de pandas. Por ejemplo, borraremos las columnas rounded_price y rounded_price_to_100multiple
Cargue la biblioteca pandas
import pandas as pd
Leer los archivos de la URL en el DataFrame de pandas
diamonds_df = pd.read_csv(diamonds_url)
diamonds_df.head()
| carat | cut | color | clarity | depth | table | price | x | y | z | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.23 | Ideal | E | SI2 | 61.5 | 55.0 | 326 | 3.95 | 3.98 | 2.43 |
| 1 | 0.21 | Premium | E | SI1 | 59.8 | 61.0 | 326 | 3.89 | 3.84 | 2.31 |
| 2 | 0.23 | Good | E | VS1 | 56.9 | 65.0 | 327 | 4.05 | 4.07 | 2.31 |
| 3 | 0.29 | Premium | I | VS2 | 62.4 | 58.0 | 334 | 4.20 | 4.23 | 2.63 |
| 4 | 0.31 | Good | J | SI2 | 63.3 | 58.0 | 335 | 4.34 | 4.35 | 2.75 |
Añadir la columna price_per_carat al DataFrame
diamonds_df['price_per_carat'] = diamonds_df['price']/diamonds_df['carat']
diamonds_df.head()
| carat | cut | color | clarity | depth | table | price | x | y | z | price_per_carat | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.23 | Ideal | E | SI2 | 61.5 | 55.0 | 326 | 3.95 | 3.98 | 2.43 | 1417.391304 |
| 1 | 0.21 | Premium | E | SI1 | 59.8 | 61.0 | 326 | 3.89 | 3.84 | 2.31 | 1552.380952 |
| 2 | 0.23 | Good | E | VS1 | 56.9 | 65.0 | 327 | 4.05 | 4.07 | 2.31 | 1421.739130 |
| 3 | 0.29 | Premium | I | VS2 | 62.4 | 58.0 | 334 | 4.20 | 4.23 | 2.63 | 1151.724138 |
| 4 | 0.31 | Good | J | SI2 | 63.3 | 58.0 | 335 | 4.34 | 4.35 | 2.75 | 1080.645161 |
Utilice la función np.where del paquete numpy de Python:
import numpy as np
diamonds_df['price_per_carat_is_high'] = np.where(diamonds_df['price_per_carat'] > 3500, 1, 0)
diamonds_df.tail()
| carat | cut | color | clarity | depth | table | price | x | y | z | price_per_carat | price_per_carat_is_high | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 53935 | 0.72 | Ideal | D | SI1 | 60.8 | 57.0 | 2757 | 5.75 | 5.76 | 3.50 | 3829.166667 | 1 |
| 53936 | 0.72 | Good | D | SI1 | 63.1 | 55.0 | 2757 | 5.69 | 5.75 | 3.61 | 3829.166667 | 1 |
| 53937 | 0.70 | Very Good | D | SI1 | 62.8 | 60.0 | 2757 | 5.66 | 5.68 | 3.56 | 3938.571429 | 1 |
| 53938 | 0.86 | Premium | H | SI2 | 61.0 | 58.0 | 2757 | 6.15 | 6.12 | 3.74 | 3205.813953 | 0 |
| 53939 | 0.75 | Ideal | D | SI2 | 62.2 | 55.0 | 2757 | 5.83 | 5.87 | 3.64 | 3676.000000 | 1 |
Aplicar una función compleja para redondear el precio de los diamantes hasta su tope:
import math
diamonds_df['rounded_price'] = diamonds_df['price'].apply(math.ceil)
diamonds_df.head()
| carat | cut | color | clarity | depth | table | price | x | y | z | price_per_carat | price_per_carat_is_high | rounded_price | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.23 | Ideal | E | SI2 | 61.5 | 55.0 | 326 | 3.95 | 3.98 | 2.43 | 1417.391304 | 0 | 326 |
| 1 | 0.21 | Premium | E | SI1 | 59.8 | 61.0 | 326 | 3.89 | 3.84 | 2.31 | 1552.380952 | 0 | 326 |
| 2 | 0.23 | Good | E | VS1 | 56.9 | 65.0 | 327 | 4.05 | 4.07 | 2.31 | 1421.739130 | 0 | 327 |
| 3 | 0.29 | Premium | I | VS2 | 62.4 | 58.0 | 334 | 4.20 | 4.23 | 2.63 | 1151.724138 | 0 | 334 |
| 4 | 0.31 | Good | J | SI2 | 63.3 | 58.0 | 335 | 4.34 | 4.35 | 2.75 | 1080.645161 | 0 | 335 |
Escribe un código para crear una función definida por el usuario:
import math
def get_100_multiple_ceil(x):
y = math.ceil(x/100)*100
return y
diamonds_df['rounded_price_to_100multiple']=diamonds_df['price'].apply(get_100_multiple_ceil)
diamonds_df.head()
| carat | cut | color | clarity | depth | table | price | x | y | z | price_per_carat | price_per_carat_is_high | rounded_price | rounded_price_to_100multiple | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.23 | Ideal | E | SI2 | 61.5 | 55.0 | 326 | 3.95 | 3.98 | 2.43 | 1417.391304 | 0 | 326 | 400 |
| 1 | 0.21 | Premium | E | SI1 | 59.8 | 61.0 | 326 | 3.89 | 3.84 | 2.31 | 1552.380952 | 0 | 326 | 400 |
| 2 | 0.23 | Good | E | VS1 | 56.9 | 65.0 | 327 | 4.05 | 4.07 | 2.31 | 1421.739130 | 0 | 327 | 400 |
| 3 | 0.29 | Premium | I | VS2 | 62.4 | 58.0 | 334 | 4.20 | 4.23 | 2.63 | 1151.724138 | 0 | 334 | 400 |
| 4 | 0.31 | Good | J | SI2 | 63.3 | 58.0 | 335 | 4.34 | 4.35 | 2.75 | 1080.645161 | 0 | 335 | 400 |
Eliminar las columnas rounded_price y rounded_price_to_100multiple utilizando la función drop:
diamonds_df = diamonds_df.drop(columns = ['rounded_price', 'rounded_price_to_100multiple'])
diamonds_df.head()
| carat | cut | color | clarity | depth | table | price | x | y | z | price_per_carat | price_per_carat_is_high | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.23 | Ideal | E | SI2 | 61.5 | 55.0 | 326 | 3.95 | 3.98 | 2.43 | 1417.391304 | 0 |
| 1 | 0.21 | Premium | E | SI1 | 59.8 | 61.0 | 326 | 3.89 | 3.84 | 2.31 | 1552.380952 | 0 |
| 2 | 0.23 | Good | E | VS1 | 56.9 | 65.0 | 327 | 4.05 | 4.07 | 2.31 | 1421.739130 | 0 |
| 3 | 0.29 | Premium | I | VS2 | 62.4 | 58.0 | 334 | 4.20 | 4.23 | 2.63 | 1151.724138 | 0 |
| 4 | 0.31 | Good | J | SI2 | 63.3 | 58.0 | 335 | 4.34 | 4.35 | 2.75 | 1080.645161 | 0 |
Escribir un DataFrame en un archivo#
En este ejercicio, escribiremos un DataFrame de diamantes en un archivo .csv. Para ello, utilizaremos el siguiente código:
Cargue la biblioteca pandas
import pandas as pd
Leer los archivos de la URL en el DataFrame de pandas
diamonds_df = pd.read_csv(diamonds_url)
diamonds_df.head()
| carat | cut | color | clarity | depth | table | price | x | y | z | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.23 | Ideal | E | SI2 | 61.5 | 55.0 | 326 | 3.95 | 3.98 | 2.43 |
| 1 | 0.21 | Premium | E | SI1 | 59.8 | 61.0 | 326 | 3.89 | 3.84 | 2.31 |
| 2 | 0.23 | Good | E | VS1 | 56.9 | 65.0 | 327 | 4.05 | 4.07 | 2.31 |
| 3 | 0.29 | Premium | I | VS2 | 62.4 | 58.0 | 334 | 4.20 | 4.23 | 2.63 |
| 4 | 0.31 | Good | J | SI2 | 63.3 | 58.0 | 335 | 4.34 | 4.35 | 2.75 |
Escriba el conjunto de datos de los diamantes en un archivo .csv:
diamonds_df.to_csv('diamonds_modified.csv')
Por defecto, la función to_csv genera un archivo que incluye las cabeceras de las columnas y los números de las filas. así como los números de fila. Añade un parámetro
index=Falsepara excluir los números de fila:
diamonds_df.to_csv('diamonds_modified.csv', index = False)
Ahora que tenemos una idea básica de cómo cargar y manejar los datos en un objeto DataFrame de pandas, vamos a empezar a hacer algunos gráficos simples a partir de los datos.
matplotlib es una biblioteca de trazado disponible en la mayoría de las distribuciones de Python y es la es la base de varios paquetes de ploteo, incluyendo la funcionalidad de ploteo incorporada en pandas y seaborn. matplotlib permite controlar todos los aspectos de una figura y es conocido por ser muy detallado.
Trazado y análisis de un histograma#
En este ejercicio, crearemos un histograma de la frecuencia de los diamantes en el conjunto de datos con sus respectivas especificaciones de carat (quilates) en el eje \(x\):
Cargue la biblioteca pandas
import pandas as pd
import seaborn as sns
Leer los archivos de la URL en el DataFrame de pandas
diamonds_df = pd.read_csv(diamonds_url)
diamonds_df.head()
| carat | cut | color | clarity | depth | table | price | x | y | z | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.23 | Ideal | E | SI2 | 61.5 | 55.0 | 326 | 3.95 | 3.98 | 2.43 |
| 1 | 0.21 | Premium | E | SI1 | 59.8 | 61.0 | 326 | 3.89 | 3.84 | 2.31 |
| 2 | 0.23 | Good | E | VS1 | 56.9 | 65.0 | 327 | 4.05 | 4.07 | 2.31 |
| 3 | 0.29 | Premium | I | VS2 | 62.4 | 58.0 | 334 | 4.20 | 4.23 | 2.63 |
| 4 | 0.31 | Good | J | SI2 | 63.3 | 58.0 | 335 | 4.34 | 4.35 | 2.75 |
Trazar un histograma utilizando el conjunto de datos de diamantes donde el eje x axis = carat. El eje \(y\) de este gráfico indica el número de diamantes del conjunto de datos con la especificación de carat en el eje \(x\).
diamonds_df.hist(column='carat');

La función hist tiene un parámetro llamado bins, que se refiere literalmente al número de intervalos de igual tamaño en los que se dividen los puntos de datos. Por defecto el parámetro bins está fijado en 10 en pandas. Podemos cambiarlo por un número diferente diferente, si lo deseamos.
diamonds_df.hist(column = 'carat', bins = 50);
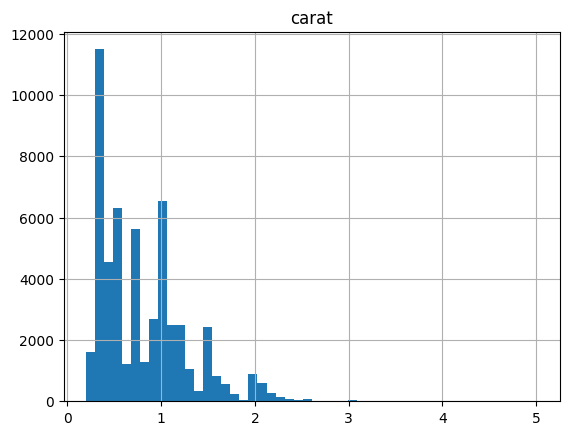
Ahora, veamos la misma función utilizando
seaborn. Note quepandasestablece el parámetro bins a un valor por defecto de 10, pero seaborn infiere un bin de tamaño apropiado basado en la distribución estadística del conjunto de datos.
import seaborn as sns
sns.distplot(diamonds_df.carat);
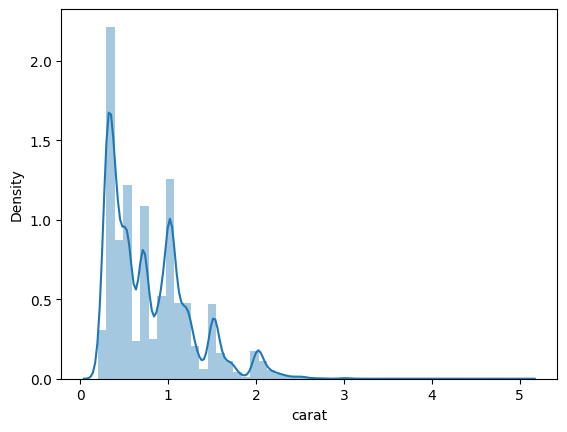
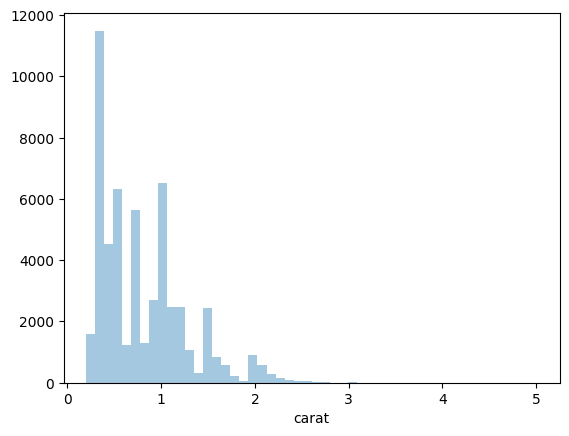
Por defecto, la función distplot también incluye una curva suavizada sobre el histograma, llamada estimación de la densidad del kernel (KDE). Si queremos eliminar el KDE y mirar sólo el histograma, podemos utilizar el parámetro kde=False.
sns.distplot(diamonds_df.carat, kde = False);
Una transformación logarítmica ayuda a identificar más tendencias. Por ejemplo, en el siguiente gráfico, el eje \(x\) muestra los valores transformados en logaritmos de la variable del precio, y vemos que hay dos picos que indican dos tipos de diamantes: uno con un precio alto y otro con un precio bajo
import numpy as np
sns.distplot(np.log(diamonds_df.price));
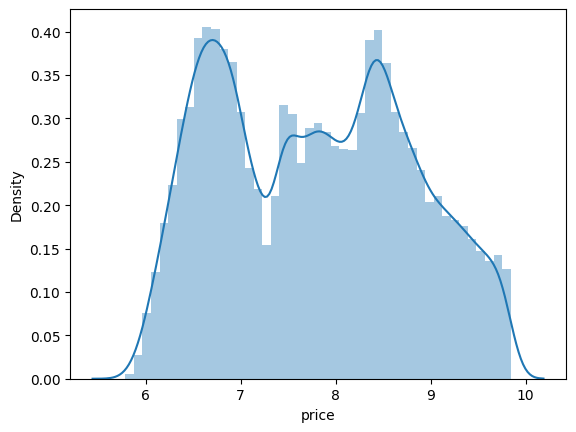
Qué valores de las características son más frecuentes en el conjunto de datos (en este caso, hay un pico en torno a 6.8 y otro pico entre 8.5 y 9, nótese que log(price) = valores, en este caso
Creación de un gráfico de barras y cálculo de la distribución del precio medio#
En este ejercicio, aprenderemos a crear una tabla utilizando la función
pandas crosstab. Utilizaremos una tabla para generar un gráfico de barras. A continuación, exploraremos un gráfico de barras generado con la bibliotecaseaborny calcularemos la distribución del precio medio. Para ello, vamos a realizar los siguientes pasos
Cargue la biblioteca pandas
import pandas as pd
import seaborn as sns
Leer los archivos de la URL en el DataFrame de pandas
diamonds_df = pd.read_csv(diamonds_url)
diamonds_df.head()
| carat | cut | color | clarity | depth | table | price | x | y | z | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.23 | Ideal | E | SI2 | 61.5 | 55.0 | 326 | 3.95 | 3.98 | 2.43 |
| 1 | 0.21 | Premium | E | SI1 | 59.8 | 61.0 | 326 | 3.89 | 3.84 | 2.31 |
| 2 | 0.23 | Good | E | VS1 | 56.9 | 65.0 | 327 | 4.05 | 4.07 | 2.31 |
| 3 | 0.29 | Premium | I | VS2 | 62.4 | 58.0 | 334 | 4.20 | 4.23 | 2.63 |
| 4 | 0.31 | Good | J | SI2 | 63.3 | 58.0 | 335 | 4.34 | 4.35 | 2.75 |
Imprime los valores únicos de la columna corte:
diamonds_df.cut.unique()
array(['Ideal', 'Premium', 'Good', 'Very Good', 'Fair'], dtype=object)
Imprime los valores únicos de la columna claridad:
diamonds_df.clarity.unique()
array(['SI2', 'SI1', 'VS1', 'VS2', 'VVS2', 'VVS1', 'I1', 'IF'],
dtype=object)
unique()devuelve un array. Hay cinco cualidades únicas de cut y ocho valores únicos en clarity. El número de valores únicos se puede obtener utilizandonunique()en `pandas.
Para obtener los recuentos de diamantes de cada calidad de cut, primero creamos una tabla utilizando la función pandas crosstab():
cut_count_table = pd.crosstab(index = diamonds_df['cut'], columns = 'count')
cut_count_table
| col_0 | count |
|---|---|
| cut | |
| Fair | 1610 |
| Good | 4906 |
| Ideal | 21551 |
| Premium | 13791 |
| Very Good | 12082 |
Pase estos recuentos a otra función pandas, plot(kind=’bar’):
cut_count_table.plot(kind = 'bar');
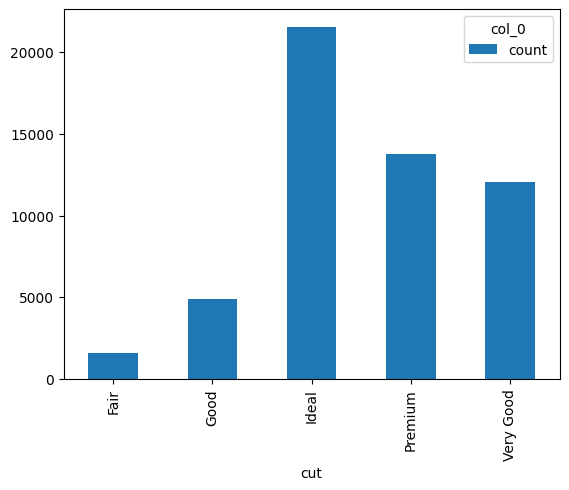
Vemos que la mayoría de los diamantes del conjunto de datos son de la calidad de corte Ideal, seguidos de Premium, Very Good, Good y Fair. Ahora, veamos cómo generar el mismo gráfico utilizando seaborn.
Generate the same bar plot using
seaborn
diamonds_df.head()
| carat | cut | color | clarity | depth | table | price | x | y | z | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.23 | Ideal | E | SI2 | 61.5 | 55.0 | 326 | 3.95 | 3.98 | 2.43 |
| 1 | 0.21 | Premium | E | SI1 | 59.8 | 61.0 | 326 | 3.89 | 3.84 | 2.31 |
| 2 | 0.23 | Good | E | VS1 | 56.9 | 65.0 | 327 | 4.05 | 4.07 | 2.31 |
| 3 | 0.29 | Premium | I | VS2 | 62.4 | 58.0 | 334 | 4.20 | 4.23 | 2.63 |
| 4 | 0.31 | Good | J | SI2 | 63.3 | 58.0 | 335 | 4.34 | 4.35 | 2.75 |
sns.catplot(data = diamonds_df, x = 'cut', aspect = 1.5, kind = "count", color = "b");
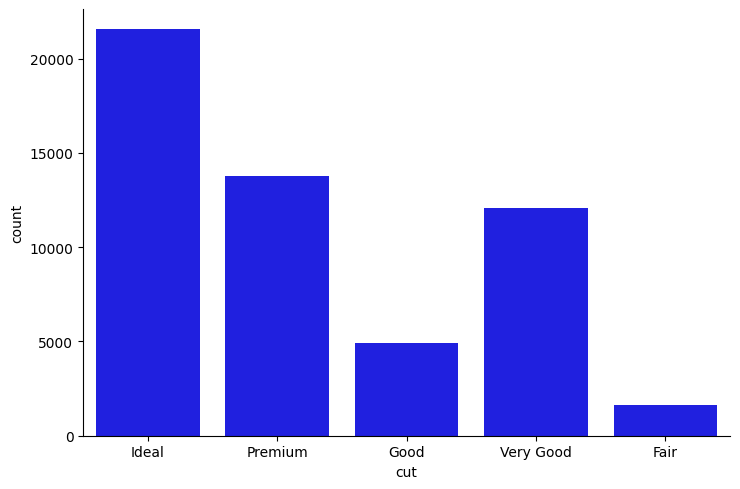
Observe cómo la función catplot() no requiere que creemos la tabla de recuento intermedia (utilizando pd.crosstab()), y reduce un paso en el proceso de trazado.
A continuación, se muestra cómo se obtiene la distribución del precio medio de las diferentes calidades de cut utilizando seaborn
import seaborn as sns
from numpy import median, mean
sns.set(style = "whitegrid")
ax = sns.barplot(x = "cut", y = "price", data = diamonds_df, estimator = mean);
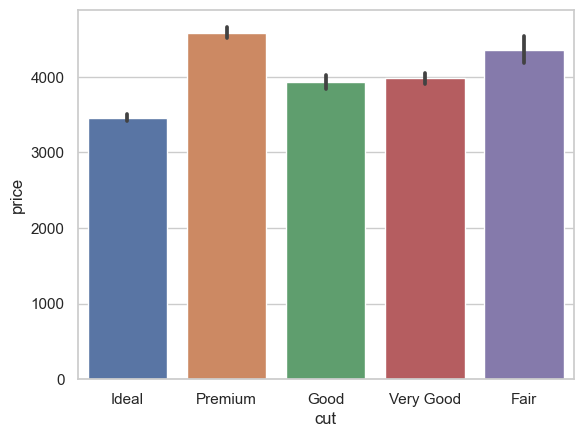
Aquí, las líneas negras (barras de error) de los rectángulos indican la incertidumbre (o dispersión de los valores) en torno a la estimación de la media. Las funciones mencionadas van mucho más allá de un simple recuento: aplican una función que calcula una medida de tendencia central (por defecto es el valor medio) y muestran, aplicando bootstrapping, el intervalo de confianza del 95% para dicha medida. Por defecto, este valor está fijado en un 95% de confianza. ¿Cómo lo cambiamos? Utilizando el parámetro ci=68, por ejemplo, lo fijamos en el 68%. También podemos representar la desviación estándar en los precios utilizando ci=sd.
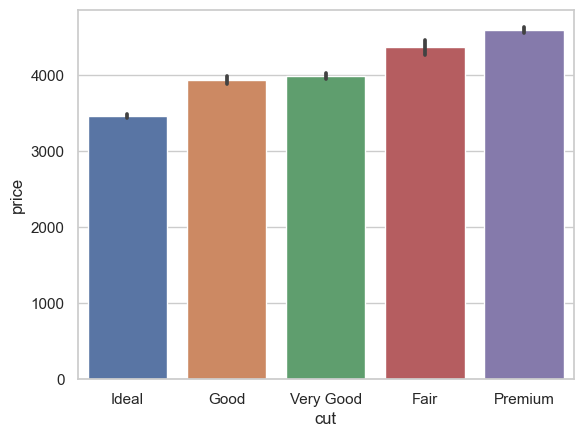
Reordenar las barras del eje x utilizando el orden:
ax = sns.barplot(x = "cut", y = "price", data = diamonds_df, estimator = mean, ci = 68,
order=['Ideal','Good','Very Good','Fair','Premium']);
Creación de gráficos de barras agrupados por una característica específica#
En este ejercicio, utilizaremos el conjunto de datos de los diamantes para generar la distribución de los precios con respecto al color para cada calidad de corte. En el ejercicio 7, vimos la distribución de precios para diamantes de diferentes calidades de talla. Ahora, nos gustaría ver la variación de cada color:
Cargue la biblioteca pandas
import pandas as pd
import seaborn as sns
Leer los archivos de la URL en el DataFrame de pandas
diamonds_df = pd.read_csv(diamonds_url)
diamonds_df.tail()
| carat | cut | color | clarity | depth | table | price | x | y | z | |
|---|---|---|---|---|---|---|---|---|---|---|
| 53935 | 0.72 | Ideal | D | SI1 | 60.8 | 57.0 | 2757 | 5.75 | 5.76 | 3.50 |
| 53936 | 0.72 | Good | D | SI1 | 63.1 | 55.0 | 2757 | 5.69 | 5.75 | 3.61 |
| 53937 | 0.70 | Very Good | D | SI1 | 62.8 | 60.0 | 2757 | 5.66 | 5.68 | 3.56 |
| 53938 | 0.86 | Premium | H | SI2 | 61.0 | 58.0 | 2757 | 6.15 | 6.12 | 3.74 |
| 53939 | 0.75 | Ideal | D | SI2 | 62.2 | 55.0 | 2757 | 5.83 | 5.87 | 3.64 |
Utilice el parámetro
huepara trazar grupos anidados:
ax = sns.barplot(x = "cut", y = "price", hue = 'color', data = diamonds_df);

Aquí podemos observar que los patrones de precios de los diamantes de diferentes colores son similares para cada calidad de talla.
Cómo ajustar los parámetros de un gráfico de barras agrupadas#
En este ejercicio, modificaremos los parámetros de los gráficos, por ejemplo,
hue, de un gráfico de barras agrupadas. Veremos cómo colocar las leyendas y las etiquetas de los ejes en los lugares adecuados y también exploraremos la función de rotación
Cargue la biblioteca pandas
import pandas as pd
import seaborn as sns
Leer los archivos de la URL en el DataFrame de pandas
diamonds_df = pd.read_csv(diamonds_url)
diamonds_df.head()
| carat | cut | color | clarity | depth | table | price | x | y | z | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.23 | Ideal | E | SI2 | 61.5 | 55.0 | 326 | 3.95 | 3.98 | 2.43 |
| 1 | 0.21 | Premium | E | SI1 | 59.8 | 61.0 | 326 | 3.89 | 3.84 | 2.31 |
| 2 | 0.23 | Good | E | VS1 | 56.9 | 65.0 | 327 | 4.05 | 4.07 | 2.31 |
| 3 | 0.29 | Premium | I | VS2 | 62.4 | 58.0 | 334 | 4.20 | 4.23 | 2.63 |
| 4 | 0.31 | Good | J | SI2 | 63.3 | 58.0 | 335 | 4.34 | 4.35 | 2.75 |
ax = sns.barplot(x = "cut", y = "price", hue = 'color', data = diamonds_df);
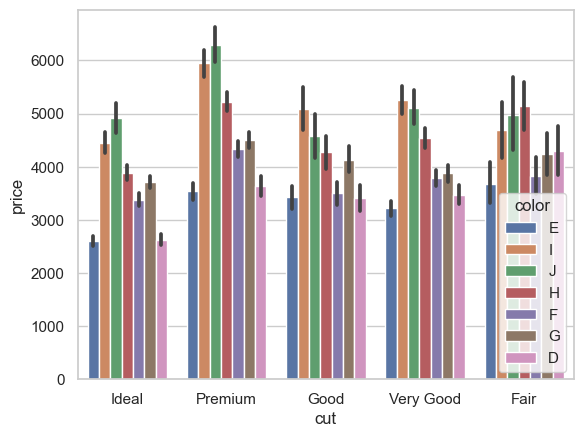
ax = sns.barplot(x='cut', y='price', hue='color', data=diamonds_df)
ax.legend(loc='upper right', ncol=4);
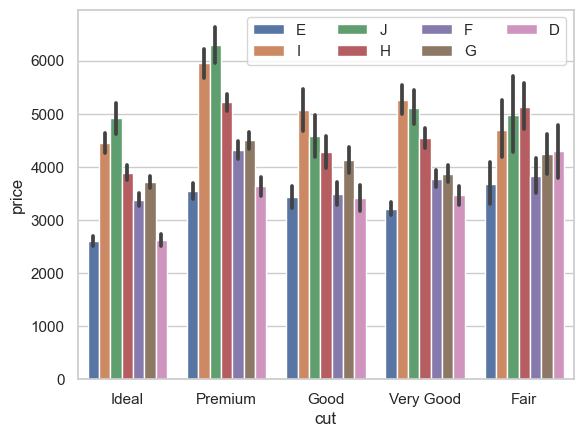
En la llamada anterior a ax.legend(), el parámetro ncol denota el número de columnas en las que deben organizarse los valores de la leyenda, y el parámetro loc especifica la ubicación de la leyenda y puede tomar cualquiera de los ocho valores 'upper left', 'upper right', 'lower left', 'lower right'.
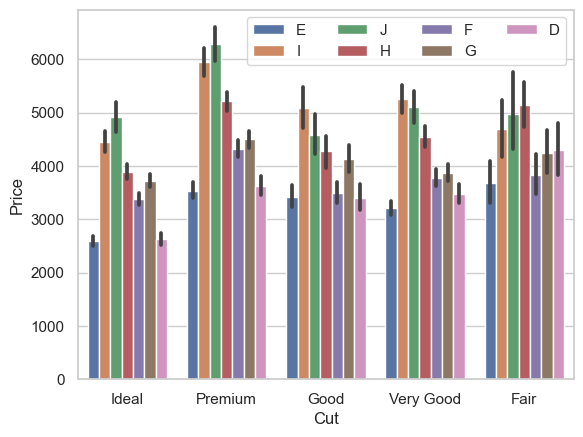
Para modificar las etiquetas de los ejes \(𝑥\) y \(𝑦\), introduzca el siguiente código
ax = sns.barplot(x='cut', y='price', hue='color', data=diamonds_df)
ax.legend(loc='upper right', ncol=4)
ax.set_xlabel('Cut', fontdict={'fontsize' : 12})
ax.set_ylabel('Price', fontdict={'fontsize' : 12});
Del mismo modo, utilice esto para modificar el tamaño de la fuente y la rotación del eje \(x\) de la garrapata etiquetas:
ax = sns.barplot(x='cut', y='price', hue='color', data=diamonds_df)
ax.legend(loc='upper right',ncol=4)
ax.set_xticklabels(ax.get_xticklabels(), fontsize=13, rotation=45)
ax.set_xlabel('Cut', fontdict={'fontsize' : 12})
ax.set_ylabel('Price', fontdict={'fontsize' : 12});
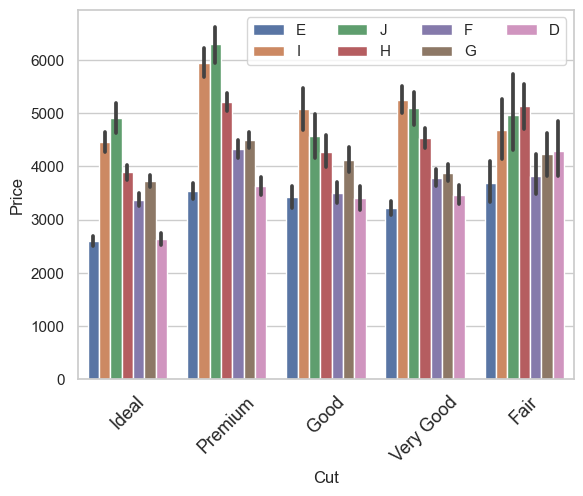
La función de rotación es especialmente útil cuando las etiquetas de ticks son largas y se amontonan en el eje \(x\).
Anotar un gráfico de barras#
En este ejercicio, anotaremos un gráfico de barras, generado con la función catplot de seaborn, utilizando una nota justo encima del gráfico.
Cargue la biblioteca pandas
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
Leer los archivos de la URL en el DataFrame de pandas
diamonds_df = pd.read_csv(diamonds_url)
diamonds_df.head()
| carat | cut | color | clarity | depth | table | price | x | y | z | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.23 | Ideal | E | SI2 | 61.5 | 55.0 | 326 | 3.95 | 3.98 | 2.43 |
| 1 | 0.21 | Premium | E | SI1 | 59.8 | 61.0 | 326 | 3.89 | 3.84 | 2.31 |
| 2 | 0.23 | Good | E | VS1 | 56.9 | 65.0 | 327 | 4.05 | 4.07 | 2.31 |
| 3 | 0.29 | Premium | I | VS2 | 62.4 | 58.0 | 334 | 4.20 | 4.23 | 2.63 |
| 4 | 0.31 | Good | J | SI2 | 63.3 | 58.0 | 335 | 4.34 | 4.35 | 2.75 |
Generar un gráfico de barras utilizando la función
catplotde la bibliotecaseaborn
ax = sns.catplot(data=diamonds_df, x="cut", aspect=1.5, kind="count", color="b");
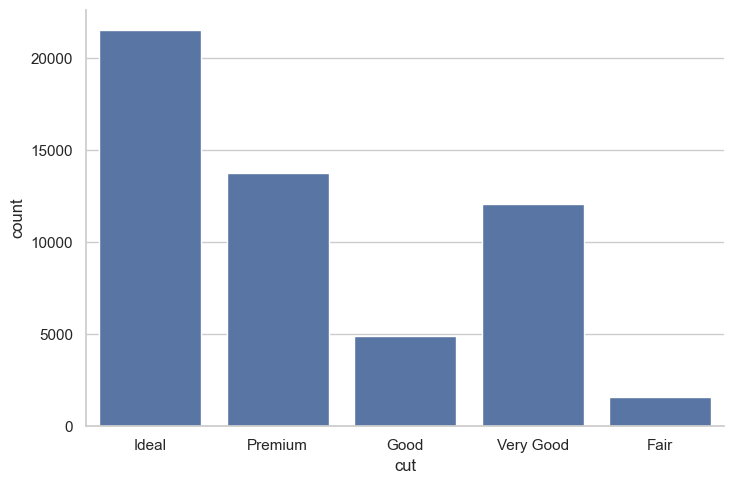
Anote la columna que pertenece a la categoría Ideal:
ideal_group = diamonds_df.loc[diamonds_df['cut']=='Ideal']
ideal_group.head()
| carat | cut | color | clarity | depth | table | price | x | y | z | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.23 | Ideal | E | SI2 | 61.5 | 55.0 | 326 | 3.95 | 3.98 | 2.43 |
| 11 | 0.23 | Ideal | J | VS1 | 62.8 | 56.0 | 340 | 3.93 | 3.90 | 2.46 |
| 13 | 0.31 | Ideal | J | SI2 | 62.2 | 54.0 | 344 | 4.35 | 4.37 | 2.71 |
| 16 | 0.30 | Ideal | I | SI2 | 62.0 | 54.0 | 348 | 4.31 | 4.34 | 2.68 |
| 39 | 0.33 | Ideal | I | SI2 | 61.8 | 55.0 | 403 | 4.49 | 4.51 | 2.78 |
Encuentre la ubicación de la coordenada \(x\) donde debe colocarse la anotación:
x = ideal_group.index.tolist()[0]
Encuentre la ubicación de la coordenada \(y\) donde debe colocarse la anotación:
y = len(ideal_group)
Imprime la ubicación de las coordenadas \(x\) e \(y\):
print(x)
print(y)
0
21551
Anota la gráfica con una nota:
sns.catplot(data=diamonds_df, x="cut", aspect=1.5, kind="count", color="b")
plt.annotate('excellent polish and symmetry ratings;\nreflects almost all the light that enters it',
xy=(x,y), xytext=(x+0.3, y+2000), arrowprops=dict(facecolor='red'));

Ahora, parece que hay muchos parámetros en la función de anotación. La documentación oficial de Matplotlib cubre todos los detalles
Ejercicio para entregar#
Trabajaremos con el conjunto de datos de 120 años de historia olímpica adquirido por Randi Griffin en Randi-Griffin y puesto a disposición en athlete_events. - Su tarea consiste en identificar los cinco deportes más importantes según el mayor número de medallas otorgadas en el año 2016, y luego realizar el siguiente análisis:
Genere un gráfico que indique el número de medallas concedidas en cada uno de los cinco principales deportes en 2016.
Trace un gráfico que represente la distribución de la edad de los ganadores de medallas en los cinco principales deportes en 2016.
Descubre qué equipos nacionales ganaron el mayor número de medallas en los cinco principales deportes en 2016.
Observe la tendencia del peso medio de los atletas masculinos y femeninos ganadores en los cinco principales deportes en 2016
Pasos principales
Descargue el conjunto de datos y formatéelo como un DataFrame de pandas.
Filtra el DataFrame para incluir solo las filas correspondientes a los ganadores de medallas de 2016.
Descubre las medallas concedidas en 2016 en cada deporte.
Enumera los cinco deportes más importantes en función del mayor número de medallas concedidas. Filtra el DataFrame una vez más para incluir solo los registros de los cinco deportes principales en 2016.
Genere un gráfico de barras con los recuentos de registros correspondientes a cada uno de los cinco deportes principales.
Generar un histograma para la característica Edad de todos los ganadores de medallas en los cinco deportes principales (2016).
Genera un gráfico de barras que indique cuántas medallas ganó el equipo de cada país en los cinco deportes principales en 2016.
Genere un gráfico de barras que indique el peso medio de los jugadores, clasificados en función del género, que ganaron en los cinco principales deportes en 2016.