
3. Modelos autorregresivos integrados de media móvil#
Introducción
El capítulo anterior cubrió técnicas de predicción basadas en suavizado exponencial, suponiendo que las series temporales tienen componentes deterministas y estocásticos. Sin embargo, estas técnicas pueden ser insuficientes cuando la suposición de ruido aleatorio completamente aleatorio no se cumple.
En tales casos, los modelos autorregresivos pueden ser útiles, ya que aprovechan la correlación entre observaciones pasadas para ajustarse inmediatamente. Estos modelos incluyen términos autorregresivos y de media móvil, y pueden ser utilizados en diferentes enfoques de predicción, como ARMA y ARIMA.
La presente sección se centra en el modelo autorregresivo y cubrirá los siguientes temas:
Media móvil (MA)
Autorregresivo (AR)
Media móvil autorregresiva (ARMA)
Media móvil integrada autorregresiva (ARIMA)
3.1. Análisis#
3.2. Modelos lineales para series de tiempo estacionarias#
En el ámbito del modelado estadístico, a menudo nos esforzamos por descubrir la genuina conexión entre entradas específicas y la variable de salida. Nuestros esfuerzos suelen dar como resultado modelos que simplemente aproximan la “verdadera” relación.
Este resultado comúnmente se origina en las decisiones estratégicas del analista para facilitar el proceso de modelado. Una suposición fundamental que a menudo simplifica los esfuerzos de modelado es la suposición de linealidad.
Filtro lineal
Un filtro lineal constituye una transformación lineal de una serie temporal, \(x_{t}\) a otra serie de tiempo \(y_{t}\),
(3.1)#\[ y_{t}=L(x_{t})=\sum_{i=-\infty}^{+\infty}\psi_{i}x_{t-i},~\text{con}~t=,\dots,-1,0,1,\dots, \]
En ese sentido, el filtro lineal puede verse como un “proceso” que convierte la entrada, \(x_{t}\), en una salida, \(y_{t}\), y esa conversión no es instantánea, sino que involucra todos (presente, pasado y futuro) los valores de la entrada en forma de suma con diferentes “pesos”, \(\psi_{i}\), en cada \(x_{t-i}\).
Además, el filtro lineal en la Ecuación (3.1) se dice que tiene las siguientes propiedades:
Invariante en el tiempo, ya que los coeficientes \(\psi_{i}\) no dependen del tiempo.
Físicamente realizable si \(\psi_{i}=0\) para \(i<0\); esto es, el output \(y_{t}\) es una función lineal de los actuales y pasados valores del input: \(y_{t}=\psi_{0}x_{t}+\psi_{1}x_{t-1}+\cdots\)
Estable si \(\sum_{i=-\infty}^{+\infty}|\psi_{i}|<\infty\).
En los filtros lineales, ciertas condiciones hacen que ciertas características, como la estacionariedad de la serie temporal de entrada, también se manifiesten en la de salida. En el capítulo previo, exploramos el concepto de estacionariedad mencionado anteriormente.
3.3. Estacionariedad#
La estacionariedad de una serie temporal está relacionada con sus propiedades estadísticas en el tiempo. Es decir, en un sentido más estricto, una serie temporal estacionaria exhibe un comportamiento estadístico similar en el tiempo, lo que a menudo se caracteriza como una distribución de probabilidad constante en el tiempo.
Sin embargo, por lo general, es satisfactorio considerar los dos primeros momentos de la serie temporal y definir la estacionariedad (o estacionariedad débil) de la siguiente manera:
El valor esperado de la serie temporal no depende del tiempo
La función de autocovarianza definida como \(\text{Cov}(y_{t} , y_{t+k})\) para cualquier rezago, \(k\) es solo una función de \(k\) y no del tiempo; es decir, \(\gamma_{y}(k) = \text{Cov}(y_{t}, y_{t+k})\).
Observación
La estacionariedad de una serie temporal se puede evaluar aproximadamente mediante la observación de su comportamiento en diferentes momentos. Si muestra un comportamiento similar en distintos instantes, se puede asumir estacionariedad y continuar con el modelado.
Además, pruebas preliminares, como el análisis de la función de autocorrelación, pueden proporcionar indicios sobre la estacionariedad. Un decaimiento lento en la autocorrelación sugiere desviaciones de la estacionariedad. También existen pruebas metodológicas más rigurosas para evaluar la estacionariedad, que se discutirán posteriormente en este capítulo.
Theorem 3.1
Dado un filtro lineal invariante en el tiempo y estable y una serie de tiempo con input \(x_{t}\) estacionario, con \(\mu_{x}=\text{E}(x_{t})\) y \(\gamma_{x}(k)=\text{Cov}(x_{t}, x_{t+k})\), la serie de tiempo
(3.2)#\[ y_{t}=L(x_{t})=\sum_{i=-\infty}^{\infty}\psi_{i}x_{t-i}, \]donde \(t=,\dots,-1,0,1,\dots,\) es también estacionaria.
El siguiente proceso lineal estable con ruido blanco \(\varepsilon_{t}\) es también estacionario
(3.3)#\[ y_{t}=\mu+\sum_{i=-\infty}^{\infty}\psi_{i}\varepsilon_{t-i}, \]y además puede reescribirse como sigue, en términos del operado backshift \(B\) como
(3.4)#\[ y_{t}=\mu+\left(\sum_{i=0}^{\infty}\psi_{i}B^{i}\right)\varepsilon_{t}=\mu+\Psi(B)\varepsilon_{t}. \]
Demostración
Calculemos valor esperado para la serie \(y_{t}\) dada en la Ecuación (3.2). Nótese que es constante respecto a \(t\)
Evaluemos ahora la autocovarianza. Nótese que esta es función de \(k\)
Por lo tanto, la serie de tiempo definida como en la Ecuación (3.2) es estacionaria. Consideremos ahora la serie de la Ecuación (3.3) y verifiquemos que es estacionaría
Dado que \(\gamma_{c}(k)=\text{Cov}(c,c)=\text{Var}(c)=0,~\forall c\in\mathbb{R}\), la autocovarianza de la Ecuación (3.3) está dada por
Nótese que la última igualdad es independiente de \(t\). Además, se usó el hecho de que: \(h=k+i-j=0\) entonces \(\gamma_{\varepsilon}(h)=\sigma^{2}\).
La Ecuación (3.3) puede reescribirse como
Observación
La Ecuación (3.4) se le conoce como el promedio móvil infinito y sirve como una clase general de modelos para cualquier serie temporal estacionaria [Wold, 1938].
Básicamente, establece que cualquier serie temporal \(y_{t}\) no determinística y estacionaria débil puede ser representada como en la Ecuación (3.3), donde \(\{\psi_{i}\}\) satisfacen \(\sum_{i=0}^{\infty}\psi_{i}^{2}<\infty\).
Una interpretación más intuitiva de este teorema es que una serie temporal estacionaria puede ser vista como la suma ponderada de las “perturbaciones” aleatorias presentes y pasadas [Yule, 1971, Bisgaard and Kulahci, 2011].
El Teorema de Wold requiere que los choques aleatorios en una media móvil infinita sean ruido blanco, que definimos como choques aleatorios no correlacionados con varianza constante. Es importante tener en cuenta que hay una diferencia entre correlación e independencia.
Indpendencia vs No Correlación
Las variables aleatorias independientes también son no correlacionadas, pero lo contrario no siempre es cierto. La independencia entre dos variables aleatorias se refiere a que su función de distribución de probabilidad conjunta es igual al producto de las distribuciones marginales. Es decir, dos variables aleatorias \(X\) e \(Y\) se dicen independientes si
Esto puede interpretarse de manera general como que si \(X\) e \(Y\) son independientes, conocer el valor de \(X\), por ejemplo, no proporciona información sobre cuál podría ser el valor de \(Y\). Para dos variables aleatorias no correlacionadas \(X\) e \(Y\), tenemos que su correlación y su covarianza son iguales a cero. Es decir,
Esto implica que si \(X\) y \(Y\) son no correlacionados, \(\text{E}[XY]=\text{E}[X]\text{E}[Y]\)
Claramente, si dos variables son independientes, estas son no correlacionadas, ya que bajo independencia se tiene que
Lo contrario no siempre es cierto. Para ilustrarlo con un ejemplo, consideremos \(X\), una variable aleatoria con una función de densidad de probabilidad simétrica alrededor de 0, es decir, \(\text{E}[X] = 0\). Supongamos que la segunda variable \(Y\) es igual a \(|X|\).
Dado que conocer el valor de \(X\) también determina el valor de \(Y\), estas dos variables claramente no son independientes. Sin embargo, se puede demostrar que
Entonces \(\text{E}[XY]=\text{E}[X]\text{E}[Y]\). Esto muestra que \(X\) e \(Y\) no están correlacionadas, pero no son independientes.
3.4. Proceso de media móvil finito \(MA(q)\)#
Proceso de media móvil de orden \(q\) (\(MA(q)\))
En los modelos de media móvil de orden finito o \(MA\), convencionalmente \(\psi_{0}\) se establece en 1 y los pesos que no se establecen en 0 se representan con la letra griega \(\theta\) con signo negativo delante. Por lo tanto, un proceso de media móvil de orden \(q\) (\(MA(q)\)) se expresa como
(3.5)#\[ y_{t}=\mu+\varepsilon_{t}-\theta_{1}\varepsilon_{t-1}-\cdots-\theta_{q}\varepsilon_{q} \]donde \(\{\varepsilon_{t}\}\) es ruido blanco.
Theorem 3.2
Dado que la Ecuación (3.5) es un caso especial de la Ecuación (3.4) con solo pesos finitos, un proceso \(MA(q)\) siempre es estacionario independientemente de los valores de los pesos. En términos del operador backshift, el proceso \(MA(q)\) está dado por
\[ y_{t}=\mu+\Phi(B)\varepsilon_{t},~\text{donde}~\Phi(B)=1-\sum_{i=1}^{q}\theta_{i}B^{i}. \]Además, dado que \(\{\varepsilon_{t}\}\) es ruido blanco, el valor esperado del proceso \(MA(q)\) es simplemente \(\text{E}(y_{t})=\mu\) y su varianza es
Similarmente, la autocovarianza en el lag \(k\) puede ser calculada como
Demostración
Nótese que utilizando el operador backshift el proceso \(MA(q)\) se escribe como
\[ y_{t}=\mu+(B^{0}-\theta_{1}B^{1}-\theta_{2}B^{2}-\cdots-\theta_{q}B^{q})\varepsilon_{t}=\mu+\left(1-\sum_{i=1}^{q}\theta_{i}B^{i}\right)\varepsilon_{t}=\mu+\Phi(B)\varepsilon_{t} \]
Dado que \(\{\varepsilon_{t}\}\) es un proceso white noise, su valor esperado está dado por
Además, su varianza está dada por
Análogamente, la autocovarianza en el lag \(k\) está dada por
\[\begin{split} \begin{align*} \gamma_{y}(k)&=\text{Cov}(y_{t}, y_{t+k})\\ &=\text{E}((\mu+\epsilon_{t}-\theta_{1}\varepsilon_{t-1}-\cdots-\theta_{q}\varepsilon_{t-q}-\mu)(\mu+\varepsilon_{t+k}-\theta_{1}\varepsilon_{t+k-1}-\cdots-\theta_{q}\varepsilon_{t+k-q}-\mu))\\ &=\text{E}((\epsilon_{t}-\theta_{1}\varepsilon_{t-1}-\cdots-\theta_{q}\varepsilon_{t-q})(\varepsilon_{t+k}-\theta_{1}\varepsilon_{t+k-1}-\cdots-\theta_{q}\varepsilon_{t+k-q})) \end{align*} \end{split}\]
Recuerde que: \(\text{E}(\varepsilon_{t})=0,~\text{Var}(\varepsilon_{t})=\text{E}(\varepsilon_{t}^{2})=\sigma^{2}\) y \(\text{Cov}(\varepsilon_{t}, \varepsilon_{t-k})=\text{E}(\varepsilon_{t}\varepsilon_{t-k})=0,~k\neq0\). Nótese además que para \(k=1\)
Análogamente, para \(k=2\) se tiene que (verifíquelo): \(\gamma_{y}(2)=\sigma^{2}(-\theta_{2}+\theta_{1}\theta_{3}+\theta_{2}\theta_{4}+\cdots+\theta_{2-q}\theta_{q})\). Por lo tanto,
Entonces la función de autocorrelación de \(MA(q)\), para \(k=1,2,\dots,q\) está dada por
Observación
Esta característica de la
ACFes muy útil para identificar el modeloMAy su orden adecuado, ya que “se corta” después del rezago \(q\). Sin embargo, en aplicaciones de la vida real, laACFmuestral, \(r(k)\), no necesariamente será igual a cero después del rezago \(q\). Se espera que se vuelva muy pequeña en valor absoluto después del rezago \(q\).Para un conjunto de datos de \(N\) observaciones, esto a menudo se prueba contra límites de \(\pm 2/\sqrt{N}\), donde \(1/\sqrt{N}\) es el valor aproximado para la desviación estándar de la
ACFpara cualquier rezago bajo la suposición de que \(\rho(k)=0\) para todos los \(k\).[Bartlett, 1946] [Brockwell and Davis, 1991] Tenga en cuenta que una fórmula más precisa para el error estándar del coeficiente de autocorrelación muestral \(k\) es proporcionada por (
bonus)\[ \text{s.e.}~(r(k))=N^{-1/2}\left(1+2\sum_{j=1}^{k-1}r(j)^{\star 2}\right)^{1/2} \]donde
\[\begin{split} r(j)^{\star}=\begin{cases}r(j) & \text{para}~\rho(j)\neq 0\\0 & \text{para}~\rho(j)=0.\end{cases} \end{split}\]
Un caso especial sería datos de ruido blanco, para los cuales \(\rho(j) = 0\) para todos los valores de \(j\). Por lo tanto, para un proceso de ruido blanco (es decir, sin autocorrelación), un intervalo razonable para los coeficientes de autocorrelación muestral sería \(\pm 2/N\) y cualquier indicación contraria puede considerarse como evidencia de dependencia serial en el proceso.
3.5. El Proceso de Media Móvil de Primer Orden, \(MA(1)\)#
Media Móvil de Primer Orden \(MA(1)\)
El modelo \(MA\) de orden finito más simple se obtiene cuando \(q = 1\) en la Ecuación (3.5)
Para el modelo de media móvil de primer orden o \(MA(1)\), tenemos la función de autocovarianza como
De manera similar, tenemos la función de autocorrelación como
De la Ecuación (3.8), podemos ver que la autocorrelación del primer rezago en \(MA(1)\) está limitada a
\[ |\rho_{y}(1)|=\frac{|\theta_{1}|}{1+\theta_{1}^{2}}\leq\frac{1}{2} \]y la función de autocorrelación se reduce a cero después del primer rezago.
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
import statsmodels.tsa.api as smtsa
import statsmodels.tsa.arima.model as arima_model
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['text.usetex'] = True
sns.set_style("darkgrid")
Show code cell source
def plotds(xt, nlag=30, fig_size=(12, 10)):
if not isinstance(xt, pd.Series):
xt = pd.Series(xt)
plt.figure(figsize=fig_size)
layout = (2, 2)
ax_xt = plt.subplot2grid(layout, (0, 0), colspan=2)
ax_acf = plt.subplot2grid(layout, (1, 0))
ax_pacf = plt.subplot2grid(layout, (1, 1))
xt.plot(ax=ax_xt)
ax_xt.set_title('Time Series')
plot_acf(xt, lags=50, ax=ax_acf)
plot_pacf(xt, lags=50, ax=ax_pacf)
plt.tight_layout()
return None
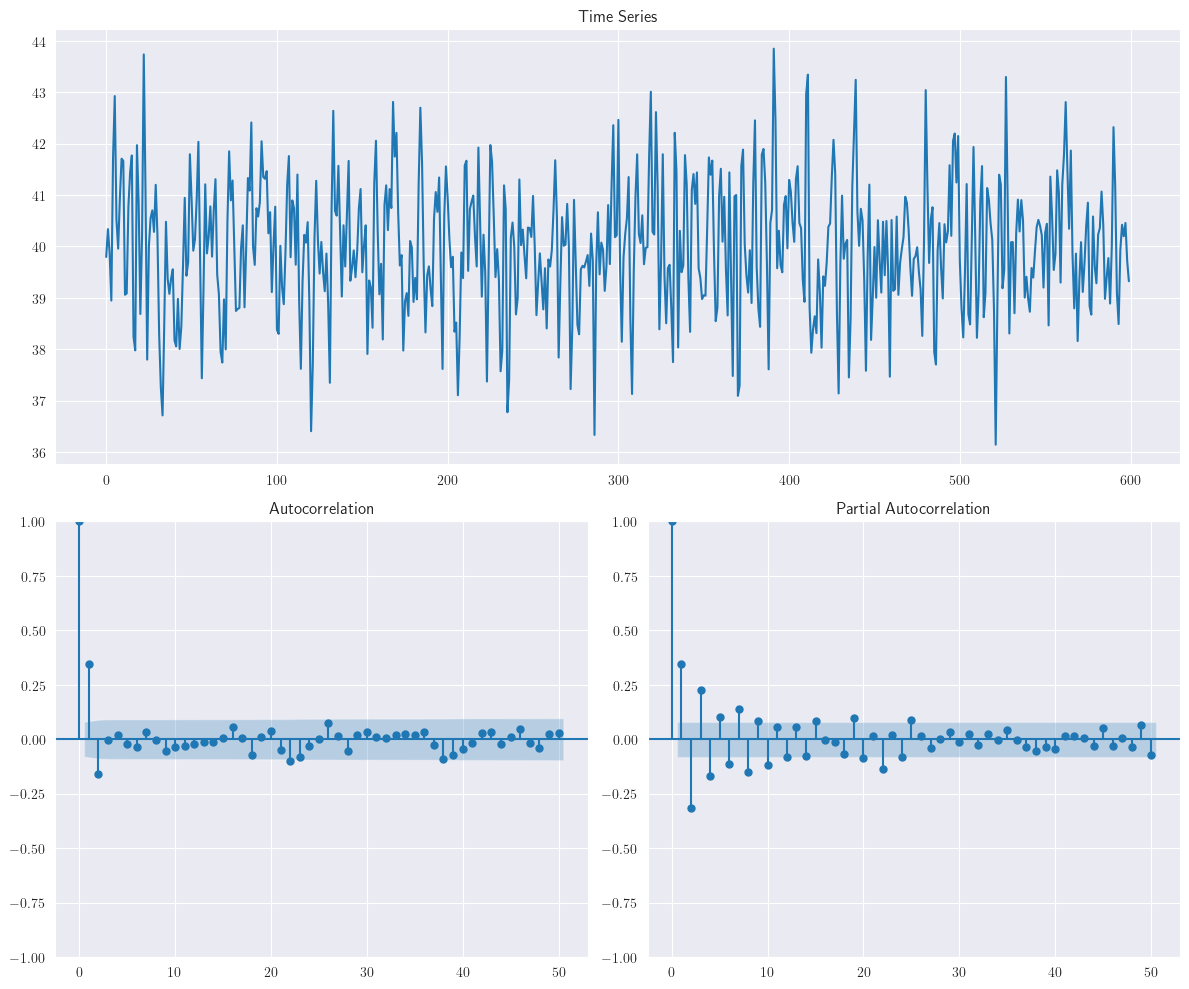
El siguiente gráfico corresponden al proceso \(MA(1)\): \(y_{t}=40+\varepsilon_{t}+0.8\varepsilon_{t-1}\). En este ejemplo se ha utilizado la librería arma_generate_sample. Debe instalarla previamente usando
pip
Show code cell source
np.random.seed(12345)
n=600
arparams = np.array([0]) # phi1, phi2,...
maparams = np.array([0.8]) # theta1, theta2,...
intercept = 40
ar = np.r_[1, -arparams] # add zero-lag and negative
ma = np.r_[1, maparams] # add zero-lag
ar1_data = intercept + smtsa.arma_generate_sample(ar=ar, ma=ma, nsample=n)
plotds(ar1_data)
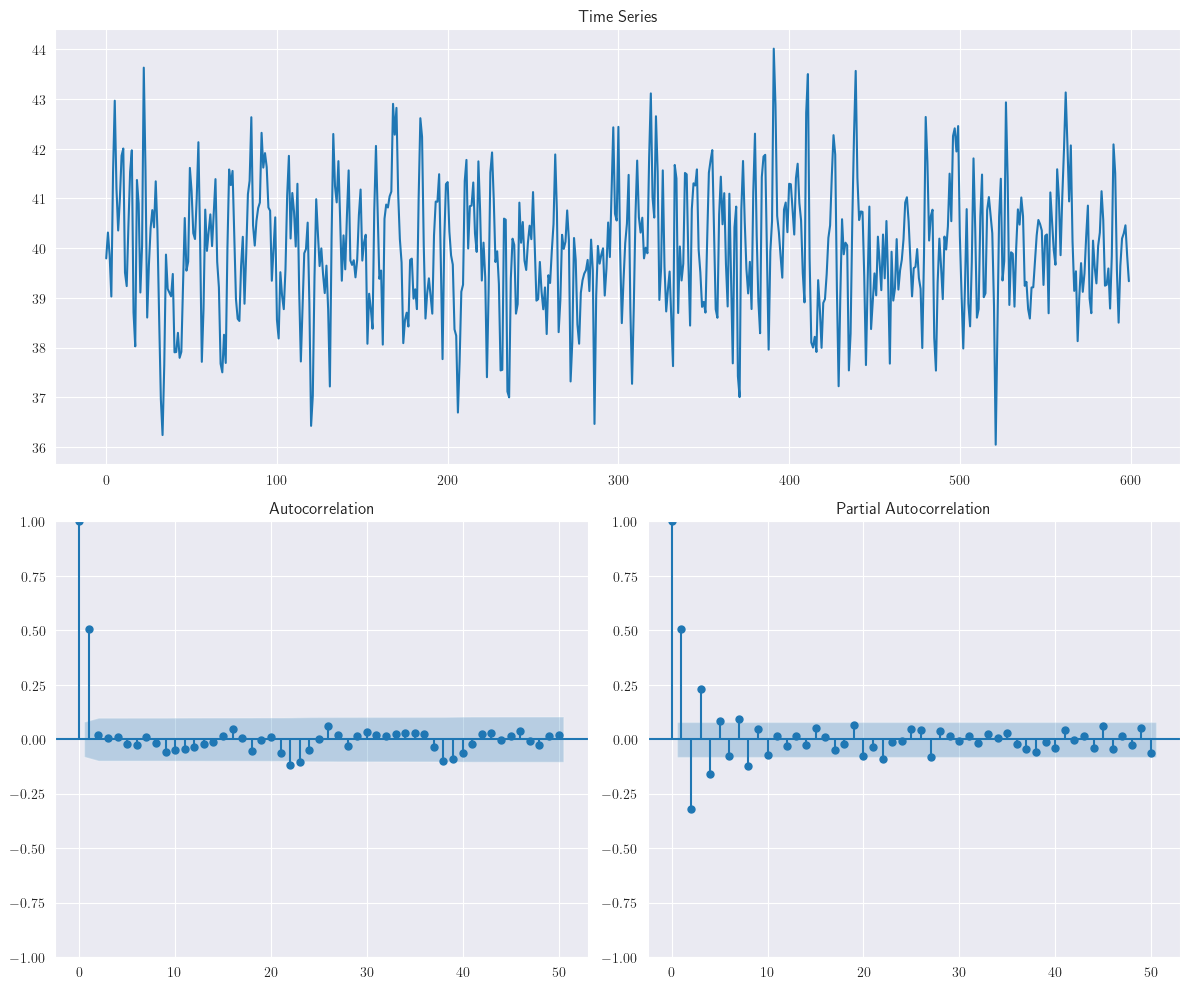
Analogamente, el siguiente gráfico corresponden al proceso \(MA(1)\): \(y_{t}=40+\varepsilon_{t}-0.8\varepsilon_{t-1}\). Podemos observar que las observaciones tienden a oscilar sucesivamente. Esto sugiere una autocorrelación negativa, como lo confirma el gráfico de la
ACFde la muestra.
Show code cell source
np.random.seed(12345)
n=600
arparams = np.array([0]) # phi1, phi2,...
maparams = np.array([-0.8]) # theta1, theta2,...
intercept = 40
ar = np.r_[1, -arparams] # add zero-lag and negative
ma = np.r_[1, maparams] # add zero-lag
ar1_data = intercept + smtsa.arma_generate_sample(ar=ar, ma=ma, nsample=n)
plotds(ar1_data)
3.6. El Proceso de Media Móvil de Segundo Orden, \(MA(2)\)#
Media Móvil de Segundo Orden \(MA(2)\)
Otro proceso de media móvil de orden finito útil es \(MA(2)\), dado como
Las funciones de autocovarianza y autocorrelación para el modelo \(MA(2)\) se expresan como
Además, la función de autocorrelación está dada por
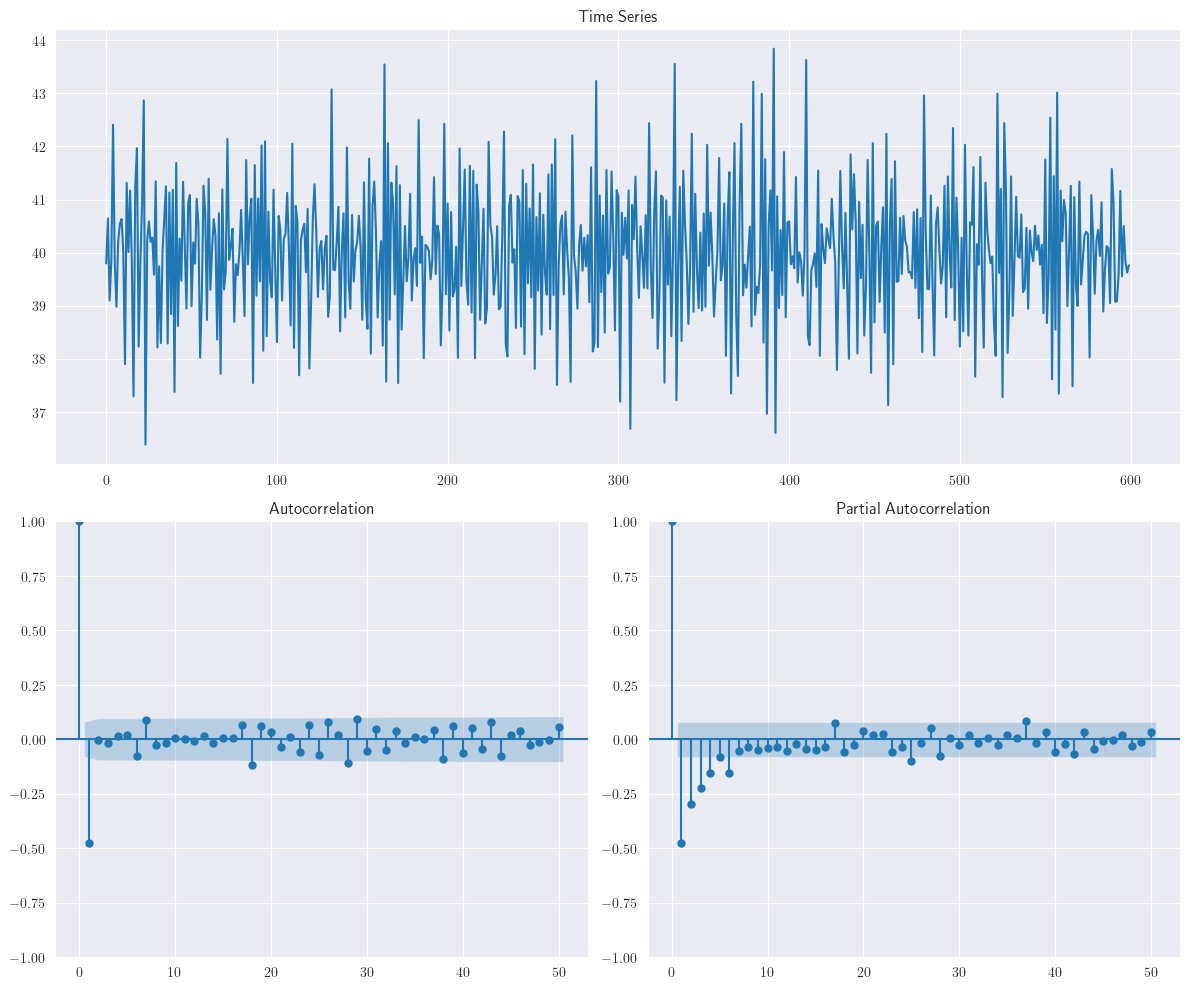
El siguiente gráfico muestra la serie temporal y la función de autocorrelación para la realización del modelo \(MA(2)\): \(y_{t}=40+\varepsilon_{t}+0.7\varepsilon_{t-1}-0.28\varepsilon_{t-2}\)
Show code cell source
np.random.seed(12345)
n=600
arparams = np.array([0]) # phi1, phi2,...
maparams = np.array([0.7, -0.28]) # theta1, theta2,...
intercept = 40
ar = np.r_[1, -arparams] # add zero-lag and negative
ma = np.r_[1, maparams] # add zero-lag
ar1_data = intercept + smtsa.arma_generate_sample(ar=ar, ma=ma, nsample=n)
plotds(ar1_data)
Observe que la función de autocorrelación muestral se anula después del rezago 2.
Observación
El teorema de descomposición de Wold, es poderoso, pero no ayuda mucho en nuestros esfuerzos de modelado y pronóstico, ya que requiere implícitamente la estimación de infinitos pesos, \(\psi_{i}\). Discutiremos un caso especial de esta descomposición, asumiendo que el proceso de series temporales puede ser adecuadamente modelado al estimar solo un número finito de pesos y establecer el resto en cero.
Otra interpretación de los procesos
MAde orden finito es que, en cualquier momento, solo un número finito de perturbaciones pasadas “contribuyen” al valor actual de la serie temporal, y que la ventana temporal de los contribuyentes “se mueve”, haciendo que la perturbación “más antigua” sea obsoleta para la siguiente observación.
3.7. Procesos autorregresivos de orden finito#
Algunos procesos pueden tener las dinámicas intrínsecas mencionadas en la anterior observación, pero para otros, es posible que necesitemos considerar las contribuciones “persistentes” de las perturbaciones que ocurrieron en el pasado. Una solución a este problema son los modelos autorregresivos, en los cuales se asume que los infinitos pesos siguen un patrón distintivo y pueden ser representados con éxito con solo unos pocos parámetros. Ahora consideraremos algunos casos especiales de procesos autorregresivos.
3.8. Proceso autorregresivo de primer orden, \(AR(1)\)#
Theorem 3.3
Considere el siguiente proceso lineal estable, con serie de tiempo \({\varepsilon}_{t}\), ruido blanco,
\[ y_{t}=\mu+\sum_{i=0}^{\infty}\psi_{i}\varepsilon_{t-i}. \]Además, para garantizar decrecimiento exponencial, fije \(\psi_{i}=\phi^{i}\), donde \(|\phi|<1\).
Demuestre que el proceso autorregresivo de primer orden, está dado por
(3.9)#\[ y_{t}=\delta+\phi y_{t-1}+\varepsilon_{t}. \]Además, demuestre que si \(|\phi|>1\), existe una solución estacionaria para el proceso \(AR(1)\); sin embargo, esta solución es no-causal o no-convergente (requiere conocimiento sobre el futuro para hacer pronósticos sobre él).
Pruebe que, para el proceso \(AR(1)\), el valor esperado, covarianza y autocorrelación, están dados por
(3.10)#\[\begin{split} \begin{align*} \text{E}(y_{t}) &= \frac{\delta}{1-\phi}\\ \gamma(k) &= \sigma^{2}\phi^{k}\frac{1}{1-\phi^{2}},~\text{para}~k=0,1,2,\dots\\ \rho(k) &= \phi^{k},~\text{para}~k=0,1,2,\dots \end{align*} \end{split}\]
Demostración
Primero, volvamos a considerar la serie temporal dada en la Ecuación (3.3) asociada con el proceso lineal estable
\[ y_{t}=\mu+\sum_{i=0}^{\infty}\psi_{i}\varepsilon_{t-i}=\mu+\sum_{i=0}^{\infty}\psi_{i}B^{i}\varepsilon_{t}=\mu+\Psi(B)\varepsilon_{t}, \]donde \(\Psi(B)=\sum_{i=0}^{\infty}\psi_{i}B^{i}\).
Una manera de modelar esta serie temporal es asumir que las contribuciones de las perturbaciones que ocurrieron hace mucho tiempo deberían ser pequeñas en comparación con las perturbaciones más recientes experimentadas por el proceso. Dado que las perturbaciones son variables aleatorias independientes e idénticamente distribuidas, podemos simplemente asumir un conjunto de infinitas ponderaciones en magnitudes descendentes que reflejen la disminución en las contribuciones de las perturbaciones pasadas.
Un conjunto simple e intuitivo de estas ponderaciones pueden seguir un patrón de decaimiento exponencial. Para ello, estableceremos \(\psi_{i}=\phi^{i}\), donde \(|\phi|<1\) para garantizar el “decaimiento” exponencial. Con esta notación, las ponderaciones en las perturbaciones, comenzando desde la perturbación actual y retrocediendo en el tiempo, serán \(1, \phi, \phi^{2}, \phi^{3},\dots\).
Por lo tanto, la Ecuación (3.3) puede escribirse como:
De la Ecuación (3.11) obtenemos
(3.12)#\[ y_{t-1}=\mu+\textcolor{blue}{\varepsilon_{t-1}+\phi\varepsilon_{t-2}+\phi^{2}\varepsilon_{t-3}+\cdots} \]
Usando la Ecuación (3.11) y Ecuación (3.12)
(3.13)#\[\begin{split} \begin{align*} y_{t} &= \mu+\varepsilon_{t}+\phi\varepsilon_{t-1}+\phi^{2}\varepsilon_{t-2}+\cdots\\ &= \mu+\varepsilon_{t}+\phi(\textcolor{blue}{\varepsilon_{t-1}+\phi\varepsilon_{t-2}+\cdots})\\ &= \mu+\varepsilon_{t}+\phi(y_{t-1}-\mu)\\ &= \textcolor{red}{\mu-\phi\mu}+\phi y_{t-1}+\varepsilon_{t}\\ &= \textcolor{red}{\delta}+\phi y_{t-1}+\varepsilon_{t}, \end{align*} \end{split}\]donde \(\delta=(1-\phi)\mu\).
El proceso de la Ecuación (3.13) es llamado proceso autorregresivo de primer orden, \(AR(1)\), dado que Ecuación (3.13) puede verse como una regresión de \(y_{t}\) sobre \(y_{t-1}\), es por esto que se usa el término autorregresivo.
Observación
El supuesto de \(|\phi|<1\) conduce a ponderaciones que decaen exponencialmente en el tiempo y también garantiza que \(\sum_{i=0}^{\infty}|\psi_{i}|<\infty\). Esto significa que un proceso \(AR(1)\) es estacionario si \(|\phi|<1\).
Para \(|\phi|>1\), las perturbaciones pasadas obtendrán ponderaciones exponencialmente crecientes a medida que pasa el tiempo y la serie temporal resultante será explosiva. Este tipo de procesos son de poco interés práctico y, por lo tanto, solo consideran casos donde \(|\phi|=1\) y \(|\phi|<1\).
La solución en Ecuación (3.11) de hecho no converge para \(|\phi|>1\). Sin embargo, podemos reescribir el proceso \(AR(1)\) para \(y_{t+1}\) como \(y_{t+1}=\delta+\phi y_{t}+\varepsilon_{t+1}\). Entonces, por medio de operaciones de despeje en esta última igualdad, obtenemos
(3.14)#\[\begin{split} \begin{align*} y_{t} &= -\phi^{-1}\delta+\phi^{-1}y_{t+1}-\phi^{-1}\varepsilon_{t+1}\\ &=-\phi^{-1}\delta+\phi^{-1}(-\phi^{-1}\delta+\phi^{-1}y_{t+2}-\phi^{-1}\varepsilon_{t+2})-\phi^{-1}\varepsilon_{t+1}\\ &= -\phi^{-1}\delta-\phi^{-2}\delta+\phi^{-2}y_{t+2}-\phi^{-2}\varepsilon_{t+2}-\phi^{-1}\varepsilon_{t+1}\\ &= -(\phi^{-1}+\phi^{-2})\delta+\phi^{-2}y_{t+2}-\phi^{-1}\varepsilon_{t+1}-\phi^{-2}\varepsilon_{t+2}\\ &\hspace{2mm}\vdots\\ &=-\delta\sum_{i=1}^{\infty}\phi^{-i}-\sum_{i=1}^{\infty}\phi^{-i}\varepsilon_{t+i}. \end{align*} \end{split}\]
Nótese que para \(|\phi|>1\) se tiene que \(|\phi^{-i}|<1\). Por lo tanto, la solución vía \(AR(1)\) es estacionaria para \(|\phi|>1\). Sin embargo, la solución dada por la Ecuación (3.14) involucra futuras perturbaciones, las cuales deseamos predecir, lo cual es impráctico. Este tipo de modelos son conocidos como, modelos no-causales.
Calculemos ahora, la media del proceso estacionario \(AR(1)\). Nótese que
(3.15)#\[ \text{E}(y_{t})=\text{E}(\delta+\phi y_{t-1}+\varepsilon_{t})=\delta+\phi\text{E}(y_{t-1})+\text{E}(\varepsilon_{t})=\delta+\phi\text{E}(y_{t-1}) \]
Dado que el proceso \(AR(1)\) es estacionario \(\text{E}(y_{t})=\text{E}(y_{t-1})\). Entonces, despejando en la Ecuación (3.15), obtenemos que la media del proceso \(AR(1)\) está dada por
\[ \text{E}(y_{t})=\frac{\delta}{1-\phi}. \]
Por otro lado, para calcular autocovarianza del proceso \(AR(1)\), nótese que, gracias a su estacionariedad se tiene que
\[ \gamma(0)=\text{Var}(y_{t})=\text{Var}(\delta+\phi y_{t-1}+\varepsilon_{t})=\phi^{2}\text{Var}(y_{t-1})+\sigma^{2}=\phi^{2}\gamma(0)+\sigma^{2} \]
Por lo tanto, \(\gamma(0)=\sigma^{2}/(1-\phi^{2})\). Analicemos la covarianza \(\gamma(k)\), para algunos pocos valores de rezagos, usando sus propiedades (ver Covariance), para realizar un razonamiento por inducción. Nótese que para \(k=1, 2,\dots,k\), dado que el ruido blanco \(\varepsilon_{t+1}\) iid es independiente de \(y_{t}\) (\(y_{t}\) depende de \(\varepsilon_{t}\)), se tiene que
Además, la función de autocorrelación para el proceso \(AR(1)\) está dada por
Por lo tanto, la función de autocorrelación para un proceso \(AR(1)\) tiene forma de decaimiento exponencial. Una realización del siguiente modelo \(AR(1)\),
\[ y_{t}=8+0.8y_{t-1}+\varepsilon_{t} \]se muestra en la siguiente figura:
Show code cell source
np.random.seed(12345)
n=600
arparams = np.array([0.8]) # phi1, phi2,...
maparams = np.array([0]) # theta1, theta2,...
intercept = 8
ar = np.r_[1, -arparams] # add zero-lag and negative
ma = np.r_[1, maparams] # add zero-lag
ar1_data = intercept + smtsa.arma_generate_sample(ar=ar, ma=ma, nsample=n)
plotds(ar1_data)
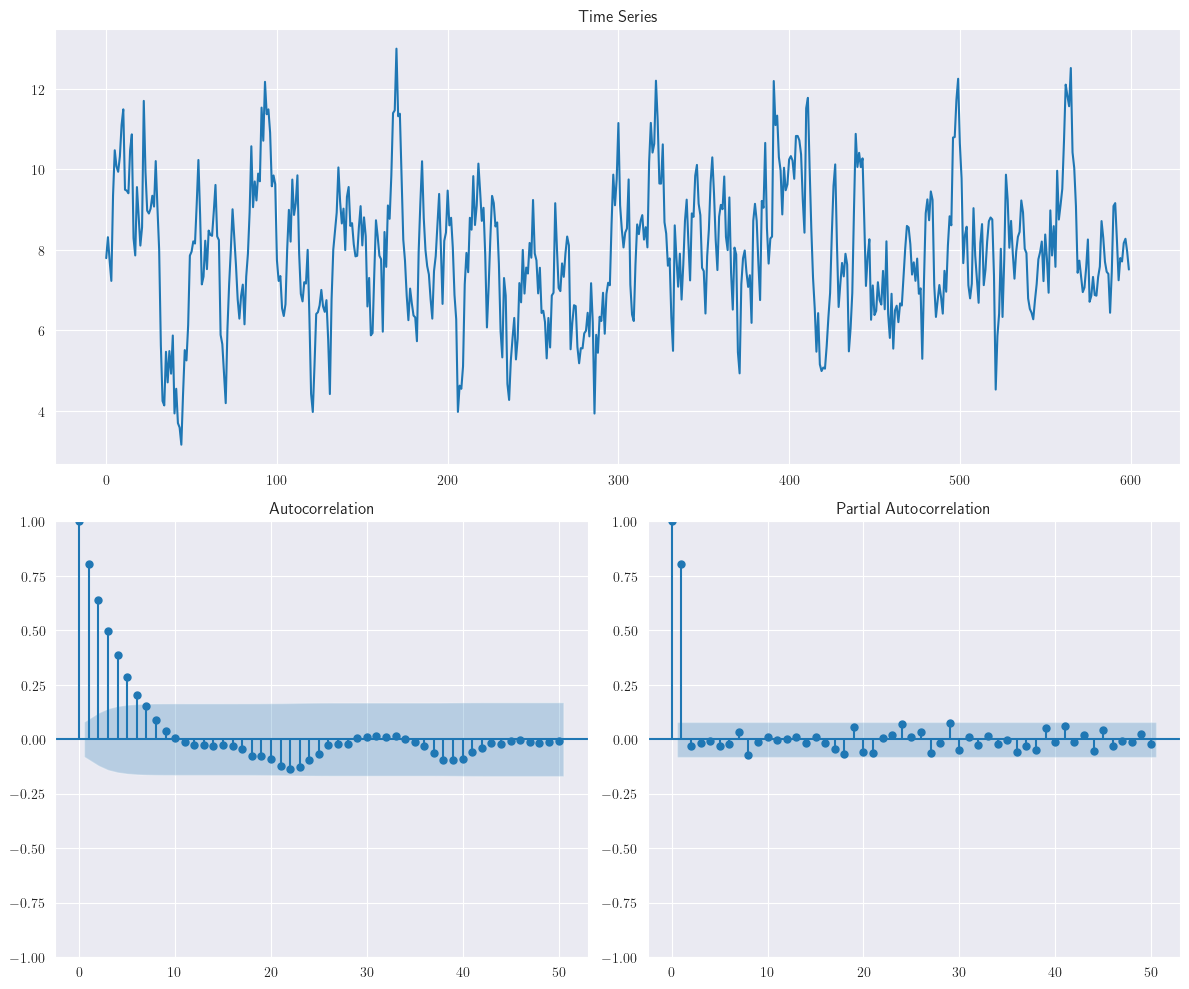
Al igual que en el modelo \(MA(1)\) con \(\theta = −0.8\), podemos observar algunos cortos períodos durante los cuales las observaciones tienden a moverse en dirección ascendente o descendente. A diferencia del modelo \(MA(1)\), sin embargo, la duración de estos períodos tiende a ser más larga y la tendencia tiende a persistir. Esto también puede observarse en el gráfico de la función de autocorrelación (
ACF) de la muestra.
Show code cell source
np.random.seed(12345)
n=600
arparams = np.array([-0.8]) # phi1, phi2,...
maparams = np.array([0]) # theta1, theta2,...
intercept = 8
ar = np.r_[1, -arparams] # add zero-lag and negative
ma = np.r_[1, maparams] # add zero-lag
ar1_data = intercept + smtsa.arma_generate_sample(ar=ar, ma=ma, nsample=n)
plotds(ar1_data)
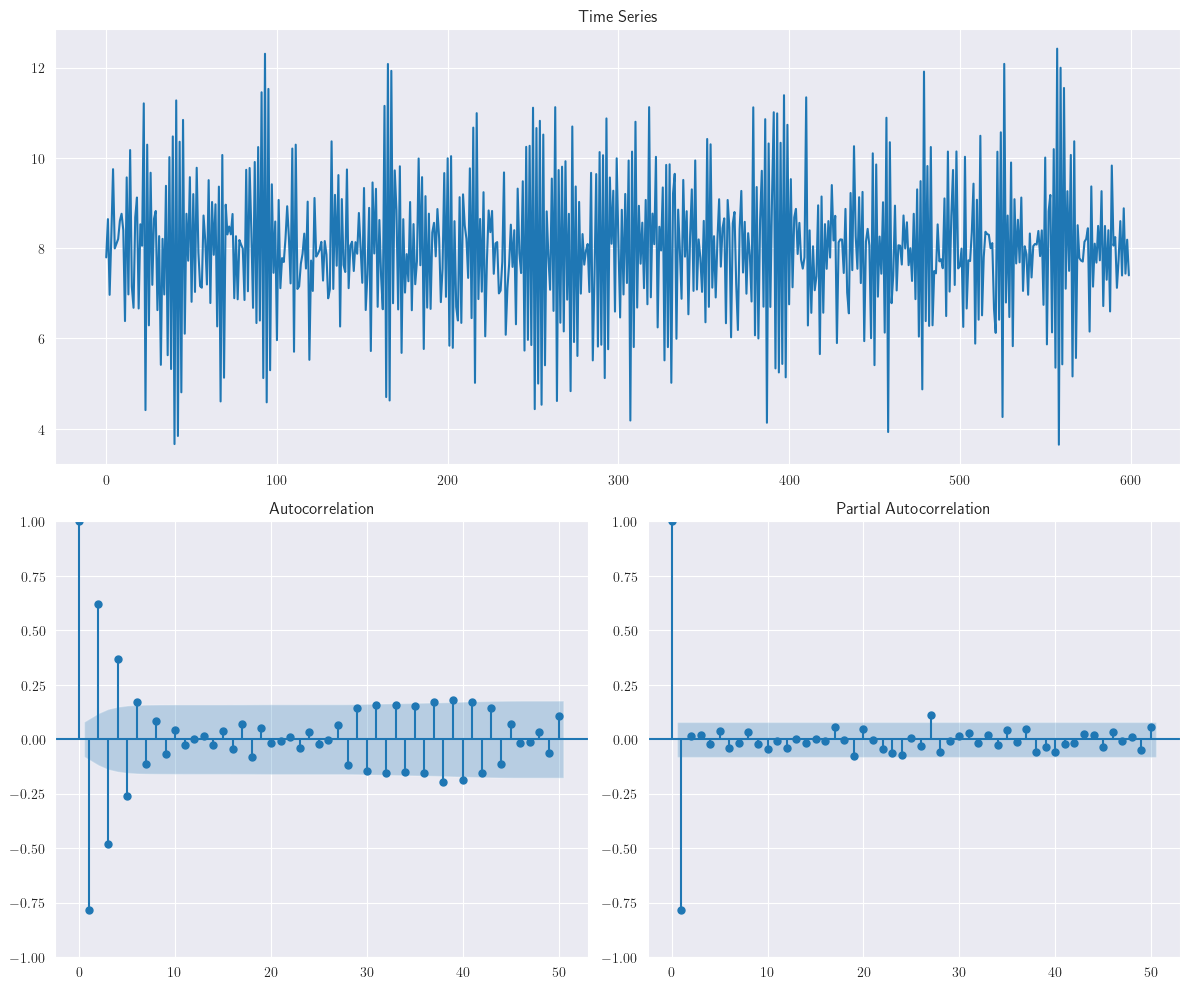
La figura anterior muestra una realización del modelo \(AR(1)\) \(y_{t} = 8 − 0.8y_{t-1} + \varepsilon_{t}\). Observamos que en lugar de secuencias persistentes, las observaciones exhiben movimientos volatiles hacia arriba/abajo debido al valor negativo de \(\Phi\).
3.9. Proceso autorregresivo de segundo orden, \(AR(2)\)#
Theorem 3.4
La clara extensión de la Ecuación (3.9) incluye la observación \(y_{t-2}\) y define el proceso autorregresivo de segundo orden \(AR(2)\) como
Demuestre que el proceso \(AR(2)\) es estacionario si los parámetros \(\phi_{1}, \phi_{2}\) satisfacen
Además,
Más aún, las raíces de las ecuaciones de Yule-Walker muestran combinación de dos términos: decaimiento exponencial y forma sinusoidal amortiguada.
Demostración
Nótese que la Ecuación (3.16) puede reescribirse como
\[ y_{t}=\delta+\phi_{1}By_{t}+\phi_{2}B^{2}y_{t}+\varepsilon_{t}\Rightarrow(1-\phi_{1}B-\phi_{2}B^{2})y_{t}=\delta+\varepsilon_{t}\Rightarrow\Phi(B)y_{t}=\delta+\varepsilon_{t}. \]
Aplicando el operador inverso \(\Phi(B)^{-1}\) en ambos miembros de la igualdad se tiene
Dado que \(\Psi(B)=\Phi(B)^{-1}\) entonces \(\Phi(B)\Psi(B)=1\), esto es
\[\begin{split} \begin{align*} (1-\phi_{1}B-\phi_{2}B^{2})(\psi_{0}+\psi_{1}B+\psi_{2}B^{2}+\cdots) &= 1\Leftrightarrow\\ \psi_{0}+(\psi_{1}-\phi_{1}\psi_{0})B+(\psi_{2}-\phi_{1}\psi_{1}-\phi_{2}\psi_{0})B^{2}+\cdots+(\psi_{j}-\phi_{1}\psi_{j-1}-\phi_{2}\psi_{j-2})B^{j} &= 1\Leftrightarrow \end{align*} \end{split}\]
Ecuación en diferencias lineal homogénea de orden \(n\)
Una ecuación en diferencias lineal homogénea de orden \(n\) está dada por
(3.20)#\[ y(t+n)+a_{1}y(t+n-1)+\cdots+a_{n-1}y(t+1)+a_{n}y(t)=0,~\text{con}~a_{i}\in\mathbb{R}, \]\(\forall i~\text{y}~a_{n}\neq0\).
A la siguiente ecuación
(3.21)#\[ P(r)=m^{n}+a_{1}m^{n-1}+a_{2}m^{n-2}+\cdots+a_{n-1}m+a_{n}=0, \]la llamamos ecuación característica asociada a la ecuación en diferencias lineal homogénea de orden \(n\) (3.20).
Para encontrar soluciones homogéneas no triviales, asumimos soluciones de la forma \(\psi_{j}=Am^{j}\), \(~A, m\in\mathbb{R}\setminus\{0\}\). Entonces la ecuación característica asociada a la Ecuación (3.19) tomaría la forma
\[ \psi_{j}-\phi_{1}\psi_{j-1}-\phi_{2}\psi_{j-2}=Am^{j}-\phi_{1}Am^{j-1}-\phi_{2}Am^{j-2}=0\Leftrightarrow m^{2}-\phi_{1}m-\phi_{2}=0. \]
Las raíces son obtenidas por medio del uso de la fórmula general. Estudiaremos tres casos para sus posibles raíces
Nótese que si \(|m_{i}|<1,~i=1,2\) entonces \(\sum_{i=0}^{\infty}|\psi_{i}|<\infty\). Por lo tanto, el modelo sería causal estacionario. Además, si las raices de la Ecuación (3.22) son complejas, esto es, de la forma \(a+bi,~i=\sqrt{-1}\), la estacionariedad se tendría si
\[ |a+bi|=\sqrt{a^{2}+b^{2}}<1 \]
Además, bajo estas condiciones \(\{y_{t}\}_{t}\) tendría una representación como \(MA\) infinito (ver Ecuación (3.4)). Dado que se tiene estacionariedad si \(|m_{i}|<1,~i=1,2\), entonces
\[ -1<\frac{\phi_{1}\pm\sqrt{\phi_{1}^{2}+4\phi_{2}}}{2}<1\Leftrightarrow-2<\phi_{1}\pm\sqrt{\phi_{1}^{2}+4\phi_{2}}<2. \]
Analicemos el valor más grande de \(m_{i},~i=1,2\), el cual es acotado por \(\phi_{1}+\sqrt{\phi_{1}^{2}+4\phi_{2}}<2\)
(3.23)#\[\begin{split} \begin{align*} \phi_{1}+\sqrt{\phi_{1}^{2}+4\phi_{2}}<2 &\Rightarrow \sqrt{\phi_{1}^{2}+4\phi_{2}}<2-\phi_{1}\\ &\Rightarrow\phi_{1}^{2}+4\phi_{2}<(2-\phi_{1})^{2}\\[1mm] &\Rightarrow\phi_{1}^{2}+4\phi_{2}<4-4\phi_{1}+\phi_{1}^{2}\\[2mm] &\Rightarrow\textcolor{red}{\phi_{1}+\phi_{2}<1}. \end{align*} \end{split}\]
Usando la otra desigualdad \(-2<\phi_{1}\pm\sqrt{\phi_{1}^{2}+4\phi_{2}}\), se tiene que (
verifíquelo)(3.24)#\[ \textcolor{red}{\phi_{2}-\phi_{1}<1}. \]
Nótese que si \(m_{i}\) es una raíz compleja, entonces: \(\phi_{1}^{2}+4\phi_{2}<0\Leftrightarrow\phi_{1}^{2}<-4\phi_{2}\), y además
\[ m_{1,2}=\frac{\phi_{1}}{2}\pm\frac{\sqrt{-\left(\phi_{1}^{2}+4\phi_{2}\right)}}{2}i. \]
Por lo tanto, el módulo complejo está dado por
Entonces, se tiene estabilidad si \(|m_{i}|<1\), esto es, si \(-\phi_{2}<1\Rightarrow\phi_{2}>-1\). Las Ecuaciones (3.23)-(3.24) entregan vía método de eliminación que \(\phi_{2}<1\), por lo tanto, \(\textcolor{red}{|\phi_{2}|<1}\). De esta forma, las condiciones de estacionariedad son las siguientes:
\[\begin{split} \begin{align*} \phi_{1}+\phi_{2} &< 1\\ \phi_{2}-\phi_{1} &< 1\\ |\phi_{2}| &< 1 \end{align*} \end{split}\]
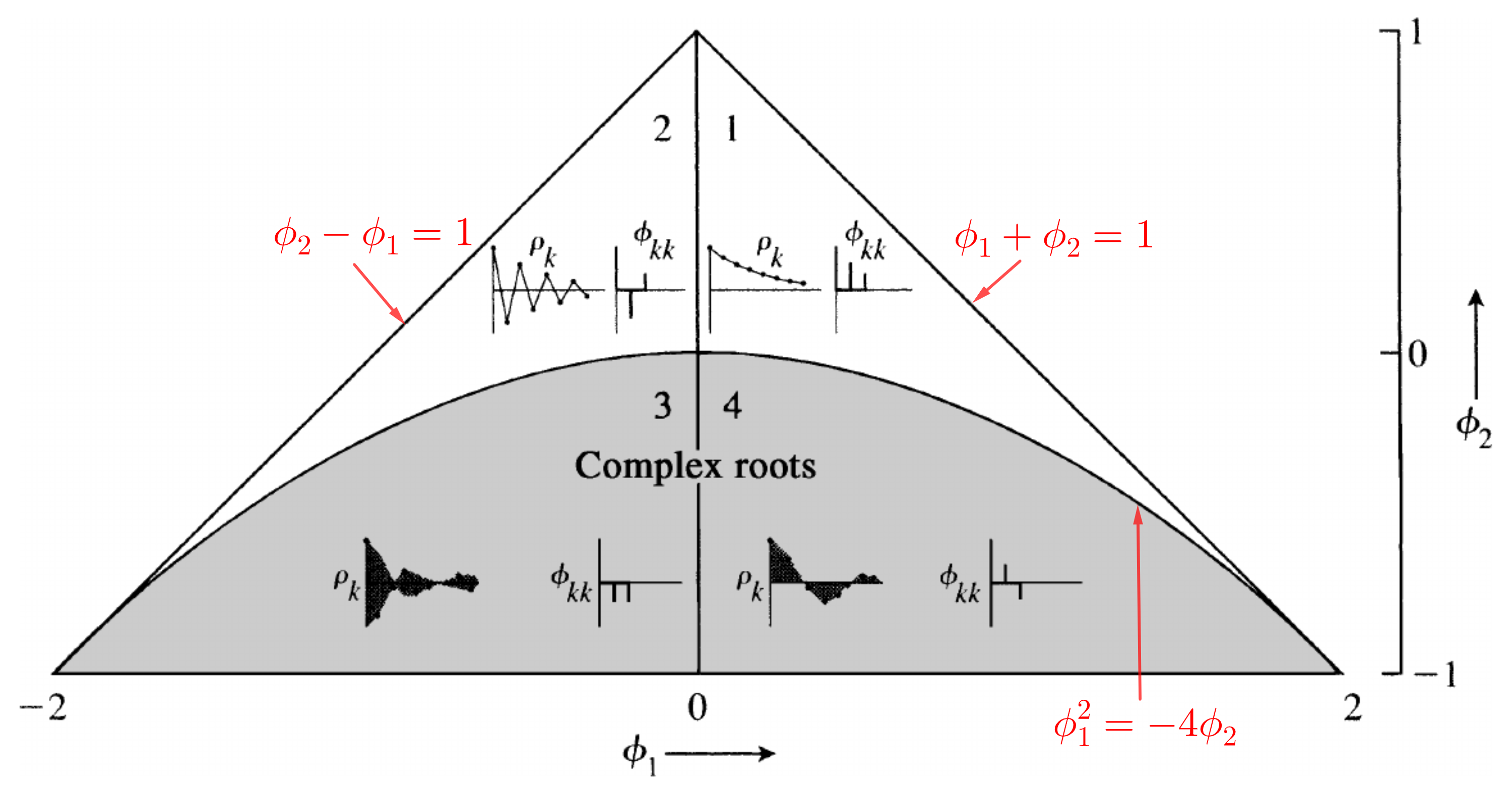
Fig. 3.1 Funciones típicas de autocorrelación y autocorrelación parcial \(\rho_{k}\) y \(\phi_{kk}\) para varios modelos \(AR(2)\) estacionarios. (Fuente: [Stralkowski, 1968]).#
Procedemos a calcular ahora, media y autocovarianza. Si se satisface la Ecuación (3.17), el proceso \(AR(2)\) es estacionario, y, por lo tanto,
Nótese que si \(1-\phi_{1}-\phi_{2}=0\) entonces \(m=1\) es solución de \(m^{2}-\phi_{1}m-\phi_{2}=0\), y, por lo tanto, la serie se considera no estacionaria. Calculemos ahora la autocovarianza
Entonces, si \(k=0\), se tiene que \(\gamma(0)=\phi_{1}\gamma(1)+\phi_{2}\gamma(2)+\sigma^{2}\) (
¿por qué?) y además(3.25)#\[ \gamma(k)=\phi_{1}\gamma(k-1)+\phi_{2}\gamma(k-2). \]
Las Ecuaciones en (3.25) se llaman las Ecuaciones de Yule-Walker para \(\gamma(k)\). De manera similar, podemos obtener la función de autocorrelación al dividir la Ecuación (3.25) por \(\gamma(0)\):
(3.26)#\[\begin{split} \begin{align*} \rho(k) &= \frac{\gamma(k)}{\gamma(0)}\\ &= \phi_{1}\frac{\gamma(k-1)}{\gamma(0)}+\phi_{2}\frac{\gamma(k-2)}{\gamma(0)}\\[2mm] &= \phi_{1}\rho(k-1)+\phi_{2}\rho(k-2),~k=1,2,\dots \end{align*} \end{split}\]
Las Ecuaciones de Yule-Walker para \(\rho(k)\) en Ecuación (3.26) pueden ser resueltas de manera iterativa
Considerando \(\rho(j)=Am^{j},~A, m\in\mathbb{R}\setminus\{0\}\) entonces, la Ecuación Característica asociada a la Ecuación (3.27) puede ser escrita como
\[ Am^{j}=\phi_{1}Am^{j-1}+\phi_{2}Am^{j-2}\Leftrightarrow m^{2}-\phi_{1}m-\phi_{2}=0. \]
Ecuación característica
Si \(m_{0}\) es solución de la ecuación característica (3.21), entonces \(y_{t}=Am_{0}^{t}\) es solución de (3.20)
Al resolver la ecuación característica pueden ocurrir los siguientes casos:
La ecuación característica (3.21) tiene todas sus raíces reales y simples \(m_{1}, m_{2},\dots, m_{n}\), entonces
\[ y_{h}(t)=c_{1}m_{1}^{t}+c_{2}m_{2}^{t}+\cdots+c_{n}m_{n}^{t} \]La ecuación característica (3.21) tiene todas sus raíces reales: \(m_{1}\) con multiplicidad, \(k\) y \(m_{k+1}, \dots, m_{n}\) simples, entonces
\[ y_{h}(t)=c_{1}m_{1}^{t}+c_{2}tm_{1}^{t}+\cdots+c_{k}t^{k-1}m_{1}^{t}+c_{k+1}t^{k}m_{k+1}^{t}+\cdots+c_{n}m_{n}^{t}. \]La ecuación característica (3.21) tiene raíces complejas simples. Si \(m_{1,2}=\alpha\pm\beta i\), son raices complejas conjugadas, siendo \(\rho=\sqrt{\alpha^{2}+\beta^{2}}\) el módulo y \(\theta=\textsf{arctan}(\beta/\alpha)\) el argumento correspondiente, entonces la solución asociada a las raíces \(m_{1}, m_{2}\) es
\[ y_{h}(t)=\rho^{t}(A\cos(\theta t)+B\sin(\theta t)). \]
Si \(m_{1}, m_{2}\) son raíces reales distintas, tenemos que
\[ \rho(k)=c_{1}m_{1}^{k}+c_{2}m_{2}^{k},~k=1,2,\dots \]donde \(c_{1}, c_{2}\) son constantes y pueden ser obtenidas a partir de \(\rho(0), \rho(1)\). Dado que \(|m_{1,2}|<1\) por estacionariedad, la autocorrelación es una combinación de términos de decrecimiento exponencial.
Si \(m_{1}, m_{2}\) son raíces complejas conjugadas de la forma \(a\pm bi\) entonces las raíces son de la forma
\[ \rho(k)=R^{k}(c_{1}\cos(mk)+c_{2}\sin(mk)),~k=0,1,2,\dots \]donde \(R=|m_{i}|=\sqrt{a^{2}+b^{2}},~i=1,2\), y \(\lambda\) es determinado por \(\cos(m)=a/R\) y \(\sin(m)=b/R\). Por lo tanto, \(a+bi=R(\cos(m)\pm\sin(m)i)\). Donde \(c_{1}, c_{2}\) son constantes. La función \(ACF\) en este caso tiene la forma de frecuencia senosoidal con factor de frecuencia \(R\) y frecuencia \(m\). Esto es, periodo \(2\pi/\lambda\).
Existe una sola raíz real (raíz doble) \(m_{1}=m_{2}=m_{0}\), entonces
\[ \rho(k)=(c_{1}+c_{2}k)m_{0}^{k},~k=0,1,2,\dots \]En este caso, la \(ACF\) exhibe un patrón de decrecimiento exponencial.
En el Caso 1, por ejemplo, un modelo AR(2) puede ser visto como un modelo AR(1) “ajustado” para el cual una única expresión de decaimiento exponencial como en el modelo \(AR(1)\) no es suficiente para describir el patrón en la ACF, y, por lo tanto, una expresión adicional de decaimiento exponencial se “agrega” al introducir el término de retardo de segundo orden, \(y_{t−2}\).
La siguiente figura muestra la realización del proceso \(AR(2)\): \(y_{t}=4+0.4y_{t-1}+0.5y_{t-2}+\varepsilon_{t}\).
Show code cell source
np.random.seed(12345)
n=600
arparams = np.array([0.4, 0.5]) # phi1, phi2,...
maparams = np.array([0]) # theta1, theta2,...
intercept = 4
ar = np.r_[1, -arparams] # add zero-lag and negative
ma = np.r_[1, maparams] # add zero-lag
ar1_data = intercept + smtsa.arma_generate_sample(ar=ar, ma=ma, nsample=n)
plotds(ar1_data)
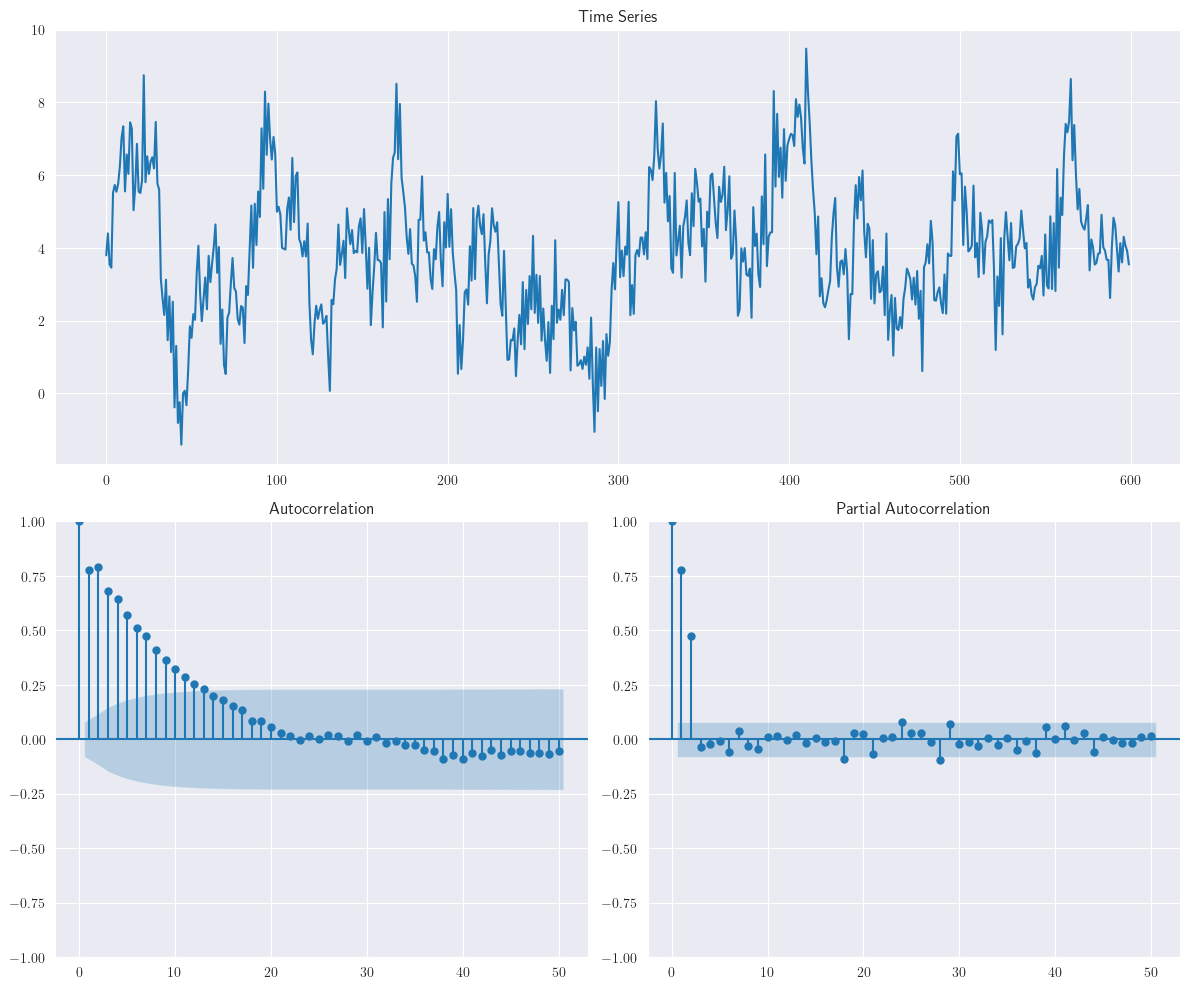
Tenga en cuenta que las raíces del polinomio asociado a este modelo son reales. Por lo tanto, la ACF es una mezcla de dos términos de decaimiento exponencial. De manera similar, la siguiente figura muestra una realización del siguiente proceso \(AR(2)\): \(y_{t}=4+0.4y_{t-1}-0.5y_{t-2}+\varepsilon_{t}\)
Show code cell source
np.random.seed(12345)
n=600
arparams = np.array([0.4, -0.5]) # phi1, phi2,...
maparams = np.array([0]) # theta1, theta2,...
intercept = 4
ar = np.r_[1, -arparams] # add zero-lag and negative
ma = np.r_[1, maparams] # add zero-lag
ar1_data = intercept + smtsa.arma_generate_sample(ar=ar, ma=ma, nsample=n)
plotds(ar1_data)
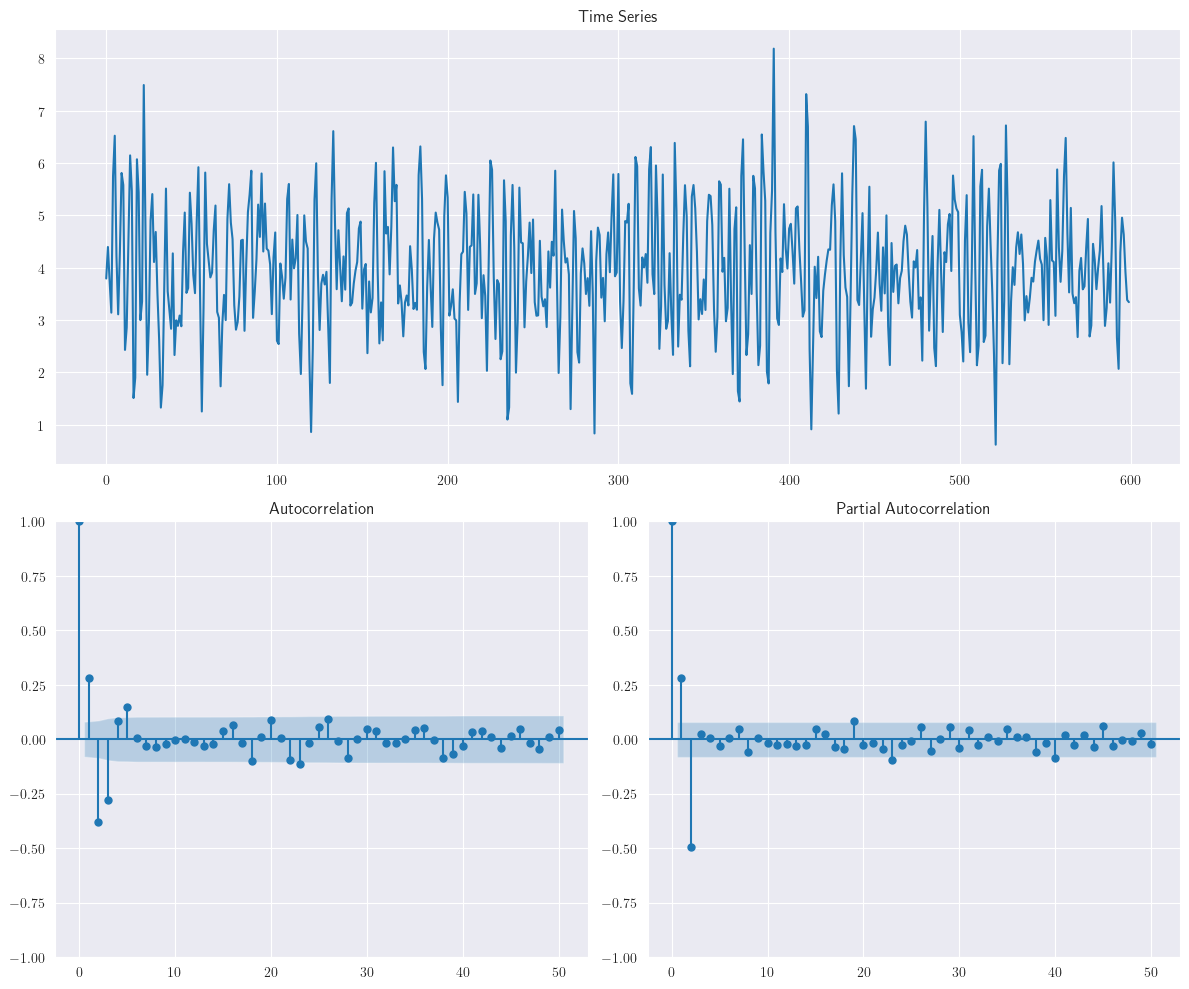
Para este proceso, las raíces del polinomio asociado son complejas conjugadas. Por lo tanto, el gráfico de la función de autocorrelación (ACF) muestra un comportamiento de sinusoides amortiguadas.
3.10. Proceso autorregresivo general, \(AR(p)\)#
En las dos secciones anteriores, se presenta un modelo \(AR\) general de orden \(p\)
(3.28)#\[ y_{t}=\delta+\phi_{1}y_{t-1}+\phi_{2}y_{t-2}+\cdots+\phi_{p}y_{t-p}+\varepsilon_{t} \]donde \(\varepsilon_{t}\) es ruido blanco.
Otra representación de la Ecuación (3.28) se puede dar como
\[ \Phi(B)y_{t}=\delta+\varepsilon_{t} \]donde \(\Phi(B)=1-\phi_{1}B-\phi_{2}B^{2}-\cdots-\phi_{p}B^{p}\).
La serie temporal \(AR(p)\), \(\{y_{t}\}\) en la Ecuación (3.28) es causal y estacionaria si las raíces del polinomio asociado
(3.29)#\[ m^{p}-\phi_{1}m^{p-1}-\phi_{2}m^{p-2}-\cdots-\phi_{p}=0 \]son menores que uno, en valor absoluto.
Además, bajo esta condición, la serie temporal \(\{y_{t}\},~ AR(p)\) también se dice que tiene una representación \(MA\) infinita, absolutamente sumable
(3.30)#\[ y_{t}=\mu+\Psi(B)\varepsilon_{t}=\mu+\sum_{i=0}^{\infty}\psi_{i}\varepsilon_{t-i}, \]donde \(\Psi(B)=\Phi(B)^{-1}\) con \(\sum_{i=0}^{\infty}|\psi_{i}|<\infty\).
Al igual que en \(AR(2)\), los pesos de los choques aleatorios en la Ecuación (3.30) pueden obtenerse de \(\Phi(B)\Psi(B)=1\) como
\[\begin{split} \begin{align*} \psi_{j} &= 0,~ j<0\\ \psi_{0} &= 1\\ \psi_{j}-\phi_{1}\psi_{j-1}-\phi_{2}\psi_{j-2}-\cdots-\phi_{p}\psi_{j-p} &=0~\forall~j=1,2,\dots \end{align*} \end{split}\]
Podemos mostrar fácilmente que, para el proceso \(AR(p)\) estacionario
\[ \text{E}(y_{t})=\mu=\frac{\delta}{1-\phi_{1}-\phi_{2}-\cdots-\phi_{p}} \]y
(3.31)#\[\begin{split} \begin{align*} \gamma(k) &= \text{Cov}(y_{t}, y_{t-k})\\[5mm] &= \text{Cov}(\delta+\phi_{1}y_{t-1}+\phi_{2}y_{t-2}+\cdots+\phi_{p}y_{t-p}+\varepsilon_{t}, y_{t-k})\\[2mm] &= \sum_{i=1}^{p}\phi_{i}\text{Cov}(y_{t-i}, y_{t-k})+\text{Cov}(\varepsilon_{t}, y_{t-k})\\ &= \sum_{i=1}^{p}\phi_{i}\gamma(k-i)+\begin{cases}\sigma^{2} & \text{si}~k=0\\0 & \text{si}~k>0\end{cases} \end{align*} \end{split}\]
Por lo tanto, tenemos
Al dividir la Ecuación (3.31) por \(\gamma(0)\) para \(k > 0\), se puede observar que la función de autocorrelación (ACF) de un proceso \(AR(p)\) satisface las ecuaciones de Yule–Walker
Las Ecuaciones (3.32) son ecuaciones lineales de orden \(p\), lo que implica que la función de autocorrelación (ACF) para un modelo \(AR(p)\) se puede encontrar a través de las \(p\) ***raíces del polinomio asociado con la Ecuación (3.29). Por ejemplo, si todas las raíces son distintas y reales, tenemos
\[ \rho(k)=c_{1}m_{1}^{k}+c_{2}m_{2}^{k}+\cdots+c_{p}m_{p}^{k},~k=1,2,\dots \]donde \(c_{1}, c_{2},\dots, c_{p}\) son constantes particulares.
Sin embargo, en general, las raíces pueden no ser todas distintas o reales. Por lo tanto, la función de autocorrelación (ACF) de un proceso \(AR(p)\) puede ser una mezcla de expresiones de decaimiento exponencial y de seno amortiguado dependiendo de las raíces de la Ecuación (3.29).
3.11. Función de Autocorrelación Parcial, \(PACF\)#
Introducción
En la sección anterior vimos que la función de autocorrelación (ACF) es una herramienta excelente para identificar el orden de un proceso \(MA(q)\), ya que se espera que “corte” después del rezago \(q\). Sin embargo, en la sección anterior, señalamos que la \(ACF\) no es tan útil en la identificación del orden de un proceso \(AR(p)\), porque probablemente tendrá una mezcla de expresiones de decaimiento exponencial y de seno amortiguado.
Por lo tanto, dicho comportamiento, aunque indica que el proceso podría tener una estructura \(AR\), no proporciona información adicional sobre el orden de dicha estructura. Para ello, definiremos y utilizaremos la función de autocorrelación parcial (PACF) de la serie temporal. Pero antes de eso, discutiremos el concepto de correlación parcial para facilitar la interpretación de la \(PACF\).
Correlación Parcial
Consideremos tres variables aleatorias \(X, Y\) y \(Z\). Luego, tomemos en cuenta la regresión lineal simple de \(X\) sobre \(Z\) y \(Y\) sobre \(Z\) como dos ecuaciones separadas
\[ \hat{X}=a_{1}+b_{1}Z~\text{donde}~b_{1}=\frac{\text{Cov}(Z, X)}{\text{Var}(Z)} \]y
\[ \hat{Y}=a_{2}+b_{2}Z~\text{donde}~b_{2}=\frac{\text{Cov}(Z, Y)}{\text{Var}(Z)} \]Entonces, los errores pueden obtenerse a partir de
\[ X^{\star}=X-\hat{X}=X-(a_{1}+b_{1}Z) \]y
\[ Y^{\star}=Y-\hat{Y}=Y-(a_{2}+b_{2}Z) \]Entonces, la correlación parcial entre \(X\) e \(Y\) después de ajustar por \(Z\) se define como la correlación entre \(X^{\star}\) e \(Y^{\star}\); \(\text{Corr}(X^{\star}, Y^{\star})=\text{Corr}(X-\hat{X}, Y-\hat{Y})\).
Es decir, la correlación parcial se puede entender como la correlación entre dos variables después de ser ajustadas por un factor común que puede estar afectándolas. Por supuesto, es posible generalizar esto permitiendo el ajuste por más de un factor.
La Función de Autocorrelación Parcial (PACF), siguiendo la definición anterior, entre \(y_{t}\) y \(y_{t−k}\) es la autocorrelación entre \(y_{t}\) y \(y_{t−k}\) después de ajustar por \(y_{t−1}, y_{t−2},\dots, y_{t−k+1}\) y eliminar su influencia intermedia.
Es decir, PACF mide la correlación “pura” entre \(y_{t}\) y \(y_{t-k}\) ajustada por las correlaciones en todos los desfases menores. Por lo tanto, para un modelo \(AR(p)\) la \(PACF\) entre \(y_{t}\) y \(y_{t−k}\) para \(k > p\) debería ser igual a cero. Una definición más formal se puede encontrar a continuación.
Función de Autocorrelación Parcial: Considera un modelo de series temporales estacionario \(\{y_{t}\}_{t}\) que no necesariamente es un proceso AR. Además, considera, para cualquier valor fijo de \(k\), las Ecuaciones de Yule-Walker para la ACF de un proceso \(AR(p)\) dadas en la Ecuación (3.32) como
Equivalentemente
Estas son las conocidas ecuaciones de [Yule, 1927] [Walker, 1931]. Obtenemos estimaciones de los parámetros de Yule-Walker reemplazando las autocorrelaciones teóricas \(ρ_{k}\) por las autocorrelaciones estimadas \(r_{k}\). Nótese que, si escribimos
\[\begin{split} \boldsymbol{\phi}= \begin{pmatrix} \phi_{1k}\\ \phi_{2k}\\ \vdots\\ \phi_{kk} \end{pmatrix},~ \boldsymbol{\rho}_{k}= \begin{pmatrix} \rho(1)\\ \rho(2)\\ \vdots\\ \rho(k) \end{pmatrix},~ \boldsymbol{P}_{k}= \begin{pmatrix} 1 & \rho(1) & \rho(2) & \cdots & \rho(k-1)\\ \rho(1) & 1 & \rho(1) & \cdots & \rho(k-2)\\ \vdots & \vdots & \vdots & \cdots & \vdots\\ \rho(k-1) & \rho(k-2) & \rho(k-3) & \cdots & 1\\ \end{pmatrix} \end{split}\]la solución de (3.33) para los parámetros \(\boldsymbol{\phi}\) en términos de las autocorrelaciones pueden ser escritos como
\[ \boldsymbol{\phi}=\boldsymbol{P}_{k}^{-1}\boldsymbol{\rho}_{k}. \]
Propiedades de la Matriz de Autocorrelación y PACF
Definición Positiva: La matriz de autocorrelación \(\boldsymbol{P}_{k}\) es siempre una matriz semidefinida positiva. Esto se debe a que cualquier combinación lineal de las variables tendrá una varianza no negativa.Invertibilidad: La matriz de autocorrelación \(\boldsymbol{P}_{k}\) es invertible siempre y cuando las series de tiempo no tengan una dependencia lineal perfecta en los desfases considerados. En el contexto de un modelo \(AR(p)\), \(\boldsymbol{P}_{k}\) será invertible si el proceso subyacente es estacionario y las raíces del polinomio característico están fuera del círculo unitario.
Para cualquier valor dado de \(k,~k = 1, 2,\dots,\) el último coeficiente \(\phi_{kk}\) se llama la autocorrelación parcial del proceso en el rezago \(k\). Se observa que para un proceso \(AR(p),~\phi_{kk} = 0\) para \(k>p\).
Por lo tanto, decimos que la PACF se corta después del rezago \(p\) para un \(AR(p)\). Esto sugiere que la \(PACF\) se puede utilizar para identificar el orden de un proceso \(AR\) de manera similar a cómo se puede utilizar la \(ACF\) para un proceso \(MA\).
Autocorrelación Parcial Muestral \(\hat{\phi}_{kk}\)
Para cálculos de muestrales, \(\hat{\phi}_{kk}\), la estimación muestral de \(\phi_{kk}\), se obtiene utilizando la \(ACF\) muestral, \(r(k)\). Además, en una muestra de \(N\) observaciones de un proceso \(AR(p), \hat{\phi}_{kk}\) para \(k>p\) está aproximadamente distribuido normalmente con
Por lo tanto, los límites del 95% para juzgar si algún \(\hat{\phi}_{kk}\) es estadísticamente significativamente diferente de cero se dan por \(\pm 2/\sqrt{N}\) [Quenouille, 1949, Jenkins and others, 1956, Daniels, 1956].
Nótese que en la siguiente figura, la cual representa el proceso
\[ AR(2):~y_{t}=4+0.8y_{t-1}-0.5y_{t-2}+\varepsilon_{t}, \]tenemos la \(PACF\) muestrales de las realizaciones del modelo \(AR(2)\). Observe que la \(PACF\) muestral se corta después del rezago 2.
Show code cell source
np.random.seed(12345)
n=600
arparams = np.array([0.8, -0.5]) # phi1, phi2,...
maparams = np.array([0]) # theta1, theta2,...
intercept = 4
ar = np.r_[1, -arparams] # add zero-lag and negative
ma = np.r_[1, maparams] # add zero-lag
ar1_data = intercept + smtsa.arma_generate_sample(ar=ar, ma=ma, nsample=n)
plotds(ar1_data)
3.12. Procesos Mixtos Autorregresivos-Media Movil#
Introducción
Los modelos ARMA (Autoregressive Moving Average) combinan dos componentes principales: el modelo autorregresivo (AR), que captura la relación lineal entre una observación y un número lineal de observaciones pasadas, y el modelo de media móvil (MA), que modela la relación lineal entre una observación y los errores de predicción pasados.
Los modelos \(ARMA\) son ampliamente utilizados en el modelamiento y predicción de datos temporales en una variedad de campos, incluyendo la economía, las finanzas, la meteorología y la ingeniería, debido a su capacidad para capturar tanto la dependencia temporal como la variabilidad aleatoria.
Proceso \(ARMA(p, q)\)
En general, un modelo \(ARMA(p, q)\) se define como:
(3.34)#\[\begin{split} \begin{align*} y_{t} &= \delta+\phi_{1}y_{t-1}+\phi_{2}y_{t-2}+\cdots+\phi_{p}y_{t-p}+\varepsilon_{t}-\theta_{1}\varepsilon_{t-1}-\theta_{2}\varepsilon_{t-2}-\cdots-\theta_{q}\varepsilon_{t-q}\\ &= \delta + \sum_{i=1}^{p}\phi_{i}y_{t-i}+\varepsilon_{t}-\sum_{i=1}^{q}\theta_{i}\varepsilon_{t-i} \end{align*} \end{split}\]o
(3.35)#\[ \Phi(B)y_{t}=\delta+\Theta(B)\varepsilon_{t} \]donde \(\varepsilon_{t}\) es un proceso ruido blanco.
3.13. Estacionariedad del proceso \(ARMA(p, q)\)#
La estacionariedad de un proceso \(ARMA\) está relacionada con el componente \(AR\) en el modelo y puede verificarse a través de las raíces del polinomio asociado
(3.36)#\[ m^{p}-\phi_{1}m^{p-1}-\phi_{2}m^{p-2}-\cdots-\phi_{p}=0 \]
Si todas las raíces de la Ecuación (3.36) son menores que uno en valor absoluto, entonces el \(ARMA(p, q)\) es estacionario. Esto también implica que, bajo esta condición, el \(ARMA(p, q)\) tiene una representación MA infinita como
(3.37)#\[ y_{t}=\mu+\sum_{i=0}^{\infty}\psi_{i}\varepsilon_{t-i}=\mu+\Psi(B)\varepsilon_{t}, \]con \(\Psi(B)=\Phi(B)^{-1}\Phi(B)\). Los coeficientes en \(\Psi(B)\) pueden ser calculados usando
\[\begin{split} \psi_{i}-\phi_{1}\psi_{i-1}-\phi_{2}\psi_{i-2}-\cdots-\phi_{p}\psi_{i-p}= \begin{cases} -\theta_{i}, & i=1,2,\dots,q\\ 0, & i>q \end{cases} \end{split}\]y \(\psi_{0}=1\).
3.14. Invertibilidad del proceso \(ARMA(p, q)\)#
La invertibilidad de un proceso \(ARMA(p, q)\) está relacionada con el componente \(AR\) del modelo y puede verificarse a través de las raíces del polinomio asociado
\[ m^{q}-\theta_{1}m^{q-1}-\theta_{2}m^{q-2}-\cdots-\theta_{q}=0 \]
Si todas las raíces de la Ecuación (3.37) son menores que uno en valor absoluto, entonces se dice que el \(ARMA(p, q)\) es invertible y tiene una representación \(AR\) infinita
\[ \Pi(B)y_{t}= \alpha +\varepsilon_{t} \]donde \(\alpha=\Theta(B)^{-1}\delta\) y \(\Pi(B)=\Theta(B)^{-1}\Phi(B)\). Los coeficientes en \(\Pi(B)\) pueden ser calculados a partir de
\[\begin{split} \pi_{i}-\theta_{1}\pi_{i-1}-\theta_{2}\pi_{i-2}-\cdots-\theta_{q}\pi_{i-q}= \begin{cases} \phi_{i}, & i=1,2,\dots,p\\ 0, & i>p \end{cases} \end{split}\]y \(\pi_{0}=-1\).
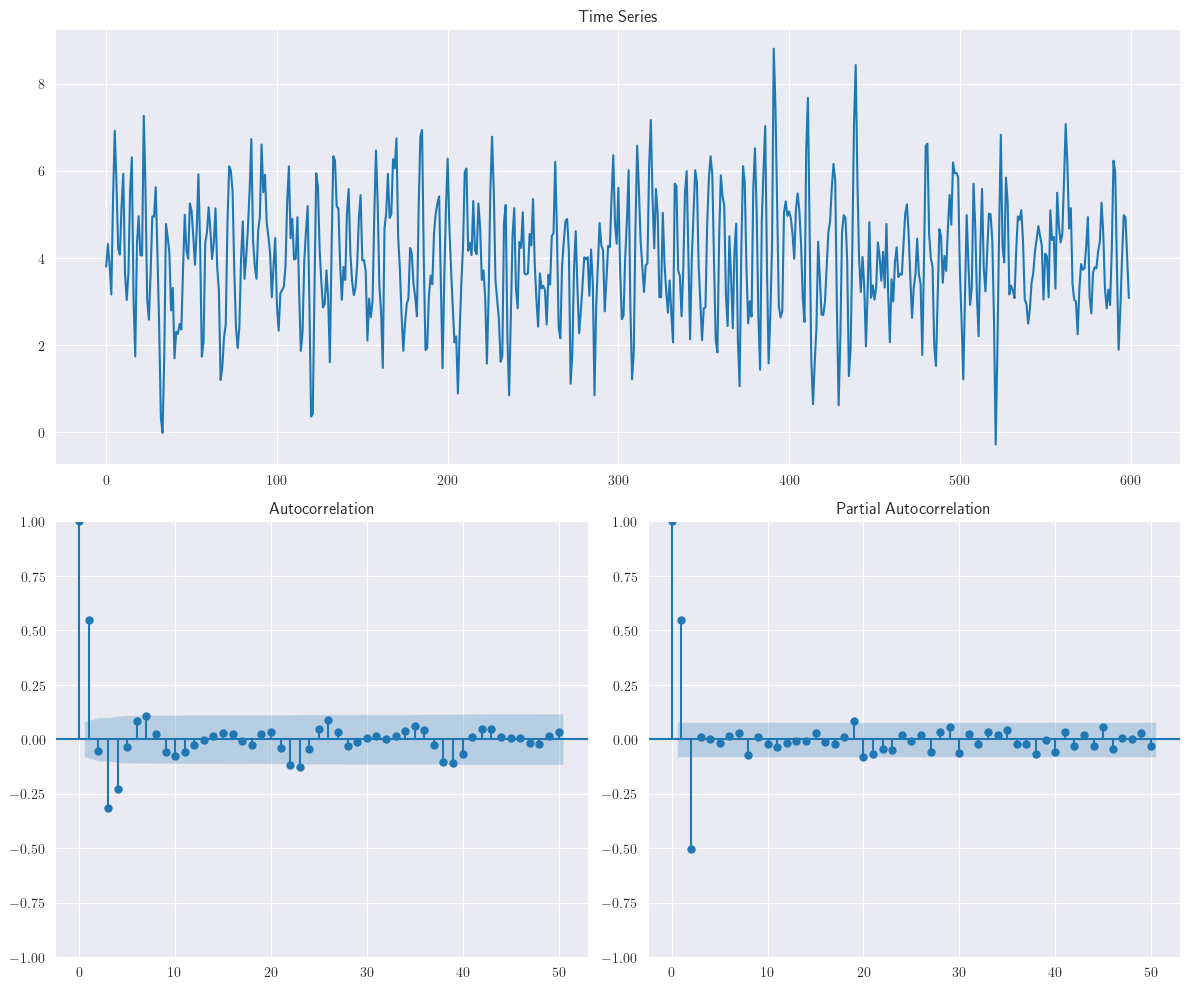
La siguiente figura muestra la ejercitación del proceso \(ARMA(1, 1)\)
\[ y_{t}=16+0.6y_{t-1}+\varepsilon_{t}+0.8\varepsilon_{t-1} \]
Show code cell source
np.random.seed(12345)
n=600
arparams = np.array([0.6]) # phi1, phi2,...
maparams = np.array([0.8]) # theta1, theta2,...
intercept = 16
ar = np.r_[1, -arparams] # add zero-lag and negative
ma = np.r_[1, maparams] # add zero-lag
ar1_data = intercept + smtsa.arma_generate_sample(ar=ar, ma=ma, nsample=n)
plotds(ar1_data)
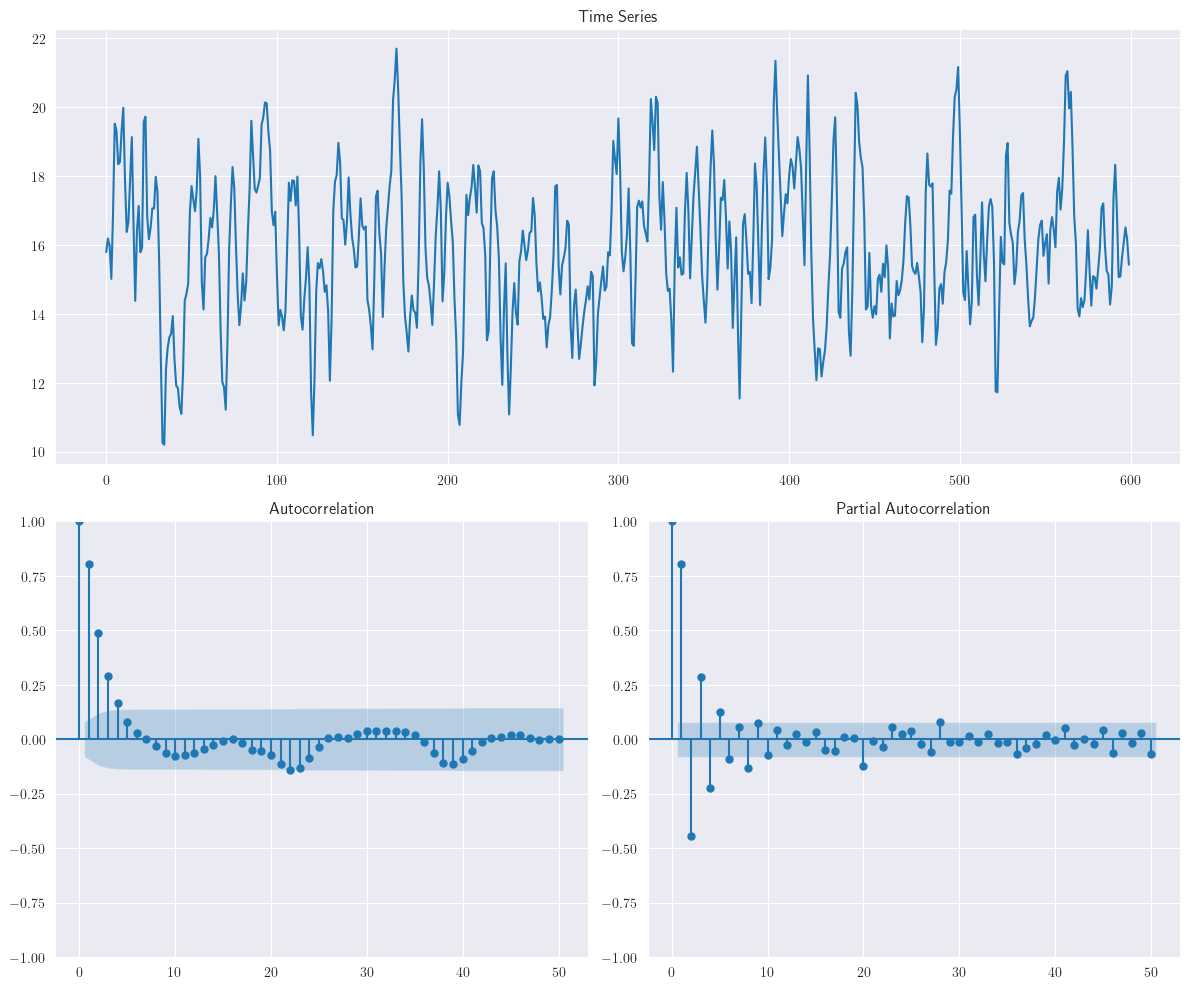
Nótese que las funciones de autocorrelación y autocorrelación parcial de la muestra exhiben un comportamiento de decaimiento exponencial (a veces en valor absoluto dependiendo de los signos de los coeficientes \(AR\) y \(MA\)), como se muestra en el proceso \(ARMA(1, 1)\)
Show code cell source
np.random.seed(12345)
n=600
arparams = np.array([-0.7]) # phi1, phi2,...
maparams = np.array([-0.6]) # theta1, theta2,...
intercept = 16
ar = np.r_[1, -arparams] # add zero-lag and negative
ma = np.r_[1, maparams] # add zero-lag
ar1_data = intercept + smtsa.arma_generate_sample(ar=ar, ma=ma, nsample=n)
plotds(ar1_data)
3.15. Funciones de autocorrelación (\(ACF\)) y autocorrelación parcial (\(PACF\)) del proceso \(ARMA(p, q)\)#
Las funciones de autocorrelación (ACF) y autocorrelación parcial (PACF) de un proceso ARMA son determinadas por las componentes AR y MA, respectivamente. Por lo tanto, tanto la ACF como la PACF de un \(ARMA(p, q)\) exhiben patrones de decaimiento exponencial y/o sinusoidales amortiguados, lo que dificulta relativamente la identificación del orden del modelo \(ARMA(p, q)\).
Para ello, se pueden utilizar funciones de muestra adicionales como la ACF de muestra extendida (ESACF), la PACF de muestra generalizada (GPACF), la ACF inversa (IACF) y correlaciones canónicas [Box et al., 2015, William and Wei, 2006, Tiao and Box, 1981, Tsay and Tiao, 1984, Ledolter and Abraham, 1984].
Sin embargo, la disponibilidad de librerías en
Pythonpermite al profesional considerar varios modelos con diferentes órdenes y compararlos según los criterios de selección de modelos como AIC, AICC y BIC. Los valores teóricos de la ACF y la PACF para series de tiempo estacionarias se resumen en la siguiente tabla.
Modelo |
ACF |
PACF |
|---|---|---|
\(MA(q)\) |
La \(ACF\) se corta después del rezago \(q\) |
Decaimiento exponencial y/o sinusoides amortiguadas |
\(AR(p)\) |
Decaimiento exponencial y/o sinusoides amortiguadas |
La \(PACF\) se corta después del rezago \(p\) |
\(ARMA(p, q)\) |
Decaimiento exponencial y/o sinusoides amortiguadas |
Decaimiento exponencial y/o sinusoides amortiguadas |
3.16. Procesos No Estacionarios#
Introducción
A menudo sucede que, aunque los procesos pueden no tener un nivel constante, exhiben un comportamiento homogéneo a lo largo del tiempo. Llamaremos a una serie de tiempo, \(y_{t}\), no estacionaria homogénea si no es estacionaria, pero su primera diferencia, es decir, \(w_{t} = y_{t} - y_{t-1} = (1 - B)y_{t}\), o diferencias de orden superior, \(w_{t} = (1 - B)^{d}y_{t}\), produce una serie de tiempo estacionaria.
Además, llamaremos a \(y_{t}\) un proceso autoregresivo integrado de media móvil (ARIMA) de órdenes \(p, d\) y \(q\), es decir, \(ARIMA(p, d, q)\), si su \(d\)-ésima diferencia, denotada por \(w_{t}= (1 - B)^{d}y_{t}\), produce un proceso \(ARMA(p, q)\) estacionario.
El término “integrado” se utiliza ya que, para \(d = 1\), por ejemplo, podemos escribir \(y_{t}\) como la suma (o “integral”) del proceso \(w_{t}\) como
Por lo tanto, un proceso \(ARIMA(p, d, q)\) puede ser escrito como
(3.38)#\[ \Phi(B)(1-B)^{d}y_{t}=\delta+\Phi(B)\varepsilon_{t} \]
Observación
Por lo tanto, una vez que se realiza la diferenciación y se obtiene una serie temporal estacionaria \(w_{t}=(1−B)^{d}y_{t}\), se pueden usar los métodos proporcionados en las secciones anteriores para obtener el modelo completo.
En la mayoría de las aplicaciones, la primera diferenciación (\(d = 1\)) y ocasionalmente la segunda diferenciación (\(d = 2\)) serían suficientes para lograr la estacionariedad. Sin embargo, a veces las transformaciones que no sean la diferenciación son útiles para reducir una serie temporal no estacionaria a una estacionaria.
Por ejemplo, en muchas series temporales económicas, la variabilidad de las observaciones aumenta a medida que aumenta el nivel promedio del proceso; sin embargo, el porcentaje de cambios en las observaciones es relativamente independiente del nivel. Por lo tanto, tomar el logaritmo de la serie original será útil para lograr la estacionariedad.
3.17. Construcción de Modelos de Series Temporales#
Introducción
Se utiliza un procedimiento iterativo de tres pasos para construir un modelo ARIMA. Primero, se identifica un modelo tentativo de la clase ARIMA mediante el análisis de datos históricos. Segundo, se estiman los parámetros desconocidos del modelo. Tercero, a través del análisis de residuos, se realizan controles diagnósticos para determinar la adecuación del modelo o indicar posibles mejoras. Discutiremos cada uno de estos pasos con más detalle.
3.18. Identificación de modelos#
Antes de comenzar con esfuerzos rigurosos de construcción de modelos estadísticos, se recomienda el uso de gráficos descriptivos, como los gráficos de series temporales simples y los gráficos de dispersión de los datos de series temporales \(y_{t}\) vs \(y_{t−1}, y_{t−2},\dots,\).
Si se sospecha de no estacionariedad, también se debe considerar el gráfico de la primera (o \(d\)-ésima) diferencia. La prueba de raíz unitaria [Dickey and Fuller, 1979] también se puede realizar para asegurarse de que se necesite realmente la diferenciación.
Una vez que se puede asumir la estacionariedad de la serie temporal, se deben obtener la ACF y PACF muestral de la serie temporal original (o su \(d\)-ésima diferencia si es necesario). Dependiendo de la naturaleza de la autocorrelación, las primeras 20–25 autocorrelaciones y autocorrelaciones parciales muestrales deberían ser suficientes.
La Tabla Comportamiento de las ACF, PACF teóricas para procesos estacionarios junto con los límtes \(\pm2/\sqrt{N}\) pueden ser usados como una guía para identificar modelos \(AR\) y \(MA\). La identificación va a requerir mayor cuidado dado que, \(ACF\) y \(PACF\) van a presentar decaimiento exponencial y comportamiento sinusoidal amortiguado.
Existen varios métodos, como el método de momentos, método de máxima verosimilitud y mínimos cuadrados que pueden ser utilizados para estimar los parámetros en el posible modelo identificado. Sin embargo, a diferencia de los problemas de regresión, muchos modelos ARIMA son no lineales y van a requerir del uso de procedimientos no lineales para el ajuste de modelos. Debe escoger el modelo mas adecuado ofrecido por la librería utilizada.
3.19. Diagnostico Checking#
Despues que un posible modelo ha sido ajustado a los datos, debemos examinar si es adecuado, y si es necesario, sugerir mejoras potenciales. Esto puede ser realizado a traves del análisis de residuales.
Los residuales para un proceso \(ARMA(p, q)\) puden ser obtenidos a partir de
(3.39)#\[ \hat{\varepsilon}_{t}=y_{t}-\left(\hat{\delta}+\sum_{i=1}^{p}\hat{\phi}_{i}y_{t-i}-\sum_{i=1}^{q}\hat{\theta_{i}}\hat{\varepsilon}_{t-i}\right) \]
Si el modelo especificado es adecuado, y por lo tanto los ordenes aproximados \(p\) y \(q\) son identificados, este debería transformar las observaciones a un proceso ruido blanco. Esto es, el comportamiento de los residuales en la Ecuación (3.39) debería ser ruido blanco.
Denotemos la función de autocorrelación muestral de los residuales por \(\{r_{e}(k)\}\). Si el modelo es apropiado, la función de autocorrelación muestral de los residuos no debería tener una estructura a identificar. Esto es, la autocorrelación no debería diferir significativamente de cero para todos los lags mayores que uno. Si conocemos los verdaderos valores de los parámetros y la forma del modelo es correcta, los errores estándar de los residuos de autocorrelación serían \(N^{-1/2}\).
Indicador chi-cuadrado
Además de considerar los términos individuales \(r_{e}(k)\), podemos obtener vía test chi-cuadrado un indicador de si los primeros \(K\) autocorrelaciones residuales unidas, indican que el modelo es adecuado. El tes estadístico es
\[ Q=(N-d)\sum_{k=1}^{K}r_{e}^{2}(k) \]la cual es distribuida aproximadamente como chi-cuadrado con \(K-p-q\) grados de libertad si el modelo es apropiado. Si el modelo es inadecuado, \(Q\) excede un punto, en la pequeña cola superior aproximada, de la distribución chi-cuadrado con \(K-p-q\) grados de libertad.
3.20. Pronóstico con proceso ARIMA#
Introducción
Una vez una serie de tiempo apropiada ha sido ajustada, esta púede ser usada para generar pronósticos de futuras observaciones. Si denotamos el tiempo actual por \(T\), la predicción \(y_{T+\tau}\) es llamada, pronóstico \(\tau\)-period-ahead y lo denotamos por \(\hat{y}_{T+\tau}(T)\).
El criterio estándar a utilizar para obtener la mejor predicción es el error cuadrático medio, para el que el valor esperado de los errores predichos al cuadrado
\[ \text{E}[(y_{T+\tau}-\hat{y}_{T+\tau}(T))^{2}]=\text{E}[e_{T}(\tau)^{2}] \]es minimizado.
Puede demostrarse que el mejor ponóstico en el sentido cuadrático medio es la esperanza condicional de \(y_{T+\tau}\) dada la actual y previas observaciones, esto es, \(y_{T}, y_{T-1}, y_{T-2},\dots\)
\[ \hat{y}_{T+\tau}(T)=\text{E}[y_{T+\tau} | y_{T}, y_{T-1},\dots] \]
Considere por ejemplo un proceso \(ARIMA(p, d, q)\) en el tiempo \(T+\tau\) (i.e periodo \(\tau\) en el futuro)
\[ y_{T+\tau}=\delta+\sum_{i=1}^{p+d}\phi_{i}y_{T+\tau-i}+\varepsilon_{T+\tau}-\sum_{i=1}^{q}\theta_{i}\varepsilon_{T+\tau-i}. \]
Además, considere su representación infinita \(MA\)
(3.40)#\[ y_{T+\tau}=\mu+\sum_{i=0}^{\infty}\psi_{i}\varepsilon_{T+\tau-i} \]
Podemos particionar la Ecuación (3.40) como
\[ y_{T+\tau}=\mu+\sum_{i=0}^{\tau-1}\psi_{i}\varepsilon_{T+\tau-i}+\sum_{i=\tau}^{\infty}\psi_{i}\varepsilon_{T+\tau-i} \]
En esta partición se puede ver claramente que la componente \(\sum_{i=0}^{\tau-1}\psi_{i}\varepsilon_{T+\tau-i}\) involucra los errores futuros, mientras que la componente \(\sum_{i=\tau}^{\infty}\psi_{i}\varepsilon_{T+\tau-i}\) involucra el error presente y los pasados.
Dada la relación entre la actual y pasadas observaciones, y el supuesto de que los random shocks tienen media cero y son independientes, el mejor pronostico en el sentido cuadratico medio es
\[\begin{split} \begin{align*} \hat{y}_{T+\tau}(T) &= \text{E}[y_{T+\tau} | y_{T}, y_{T-1},\dots]\\[3mm] &= \text{E}\left[\mu+\sum_{i=0}^{\tau-1}\psi_{i}\varepsilon_{T+\tau-i}+\sum_{i=\tau}^{\infty}\psi_{i}\varepsilon_{T+\tau-i}\right]\\ &= \mu+\sum_{i=0}^{\tau-1}\psi_{i}\text{E}[\varepsilon_{T+\tau-i} | y_{T}, y_{T-1},\dots]+\sum_{i=\tau}^{\infty}\psi_{i}\text{E}[\varepsilon_{T+\tau-i} | y_{T}, y_{T-1},\dots]\\[1mm] &= \mu+\sum_{i=\tau}^{\infty}\psi_{i}\varepsilon_{T+\tau-i},~\text{E}[\varepsilon_{T+\tau-i} | y_{T}, y_{T-1},\dots]= \begin{cases} 0 & \text{si}~i<\tau\\ \varepsilon_{T+\tau-i} & \text{si}~i\geq\tau. \end{cases} \end{align*} \end{split}\]
Seguidamente, el error del pronóstico es calculado a partir de
(3.41)#\[ e_{T}(\tau)=y_{T+\tau}-\hat{y}_{T+\tau}(T)=\sum_{i=0}^{\tau-1}\psi_{i}\varepsilon_{T+\tau-i} \]
Dado que el error de pronóstico en la Ecuación (3.41) es una combinación lineal de random shocks, tenemos que
\[\begin{split} \begin{align*} \text{E}[e_{T}(\tau)] &= 0\\ \text{Var}[e_{T}(\tau)] &= \text{Var}\left[\sum_{i=0}^{\tau-1}\psi_{i}\varepsilon_{T+\tau-i}\right]\\ &= \sum_{i=0}^{\tau-1}\psi_{i}^{2}\text{Var}(\varepsilon_{T+\tau-i})\\ &= \sigma^{2}\sum_{i=0}^{\tau-1}\psi_{i}^{2}\\[2mm] &= \sigma^{2}(\tau),~\tau=1,2,\dots \end{align*} \end{split}\]
3.21. Implementación#
Estudiemos implicaciones de los modelos de componentes \(AR\). El conjunto de datos
AR(1)puede ser generado utilizando la funciónarma_generate_sampledel módulostatsmodels.tsa
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
import statsmodels.tsa.api as smtsa
import statsmodels.tsa.arima.model as arima_model
import warnings
warnings.filterwarnings("ignore")
n = 600
ar = np.r_[1, -0.6]
ma = np.r_[1, 0]
ar1_data = smtsa.arma_generate_sample(ar=ar, ma=ma, nsample=n)
plotds(ar1_data)
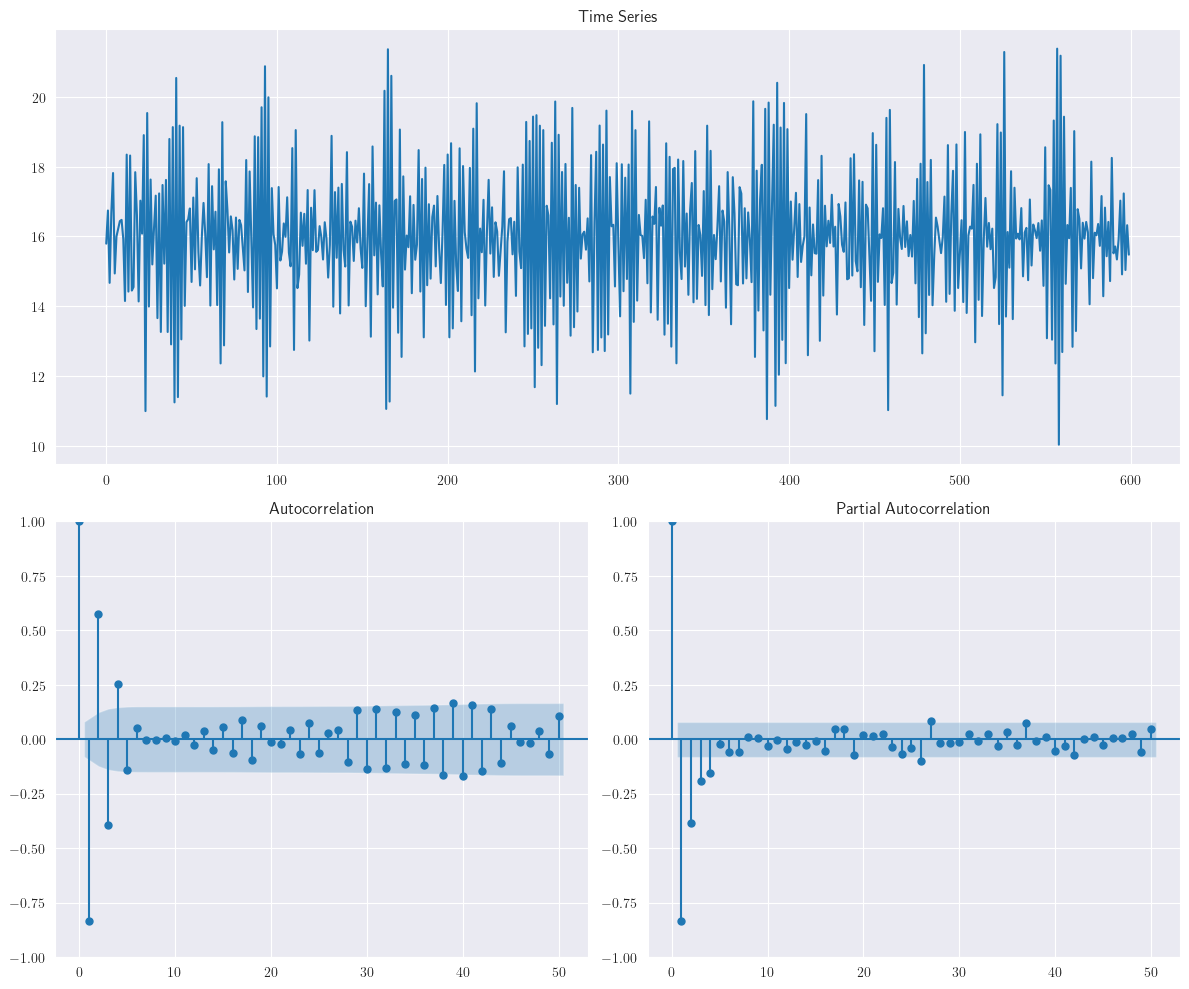
El script anterior genera un conjunto de datos para el escenario \(AR(1)\) con correlación serial definida para el retardo anterior como 0.6. El componente \(MA\) se fija en cero para eliminar cualquier efecto de media móvil de la señal de la serie temporal.
Considere el siguiente modelo \(y_{t}=\phi_{1}y_{t-1}+\varepsilon_{t}\). Los datos son simulados usando componentes autoregresivas menores que 1, por lo tanto, la autocorrelación decrecerá sobre el tiempo siguiendo la relación entre \(\phi\) y \(t\)
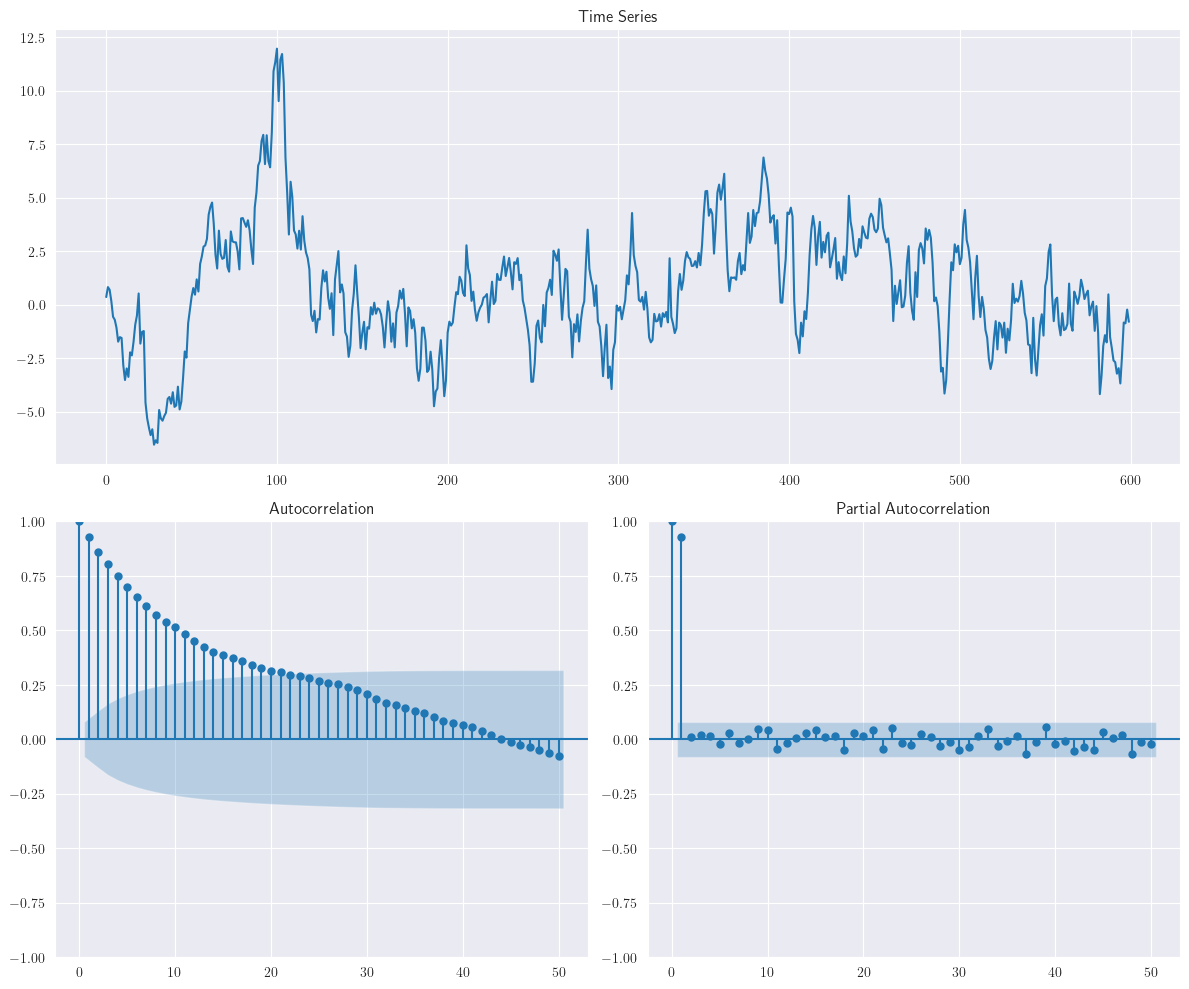
Por lo tanto, el gráfico ACF decrece exponencialmente y la PACF remueve el efecto de rezago mientras calcula correlación, solo términos significativos son capturados. El valor de \(\phi\) afecta la estacionariedad de la señal. Por ejemplo, si aumentamos el valor de \(\phi\) de 0.6 a 0.95 en \(AR(1)\), el modelo tiende a la no estacionariedad, como se muestra en el siguiente ejemplo:
ar = np.r_[1, -0.95]
ma = np.r_[1, 0]
ar1_data = smtsa.arma_generate_sample(ar=ar, ma=ma, nsample=n)
plotds(ar1_data)
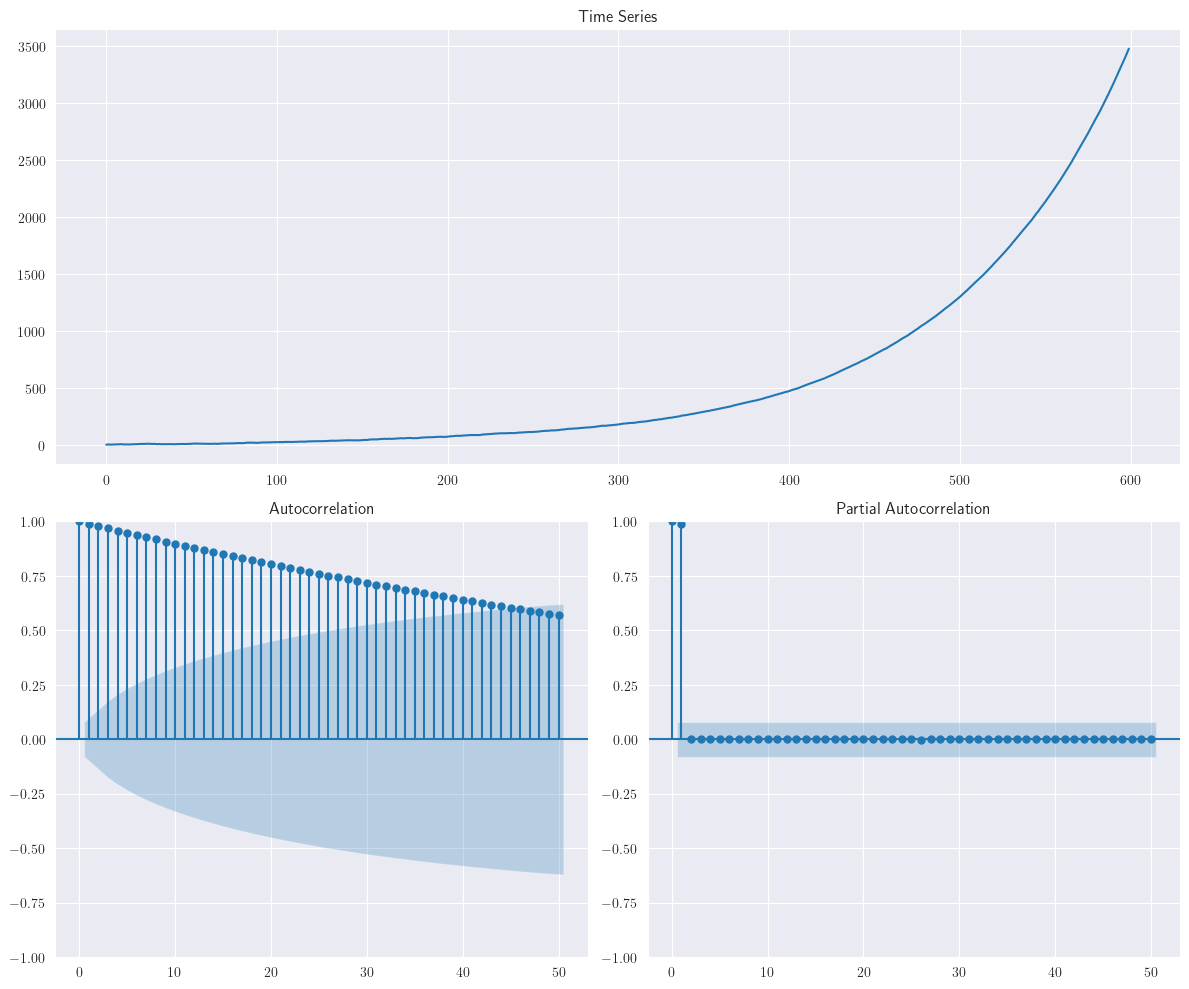
En el escenario en que \(\phi>1\), el modelo se convierte en no estacionario. Un ejemplo de proceso no estacionario con \(\phi>1\) lo podemos ver a continuación, considerando \(\phi=1.01\)
ar = np.r_[1, -1.01]
ma = np.r_[1, 0]
ar1_data = smtsa.arma_generate_sample(ar=ar, ma=ma, nsample=n)
plotds(ar1_data)
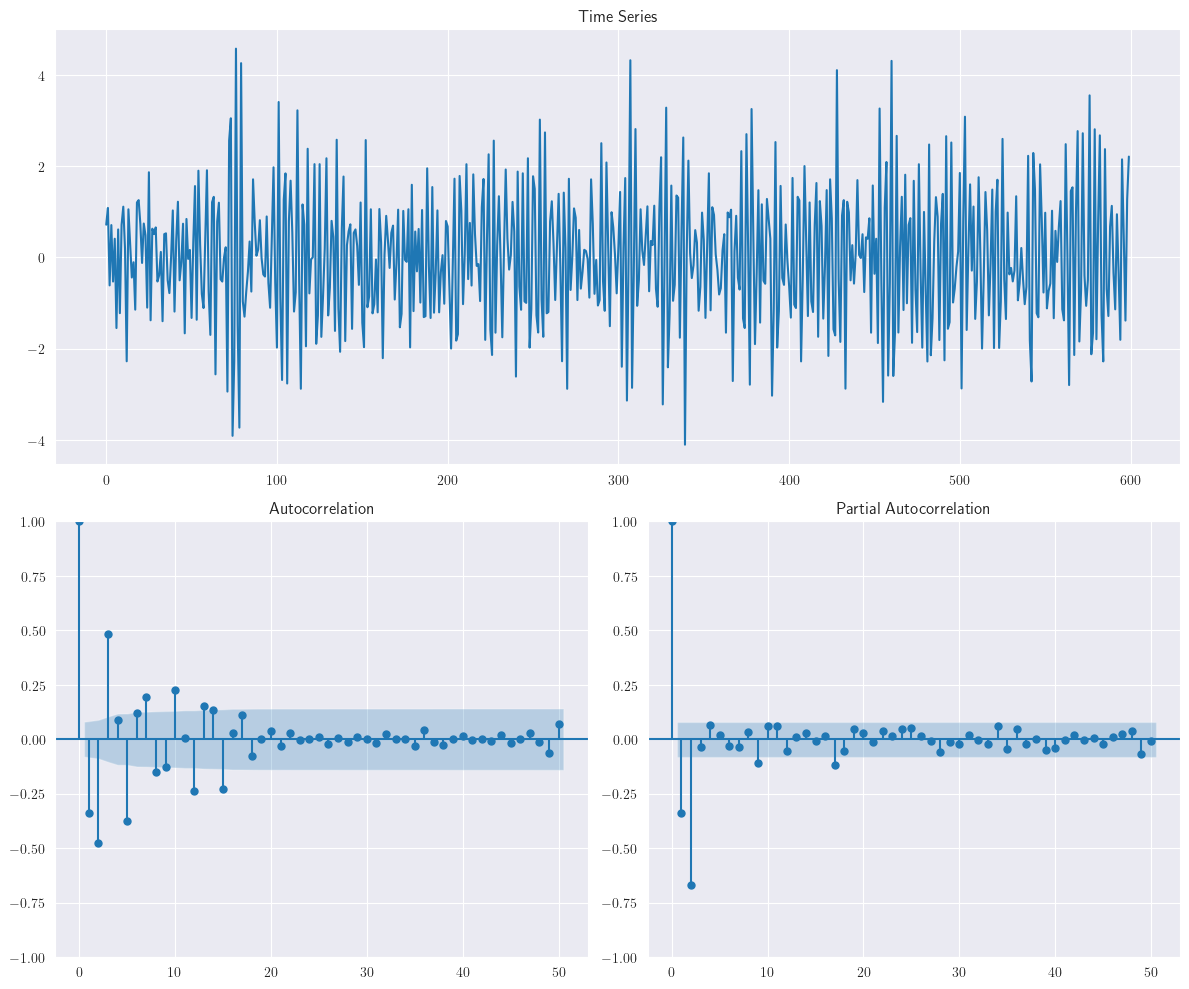
Similarmente, modelos autorregresivos de alto orden, pueden ser generados para validar efecto sobre los componentes de la PACF con el orden. Los conjuntos de datos con componentes \(AR(2)\) y \(AR(3)\) son generados utilizando el siguiente script
ar = np.r_[1, 0.6, 0.7]
ma = np.r_[1, 0]
ar2_data = smtsa.arma_generate_sample(ar=ar, ma=ma, nsample=n)
plotds(ar2_data)
ar = np.r_[1, 0.6, 0.7, 0.5]
ma = np.r_[1, 0]
ar3_data = smtsa.arma_generate_sample(ar=ar, ma=ma, nsample=n)
plotds(ar3_data)
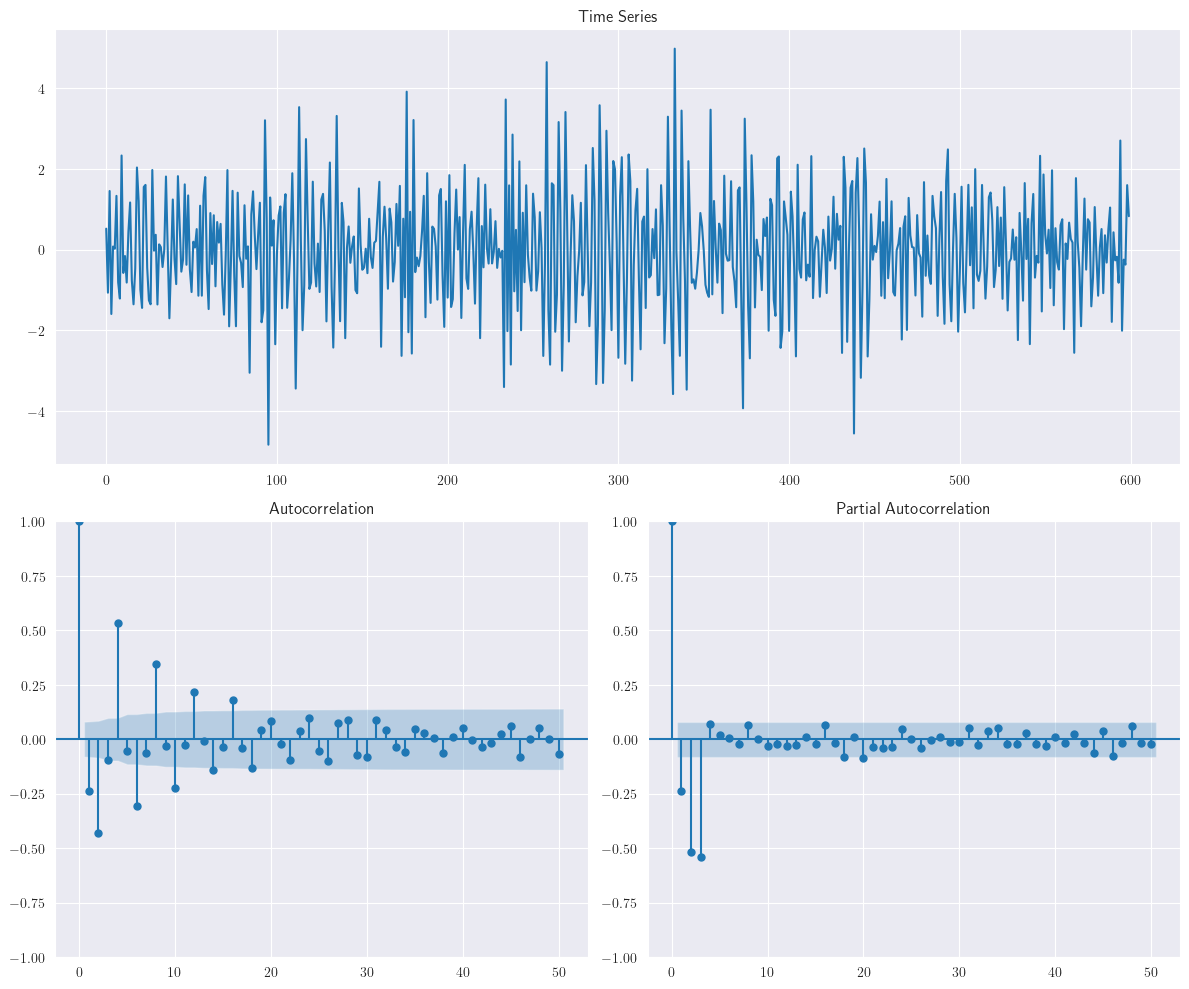
Como se puede ver, a partir de diferentes fuentes de datos, la PACF está capturando la componente autorregresiva y \(q\) es el valor donde esta es significativa.
El modelo para \(AR(3)\) puede ser evaluado usando la clase
ARIMA.fitdel módulo dePython,statsmodels.tsa.api(ver statsmodels.tsa.arima.model.ARIMA).Si ajustamos un modelo \(AR(3)\) sobre los datos generados con \(AR\), las correlaciones de 0.6, 0.7 y 0.5 se pueden visualizar (aproximadas vía MLE) en el siguiente
summary(). Nótese que son parecidos a la relación real obtenida en el ejemplo anterior usandosmtsa.arma_generate_sample
ar3 = arima_model.ARIMA(ar3_data.tolist(), order=(3, 0, 0)).fit()
ar3.summary()
| Dep. Variable: | y | No. Observations: | 600 |
|---|---|---|---|
| Model: | ARIMA(3, 0, 0) | Log Likelihood | -847.763 |
| Date: | Fri, 31 Jan 2025 | AIC | 1705.527 |
| Time: | 21:42:05 | BIC | 1727.512 |
| Sample: | 0 | HQIC | 1714.085 |
| - 600 | |||
| Covariance Type: | opg |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| const | 0.0028 | 0.014 | 0.198 | 0.843 | -0.025 | 0.030 |
| ar.L1 | -0.6479 | 0.034 | -18.891 | 0.000 | -0.715 | -0.581 |
| ar.L2 | -0.7168 | 0.030 | -23.592 | 0.000 | -0.776 | -0.657 |
| ar.L3 | -0.5454 | 0.034 | -16.194 | 0.000 | -0.611 | -0.479 |
| sigma2 | 0.9852 | 0.057 | 17.270 | 0.000 | 0.873 | 1.097 |
| Ljung-Box (L1) (Q): | 0.71 | Jarque-Bera (JB): | 1.04 |
|---|---|---|---|
| Prob(Q): | 0.40 | Prob(JB): | 0.59 |
| Heteroskedasticity (H): | 0.94 | Skew: | -0.10 |
| Prob(H) (two-sided): | 0.68 | Kurtosis: | 3.00 |
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
summary() Output
En el presente resumen,
Covariance Type: opgcorresponde a la estimación por producto exterior de gradientes Outer-Product-of-Gradients (OPG) para la matriz de covarianza asociada a las estimaciones de coeficientes del modelo.El
AIC, BIC, HQICutilizan la estimación de máxima verosimilitud (Log Likelihood) de un modelo como medida de ajuste. Los valores deAIC, BIC, HQICson bajos para los modelos con Log Likelihood altos. Esto significa que el modelo se ajusta mejor a los datos, que es lo que queremos. Por ejemplo,AICse define de la siguiente forma: \(AIC=2k-2\ln(L)\), donde \(k\) es el número de parámetros en el modelo estadístico, y \(L\) es el máximo valor de la función de verosimilitud para el modelo estimado.Al ajustar modelos, es posible aumentar la verosimilitud añadiendo parámetros, pero hacerlo puede dar lugar a un sobreajuste. Tanto el BIC como el AIC intentan resolver este problema introduciendo un término de penalización por el número de parámetros del modelo; el término de penalización es mayor en el
BICque en elAICpara tamaños de muestra superiores a 7.BICestá definido como \(BIC=k\ln(n)-2\ln(L)\), donde aquí \(n\) representa el tamaño de la muestra. El criterio de información de Hannan–Quinn (HQIC) está dado por \(HQIC=2k\ln(\ln(n))-2\ln(L)\). Este criterio reduce la penalización deBIC, de tal forma que en términos de penalización se ubica entreAICyBIC. La selección del criterio va a depender del objetivo principal del investigador.Los coeficientes del modelo autorregresivo son
ar.L1, ar.L2, ar.L3. El valor deconstes equivalente al intercepto en modelos de regresión lineal ysigma2es la varianza estimada del residuo en el modelo. La columnaP>|z|corresponde al \(p\)-value.std erres el error estándar asociado a cada coeficiente, para los cuales el intervalo de confianza aparece en la última columna[0.025, 0.075].Para determinar si la asociación entre la respuesta y cada término del modelo es estadísticamente significativa, comparamos el \(p\)-value del término con su nivel de significancia para evaluar la hipótesis nula.
La hipótesis nula es que el término no es significativamente diferente de 0, lo que indica que no existe asociación entre el término y la respuesta. Nótese que los coeficientes:ar.L1, ar.L2, ar.L3, son estadísticamente significativos. Cuando un coeficiente no es estadísticamente significativo, es posible que desee volver a ajustar el modelo sin el término asociado.El siguiente paso es determinar si el modelo cumple el supuesto del análisis. Utilizamos el estadístico chi-cuadrado de Ljung-Box (Ljung-Box (L1) (Q)), el \(p\)-value asociado
Prob(Q)y la función de autocorrelación de los residuos para determinar si el modelo cumple el supuesto de que los residuos son independientes. Si no se cumple el supuesto, es posible que el modelo no se ajuste correctamente a los datos y debe tener cuidado al interpretar los resultados. En este caso lahipótesis nula es que los residuos son independientes o que no hay correlación en los residuales. Nótese que el \(p\)-value es mayor o igual que 0.05, y está representado porProb(Q).Por otro lado, Jarque-Bera (JB) es un test de normalidad, en este caso para los residuales. La hipótesis nula a contrastar es que los
residuales están normalmente distribuidos. Nótese también que en este caso el \(p\)-value (Prob(JB)) es mayor al nivel de significancia. El sesgo y la curtosisSkew, Kurtosismuestran un sesgo negativo en los residuales y una distribuciónleptocúrticacon mayor concentración de los datos en torno a la media.El valor
Heteroskedasticity (H)es el estadístico asociado con el test de heterocedasticidad de los residuos estandarizados con \(p\)-valueProb(H) (two-sided). Lahipótesis nula es, los residuos no presentan heteroscedasticidad. Nótese que el \(p\)-value es mayor o igual que 0.05, y está representado porProb(H) (two-sided).
ar3.plot_diagnostics(figsize=(14,10));
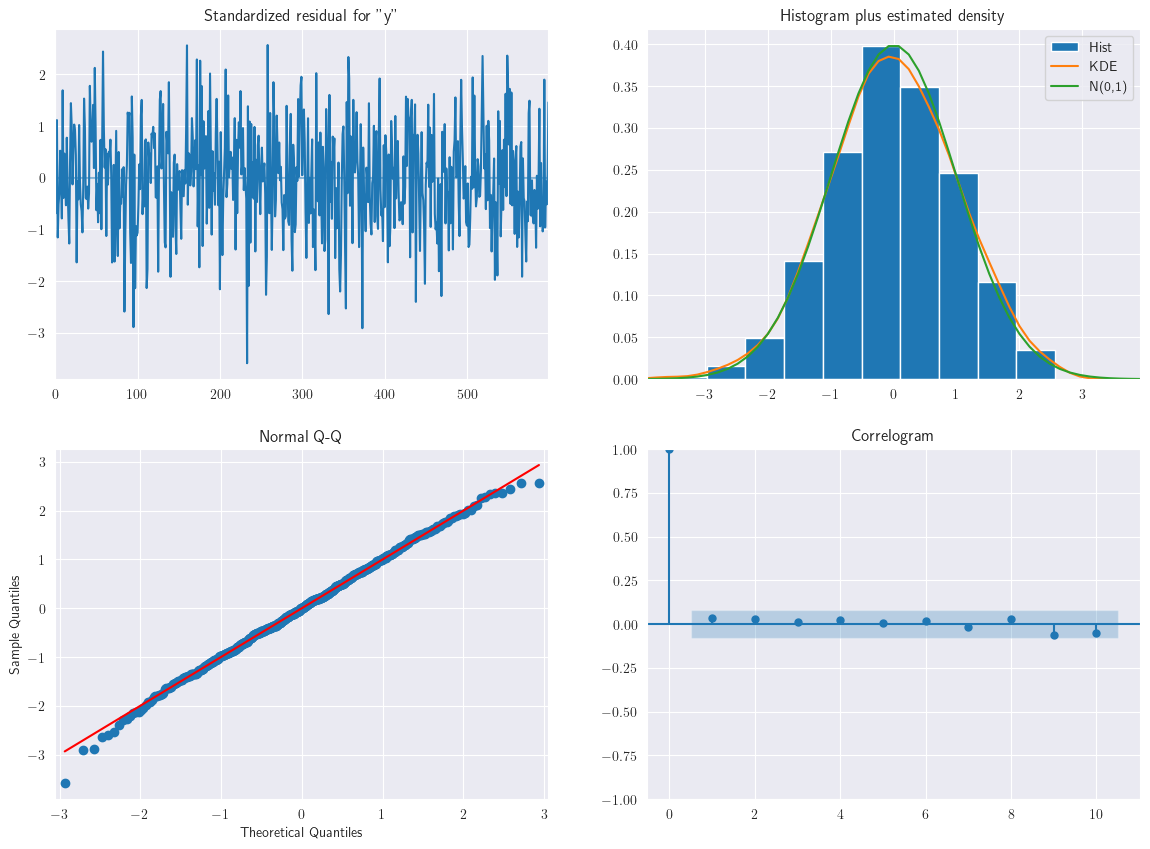
Nótese que en la ACF no hay correlaciones significativas, puede concluir que los residuos son independientes. Esto es, ninguna de las correlaciones de la función de autocorrelación de los residuos es significativa. Se puede concluir que el modelo cumple el supuesto de que los residuos son independientes.
Tanto \(AR\) como \(MA\) pueden utilizarse para corregir la dependencia serial, pero normalmente la autocorrelación positiva se corrige utilizando modelos \(AR\) y la dependencia negativa se corrige utilizando modelos \(MA\).
3.22. Modelos de media móvil#
Observación (Cross Validated)
¿Por qué molestarse en tomar alguna parte de un ruido blanco anterior \(\theta_{1}\varepsilon_{t-1}\) para la estimación del siguiente paso temporal, sabiendo que los términos de ruido blanco no están relacionados a lo largo del tiempo?
Ejemplo: Si un huracán azota Houston, va a haber un impacto en las ventas de, digamos, Target. Desde un alto nivel, esto es un gran valor negativo de \(\varepsilon_{t}\) para esa semana. La semana siguiente, habrá otra innovación semanal, \(\varepsilon_{t+1}\) pero es posible que el efecto del huracán no haya desaparecido del todo en el límite de la semana, por lo que habrá algún efecto de arrastre sobre las ventas, dado por la innovación de la semana anterior.
¿Por qué la varianza de los términos de innovación se mantiene constante dado que se esperaría que en realidad varíara con el tiempo?
Ejemplo: Incluso si varía, mientras no varíe por mucho, probablemente sea mejor simplemente modelarlo como una constante en lugar de tratar de estimarlo como un término variable. Por ejemplo, la demanda minorista de plátanos es bastante estable a lo largo del año, excepto en Navidad, cuando es más baja, pero fluctúa de forma errática semana a semana, a nivel de tienda. No podemos predecir exactamente cuál será la demanda la próxima semana, así que modelamos esa imprecisión como ruido blanco.
Para ilustrar un modelo de serie temporal de media móvil, generemos una señal utilizando el siguiente código
import statsmodels.tsa.api as smtsa
Número de muestras
n = 600
Generamos un conjunto de datos para \(MA(1)\)
ar = np.r_[1, 0]
ma = np.r_[1, 0.7]
ma1_data = smtsa.arma_generate_sample(ar=ar, ma=ma, nsample=n)
plotds(ma1_data)
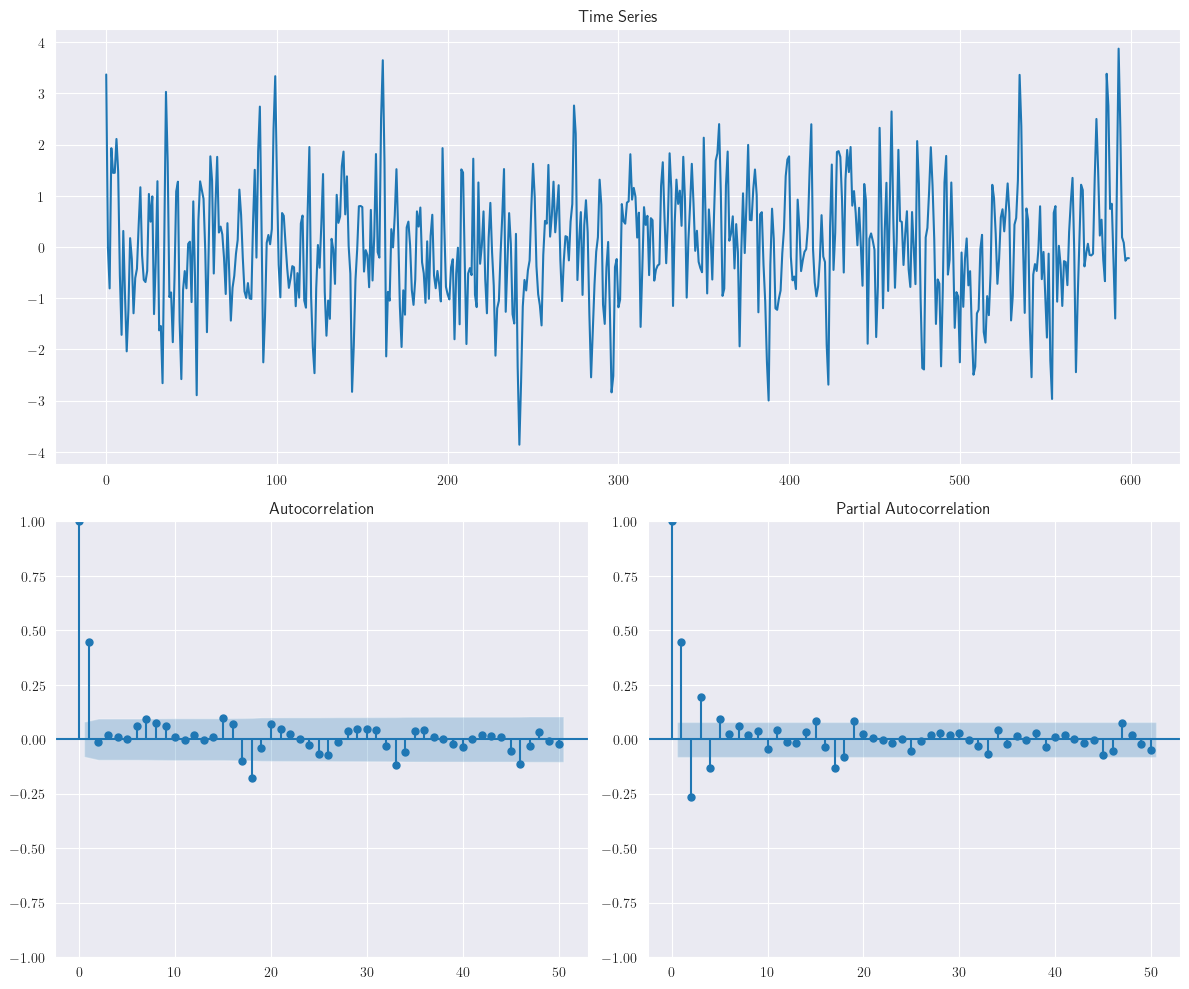
En el script anterior, \(n\) representa el número de muestras que se generarán con \(AR\) que define el componente autorregresivo y \(MA\) que explica el componente de media móvil de la señal de la serie temporal. Por ahora, mantendremos el impacto de \(AR\) en la señal de la serie temporal como cero. Este script generará un conjunto de datos de series temporales con una dependencia \(MA(1)\) y 0.7 de correlación serial con el error y puede ser representado como como sigue:
Para evaluar si la señal de la serie temporal consta de un componente \(MA\) o \(AR\), se utiliza la autocorrelación (ACF) y la autocorrelación parcial (PACF) respectivamente.
El
ACFdel conjunto de datos anterior muestra una dependencia de 1 rezago. Como la relación \(MA\) es capturada usando \(y_{t} = \theta\varepsilon_{t-1} + \varepsilon_{t}\), que es independiente de los términos de rezago, el ACF tiende a capturar el orden \(q\) apropiado de la serie \(MA\).Como puede observarse en la siguiente siguiente figura, la ACF no llega a cero después del orden definido, sino que se reduce a un valor pequeño. El intervalo de confianza se comprueba utilizando la relación \(\pm 2/\sqrt{N}\), donde \(1/\sqrt{N}\) representan una aproximación de la desviación estándar, que se cumple bajo la condición de independencia.
Veamos el impacto del componente \(MA\) de
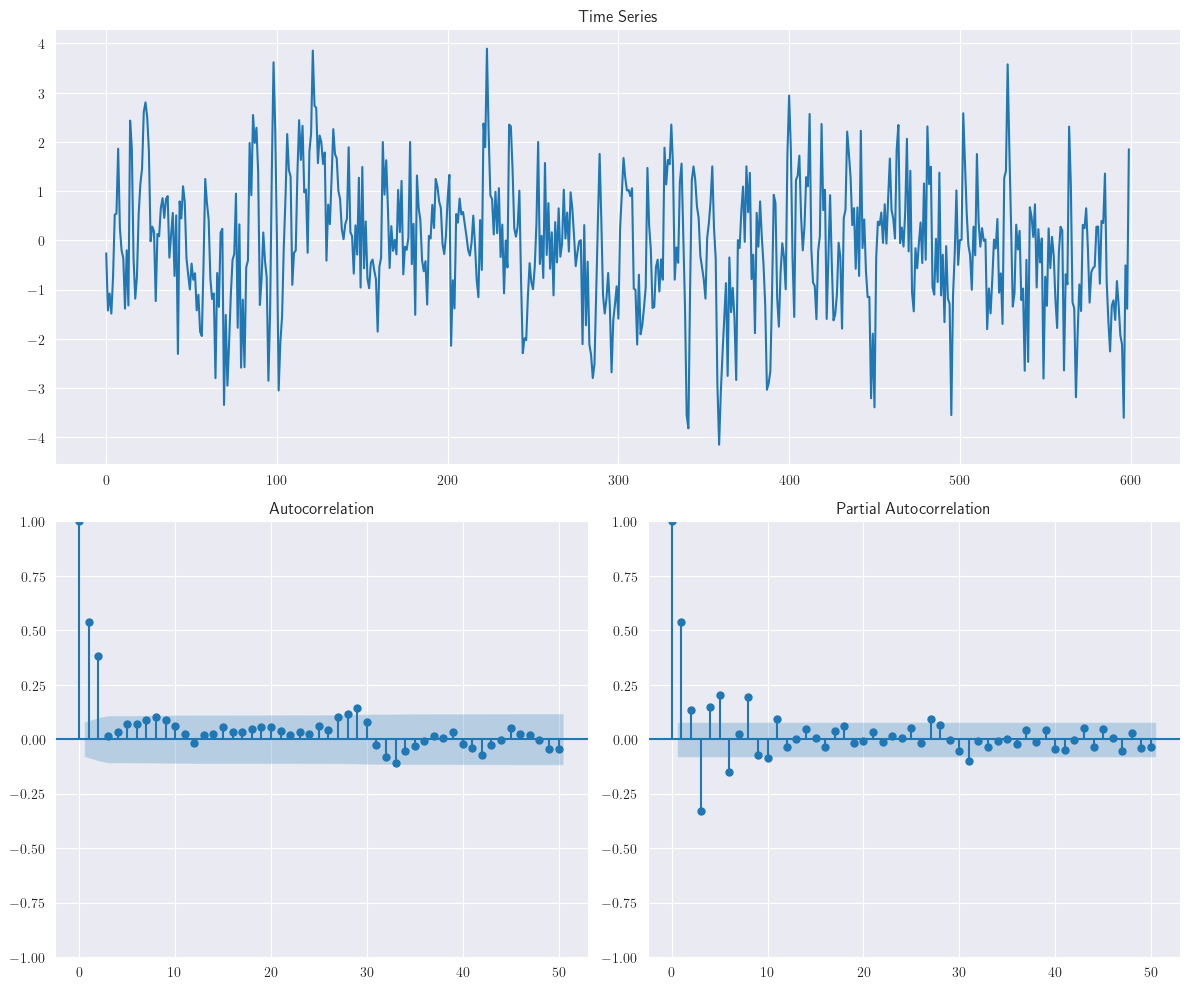
ACFyPACFcon un orden mayor de \(q\) utilizando el siguiente script, el cual generará series de tiempo de medias moviles de ordenes \(MA(2)\) y \(MA(3)\) sin impacto del componente autorregresivo. Además se generan, las funcionesACFyPACF, como en los anteriores ejemplos
ar = np.r_[1, 0]
ma = np.r_[1, 0.6, 0.7]
ma2_data = smtsa.arma_generate_sample(ar=ar, ma=ma, nsample=n)
plotds(ma2_data)
ar = np.r_[1, 0]
ma = np.r_[1, 0.6, 0.7, 0.5]
ma3_data = smtsa.arma_generate_sample(ar=ar, ma=ma, nsample=n)
plotds(ma3_data)
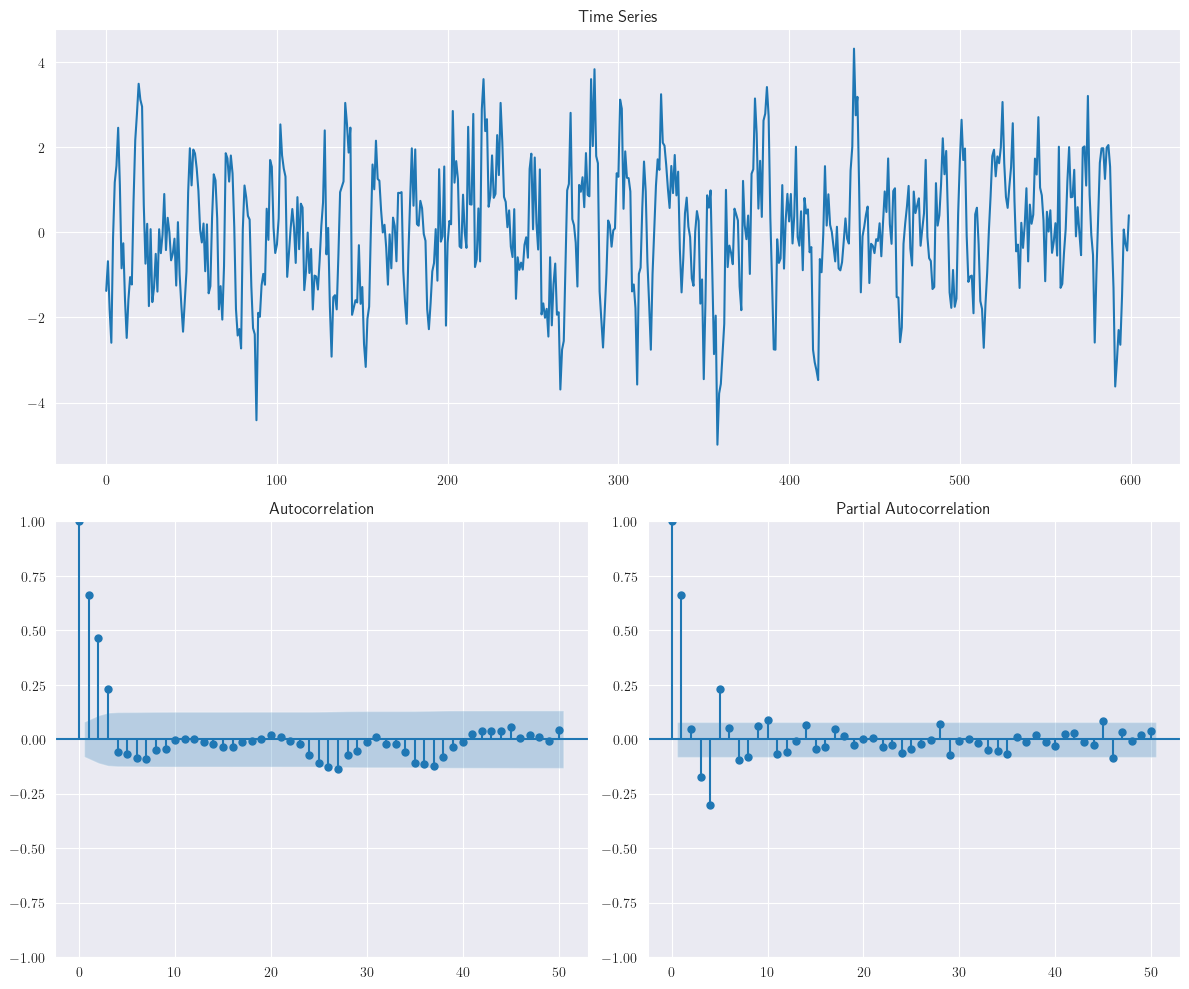
Normalmente, la ACF define bien la correlación serial del error y, por tanto, se utiliza para detectar \(MA(q)\); sin embargo, a medida que aumenta el orden y entran en escena otros componentes de la serie temporal, como la estacionalidad, tendencia o estacionariedad, la interpretación se complica. El \(MA(q)\) supone que el proceso es estacionario y que el error es un ruido blanco para garantizar una estimación insesgada.
Se puede construir un modelo \(MA(q)\) utilizando la función
ARIMAdel módulostatsmodel.tsa. Nótese que usamos siempre cero en la segunda componente de la función ARIMA, en la siguiente sección explicaremos el por qué de esto, al introducir el concepto de diferenciación. Un script de ejemplo para ajustar un modelo \(MA(1)\) es el siguiente
ma1 = smtsa.ARIMA(ma1_data.tolist(), order=(0, 0, 1)).fit()
Como el orden de \(AR\) se mantiene en cero,
smtsa.ARIMAconstruye un \(MA(1)\). El resumen del modelo devuelto porsmtsa.ARMAse muestra aquí
ma1.summary()
| Dep. Variable: | y | No. Observations: | 600 |
|---|---|---|---|
| Model: | ARIMA(0, 0, 1) | Log Likelihood | -842.209 |
| Date: | Fri, 31 Jan 2025 | AIC | 1690.418 |
| Time: | 21:42:07 | BIC | 1703.609 |
| Sample: | 0 | HQIC | 1695.553 |
| - 600 | |||
| Covariance Type: | opg |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| const | 0.0114 | 0.067 | 0.170 | 0.865 | -0.121 | 0.143 |
| ma.L1 | 0.6789 | 0.031 | 22.252 | 0.000 | 0.619 | 0.739 |
| sigma2 | 0.9689 | 0.055 | 17.504 | 0.000 | 0.860 | 1.077 |
| Ljung-Box (L1) (Q): | 0.18 | Jarque-Bera (JB): | 0.40 |
|---|---|---|---|
| Prob(Q): | 0.67 | Prob(JB): | 0.82 |
| Heteroskedasticity (H): | 0.92 | Skew: | 0.06 |
| Prob(H) (two-sided): | 0.54 | Kurtosis: | 3.05 |
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
Queda como ejercicio para el estudiante interpretar cada summary() basado en el análisis realizado para los modelos AR. Como puede verse, el modelo ha captado una correlación entre los residuos, que es bastante cercano al valor simulado de 0.7. Del mismo modo, ejecutamos el modelo para el conjunto de datos \(MA(3)\) y el resultado se muestra a continuación
ma3 = smtsa.ARIMA(ma3_data.tolist(), order=(0, 0, 3)).fit()
ma3.summary()
| Dep. Variable: | y | No. Observations: | 600 |
|---|---|---|---|
| Model: | ARIMA(0, 0, 3) | Log Likelihood | -852.803 |
| Date: | Fri, 31 Jan 2025 | AIC | 1715.606 |
| Time: | 21:42:07 | BIC | 1737.591 |
| Sample: | 0 | HQIC | 1724.165 |
| - 600 | |||
| Covariance Type: | opg |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| const | 0.0530 | 0.119 | 0.445 | 0.656 | -0.180 | 0.286 |
| ma.L1 | 0.6478 | 0.038 | 16.834 | 0.000 | 0.572 | 0.723 |
| ma.L2 | 0.6936 | 0.034 | 20.646 | 0.000 | 0.628 | 0.759 |
| ma.L3 | 0.5455 | 0.038 | 14.367 | 0.000 | 0.471 | 0.620 |
| sigma2 | 1.0020 | 0.058 | 17.254 | 0.000 | 0.888 | 1.116 |
| Ljung-Box (L1) (Q): | 0.01 | Jarque-Bera (JB): | 0.52 |
|---|---|---|---|
| Prob(Q): | 0.93 | Prob(JB): | 0.77 |
| Heteroskedasticity (H): | 0.93 | Skew: | -0.07 |
| Prob(H) (two-sided): | 0.63 | Kurtosis: | 3.01 |
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
Nótese también que el modelo ha captado correlaciones entre los residuos, que están bastante cercanas a los valores simulados 0.6, 0.7 y 0.5.
3.23. Creación de conjuntos de datos con ARIMA#
Las dos secciones anteriores describen el modelo autorregresivo \(AR(p)\), que realiza una regresión sobre sus propios términos rezagados y el modelo de media móvil \(MA(q)\) construye una función en términos de errores pasados. Los modelos \(AR(p)\) tienden a captar el efecto de reversión a la media (mean reversion), mientras que los modelos \(MA(q)\) tienden a captar el efecto de choque en el error, que no son normales o imprevistos. La reversión a la media es un término financiero para la suposición de que el precio de un activo tenderá a converger al precio promedio a lo largo del tiempo. Así pues, el modelo \(ARMA\) combina la potencia de los componentes \(AR\) y \(MA\). Un modelo de previsión de series temporales \(ARMA(p, q)\) incorpora el modelo \(AR\) de orden \(p\) y el modelo \(MA\) de orden \(q\), respectivamente.
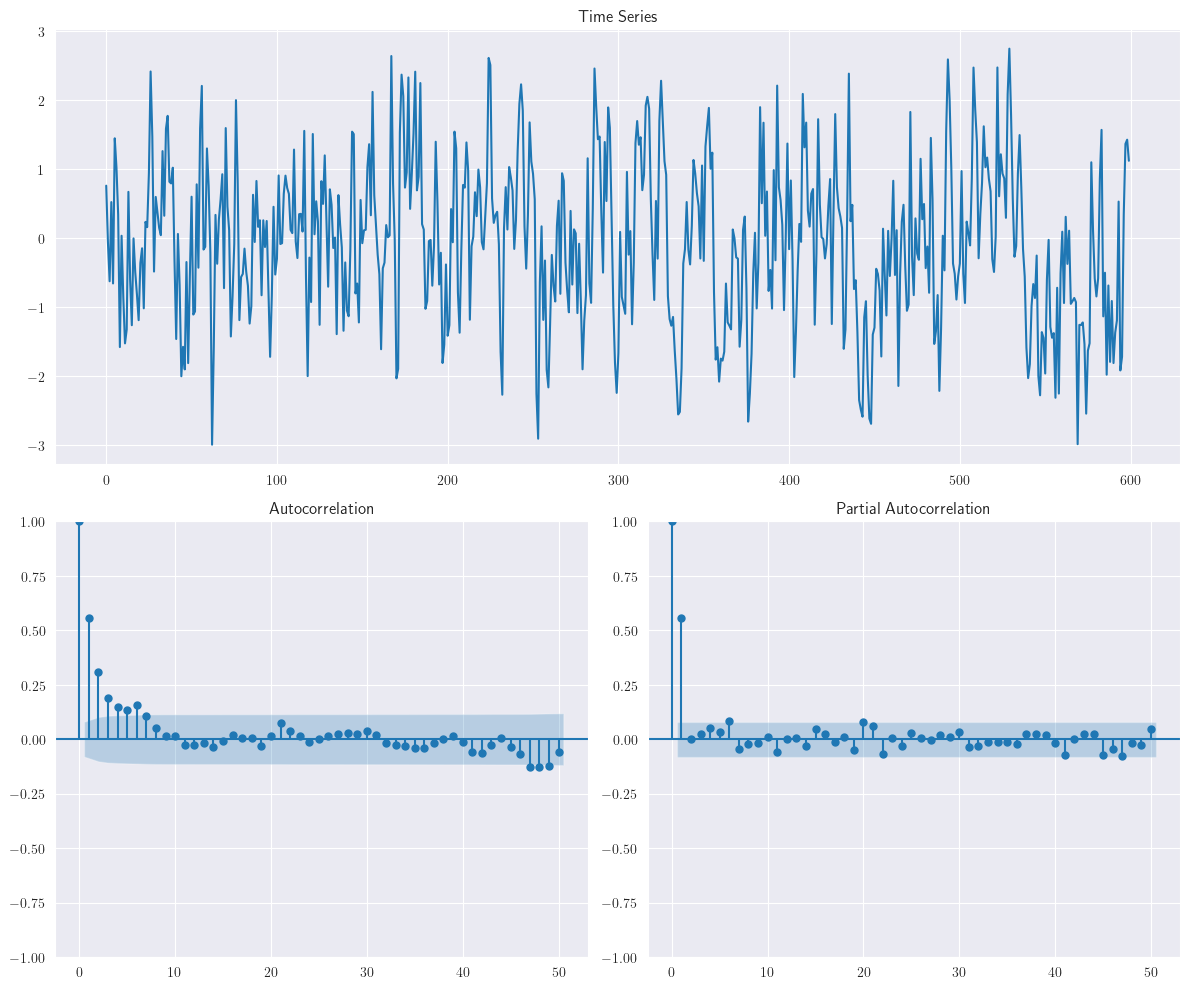
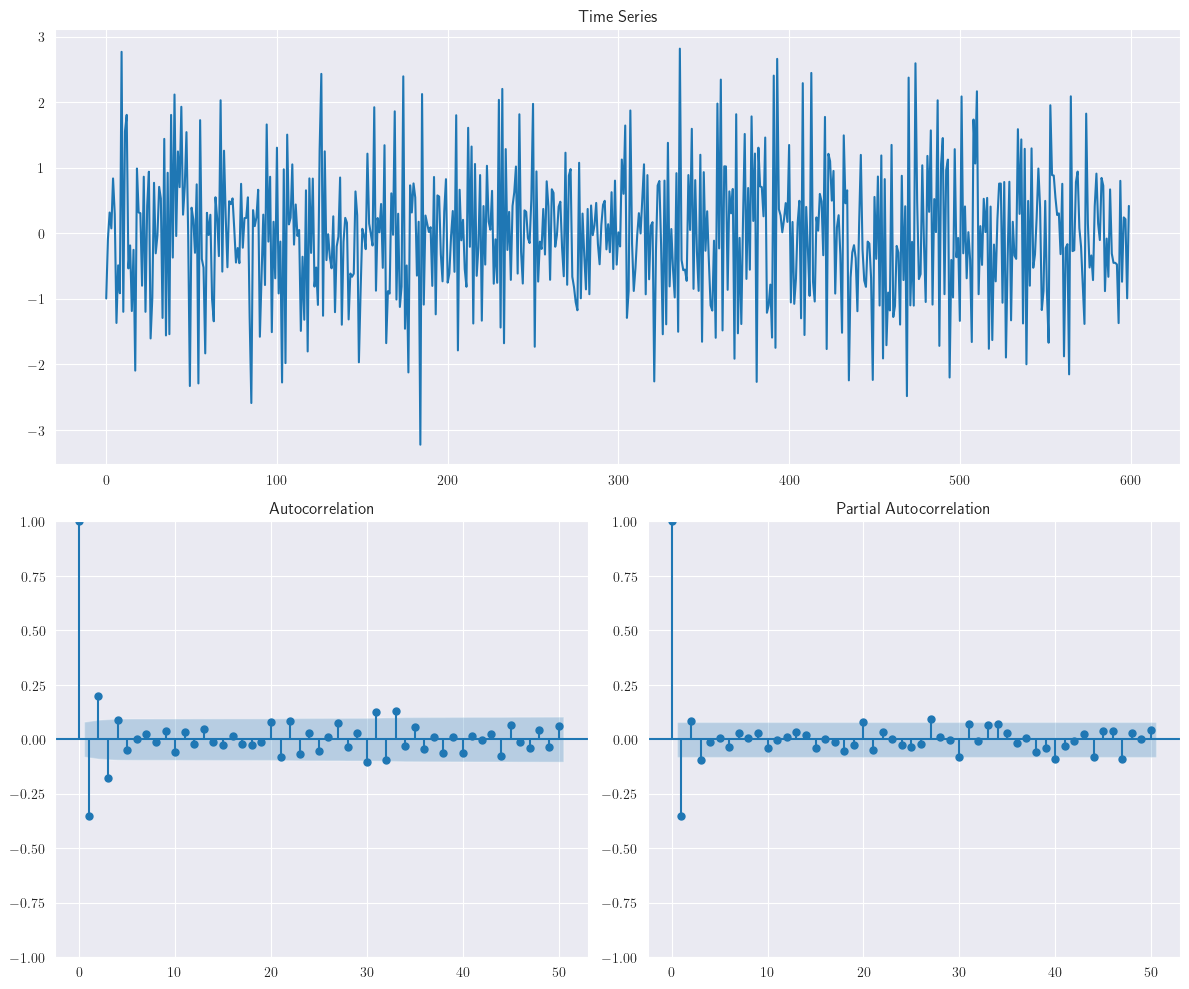
Vamos a generar un conjunto de datos \(ARMA(1,1)\) actualizando el script utilizado anteriormente con componentes
ARyMAactualizados. También restringiremos el número de muestras a 600 para simplificar:
n = 600
ar = np.r_[1, 0.6]
ma = np.r_[1, 0.3]
ar1ma1_data = smtsa.arma_generate_sample(ar=ar, ma=ma, nsample=n)
plotds(ar1ma1_data)
Podemos utilizar el test de Dickey Fuller, considerando como hipótesis nula \(H_{0}\): la serie de tiempo no es estacionaria. Como es usual, este tipo de tests entrega un \(p\)-value en el cual basamos la decisión de aceptar o rechazar la hipótesis inicial, con una significancia \(\alpha\) de 0.05. Esto puede ser llevado a cabo usando la función
adfuller()destattools.
from statsmodels.tsa import stattools
adf_result = stattools.adfuller(ar1ma1_data, autolag='AIC')
print('p-value of the ADF test in air miles flown:', adf_result[1])
p-value of the ADF test in air miles flown: 4.896647961106425e-29
La palabra clave argumento
autolag='AIC'indica a la función que el número de rezagos se elija para minimizar el criterio de información correspondiente.
Observación
Los procesos de ventas en general siguen un modelo \(ARMA(1,1)\), ya que las ventas en el tiempo \(t\) son función de las ventas anteriores que se produjeron en el tiempo \(t-1\), que interviene en el componente \(AR\). El componente \(MA\) de \(ARMA(1,1)\) se debe a las campañas temporales lanzadas por la empresa, como la distribución de cupones.
La distribución de cupones, por ejemplo, provocará un efecto de media móvil en el proceso. Las ventas aumentan temporalmente y el cambio en el efecto de las ventas es captado por el componente de media móvil. En la figura anterior, tanto
ACFcomoPACFmuestran una curva senoidal con una fuerte correlación en los rezagos iniciales; por lo tanto, los parámetros \(p\) como \(q\) están presentes.
En los datos de series temporales \(ARMA(1,1)\), tanto
ACFcomoPACFhan mostrado un patrón de onda senoidal, \(p\) y \(q\) afectan a la señal de la serie temporal. El impacto de los retardos puede calcularse mediante la curva impulso-respuesta (ver statsmodels.tsa.arima_process.arma_impulse_response), como se muestra en la siguiente figura, para la señal de serie temporal \(ARMA(1,1)\). La figura muestra que, tras cinco retardos, el efecto sobre la respuesta es mínimo
Observación
La IRF (Impulse Response Function) describe cómo una perturbación o “impulso” (cambio inesperado) en una variable del sistema afecta a esa variable y a otras variables del sistema a lo largo del tiempo. Permite estudiar cómo un choque inicial (por ejemplo, un cambio repentino en una variable económica) afecta el sistema a lo largo del tiempo.
from statsmodels.tsa import arima_process
plt.plot(arima_process.arma_impulse_response(ar, ma, leads=20))
plt.ylabel("Impact");
plt.xlabel("Lag");
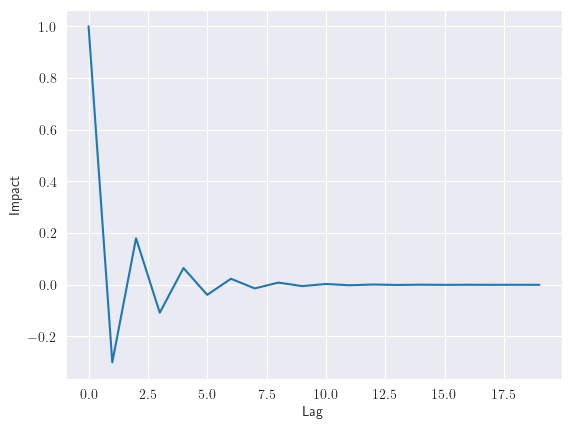
Para evaluar los valores
ARyMAde los datos, se utiliza la funciónARIMA.fit()del módulostatsmodels.tsa.api, como se muestra en el siguiente script:
ar1ma1 = smtsa.ARIMA(ar1ma1_data.tolist(), order=(1, 0, 1)).fit()
ar1ma1.summary()
| Dep. Variable: | y | No. Observations: | 600 |
|---|---|---|---|
| Model: | ARIMA(1, 0, 1) | Log Likelihood | -826.795 |
| Date: | Fri, 31 Jan 2025 | AIC | 1661.590 |
| Time: | 21:42:07 | BIC | 1679.178 |
| Sample: | 0 | HQIC | 1668.436 |
| - 600 | |||
| Covariance Type: | opg |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| const | -0.0224 | 0.032 | -0.700 | 0.484 | -0.085 | 0.040 |
| ar.L1 | -0.6278 | 0.084 | -7.518 | 0.000 | -0.791 | -0.464 |
| ma.L1 | 0.3226 | 0.102 | 3.164 | 0.002 | 0.123 | 0.522 |
| sigma2 | 0.9211 | 0.054 | 17.164 | 0.000 | 0.816 | 1.026 |
| Ljung-Box (L1) (Q): | 0.03 | Jarque-Bera (JB): | 0.05 |
|---|---|---|---|
| Prob(Q): | 0.87 | Prob(JB): | 0.98 |
| Heteroskedasticity (H): | 1.02 | Skew: | 0.02 |
| Prob(H) (two-sided): | 0.88 | Kurtosis: | 2.97 |
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
El resultado del modelo muestra valores del coeficientes \(AR\) y \(MA\) cercanos de los valores 0.6 y 0.3 utilizados por el componente \(AR\) y \(MA\), respectivamente, para generar la señal de la serie temporal. Asimismo, el Criterio de información de Akaike (AIC) lo usamos como criterio para establecer una evaluación para las órdenes \(p\) y \(q\). Una ilustración de la minimización del \(AIC\) en el conjunto de datos \(ARMA(1,1)\) se muestra a continuación:
aicVal=[]
for ari in range(1, 3):
for maj in range(1,3):
arma_obj = smtsa.ARIMA(ar1ma1_data.tolist(), order=(ari, 0, maj)).fit()
aicVal.append([ari, maj, arma_obj.aic])
dfAIC = pd.DataFrame(aicVal, columns=['AR(p)', 'MA(q)', 'AIC'])
dfAIC
| AR(p) | MA(q) | AIC | |
|---|---|---|---|
| 0 | 1 | 1 | 1661.589913 |
| 1 | 1 | 2 | 1663.118934 |
| 2 | 2 | 1 | 1663.291217 |
| 3 | 2 | 2 | 1663.488211 |
La tabla anterior muestra que \(ARMA(1, 1)\) es el modelo más óptimo con un valor \(AIC\) mínimo; por lo tanto, se preferirá \(ARMA(1, 1)\) a otros modelos. Ilustremos un modelo \(ARMA\) utilizando datos de series en tiempo real. El conjunto de datos seleccionado para la siguiente ilustración, corresponde a los precios de las acciones de IBM de 1962 a 1965. El primer paso consiste en cargar los módulos y el conjunto de datos en el entorno
Python.
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
import statsmodels.api as sm
ibm_df = pd.read_csv('datasets/ibm-common-stock-closing-prices.csv')
ibm_df.rename(columns={'IBM common stock closing prices': 'Close_Price'}, inplace=True)
ibm_df=ibm_df.dropna()
ibm_df.head()
| Date | Close_Price | |
|---|---|---|
| 0 | 1962-01-02 | 572.00 |
| 1 | 1962-01-03 | 577.00 |
| 2 | 1962-01-04 | 571.25 |
| 3 | 1962-01-05 | 560.00 |
| 4 | 1962-01-08 | 549.50 |
El script anterior utiliza
pandaspara cargar el conjunto de datos. Los nombres de las columnas se renombran utilizando la funciónrenamesoportada porpandas DataFrame. El conjunto de datos tiene el siguiente aspecto:
El gráfico IBM muestra una tendencia significativa de los datos a lo largo del tiempo. El siguiente paso en el proceso es observar los gráficos de
ACFyPACFlos cuales pueden obtenerse utilizando la funciónplotdsdefinida anteriormente
plotds(ibm_df.Close_Price)
La ACF decae linealmente, mostrando una fuerte correlación en serie; sin embargo, la autocorrelación parcial sólo muestra una autocorrelación positiva significativa, la corrección debe hacerse utilizando el componente \(AR\) con correlación de primer orden.
Para obtener los órdenes \(p\) y \(q\) óptimos para \(ARMA\), se realiza una búsqueda en red (GridSearch) con la minimización del \(AIC\) como criterio de búsqueda utilizando el siguiente script
aicVal=[]
for ari in range(1, 3):
for maj in range(0,3):
arma_obj = smtsa.ARIMA(ibm_df.Close_Price.tolist(), order=(ari, 0, maj)).fit()
aicVal.append([ari, maj, arma_obj.aic])
dfAIC = pd.DataFrame(aicVal, columns=['AR(p)', 'MA(q)', 'AIC'])
dfAIC
| AR(p) | MA(q) | AIC | |
|---|---|---|---|
| 0 | 1 | 0 | 6697.784241 |
| 1 | 1 | 1 | 6699.670009 |
| 2 | 1 | 2 | 6701.984008 |
| 3 | 2 | 0 | 6699.671126 |
| 4 | 2 | 1 | 6700.721967 |
| 5 | 2 | 2 | 6702.721949 |
Para obtener la fila con el menor valor de AIC usamos
dfAIC.nsmallest(n=1, columns="AIC")
| AR(p) | MA(q) | AIC | |
|---|---|---|---|
| 0 | 1 | 0 | 6697.784241 |
La función
ARIMA.fitse utiliza para ajustar el modelo de previsión \(ARMA\) con \(p\) y \(q\) definidos utilizando el criterio de máxima verosimilitud. El \(AIC\) recomienda el modelo \(ARMA(1, 0)\) como modelo óptimo con el mínimo valor de \(AIC\), aunque también puede utilizarse el modelo \(ARMA(1, 1)\) dado que el \(AIC\) es bastante similar. El modelo \(ARMA(1, 0)\) se reajusta como modelo óptimo utilizando el siguiente script
arma_obj_fin = smtsa.ARIMA(ibm_df.Close_Price.tolist(), order=(1, 0, 0)).fit()
ibm_df['ARMA']=arma_obj_fin.predict()
f, axarr = plt.subplots(1, sharex=True)
f.set_size_inches(5.5, 5.5)
ibm_df['Close_Price'].iloc[1:].plot(color='b', linestyle = '-', ax=axarr)
ibm_df['ARMA'].iloc[1:].plot(color='r', linestyle = '--', ax=axarr)
axarr.set_title('ARMA(1,0)')
plt.xlabel('Index')
plt.ylabel('Closing price');
f, axarr = plt.subplots(1, sharex=True)
f.set_size_inches(5.5, 5.5)
ibm_df['Close_Price'].iloc[1:].plot(color='b', linestyle = '-', ax=axarr)
ibm_df['ARMA'].iloc[1:].plot(color='r', linestyle = '--', ax=axarr)
axarr.set_title('ARMA(1,1)')
plt.xlabel('Index')
plt.ylabel('Closing price');
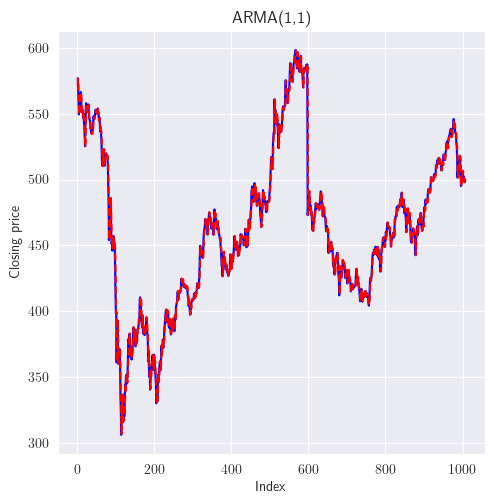
Una de las principales limitaciones de estos modelos es que ignoran el factor de volatilidad, lo que hace que la señal no sea estacionaria. El modelo \(AR\) considera un proceso estacionario, es decir, el término de error es
iidy sigue una distribución normal \(\varepsilon_{t} \sim N(0, \sigma_{\epsilon}^{2})\) y \(|\phi|<1\).La condición \(|\phi|<1\) hace que la serie temporal sea una serie temporal finita ya que el efecto de las observaciones más recientes en la serie temporal sería mayor en comparación con las observaciones anteriores. Las series que no satisfacen estos supuestos caen en series no estacionarias.
ar = np.r_[1, 1.05]
ma = np.r_[1, 0]
ar1_data = smtsa.arma_generate_sample(ar=ar, ma=ma, nsample=n)
plotds(ar1_data)
Del gráfico anterior se desprende que la varianza del proceso sigue aumentando al final del conjunto de datos y se observa una fuerte tendencia en la ACF. El modelo
ARIMAque se analiza en la sección siguiente tiene en cuenta escenarios no estacionarios para la predicción.
3.24. ARIMA#
\(ARIMA\), también conocido como modelo Box-Jenkins, es una generalización del modelo \(ARMA\) incluyendo componentes integrados. Los componentes integrados son útiles cuando los datos son no estacionarios, y la parte integrada del \(ARIMA\) ayuda a reducir la no estacionariedad. \(ARIMA\) aplica la diferenciación a las series temporales una o más veces para eliminar el efecto de no estacionariedad. Los ordenes \(p, d, q\) del modelo \(ARIMA(p, d, q)\) representan el orden de los componentes \(AR\), de diferenciación y \(MA\).
La principal diferencia entre los modelos \(ARMA\) y \(ARIMA\) es el componente \(d\), que actualiza la serie sobre la que se construye el modelo de predicción. El componente \(d\) tiene por objeto hacer la serie estacionaria y de esta forma el modelo \(ARMA\) puede aplicarse al conjunto de datos sin tendencia.
Ilustremos un modelo \(ARIMA\) utilizando el conjunto de datos de series temporales del índice
Dow Jones (DJIA)de 2016. El conjunto de datosDJIAcon sus gráficosACFyPACFbásicos se muestra en la siguiente figura
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
from statsmodels.tsa.arima_model import ARIMA
import statsmodels.api as sm
import statsmodels.tsa.api as smtsa
djia_df = pd.read_excel('datasets/DJIA_Jan2016_Dec2016.xlsx')
djia_df.head()
| Date | Open | High | Low | Close | Adj Close | Volume | |
|---|---|---|---|---|---|---|---|
| 0 | 2016-01-04 | 17405.480469 | 17405.480469 | 16957.630859 | 17148.939453 | 17148.939453 | 148060000 |
| 1 | 2016-01-05 | 17147.500000 | 17195.839844 | 17038.609375 | 17158.660156 | 17158.660156 | 105750000 |
| 2 | 2016-01-06 | 17154.830078 | 17154.830078 | 16817.619141 | 16906.509766 | 16906.509766 | 120250000 |
| 3 | 2016-01-07 | 16888.359375 | 16888.359375 | 16463.630859 | 16514.099609 | 16514.099609 | 176240000 |
| 4 | 2016-01-08 | 16519.169922 | 16651.890625 | 16314.570313 | 16346.450195 | 16346.450195 | 141850000 |
Analicemos la columna Date y utilicémosla como índice de fila para el DataFrame y utilicemosla como columna
djia_df['Date'] = pd.to_datetime(djia_df['Date'], '%Y-%m-%d')
djia_df.index = djia_df['Date']
djia_df.drop('Date', axis=1, inplace=True)
djia_df.head()
| Open | High | Low | Close | Adj Close | Volume | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 2016-01-04 | 17405.480469 | 17405.480469 | 16957.630859 | 17148.939453 | 17148.939453 | 148060000 |
| 2016-01-05 | 17147.500000 | 17195.839844 | 17038.609375 | 17158.660156 | 17158.660156 | 105750000 |
| 2016-01-06 | 17154.830078 | 17154.830078 | 16817.619141 | 16906.509766 | 16906.509766 | 120250000 |
| 2016-01-07 | 16888.359375 | 16888.359375 | 16463.630859 | 16514.099609 | 16514.099609 | 176240000 |
| 2016-01-08 | 16519.169922 | 16651.890625 | 16314.570313 | 16346.450195 | 16346.450195 | 141850000 |
djia_df=djia_df.dropna()
plotds(djia_df['Close'], nlag=50)
El conjunto de datos muestra claramente una señal no estacionaria con una tendencia creciente. El
ACFtambién muestra un decaimiento exponencial, mientras que laPACFtiene una fuerte correlación en el retardo 2. La no estacionariedad también puede comprobarse evaluando la media y la varianza en distintos periodos de tiempo. La diferencia en la media y la varianza valida la hipótesis de no estacionariedad. Por ejemplo, dividimos el conjunto de datos delDJIAen dos semestres, de enero a junio de 2016 y de julio a diciembre de 2016, y evaluamos la media y la varianza para cada semestre del siguiente modo:
mean1, mean2 =djia_df.iloc[:125].Close.mean(), djia_df.iloc[125:].Close.mean()
var1, var2 = djia_df.iloc[:125].Close.var(), djia_df.iloc[125:].Close.var()
print('mean1=%f, mean2=%f' % (mean1, mean2))
print('variance1=%f, variance2=%f' % (var1, var2))
mean1=17226.579164, mean2=18616.603593
variance1=487045.734003, variance2=325183.639530
La media y la varianza evaluadas para ambos semestres muestran una diferencia significativa en los valores de la media y la varianza, lo que sugiere que los datos no son estacionarios. Otra forma de evaluar la no estacionariedad es utilizar pruebas estadísticas como la prueba de
Dickey-Fuller (ADF). El \(ADF\) es una prueba de raíz unitaria que evalúa la fuerza de la tendencia en una componente de la serie temporal.
En otras palabras, la hipótesis nula es la presencia de la raíz unitaria o no estacionariedad mientras que la hipótesis alternativa sugiere la estacionariedad de los datos. Realicemos la prueba
ADFpara el conjunto de datosDJIA:
from statsmodels.tsa.stattools import adfuller
adf_result= adfuller(djia_df.Close.tolist())
print('ADF Statistic: %f' % adf_result[0])
print('p-value: %f' % adf_result[1])
ADF Statistic: -0.462320
p-value: 0.899162
Idealmente, un valor más negativo del estadístico ADF representará una señal estacionaria. Para el conjunto de datos, como el valor \(p\) es bastante alto, no podemos rechazar la hipótesis nula, lo que la convierte en una señal no estacionaria. La mayoría de los paquetes garantizan la estacionariedad antes de ejecutar los modelos.
La mayoría de los paquetes escritos en
Pythoncomprueban la estacionariedad de un conjunto de datos. La diferenciación ayudará a que la señal sea estacionaria. Tracemos las series temporales originales y las de primera diferencia
first_order_diff = djia_df['Close'].diff(1).dropna()
fig, ax = plt.subplots(2, sharex=True)
fig.set_size_inches(5.5, 5.5)
djia_df['Close'].plot(ax=ax[0], color='b')
ax[0].set_title('Close values of DJIA during Jan 2016-Dec 2016')
first_order_diff.plot(ax=ax[1], color='r')
ax[1].set_title('First-order differences of DJIA during Jan 2016-Dec 2016');
plotds(first_order_diff, nlag=50)
adf_result= adfuller(first_order_diff)
print('ADF Statistic: %f' % adf_result[0])
print('p-value: %f' % adf_result[1])
ADF Statistic: -17.135094
p-value: 0.000000
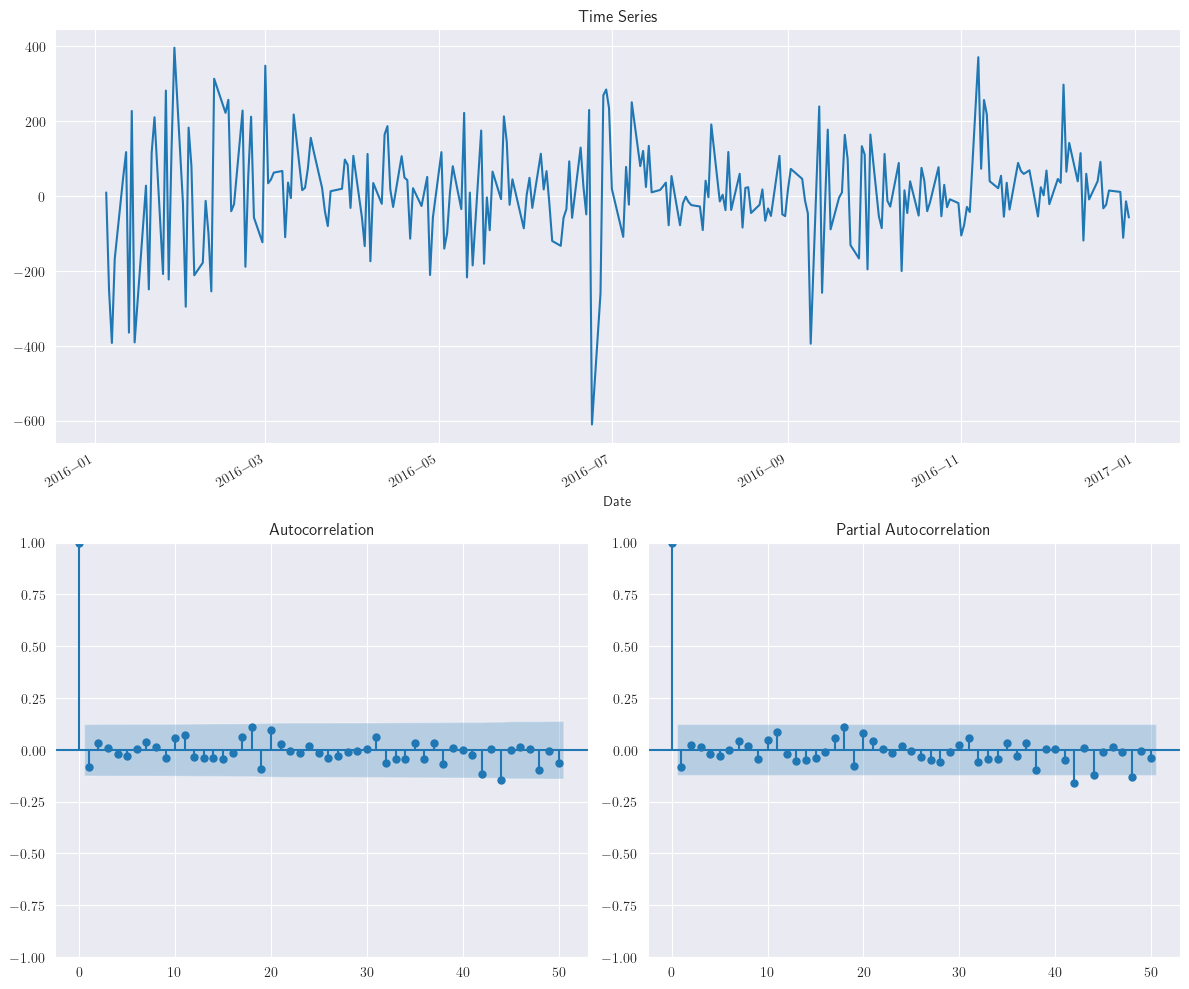
El estadístico ADF de los residuos tiene un valor de -17.135094 con un valor \(p=0.000000\), lo que indica que la serie de tiempo es estacionaria; sin embargo, tanto la
ACFcomo elPACFno muestran mucha tendencia del componente de media móvil, mostrando un comportamiento de paseo aleatorio. Además, otra forma de ejecutar es optimizar utilizando AIC como criterio
aicVal=[]
for d in range(1,3):
for ari in range(0, 3):
for maj in range(0,3):
try:
arima_obj = smtsa.ARIMA(djia_df['Close'].tolist(), order=(ari, d, maj))
arima_obj_fit=arima_obj.fit()
aicVal.append([ari, d, maj, arima_obj_fit.aic])
except ValueError:
pass
dfAIC = pd.DataFrame(aicVal, columns=['AR(p)', 'd', 'MA(q)', 'AIC'])
dfAIC
| AR(p) | d | MA(q) | AIC | |
|---|---|---|---|---|
| 0 | 0 | 1 | 0 | 3182.101860 |
| 1 | 0 | 1 | 1 | 3182.670296 |
| 2 | 0 | 1 | 2 | 3184.581580 |
| 3 | 1 | 1 | 0 | 3182.624230 |
| 4 | 1 | 1 | 1 | 3184.571180 |
| 5 | 1 | 1 | 2 | 3186.467647 |
| 6 | 2 | 1 | 0 | 3184.573347 |
| 7 | 2 | 1 | 1 | 3186.447498 |
| 8 | 2 | 1 | 2 | 3188.433187 |
| 9 | 0 | 2 | 0 | 3362.452244 |
| 10 | 0 | 2 | 1 | 3181.460160 |
| 11 | 0 | 2 | 2 | 3182.546756 |
| 12 | 1 | 2 | 0 | 3280.491626 |
| 13 | 1 | 2 | 1 | 3182.515214 |
| 14 | 1 | 2 | 2 | 3184.482508 |
| 15 | 2 | 2 | 0 | 3252.415990 |
| 16 | 2 | 2 | 1 | 3184.488464 |
| 17 | 2 | 2 | 2 | 3186.338422 |
print('Best ARIMA parameters based on AIC:\n')
dfAIC[dfAIC.AIC == dfAIC.AIC.min()]
Best ARIMA parameters based on AIC:
| AR(p) | d | MA(q) | AIC | |
|---|---|---|---|---|
| 10 | 0 | 2 | 1 | 3181.46016 |
Elejimos \(ARIMA(0, 2, 1)\) para el ajuste y la evaluación del modelo, por contar con el menor \(AIC\). \(ARIMA(0, 2, 1)\) aplica una diferenciación de segundo orden y un componente de media móvil de primer orden para determinar la relación entre las observaciones. El parámetro del modelo se configura como se muestra en el siguiente script
arima_obj = smtsa.ARIMA(djia_df['Close'].tolist(), order=(0, 2, 1))
arima_obj_fit = arima_obj.fit()
arima_obj_fit.summary()
| Dep. Variable: | y | No. Observations: | 252 |
|---|---|---|---|
| Model: | ARIMA(0, 2, 1) | Log Likelihood | -1588.730 |
| Date: | Fri, 31 Jan 2025 | AIC | 3181.460 |
| Time: | 21:42:11 | BIC | 3188.503 |
| Sample: | 0 | HQIC | 3184.295 |
| - 252 | |||
| Covariance Type: | opg |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| ma.L1 | -0.9983 | 0.153 | -6.535 | 0.000 | -1.298 | -0.699 |
| sigma2 | 1.828e+04 | 2884.024 | 6.340 | 0.000 | 1.26e+04 | 2.39e+04 |
| Ljung-Box (L1) (Q): | 1.60 | Jarque-Bera (JB): | 47.47 |
|---|---|---|---|
| Prob(Q): | 0.21 | Prob(JB): | 0.00 |
| Heteroskedasticity (H): | 0.46 | Skew: | -0.22 |
| Prob(H) (two-sided): | 0.00 | Kurtosis: | 5.09 |
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
pred=np.append([0,0], arima_obj_fit.fittedvalues.tolist())
n_first = pred.shape[0] - djia_df.shape[0]
djia_df['ARIMA']=pred[n_first:]
diffval=np.append([0,0], arima_obj_fit.resid)
djia_df['diffval']=diffval[n_first:]
La comparación con los valores reales y previstos se obtiene y visualiza utilizando el siguiente script
f, axarr = plt.subplots(1, sharex=True)
f.set_size_inches(5.5, 5.5)
djia_df['Close'].iloc[200:].plot(color='b', linestyle = '-', ax=axarr)
djia_df['ARIMA'].iloc[200:].plot(color='r', linestyle = '--', ax=axarr)
axarr.set_title('ARIMA(0,2,1)')
plt.xlabel('Index')
plt.ylabel('Closing price');
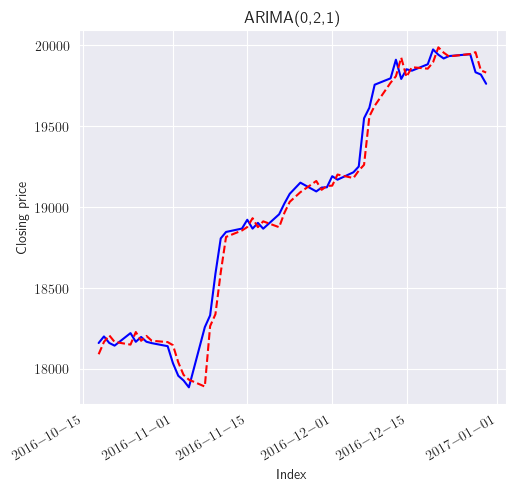
La ampliación del modelo \(ARIMA\) incluye el componente de estacionalidad para \(AR\), \(I\), y \(MA\) representado en mayúsculas. El \(ARIMA\) estacional se representa como
\[ ARIMA(p, d, q) (P, D, Q)_{m}, \]donde \(P, D\) y \(Q\) representan la parte estacional de la media autorregresiva, integrada y media móvil, respectivamente.
La \(m\) en el modelo \(ARIMA\) estacional representa el número de periodos por estación. En los casos en los que existe estacionalidad, pueden ser necesarios los pasos adicionales de diferencia estacional y ajuste estacional para garantizar que la señal sea estacionaria. Por ejemplo, si se observan los gráficos de diferencia
ACF y PACF del DJIA, la autocorrelación se vuelve ligeramente significativa en el índice 42, lo que significa que puede haber estacionalidad.Un gráfico de la función de autocorrelación retardada debería mostrar una autocorrelación positiva relativamente grande en el retardo 42, con picos más pequeños en los retardos 84 y 126 (si se examina un mayor número de retardo).. La estacionalidad está presente en la primera diferencia y puede verse utilizando las siguientes líneas de código
x=djia_df['Close']-djia_df['Close'].shift(42)
x.plot();
La estacionalidad precedente puede corregirse utilizando \(ARIMA\) estacional soportado en el modelo
statmodels.SARIMAX. El script para configurar un modelo \(ARIMA\) estacional para el conjunto de datosDJIAes el siguiente:
x=djia_df['Close']-djia_df['Close'].shift(42)
mod = sm.tsa.statespace.SARIMAX(djia_df['Close'], trend='n', order=(0, 2, 1),
seasonal_order=(1, 1, 1, 42))
sarimax= mod.fit()
sarimax.summary()
RUNNING THE L-BFGS-B CODE
* * *
Machine precision = 2.220D-16
N = 4 M = 10
At X0 0 variables are exactly at the bounds
At iterate 0 f= 5.54082D+00 |proj g|= 1.11811D-01
This problem is unconstrained.
At iterate 5 f= 5.50715D+00 |proj g|= 5.01653D-03
At iterate 10 f= 5.50497D+00 |proj g|= 8.83394D-03
At iterate 15 f= 5.49379D+00 |proj g|= 1.06844D-01
At iterate 20 f= 5.43162D+00 |proj g|= 3.52349D-02
At iterate 25 f= 5.42290D+00 |proj g|= 3.53907D-05
* * *
Tit = total number of iterations
Tnf = total number of function evaluations
Tnint = total number of segments explored during Cauchy searches
Skip = number of BFGS updates skipped
Nact = number of active bounds at final generalized Cauchy point
Projg = norm of the final projected gradient
F = final function value
* * *
N Tit Tnf Tnint Skip Nact Projg F
4 26 34 1 0 0 2.631D-06 5.423D+00
F = 5.4228981927828199
CONVERGENCE: NORM_OF_PROJECTED_GRADIENT_<=_PGTOL
| Dep. Variable: | Close | No. Observations: | 252 |
|---|---|---|---|
| Model: | SARIMAX(0, 2, 1)x(1, 1, 1, 42) | Log Likelihood | -1366.570 |
| Date: | Fri, 31 Jan 2025 | AIC | 2741.141 |
| Time: | 21:42:15 | BIC | 2754.491 |
| Sample: | 0 | HQIC | 2746.539 |
| - 252 | |||
| Covariance Type: | opg |
| coef | std err | z | P>|z| | [0.025 | 0.975] | |
|---|---|---|---|---|---|---|
| ma.L1 | -1.0000 | 16.163 | -0.062 | 0.951 | -32.678 | 30.678 |
| ar.S.L42 | -0.2542 | 0.093 | -2.727 | 0.006 | -0.437 | -0.072 |
| ma.S.L42 | -0.4671 | 0.130 | -3.597 | 0.000 | -0.722 | -0.213 |
| sigma2 | 2.355e+04 | 3.8e+05 | 0.062 | 0.951 | -7.22e+05 | 7.69e+05 |
| Ljung-Box (L1) (Q): | 0.07 | Jarque-Bera (JB): | 21.28 |
|---|---|---|---|
| Prob(Q): | 0.79 | Prob(JB): | 0.00 |
| Heteroskedasticity (H): | 0.41 | Skew: | -0.24 |
| Prob(H) (two-sided): | 0.00 | Kurtosis: | 4.49 |
Warnings:
[1] Covariance matrix calculated using the outer product of gradients (complex-step).
El modelo muestra una mejora significativa en términos de AIC y puede optimizarse aún más para diferentes componentes del modelo
SARIMAX
3.25. Intervalo de confianza#
Una de las preguntas más frecuentes en previsión es: ¿Cuál es el intervalo de confianza de las estimaciones? El nivel de confianza de un modelo de previsión viene definido por el parámetro \(\alpha\) de la función de previsión. El valor \(\alpha = 0.05\) representa una estimación con un 95% de confianza, lo que puede interpretarse como que las estimaciones devueltas por el modelo tienen una probabilidad del 5% de no caer en el intervalo de distribución definido. El intervalo de confianza se evalúa del siguiente modo
Aquí, \(Z_{\alpha}\) es el valor crítico definido en función de \(\alpha\). Para el valor \(\alpha=0.05\), el valor crítico es \(1.96\). El intervalo de confianza con un valor \(\alpha\) de \(0.05\) para el conjunto de datos
DJIAmodelado utilizando el modelo \(ARIMA(0,2,1)\) puede obtenerse utilizando la función de previsión del objetoarima_obj_fit
tau_h = 40
forecast = arima_obj_fit.get_forecast(tau_h)
yhat = forecast.predicted_mean
yhat_conf_int = forecast.conf_int(alpha=0.05)
yhat.shape
(40,)
plt.plot(yhat)
plt.plot(yhat_conf_int)
plt.xlabel('Forecasting Index')
plt.ylabel('Forecasted value');
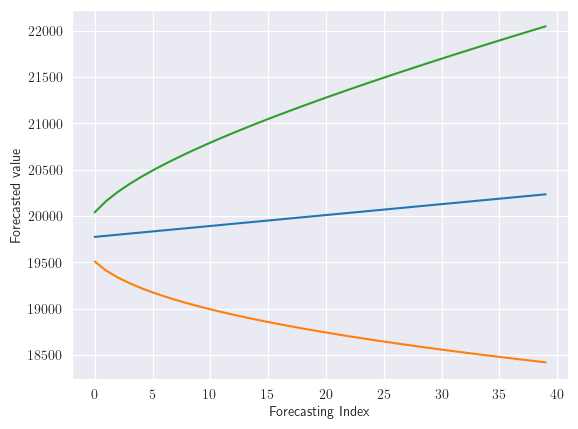
3.26. Yahoo Finance#
Una opción gratuita, en el caso de que no desee pagar por los servicios de APIs tales como la de finnhub, es Yahoo Finance. En esta sección estudiaremos como hacer uso de la API de Yahoo Finance y además, como podemos descargar la información necesaria para un EDA y graficos de velas por ejemplo.
Descargaremos para este ejemplo los datos de las acciones de Apple utilizando la API de yahoo Finance. Para esto debe primero que todo, debe instalar la librería que le permitirá hacer uso de API
pip install yfinance
Para usar la API, solo tiene que crear un objeto ticker con su respectivo símbolo, y luego puede realizar simples queries a métodos en el objeto que devuelven todo lo necesario par analizar series de tiempo financieras. Si usamos la función
.info()podemos acceder a toda la información que podemos consultar sobre una acción
import yfinance as yf
msft = yf.Ticker("AAPL")
msft.info
{'address1': 'One Apple Park Way',
'city': 'Cupertino',
'state': 'CA',
'zip': '95014',
'country': 'United States',
'phone': '(408) 996-1010',
'website': 'https://www.apple.com',
'industry': 'Consumer Electronics',
'industryKey': 'consumer-electronics',
'industryDisp': 'Consumer Electronics',
'sector': 'Technology',
'sectorKey': 'technology',
'sectorDisp': 'Technology',
'longBusinessSummary': 'Apple Inc. designs, manufactures, and markets smartphones, personal computers, tablets, wearables, and accessories worldwide. The company offers iPhone, a line of smartphones; Mac, a line of personal computers; iPad, a line of multi-purpose tablets; and wearables, home, and accessories comprising AirPods, Apple TV, Apple Watch, Beats products, and HomePod. It also provides AppleCare support and cloud services; and operates various platforms, including the App Store that allow customers to discover and download applications and digital content, such as books, music, video, games, and podcasts, as well as advertising services include third-party licensing arrangements and its own advertising platforms. In addition, the company offers various subscription-based services, such as Apple Arcade, a game subscription service; Apple Fitness+, a personalized fitness service; Apple Music, which offers users a curated listening experience with on-demand radio stations; Apple News+, a subscription news and magazine service; Apple TV+, which offers exclusive original content; Apple Card, a co-branded credit card; and Apple Pay, a cashless payment service, as well as licenses its intellectual property. The company serves consumers, and small and mid-sized businesses; and the education, enterprise, and government markets. It distributes third-party applications for its products through the App Store. The company also sells its products through its retail and online stores, and direct sales force; and third-party cellular network carriers, wholesalers, retailers, and resellers. Apple Inc. was founded in 1976 and is headquartered in Cupertino, California.',
'fullTimeEmployees': 164000,
'companyOfficers': [{'maxAge': 1,
'name': 'Mr. Timothy D. Cook',
'age': 63,
'title': 'CEO & Director',
'yearBorn': 1961,
'fiscalYear': 2023,
'totalPay': 16239562,
'exercisedValue': 0,
'unexercisedValue': 0},
{'maxAge': 1,
'name': 'Mr. Jeffrey E. Williams',
'age': 60,
'title': 'Chief Operating Officer',
'yearBorn': 1964,
'fiscalYear': 2023,
'totalPay': 4637585,
'exercisedValue': 0,
'unexercisedValue': 0},
{'maxAge': 1,
'name': 'Ms. Katherine L. Adams',
'age': 60,
'title': 'Senior VP, General Counsel & Secretary',
'yearBorn': 1964,
'fiscalYear': 2023,
'totalPay': 4618064,
'exercisedValue': 0,
'unexercisedValue': 0},
{'maxAge': 1,
'name': "Ms. Deirdre O'Brien",
'age': 57,
'title': 'Chief People Officer & Senior VP of Retail',
'yearBorn': 1967,
'fiscalYear': 2023,
'totalPay': 4613369,
'exercisedValue': 0,
'unexercisedValue': 0},
{'maxAge': 1,
'name': 'Mr. Kevan Parekh',
'age': 52,
'title': 'Senior VP & CFO',
'yearBorn': 1972,
'fiscalYear': 2023,
'exercisedValue': 0,
'unexercisedValue': 0},
{'maxAge': 1,
'name': 'Suhasini Chandramouli',
'title': 'Director of Investor Relations',
'fiscalYear': 2023,
'exercisedValue': 0,
'unexercisedValue': 0},
{'maxAge': 1,
'name': 'Mr. Greg Joswiak',
'title': 'Senior Vice President of Worldwide Marketing',
'fiscalYear': 2023,
'exercisedValue': 0,
'unexercisedValue': 0},
{'maxAge': 1,
'name': 'Mr. Michael Fenger',
'title': 'VP of Worldwide Sales',
'fiscalYear': 2023,
'exercisedValue': 0,
'unexercisedValue': 0},
{'maxAge': 1,
'name': 'Mr. Ron Okamoto',
'title': 'Head of Developer Relations',
'fiscalYear': 2023,
'exercisedValue': 0,
'unexercisedValue': 0},
{'maxAge': 1,
'name': 'Mr. Eduardo H. Cue',
'age': 60,
'title': 'Senior Vice President of Services',
'yearBorn': 1964,
'fiscalYear': 2023,
'totalPay': 2807461,
'exercisedValue': 0,
'unexercisedValue': 0}],
'auditRisk': 3,
'boardRisk': 1,
'compensationRisk': 3,
'shareHolderRightsRisk': 1,
'overallRisk': 1,
'governanceEpochDate': 1735689600,
'compensationAsOfEpochDate': 1703980800,
'irWebsite': 'http://investor.apple.com/',
'maxAge': 86400,
'priceHint': 2,
'previousClose': 237.59,
'open': 247.04,
'dayLow': 233.44,
'dayHigh': 247.19,
'regularMarketPreviousClose': 237.59,
'regularMarketOpen': 247.04,
'regularMarketDayLow': 233.44,
'regularMarketDayHigh': 247.19,
'dividendRate': 1.0,
'dividendYield': 0.0042,
'exDividendDate': 1731024000,
'payoutRatio': 0.1571,
'fiveYearAvgDividendYield': 0.61,
'beta': 1.24,
'trailingPE': 37.76,
'forwardPE': 28.501797,
'volume': 93080144,
'regularMarketVolume': 93080144,
'averageVolume': 49211806,
'averageVolume10days': 68909240,
'averageDailyVolume10Day': 68909240,
'bid': 235.77,
'ask': 239.4,
'bidSize': 300,
'askSize': 400,
'marketCap': 3572851277824,
'fiftyTwoWeekLow': 164.08,
'fiftyTwoWeekHigh': 260.1,
'priceToSalesTrailing12Months': 9.1369095,
'fiftyDayAverage': 240.008,
'twoHundredDayAverage': 219.37785,
'currency': 'USD',
'enterpriseValue': 3645256499200,
'profitMargins': 0.23971,
'floatShares': 15091184209,
'sharesOutstanding': 15037899776,
'sharesShort': 135189465,
'sharesShortPriorMonth': 156458273,
'sharesShortPreviousMonthDate': 1734048000,
'dateShortInterest': 1736899200,
'sharesPercentSharesOut': 0.009,
'heldPercentInsiders': 0.020669999,
'heldPercentInstitutions': 0.62310004,
'shortRatio': 2.74,
'shortPercentOfFloat': 0.009,
'impliedSharesOutstanding': 15139200000,
'bookValue': 3.767,
'priceToBook': 62.649323,
'lastFiscalYearEnd': 1727481600,
'nextFiscalYearEnd': 1759017600,
'mostRecentQuarter': 1727481600,
'earningsQuarterlyGrowth': -0.358,
'netIncomeToCommon': 93736001536,
'trailingEps': 6.25,
'forwardEps': 8.31,
'lastSplitFactor': '4:1',
'lastSplitDate': 1598832000,
'enterpriseToRevenue': 9.322,
'enterpriseToEbitda': 27.07,
'52WeekChange': 0.26593137,
'SandP52WeekChange': 0.22828305,
'lastDividendValue': 0.25,
'lastDividendDate': 1731024000,
'exchange': 'NMS',
'quoteType': 'EQUITY',
'symbol': 'AAPL',
'underlyingSymbol': 'AAPL',
'shortName': 'Apple Inc.',
'longName': 'Apple Inc.',
'firstTradeDateEpochUtc': 345479400,
'timeZoneFullName': 'America/New_York',
'timeZoneShortName': 'EST',
'uuid': '8b10e4ae-9eeb-3684-921a-9ab27e4d87aa',
'messageBoardId': 'finmb_24937',
'gmtOffSetMilliseconds': -18000000,
'currentPrice': 236.0,
'targetHighPrice': 325.0,
'targetLowPrice': 197.0,
'targetMeanPrice': 251.8335,
'targetMedianPrice': 254.5,
'recommendationMean': 2.0,
'recommendationKey': 'buy',
'numberOfAnalystOpinions': 40,
'totalCash': 65171001344,
'totalCashPerShare': 4.311,
'ebitda': 134660997120,
'totalDebt': 119058997248,
'quickRatio': 0.745,
'currentRatio': 0.867,
'totalRevenue': 391034994688,
'debtToEquity': 209.059,
'revenuePerShare': 25.485,
'returnOnAssets': 0.21464,
'returnOnEquity': 1.5741299,
'grossProfits': 180682997760,
'freeCashflow': 110846001152,
'operatingCashflow': 118254002176,
'earningsGrowth': -0.341,
'revenueGrowth': 0.061,
'grossMargins': 0.46206,
'ebitdaMargins': 0.34437,
'operatingMargins': 0.31171,
'financialCurrency': 'USD',
'trailingPegRatio': 2.1681}
yahoo_fines otra biblioteca de código abierto completamente gratuita, similar ayfinance, desarrollada por el autor de theautomatic. Carece de análisis de mercado/noticias, aunque ofrece una buena gama de datos de fundamentos y opciones. Puede consultar cada uno de los atributos de esta librería, a los cuale puede hacer en yahoo_fin-documentation. Para instalarla, utilice la siguiente orden:
pip install yahoo_fin
yahoo_fintambién tiene algunas dependencias:ftplib, io, pandas, requests, requests_html. Con la exsepción derequests_html, todos ellos deberían venir preinstalados conminiconda. Para instalarrequests_htmlutilice:
pip install requests_html
Para descargar datos históricos utilizando la biblioteca
yahoo_fin, el método a utilizar es esget_data(). Tendremos que importarlo desde el módulostock_info
from yahoo_fin.stock_info import get_data
Warning - Certain functionality
requires requests_html, which is not installed.
Install using:
pip install requests_html
After installation, you may have to restart your Python session.
Esta función toma los argumentos
ticker: ticker de la acción/bono deseado, sin distinción entre mayúsculas y minúsculasstart_date: fecha de inicio de los datos (mm/dd/aaaa)end_date: fecha en la que desea que finalicen los datos (mm/dd/aaaa)index_as_date: {True, False}. Por defecto esTrue. Si esTrueentonces las fechas de los registros se establecen como el índice, de lo contrario se devuelven como una columna separada.interval: {“1d”, “2wk”, “1mo”}. Se refiere al intervalo para muestrear los datos: “1d”= diario, “1wk”= semanal, “1mo”=mensual.
Por ejemplo, usemos la función
get_data()para obtener los datos asociados con la acción de Apple cuyo símbolo esAAPL, de la siguiente manera:
from datetime import datetime, timedelta
import seaborn as sns
import matplotlib.pyplot as plt
Usamos las funciones
set_theme()para configurar el tema a usar en las figuras, en éste caso paper el cual invocamos usandoset_context("paper"). Para ver más temas para figuras conseabornvisitar aesthetics.
sns.set_theme()
sns.set_context("paper")
stock = 'AAPL'
resolution = '1d'
end_date = datetime.now()
start_date = end_date - timedelta(days=365)
def date_format(date_h):
return date_h.strftime('%d/%m/%Y')
AAPL_df = get_data(stock, start_date=start_date, end_date=end_date, interval=resolution, index_as_date=False)
AAPL_df.head()
| date | open | high | low | close | adjclose | volume | ticker | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2024-02-01 | 183.990005 | 186.949997 | 183.820007 | 186.860001 | 185.949036 | 64885400 | AAPL |
| 1 | 2024-02-02 | 179.860001 | 187.330002 | 179.250000 | 185.850006 | 184.943954 | 102518000 | AAPL |
| 2 | 2024-02-05 | 188.149994 | 189.250000 | 185.839996 | 187.679993 | 186.765030 | 69668800 | AAPL |
| 3 | 2024-02-06 | 186.860001 | 189.309998 | 186.770004 | 189.300003 | 188.377151 | 43490800 | AAPL |
| 4 | 2024-02-07 | 190.639999 | 191.050003 | 188.610001 | 189.410004 | 188.486603 | 53439000 | AAPL |
Utilizaremos la función
lineplotdeseabornpara realizar un gráfico de la serie de tiempo de interés. Nótese que se ha colocado;al final de éste llamado, ¿con que objetivo?
sns.lineplot(data=AAPL_df, x=AAPL_df.date, y=AAPL_df.close);
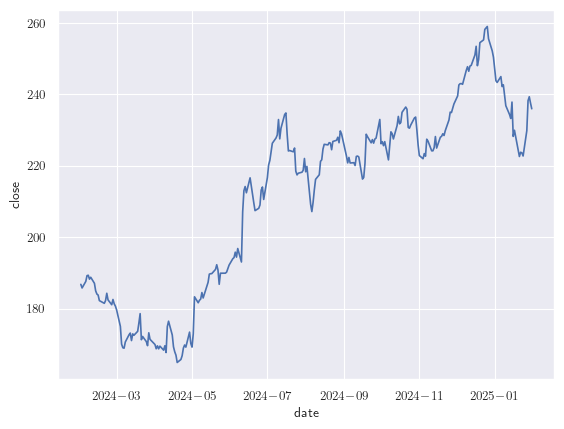
Gráficos de velas en Python: El gráfico de velas es un estilo de gráfico financiero que describe la apertura, el máximo, el mínimo y el cierre para una coordenada \(x\) determinada (probablemente la hora). Los recuadros representan la dispersión entre los valores de apertura y cierre y las líneas representan la dispersión entre los valores bajos y altos. Los puntos de muestra en los que el valor de cierre es mayor (menor) que el de apertura se denominan crecientes (decrecientes).
Por defecto, las velas crecientes se dibujan en verde, mientras que las decrecientes se dibujan en rojo. Para realizar la figura usamos la función
Figure()de la clasegodeplotly, esta función recibe como input los datos asociados al candlestick suministrados por medio de la funciónCandlesticktambién de la clasegodeplotly
import plotly.graph_objects as go
fig = go.Figure(data=[go.Candlestick(x = AAPL_df.date,
open = AAPL_df.open,
high = AAPL_df.high,
low = AAPL_df.low,
close = AAPL_df.close)
])
fig.update_layout(
title="Apple Inc. (AAPL)",
xaxis_title="Day",
yaxis_title="AAPL-USD",
font=dict(
family="Courier New, monospace",
size=12,
color="RebeccaPurple"
)
)
fig.update_layout(xaxis_rangeslider_visible=False)
fig
Utilizaremos ahora una prueba estadística para verificar si la serie de tiempo es estacionaria o no. Esta prueba es la de
Dickey-Fuller. En cursos avanzados de series de tiempo se estudian las matemáticas detrás de este tipo de pruebas así como los plots ACF y PACF, en esta sección solo mencionaremos en una bastante resumida la idea detrás de su uso.Para hacer uso de esta prueba importamos la función
adfullerde la clasestatsmodels.tsa.stattools. Para aplicar el test pasamos los datos del precio de cierre, serie de tiempo de interés, usandoAAPL_df.close. Este será el argumento de la funciónadfullerencargada de realizar el test deDickey-Fuller
from statsmodels.tsa.stattools import adfuller
from numpy import log
result = adfuller(AAPL_df.close)
print('ADF Statistic: %f' % result[0])
print('p-value: %f' % result[1])
ADF Statistic: -0.920830
p-value: 0.781035
Realizaremos ahora figuras de autocorrelación para confirmar que la serie de tiempo diferenciada es estacionaria, así como también para verificar cuál es el orden de integración necesario para llevar nuestra serie de tiempo no estacionaria a una estacionaría. Para esto usaremos la función
plot_acfde Python, la cual recibe como argumentos, la serie de tiempo de interés y el número de lags que deseamos considerar en la figura.Nótese que utilizamos la función
.diff()para realizar diferenciación en nuestra serie de tiempo, con el objetivo de remover tendencia, además nótese también que se eliminan valoresnanque podamos obtener en este proceso debido a que esta figura consiste en representar todos los valores \(\rho_{k}\) definidos anteriormente, donde aparece un cociente para el cual evitamos valores nulos en el denominador.Realizaremos tres figuras, correspondientes a la autocorrelación de la serie original, la serie diferenciada una vez, y dos veces. Colocaremos estas figuras en una matriz de \(3\times2\) usando la función
fig, axes = plt.subplots(3, 2, sharex=True)dematplotlib.
import numpy as np, pandas as pd
from statsmodels.graphics.tsaplots import plot_acf
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams.update({'figure.figsize': (15,15)})
fig, axes = plt.subplots(3, 2, sharex=True)
axes[0, 0].plot(AAPL_df.close); axes[0, 0].set_title('Original Series')
plot_acf(AAPL_df.close, ax=axes[0, 1], lags = 240);
axes[1, 0].plot(AAPL_df.close.diff()); axes[1, 0].set_title('1st Order Differencing')
plot_acf(AAPL_df.close.diff().dropna(), ax=axes[1, 1], lags = 240);
axes[2, 0].plot(AAPL_df.close.diff().diff()); axes[2, 0].set_title('1st Order Differencing')
plot_acf(AAPL_df.close.diff().diff().dropna(), ax=axes[2, 1], lags = 240);
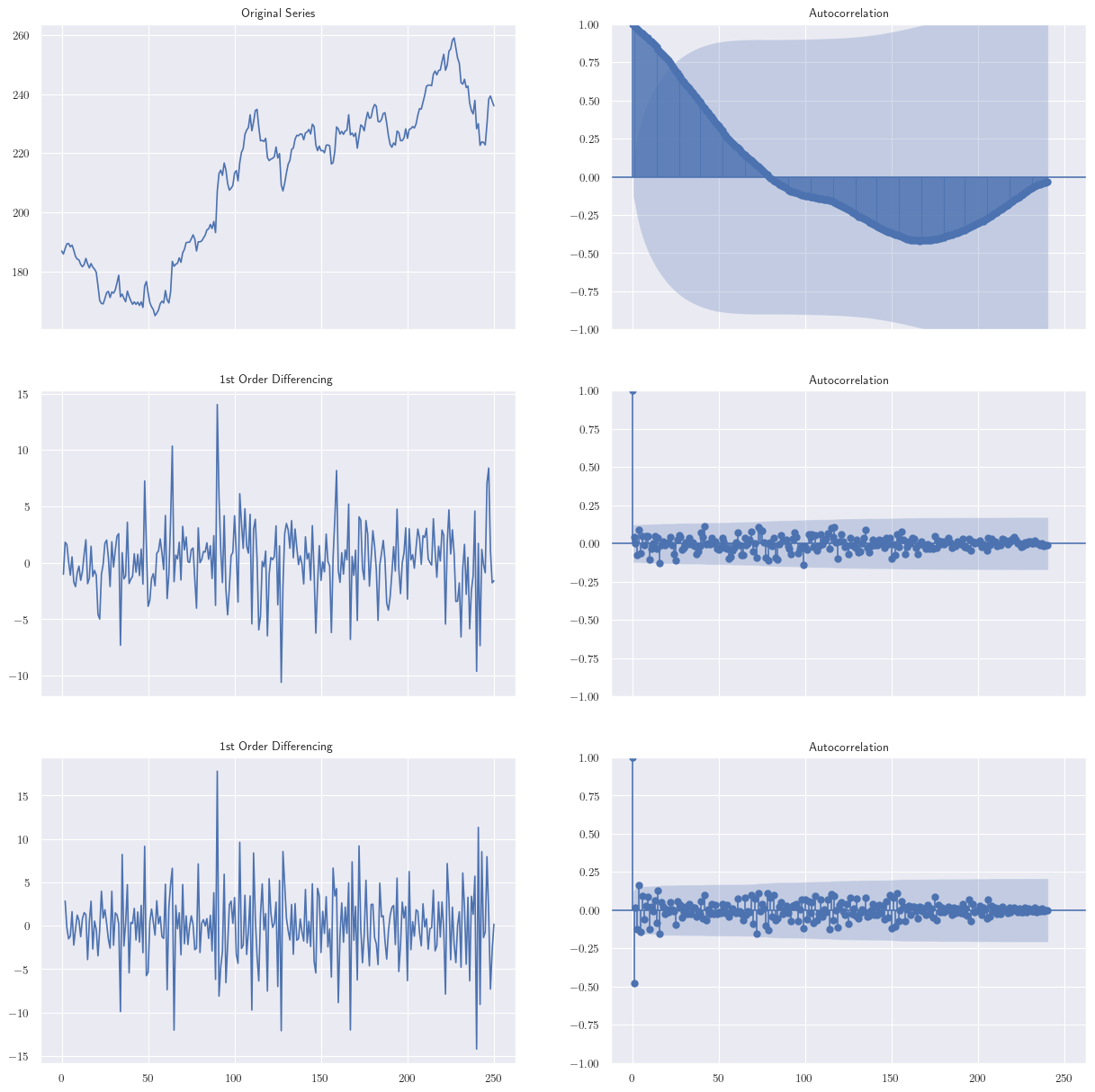
Nótese el decaimiento geométrico en la primera figura de autocorrelación, que baja desde la parte positiva con una tendencia lineal, el cual se interpreta como una autocorrelación asociada a una serie de tiempo no estacionaría, como indica la prueba de
Dickey-Fullerque presenta efectivamente tendencias.Los intervalos de confianza se dibujan como un cono. Por defecto, se establece un intervalo de confianza del 95%. Al observar el gráfico de autocorrelación para la segunda diferenciación, la segunda autocorrelación entra en la zona negativa con bastante rapidez, lo que indica que la serie podría haber sido sobrediferenciada.
n_AAPL = len(AAPL_df.close); n_test = 28 # This can be changed
train_size = n_AAPL - n_test
train = AAPL_df.close[:train_size]
dates_train = AAPL_df.date[:train_size]
test_4w = AAPL_df.close[train_size:train_size + n_test]
dates_4w = AAPL_df.date[train_size:train_size + n_test]
print("train:", train.shape)
print("test_4w:", test_4w.shape)
train: (223,)
test_4w: (28,)
train_df = AAPL_df[["close"]][:train_size]
test_4w_df = AAPL_df[["close"]][train_size:train_size + n_test]
test_4w_df.head()
| close | |
|---|---|
| 223 | 249.789993 |
| 224 | 254.490005 |
| 225 | 255.270004 |
| 226 | 258.200012 |
| 227 | 259.019989 |
Utlizamos ahora el modelo
ARIMAimportado desde la libreríastatsmodelsde Python para obetener distintos ARIMA de ordenes \(p,d,q\). Consideramosmethod = 'mle'para el cálculo de la verosimilitud exacta a través del filtro de Kalman. Como ejercicio puede reescribir estas líneas de código en una función que dependa sólo del inputtrainy retorne los ordenes \(p, d, q\) asociados al criterio AIC de bondad de ajuste
from statsmodels.tsa.arima.model import ARIMA
best_aic = np.inf
best_bic = np.inf
best_order = None
best_mdl = None
pq_rng = range(5)
d_rng = range(3)
for i in pq_rng:
for d in d_rng:
for j in pq_rng:
try:
# print(i, d, j)
tmp_mdl = ARIMA(train, order=(i,d,j)).fit()
tmp_aic = tmp_mdl.aic
if tmp_aic < best_aic:
best_aic = tmp_aic
best_order = (i, d, j)
best_mdl = tmp_mdl
except: continue
print('aic: {:6.5f} | order: {}'.format(best_aic, best_order))
aic: 1109.19021 | order: (0, 1, 0)
Existe una función llamada
auto_arimade Python la cual es útli en ciertos casos especificos. Éste no es uno de ellos dado que el modelo ARIMA que entrega es un simple random walk \(x_{t}=x_{t-1}+\omega_{t}\), el cual predice puramente como un modelo estocástico con dependencia temporal basado totalmente en el punto temporal anterior \(t-1\)
import pmdarima as pm
model = pm.arima.auto_arima(train, start_p=1, start_q=1,
test='adf', # use adftest to find optimal 'd'
max_p=3, max_q=3, # maximum p and q
m=1, # frequency of series
d=None, # let model determine 'd'
seasonal=False, # No Seasonality
start_P=0,
D=0,
trace=True,
error_action='ignore',
suppress_warnings=True,
stepwise=True)
Performing stepwise search to minimize aic
ARIMA(1,1,1)(0,0,0)[0] intercept : AIC=1112.783, Time=0.04 sec
ARIMA(0,1,0)(0,0,0)[0] intercept : AIC=1109.216, Time=0.01 sec
ARIMA(1,1,0)(0,0,0)[0] intercept : AIC=1110.882, Time=0.01 sec
ARIMA(0,1,1)(0,0,0)[0] intercept : AIC=1110.845, Time=0.01 sec
ARIMA(0,1,0)(0,0,0)[0] : AIC=1109.190, Time=0.00 sec
Best model: ARIMA(0,1,0)(0,0,0)[0]
Total fit time: 0.070 seconds
Por lo tanto para éste problema consideramos los mejores ordenes \(p, d, q\) obtenidos a a partir del criterio de Akaike. Los usamos como argumento de entrada en nuestro modelo ARIMA junto a nuestro train set, para obtener el modelo de ajustado de interés que utlizaremos para predecir valores futuros usando rolling
from statsmodels.graphics.tsaplots import plot_predict
model = ARIMA(train, order=best_order)
model_fit = model.fit()
model_fit.plot_diagnostics(figsize=(14,10));
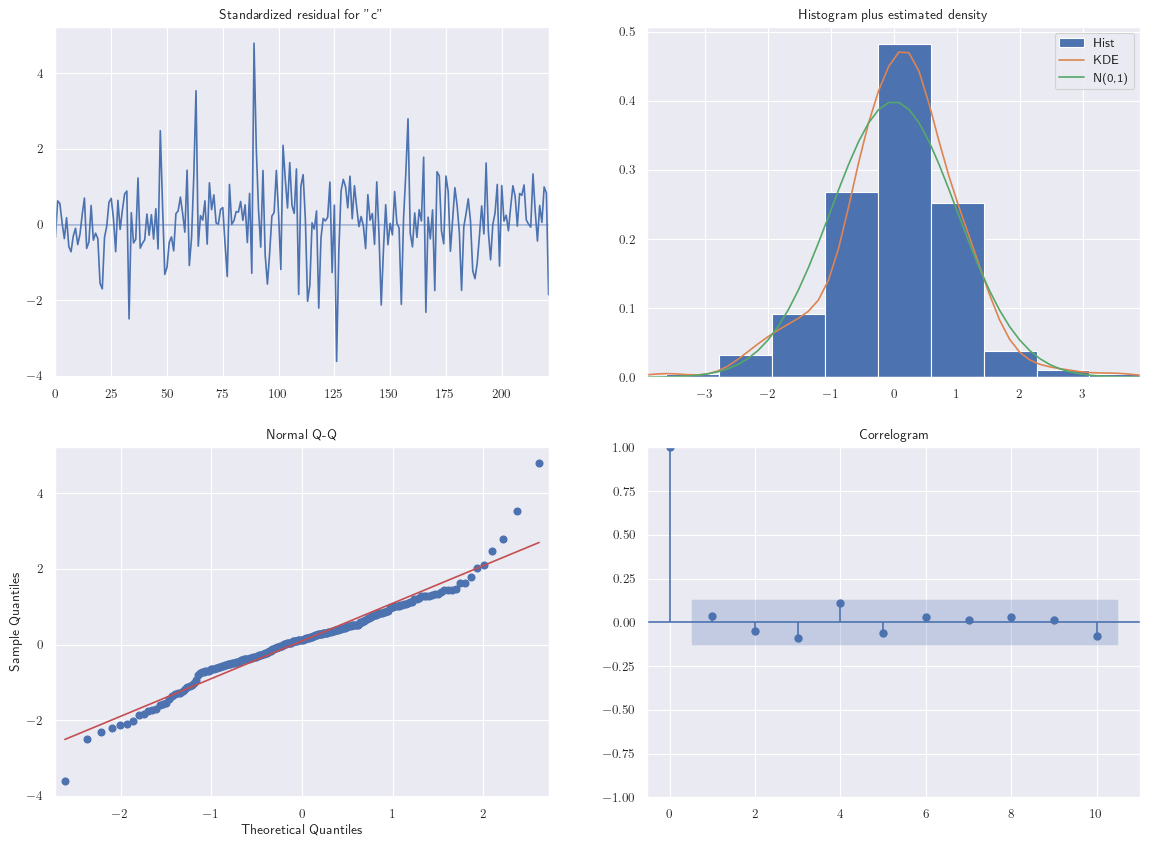
acf_djia, confint_djia, qstat_djia, pvalues_djia = stattools.acf(model_fit.resid,
nlags=20,
qstat=True,
alpha=0.05)
alpha = 0.05
for l, p_val in enumerate(pvalues_djia):
if p_val > alpha:
print('Null hypothesis is accepted at lag = {} for p-val = {}'.format(l, p_val))
else:
print('Null hypothesis is rejected at lag = {} for p-val = {}'.format(l, p_val))
Null hypothesis is accepted at lag = 0 for p-val = 0.9433865178689261
Null hypothesis is accepted at lag = 1 for p-val = 0.994493997425733
Null hypothesis is accepted at lag = 2 for p-val = 0.9996438796276171
Null hypothesis is accepted at lag = 3 for p-val = 0.9999613073289275
Null hypothesis is accepted at lag = 4 for p-val = 0.9999821581947234
Null hypothesis is accepted at lag = 5 for p-val = 0.9999984198045504
Null hypothesis is accepted at lag = 6 for p-val = 0.9999995179965943
Null hypothesis is accepted at lag = 7 for p-val = 0.9999998344316939
Null hypothesis is accepted at lag = 8 for p-val = 0.9999999772906434
Null hypothesis is accepted at lag = 9 for p-val = 0.9999999960156721
Null hypothesis is accepted at lag = 10 for p-val = 0.999999998455671
Null hypothesis is accepted at lag = 11 for p-val = 0.9999999997689308
Null hypothesis is accepted at lag = 12 for p-val = 0.9999999999683596
Null hypothesis is accepted at lag = 13 for p-val = 0.999999999995732
Null hypothesis is accepted at lag = 14 for p-val = 0.9999999999991208
Null hypothesis is accepted at lag = 15 for p-val = 0.9999999999995468
Null hypothesis is accepted at lag = 16 for p-val = 0.9999999999999177
Null hypothesis is accepted at lag = 17 for p-val = 0.9999999999999867
Null hypothesis is accepted at lag = 18 for p-val = 0.9999999999999982
Null hypothesis is accepted at lag = 19 for p-val = 0.9999999999999997
Para graficar el ajuste de nuestro modelo ARIMA frente a nuestro conjunto de entrenamiento utilizamos la función
plot_predictque proviene del objeto instanciado usando la función ARIMA.
plt.rcParams.update({'figure.figsize': (10,6)})
fig, ax = plt.subplots();
plot_predict(model_fit, 2, ax=ax);
plt.show();
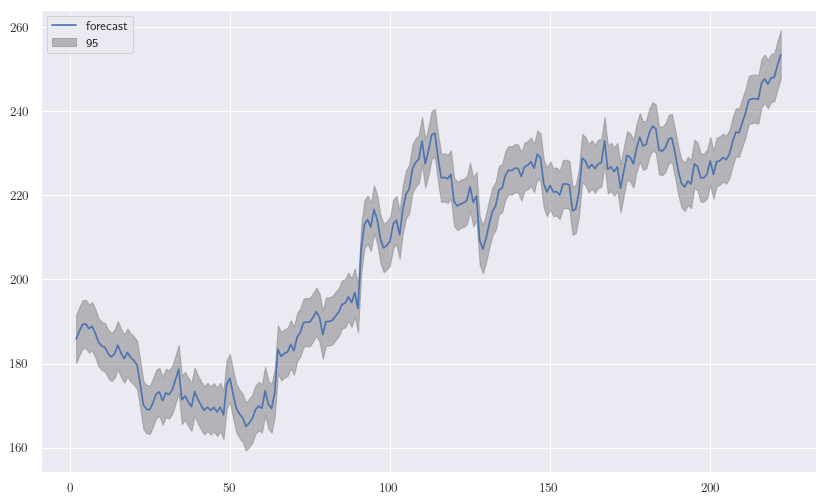
Para medir el error de predicción cometido en las predicciones, utilizaremos las métricas usuales en análisis de series de tiempo:
MAPE, MAE, RMSE, MSE
def forecast_accuracy(forecast, actual, str_name):
mape = np.mean(np.abs(forecast - actual)/np.abs(actual)) # MAPE
mae = np.mean(np.abs(forecast - actual)) # MAE
rmse = np.mean((forecast - actual)**2)**.5 # RMSE
mse = np.mean((forecast - actual)**2) # MSE
df_acc = pd.DataFrame({'MAE': [mae],
'MSE': [mse],
'MAPE': [mape],
'RMSE': [rmse]},
index=[str_name])
return df_acc
3.26.1. Rolling forecast#
Realizamos ahora predicciones utilizando rolling forecasting. El rolling forecast entrega reportes que utilizan datos históricos para predecir cifras futuras de forma continua durante un periodo de tiempo. Las previsiones continuas se utilizan a menudo en los reportes financieros, la gestión de la cadena de suministro, la planificación y la elaboración de presupuestos.
El rolling forecast es una ayuda esencial para tomar decisiones empresariales acertadas. Gracias a su capacidad de respuesta, las previsiones continuas ayudan a las empresas a responder más rápidamente a las condiciones cambiantes del mercado. Si se utilizan con eficacia, las previsiones continuas pueden ayudar a identificar las deficiencias de rendimiento, acortar los ciclos de planificación y tomar la mejor decisión para los resultados. Para nuestros ejemplos, nuestro horizonte de predicción será de un día
def arima_rolling(history, test):
predictions = list()
for t in range(len(test)):
model = ARIMA(history, order=best_order)
model_fit = model.fit()
output = model_fit.forecast()
yhat = output[0]
predictions.append(yhat)
obs = test[t]
history.append(obs)
print('predicted=%f, expected=%f' % (yhat, obs))
return predictions
test_4wl = test_4w.tolist()
yhat_4w = arima_rolling(train.tolist(), test_4wl)
predicted=248.050003, expected=249.789993
predicted=249.789993, expected=254.490005
predicted=254.490005, expected=255.270004
predicted=255.270004, expected=258.200012
predicted=258.200012, expected=259.019989
predicted=259.019989, expected=255.589996
predicted=255.589996, expected=252.199997
predicted=252.199997, expected=250.419998
predicted=250.419998, expected=243.850006
predicted=243.850006, expected=243.360001
predicted=243.360001, expected=245.000000
predicted=245.000000, expected=242.210007
predicted=242.210007, expected=242.699997
predicted=242.699997, expected=236.850006
predicted=236.850006, expected=234.399994
predicted=234.399994, expected=233.279999
predicted=233.279999, expected=237.869995
predicted=237.869995, expected=228.259995
predicted=228.259995, expected=229.979996
predicted=229.979996, expected=222.639999
predicted=222.639999, expected=223.830002
predicted=223.830002, expected=223.660004
predicted=223.660004, expected=222.779999
predicted=222.779999, expected=229.860001
predicted=229.860001, expected=238.259995
predicted=238.259995, expected=239.360001
predicted=239.360001, expected=237.589996
predicted=237.589996, expected=236.000000
forecast_accuracy(np.array(test_4wl), np.array(yhat_4w), "4 weeks")
| MAE | MSE | MAPE | RMSE | |
|---|---|---|---|---|
| 4 weeks | 3.08607 | 16.322772 | 0.012905 | 4.040145 |
ax = sns.lineplot(x=dates_train[-100:], y=train[-100:], label="Train", color='g')
sns.lineplot(x=dates_4w, y=test_4wl, label="Test", color='b')
sns.lineplot(x=dates_4w, y=yhat_4w, label="Forecast", color='r')
plt.show()
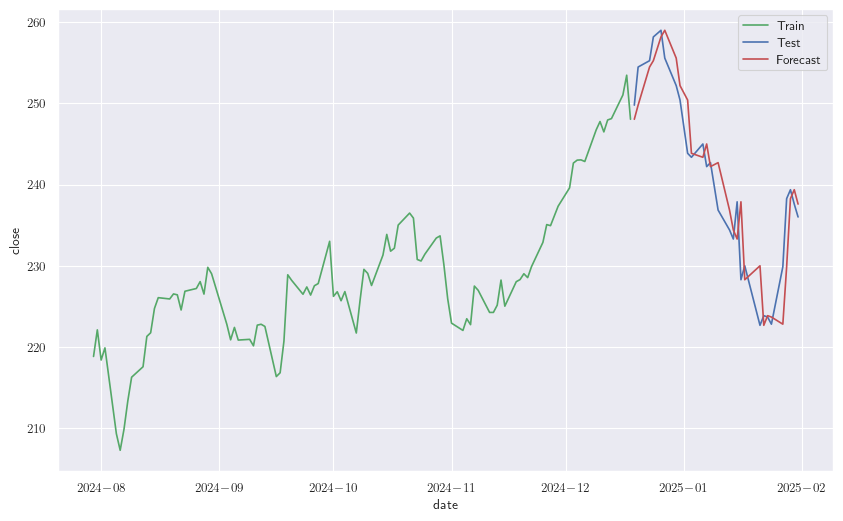
pred_error = np.array(test_4wl) - np.array(yhat_4w)
from pandas.plotting import autocorrelation_plot
La función de autocorrelación ACF nos muestra que los residuos de predicción son independientes, no correlacionados, tal como se espera en esta prueba
fig = plt.figure(figsize=(5.5, 5.5))
autocorrelation_plot(pred_error, color='b')
plt.title('ACF for Prediction Error');
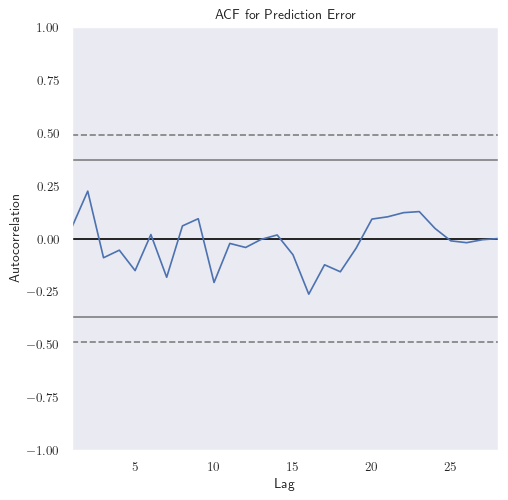
acf_djia, confint_djia, qstat_djia, pvalues_djia = stattools.acf(pred_error,
nlags=20,
qstat=True,
alpha=0.05)
alpha = 0.05
for l, p_val in enumerate(pvalues_djia):
if p_val > alpha:
print('Null hypothesis is accepted at lag = {} for p-val = {}'.format(l, p_val))
else:
print('Null hypothesis is rejected at lag = {} for p-val = {}'.format(l, p_val))
Null hypothesis is accepted at lag = 0 for p-val = 0.7625074933101608
Null hypothesis is accepted at lag = 1 for p-val = 0.4252317996542302
Null hypothesis is accepted at lag = 2 for p-val = 0.5751817323269726
Null hypothesis is accepted at lag = 3 for p-val = 0.7187666856646902
Null hypothesis is accepted at lag = 4 for p-val = 0.7107928670812402
Null hypothesis is accepted at lag = 5 for p-val = 0.8159193399735329
Null hypothesis is accepted at lag = 6 for p-val = 0.7467232157291811
Null hypothesis is accepted at lag = 7 for p-val = 0.8161873316524504
Null hypothesis is accepted at lag = 8 for p-val = 0.849770980439386
Null hypothesis is accepted at lag = 9 for p-val = 0.7414693922968505
Null hypothesis is accepted at lag = 10 for p-val = 0.8106715575241739
Null hypothesis is accepted at lag = 11 for p-val = 0.8609704152171032
Null hypothesis is accepted at lag = 12 for p-val = 0.9047288260397084
Null hypothesis is accepted at lag = 13 for p-val = 0.9359898182982951
Null hypothesis is accepted at lag = 14 for p-val = 0.9472981118305062
Null hypothesis is accepted at lag = 15 for p-val = 0.7315560083110941
Null hypothesis is accepted at lag = 16 for p-val = 0.7123220582959362
Null hypothesis is accepted at lag = 17 for p-val = 0.6327743493467581
Null hypothesis is accepted at lag = 18 for p-val = 0.6827129563235688
Null hypothesis is accepted at lag = 19 for p-val = 0.6849689939002953
Resumen
En este capítulo, cubrimos los modelos autorregresivos como un modelo \(MA\) para capturar la correlación serial utilizando la relación de error. En líneas similares, se cubrieron los modelos \(AR\), que establecen la previsión utilizando los rezagos como observaciones dependientes. Los modelos \(AR\) son buenos para captar información sobre tendencias. También se ilustró el enfoque basado en \(ARMA\), que integra los modelos \(AR\) y \(MA\) para captar las tendencias temporales y los acontecimientos inesperados que provocan muchos errores que tardan en corregirse, como una crisis económica.
Todos estos modelos suponen estacionariedad; en los casos en los que no se da estacionariedad, se utiliza un modelo basado en la diferenciación, como el \(ARIMA\), que diferencia los conjuntos de datos de series temporales para eliminar cualquier tendencia. Los métodos de previsión se ilustraron con ejemplos utilizando el módulo
tsadePython. El presente capítulo se centra en el uso demétodos estadísticospara la previsión. En el capítulo siguiente se ampliará el enfoque estadístico a los métodos deaprendizaje automáticopara la previsión, concretamentemodelos de aprendizaje profundo.